一種改進的Lucene語義相似度檢索算法*
2011-07-24 11:31:24黃承慧陸寄遠
中山大學學報(自然科學版)(中英文) 2011年2期
黃承慧,印 鑒,陸寄遠
(1. 中山大學信息科學與技術學院,廣東 廣州 510275;2. 廣東金融學院計算機科學與技術系,廣東 廣州510520)
隨著信息時代的到來,幾乎所有的紙質文件都將轉化為電子版進行保存。這種趨勢是不可逆轉的,對比紙質文件,電子文件更容易保存和使用,同時也更安全。所有這些要求促使我們尋找適當的方法,幫助用戶在日益廣闊的信息海洋中更加有效的瀏覽和管理這些電子文件。
Lucene是一個基于Java的用于文本檢索和搜索的開放源代碼工具包[1]。應當指出的是,Lucene不是一個具備完整功能的搜索應用程序,它只是一個具備索引和檢索功能的軟件庫,相對于其他檢索工具,Lucene有著更好的靈活性,人們可以將其應用于文獻檢索和搜索引擎等。
盡管Lucene已經被廣泛應用,相關的研究也層出不窮,然而大多數研究都是基于Lucene內部默認實現的詞頻分析檢索函數來考察檢索文本之間的相似性以進行檢索,很少有考慮詞項語義的Lucene檢索研究。此外,對于Lucene詞頻分析檢索函數的性能也很少被討論。因此,如果能對Lucene的檢索函數加以改進的話,則能夠有利于各種基于Lucene的應用,如業界廣泛使用的開源搜索引擎Nutch[2]。
本文基于上述觀察,提出了一種結合檢索詞項語義的檢索函數,該函數改進了傳統基于詞頻的方法對語義忽視所造成的檢索不夠精確的問題,同時也給出了一個初步判定文檔相似性的算法。通過這些改進,實驗結果表明,對比傳統的基于詞頻的方法,本文提出的方法能夠取得較好的檢索精確度和召回率。
1 相關工作
Lucene作為優秀的檢索軟件包,被廣泛的應用到檢索領域中[3-5]。但其用于處理檢索結果排序的核心技術是基于傳統詞頻分析技術的,因而在檢索精確度和召回率上存在先天的不足。針對這些問題,許多文獻都利用附加的外部本體來改進Lucene的檢索工作。
文獻[6]為了解決傳統搜索引擎所面臨的低效檢索精確度以及無法理解用戶查詢意圖的缺陷,在Lucene的基礎上提出了一個基于本體的語義搜索引擎框架。文獻[7]在開放目錄項目(Open Directory Project)提供的輕量級本體的基礎上,利用經典的TF-IDF詞頻分析技術,Lucene 用于計算檢索結果和相關概念的相似度,以此提高搜索結果的質量。文獻[8]則根據Wiki百科辭典的問答任務,分析Wiki百科辭典中的文章和查詢中的單詞詞頻,利用Lucene計算相似度,獲得了較好的結果。
在各種本體的使用上,Wordnet是使用最多的一個本體知識庫。文獻[9-10]都是利用Wordnet提供的同義詞對用戶的查詢進行詞項擴展,同時優化用戶提交查詢語句中的關鍵詞組,以此提高Lucene的檢索效果。文獻[11]利用潛語義索引技術和Wordnet作為本體,提出了一種獨立于Wordnet知識但依賴于潛語義索引知識的模型,利用該模型擴展Lucene查詢,取得了較好的效果。類似的,文獻[12]則集成了Lucene、WORDNET、潛語義分析以及和領域相關的受控詞匯等技術來改進Lucene檢索結果的有效性。
面對冗長的搜索結果列表,用戶通常只會選擇排在前面若干項的搜索結果而忽略后面的搜索列表。文獻[6]提出了一種高效的搜索方法來減少搜索結果的冗長列表。通過文中提出的基于本體的語義自適應搜索技術,本體中儲存了檢索詞項之間的關系,在用戶查詢被Lucene處理之前,該方法首先將用戶的查詢擴展為本體中的詞匯及其關系,并對擴展后的詞匯進行加權處理,每次用戶對檢索結果的點擊瀏覽都回引起權重的改變,從而逐步逼近用戶真實的查詢意圖,減少了不必要的檢索結果。
上述種種對Lucene檢索的擴展研究,或者考察利用本體對檢索詞項的詞頻進行分析,或者利用本體考察檢索詞項在本體中所處層次結構的相似性,均未考察檢索詞項本身的語義相似性。因而不能更好的理解用戶檢索所涉及的真正意圖。基于此,本文在Lucene內置的詞頻相似度函數的基礎上考察詞項的語義相似性,以此提高檢索的準確度和召回率。
2 Lucene相似度函數的改進
Lucene內部缺省實現的相似度檢索函數來源于經典的詞頻分析技術TF-IDF。該方法將文本看作是一個容納詞項的袋子,不考慮詞項出現的順序,也不考慮詞項的含義。文本特征向量由文本中出現的詞項在單個文本中出現的頻率以及該詞項在整個文本集中出現的頻率來表示。每一篇文本建模為文中出現的n個加權詞項組成的向量。該方法基于以下經驗觀察
