甲型流感病毒PB1-PA蛋白作用位點(diǎn)的發(fā)現(xiàn)與分析*
2011-07-24 11:25:58林強(qiáng)乾趙艷超張淑波陳維田
關(guān)鍵詞:區(qū)域
何 淼,林強(qiáng)乾,趙艷超,張淑波,陳維田
(1. 中山大學(xué)生命科學(xué)學(xué)院,廣東 廣州 510275;2. 香港理工大學(xué)屋宇設(shè)備工程系,香港 九龍)
甲型流感病毒包含8個(gè)獨(dú)一無(wú)二的單鏈RNA片段,RNA松散地包埋在許多核蛋白(Nucleoprotein,NP)分子中,其中,包含3個(gè)病毒RNA聚合酶(PB1、PB2及PA)的復(fù)合體位于病毒顆粒的內(nèi)核[1]。1990年,Ayae等[2]用梯度氯化銫離心法從甲型流感病毒中分離出RNA聚合酶,隨后分離出了PB1蛋白、PB2蛋白和PA蛋白。
PB1蛋白,又稱為聚合酶堿性蛋白1(Polymerase Basic Protein 1),由RNA片段2編碼。它在RNA聚合酶復(fù)合體中的作用是負(fù)責(zé)病毒RNA分子的延伸,同時(shí)也在模版RNA合成的延伸過(guò)程中起作用。PB1蛋白酶定位在感染細(xì)胞的細(xì)胞核中[1]。研究表明,PB1蛋白的第506-659位氨基酸的保守性不顯著,但是,仍分布有許多零星的保守片斷,這些保守片段是否代表蛋白表面氨基酸或相互作用位點(diǎn)仍需檢驗(yàn)。
PA蛋白,又稱為聚合酶酸性蛋白(Polymerase Acid Protein),由RNA片段3編碼。是RNA聚合酶復(fù)合體中的最后一個(gè)蛋白,它對(duì)病毒RNA聚合過(guò)程的作用未知。有證據(jù)表明,它可能起著蛋白激酶或螺旋解構(gòu)酶的作用。PA聚合酶也定位在感染細(xì)胞的細(xì)胞核中[1]。Amelia等通過(guò)重組的猿40病毒,用蛋白片斷缺失法分析了PA蛋白的區(qū)域,研究顯示,區(qū)域I(124-139位氨基酸)與區(qū)域II(186-247位氨基酸)具有重要功能;兩個(gè)核定位信號(hào)均存在于區(qū)域I與區(qū)域II中,結(jié)論表明,PA蛋白包含一個(gè)核定位信號(hào)區(qū)域,是病毒執(zhí)行繁殖復(fù)制的重要區(qū)域[3]。
大部分蛋白質(zhì)需要相互作用才能發(fā)揮出其生物學(xué)作用。通過(guò)構(gòu)成復(fù)合體才能發(fā)揮生物學(xué)作用的蛋白質(zhì),在相互作用面上的結(jié)構(gòu)域或序列,具有比一般功能的結(jié)構(gòu)域更高的保守度。Caffrey發(fā)現(xiàn)相互作用表面氨基酸比其它暴露在表面的氨基酸具有更高的保守度[4];Minsteris和 Wang發(fā)現(xiàn)相互作用的表面氨基酸具有與蛋白伴侶共進(jìn)化的屬性[5]。
