面向作業車間重調度的改進合同網機制研究*
2013-09-13 07:55:28丁彬楚湯洪濤
機電工程 2013年2期
丁彬楚,湯洪濤
(浙江工業大學 工業工程研究所,浙江 杭州 310014)
0 引 言
車間初始生產調度方案實際執行時,會遇到各種各樣的擾動,這些擾動會帶來重調度的需求,并且這些擾動對重調度方法的實時性、動態性及其耦合能力都有很高要求。基于多Agent的調度技術采用協商機制解決調度決策中的各類沖突,能夠準確地反映系統的動態重調度過程,降低問題求解的復雜性,對動態的現實環境具有良好的靈活性和適應性。
現有的協商機制中基于合同網(CNP)的協商機制最為常用,一般認為,合同網協商機制具有較好的開放性以及動態分配和自然平衡能力。但是,傳統的合同網協商機制僅僅規定單一的工作過程,本身沒有優化能力和動態學習能力,因此具有自學習能力的合同網協商機制成為了該領域研究的熱點。Csaji等[1]以提高Agent的學習能力為目的,提出了基于時間差分學習算法TD(λ),從而在協商過程中獲得更好的投標者。Wang和Usher[2-3]為解決動態單機調度問題中調度規則動態優化選擇的問題,集成了強化學習中的Q-學習和CNP機制。王世進等[4]在此基礎上,深入探討了集成Q-學習和CNP機制的分布式柔性作業車間環境下作業動態分配優化問題,給出了具有針對性的集成機制的策略決策過程和學習過程。Q學習能夠使Agent從給定的調度規則中選擇出較好的調度規則,但是當這些啟發式規則在學習中得不到最優解時,不能及時得到修正,并且Q學習本身無規劃能力,不能滿足重調度需求。張化祥等[5]通過考慮個體多步進化效果優化變異策略的選擇,提出了一種基于Q學習的適應性進化規劃算法(QEP),用變異策略代替了啟發式規則,提供了更多的交互機會,使Q學習更具有廣泛性。
在以上Q學習、QEP等算法的研究基礎上,本研究將其應用于動態重調度問題的研究,并引入滾動窗口技術改進QEP算法,提出集成QEP和CNP的協商機制,以實現柔性作業車間動態重調度過程。
1 重調度假設及目標
本研究中的動態重調度針對的對象為柔性作業車間,給出假設條件如下:
(1)各設備同一時刻只能加工一個工件;
(2)工件在設備上的加工時間已知;
(3)正在加工的工件不進行重調度;
(4)調度過程中除設備以外的其他資源充足,無需調度。
重調度的目標描述如下:首先,仍應盡量保證原調度方案的優化目標,即最大完成時間最小;其次,在實際的生產過程中,調度系統總體上是按照初始調度方案準備調度所需加工工具和材料,當調度方案改變時,勢必會造成這些工具和材料的運輸和浪費,所以重調度產生的調度方案應盡量減少與當前調度方案的差異,即最小化與重調度前調度方案的背離。
對于多目標的求解方式主要有3種:決策先于優化、決策與優化交替以及優化先于決策[6-7]。本研究采用傳統的決策先于優化的方式,給出重調度目標函數數學表達式如下:
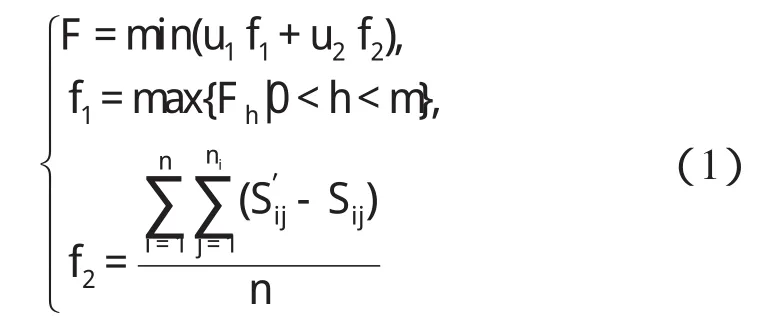
