ACPSO-SVR結合的非線性建模預測算法研究
2012-09-27 01:41:52韓曉霞韓曉明謝克明
電子設計工程 2012年5期
韓曉霞,謝 剛,韓曉明,謝克明
(太原理工大學 信息工程學院,山西 太原 030024)
ACPSO-SVR結合的非線性建模預測算法研究
韓曉霞,謝 剛,韓曉明,謝克明
(太原理工大學 信息工程學院,山西 太原 030024)
提出一種基于自適應混沌粒子群優化和支持向量機結合的非線性預測建模算法(ACPSO-SVR),引入ACPSO啟發式尋優機制對SVR模型的超參數進行自動選取,在超參數取值范圍變化較大的情況下,效果明顯優于網格式搜索算法。選取UCI機器學習數據庫中的Forest fires標準數據集進行測試,實驗結果表明該方法具有較高的精度和良好的泛化能力,對于解決多變量的回歸預測問題是一種有效的方法。最后給出了混合算法在碳一多相催化領域的兩種典型應用,在反應動力學模型未知的情況下建立催化劑組份模型和操作條件模型,以及基于混合算法的最優催化劑設計框架。
支持向量機;自適應混沌粒子群優化;建模;預測;碳一多相催化劑
許多實際工業過程或研究對象都具有很高的復雜性,其機理尚不十分清楚,或機理方程非常復雜,難以用現有的數學理論建立機理模型。隨著人工智能和計算機技術的發展,非線性工業過程建模技術和方法主要集中在專家經驗方法、神經網絡方法、模糊邏輯方法、支持向量機方法、模式識別方法、遺傳編碼方法等方面。
支持向量機(Support Vector Machines,SVM)遵循統計學習VC維理論和結構風險最小化原理 (Structural Risk Minimization,SRM),最早應用于模式識別領域,后來通過引入ε不敏感損失函數概念,推廣到ε-SVR (Support Vector Regression,SVR),廣泛應用于函數回歸問題,成為經驗建模中重要的智能建模方法之一。由于SVR能較好地解決小樣本、高維、非線性和局部極小點等實際問題,并且可以有效地克服維數災難和過擬合等問題,己經成功地應用于復雜工業過程的動態建模、系統辨識和控制、數據分析、故障診斷等方面。
針對SVR模型的超參數選擇直接影響著SVR的一般性能和回歸檢驗,是確保SVR模型優秀性能的關鍵,筆者提出自適應混沌粒子群優化算法對SVR模型的超參數進行優化選擇,在此基礎上,提出了基于ACPSO-SVR的預測模型,并給出了詳細的建模與算法流程。應用該方法對UCI數據庫的Forest fires回歸預測數據進行測試,結果顯示基于ACPSO-SVR的預測模型具有較高的精度和良好的泛化能力,對于解決多變量的建模和預測問題是一種有效的方法。最后,給出了該方法在碳一多相催化劑建模與最優化設計中的2種應用。
1 算法理論
1.1 支持向量回歸機
支持向量機[1]是統計學習理論中最年輕、最實用的部分,是基于結構風險最小化原理和VC維理論的新型機器學習方法。它最初主要用來解決模式識別問題。1997年,Vapnik等拓寬了SVM的應用范圍,成功地解決了小樣本、非線性及高維數據的函數回歸擬合問題。對于非線性回歸,通過引入核函數來簡化非線性逼近,將低維空間映射到高維的重建核Hilbert空間,即x→Q(x),然后在高維特征空間中進行線性回歸,從而取得在原空間非線性回歸的效果。根據Mercer定理[2]計算核函數中的內積運算就可以實現非線性函數擬合。
SVR學習與預測的示意圖如圖1所示。
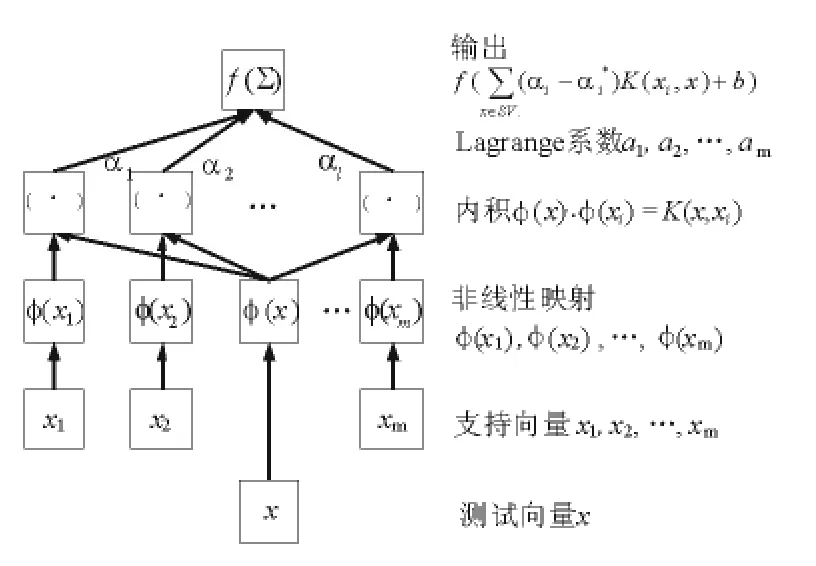
圖1 SVR學習與預測算法示意圖Fig.1 Schematic diagram of the SVR training and predicting algorithm
圖1可見,SVR的訓練過程與ANN有著某種類似,兩者都具有網絡結構和節點權值,但與ANN訓練過程中網絡結構固定不變不同,在SVR的訓練過程中,其網絡的結構和權值隨著尋優過程的變化而時刻調整著,即在算法的復雜性與預測精度之間進行協調。