1) 詞頻(Term Frequency):某個詞項在一個文本中出現的次數越多,它和文本的主題越相關;要注意在特定的語言環境下都有許多特定的詞不具備這種特性而應將其排除,如中文的“的”“地”、英文的“a”“an”。
2) 逆文本頻率(Inverse Document Frequency):某個詞項在文本集合的多篇文本中出現越多,該詞項的區分能力越差。例如:在一個包含1000篇文本的集合中,如果某個詞項A在100篇文本中都出現,而另一個詞項B只在10篇文本中出現,則詞項B比A具有更好的區分能力。
通過對文本集合中的每一個詞項都進行上述分析,得到每一篇文本中每一個詞項的TF-IDF值。之后再利用這些TF-IDF值為每一篇文本建立一個向量模型,通過計算向量間的余弦相似度或者Jaccard系數來表示文本之間的相似性,最終根據檢索文檔與用戶查詢之間的相似度值高低排序,將檢索結果以列表形式返回給用戶。
Lucene的評分機制采用了信息檢索中的空間向量模型和布爾模型相結合的方法,來最終決定一個給定的文檔和一個用戶的查詢到底從多大程度上是相關的。在查詢中,使用布爾模型中的布爾邏輯首先減少了需要進行評分的文檔。其次,Lucene在支持布爾模型和模糊查詢的基礎上,還加入了一些性能提高和優化。但是其核心還是基于向量模型。
Lucene采用的相似度計算函數如公式(1)所示
|D|×Boost(t,D))
(1)
上式中Q代表用戶查詢,D代表被檢索的文檔,兩者均被表示為詞頻向量。c(t,D)表示詞項t在文檔D中出現的頻率。df(t)是文檔集合中包含詞項t的文檔數目,|D|是文檔D的長度,|Q|是查詢Q的長度,|Q∩D|是同時出現在文檔D和查詢Q中的詞項的數目, Boost(t,D)表示與查詢詞項t和查詢D有關的加權因子。 qNorm(Q) 是一個規范化因子,在搜索的時候起作用,使得不同查詢間的分數可比較。其計算公式如下
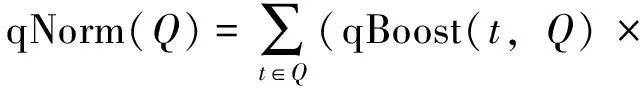
(2)
其中qBoost(t,Q)表示與查詢詞項t和查詢Q有關的加權因子。
文獻[13]對信息檢索的相似度函數做了深入研究,提出了一種更健壯、更好的基于公理化思想的檢索相似度函數。其計算公式如下
(3)
其中c(t,Q)表示詞項t在查詢Q中出現的頻率,df(t)是文檔集合中包含詞項t的文檔數目,c(t,D)表示詞項t在文檔D中出現的頻率,|D|表示文檔D中所有不同詞項的總數目,即文檔詞項向量的維度,avdl則表示整個文檔集合中所有文檔包含的平均詞項數目。
盡管上述檢索函數在實踐中證明有著較好的效果,然而他們都未能捕捉文本中的語義信息。隨著互聯網的發展,海量的文本數據要求我們能夠更為精確的捕捉和刻畫文本的含義而不僅僅是文本詞項出現的頻率。例如一篇關于銀行(bank)的文章和一篇關于河岸(bank)的文章,由于銀行和河岸兩者詞項的拼寫都是bank,基于詞頻的檢索方法就會將它們檢索返回給用戶。而一篇關于蘋果和一篇關于橘子的文章則因為兩者的詞項拼寫不同(apple和orange)在用戶檢索時只返回蘋果或者橘子的文章,而無法同時返回給用戶。
如果考察檢索詞項的語義信息,更為準確的捕捉用戶的意圖就能夠有效地解決上述不足。為此,本文針對公式(3)結合詞項語義相似度進行改進,改進后的檢索函數如公式(4)所示
(4)
其中Sim(t,Q)表示查詢Q中與詞項t相似的詞的頻率,Sim_df(t)表示文檔集合中包含與詞項t相似的文檔數目,Sim(t,D)表示文檔D中與詞項t相似的詞項的頻率。這三個涉及詞項相似度的因子要求我們給出詞項相似度的閾值,我們將在實驗部分對其進行闡述。
與公式(3)比較,本文擴展了經典的詞頻分析技術,使得檢索結果不僅包含了被檢索詞項出現的文檔,而且還包含了與被檢索詞項相似的文檔,從而更為準確的體現了檢索的含義。我們注意到,由于相似性的引入,使得原本只由檢索詞項出現的檢索結果擴大為與檢索詞項具有相似性的檢索結果,從而大大的增加了檢索返回的文檔數目。因此,我們有必要對返回的檢索結果進行適當的過濾處理,使得檢索結果既包含與用戶檢索需求相關的文檔,又不至于泛濫到包含所有與用戶檢索相關甚小的文檔。具體的算法描述如下
算法1:
1) 預處理文檔集合,刪除停用詞。
2) 初始化文檔向量。
3) 遍歷文檔集合,不考慮相似度計算df(t)。
