基于數據倉庫的水利工程信息管理系統設計
2012-07-04 08:02:44黃偉建徐學鋼王子軒
河北工程大學學報(自然科學版) 2012年1期
黃偉建,徐學鋼,王子軒
(1.河北工程大學信息與電氣工程學院,河北 邯鄲056038;2.北京師范大學藝術與傳媒學院,北京100875)
二十一世紀以來,我國在水利信息化建設的過程中,完成了大量的水利信息管理系統,這對于我國水利工程的投資建設和運行管理都起到了良好的促進作用。隨著水利信息化的發(fā)展,水利信息系統規(guī)模越來越大,對系統運行質量要求越來越高,任務越來越重,管理越來越復雜[1]。現有的水利信息管理系統所提供的功能大多是業(yè)務型的,只能處理直接的水利數據,難以獲取這些數據信息背后的隱含信息,如文獻[2]開發(fā)的東海縣水利工程管理系統,僅僅按照業(yè)務需要,把系統劃分為農田水利、工程管理、防汛抗旱、自然環(huán)境、水利史和大事記等業(yè)務模塊;而文獻[3]開發(fā)的水利工程科技檔案管理信息系統,僅能提供用戶管理、單位管理、檔案管理和管理員管理等管理信息。而這些直接數據信息背后的隱含信息,如各項水利工程的建設趨勢、各個承擔任務科室的進展趨勢、各類項目資金的完成趨勢等均無法體現。
本文基于數據倉庫技術和聯機分析處理(On-Line Analytical Processing,OLAP)技術,設計水利工程信息管理系統。系統按照渠道、科室和資金3個主題設計建立數據倉庫,以克服傳統的水利信息管理系統難以獲取這些隱含信息的缺陷,為水利工程決策人員提供高效的信息服務。
1 關鍵技術
1.1 數據倉庫
數據倉庫技術是二十世紀末在計算機領域中迅速發(fā)展起來的一種新技術。數據倉庫是面向主題的、集成的、穩(wěn)定的、隨時間變化的數據集合,用以支持經營管理中的決策制定過程。從數據庫基礎上發(fā)展起來的數據倉庫技術,從本質上講是一種新的信息集成技術。數據倉庫中存儲著海量的當前數據、歷史數據和綜合數據。這些數據往往是多個數據源的數據集成,并依照主題進行重組。數據倉庫中的數據一般不再修改。這些數據雖然也是隨時間變化而變化的,但時限比操作型數據的時限要長得多。數據倉庫在功能上與操作型的數據庫最主要的區(qū)別是建立決策支持系統,它可有效地實現對水利工程信息資源的管理和利用,為水利工程管理者的決策分析提供準確一致的量化信息[4-5]。
1.2 OLAP 技術
OLAP技術是基于數據倉庫的、針對主題的、能快速進行聯機數據訪問和分析的軟件技術。它對數據信息進行多種不同形式地觀察,使用戶可以從不同的維度、不同的側面和不同的數據綜合程度來觀察數據,從而獲得數據背后隱含的新的有價值的信息。OLAP分析工具是多維數據分析工具的集合[6],而水利工程的數據信息一般是多維的,因此多維數據就是水利工程決策的主要內容。OLAP技術側重于對水利局領導的決策支持,以便他們能準確掌握水利工程的狀況,制定出正確的方案和措施。OLAP先將數據倉庫當中的數據組織成多維數據立方體后,再通過“數據切片”、“數據切塊”和“數據鉆取”等操作方法對立方體進行分析操作。
(1)“數據切片”是從多維數據立方體上的某一維度上選定一個值后,把多維數據從n維降為n-1維。例如,在“橋梁工程”的多維數據立方體中,時間維度取“2009年”,則得到關于2009年所建設的所有橋梁工程數據信息的一個數據切片。
(2)“數據切塊”是從一個完整的數據立方體中切取一部分數據,從而得到一個新的體積較小的數據立方體。例如,在“橋梁工程”的多維數據立方體中,時間維度取“2007~2009年”,項目維度取“以工代賑”,投資額維度取“100萬元以下”,則會得到關于2007~2009年間的建設的投資額在100萬元以下所有以工代賑項目的橋梁工程數據信息的一個數據切塊。
