應用半連接的分布式數據庫查詢優化算法
2013-09-18 05:32:32李川
重慶理工大學學報(自然科學) 2013年11期
李 川
(西安航空學院計算機工程系,西安 710077)
隨著信息技術的高速發展,數據庫技術已經廣泛應用于當今社會的各行各業。特別是在生物學、農林業等領域,需要調查研究的數據量大,而且每個數據元組又包含了大量的屬性。對于這些數據,各研究機構研究的內容和方向不盡相同。如何將這些數據做到既邏輯統一又合理分布是一個非常重要的問題。分布式數據庫是物理上分布而邏輯上統一的系統。
將大規模數據(包括大規模關系或大規模元組)的數據庫建立成分布式數據庫系統,由于分布式數據庫的分布性和冗余性使得數據查詢操作變得復雜,因此如何提高查詢效率成為分布式數據庫研究的重要問題。本文針對大規模數據元組或較多記錄的數據,建立分布式數據庫模型,詳細分析了分布式查詢處理的目標、數據分片體系結構、查詢優化方法及改進策略。
1 分布式數據庫查詢優化目標
分布式數據庫不同于集中式數據庫,查詢處理除了考慮CPU代價和I/O代價之外,還應包括數據在網絡上的傳輸代價
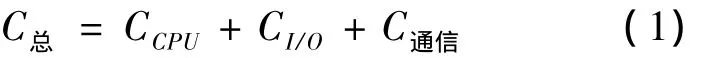
通信代價估算公式為

其中:C初為初始化的時間,單位為s;R為傳輸率,單位為 bit/s;X為需要傳輸的數據量,單位為 bit[1]。
分布式數據庫系統的查詢優化有2個準則[2]:一種準則以總代價最小為標準,例如在廣域網分布式數據庫系統中,忽略CCPU+CI/O,只考慮C通信;另一種準則以每次查詢的響應時間最短為標準,一般應用在高速局域網分布式數據庫中。
總之,分布式查詢優化的準則是使通信費用最低和響應時間最短,即以最小的代價在最短的響應時間內獲得需要的數據[3-4]。具體采用哪種準則需要根據具體的分布式數據系統網絡結構而定。
2 分布式數據庫數據分片
2.1 分布式數據庫數據分片機制
數據分片是分布式數據庫的重要特性。數據分片把關系按照用戶需求有效劃分成若干個片段,這些片段可以分布在不同站點上,但在邏輯上是一個整體。常見的分片方式為水平分片和垂直分片。水平分片是將關系按行橫向以某種條件分為若干個子集;垂直分片是將關系按列豎向分為若干個子集。實際劃分時采用水平分片或是垂直分片根據用戶需求及網絡的情況具體而定。在本文的應用中,一種植物的數據記錄規模較大(超過104條),且數據元組規模也較大(超過200個屬性列),由于各個研究機構研究的內容及側重點均不同,因此不能單純地采用水平分片或垂直分片,而應采用一種混合型的改進算法。