對于非線性支持向量機回歸,構造SVM回歸估計函數:
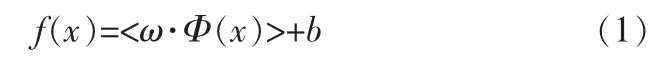
使得預測的期望風險函數最小:
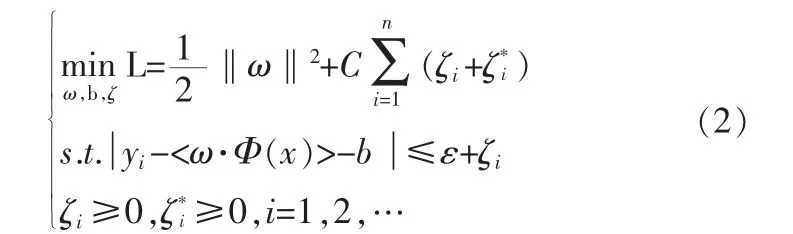
式(2)中,松弛變量(ζi,ζ*i)和懲罰因子 C(>0)用于調節超出ε管道的樣本點。懲罰因子C和管道因子ε是兩個可以調節的自由參數,C表示模型的復雜性和逼近誤差之間的平衡,ε表示訓練數據合適的管道寬度[3]。在SVM回歸算法求解實際問題只需對支持向量進行,支持向量可以看做是壓縮了的訓練集里信息量最真實的數據點,于是最終的回歸估計函數形式為:
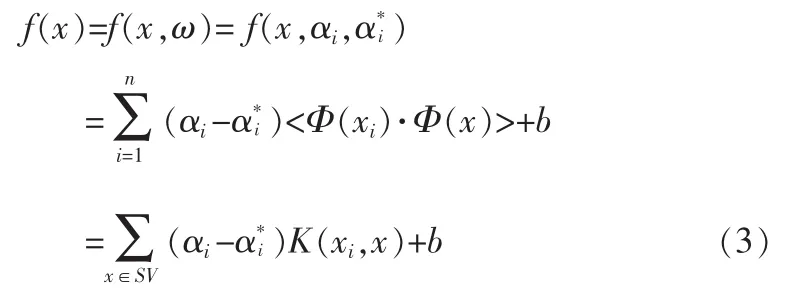
其中K為核函數,采用不同的核函數可以構建出不同的支持向量回歸機。 文中采用徑向基核(Gaussian 核),K(x,xi)=exp[-(x-xi)/2σ2],它對于常見的模式識別問題都具有優異的泛化性能。以上自由參數和核函數的選擇共同決定SVR回歸估計的準確性和泛化能力。
1.2 自適應混沌粒子群算法
自適應混沌粒子群優化 (Adaptive Chaos Particle Swarm Optimization,ACPSO)算法引入混沌優化思想和自適應慣性權調整策略,利用混沌特性提高種群的多樣性和粒子搜索的遍歷性,將混沌狀態引入到優化變量使粒子獲得持續搜索的能力;引入自適應慣性權系數 (Adaptive Inertia Weight Factor,AIWF)[4],提高算法效率,避免陷入早熟,有利于全局范圍內產生很好的搜索能力。
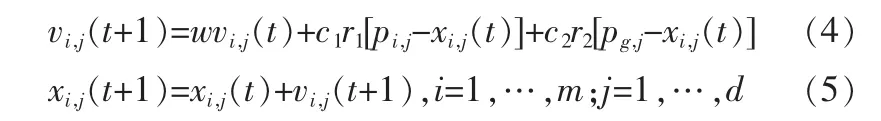
已知基本粒子群優化算法[5]按公式(4)和(5)分別更新各粒子的速度和位置:在ACPSO算法中,采用自適應慣性權系數AIWF來動態調節慣性權重w,其計算公式如下:
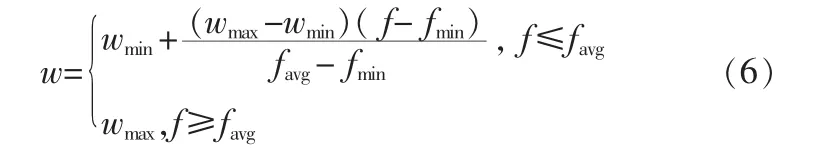
其中,wmax和 wmin分別代表慣性權重w的最大值和最小值,f為粒子當前的目標函數值,favg和 fmin分別為所有粒子的平均值和最小目標值。
當各粒子的目標值區域一致或者趨于局部最優時,將使w增加;而當各粒子的目標值比較分散時,將使w減少。同時,對于目標值f優于平均目標值favg的粒子,將對應于較小的w,從而使該粒子得以保護;而對于目標值f差于平均目標值favg的粒子,將對應于較高的w,從而使該粒子能夠更快地趨向較好的搜索空間。
ACPSO算法是一個兩階段算法,其中AIFW調整算法主要用于執行全局搜索,而混沌優化搜索[6-7]除了在初始階段產生混沌序列之外,將根據PSO算法的結果執行局部搜索。
1.3 建模與算法流程圖
將ACPSO-SVR混合算法應用于非線性系統建模與預測中,建模流程如圖2所示。本文選用libSVM工具箱ε-SVR回歸,SVR 超參數(C,σ,ε)采用 ACPSO 算法優化,核函數選用RBF核函數,目標函數采用CV意義下的性能指標對網格上的每組參數對(C,σ,ε)進行泛化能力評價,libSVM工具箱中ε-SVR回歸的性能指標采用均方誤差MSE(Mean Squared Error)、根均方誤差 RMSE(Root Mean Squared Error)和相關系數 CC(Squared Correlation Coefficient)。
2 算法性能分析
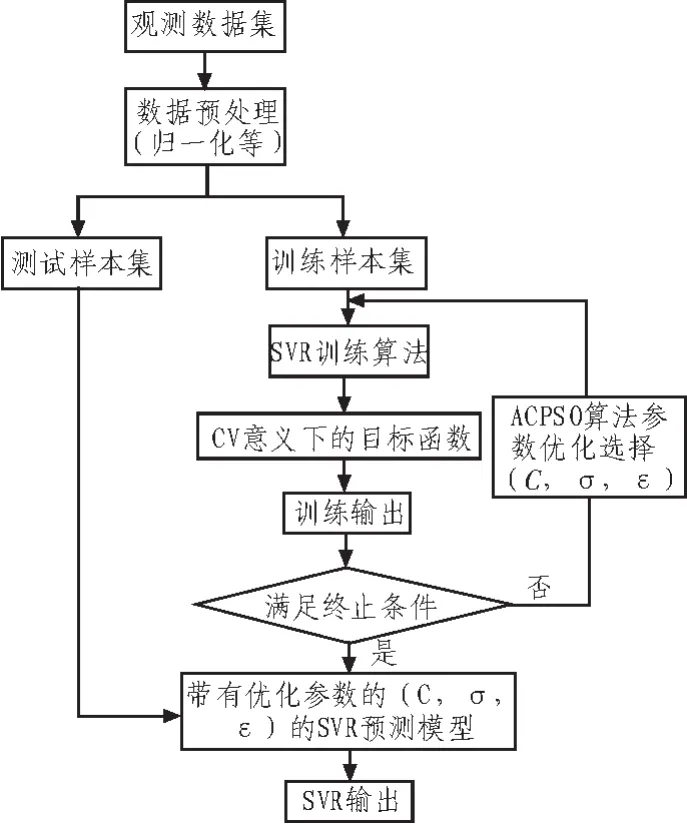
圖2 ACPSO算法優化SVR超參數流程圖Fig.2 Modeling flow diagram based on ACPSO-SVR