(3)“數據鉆取”是通過改變數據立方體維度的層次,來達到變換分析粒度的目的。數據鉆取的方向分為下鉆和上鉆。下鉆是指用戶從某一個較高的層次出發(fā),去觀察較低層次的細節(jié)數據信息。上鉆跟下鉆正好相反,是指用戶從某一個較低的層次出發(fā),去觀察較高層次的宏觀數據信息。例如在時間維度中,從“年”的層次出發(fā),去觀察“月”的數據就是下鉆;而“月”的層次出發(fā),去觀察“年”的數據就是上鉆。
1.3 B/S架構模式
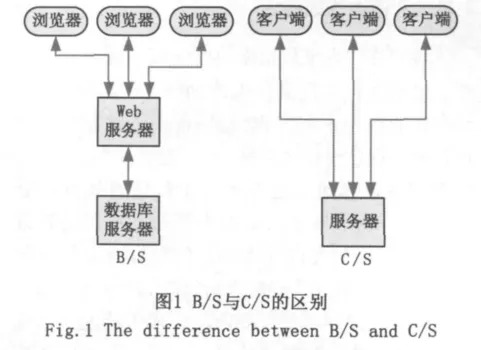
C/S(客戶端/服務器)和 B/S(瀏覽器/服務器)是兩種常用的架構模式[7]。傳統的C/S(客戶端/服務器)架構模式是兩層結構,分為客戶端和服務器兩部分,通過局域網直接連接。而B/S(瀏覽器/服務器)架構模式則是三層結構,為瀏覽器(相當于C/S架構模式中的客戶端)、Web服務器和數據庫服務器(相當于C/S架構模式中的服務器)3部分。瀏覽器與數據庫服務器不直接連接,而是通過中間層Web服務器進行間接連接,見圖1。其中瀏覽器與Web服務器可以通過局域網或廣域網進行連接,能充分利用Internet,延長連接距離。B/S架構模式將系統功能實現的所有應用軟件都安裝在Web服務器和數據庫服務器上,系統的維護工作也集中在這兩處,與客戶端的瀏覽器無關,客戶端零維護。系統的改進和升級也可以只在服務器端進行,所以系統的可靠性和穩(wěn)定性比C/S架構模式更高。瀏覽器、Web服務器、數據庫服務器三者為邏輯上的劃分[8],這三者也可以只布置在一臺計算機上。
2 系統的結構設計
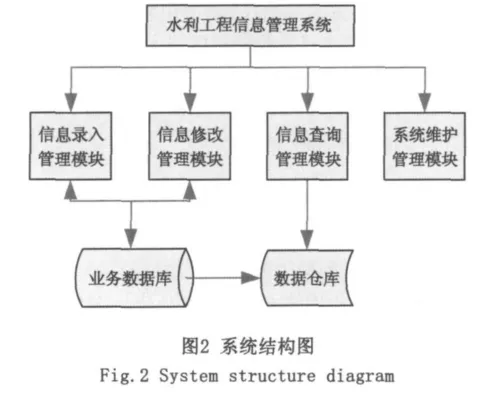
水利工程信息管理系統主要包括信息錄入管理、信息修改管理、信息查詢管理和系統維護管理4個模塊(系統結構見圖2)。根據具體需求,每個模塊都具有各自的功能[9]。
2.1 信息錄入管理模塊
負責錄入水利工程數據信息的工作。由于信息錄入人員不一定都精通計算機技術,所以本模塊的編制盡量智能化,錄入操作盡量簡單化。每一次錄入時,系統都會通過多次詢問來引導錄入者輸入格式正確、內容全面的數據信息。如果某一項工程不是首次錄入,系統還會自動顯示前一次錄入本工程的數據信息,提示錄入者檢查本次錄入的數據信息是否存在缺項或錯誤。
2.2 信息修改管理模塊
負責修改系統數據庫內的錯誤數據信息的工作。由于水利工程管理工作的特殊性,系統內已經存在的各種水利工程信息,都不能被刪除。即使某項工程已經報廢拆除,也不能刪除相關信息,因為這會影響到對過去水利工程建設情況的查詢。不過,由于操作人員的失誤所造成的信息錄入錯誤,系統是允許修改的。信息修改工作必須謹慎,只能由系統管理員進行操作,其他級別的用戶不能進行操作。并且修改工作還不能通過遠程網絡方式操作。這樣才能盡可能保證系統內數據信息的前后一致性。
2.3 信息查詢管理模塊
負責查詢水利工程數據信息的工作。這是管理系統的核心模塊。業(yè)務數據庫中數據信息經過抽取、清洗等處理后,集成在數據倉庫內。系統利用OLAP技術,將數據組織成多維數據立方體的形式,通過切片、切塊、鉆取等各種分析操作,使用戶能從多角度、多側面、多層次地查詢數據庫中的水利工程數據信息。管理系統把一些關鍵的查詢過程和查詢結果經過處理后存儲下來,并且當系統數據信息有更新時還能自動更新。這樣,當以后再進行類似的查詢時就不用每次都去搜索整個數據庫,而能快速地得到正確的查詢結果。系統能夠根據需要,把每次查詢的結果信息自動生成合適的數據報表,并能實現同上級機關相關軟件的接口對接。
2.4 系統維護管理模塊
負責對用戶和數據庫的維護進行管理工作。包括對用戶進行用戶申請、登錄申請和用戶級別設置等的工作,和對數據庫進行增加數據庫和數據備份等的工作。
2.5 系統的開發(fā)平臺
