支持向量機在分析型CRM中的應用研究
2010-08-14 01:11:26楊啟仁杜圣東
網絡安全與數據管理 2010年13期
楊啟仁 ,杜圣東
(1.貴州民族學院 計算機與信息工程學院,貴州 貴陽 550025;2.西南交通大學 CAD工程中心,四川 成都 610031)
隨著通信市場競爭的加劇,移動運營商之間對客戶的爭奪也日趨激烈。各運營商都有自己完整的運營支撐系統,如計費系統、帳務系統、營業系統和客戶服務系統等。這些系統累積了海量的客戶相關數據,很多企業也都擁有自己的客戶關系管理CRM(Custom Relationship Management)系統[1]。如何通過數據挖掘技術對CRM系統中累積的大量歷史數據進行分析處理,以提供有效的決策知識,從而獲得新客戶,提高客戶滿意度、防止客戶流失是分析型CRM的目標。分析型CRM[2](Analytic CRM)是創新和使用客戶知識(在這一過程中采用數據倉庫、OLAP和數據挖掘技術對客戶數據進行分析,提煉出有用信息),幫助企業提高優化客戶關系的決策能力和整體運營能力的概念、方法、過程以及軟件的集合。CRM從上世紀90年代初基于部門級的專用解決方案,(如銷售隊伍自動化、客戶服務支持)發展到現在以客戶為中心的整體解決方案,尤其是Internet的迅猛發展與成熟的電子商務平臺,大大推進了應用的廣度和深度。目前,數據挖掘與CRM相結合的分析型CRM相關技術的研究與應用成為學術界和工業界研究的熱點。
統計學習理論[3]是一種專門研究小樣本情況下機器學習規律的理論,支持向量機SVM(Support Vector Machine)作為一種新的數據挖掘技術,是在統計學習理論的基礎上發展起來的新的學習算法。由于其基于結構風險最小化原則,即由有限的訓練樣本集得到較小的誤差以確保對獨立的測試樣本集仍保持較小的誤差,因此能有效地解決過學習問題,具有良好的推廣性;另外,由于SVM算法能解決凸優化問題,局部最優解就是其全局最優解,因此具有較好的分類準確性。這些優良特性使得SVM成為繼人工神經網絡ANN(Artifical Neural Network)[4]和模式識別之后的又一研究熱點。最有代表性的是美國郵政手寫數字庫識別研究成功地應用了SVM。在其他應用領域,如人臉識別、語音識別、模式識別、圖像處理及文本分類等方面也取得了大量的研究成果。
本文在研究支持向量機并將其應用于分析型CRM的過程中,以移動通信作為分析型CRM系統的典型應用行業,其原因除了滿足更激烈的商業競爭外,還在于其擁有較為完整的、規范化的并對其發展戰略十分重要的客戶數據基礎。根據CRM中的客戶歷史數據對未來客戶流失的可能性進行預測評估,為決策者提供有用知識具有一定的實用意義。
1支持向量機(SVM)