為驗證本文提出的ACPSO-SVR建模方法的預測能力,選取UCI機器學習數據庫(http://archive.ics.uci.edu/ml/)中的Forest Fires標準數據集進行測試。Forest Fires數據集是一個預測森林火災發生地的數據庫,數據集規模517×13,屬于多變量的預測問題。實驗的硬件環境為PIV3.4 GHz,1 G內存,120 G硬盤;仿真工具為Matlab7.0。
首先將原始數據預處理,歸一化到[0,1]之間。選用ε-SVR回歸算法,高斯基RBF核函數,10-fold交叉驗證模式。設置SVR模型參數的取值范圍:懲罰參數c的變化范圍(取以2為底的對數后)為[2-10,210],RBF函數寬度σ的變化范圍(取以 2 為底的對數后)為[2-5,25],損失函數 ε =0.001,SVR 模型輸出為均方誤差MSE和相關系數R。設置ACPSO的參數取值范圍:學習因子c1=1.5,c2=1.7,最大迭代次數 M=200,種群規模PoP=20。
圖3所示為采用ACPSO對SVR模型參數選擇結果圖。
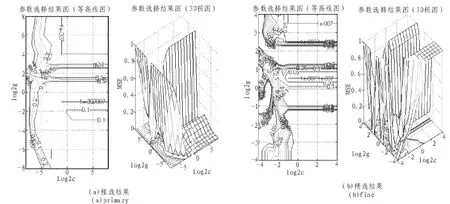
圖3 基于ACPSO的SVR模型參數優化結果圖Fig.3 Optimization results of SVR model based on ACPSO
其中(a)圖是SVR參數初選結果,(b)圖為將參數c和σ的取值范圍依據 (a)圖結果進一步縮小范圍后的精選結果圖。粗選結果:Best Cross Validation MSE=0.000 961 388,Best c=0.29,Best g=2,由圖 3(a),對應 MSE 最小處,重新設置懲罰參數c的變化范圍 (取以2為底的對數后)為[20,210],RBF函數寬度σ的變化范圍(取以2為底的對數后)為[2-2,23],得到最好的 Best c=0.17,Best g=2.5,回歸結果:均方誤差 MSE=1.950 29e-005,相關系數R=99.934 5%。
圖4(a)所示為SVR參數精選過程中ACPSO的適應度曲線,(b)所示為ACPSO-SVR回歸預測的誤差曲線,結果表明基于ACPSO-SVR的預測算法具有良好的回歸能力,對于多變量回歸問題能保證良好的預測精度。
3 算法應用
隨著國民經濟的發展,尤其新能源需求、新材料的不斷涌現,多相催化科學與技術面臨新的挑戰,既要從經濟、安全、多功能等方面尋求新型、高效的催化劑,又要從化學進程全局出發全面考察催化劑的性能。作為催化領域的難點和迫切需要解決的3個關鍵問題:催化劑的動力學關系模型、催化劑的活性關系模型、催化劑的優化設計,這無論是對于催化劑對象的特性研究,還是實際化工生產過程控制、優化、模擬等都具有重要的現實意義。作者嘗試在碳一催化劑的建模與最優化設計中,使用本文提出的非線性系統建模與預測算法,克服傳統催化劑研發中反復 “試錯”試驗的缺陷,縮短了催化劑研發的時間,節約資金和降低時間的消耗,取得了一定的成果。
3.1 建模與預測中應用
煤基二甲醚(簡稱DME),在我國富煤、貧油、少氣的能源環境下,成為優先發展的替代能源。而影響漿態床二甲醚合成工業化進程的關鍵因素是催化劑穩定性和活性之間的關系。將本文提出的ACPSO-SVR建模與預測方法應用于合成二甲醚多相催化劑實驗室制備中,結合兩種催化劑各自優點,尋求一種Cu-Zn-Al-Zr的新配方組分,以及最佳的制備條件,提高CO轉化率和二甲醚的選擇性。
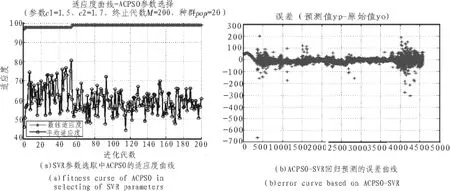
圖4 基于ACPSO-SVR預測算法性能曲線Fig.4 Performance curves of ACPSO-SVR prediction algorithm
圖5所示為基于ACPSO-SVR建模與預測示意圖。以催化劑的組分(Cu-Zn-Al-Zr)和制備條件(溫度、攪拌回流時間、加料方式)作為輸入變量。催化劑性能指標(CO轉化率、二甲醚的選擇性)作為輸出變量,建立Cu-Zn-Al-Zr漿狀催化劑動態模型,實現預測。