4) 遍歷文檔集合根據詞項相似度計算方法尋找包含與檢索詞項相似度超過閾值μ(0<μ≤1)的詞匯的文檔。
5) 根據公式(4)計算文檔與用戶查詢的相關性,按相關性大小降序返回檢索列表PrimaryList。
6) 取檢索列表PrimaryList排名在df(t)/μ之前的文檔作為最終檢索結果ResultList。
算法1中用于計算詞項之間相似度的方法,采用了WordNet::Similarity工具包,該工具包實現了8種主流的詞與詞之間相似度計算的方法[14]。文獻[15]指出,基于信息內容度量的相似度方法優于其它方法。因此,本文采用了文獻[16]所實現的相似度算法作為算法1中計算詞項之間相似度的方法。相似度閾值μ在實驗部分有詳細描述。
3 實 驗
實驗數據采用業界廣泛采用的Ruters-21578數據集(Re1),Re1數據集采用了ModApte劃分,共9 603篇文檔,Ruters-22173數據集(Re2),Re2數據集采用了ModWiener劃分,共9 610篇文檔。在數據集Re1,Re2上建立Lucene支持的布爾查詢,對Lucene缺省的相似度函數、改進的公理化相似度函數以及本文提出的基于語義相似性的度量函數進行了對比研究,實驗結果如圖1所示。
本文提出的語義相似度檢索公式(4)中,需要根據詞項的相似度來計算查詢Q中與詞項t相似的詞的頻率、文檔集合中包含與詞項t相似的文檔數目以及文檔D中與詞項t相似的詞項的頻率。實驗采用了基于信息內容度量的相似度計算方法,在對文檔集合的常見詞匯進行計算后,我們設定詞項相似度閾值為0.57,即兩個詞項之間的相似度如果超過0.57,則認為這兩個詞項是相似的,從而對相應的詞頻進行計數。需要指出的是,計算兩個詞項相似度的WordNet::Similarity工具包是采用Perl語言編寫的,計算效率較低。因此,本文對實驗數據集中的詞項相似度預先進行了計算,以名稱為兩個詞項,值為詞項相似度的哈希表的形式保存在內存中,實際進行檢索時,只需從哈希表中查找已經計算好的相似度,從而減少算法的運算時間。
實驗的總體結果是比較滿意的,在Re1,Re2兩個數據集上,對比傳統的基于詞頻的相似度函數,本文提出的方法在檢索精度指標上均取得了10%以上的提升。這說明了本文在傳統詞頻分析的基礎上結合語義信息是可行的。
4 結 語
本文針對Lucene內置的文本檢索相似度函數進行了改進,將傳統的基于詞頻分析的相似度函數增加詞項的語義信息,并利用基于信息理論的詞項語義相似度量理論計算詞項之間的語義相似性,以此對文檔進行檢索。實驗結果表明,本文提出的方法是有效的,能夠進一步提高檢索的精度。
本文對文本檢索的語義信息進行了有益的嘗試,實驗的結果雖然對比傳統方法有一定的改進,但計算詞項之間相似度的時間開銷是需要我們進一步去優化和改進的。此外,單純的考察詞項之間的相似性丟失了文檔內在的結構性特征,以致檢索結果的提高有一定的局限性。我們預期在后續的研究里進一步考察文檔的結構信息,并結合現有的語義相似度分析技術,以便得到更好的檢索效果。
參考文獻:
[1]Lucene.Lucene Java 3.0.1[EB/OL].(2010-02-26)[2010-03-30]. http://lucene.apache.org/
[2]Nutch.Apache Nutch 1.0 release[EB/OL].(2009-03-23)[2010-03-30]. http://lucene.apache.org/nutch/
[3]SONG J, ZHU Y Q, LIU R D. Enhanced full text retrieval kit based on Lucene [J]. Computer Engineering and Applications, 2008, 44 (4): 172- 175.
[4]GUAN J H, GAN J F. Design and implementation of web search engine based on Lucene [J]. Computer Engineering and Design, 2007, 28(2):489-491.
[5]ZHOU D P, XIE K L. Lucene search engine [J]. Computer Engineering, 2007, 33(18):95-96.