VAPNIK V提出的SVM理論[5]最基本的思想之一是結構化風險最小化原則SRM(Structural Risk Minimization),該理論優于傳統的經驗風險最小化原則ERM(Empirical Risk Minimization)。不同于ERM試圖最小化訓練集上的誤差的做法,SRM試圖最小化VC維的上界(SRM和VC維理論見參考文獻[6]),與傳統的降維方法相反,SVM通過提高數據的維度把非線性分類問題轉換成線性分類問題,較好地解決了傳統學習算法(如人工神經網絡)中訓練集誤差最小而測試集誤差仍較大的問題,算法的效率和精度都有很大提高。近年來該方法成為構造數據挖掘分類模型和數據挖掘回歸預測模型的一項新型技術。
1.1 SVM分類算法
SVM是通過構造一個最優超平面,對二值分類問題進行分割。所謂最優分類面就是要求分類面不但能將二值分類正確分開(保證經驗風險最小),而且使分類間隔最大。
以對 m 個樣本:(x1,y1),(x2,y2),…,(xm,ym)求解最優分類超平面為例,求解系數w和b,使超平面(wx)+b=0達到分類誤差小、推廣能力強的要求。必須滿足最優分類超平面的條件:
根據最優化理論,利用Lagrange函數將其轉化為求解標準型二次型規劃問題:
求解上式得最優分類決策函數為:
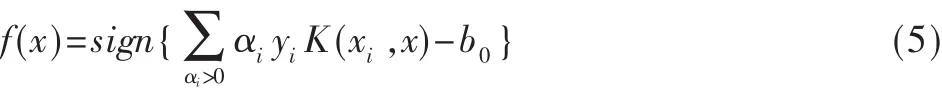
b0可由約束條件 αi[yi(wTxi+b)-1]=0求解,αi不為零的樣本即為支持向量。
對于非線性二元分類,則通過某種事先選擇的非線性映射(即核函數),將輸入向量x映射到一個高維特征空間中,然后在這個高維空間中構造最優分類超平面,這種方法通過核函數做升維處理避免了在高維特征空間中進行復雜的運算。
1.2 SVM分類預測模型
由于現有的SVM分類模型[7]用于數據挖掘還處于試驗階段,通常只對訓練好的模型做簡單的測試。雖然測試模型可以對該模型的推廣性能做出一些定量分析,但在現實中該分類模型是否真正實用還需了解其特點,如模型推廣性、模型穩定性等。可將SVM分類模型應用于分析型CRM的客戶流失分類預測,分類模型的完整建立過程分為:學習階段、測試階段和評估階段。
1.2.1學習訓練階段
(1)從客戶主題數據集市中抽取客戶相關數據建立訓練樣本集;

(2)選擇合適的核函數及核參數,作為高維特征空間在低維輸入空間的一個等效形式;
(3)對輸入訓練樣本進行規范化,將輸入數據限定在核函數要求的范圍之內;
(4)構造核矩陣 H(n,n);
(5)在式(7)約束條件下,最大化式(8),以求解拉格朗日系數 a;
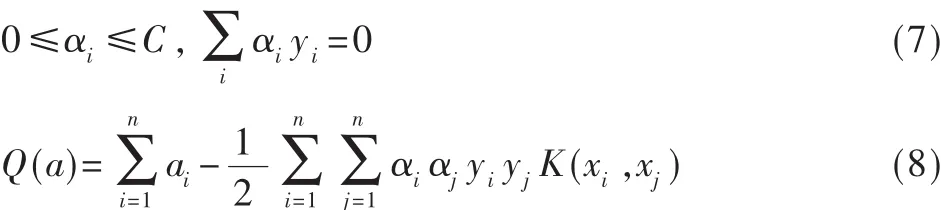
(6)找出支持向量SV,求解分類超平面系數b;
(7)建立訓練數據的最優決策超平面,完成訓練過程。
1.2.2測試階段
(1)裝入SVM學習階段的有關數據,包括訓練數據,系數a、b,以及得到的支持向量 SV;
