詞類共現頻率的MapReduce并行生成方法
2013-09-18 05:32:28程興國肖南峰
重慶理工大學學報(自然科學) 2013年11期
關鍵詞:單詞
程興國,肖南峰
(華南理工大學計算機科學與工程學院,廣州 510640)
在語言學中,語料庫(corpus)指大量文本的集合。庫中的文本(稱為語料)經過整理通常具有既定的格式與標記,特指計算機存儲的數字化語料庫。
語料庫是語料庫語言學研究的基礎資源,也是經驗主義語言研究方法的主要資源,應用于詞典編纂、語言教學、傳統語言研究、自然語言處理中基于統計或實例的研究等方面。詞類共現是其研究內容之一,詞類共現頻率以共現矩陣的形式表達[2]。
共現矩陣是一個n×n的方陣,n是所需處理的語料中的單詞數(不同單詞的數量)。矩陣元素mij的值代表單詞wi和wj的共現(共同出現)次數。wi,wj共現定義為:wi,wj在指定的上下文范圍中同時出現。上下文的范圍可以有各種定義,例如同一個句子、同一個段落、同一個文檔或是同一個由連續k個單詞構成的序列(k的值也是可以定義的)。由于共現關系是對稱關系,因此m的上三角陣與下三角陣是相同的[3]。
共現矩陣的空間開銷是O(n2),其中n為詞匯表(vocabulary)的大小(即不同單詞的數量)。根據數據集的不同,詞匯表的大小也會有差距:英語語料庫中可能包含幾萬個詞匯,而對于Web規模的語料庫則可能有幾十億大的詞匯表。如果詞匯表不大,共現矩陣能放入單機內存中處理是最好不過的。但是大的語料數據往往有很大的詞匯表,以至于共現矩陣過大無法放進內存。虛存的使用會降低算法性能,即使壓縮能將共現矩陣的空間開銷降低一些,這種基于單機、主存的處理模式仍是有上限的。本文基于MapReduce模型實現共現矩陣的計算算法,具有良好的可擴展性,能處理大規模語料數據。
1 MapReduce編程模型
MapReduce模型是Google實驗室提出的分布式并行編程模型或框架,它能組織集群來處理大規模數據集,成為云計算平臺主流的并行數據處理模型。Apache開源社區的Hadoop項目用Java語言實現了該模型[4-5]。
MapReduce編程模型的基本思路是將大數據集分解為成百上千的小數據集splits,每個(或若干個)數據集分別由集群中的1個節點(一般是一臺普通的計算機)并行執行Map計算任務(指定了映射規則)并生成中間結果,然后這些中間結果又由大量的節點并行執行Reduce計算任務(指定了歸約規則),形成最終結果。圖1描述了MapReduce的運行機制。在數據輸入階段,JobTracker獲得待計算數據片在NameNode上的存儲元信息;在Map階段,JobTracker指派多個TaskTracker完成Map運算任務并生成中間結果;Partition階段完成中間結果對Reducer的分派;Shuffle階段完成中間計算結果的混排交換;JobTracker指派Task-Tracker完成Reduce任務;Reduce任務完成后通知JobTracker與NameNode以產生最后的輸出結果。MapReduce詳細執行過程如圖1所示[6]。

圖1 MapReduce詳細執行過程
2 詞類共現頻率的MapReduce方法
2.1 pair算法
表1展示了一種基于pair的MapReduce共現矩陣計算算法(以下簡稱為pair算法)。

表1 pair算法偽代碼清單
mapper接受(docid,doc)對作為輸入,對于每個共現對(w,u)都產生一個輸出key-value對(見表1的第5行)。這里采用直觀的二層循環的方式完成:第1層循環遍歷所有單詞;第2層循環遍歷所有與當前單詞相鄰(共現)的單詞。如果將共現矩陣看作一張圖(graph),這相當于每次輸出圖中的一條邊上的一個計數。
reducer將所有具有相同key值的((w,u),1)相加得出最終的((w,u),s)集合,集合中的每個元素對應共現矩陣中的一個元素,因此這個集合等價于共現矩陣。
2.2 stripe算法
表2展示了一種基于stripe的MapReduce共現矩陣計算算法(以下簡稱為stripe算法)。

