基于聲韻拼接的中文孤立詞語音識別方法的研究
2013-09-30 06:39:40張志楠李琳琳賈玉輝
中國信息化·學術版 2013年6期
張志楠 李琳琳 賈玉輝
[摘要]本文提出了一種基于HTK搭建的中文孤立詞語音識別系統的方法,系統采用中文特有的聲韻拼接結構作為建模基元,通過頻譜歸一化處理(Cepstral Mean Normalization,CMN)之后一定程度上提升了識別準確度,并且結合三音素(Triphones)的狀態綁定(Tied-State)策略又給出一種詞表的自動更新過程,可以針對任意給定的詞表做識別,在一定程度上實現了識別詞表的可定制性。
[關鍵詞]語音識別;頻譜歸一化;三音素;狀態綁定;
[中圖分類號]G71 [文獻標識碼]A [文章編號]1672-5158(2013)06-0325-02
目前,現已發行的HTK穩定版是3.4。本系統即是在其基礎上來搭建。可以方便有效的建立及操作HMM。HMM已經被廣泛地應用在了諸多的科研領域,比如AI(Artificial Intelligence,人工智能)和生物工程,HTK也主要針對智能語音技術的應用及研究而設計。
本系統是針對所有的中文詞匯能夠做識別,這種識別過程是基于三音素(Triphone)的自動拼接過程,因此,我們設計了一個詞庫,包含403個中文詞匯,覆蓋了所有的聲韻拼接,并且我們借助HTK的輔助錄音工具來采集足夠的語音數據用于模型訓練。此外,為能夠使得識別系統能夠針對不同的采樣率做識別,又特別加入了一種采用率下采樣(Downsampling)自動轉換機制,以使得系統能夠針對待識別語音做采用率自動轉換識別的功能。
1 聲韻母基元
1.1 模型基元定義
模型識別基元的選擇對于語音識別率以及訓練數據量的大小都有較大的影響。音素(Phoneme)、聲韻母(Initial/Final)、音節(Syllable)、整詞(Word)都是中文語音識別中常用到的建模單元,漢語中有409個無調音節和1300多個有調音節。
采用聲韻母建立聲學模型是相對比較合適的,特別說明本文中使用的問題集是基于語音學知識的。基于音素(Phoneme)的語音識別已經被廣泛地應用在英文識別中并且取得了很好的識別性能。本文所采用的基元集是由37個韻母,24個聲母和1個靜音模型共同組成,參見(表1):
2 基于Triphones模型的自動拼詞識別機制實現
2.1 原理介紹
首先解碼原始音頻數據進行識別,得到初步的單音素以及前后階音素的關系,然后依據得到的這種上下文依賴關系,查找其對應的映射文件,進而確定相應的三音素模型。再根據這種聲韻拼接信息,通過查找Triphone模型的上下文相關模型映射文件生成了最終的全詞匹配結果。
2.2 實現過程
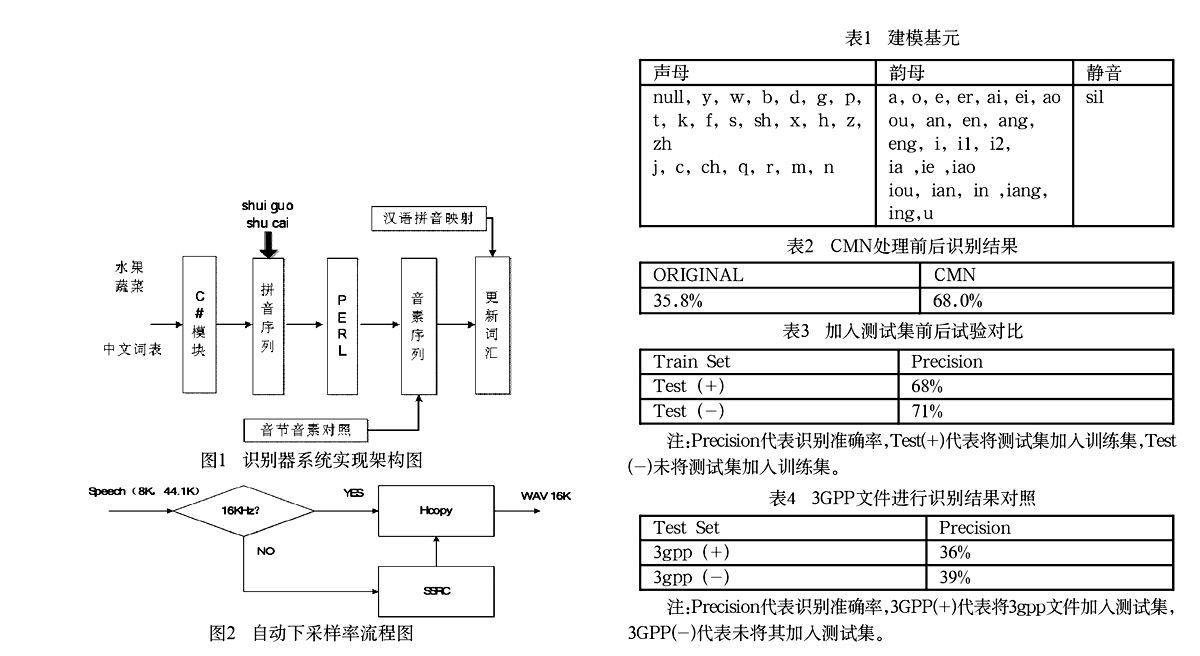
該模塊旨在實現待識別詞匯表的自動更新識別功能。整個識別過程是不需要重新訓練的。之前已經完成了漢字轉拼音的轉換程序,在此基礎之上又進—步實現了系統自動拼詞的機制。其目的在于允許用戶傳送詞匯表(并不在訓練集當中),自動做拼接識別。