研究表明諸如NLS序列、聚合酶功能區(qū)序列、PB2蛋白與PA蛋白結(jié)合區(qū)序列完全沒(méi)有發(fā)生重疊的現(xiàn)象[6]。PB2蛋白需要與PB1蛋白結(jié)合才能發(fā)揮出轉(zhuǎn)錄酶的功能。PB1蛋白的N端78個(gè)氨基酸和PA蛋白C端的3/4個(gè)蛋白片斷結(jié)合[7];PB1蛋白的第506-659位氨基酸與PB2蛋白的124個(gè)氨基酸相互作用[8]。研究顯示,PB1、PB2與PA蛋白在病毒體外亦能自動(dòng)形成復(fù)合體[2]。
本文基于共進(jìn)化理論,從PB1蛋白的N端結(jié)構(gòu)域與PA蛋白的C端結(jié)構(gòu)域入手,研究了甲型流感病毒的PB1蛋白與PA蛋白間具有潛在共進(jìn)化關(guān)系的肽段,創(chuàng)新性推測(cè)出復(fù)合體中的相互作用位點(diǎn),并在三維結(jié)構(gòu)上標(biāo)記出相互作用位點(diǎn)。
1 數(shù)據(jù)和方法
1.1 數(shù)據(jù)來(lái)源
甲型流感病毒序列全部來(lái)自于NCBI的流感病毒專門數(shù)據(jù)庫(kù) Influenza Virus Resource(http://www.ncbi.nlm.nih.gov/genomes/FLU/FLU.html)。本文提取了1428株病毒的PB1蛋白序列和1580株病毒的PA蛋白序列。序列下載后,以FASTA格式保存。
PB1與PA的結(jié)構(gòu)信息來(lái)自于Protein Data Base(PDB)。在PDB上檢索文件名為2ZNL.pdb的蛋白結(jié)構(gòu)數(shù)據(jù),作為蛋白結(jié)構(gòu)信息的來(lái)源。
1.2 計(jì)算方法
本文自主設(shè)計(jì)了CD search(Conserved Domain Search)軟件,主要用于“保守九聚氨基酸肽片段(Conserved 9-mer Peptide,簡(jiǎn)記為C9MP)”的篩選,以C9MP為單位的序列比對(duì)和共進(jìn)化參數(shù)計(jì)算結(jié)果為篩選依據(jù);所謂C9MP是指九個(gè)在一級(jí)結(jié)構(gòu)上連續(xù)排列的氨基酸所構(gòu)成的短肽片段。利用軟件進(jìn)行序列比對(duì),篩選出所有序列中90%以上完全匹配的9個(gè)連續(xù)氨基酸,即保守九聚氨基酸肽片段;計(jì)算一個(gè)蛋白所有保守片段與另一個(gè)蛋白的保守片段相關(guān)的η、Z、na、nb、NA、NB、MA、MB等8個(gè)共進(jìn)化參數(shù)。
利用CLUSTALX2.0進(jìn)行第1次序列比對(duì),選擇BLOSUM矩陣,輸出得到PB1.fasta和PA.fasta。獲得的.fasta文件中序列總數(shù)為M值,其中,MA值表示PB1.fasta中包含的序列總數(shù),MB表示PA.fasta中包含的序列總數(shù)。