表2 stripe算法偽代碼清單
mapper構造當前文檔的共現對的過程與表1所示算法類似,也是通過二層循環,但mapper記錄與輸出數據的方式有了一些變化:對于當前文檔的每個單詞/術語(term)w,維護一個關聯數組H,使得H{u}記錄的是共現對(w,u)出現的次數。reduce操作則是對分配到當前reducer的由mapper產生的(w,H)對進行加和合并,最后得到一個(w,H)的集合。對于其中每個元素,w是一個單詞/術語,H中存儲的是所有與w共現的單詞u以及共現對(w,u)出現的次數。這個集合同樣等價于共現矩陣。
為了更好地理解stripe算法,下面結合例子來說明。例如,對于如下的共現對輸入:
文檔 1(1,2)(1,2)(1,3)(2,3)
文檔 2(2,4)(1,4)(3,4)
輸出共現矩陣(共現對計數):
(1,2)∶2(1,3)∶1(2,3)∶1(2,4)∶1(1,4)∶1(3,4)∶1
stripe模式在mapper內對于當前單詞wi維護一個關聯數組(可以是哈希表、treemap等k-v結構)H。在H中,k是與wi存在共現關系的單詞wj,v是共現對(wi,wj)的計數。例如,對于上面給出的實例,當處理文檔1時,mapper有如表3所示的處理過程。

表3 stripe模式算法處理過程
隨后,reducer接受(w,[H1,H2,H3…]),合并H1,H2,H3…后輸出結果,共現矩陣計算完畢。
2.3 pair算法與stripe算法的比較
pair算法與stripe算法代表了兩種從觀察集中發現、計數共現事件(在本例中即為從語料庫中構造共現矩陣)的方法。這兩種算法的思路在很多類問題中都能得到有效應用(例如文本處理、數據挖掘、生物信息計算等)。
直觀比較下,基于stripe的算法數據表示更為緊湊,而基于pair的算法會產生比基于stripe的算法多得多的中間結果key-value對。因此執行時基于pair的算法需要排序的元素數更多。
進一步來看,pair算法與stripe算法又是統一的,兩者只是記錄的粒度不同:pair算法單獨記錄每一次共現,而stripe算法將滿足某種條件的共現記錄在一起。
stripe算法工作的前提是對于每個mapper輸入((docid,doc)對),其對應產生的關聯數組都能放入內存之中,虛存的引入將會大大降低其性能。因此,stripe在詞匯表很大的情況下難以勝任,一般處理幾個GB的語料數據沒有問題,而TB甚至PB級的數據就可能會導致內存溢出。相比之下,pair算法則不存在這個問題。
3 stripe算法內存瓶頸的解決
3.1 分治解決內存瓶頸
在stripe算法中,可以將語料數據的詞匯表劃分為b個桶(比如通過哈希),這樣原stripe就會被劃分為b個“子 stripe(sub-stripe)”。這種方法可以解決詞匯表很大時stripe算法內存不足的問題。需要注意的是,當b=1時,即為標準的stripe算法;當b=|V|(其中|V|是詞匯表中的詞匯數)時,stripe算法即等價于pair算法。
單詞表很大的情況下,每個文檔可能包含的單詞量非常多。此時對于每個wi可能都有非常多的單詞與之共現。假如對于每個單詞wi,與之共現的不同的wj單詞數平均是一個相對于詞匯表規模的固定比例r(例如1%),那么對于規模為n的單詞表,維護一個特定單詞wi的H平均需要存儲r×n個k-v對。如果H的空間利用率是常數的話(例如50%或100%),那么維護H的空間開銷是O(n)。
簡而言之,詞匯表很大會導致與每個wi共現的不同wj很多,最終導致H變得很大。考慮stripe的應用情境:mapper內維護H,可以得出stripe受限于單機內存容量的結論(一個mapper任務在一臺機器上運行)。因此stripe雖然高效,卻不能直接應用于詞匯表很大的語料數據。
內存瓶頸問題的本質是每個wi需要維護的wj過多,導致H過大,如圖2所示。

