模板匹配和神經網絡法用于車牌識別的比較研究
2013-09-17 10:31:26夏領梯張煜東
微型電腦應用 2013年9期
關鍵詞:方法
韋 耿,夏領梯,張煜東
0 引言
車牌識別LPR(License Plate Recognition)是智能交通管理系統的核心組成部分,通過車牌自動識別系統,可以實現對車輛的自動監控,流量監控,驗證,登記以及報警等功能,從而給交通管理系統帶來了極大方便[1]。因此,車牌識別系統的實現是推進交通管理智能化的重要課題之一,在交通監視和控制中有著特別重要的實際運用價值和廣泛的應用前景[2,3]。但是,車牌識別多在室外條件下進行,易受到天氣、背景、車牌磨損、圖像傾斜等因素的影響。因此,實現準確快速的車牌識別,具有重要的現實意義。
車牌識別系統大致分為車輛圖像獲取、車牌定位、字符分割和字符識別等4大部分。其中字符識別的方法目前主要有模板匹配法[4,5]和神經網絡識別法[6,7]。本文采用模板匹配法和神經網絡法對車牌進行字符識別,并在Matlab平臺上實現了兩種算法。通過仿真,重點比較兩種方法的優缺點,獲得一些有意義的結論。
1 車牌字符識別原理
在實際的應用中,使用較多的方法有模板匹配法和神經網絡法。
1.1 模板匹配算法
模板匹配方法是將待識別的字符進行歸一化操作,然后與存放的模板庫里已標記類別的標準字符模板進行比較,找出匹配度最高的,來判別待識別字符的類別。該方法是實現離散輸入模式分類的有效途徑之一,其實質是度量輸入模式與樣本之間的某種相似性,根據匹配相似程度,取相似性最大者為輸入模式所屬類別。本文采用的模板匹配法流程,如圖1所示:
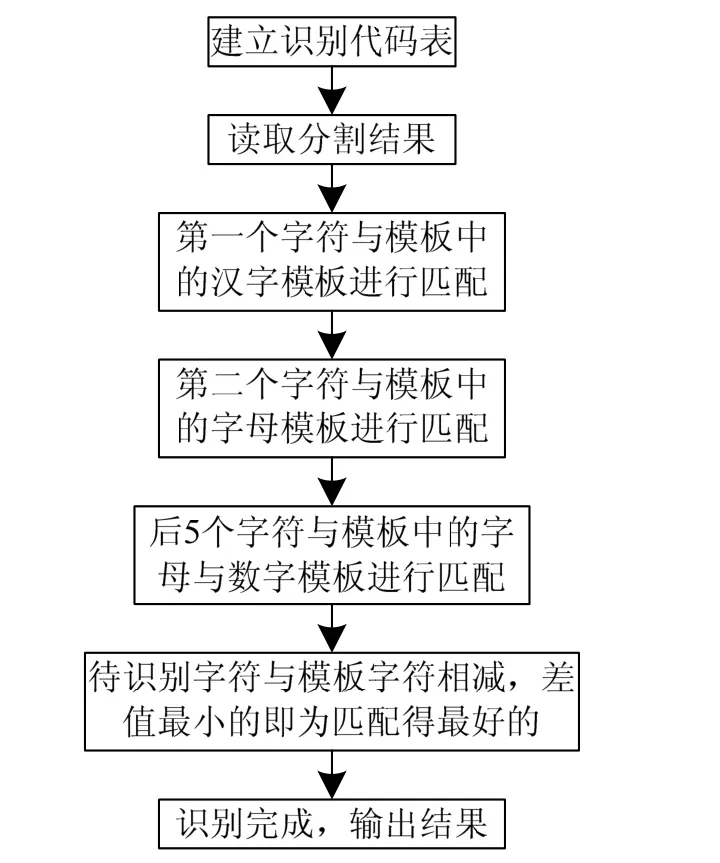
圖1 模板匹配流程圖
取字符模板,接著依次取待識別字符與模板進行匹配,將其與模板字符相減,得到的0越多,那么就越匹配,把每一幅相見后的圖的0值個數保存,然后找數值最大的,即為識別出來的結果。
1.2 神經網絡方法
神經網絡是從生物學神經系統的信號傳遞而抽象發展成的一門學科。神經網絡是有大量處理單元(神經元)廣泛連接而成的網絡,是對人腦的抽象、簡化和模擬,反映人的基本特征。通過學習它可以從外界獲取知識,并且內部的神經元還可儲存已學的知識。人工神經網絡即將生物神經元模型抽象成一個信號傳遞的數學模型,如圖2所示:
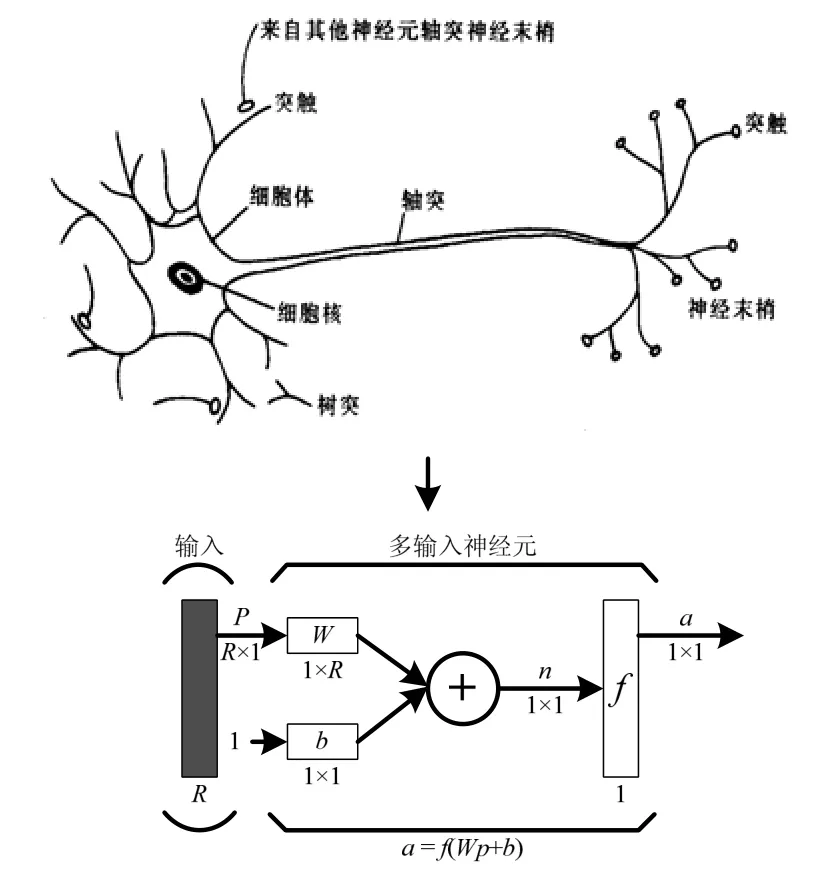
圖2 生物神經元模型--信號傳遞的數學模型
神經網絡的工作方式,由兩個階段組成:
(1)學習期:神經元之間的連接權值可由學習規則進行修改,以使目標函數達到最小。
(2)工作期:連接權值不變,由網絡的輸入得到相應的輸出。
神經網絡有很多種,由于基于 BP方法的分類器已趨成熟且性能較好,因而BP神經網絡有著廣泛的應用。BP神經網絡是一種按誤差逆傳播算法訓練的多層前饋網絡,其結構,如圖3所示:
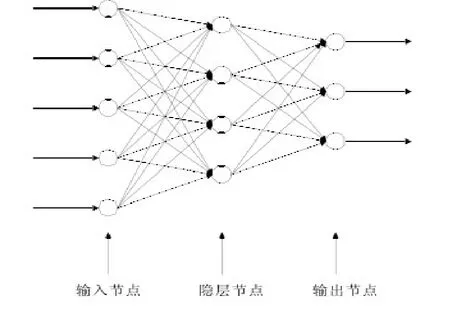
圖3 多層前饋型網路結構
這種網絡不僅有輸入層結點,輸出層結點,而且有一層或多層隱含結點。對于輸入信息,要先向前傳播到隱含層的結點上,經過各單元的特性為 Sigmoid型的激活函數運算后,把隱含結點的輸出信息傳播到輸出結點,最后給出輸出結果。
Sigmoid函數是神經網絡的激勵函數。激勵函數將輸出信號壓縮在一個允許的范圍內,使其成為有限值,通常神經元輸出的范圍在[0,l]或者[-1,l]的閉區間上。常用的基本激勵函數有閉值函數、分段線性函數、Sigmoid函數。其中Sigmoid函數也稱為s型函數,它是人工神經網絡中用的最多的激勵函數。
進行車牌識別前需要使用樣本對神經網絡進行訓練,然后使用訓練好的網絡對車牌進行識別,如圖4所示:
圖4 訓練界面
2 仿真結果及討論
2.1 模板匹配運行結果
模板匹配法一般要求模板庫存放大量的標準字符模板,這種方法需要將待識別字符要與所有模板字符進行比較,因而計算量相對較大。但是當模板庫較大,識別正確率一般可以保證處于較高的水平。模板庫樣本,如圖5所示:

圖5 模板庫字符樣本
利用模板匹配方法,對圖6(a)和(b)所示的車牌進行識別,結果如圖6(c)和(d)所示。可以看出,模板匹配方法對漢字的識別結果并不理想,這是因為在模板匹配時,所設計的模板和它對應的字符圖像難以完全吻合。對較為復雜的漢字而言,這種不吻合所帶來的失配量會對匹配結果產生不良的影響。從圖中還看出,模板匹配方法對字母“U”的識別也欠準確,而對數字的識別取得較好的效果。
2.2 BP神經網絡
BP學習算法可以歸納如下:
(1)設置變量和參數,其中包括訓練樣本,權值矩陣,學習速率。
(2)初始化,給各個權值矩陣一個較小的隨機非零向量。(3)輸入隨機樣本。
(4)對輸入樣本,前向計算BP網絡每層神經元的輸入信號和輸出信號。
(5)由實際輸出和期望輸出求得誤差。判斷是否滿足要求,若滿足轉第(8)步;不滿足轉(6)。
(6)判斷是否己經到了最大迭代次數,若到,轉第(8)步,否則反向計算每層神經元的局部梯度。
(7)根據局部梯度修正各個矩陣的權值。(8)判斷是否學習完所有的樣本,是則結束,否則轉(3)。利用BP神經網絡方法,對圖6(a)和(b)所示的車牌進行識別,結果如圖6(e)和(f)所示:

圖6 車牌識別結果
可以看出,神經網絡方法對漢字的識別結果較為理想,這是因為神經網絡經過學習訓練后,能夠匹配較準確的樣本。即使對較為復雜的漢字,經過多次迭代同樣可以取得較好的識別結果。同時,神經網絡方法對字母和數字也能進行較好的識別。
2.3 仿真結果討論
根據模板匹配及神經網絡這兩種方法的實現結果,可以得到以下結論:
(1)車牌中數字的識別率最高,這主要是由于數字字符的結構簡單,彼此間的相似度較小。
(2)在實際應用中,由于干擾因素很多,識別率會有一定的下降,如模板匹配法進行字符識別時,由于字符“U”的頂部存在噪音干擾,最終被識別為“D”(如圖6(d))。