圖5 基于多相催化歷史數據的SVR建模示意圖Fig.5 Configuration of SVR model based heterogeneous catalysis historical data
3.2 最優化設計中應用
多相催化過程是個混合過程,過程的優化目標屬于多目標優化,可以描述為:給定過程的操作變量值或多相催化劑的組分變量值作為輸入變量,以及相應的過程輸出變量值,如催化劑的活性和選擇性、目標產物的轉化率等,尋求輸入變量的最優值,使得預先指定的過程性能同時最大,即發現具有最佳組分或最佳操作條件下的具有最優催化性能的最優催化劑。
然而,在多相催化領域,獲取催化劑性能評價(活性、選擇性、穩定性)非常困難,需要反復的制備、表征,不借助軟計算方法來發現最優組分和最優制備條件下的催化劑,其成本和時間耗費難以想象。將訓練好的ACPSO-SVR模型作為最優化設計方法中的適應度評價模型,試圖通過ACPSO-SVR最優化設計來解決上述多相催化劑實驗室設計問題。
4 結 論
本文提出了一種非線性系統的建模與預測的新方法,該算法理論上具有全局最優點,解決了神經網絡方法無法避免的局部最優解和網絡結構難以選擇等問題,同時克服了維數災難問題,SVR算法的復雜度與樣本維數無關,具有良好的泛化能力。
仿真結果表明,將ACPSO算法的智能搜索用于ε-SVR支持向量回歸機算法的參數選擇過程中,與K-CV(K-fold cross validation)意義下的窮盡式網格搜索算法(Grid-search Method)相比,能夠在更大的參數空間內,不必遍歷網格內的所有參數點,以較少的搜索次數獲得全局最優解,使得SVR算法具有良好的泛化能力和逼近精度。
[1]VAPNIK V.The nature of statistical learning theory[M].New York:Springer,1995.
[2]Burges C J C.A tutorial on support vector machines for pattern recognition[J].Data Mining and Knowledge Discovery,1998(2):121-167.
[3]Cherkassky V,Yunqian M.Practical selection of SVM parameters and noise estimation for SVM regression[J].Neural Networks,2004(17):113-126.
[4]王凌,劉波.微粒群優化與調度算法[M].北京:清華大學出版社,2008.
[5]Kennedy J,Eberhart R C.Particle swarm optimization[C]//Proc IEEE International Conference on Neural Networks,Perth, Australiam, Piscataway:IEEE Press,1995:1942-1948.
[6]李兵,蔣慰孫.混沌優化方法及其應用[J].控制理論與應用,1997,14 (4):613-615.
LI Bing,JIANG Wei-sun.Chaos optimization method and its application[J].Control Theory&Applications,1997,14(4):613-615.
[7]賈東立,張家樹.基于混沌變異的小生境粒子群算法[J].控制與決策,2007,22(1):117-120.
JIA Dong-li,ZHANG Jia-shu.Niche particle swarm optimization combined with chaotic mutation[J].Control and Decision,2007,22(1):117-120.
