樣本大小對非平衡數(shù)據(jù)分類的影響*
2010-11-27 01:46:30職為梅葉陽東
網(wǎng)絡(luò)安全與數(shù)據(jù)管理 2010年19期
職為梅,范 明,葉陽東
(鄭州大學(xué) 信息工程學(xué)院,河南 鄭州 450052)
分類是數(shù)據(jù)挖掘中的重要任務(wù)之一,在商業(yè)、金融、電訊、DNA分析、科學(xué)研究等諸多領(lǐng)域具有廣泛的應(yīng)用。統(tǒng)計學(xué)、機器學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)等領(lǐng)域的研究者提出了很多分類方法[1]。分類稀有類是分類中的一個重要問題。這個問題可以描述為從一個分布極不平衡的數(shù)據(jù)集中標(biāo)識出那些具有顯著意義卻很少發(fā)生的實例。分類稀有類在現(xiàn)實生活中的很多領(lǐng)域都有廣泛的應(yīng)用。例如,網(wǎng)絡(luò)侵入檢測、欺騙探測和偏差探測。在網(wǎng)絡(luò)入侵中,一個計算機通過猜測一個密碼或打開一個ftp數(shù)據(jù)連接進行遠程攻擊。雖然這種網(wǎng)絡(luò)行為不常見,但識別并分析出這種行為對于網(wǎng)絡(luò)安全很有必要。
普通分類問題中,各個類包含的數(shù)據(jù)分布比較平衡,稀有類分類問題中,數(shù)據(jù)的分布極不平衡。例如:將一批醫(yī)療數(shù)據(jù)分類為“癌癥患者”和“非癌癥患者”兩個類,其中 “癌癥患者”是小比例樣本(假設(shè)占總樣本的1%),稱其為目標(biāo)類,“非癌癥患者”為多數(shù)類樣本,稱為非目標(biāo)類,從大量數(shù)據(jù)中正確識別“癌癥患者”就是稀有類分類問題。由于在數(shù)據(jù)集中所占比率太小,使得稀有類分類問題比普通分類問題更具挑戰(zhàn)性。
研究表明,解決稀有類分類問題的方法總體上可以分為:基于數(shù)據(jù)集的、算法的[2],以及使用組合分類器方法,如 Bagging、Random Forest及 Rotation Forest等。
影響稀有類分類的因素有很多,本文針對其中的一個因素——樣本大小進行研究。實驗基于上述的若干組合分類器,在特定的類比率[3]下通過改變樣本大小,觀察樣本大小對稀有類分類的影響。
1 影響稀有類分類的因素
通常認為影響稀有類分類的因素是不平衡的類分布(Imbalanced class distribution),但是大量的研究和實驗證明,數(shù)據(jù)的不平衡性只是影響稀有類分類的一個因素,還有一些重要的因素影響稀有類分布,如小樣本規(guī)格(Small sample size)和分離性(Separability)[2]。下面簡單討論這些因素對稀有類分類的影響。
(1)不平衡的類分布:研究表明,類分布越是相對平衡的數(shù)據(jù)分類的性能越好。參考文獻[4]探討了訓(xùn)練集的類分布和判定樹分類性能的關(guān)系,但是不能確定多大的類分布比率使得分類性能下降。研究表明,在有些應(yīng)用中1:35時不能很好地建立分類器,而有的應(yīng)用中1:10時就很難建立了。
(2)樣本大小:給定特定的類分布比率(稀有類實例和普通類實例的比值),樣本大小在確定一個好的分類模型中起著非常重要的作用,要在有限的樣本中發(fā)現(xiàn)稀有類內(nèi)在的規(guī)律是不可能的。如對于一個特定的數(shù)據(jù)集,類分布比率為 1:20,其中稀有類實例為 5個,非稀有類實例為100個。改變該數(shù)據(jù)集的樣本大小,使得稀有類實例為50個,非稀有類實例為1 000個。結(jié)果是類分布同樣為1:20,但是前者沒有后者提供的稀有類信息量大,稀有類分類的性能沒有后者高。
(3)分離性:從普通類中區(qū)分出稀有類是稀有類分類的關(guān)鍵問題。假定每個類中存在高度可區(qū)分模式,則不需要很復(fù)雜的規(guī)則區(qū)分它們。但是如果在一些特征空間上不同類的模式有重疊就會極大降低被正確識別的稀有類實例數(shù)目。
根據(jù)以上分析可知,由于影響稀有類分類的因素多種多樣,使得稀有類分類問題更加復(fù)雜,分類的性能降低。本文在其他因素相同的前提下研究樣本大小對稀有類分類的影響。實驗證明在類分布相同的情況下,樣本越大稀有類分類的性能越好。
2 稀有類分類的評估標(biāo)準(zhǔn)
常用的分類算法的評估標(biāo)準(zhǔn)有:預(yù)測的準(zhǔn)確率、速度、強壯性、可規(guī)模性及可解釋性。通常使用分類器的總準(zhǔn)確率來評價普通類的分類效果。而對于稀有類分類問題,由于關(guān)注的焦點不同,僅用準(zhǔn)確率是不合適的。
由線性擬合可以得到Q(hkl),然后對所有的峰取平均可以得到t/G.圖5是鉻的P-t/G圖.從圖中可以看出,t/G在超過19 GPa后變得平坦,表明此時鉻由于屈服發(fā)生塑性形變,此時t/G的數(shù)值為0.005.