對(duì)于每一個(gè)保守多肽片段來(lái)說(shuō),相同的片段占了90%以上,不相同的片段總數(shù)N值被精確統(tǒng)計(jì)出來(lái)。在PB1蛋白中不相同的片段數(shù)為NA;在PA蛋白中,對(duì)應(yīng)的值為NB。
提取兩個(gè)病毒蛋白.fasta文件中的GI號(hào)及病毒名,構(gòu)建兩個(gè)僅包含GI號(hào)及病毒名的數(shù)據(jù)文件PB1_gz.txt與PA_gz.txt。提取PB1.fasta與PA.fasta所包含的共有病毒,統(tǒng)計(jì)共有的病毒株數(shù),得到η值。na(0-8)值代表PB1蛋白的氨基酸位置0-8在η條件下的變異數(shù)目,nb(0-8)值代表PA蛋白的氨基酸位置0-8在η條件下的變異數(shù)目。假設(shè)PB1蛋白含有X個(gè)C9MP,在PA蛋白含有Y個(gè)C9MP,則總共有Z=X×Y個(gè)潛在相互作用位點(diǎn)。
假設(shè)在甲型流感病毒毒株中,我們考慮PB1蛋白的第一個(gè)顯著保守片段(記為A1)和PA蛋白的第一個(gè)顯著保守片段(記為B1),A1片段在MA中有NA個(gè)突變序列,B1片段在MB中有NB個(gè)突變序列,那么,在沒(méi)有進(jìn)化壓力的情況下,A1和B1在同一個(gè)病毒株中出現(xiàn)變異的概率是:
如果Z值在η值范圍內(nèi)。在η范圍能夠找到包含兩個(gè)變異C9MP的方法數(shù)為:
假設(shè)在η值范圍內(nèi),A1片段的變異數(shù)目是na,B1片段的變異數(shù)是nb,那么在η范圍(但不在Z值內(nèi))變異數(shù)目為:
由于分布在所有甲型流感病毒毒株變異方式的數(shù)目受到η以外變異數(shù)目的約束,定義wA與wB作為在η以外PB1蛋白和PA蛋白的變異方式數(shù)目:
計(jì)算在Z中可能發(fā)生重疊的變異方法總數(shù),需要將na和nb的所有可能值累加求和:
最后,P值表示為下式:
其中,W為沒(méi)有任何限制條件下,篩選自所有PB1蛋白和PA蛋白變異的總方式數(shù)。
這里P值被Wang等定義為共進(jìn)化值,即文中計(jì)算的Pcov值[9]。
共進(jìn)化相關(guān)變量具體計(jì)算和圖形輸出均利用Matlab7.0完成。
DSSP是用于計(jì)算多肽在模擬過(guò)程中二級(jí)結(jié)構(gòu)變化的專用軟件。將2znl.pdb輸入DSSP軟件,分析蛋白質(zhì)氨基酸的溶劑可及性(ACC),程序自動(dòng)列表會(huì)產(chǎn)生ACC數(shù)據(jù)。文中分別計(jì)算了PB1蛋白與PA蛋白的ACC值。根據(jù)Rost的工作,暴露于水環(huán)境中的表面積大于其整體表面積25%的氨基酸為表面氨基酸。當(dāng)兩個(gè)表面氨基酸相互作用,其親水表面積減少超過(guò)1A2時(shí),定義為相互作用表面氨基酸[10]。文中分別計(jì)算了氨基酸在形成復(fù)合體前單體狀態(tài)下的ACC值和形成復(fù)合體后的ACC值。
