基于蟻群優化的超聲波電動機系統動態模糊辨識建模
2011-11-20 08:34:56史敬灼
微特電機 2011年10期
呂 琳,史敬灼
(河南科技大學,河南洛陽471003)
0 引 言
建立超聲波電動機系統模型可采用不同方法,從適合于控制應用的角度出發,控制建模方法研究日益受到重視。通常,為便于在線實現并盡量減小在線計算量,控制模型應相對簡單并能夠表征超聲波電動機系統控制非線性的主要方面。由于理論建模的局限性,控制建模通常以基于實驗數據的辨識方法為主[1-2]。根據模型辨識方法的不同,模型的形式可以是傳遞函數、差分方程、神經網絡等。
近年來,基于模糊邏輯理論的模糊建模方法逐漸興起,為非線性復雜系統建模提供了另一有效途徑。模糊建模方法在電機領域的應用還不多,更多的是采用模糊方法實現轉速或位置控制。
本文研究超聲波電動機系統動態模型的模糊建模方法。論述了超聲波電動機系統的模糊建模方法與過程,給出了采用蟻群優化確定模糊聚類隸屬函數的方法,并用最小二乘法辨識模糊規則結論部分的待定參數,建立了能夠表征超聲波電動機驅動電壓幅值、頻率與其轉速之間非線性動態關系的二輸入單輸出Takagi-Sugeno(以下簡稱T-S)模糊模型。
1 建模所需數據的實驗測取
實驗系統框圖如圖1所示。實驗用電機為Shinsei USR60型兩相行波超聲波電動機,H橋相移PWM驅動電路。控制部分采用DSP為主控芯片,用于實現控制算法,包含分別用于控制兩相驅動電壓幅值的A、B相電壓閉環控制器,以及通過調節驅動頻率實現轉速控制的轉速閉環控制器。圖中,Nref、Uref分別為轉速、驅動電壓幅值的給定值。設定Nref測取轉速階躍響應,其間調節Uref以改變電機驅動電壓的幅值大小;隨著驅動電壓幅值的變化,在轉速閉環控制作用下,頻率必然改變以維持電機轉速為Nref;同時記錄Uref、頻率及轉速的動態變化過程,得到一組數據。改變Uref調節方式、Nref數值,重復上述過程,測得多組數據用于建模。

圖1 轉速控制實驗系統結構
2 超聲波電動機系統模糊建模方法
一般地,T-S模糊模型的基本結構如圖2所示,包含輸入量化、模糊化(隸屬度計算)、基于模糊規則的模糊推理和輸出比例運算等基本環節。其模糊規則形式如下,前提條件是模糊的,結論是清晰值。

圖2 模糊模型基本結構
Ri:If(x1isAi1)and(x2isAi2)and…and(xrisAir),theny=ai0+ai1x1+ai2x2+…+airxr
規則中,Ri代表第i條模糊規則。xk是模糊模型的第k個輸入變量,Ajk是變量xk的第j個模糊子集,yi是第i條規則Ri的輸出,aij是結論部分待定參數。
建立超聲波電動機系統的T-S模型,需要根據實測輸入、輸出數據進行結構辨識和參數辨識。參數辨識指規則前提部分和結論部分的參數辨識。參數辨識是在一定的模糊推理結構約束下,確定最優的模型參數,以使模型輸出盡量接近實測數據的優化過程。結構辨識是參數辨識的基礎。首先要確定輸入變量及輸入論域空間;然后,可采用模糊網格、模糊聚類、模糊樹等算法進行輸入空間的模糊劃分。其中,模糊聚類算法最為常用,它用隸屬度描述向量屬于一個聚類的可能性。首先,設定一個聚類數,該聚類數既是隸屬函數個數也是規則數;然后對輸入空間進行模糊劃分,采用蟻群算法確定高斯型隸屬函數的中心、寬度等特征值,即可完成超聲波電動機系統T-S模型的結構辨識。T-S模型結論部分的待定參數可用最小二乘法辨識得到。模型建立后,進行驗證計算,如果模型輸出值誤差較大,則增加規則數重新進行建模。建模基本步驟如下:
(1)確定輸入變量及個數p、聚類數c;
(2)根據實測的建模數據,確定驅動電壓幅值、頻率和轉速對應的論域區間[M-,M+];
(4)計算各數據點xk與聚類中心的距離dik:

(5)計算建模數據的隸屬度μik:
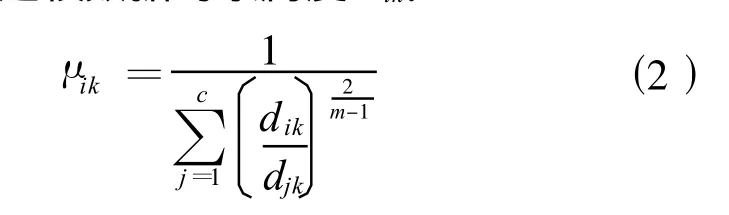
式中:m為常數,通常取m=2。
(6)采用最小二乘法求得T-S模型結論部分的待定參數aij;
(7)進行模型驗證。若模型精度不理想,則改變輸入變量個數p和/或聚類數c,轉步驟(2)。
根據實測數據分析,確定模型輸入變量為當前及以前時刻的驅動電壓幅值(峰峰值)u(k-3)、u(k-2)、u(k-1)、u(k),頻率值f(k-3)、f(k-2)、f(k-1)、f(k)和轉速值n(k-2)、n(k-1);輸出變量為當前時刻的轉速值n(k)。輸入變量個數p=10,規則數(亦即聚類數)c=10。u(k-3)、u(k-2)、u(k-1)、u(k)的隸屬函數是一樣的,各有10個高斯型隸屬函數,f(k-3)、f(k-2)、f(k-1)、f(k)和n(k-2)、n(k-1)也各有10個隸屬函數,共30個隸屬函數。每個隸屬函數有寬度和中心等2個待定參數,所以共有60個待定參數需要通過蟻群算法優化獲得。
3 用于超聲波電動機模糊建模的蟻群算法
所建動態模糊模型中,高斯型隸屬函數的中心和寬度等參數共有60個。期望通過基于實測數據的動態優化過程,獲取如此多的優化參數值,需要慎重選擇適當的優化算法以得到確實有效的優化結果。另一方面,超聲波電動機本身的顯著非線性,必然使得作為優化目標的模糊模型具有較高的復雜性;這進一步增加了優化過程的復雜度。
蟻群算法是一類內含隨機性的群體智能優化算法。因其在解決復雜優化問題方面表現出的良好性能,蟻群算法的應用領域正在不斷拓展[3-4]。假定有q個待優化的參數,分別為a1,a2,…,aq。首先,對每一個參數ai(1≤i≤q)將其設置為可能取值范圍內的Q個非零隨機數,形成集合Wai。蟻群從蟻巢出發去尋找食物,每只螞蟻都從集合Wa1出發,根據集合中的每個元素的信息素選擇一個值,在全部集合中選擇一組值,當螞蟻在所有集合中完成元素選擇后,它就到達食物源并按原路返回蟻巢,同時調節集合中元素的信息素。反復進行這一過程,當達到給定的迭代次數或者性能指標時,尋優過程結束。
采用蟻群算法優化超聲波電動機T-S動態模糊模型中的隸屬函數參數,計算步驟如下。
(1)分別在u、f和n的取值范圍內隨機產生100個非零數,組成60×100矩陣;
(2)初始化參數。設定螞蟻個數m,信息素的殘留程度ρ(0≤ρ<1),信息素總量Q,最大循環次數Nm,令每個集合中每個元素的信息素τj(Wai)=C(C為常數),Δτj(Wai)=0,j=1,2,…,100。τj(Wai)表示集合Wai的第j個元素的信息素,Δτj(Wai)=0表示在本次循環中集合Wai上的第j個元素上的信息素的增量;
(3)第k只螞蟻從集合Wa1出發(k=1,2,…,m),根據移動概率獨立隨機的從集合Wai中選擇第j個元素。移動概率計算如下:
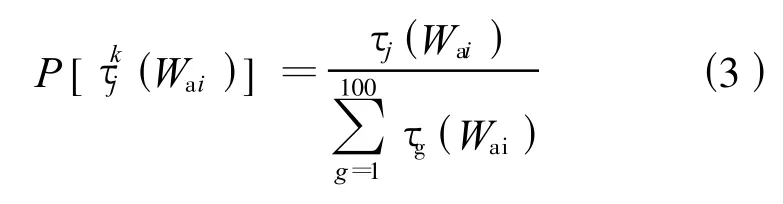
當第k只螞蟻在所有集合里完成元素的選擇后,就到達食物源。
(4)重復步驟(3)。m只螞蟻在所有集合里完成元素的選擇后,按照每只螞蟻選擇的元素,即超聲波電動機T-S動態模糊模型中的隸屬函數參數,根據輸入數據計算模型輸出,與實測數據比較得到誤差,進而得到每只螞蟻的性能指標如下:

式中:Y為模型輸出;O為實驗數據;d=1,2,…,h,h為實測數據點個數。記錄本次循環中性能指標的最小值,并記錄該值對應的螞蟻所選擇的元素;
(5)更新信息素
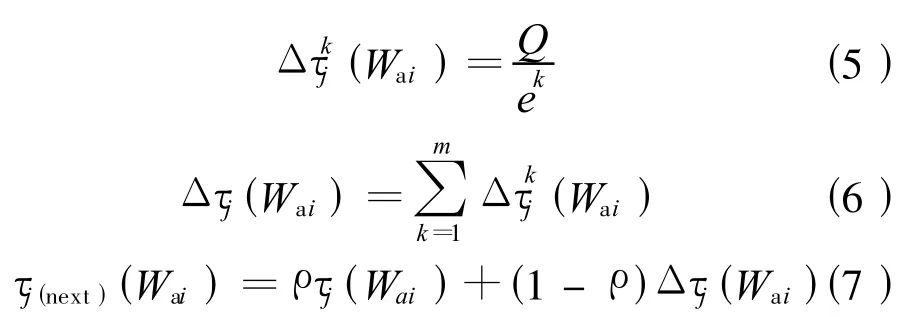
式中:Δτkj(Wai)表示第k只螞蟻在本次循環中留在集合Wai上的第j個元素上的信息素;τj(next)(Wai)為更新的信息素,用于下一次循環中;ek是第k只螞蟻的最大輸出誤差:

(6)當所有螞蟻都完成元素的選擇,更新信息素后,完成一次循環。重復步驟(3)~(5),直到指定最大循環次數Nm或者達到指定的性能指標值Je,循環結束,并輸出最優解。
4 蟻群優化模糊建模
蟻群優化算法中,螞蟻個數m、信息素殘留程度ρ等參數對優化過程具有重要影響,甚至會影響優化算法的有效性。但是這些參數的取值與優化對象密切相關,至今沒有明確的方法;通常需要針對特定的優化對象,通過嘗試逐步尋求適當的m、ρ等參數取值,以加快優化進程、改善優化結果。
4.1 螞蟻個數m的確定
設定ρ=0.7,取信息素總量Q=100,m分別取為40、50、60和80,通過比較優化過程及優化結果,尋找合適的m值。優化過程退出條件設定為固定循環次數,即當優化循環次數達到預先設定的最大循環次數Nm時,輸出最優解,優化過程結束。此處,取Nm=150。考慮到蟻群優化過程中包含隨機因素,對每個m值各進行三次優化計算,每次得到一個最優解及對應的最小性能指標Jmin,同時記錄優化過程所用時間。對三次優化計算所得最小性能指標Jmin取平均值,可作為衡量優化效果好壞的依據。

表1 不同m值的優化過程對比
表1給出了上述優化計算的結果。計算所用計算機的CPU為Pentium 4,主頻2.93 GHz,內存容量為512 MB。可以看出,隨著螞蟻數的增加,計算時間變長;m=50和m=80情況下的Jmin平均值較小。下面改變優化過程退出條件,比較m=50和m=80的優化效果,確定優化效果較好的螞蟻數。
表1中,Jmin值通常大于800;因而設定退出條件為Jmin≤800或Nm>1000。其中,最大循環次數Nm設定為1 000,以限制優化過程時間長度。改變退出條件后,分別在m=50和80的情況下,進行三次優化運算,得到結果如表2所示。可以看出,m=80時,三次優化計算所得最小性能指標Jmin均達到800以下,且計算所用時間明顯少于m=50情況。至此可以確定,螞蟻個數m取為80較為合適。