Application of adaptive chaos particle swarm optimization and support vector regression for modeling and forecasting of nonlinear system
HAN Xiao-xia, XIE Gang, HAN Xiao-ming, XIE Ke-ming
(College of Information Engineering,Taiyuan University of Technology,Taiyuan030024,China)
An effective relevance prediction algorithm is presented for nonlinear system forecasting and modeling based on adaptive chaos particle swarm optimization and support vector regression,namely ACPSO-SVR method.A heuristic optimization method ACPSO was introduced to automatic selection of hyper-parameters in SVR.The forest fires standard data set of UCI machine learning database was selected to test.The experimental results showed that the new method has high relatively precision and good generalization ability with a wide range of parameter values,better than that of mesh searching algorithm.It could be used as an effective method to solve the problems of multivariate regression predication.Moreover,two main applications were introduced in C1 heterogeneous catalysts yield,obtaining the catalyst composition model and the kinetic model,and building the optimization framework of catalyst development in laboratory.
support vector regression; adaptive chaos particle swarm optimization; modeling; forecasting; C1 heterogeneous catalysts
TP391
A
1674-6236(2012)05-0014-04
2012-01-06稿件編號:201201017
國家自然科學基金(60975032);國家青年科學基金資助(20606022)
韓曉霞(1976—),女,山西忻州神池人,博士,講師。研究方向:智能控制理論與應用,軟計算方法,智能傳感器與檢測技術。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
石油石化綠色低碳(2019年6期)2019-02-13 09:39:01
光學精密工程(2016年6期)2016-11-07 09:07:19
浙江大學學報(工學版)(2016年11期)2016-06-05 09:21:04