本文采用ZDOCK2.3軟件對(duì)蛋白質(zhì)相互作用的三維結(jié)構(gòu)進(jìn)行了模擬。
2 結(jié)果與分析
2.1 CD Search結(jié)果與分析
根據(jù)CD search分析的結(jié)果,PB1蛋白具有447個(gè)C9MP,對(duì)位置重疊片段進(jìn)行整合,得到26個(gè)域。這里的“域”指的是由數(shù)個(gè)C9MP連結(jié)在一起,按照前后順序構(gòu)成的一個(gè)更大片段。如386-396的KKIEKIRPLLI,實(shí)際上是由3個(gè)C9MP,386-394(KKIEKIRPL)與387-395(KKIEKIRPLL)與388-396(IEKIRPLLI),重疊構(gòu)成。PA蛋白具有373個(gè)C9MP,對(duì)重疊片段整合,可以得到29個(gè)域。
2.2 共進(jìn)化數(shù)值計(jì)算與分析
本文計(jì)算了PB1蛋白的447個(gè)C9MP與PA蛋白的373個(gè)C9MP所有可能的相互作用,即447×373個(gè)相互作用,包含了166 731個(gè)數(shù)值點(diǎn)。利用Matlab的可視化工具輸出圖形(見圖1),圖中的小色塊單位是-log(Pcov)值。為了更直觀找出相互作用關(guān)系,忽略漸變的可能性,直接將-log(Pcov)大于5(即Pcov>10-5)的區(qū)域用顯著的紅色標(biāo)注出來(lái),Wang 等[9]認(rèn)為這些紅色區(qū)域是“毫無(wú)疑問(wèn)地”在共進(jìn)化上具有高度關(guān)聯(lián)的區(qū)域。藍(lán)色區(qū)域意味著低的共進(jìn)化值,藍(lán)色區(qū)域在復(fù)合體結(jié)構(gòu)和功能的穩(wěn)定性方面可以被認(rèn)為做出較少貢獻(xiàn)。

圖1 在假定極端保守情況下PB1-PA完整的C9MP共進(jìn)化關(guān)系(圖中縱軸表示PA蛋白的C9MP,橫軸表示PB1蛋白的C9MP)
2.3 PB1蛋白與PA蛋白相互作用位點(diǎn)預(yù)測(cè)與分析
Carol等發(fā)現(xiàn)PB1蛋白、PB2蛋白與PA蛋白都能在宿主受感染細(xì)胞中大量表達(dá)。這三個(gè)蛋白在宿主細(xì)胞中相互作用形成一個(gè)核酸酶復(fù)合體,其中,PB1蛋白可以與PB2蛋白相互作用而不需要依賴于其它因素;PA蛋白可能需要經(jīng)過(guò)修飾后才能夠與PB1蛋白相互作用[11]。Yasushi研究小組找到了PB1蛋白與PA蛋白的相互作用域,分別位于PB1蛋白的1-140處與PA蛋白的201-716[12]。
依據(jù)CD Search結(jié)果,對(duì)于PB1-PA蛋白復(fù)合體來(lái)說(shuō),PB1蛋白的氨基酸位點(diǎn)1-140包含87個(gè)C9MP,PA蛋白的氨基酸位點(diǎn)201-716包含245個(gè)C9MP。