(2)根據

計算新輸入測試數據樣本的相應決策輸出值;
(3)利用指示函數將 f(x)歸為{-1,+1},做出分類決策。
1.2.3評估階段
在用實驗數據訓練和測試模型時,只是對該模型的預測效果作簡單的對比,如果訓練好的模型實際輸出與預測輸出誤差很小,可認為該模型推廣能力強。但現實中的數據是多變的,只是用歷史數據進行預測,并不能表明該模型在后續預測中一直會有好的效果。本文所提出的評估階段實際上是預測模型的試運行過程,在該過程中,把現實中的數據輸入測試好的模型,根據輸出對模型作一些優化和調整。
以上三個階段是一個循環往復的過程:首先用訓練集建立初始模型,將測試集輸入訓練好的初始模型得出測試誤差,如果誤差較大則反復修正初始模型,當修正后的模型效果達到要求時,再用評價數據集對該模型進行評價,如果評估效果不好,則返回修正模型,如此反復直到得出最優的分類預測模型。
2分析型CRM
2.1分析型CRM體系結構
分析型CRM體系結構如圖1所示,分為數據源層、數據存儲層、應用支持層和用戶交互層。
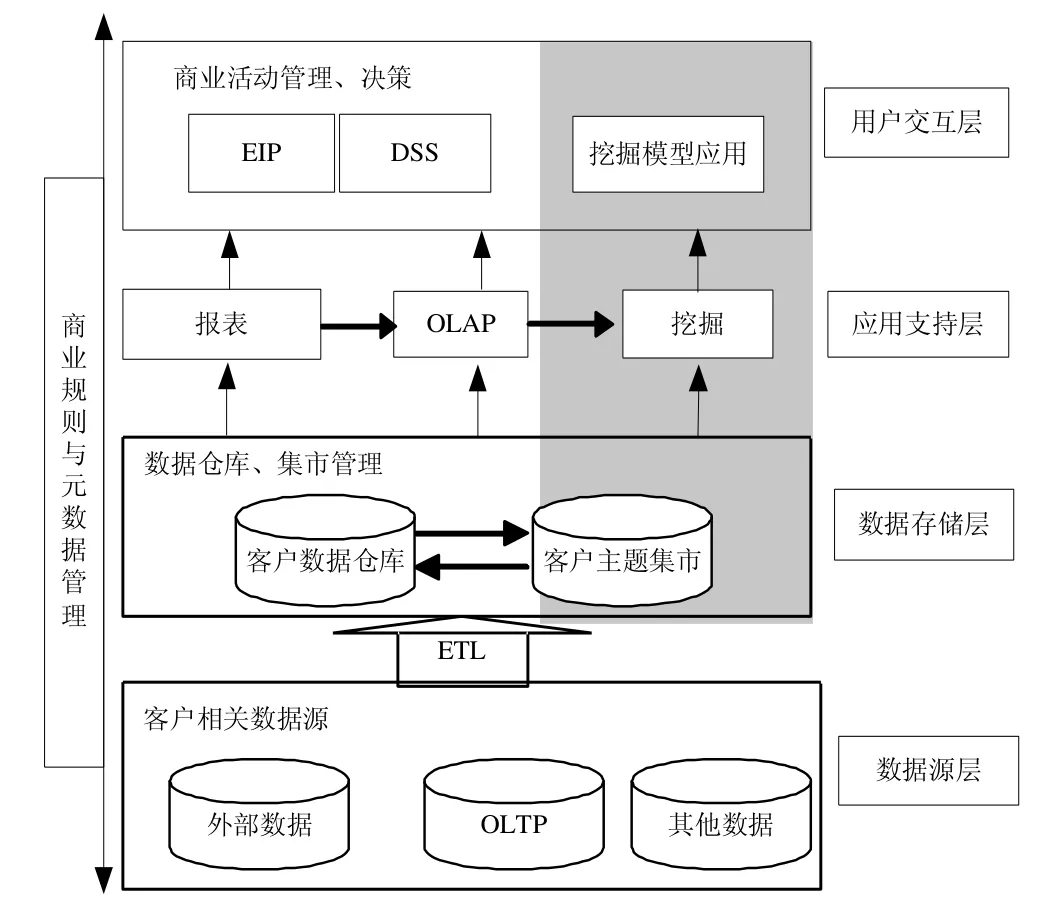
圖1 分析型CRM體系結構
(1)數據源層包括了企業常用信息系統和一些外部系統的數據源,如涉及客戶交互的一些交易系統和服務系統,但各系統間的客戶數據是分散的,而且可能重合,會出現不一致的問題。
(2)數據存儲層是為了整個企業有集中統一的客戶視圖,通過從各源系統抽取數據,進行整合的數據倉庫,在客戶數據倉庫的基礎上,可以建立相關分析的客戶主題數據集市。
(3)應用支持層除了支持復雜、智能化報表查詢外,還支持OLAP分析,提供數據挖掘功能。
(4)用戶交互層提供分析、挖掘結果,企業管理、決策層和企業其他服務人員與客戶的交互形成反饋機制,從而有效地利用分析和挖掘得到有用知識。
本文研究重點是陰影板塊部分:
(1)在企業已有CRM數據倉庫的基礎上,抽取出客戶流失預測相關的數據,建立相關主題的客戶數據集市;
(2)從客戶主題數據集市中抽取客戶流失相關表的一些關鍵屬性字段,形成SVM分類預測挖掘模型的輸入數據;
(3)通過對SVM分類預測模型的訓練和驗證,并對最優模型進行應用,進一步驗證反饋,形成比較穩定的客戶流失分類預測模型。
2.2分析型CRM主題數據集市設計
通信行業主要采用事實表和維表的形式建立數據倉庫。在建立數據集市過程中重點考慮BOSS系統和分析型CRM的接口,不僅要實現物理上的轉化,而且還要在邏輯上實現從BOSS系統實體到數據倉庫實體的成功過渡。這是因為數據倉庫的數據不再是業務類型,而是按主題組織。如BOSS系統中含有客戶管理類實體、計費賬務管理類實體等;而數據倉庫則分為客戶主題、賬務主題等。