圖2 詞匯表中wi和wj構成
為簡單考慮,先假設這r×n個wj均勻分布在整個詞匯表區間里。如果能對該詞匯表做劃分,那么就可減少一次需要統計的wj的數量,從而減小H。劃分情況如圖3所示。

圖3 詞匯表拆分b桶
將詞匯表劃分為b個桶后,對于每個桶單獨統計就可減小H,而b的值是可變的。這樣即使詞匯表過大,也可以通過增大b縮小需要一次處理的詞匯表大小,從而使得stripe模式能應用至任意大小的詞匯表。
3.2 算法實現
分治可以通過在原有的stripe算法上增加一次預處理實現。預處理的功能即劃分詞匯表,代碼見表4。

表4 stripe算法預處理偽代碼清單
經過預處理后,數據集被劃分為b個子數據集(桶),其中第 i個數據集中只包含(wi,wj),hash(wj)mod b=i。對這b個數據集分別使用stripe算法計算共現矩陣。由于數據集根據wj劃分,可知每個數據集的計算結果都是最終全局共現矩陣的其中幾列,而數據集之間的計算結果無交集。因此只需要將各數據集的結果簡單合并即可得到全局共現矩陣,如圖4所示。
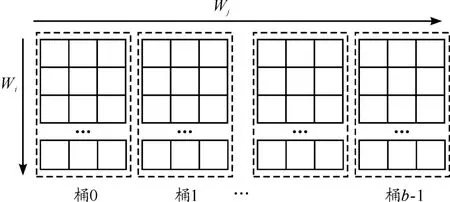
圖4 拆分為b個桶示意圖
4 實驗和結果分析
4.1 環境搭建
實驗中云計算平臺的結構:1臺機器作為NameNode和JobTracker的服務節點,其他8臺機器作為DataNode和TaskTracker的服務節點。每臺節點硬件配置如下:CPU型號為Intel(R)Core(TM)Duo T8300@2.40GHz;內存為 2GB;硬盤為2TB;基于hadoop-0.20.2版本構建集群。
4.2 實驗對照
為達到對照的效果,分別進行pair算法、stripe算法(下稱算法1)和分桶的stripe算法(下稱算法2)。算法2中,桶的個數分別為40和80個,取得的實驗數據如表5所示。
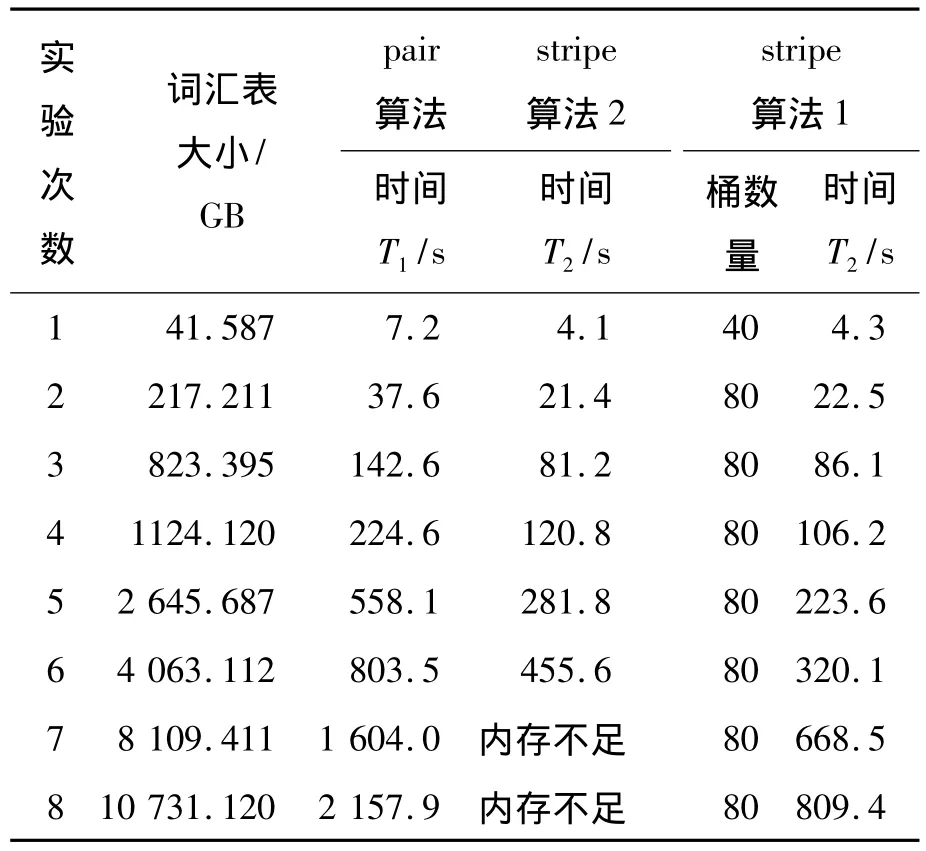
表5 對照實驗數據
從表5和圖5可以得出:pair算法較stripe算法性能差,并且隨著詞匯表的增加,其時間急劇增加,直至報內存不足;而stripe拆分算法(stripe算法2)較stripe算法1并沒有明顯的性能優勢,反而時間有所增加,原因是算法2增加了一個預處理階段,耗費了一定的時間;但隨著詞匯表的增大,算法2的優勢逐漸凸顯,海量的詞匯表時也沒有報內存不足,只是時間稍長,如果適當增加集群的大小,時間會有相當程度的降低。