處理結束后,還要調用自動映射處理模塊將用戶傳過來的新詞匯表映射到已存在的詞表當中,并相應的標出漢語,以便于在反饋用戶結果的時候將拼音對應的漢語一并反饋給用戶(圖1)。
3 HTK上實現Downsampling自動轉換機制
3.1 原理介紹
通過修改功能模塊,我們將SSRC自動采樣率的轉換功能嵌套在HTK當中,實現了下采樣的自動轉換功能,前端采樣自動檢測準確與否,直接影響到語音識別系統的識別性能。
3.2 實現方法
該模塊提供一種采樣速率自動轉換機制,用于提高最終的語音識別率。首先,我們需要引入一個新的開源工具包SSRC,其功能是實現采樣率的自動轉換。通過做SSRC使測試語音與訓練時語音采樣速率保持一致,也是優化識別系統整體識別性能的一種方法,進一步減少因為采樣率不一致而導致的誤識率(圖2)。
整體的采樣率自動轉換功能模塊參照下面步驟運行:
對從客戶端采集到的聲音文件進行初步的判斷,采樣率是否滿足系統的要求,如果上圖第一次判斷走了“NO”分支,要接著進行SSRC的采樣率自動轉換,統一將從客戶端采集到的聲音文件的采樣率標準化;然后,抽取相應的Mel頻譜參數(MFCC),再將特征參數傳人識別系統的核心模塊Recognizer,得到識別結果。
4 實驗結果
本實驗采用的訓練數據是由12個人借助HTK錄音工具共同錄制的包含4200個詞條的語音庫。測試數據集是由三個人采用平板電腦錄制的30個連續發音詞條(每人10條)。然后又通過CoolEdit工具[9]將其手工切分為彼此分離開來的詞條,即每一個單獨的詞匯保存與一個獨立的WAV文件中,然后對所有這些WAV片段做識別(表2)。
由上面結果容易看出,CMN可以大大提升識別系統的識別性能。倒譜均值歸一化算法(CMN)對于語音識別系統抗噪聲性能的提高十分有效。接下來,我們將測試語音經過SSRC做采樣率自動轉換,都同一轉換為16KHz,然后將錄音測試詞(2/3)加入訓練集。剩余1/3做集外測試,并重估參數,得出的實驗結果如(表3):
①在未將測試詞加入訓練集,并作CMN,SSRC:識別結果18/28=68%
②將測試詞加入訓練集,并作CMN,SSRC處理:識別結果20/28=71%
③將測試詞加入訓練集,并作CMN處理,采樣率按照初始(44100HZ),未作SSRc處理:識別結果很低,基本不能識別。另外,以上是針對原始音頻格式wAV所做的識別結果。而對于3GPP音頻文件的識別結果準確度卻比較低(圖4):
由以上實驗結果可以看出,本識別系統對于3gpp格式的媒體文件尚不能夠有很好的識別率,因此,綜上所述本系統目前對3GPP格式的識別相對較低(39%),而對WAV格式的音頻支持相對較好(71%)。
5 結束語
本文依照中文發音的特性,選取了擴展的聲韻母基元XIF作為識別基元,問題集的設計也建立在當今中文語音學知識體系架構之上,再結合基于Triphones的模型訓練,得到了一個可以自動按照中文聲韻拼接規則對任意詞匯做識別,與其它識別基元作對比。借助決策樹以Triphones模型來共同搭建語音識別系統,能夠有效地降低其對于識別階段所帶來的負面影響,并且提升了識別器對于識別環境的魯棒性。