本文中客戶主題數據集市[8]是從CRM數據倉庫中抽取客戶數據、業務數據、帳務數據等信息,這些數據經過轉換、裝載、聚合進入到接口數據層,可作為客戶流失分類預測模型的基礎數據;數據模型層再根據模型需求對接口層數據進行匯總,生成客戶流失分類預測挖掘模型輸入的寬表,總體數據集市結構如圖2所示。
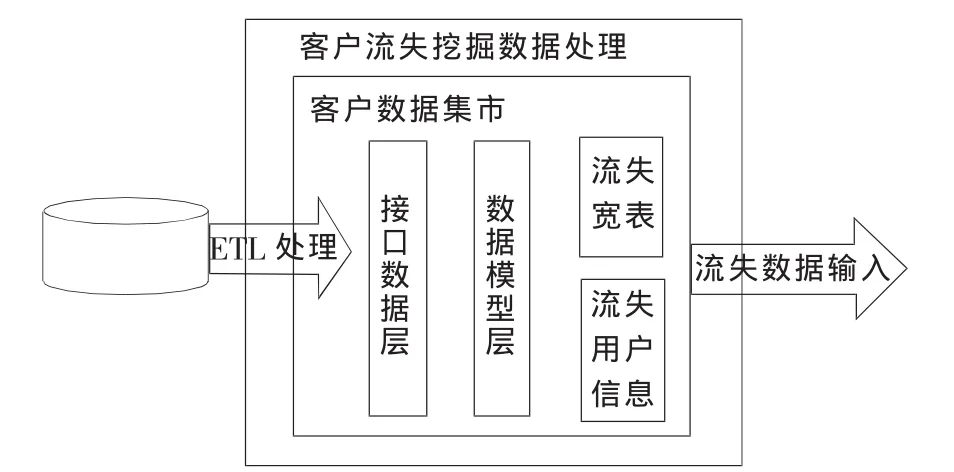
圖2 客戶主題數據集市結構圖
3實證研究
3.1電信數據處理
本文針對流失挖掘的需求建立了相關的客戶主題數據集市,從客戶數據倉庫中抽取流失分類預測挖掘主題相關的數據,即提取與客戶流失因素相關的屬性,并且選擇部分數據作為訓練集。涉及到的數據源(這里只列出有代表性的字段,實際模型調整過程中,個別字段和屬性可根據業務建議和模型本身特點添加或者刪減)如表1所示。
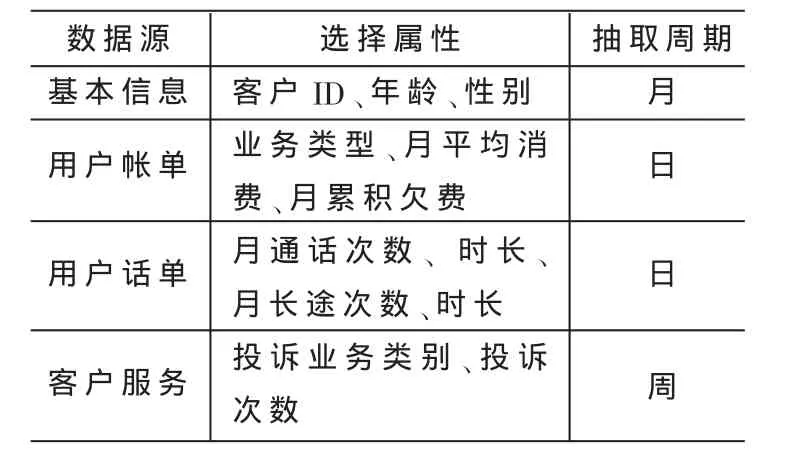
表1 數據源描述
在提取的與流失因素相關的屬性中,既有單粒度屬性,又有多重粒度的屬性,還有派生屬性。在屬性選擇的過程中,用到了屬性歸約和泛化技術,最終選取表1中的屬性作為模型輸入字段,客戶流失標記(在網、流失)作為模型輸出。客戶流失標記的處理如下:在2個月的預測期和1個月的評估期中,正常客戶可以呈現出多種異常狀態。文中以其中3種狀態為流失傾向的客戶特征,對其做流失標記:
(1)拆機。
(2)2個月零通話(2個月總通話次數=0且總發短信次數=0)。
(3)2個月低額消費(每個月通話次數≤5且每個月發短信次數≤5),代表一定的流失傾向。
流失分類預測模型利用3個月的的歷史數據對客戶在未來2個月的流失傾向進行預測,用未來第3個月的數據進行評估。本文選擇基于200501~200504月之間3個月的客戶數據對SVM模型進行訓練,用200505~200506之間1個月的數據進行預測,用200507月的客戶數據進行評估。
3.2實驗結果分析
經過數據預處理后,形成了模型輸入的匯總表(即寬表),輸入到本文的SVM分類預測模型中進行訓練、預測和評估。模型指標評價如圖3所示,模型的評價指標主要是查全率和查準率,具體指標如下:
查準率=命中用戶/預測離網用戶
查全率=命中用戶/實際離網用戶
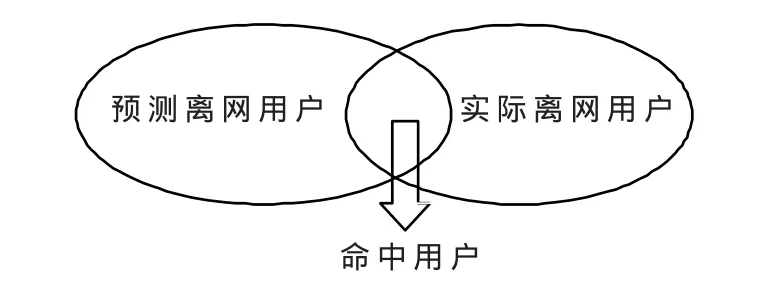
圖3 模型指標評價
通過對SVM模型的反復調整,形成最優模型時各處理階段的數據如表2所示。
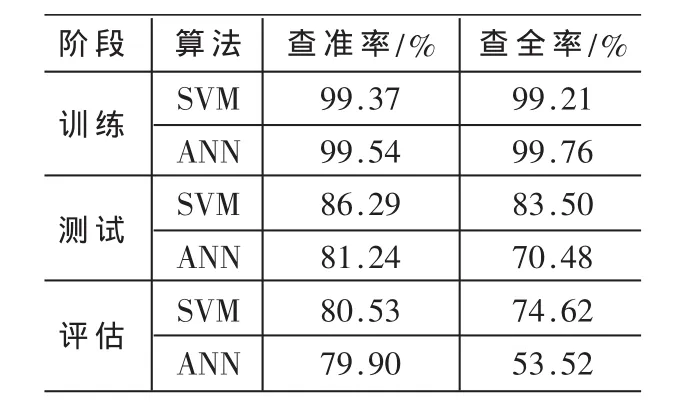
表2 實驗結果
從表2的實驗數據可以看出,本文中的SVM分類模型相對ANN分類模型,做客戶流失分類預測和評估時的查全率和查準率都有一定提高。在訓練階段,由于ANN存在過度訓練情況,查全率和查準率都比SVM的訓練精度要高;而測試階段,SVM模型良好的推廣性得到了驗證,相比ANN的查全、查準率有較大提高;在評估階段,SVM分類模型相對于ANN更是表現出了很好的穩定性。