本系統的數據庫采用SQL Server 2005系統,使用Java作為開發(fā)語言,基于Eclipse開發(fā)。SQL Server是一種關系數據庫管理系統,具有使用方便、可伸縮性好、與相關軟件集成程度高和可多種平臺使用等優(yōu)點[10-11]。在SQL Server 2005 系統中提供了大量的數據倉庫設計、建立和操作等方面的工具。Java是一種跨平臺的、適合于分布式計算機環(huán)境的面向對象的編程語言,具有可移植、穩(wěn)定、簡單、高性能和可動態(tài)執(zhí)行等特征。Java應用程序(Java Applet)存放在Web服務器中,應客戶端瀏覽器的請求,傳送至客戶端,由瀏覽器去執(zhí)行。它可以有效地實現B/S架構模式的功能。
3 數據倉庫的設計與實現
數據倉庫的構建是一個不斷循環(huán)、反饋而使系統不斷增長與完善的過程[12],它的設計主要包括概念模型設計、邏輯模型設計和物理模型設計3個階段。
3.1 概念模型設計
概念模型設計主要界定系統邊界和確定主要的主題域及其內容,它包括需求分析、主題確定和概念模型確定等內容。
3.1.1 需求分析
水利工程的高級管理者,不光需要知道水利工程的具體數據信息,更重要的是需要了解:各個渠道配套工程的建設趨勢;各個職能科室承擔的工程建設任務的進展趨勢;各類項目資金的完成趨勢。
3.1.2 主題確定
根據需求分析,確定系統數據倉庫的主題為:渠道、科室和資金。
3.1.3 概念模型確定
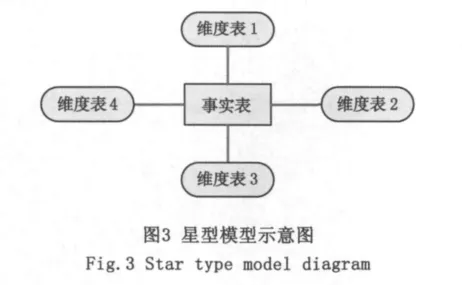
數據倉庫的概念模型常見的有3種:星型模型、雪花模型和事實星座模型。星型模型可以采用關系型數據庫結構,模型的核心是事實表,圍繞事實表的是維度表,通過事實表將各種不同的維度表連接起來,各個維度表都連接到中央事實表[13],見圖3。在該模型中,因為大部分數據都在事實表中,只需搜尋事實表就可進行查詢。并且維度表都比較小,能放在高速緩存中,可以快速地與事實表進行連接。星型模型實際上是以“空間”換“時間”,通過適當增加冗余存儲空間來顯著地提高系統查詢速度,所以本系統數據倉庫的邏輯模型采用星型模型。
3.2 邏輯模型設計
邏輯模型是數據倉庫從概念模型向物理模型過渡的中間層次模型。邏輯模型設計是把概念模型當中各種概念和實體間的相互關系,進行分解細化,使之能適應計算機系統存儲模式。邏輯模型設計主要包括事實表的設計和維度表的設計。
3.2.1 事實表設計
數據倉庫中的每個主題都需要通過一個或多個相關的事實表進行具體設計實現。事實表不僅是數據倉庫的核心,也是構成數據倉庫的所有類型表中體積最大的[14],它包含和決策目標緊密相關的數據信息。事實表的內容一般由兩部分組成:鍵和指標。事實表使用鍵把各個維度表聯系起來,指標用于記錄事實表的詳細信息。
不同的主題設計的事實表各有不同,以渠道主題為例設計事實表,它包括渠道工程信息表、配套工程信息表和工程歷次建設信息表。
3.2.1 維度表設計
事實表中的內容進一步分解,就得到維度表。維度表是事實表的關聯表[15],含有事實表中的特征數據,使用關鍵字同事實表進行關聯。維度表中還包含有多個詳細屬性,用于說明對象的邏輯關系。在設計維度表時,盡可能簡化維度表與事實表之間的聯系,盡量減少表之間連接數量,以減輕計算機系統的運算負擔。
下面列出渠道主題的的配套工程信息事實表的維度表:
建設時間維度表:年、月、日;
主要工程量維度表:土方、石方、混凝土方、鋼筋用量;
建設投資組成維度表:上級資金、地方配套、群眾自籌。
3.3 物理模型設計
物理模型設計即為邏輯模型中的數據確定一個符合要求的物理結構[16],也就是將邏輯模型當中的相關內容轉變?yōu)樵谟嬎銠C系統可以存儲的模式[17]。在認真分析系統數據倉庫的基礎上,研究它的存儲結構及方法、數據使用環(huán)境及使用方式和數據信息規(guī)模等主要參數,完成水利工程信息管理系統數據倉庫的物理模型設計。