式中:m—作業車間設備數量,n—調度工件數,ni—工件i的工序數,Fh—設備h完成所有任務的時間,Sij—工件i第j道工序重調度前的開工時間,S′ij—重調度后開工時間。
2 改進QEP重調度算法
本研究給出的調度目標重點在于吸收和修復動態事件對調度的影響,因此筆者引入滾動窗口重調度技術。滾動窗口技術的應用可以減少動態重調度涉及的對象,縮小問題求解的規模[8],并將該技術集成到QEP算法中,使算法在求解重調度問題時具有合理的規劃性,避免盲目進化,提高進化效率。
改進QEP算法流程設計如圖1所示。
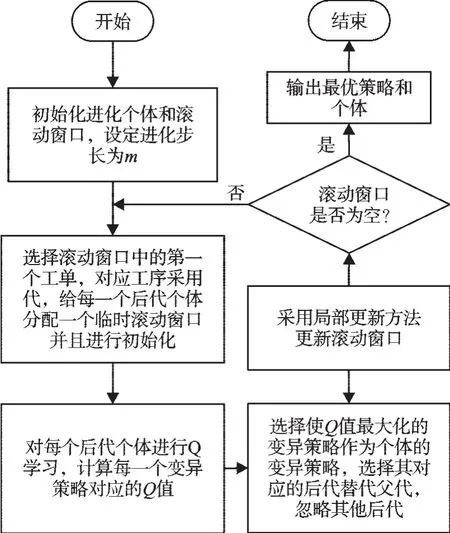
圖1 改進QEP算法流程
2.1 滾動窗口初始化及更新設計
當生產過程中有擾動事件發生時,某工件當前加工工序受到影響,并且由于該工件受到工序約束和設備約束,影響會進一步擴散,即重調度的擴散效應[9]。研究者通常采用二維分支樹(即工件分支和設備分支)來描述該擴散過程。滾動窗口初始化和更新建立在這種擴散過程的基礎上。
針對3種常見擾動事件,滾動窗口初始化方法為:
(1)加工延遲。初始滾動窗口為延遲工件兩分支上的工單;
(2)設備故障。初始滾動窗口為故障設備故障時間內待加工工單,如果設備故障時間未知,則表示為故障設備上所有工單;
(3)故障恢復。初始滾動窗口為所有可在該設備上加工的工單,已完工和正在加工的工單除外,同時滾動窗口內工單按照開工時間的先后順序進行排列。
本研究設計了局部和全局兩種滾動窗口更新方法。局部更新是針對某一工單進行更新、整合,步驟如下:
(1)以更新的工單為根節點,將工件分支和設備分支上的工單加入滾動窗口并刪除更新的工單;
(2)去除滾動窗口中重復的、無延遲發生的工單;
(3)按照工單開工時間的先后順序進行排序。
全局更新是針對滾動窗口內所有工單進行更新、整合,步驟如下:
(1)根據當前滾動窗口,將各工單工件分支和設備分支上的工單作為當前滾動窗口,替換原滾動窗口,在二維分支樹上表示為下一層的工單集;
步驟(2)、(3)同局部更新。
2.2 進化分析
Q學習通過選擇最大化Agent帶折扣累積收益的行動,可以學習到Agent的最優行動集。進化過程中,研究者若把個體變異策略看成行動,則個體選擇最優變異策略就轉化為Agent選擇最優行動,在選擇最優行動時考慮行動的立即及多步滯后收益,即計算折扣累計收益。
本研究假設個體進化步長為m(m>1),即考慮m-1步滯后收益,個體開始選擇變異策略為a,可以計算個體采用行動a時的收益為:
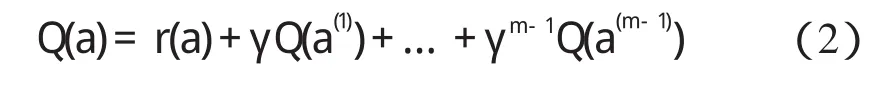
式中:r(a)—個體采用變異策略a的立即收益,此時個體進化了一次。
新生成的個體采用a(1)生成新個體,此時收益記為Q(a(1)),依次類推,m-1次進化后,新生成的個體采用a(m-1)生成新個體,此時收益記為Q(a(m-1))。式(2)為個體采用a,a(1),…,a(m-1)變異策略集的累計收益。定義個體立即收益r(a)=fp(a)-fo(a)。其中:fp(a)—父代個體對應的適應度值,fo(a)—采用變異策略a后生成的子代個體對應的適應度值。適應度函數計算公式如下:

其中,函數f1,f2已在公式(1)中給出。本研究將立即收益代入式(3),得到Q值的計算公式為:
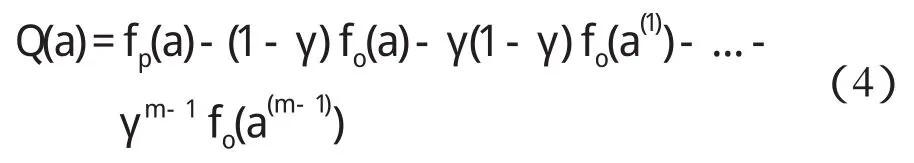
2.3 改進Q學習過程設計
在Q學習過程中,為保證滯后收益對Q(a)的有效性,本研究針對每個個體分配了一個臨時滾動窗口。
個體Q學習流程設計如圖2所示。
Step1:獲取臨時滾動窗口,設置進化代數t=2;如果臨時滾動窗口為空,轉入step5;

圖2 Q學習流程圖
Step2:遍歷臨時滾動窗口中每一個工單,采用Boltzmann選擇每一個工單對應工序的變異策略;Boltzmann分布計算變異策略被保留下來的概率為:

式中:n—工序變異產生的后代個數;α—調節系數,α∈(0,1);T0—初始溫度。
在Q學習的初始階段,溫度參數T設置較高,系統探索未嘗試的動作(選擇非最優變異策略),以獲得更多回報的機會;在Q學習的后期,筆者設置較低的溫度參數,使系統傾向于利用當前最優的變異策略。
Step3:采用全局更新的方法更新臨時滾動窗口,同時設置進化代數加1;
Step4:判斷t是否大于m,或者臨時滾動窗口為空;滿足條件則轉step5;不滿足則轉step2;
Step5:計算個體的Q值,Q學習結束。
以下給出m=2時的Q學習過程示意圖:

圖3 Q學習過程示意圖
2.4 變異策略
基于文獻[10]的研究,本研究給出以下變異策略:
(1)工序所用設備不變,加工順序不變,只是調整各個工序的開始時間和結束時間,記為“設備不變,順序不變”;
(2)工序所用設備不變,但在設備內的加工順序可以調整,記為“設備不變,順序可變”;
(3)工序使用設備發生變化,插入到并行設備加工列表中,記為“設備可變,順序可變”。
3 集成QEP的改進合同網協商機制
擾動事件發生時,集成QEP的合同網機制協商過程如圖4所示。其基本交互過程發生在工序Agent(PA)和設備Agent(MA)之間。
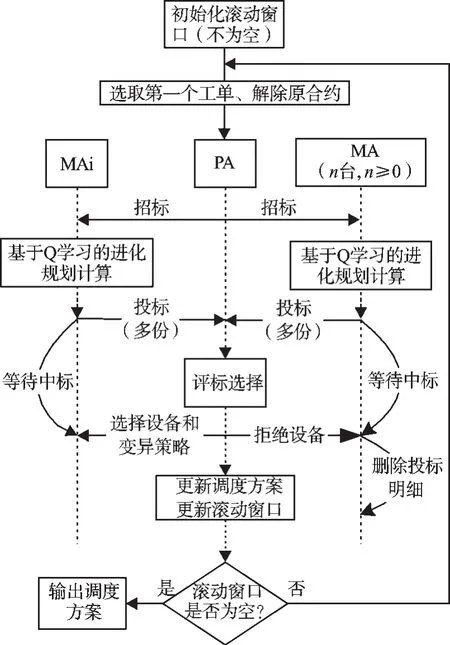
圖4 QEP-CNP協商流程圖
基本流程描述如下:
Step1:初始化滾動窗口;
Step2:獲取滾動窗口中的第一個工單,生成相應的工序Agent(PA),解除原先合約,并獲取調度需要的相關信息,包括加工時間、可加工設備、設備上的工單列表等;
Step3:PA向能夠加工它的設備發送招標請求;
Step4:設備Agent(MA)作為投標方進行Q學習,根據工件平均背離、總完成時間和設備負載等生成多份標書,向PA發送應標信息;
Step5:PA評價各MA發回的投標書,選擇中標的MA和最優變異(最大Q值),更新調度方案;兩份標書評價值相等時,根據設備負載,選擇負載小的MA和最優變異策略;
Step6:采用局部更新方法更新滾動窗口;
Step7:判斷滾動窗口是否為空;否,轉Step2;是,協商結束,輸出調度方案。
4 仿真實驗
本研究將文獻[11]給出的10×10標準算例調度最優解作為初始調度解,其甘特圖如圖5所示。筆者針對表1給出的動態事件進行重調度仿真。
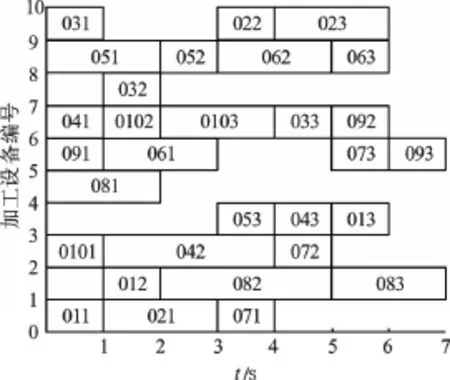
圖5 10×10甘特圖(最短加工時間:t=7 s)