2.2 改進的分片機制
數據冗余可提高數據的可靠性和查詢效率。首先,為保證數據可靠性,將所有數據存放在一個數據庫,形成一個統一全面的數據庫,該數據庫為備用數據庫。因為其數據規模較大,查詢效率低,故一般不直接在該庫中進行查找,將存放該數據的站點稱為備用數據庫站點;然后,根據植物的數據結構特征和研究機構的需求進行水平分片;最后,將水平分片得到的片段分別進行垂直分片。分片結構如圖1所示。
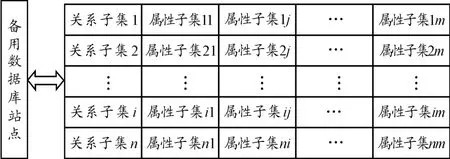
圖1 帶有冗余的大規模數據分布式數據庫分片結構
3 基于半連接的查詢優化算法研究
3.1 分布式數據庫數據查詢方法
分布式數據庫查詢過程一般分為4個步驟:查詢分解、數據本地化、全局優化和局部優化。其中全局優化和局部優化是2個可以明顯提高查詢效率的過程。局部優化是在各站點的數據查詢,該過程和普通集中式數據庫的查詢優化方法相同,故在此不再討論。
在全局優化階段,各個站點間的連接運算是產生代價的主要操作。而關于如何處理連接操作,以往的研究提出很多種算法,主要分為基于半連接的查詢優化算法和基于直接連接的查詢優化算法兩大類。
基于直接連接的查詢一般多用于高速局域網中。由于局域網的網絡傳輸速度很快,因此可忽略數據傳輸的代價。所采用的方式為一次將所有數據傳輸,然后再進行查詢。
基于半連接的查詢常用于廣域網環境下。廣域網一般傳輸速度有限,所以減少2個站點進行連接時的傳輸代價是半連接查詢優化的關鍵。通常2個站點間需要2次以上的數據傳輸,但總的數據傳輸量遠小于傳輸整個關系的數據量。其基本原理是:在進行連接之前,先根據需求消除與連接無關的數據,減少作為連接的數據量,從而減小通信代價。雖然在連接之前所做的消除與連接無關數據的操作也會增加額外的代價,但與減小通信代價相比,還是很小的。
本文主要針對大規模數據廣域網分布式數據進行庫查詢優化,所以重點研究基于半連接的查詢優化。
3.2 改進的半連接查詢優化算法
3.2.1 一般的半連接查詢方法
半連接是投影和連接組成的一種關系代數運算。假設R1、R2是2個關系,分別位于站點S1、S2,而屬性A1、A2分別在R1和R2上,半連接操作可表示為
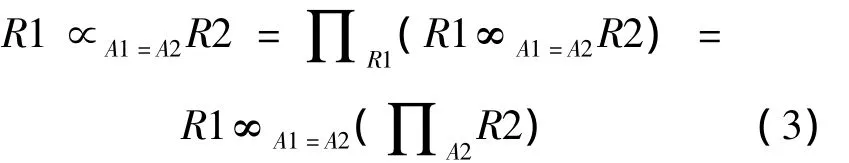
連接操作可表示為:
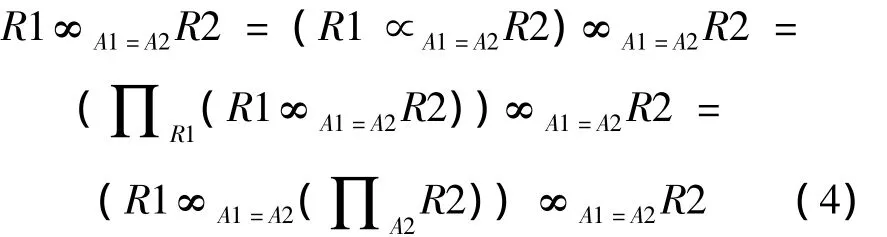
其中:∞表示連接操作,∝表示半連接操作,∏表示投影操作。
直接連接是將站點S2中的所有關系R2一次傳輸給站點S1,而半連接的執行過程如表1所示。