(3)當字符較規整時,模板匹配及神經網絡對車牌的識別率都較高。但對于缺損或畸變較嚴重時,神經網絡更具優越性。
(4)模板匹配實現過程簡單,速度快;而神經網絡在識別前需進行網絡訓練,因而速度慢。
總而言之,模板匹配法實現簡單,當字符較規整時,其識別率較高。但該方法對車牌圖片要求較高,在圖像受嚴重干擾時,識別率較低,不及神經網絡。神經網絡法可處理一些環境信息十分復雜、背景知識不清楚、推理規則不明確的識別問題,允許樣品有較大的缺損和畸變,且具有自適應性好、識別率高、容錯性較好及強大的自學習和自調整能力。這使得它非常適合于模式識別問題。但神經網絡字符識別仍存在缺點:它需要較長時間進行網絡訓練,并且依賴于大量的學習樣本,此外目前能識別的模式類還不夠多。
3 結論
本文采用模板匹配法和神經網絡法對車牌字符識別進行研究,并比較了它們的優缺點,最后在Matlab平臺上進行仿真,獲得一些有意義的結論。
[1]任沙浦,沈國江.短時交通流智能混合預測技術.[J]浙江大學學報(工學版),2010,44(8),pp:473-1478.
[2]高韜,劉正光,岳士宏,張軍.用于智能交通的運動車輛跟蹤算法.[J]中國公路學報,2010,23(3),pp:89-94.
[3]李宇成,楊光明,王目樹.車牌識別系統中關鍵技術的研究.[J]計算機工程與應用,2011,47(27),pp:180-184.
[4]Karungaru,S.Fukumi M.and Akamatsu.N.Detection and Recognition of Vehicle License Plates using Template Matching.Genetic Algorithms and Neural Networks.2009 International Conference on Information and Computing Science,[C]2009:1975-1985.
[5]嚴萍,曾金明.一種有效的車牌字符識別法——模板匹配—特征點匹配相結合的車牌字符識別法.[J]西昌學院學報(自然科學版),2011,25(1),pp:42-44.
[6]O.V.Villegas and D.G.Balderrama.License plate recognition using a novel fuzzy multilayer neural network.[J]International Journal of Computers,2009,3,pp:31-39.
[7]劉高平,趙杜娟,黃華.基于自編碼神經網絡重構的車牌數字識別.[J]電子?激光,2011,22(1),pp:144-148.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