表1 動態事件表
動態重調度算法選擇參數如下:完成時間權重為0.8,工時偏差權重為0.2,進化步長為2,變溫調節系數為0.8,初始溫度為10。由于重調度協商過程中工件和設備目標明確,容易達成一致,直接受影響的工件重調度所需要的時間可以忽略。
本研究通過仿真得到3個時刻重調度后的甘特圖如圖6所示。
本研究將改進的合同網協商機制與基本合同網協商機制相比,得到的仿真結果如表2所示。通過對比可以看出,改進的合同網協商機制具有較好的全局優化性能。

表2 仿真結果表
5 結束語

圖6 動態重調度甘特圖
本研究針對面向作業車間重調度問題的改進合同網協商機制進行了研究,設計了改進的QEP算法,提出了集成QEP和合同網的協商機制。該協商機制具有良好的反應能力和全局優化性能,但同時也存在如下問題:
首先,針對多目標問題,研究者在設計目標函數時采用簡單的加權法雖然提高了系統的反應能力,但是在一定程度上削弱了系統的優化能力;
其次,通過集成改進的QEP算法和合同網,雖然使得多Agent具有一定的自學習能力,但出于系統時間性能的考慮,簡化了Q學習每一步的進化操作,并且算法中的變異策略冗余度較高,未能做出有效優化。后續研究將從這幾方面進一步改善合同網機制。
(References):
[1] CSAJI B,MONOSTORI L,KADAR B.Reinforcement learn?ing in a distributed market-based production control system[J].Advanced Engineering Informatics,2006,20(3):279-288.
[2] WANG Y,USHER J.Application of reinforcement learning for agent-based production scheduling[J].Engineering Applications of Artificial Intelligence,2005,18(1):73-82.
[3] WANG Y,USHER J.A reinforcement learning approach for development routing policies in multi-agent production scheduling[J].The International Journal of Advanced Manufacturing Technology,2007,33(3/4):323-333.
[4] 王世進.面向制造任務動態分配的改進合同網機制[J].計算機集成制造系統,2011(6):1257-1263.
[5] 張化祥,陸 晶.基于Q學習的適應性進化規劃算法[J].自動化學報,2008(7):819-822.
[6] 陳 宇.不確定環境下的多Agent魯棒性生產調度研究[D].廣州:廣東工業大學自動化學院,2009.
[7] 崔遜學.多目標進化及其應用[M].北京:國防工業出版社,2006.
[8] 邵斌彬.柔性制造動態多目標調度模型在MES中的研究與應用[D].上海:上海交通大學軟件學院,2008.
[9] MARLER R,ARORA J.survey of multi-objective optimiza?tion methods for engineering[J].Structural and Multidis?ciplinary Optimization,2004,26(6):369-395.
[10] 丁 雷,王愛民,寧汝新.工時不確定條件下的車間作業調度技術[J].計算機集成制造系統,2010(1):98-108.
[11] 李修琳,魯建廈,柴國鐘,等.混合蜂群算法求解柔性作業車間調度問題[J].計算機集成制造系統,2011(7):1495-1500.
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
四川勞動保障(2021年9期)2022-01-18 05:11:08
經濟技術協作信息(2018年22期)2019-01-19 03:00:18
文苑(2018年21期)2018-11-09 01:23:06
電子制作(2018年11期)2018-08-04 03:26:08
中國衛生(2016年9期)2016-11-12 13:28:08
工業設計(2016年12期)2016-04-16 02:52:00
中國衛生(2015年9期)2015-11-10 03:11:12
設備管理與維修(2015年12期)2015-04-09 06:57:00
中國衛生(2014年3期)2014-11-12 13:18:12