圖1表明,PB1-PA的結(jié)構(gòu)域有許多在進(jìn)化上具有相關(guān)聯(lián)的域,其中,不少具有極高的Pcov值。但是,由于目前PDB數(shù)據(jù)庫(kù)中只有一個(gè)PB1蛋白與PA蛋白相互作用的結(jié)構(gòu)圖,為了便于驗(yàn)證與對(duì)照,本文選擇了PDB數(shù)據(jù)庫(kù)中的PB1MP1,探討其與PA蛋白的相互作用,探究相互作用位點(diǎn),該方法可以推廣至其它區(qū)域相互作用位點(diǎn)的預(yù)測(cè)分析。

表1 PB1MP1的基本信息
計(jì)算發(fā)現(xiàn)PB1MP1與PA蛋白上的C9MP僅在1、10、18-22、27-33、40-46、58-59、144-145、151-154、220-221、231-234位置上(見表2)同時(shí)具有PB1MP1與PA蛋白殘基201-716區(qū)域內(nèi)最低的共進(jìn)化值。
通過(guò)蛋白質(zhì)的三維結(jié)構(gòu)模擬,可以顯著地發(fā)現(xiàn)PA蛋白上與PB1MP1可能存在共進(jìn)化關(guān)系的各個(gè)C9MP與PB1MP1在結(jié)構(gòu)上距離較遠(yuǎn)。但是,在這12個(gè)C9MP中,惟一例外的是編號(hào)10的C9MP,模擬顯示其與PB1MP1具有顯著的接觸。為了便于下文引用,參照Wang的命名規(guī)則,即依據(jù)氨基酸片段的首尾字母和起始位置編碼,命名10號(hào)C9MP為PAQG670。
對(duì)PAQG670片段變異統(tǒng)計(jì)分析發(fā)現(xiàn)(見表3),同為接觸面的氨基酸,Q670 比R673更為保守。統(tǒng)計(jì)發(fā)現(xiàn)R673位置上共有13個(gè)R變異為K。由于相互作用位點(diǎn)在復(fù)合體中的功能十分重要,檢索分析表明,PAQG670與PB1MP1的變異實(shí)際上沒(méi)有存在于同一個(gè)病毒中,與R673對(duì)位的PB1MP1的氨基酸沒(méi)有發(fā)生協(xié)同突變,因此,可以排除R673作為潛在相互作用位點(diǎn)的可能。在對(duì)這些變異檢索過(guò)程沒(méi)有發(fā)現(xiàn)Q670突變。在此,定義共同序列為剔除變異后的剩余序列。序列比對(duì)發(fā)現(xiàn),Q670在接近1580個(gè)病毒株中沒(méi)有發(fā)生突變,因此,Q670屬于高度保守位點(diǎn),也是可能潛在的相互作用位點(diǎn)。
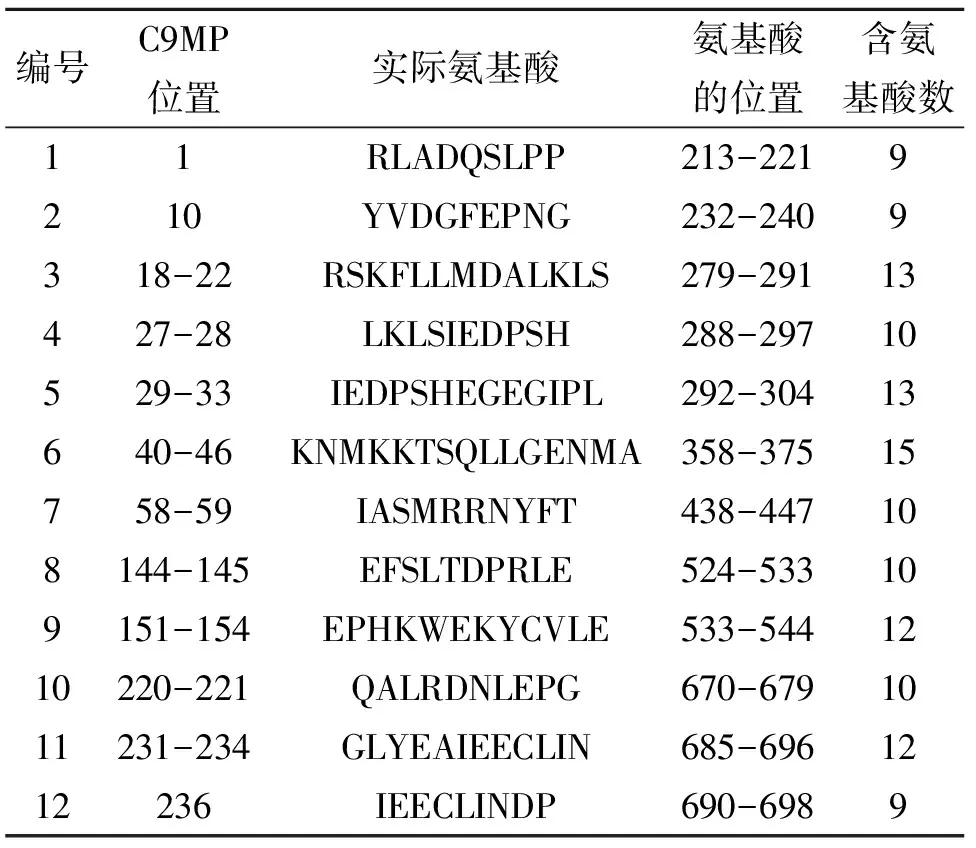
表2 PA蛋白與PB1蛋白可能存在共進(jìn)化關(guān)系的C9MP位置