在稀有類分類問題中應(yīng)更關(guān)注稀少目標(biāo)類的正確分類率。在評價稀有類分類時,還應(yīng)該采用其他的評價標(biāo)準(zhǔn)。
這里假設(shè)只考慮包含兩個類的二元分類問題,設(shè)C類為目標(biāo)類,即稀有類,NC為非目標(biāo)類。根據(jù)分類器的預(yù)測類標(biāo)號和實際類標(biāo)號的分布情況存在如表1所示的混合矩陣(Confusion Matrix)。

表1 二元分類問題的混合矩陣
根據(jù)表1得到如下度量:

通常情況下使用召回率(recall)即 TPrate、精確率(precision)即PPvalue和F-度量來評估稀有類分類。F-度量(F-measure)由下式定義:F=;其中R為recall,P 為 precision。
3 組合分類器介紹
組合分類器是目前機器學(xué)習(xí)和模式識別方面研究的熱門領(lǐng)域之一,大量研究表明,在理論和實驗中,組合方法比單個分類模型有明顯的優(yōu)勢。組合方法由訓(xùn)練數(shù)據(jù)構(gòu)建一組基分類器,通過對每個基分類器的預(yù)測進行投票后分類。常用的組合分類器有:Bagging、Random Forest及 Rotation Forest。
3.1 Bagging介紹
Bagging[5]算法是一種投票方法,各個分類器的訓(xùn)練集由原始訓(xùn)練集利用可重復(fù)取樣 (bootstrap sampling)技術(shù)獲得,訓(xùn)練集的規(guī)模通常與原始訓(xùn)練集相當(dāng)。基本思想如下:給定s個樣本的集合 S,其過程如下:對于迭代t(t=1,2,...,T),訓(xùn)練集 St采用放回選樣,由原始樣本集S選取。由于使用放回選樣,S的某些樣本可能不在St中,而其他的可能出現(xiàn)多次。由每個訓(xùn)練集St學(xué)習(xí),得到一個分類算法Ct。為對一個未知的樣本X分類,每個分類算法Ct返回它的類預(yù)測,算作一票。Bagging的分類算法C*統(tǒng)計得票,并將得票最高的類賦予X[1]。
3.2 Random Forest介紹
隨機森林是一種組合分類器方法,構(gòu)成隨機森林的基本分類器是決策樹。基本思想如下:首先設(shè)定森林中有M棵樹,即有M個決策樹分類器,且全體訓(xùn)練數(shù)據(jù)的樣本總數(shù)為N。使用bagging方法,即通過從全體訓(xùn)練樣本中隨機地有放回地抽取N個樣本,形成單棵決策樹的訓(xùn)練集。重復(fù)M次這樣的抽樣過程分別得到M棵決策樹的學(xué)習(xí)樣本。單棵決策樹建造過程不進行剪枝,森林形成之后,對于一個新的樣本,每棵樹都得出相應(yīng)的分類結(jié)論,最后由所有樹通過簡單多數(shù)投票決定分類結(jié)果。
3.3 Rotation Forest介紹
Rotation Forest是一個基于判定樹的組合分類器,其基本思想如下:假設(shè)x=[x1,…,xn]為不含類標(biāo)號的數(shù)據(jù)集X的一個元組,則該數(shù)據(jù)集可以表示為N×n的矩陣;定義Y=[y1,…,yN]為X中元組對應(yīng)的類標(biāo)號集合,其中 yi∈{w1,…,wc};定義 D1,…,DL 為組合方法中的基分類器;F為屬性集合。Rotation Forest意在建立L個不同的準(zhǔn)確的分類器。特征集F被劃分成K個子集,在每個子集上運用PCA[6](principal component analysis)進行特征提取,合并所有的主成份重建一個新的特征集,原始數(shù)據(jù)被映射到新的特征空間。基于新的數(shù)據(jù)集訓(xùn)練得到Di分類器。L次不同的屬性集劃分得到L個不同的提取特征集,映射原始數(shù)據(jù)得到L個不同的數(shù)據(jù)集,分別訓(xùn)練得到L個分類器。對于未知樣本的實例X,組合L個分類器計算每個類的置信度,將其歸類于置信度最高 的 類 中[6,7]。