[6]YANG C, YANG K C, YUAN H C. Improving the search process through ontology-based adaptive semantic search [J]. Metadata and Semantics for Digital Libraries, 2007, 25(2) : 234-248.
[7]ZHU D Y, DREHER H. Determining and satisfying search users real needs via socially constructed search concept classification [C]//IEEE DEST 2007, 2007.
[8]BUSCALDI D, ROSSO P. A bag-of-words based ranking method for the Wikipedia question answering task [C]//CLEF 2006, 2007: 550-553.
[9]ZHENG T, ZHENG C. Semantic retrieval system based on Lucene [J]. Computer Engineering, 2008, 34(16):92-94.
[10]JIANG Y F, WANG H, ZHANG Y H, et al. Design and implementation of semantic search engine based on Lucene[J]. Computer Engineering and Design, 2008, 29(20):5336-5341.
[11]DU L, JIN H D, DE VEL O, et al. A latent semantic indexing and WordNet based information retrieval model for digital forensics[C]// IEEE ISI 2008, 2008: 70-75.
[12]RAVISHANKAR D, THIRUNARAYAN K, IMMANENI T. A modular approach to document indexing and semantic search[C]// WTAS 2005, 2005: 165-170.
[13]FANG H, ZHAI C. An exploration of axiomatic approaches to information retrieval [C]//Proceedings of the 2005 ACM SIGIR Conference on Research and Development in Information Retrieval, 2005: 480-487.
[14]PEDERSEN T, PATWARDHAN S, MICHELIZZI J. Wordnet::similarity-measuring the relatedness of concepts[C]//Proc of AAAI-04, San Jose, California, USA, 2004: 1024-1025.
[15]BUDANITSKY A, HIRST G. Semantic distance in WordNet: an experimental, application-oriented evaluation of five measures [C]// Proc of the Workshop on WordNet and other Lexical Resources, 2001.
[16]LIN D. An information-theoretic definition of similarity[C]//Proceedings of the 15th International Conference on Machine Learning, Madison, WI, US, 1998.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
現代語文(2016年21期)2016-05-25 13:13:44
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
創業家(2015年5期)2015-02-27 07:53:25