表2 m=50和m=80情況下的優化過程對比
4.2 信息素殘留程度ρ的確定
設定m=80,信息素總量Q=100,最大循環次數Nm=200,ρ分別取為0.3﹑0.5﹑0.7和0.9,分別進行三次優化計算,得到結果如表3所示。
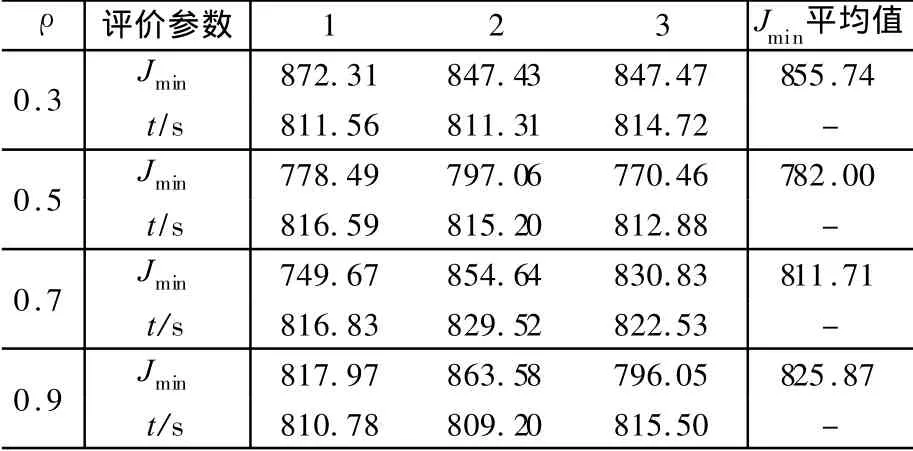
表3 不同ρ值的優化過程對比
表3表明,由于循環次數及m值固定,每次優化過程的計算時間基本相同。在ρ=0.5時,Jmin平均值最小,表明優化效果較好。由此可以確定,在循環次數Nm=200的情況下,取ρ=0.5,可以得到較好的優化效果。可以考慮增大循環次數,看是否能得到一個更小的性能指標,使優化效果更細想。
下面,在m=80、ρ=0.5的情況下,改變退出條件,期望得到更好的優化結果。根據表3的Jmin值情況,將退出條件中的性能指標設定為Jmin≤700。為了避免出現計算時間過長的情況,將最大循環次數設為2 000。故退出條件為Jmin≤700或Nm>2 000。經過優化計算,得到最優解,對應的Jmin值為662.1,計算過程歷時935.55 s。
根據上述最優解,得到超聲波電動機動態T-S模糊模型中輸入變量u、f和n的高斯型隸屬函數參數。模型計算輸出與實驗數據對比如圖3、圖4所示。圖3、圖4中,模型輸出的最大相對誤差值分別為1.4%、1.2%,平均誤差為0.68 r/min、0.65 r/min,較好地反映了超聲波電動機的動態特性。
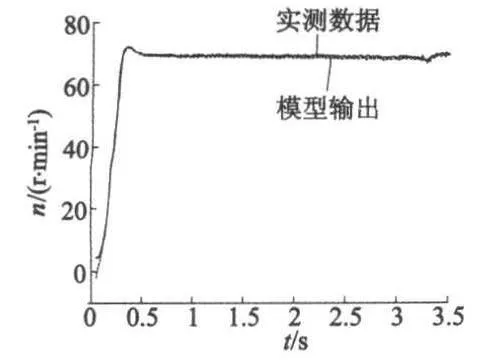
圖3 模型輸出與實測數據對比(nref=70 r/min)
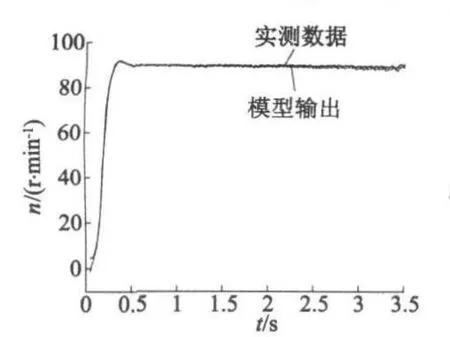
圖4 模型輸出與實測數據對比(nref=90 r/min)
5 結 語
蟻群算法可以有效避免局部優化,尋優方法簡單高效,魯棒性強。本文利用蟻群算法對超聲波電動機系統T-S動態模糊模型參數進行優化,得到了較為滿意的效果。
[1] Tomonobu S,Mitsuru N,Naomitsu U,et al.Mathematical model of ultrasonic motors for speed control[J].Electric Power Components and Systems,2008,36(6):637-648.
[2] Chen T C,Yu C H.Generalized regression neural-networkbased modeling approach for traveling-wave ultrasonic motors[J].Electric Power Components and Systems,2009,37(6):645-657.
[3] 王旭東,劉金鳳,張雷.蟻群神經網絡算法在電動車用直流電機起動過程中的應用[J].中國電機工程學報,2010,30(24):95-100.
[4] 王志強,劉剛.高速無刷直流電機鎖相轉速控制器參數蟻群優化[J].微電機,2010,43(6):54-58.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