3.4 數據倉庫的實現
系統使用SQL Server 2005中的數據倉庫工具建立數據倉庫,使用JSP實現數據倉庫的接口設計,使用Analysis Services工具采集和分析數據信息。數據的采集工作就是進行數據的抽取、轉換、清洗和裝載的過程,將業(yè)務數據庫當中的水利工程數據信息加載到數據倉庫中,從而完成數據信息從數據源向數據倉庫的轉化。它主要進行:識別數據源信息,管理元數據,集成不同數據源的數據格式,清理數據集,數據分割,定期更新和維護數據。
4 結語
本文設計開發(fā)的水利工程信息管理系統,利用數據倉庫技術確定渠道、科室和資金3個主題,利用OLAP技術從不同的維度、側面和數據綜合程度對數據信息進行多種不同形式地觀察,從而達到獲取這些直接數據信息背后關于3個主題的隱含信息的目的。如果用戶對隱含信息的獲取有新的或不同的需求,可以增加或更改主題,并按照新主題設計數據倉庫。
[1]蔡陽,詹全忠,周維續(xù),等.水利信息系統運行保障平臺關鍵技術研究[J].水利水電技術,2010,41(2):91-93.
[2]朱俊昌,高亞楠,鄭源,等.中小型水利工程管理系統的設計與實現[J].水電能源科學,2010,28(8):140-142.
[3]吳杰,王冬梅.水利工程科技檔案管理信息系統設計與實現[J].人民長江,2007,38(11):194-195.
[4]郭峻峰,倪志偉,高雅卓,等.一種提高數據倉庫查詢效率的有效方法[J].計算機集成制造系統,2009,15(12):2451-2457.
[5]陳步英,馬驊,張小志.高校財務數據倉庫研究[J].財會通訊,2010(11):119-120.
[6]楊 云,羅艷霞.基于Web數據倉庫構建GSM網絡優(yōu)化系統[J].計算機工程與設計,2010,31(12):2894-2900.
[7]王春波,楊大兵.基于ArcSDE技術的地籍管理系統研究[J].河北工程大學學報:自然科學版,2010,27(3):77-80.
[8]蔣 薇,賴青貴,陳 楠.基于B/S架構的"神龍一號"數據庫系統的實現[J].強激光與粒子束,2010,22(3):642-646.
[9]張穎,劉惠德,侯旭輝,等.礦井水文地質信息系統的設計與實現[J].河北工程大學學報:自然科學版,2008,25(4):82-85.
[10]胡逢愷,趙 剛,程旭.基于SQL Server數據庫的三維模型存取研究與實現[J].四川理工學院學報:自然科學版,2010,23(2):212-215.
[11]胡開明,陳建華.用.NET實現對SQL SERVER數據庫安全的動態(tài)監(jiān)控[J].四川理工學院學報:自然科學版,2010,23(3):299-302.
[12]黃曉穎,李亞芬,王 普.基于數據倉庫的學科建設決策支持系統的設計[J].計算機工程與設計,2010,31(23):4995-4998.
[13]秦永平,王麗萍.基于數據倉庫的突發(fā)公共衛(wèi)生事件預警預報系統[J].計算機工程與設計,2010,31(13):3119- 3122.
[14]趙寶華,阮文惠.高校財務數據倉庫的設計與實現[J].計算機工程,2008,34(17):266-268.
[15]王志宏,顧新建.基于數據倉庫的產品族供應鏈管理系統[J].浙江大學學報:工學版,2009,43(7):1197-1202.
[16]李志剛,馬剛.數據倉庫與數據挖掘的原理及應用[M].北京:高等教育出版社,2008.
[17]劉永立,王海濤,孫維民,等.基于基礎數據庫的煤礦應急救援指揮信息系統[J].黑龍江科技學院學報,2010,20(1):44-47.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