4 實驗結(jié)果及其分析
為了驗證稀有類分類算法受到樣本規(guī)格大小的影響,使用UCI機器學(xué)習(xí)庫[8]中的稀有類數(shù)據(jù)集sick作為實驗數(shù)據(jù)集。實驗環(huán)境選擇weka平臺,使用weka平臺提供的unsupervised resample數(shù)據(jù)預(yù)處理方法改變樣本的大小。實驗采用十折交叉驗證的方法統(tǒng)計分類的準(zhǔn)確率。
sick數(shù)據(jù)集的基本情況為:30個屬性(帶類標(biāo)號)、2個類(0,1),共有實例3 772條。其中 sick和negative類分別擁有實例數(shù)目3 541和231,分別占總樣本比例93.88%和6.12%。sick類可看作稀有類。
4.1 實驗結(jié)果
基于每個數(shù)據(jù)集,采用weka平臺提供的unsupervised resample數(shù)據(jù)預(yù)處理方法改變樣本規(guī)格的大小,使得實例數(shù)目分別是原始數(shù)據(jù)的倍到10倍不等。對這些處理后的數(shù)據(jù)集分別應(yīng)用組合分類器bagging、FandomForest和Rotation Forest算法進行分類。
表2是應(yīng)用Rotation Forest算法在處理后得到的sick數(shù)據(jù)集上關(guān)于sick類的實驗結(jié)果。sick數(shù)據(jù)集樣本被擴充了若干倍不等。
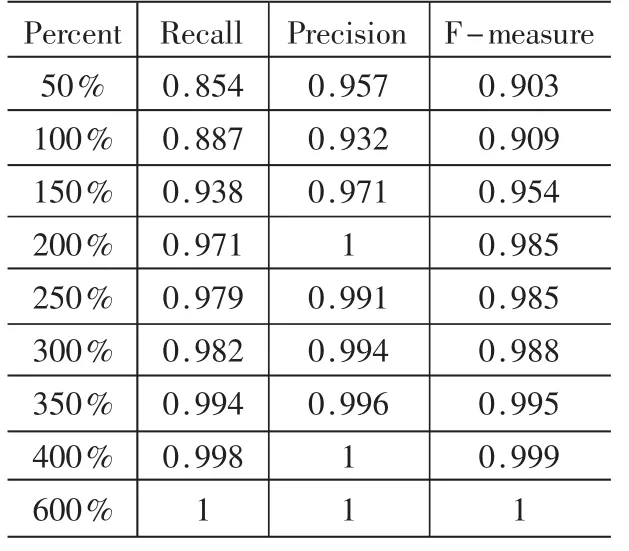
表2 Rotation Forest在sick上的實驗結(jié)果
表3是應(yīng)用Random Forest算法在處理后得到的sick數(shù)據(jù)集上關(guān)于sick類的實驗結(jié)果。sick數(shù)據(jù)集樣本被擴充了若干倍不等。

表3 Rotation Forest在sick上的實驗結(jié)果
表4是應(yīng)用Bagging算法在處理后得到的sick數(shù)據(jù)集上關(guān)于sick類的實驗結(jié)果。sick數(shù)據(jù)集被擴充了若干倍不等。Bagging算法在sick數(shù)據(jù)集上實驗時,樣本被擴充到10倍后,recall值仍沒有達到1,后來實驗又將樣本擴充至12倍,但由于內(nèi)存不夠?qū)嶒灲K止。
通過上述表格中的實驗結(jié)果,可以看到隨著樣本規(guī)格變大,衡量稀有類分類的這些參數(shù)也呈遞增。這也意味著隨著稀有類實例數(shù)目的增加,算法可以獲得更多關(guān)于稀有類的信息,從而有利于對稀有類實例的識別。
4.2 結(jié)果分析
通常認為影響稀有類分類的重要因素是數(shù)據(jù)分布的不平衡性,也就是說對于稀有類問題,普通的分類算法往往失效,但本文的實驗結(jié)果表明,數(shù)據(jù)分布的不平衡性影響稀有類分類的一個因素,在特定的類比率下,使樣本規(guī)格變大,普通的分類算法往往也可以取得很好的分類結(jié)果。
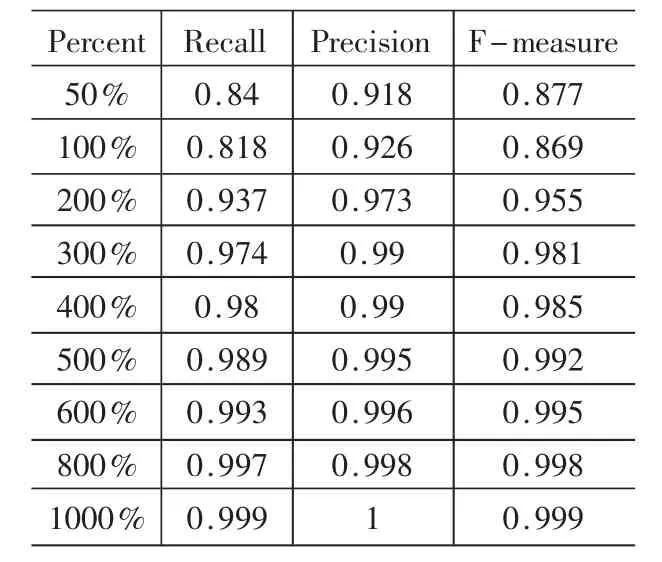
表4 Bagging算法在sick上的實驗結(jié)果