表3中的黑斜體字母表明某個(gè)位置氨基酸的變異情況。在我們所關(guān)心的氨基酸Q670及R673中,Q670的保守度要遠(yuǎn)遠(yuǎn)高于R673的保守度。E677,P687,G679等位點(diǎn)高度保守,如果兩者存在相互作用,需要確認(rèn)與Q670對(duì)位的PB1氨基酸具有穩(wěn)定性的特征。與Q670對(duì)位的PB1氨基酸分別是F9、V12、P13和A14。在這4個(gè)氨基酸中,A14由于其在所有病毒株的PB1蛋白變異率高于10%,因而被放棄。在表4中,黑體字母同樣代表該位置氨基酸的變異情況,計(jì)算表明,除了6、8位置的氨基酸外,其它氨基酸發(fā)生變異的程度都較低;可以看出,F(xiàn)9、V12和P13均具有很高的保守度,表明這些位點(diǎn)均有參與相互作用的可能。
利用三維模擬的方式,本文重構(gòu)了PAQG670和PB1MP1的相互接觸情況(見圖2)。局部放大了關(guān)鍵相互作用位點(diǎn)(圖3)。圖中的網(wǎng)格表示了整個(gè)蛋白的空間范圍,Q670上下方的鏤空區(qū)是氨基酸填充區(qū);從圖3中可以看出,Q670與PB1MP1的F9、V12和P13在復(fù)合體中是緊密結(jié)合的,此處可能是PAQG670與PB1MP1的相互作用位點(diǎn)之一。
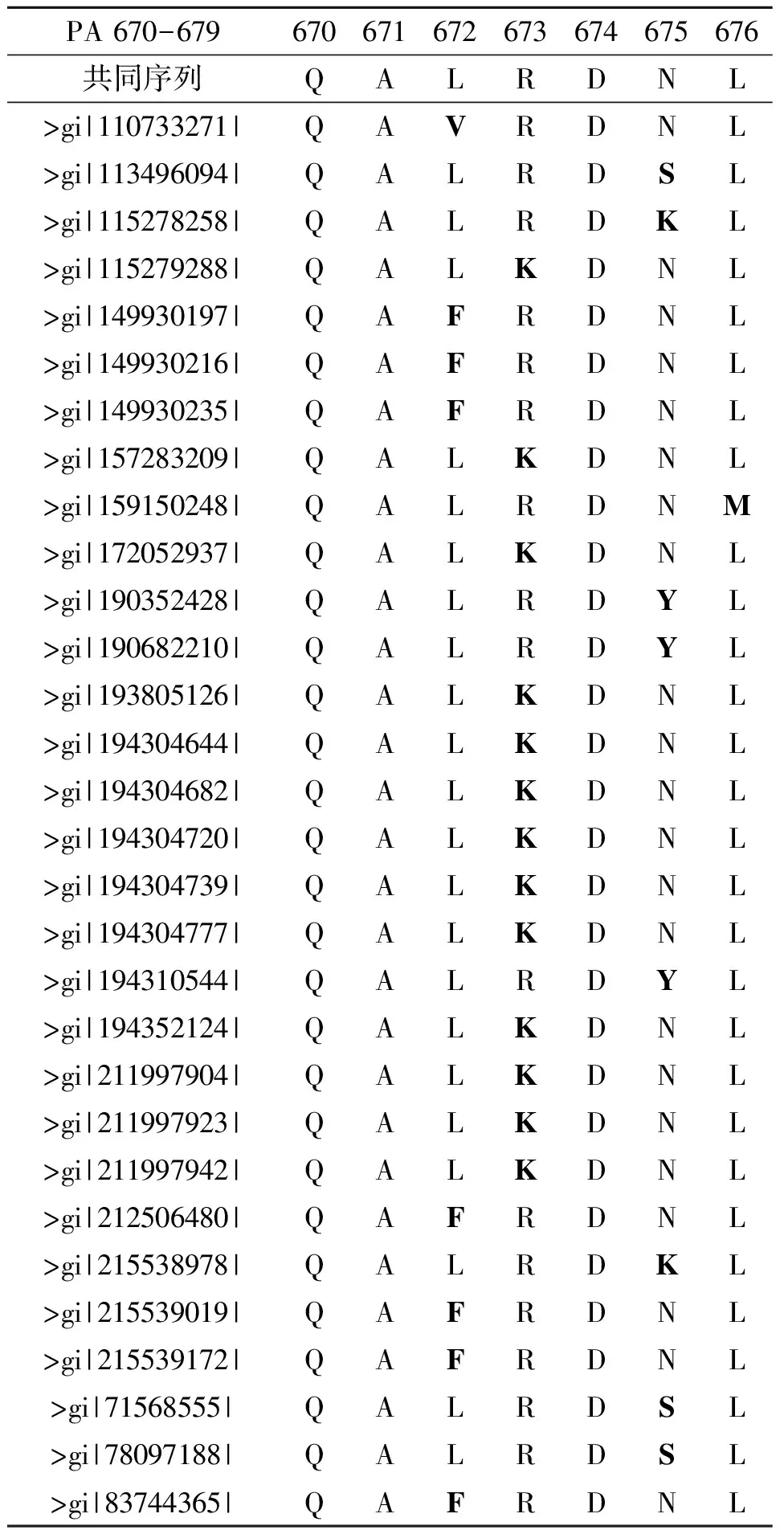
表3 PAQG670變異情況
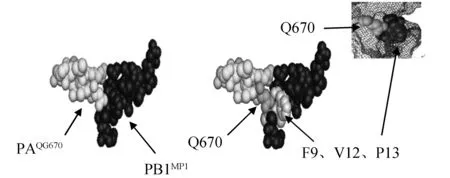
圖2 PAQG670的Q670與PB1MP1的F9、V12和P13相互作用三維模擬效果
表4 PB1MP1變異情況
Table 4 The mutations of PB1MP1
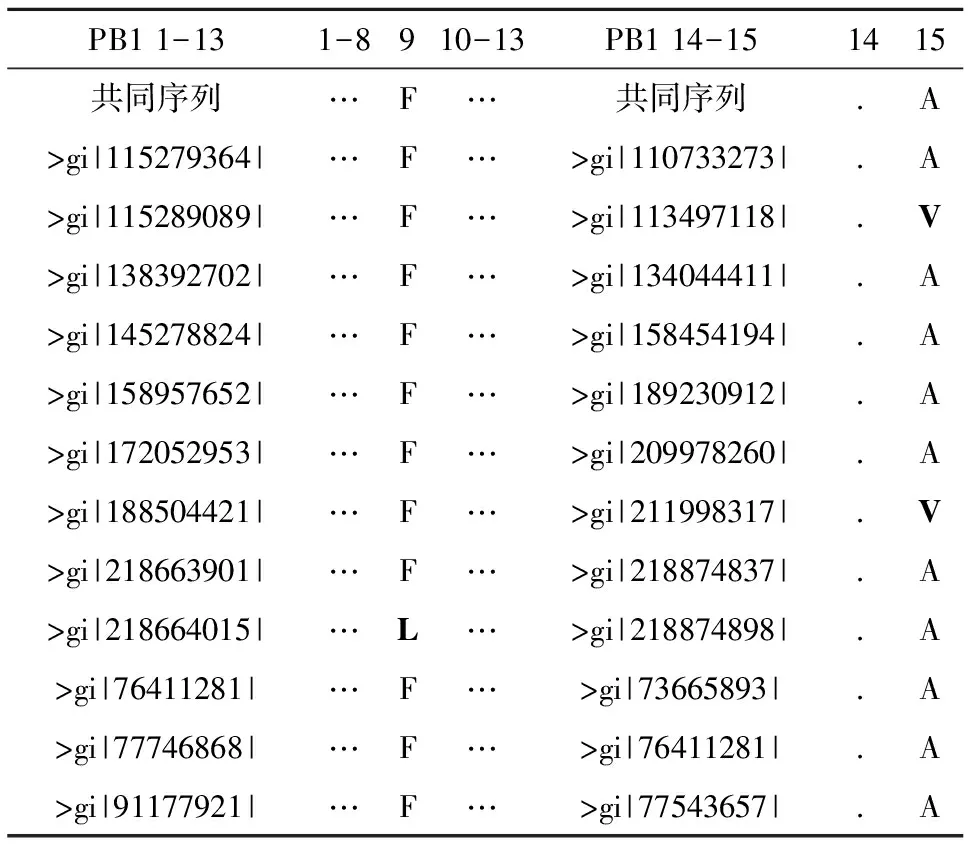
PB1 1-131-8910-13PB1 14-151415共同序列…F…共同序列.A>gi|115279364| …F…>gi|110733273|.A>gi|115289089| …F…>gi|113497118| .V>gi|138392702| …F…>gi|134044411| .A>gi|145278824| …F…>gi|158454194| .A>gi|158957652| …F…>gi|189230912| .A>gi|172052953| …F…>gi|209978260| .A>gi|188504421| …F…>gi|211998317| .V>gi|218663901| …F…>gi|218874837| .A>gi|218664015| …L…>gi|218874898| .A>gi|76411281| …F…>gi|73665893| .A>gi|77746868| …F…>gi|76411281| .A>gi|91177921| …F…>gi|77543657| .A