表1 半連接執行過程
在廣域網分布式數據庫系統中,只考慮通信代價,再次忽略網絡的差異性,即式(2)中的C初和R都一樣。下面根據式(2)計算比較使用直接連接和使用半連接方法實現的代價。
使用直接連接方法:
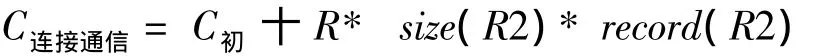
其中:size(R2)為R2元組的長度;record(R2)為R2的總記錄數。
根據表1,使用半連接需要傳輸2次數據,分別為:
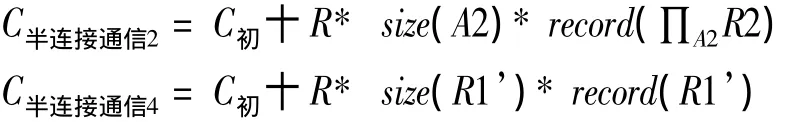
其中:size(A2)為關系R2中A2屬性的長度;record(∏A2R2)為關系R2中屬性A2上投影運算后的記錄數;size(R1’)為關系R1’元組的長度,即R1的長度;record(R’)為關系R1’的記錄數。
半連接的總代價為

在大規模數據記錄多字段的數據庫結構下,容易得出
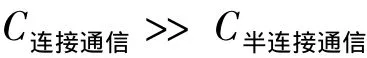
因此,在廣域網中通過半連接的查詢方式可大大減小通信代價。
3.2.2 改進的半連接查詢優化
在一般的半連接查詢中,連接代價主要是2次傳輸的代價。其中的第一次傳輸,即由站點S2將∏A2R2從S2傳輸到站點S1,因為只有一個屬性,所以相對于大規模數據而言其傳輸的數據量較少;第二次傳輸,即由站點S1將R1’傳輸到站點S2,需要傳輸的數據元組長度為R1的長度,記錄個數為R1’的記錄數。這樣,當R1長度很長,R1’記錄很多時,該次傳輸的數據量仍然相當大,即帶來了較大通信代價。由此提出一種改進的半連接查詢方法。
首先,介紹改進半連接查詢中涉及到的幾個概念和理論。
定理1 連接運算的交換律。
假設有關系 R1和關系 R2,那么 R1∞R2=R2∞R1,即連接運算滿足交換律。
定義1 關系元組比Rsize。
假設有關系 R1和關系 R2,那么 Rsize=size(R1)/size(R2),稱為關系R1和R2的關系元組比。
定義2 關系記錄比Rrecord。
假設有關系 R1和關系 R2,那么 Rrecord=record(R1)/record(R2),稱為關系R1和 R2的關系記錄比。
定義3 關系數據比Rdata。
假設有關系R1和關系R2,那么Rdata=Rsize*Rrecord,稱為關系R1和R2的關系數據比。
由于關系R1的記錄數和R1’的記錄數一般情況下是成正比的,所以可認為:
當Rdata>1時,即站點S1上的數據量大于站點S2上的數據量;
當Rdata<1時,即站點S1上的數據量小于站點S2上的數據量;
當滿足第2種情況時,采用一般的半連接方法是比較合適的,但當滿足第1種情況的時候,顯然采用一般半連接的傳輸代價較大。由于連接運算滿足交換律,所以可將傳輸的內容改為將R2’從站點S2傳輸到站點S1,由此降低了傳輸代價。改進的半連接查詢算法過程描述見表2。

表2 改進半連接查詢算法過程
3.2.3 算法性能比較
假設關系R1和R2的關系結構如表3所示。

表3 關系結構
根據表3得關系數據比為2,按照改進的半連接查詢,計算所需數據如表4所示。
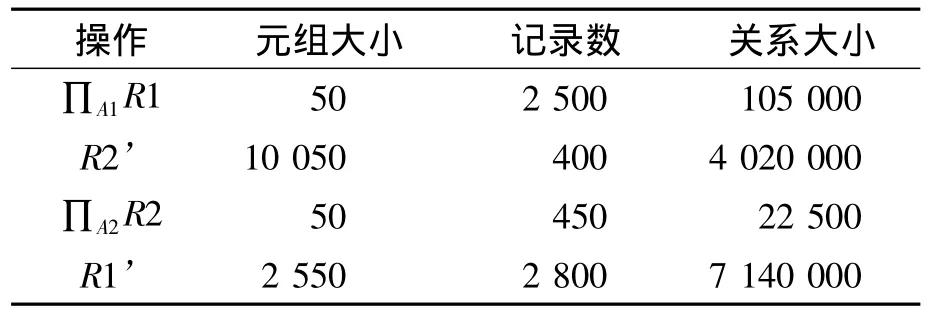
表4 改進半連接查詢計算數據
由此可以得出2種算法的代價。
一般半連接查詢代價:
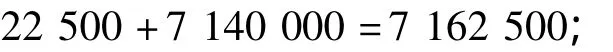
改進半連接查詢代價:
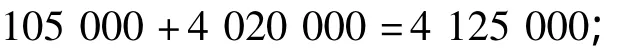
改進半連接查詢算法在數據傳輸之前,先進行數據關系大小比較(比較所產生的代價可忽略),保證了實際傳輸數據比較小,從而降低了傳輸代價。
4 結束語
本文主要分析和研究了分布式數據庫的特點、查詢優化目標、數據分片機制、查詢優化的算法等。提出了在廣域網中大規模數據的分布式數據庫改進的數據分片模型及改進半連接查詢算法。通過實例分析表明:改進半連接查詢算法極大地降低了傳輸代價,提高了查詢效率。
由于本文提出的改進半連接查詢優化算法是基于廣域網的大規模數據,因此在高速局域網或者數據規模不大的情況下該算法并不適用。在進行連接操作時,當要連接的2個數據關系大小差異較大時,采用該算法較適合,反之使用該算法意義不大。另外,本文認為在某一關系上投影操作之后,關系記錄數與原關系記錄數成正比,這在有些情況下是無法滿足的,因此也會對改進算法帶來負面影響。
[1]石小艷.分布式數據庫中的查詢策略與查詢優化[J].計算機與網絡,2010(30):244-245.
[2]姜愛福,李長云.分布式查詢優化的技術實現[J].計算技術與自動化,2005(1):72-74.
[3]陳鐘.一種改進的分布式數據庫查詢優化算法[J].計算機應用,2008(28):233 -235.
[4]陳世保.基于直接連接的分布式數據庫查詢優化實現方法研究[J].計算機時代,2011(7):17-20.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