分析型CRM在各領域的應用已經十分廣泛,能否有效地應用數據挖掘技術對于分析型CRM十分關鍵。本文將支持向量機這種新的數據挖掘方法應用于移動領域客戶流失挖掘,對客戶離網的可能性進行預測,為決策者提供有用知識。實驗中對SVM和ANN這兩種模型用于流失分類預測的效果進行了對比,結果顯示SVM相比ANN具有更優的分類預測效果和更好的模型穩定性,從而驗證了SVM應用于分析型CRM中的客戶流失挖掘是有效可行的。
[1]BARNES J G.Secrets of customer relationship management[M].McGraw.Hill Education,2001.
[2]BERSON A, SMITH S, THEARLING K.Building data mining applications for crm[M].McGraw.Hill Education,1999.
[3]VAPNIK V.The nature of statistical learning theory[M].New York, Springer, 1995.
[4]ALMEIDA J S.Predictive non-linear modeling of complex data by artificial neural networks[J].Curr Opin Biotechnol.2002,13(1):72-6.
[5]CRISTIANINI N,SHAWE J.An introduction to support vector machines,Cambridge[M].U.K Cambridge University Press,2000.
[6]CHERKASSKY V, SHAO X, MULIER F, et al.Model complexity control for regression using VC generalization Bounds[J].IEEE Transaction on Neural Networks, 1999,10(5):1075-1089.
[7]田盛豐,黃厚寬.基于支持向量機的數據庫學習算法[J].計算機研究與發展,2000,37(1):17-22.
[8]陳潔謦.數據倉庫與決策支持系統[M].北京:科學出版社,2005.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:24
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
山東工業技術(2016年15期)2016-12-01 05:31:22
信息通信技術(2015年6期)2015-12-26 01:16:46