利用DSSP程序,如果將PA蛋白與PB1蛋白分別獨(dú)立計(jì)算ACC值,PA蛋白的Q670,PB1蛋白的F9、V12、P13的ACC值分別為82、117、43和103 A2;如果考慮將PA蛋白與PB1蛋白結(jié)合形成復(fù)合體后,計(jì)算ACC值,則PA蛋白的Q670、PB1蛋白的F9、V12、P13的ACC值分別下降至13、56、14和79 A2。計(jì)算結(jié)果見表5。

表5 PAQG670的Q670與PB1MP1復(fù)合體形成前后參數(shù)變化
在成為復(fù)合體前,上述4個(gè)氨基酸暴露在水環(huán)境中的面積與整體面積比(ARR)是26.8%、36.3%、16.7%和43.1%;成為復(fù)合體后,上述4個(gè)氨基酸的ARR值下降到4.2%、17.4%、5.4%和33.1%。
當(dāng)PB1蛋白與PA蛋白尚未相互作用時(shí),依據(jù)生物學(xué)定義,PA的Q670、PB1的F9和P13都是表面氨基酸。特別PB1的P13(ARRmax =43.1%)高度暴露于水環(huán)境中。當(dāng)PB1蛋白與PA蛋白相互作用時(shí),PA的Q670、PB1的F9和P13暴露在水環(huán)境中的表面積均迅速下降,降幅(比例)分別達(dá)到69 A2(22.6%)、61 A2(18.9%)和136 A2(10.0%),均顯著超過(guò)了Rost(1994)[10]給出的臨界值1A2;因此,它們均可成為相互作用的表面氨基酸。
3 討 論
本文的主要結(jié)論是PAQG670的Q670與PB1的F9、P13構(gòu)成了一個(gè)潛在的相互作用域,該相互作用域由這3個(gè)氨基酸構(gòu)成。
研究表明,越是功能重要的區(qū)域,如果出現(xiàn)變異,蛋白(或蛋白復(fù)合體)失活的可能性越高[13]。類似核酸酶復(fù)合體這種關(guān)乎病毒復(fù)制、繁殖的精密蛋白復(fù)合體,出現(xiàn)變異的大部分結(jié)果是導(dǎo)致病毒無(wú)法繁殖子代病毒[14]。相互作用表面氨基酸的保守性要明顯高于其它表面氨基酸[15]。
BLAST和C9MP搜索結(jié)果顯示,甲型流感病毒的PB1蛋白與PA蛋白比HIV病毒的RT蛋白和IN蛋白保守許多[9]。本文的研究過(guò)程與Wang et al的顯著不同,主要差異在于本文研究的PAQG670與PB1MP1的變異沒(méi)有同時(shí)存在于同一個(gè)病毒中。
本研究也初步發(fā)現(xiàn),共進(jìn)化理論不僅可用于尋找相互作用位點(diǎn),而且,也有可能用于尋找存在共進(jìn)化可能性的區(qū)域。本研究結(jié)果對(duì)于臨床治療的靶標(biāo)發(fā)現(xiàn),疫苗和藥物的研發(fā)具有重要指導(dǎo)意義。
參考文獻(xiàn):
[1]WEBSTER R G, BEAN W J, GORMAN O T, et al. Evolution and ecology of influenza A viruses[J]. Microbiol Rev,1992,56(1):152-179.