本文對稀有類分類問題進行了研究,分析了影響稀有類分類問題的因素,探討了稀有類分類的評估標(biāo)準(zhǔn)。針對影響稀有類分類的一個因素:樣本規(guī)格的大小進行研究,在同等類分布比率下,改變樣本規(guī)格的大小,在weka平臺下進行實驗,得到數(shù)據(jù)集中稀有類的recall、precision和F-measure值。實驗結(jié)果表明,在特定的類比率下,使樣本規(guī)格變大,普通的分類算法往往也可以取得很好的分類結(jié)果。同時也說明,數(shù)據(jù)分布的不平衡性只是影響稀有類分類的一個因素,即使數(shù)據(jù)分布極不平衡,通過增加樣本中稀有類實例的數(shù)目(類比率不變),也可以提高稀有類分類的各個指標(biāo)。
本文中的實驗基于多個組合分類器進行,每個組合分類器在每個數(shù)據(jù)集下的實驗結(jié)果都表明了樣本大小是影響稀有類分類正確的重要因素。在數(shù)據(jù)分布及不平衡下提供足夠的稀有類實例仍然可以獲得好的分類結(jié)果。
[1]HAN J,KANBER M,著,數(shù)據(jù)挖掘:概念與技術(shù)[M],范明,孟小峰,譯.北京:機械工業(yè)出版社,2001.
[2]Yanmin, Mobamed S.Kamel, Andrew K.C.Wong, Costsensitive boosting for classification of imbalanced data.Patter Recognition, 2007(10):3358-3378.
[3]VISA S,RALESCU A.Issues in mining imbalanced data sets-a review paper[C].In Proceedings of the Sixteen Midwest Artificial Intelligence and Cognitive Science Conference, 2005:67-73.
[4]WEISS G,PROVOST F.Learning when training data are costly:the effect of class distribution on tree induction[C].J.Aritif.Intell.Res, 2003(19):315-354.
[5]Breiman.Bagging predictiors[M].Machine Learning, 1996,24:123-140.
[6]KUNCHEVA L I,RODRIGUEZ J J, An experimental study on Rotation Forest ensembles[C].In:MCS 2007, Lecture Notes in Computer Science, vol.4472, Springer, Berlin,2007:459-468.
[7]RODRIGUEZ J J, KUNCHEVA L I, ALONSO C J.Rotation forest:a new classifierensemblemethod[C].IEEE Trans.Pattern Anal.Mach.Intell.2006,28:1619-1630.
[8]BLAKE C.MERZ C.UCIrepositoryofmachinelearning databases.http://www.ics.uci.edu/~mlearn/MLRepository.html.1998.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