圖5 對照實驗數據曲線
5 結束語
本文闡述了基于MapReduce模型的兩個并行算法:pairs和stripes算法。針對stripes模式在詞匯表很大時存在內存溢出問題,本文給出了劃分詞匯表的解決方法,對輸入詞匯表進行拆分,此過程也可利用MapReduce模型進行預處理。實驗數據證明利用MapReduce的并行性能較好地提高海量語料庫中詞類共現頻率統計的效率和性能。
上述算法可以進行改進,例如都可以應用combiner(Map階段產生的中間結果合并)。對于stripe算法,應用combiner算法很簡單,效率也很高,只需要合并關聯數組即可,且合并的步數不會超過語料數據詞匯表的尺寸(因為需要合并的關聯數組元素數不會超過語料數據詞匯表的尺寸);而pair算法的合并工作量就大很多,它只能合并那些具有相同(w,u)值的((w,u),1)對,而(w,u)的可能取值通常很多。
這兩種算法都可以應用mapper內合并。無論具體做法是什么,有一點與使用combiner相同:pair算法產生的中間結果key-value對在key的取值范圍內呈現稀疏分布的特征,因此即使對其應用局部合并,能真正合并的項也是很少的。另外,(w,u)的可能取值非常大,也使得pair應用mapper內合并時很有可能遇到內存不足的問題。of Computer and System Sciences
[1]Jimmy Lin,Chris Dyer.Data-Intensive Text Processing with MapReduce[J].Morgan & Claypool Publishers,2010(7):26-28.
[2]馮志偉,自然語言處理的歷史與現狀[J].中國外語,2008(1):14-22.
[3]楊代慶,張智雄.基于Hadoop的海量共現矩陣生成方法[J].現代圖書情報技術,2009(4):23-26.
[4]Apache Hadoop,Hadoop[EB/OL].[2011 - 02 - 15].http://hadoop.apache.org.
[5]Hadoop MapReduce[EB/OL].[2008-12-16].http://wiki.apache.org/hadoop/HadoopMapReduce.
[6]Tom White,Hadoop.The Definitive Guide[Z].OReilly Yahoo Press,2ndedition.
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
意林(繪英語)(2017年5期)2017-05-15 02:17:23