[2]HONDA A, MUKAIGAWA J, YOKOIYAMA A, et al. Purification and molecular structure of RNA polymerase from influenza virus A/PR8[J]. J Biochem,1990,107(4):624-628.
[3]NIETO A, DE LA LUNA S, BARCENA J, et al. Complex structure of the nuclear translocation signal of influenza virus polymerase PA subunit[J]. J Gen Virol,1994,75 ( Pt 1):29-36.
[4]CAFFREY D R, SOMAROO S, HUGHES J D, et al. Are protein-protein interfaces more conserved in sequence than the rest of the protein surface?[J]. Protein Sci,2004,13(1):190-202.
[5]MINTSERIS J, WENG Z. Structure, function, and evolution of transient and obligate protein-protein interactions[J]. Proc Natl Acad Sci U S A,2005,102(31):10930-10935.
[6]GONZALEZ S, ZURCHER T, ORTIN J. Identification of two separate domains in the influenza virus PB1 protein involved in the interaction with the PB2 and PA subunits: a model for the viral RNA polymerase structure[J]. Nucleic Acids Research,1996,24(22):4456.
[7]ZURCHER T, de la LUNA S, SANZ-EZQUERRO J J, et al. Mutational analysis of the influenza virus A/Victoria/3/75 PA protein: studies of interaction with PB1 protein and identification of a dominant negative mutant[J]. J Gen Virol,1996,77 ( Pt 8):1745-1749.
[8]PERALES B, de la LUNA S, PALACIOS I, et al. Mutational analysis identifies functional domains in the influenza A virus PB2 polymerase subunit[J]. J Virol,1996,70(3):1678-1686.
[9]WANG Y E, DELISI C. Inferring protein-protein interactions in viral proteins by co-evolution of conserved side chains[J]. Genome Inform,2006,17(1):23-35.
[10]ROST B, SANDEr C. Conservation and prediction of solvent accessibility in protein families[J]. Proteins,1994,20(3):216-226.
[11]ST A C, SMITH G E, SUMMERS M D, et al. Two of the three influenza viral polymerase proteins expressed by using baculovirus vectors form a complex in insect cells[J]. J Virol,1987,61(2):361-365.
[12]OHTSU Y, HONDA Y, SAKATA Y, et al. Fine mapping of the subunit binding sites of influenza virus RNA polymerase[J]. Microbiol Immunol,2002,46(3):167-175.
[13]DARLIX J L, LAPADAT-TAPOLSKY M, de ROCQUIGNY H, et al. First glimpses at structure-function relationships of the nucleocapsid protein of retroviruses[J]. J Mol Biol,1995,254(4):523-537.
[14]STEINHAUER D A, HOLLAND J J. Rapid evolution of RNA viruses[J]. Annu Rev Microbiol,1987,41:409-433.
[15]OFRAN Y, ROST B. Predicted protein-protein interaction sites from local sequence information[J]. FEBS Lett,2003,544(1/3):236-239.
猜你喜歡
發(fā)明與創(chuàng)新·小學(xué)生(2021年3期)2021-03-25 11:48:49
科學(xué)(2020年5期)2020-11-26 08:19:22
軟件(2020年3期)2020-04-20 01:45:18
商周刊(2018年15期)2018-07-27 01:41:20
敦煌學(xué)輯刊(2018年1期)2018-07-09 05:46:42
北京教育·普教版(2017年1期)2017-02-05 13:26:23
新疆農(nóng)墾科技(2016年2期)2016-08-21 13:50:16
中國(guó)科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
新疆財(cái)經(jīng)大學(xué)學(xué)報(bào)(2015年3期)2015-12-10 03:49:15
