基于神經網絡和遺傳算法的瓦斯含量預測研究
2013-10-22 06:55:22王富軍
山西煤炭 2013年2期
關鍵詞:模型
王富軍
(大同煤炭職業技術學院,山西 大同 037003)
瓦斯爆炸是煤礦生產中最嚴重的災害之一。由于煤層瓦斯含量的復雜性、動態性、非線性、隨機性,給煤層瓦斯含量的預測帶來很大困難。許多學者利用神經網絡等理論和方法建立了不同的預測模型[1-2],例如遼寧工程技術大學付華教授的基于BP網絡和D-S證據理論的瓦斯監測系統[1]。基于此,以同煤集團馬脊梁礦某煤層為研究對象,分析影響煤層瓦斯含量的煤層埋藏深度、煤層厚度、頂板巖性、上覆基巖厚度、頂板30 m砂巖比等因素的基礎上,建立神經網絡模型,并將神經網絡與遺傳算法結合,以神經網絡能準確提取、捕捉煤層瓦斯含量與各影響因素之間的非線性關系,又靠遺傳算法能夠尋求各個因素之間的最優解,可實現礦井內煤層瓦斯含量的預測。
1 神經網絡模型的構建
煤礦瓦斯含量涉及的因素較多,各參數之間耦合性較強,為了提高瓦斯含量預測精度,采用有非線性和自學習能力的神經網絡作為主要預測方法,采用具有優化能力的遺傳算法作為解決數據優化問題,并尋求瓦斯含量預測值最優。本文利用神經網絡和遺傳算法的優點,構建瓦斯含量預測模型。
1.1 神經網絡理論
神經網絡一般包括:輸入層,中間層(隱層),輸出層。見圖1。

圖1 神經網絡原理圖
本文采用反向傳播算法 (Back Propagation Algorithm,簡稱BP算法)作為神經網絡模型的預測。BP算法包括兩個過程,一是從輸入層輸入的信息經過各隱層(隱層1,隱層2,…,隱層n)預測,最后從輸出層輸出。二是誤差等信息從輸出層反向經過各隱層(隱層n,隱層n-1,…,隱層l),反饋到輸入層。本文輸出層采用Sigmoid函數作為輸入神經元函數,即f(x)=ex/(ex+1)。其中,誤差在反向傳輸過程中,實現各種學習[2]。神經網絡輸入層包括5個節點(煤層埋藏深度、煤層厚度、頂板巖性、上覆基巖厚度、頂板30m砂巖比)。神經網絡輸出層只有一個節點(瓦斯含量預測值)。
假設選取的樣本數足夠大,有N個樣本點(xK,yK)(K=1,2,…,N)。任意樣本點的輸入值xK經過模型后輸出的實際值為dK,理想值為yK,dK與yK間的誤差期望為:

其中,(yk-dk)=Ek為單個樣本的學習誤差。假設神經元輸入節點j的輸入值為netjK,神經元輸出節點i的輸出值為OiK。根據多維神經網絡原理,netjK=ΣWijOik,則Ojk=f(netjK)。在k樣本下,取δjk為神經元輸入節點j的輸出梯度,則OiK=dk。
如果節點j不是輸出層節點時,這時,

1.2 遺傳算法原理
遺傳算法是模擬生物界優勝劣汰的自然法則而建立的一種全局搜索算法[3]。利用遺傳算法優化,主要是對BP神經網絡中的誤差權值進行優化。具體步驟如下:
1)初始化種群,利用BP神經網絡的誤差權值,算得特定種群。
2)利用神經網絡模型算得個體的自適應度值。
3)經選擇、交叉、變異等操作,產生下一代種群。
4)得到的下一代種群是否滿足結束條件;若否則轉2),若是則轉 5)。
5)選取經過遺傳算法模型得到的最優個體,反向操作后,取代神經網絡模型中對應的權值,結束遺傳算法。
2 瓦斯含量的預測
基于神經網絡和遺傳算法的瓦斯含量預測模型流程圖,見圖2。
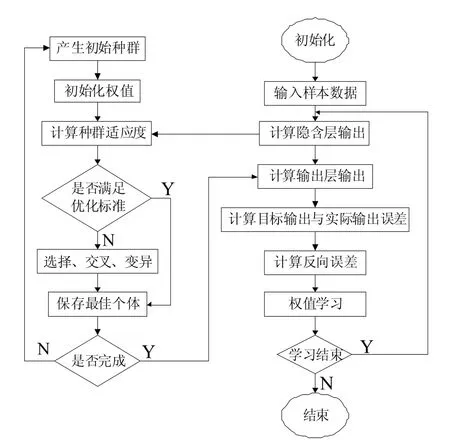
圖2 瓦斯含量預測模型的流程圖
1)計算實例。為了計算模型預測瓦斯含量預測方法的準確性及可靠性,選擇馬脊梁礦生產實際中的瓦斯含量進行預測。馬脊梁礦年產500萬t、兩個開采煤層,瓦斯鑒定級別為低沼氣礦井,局部瓦斯異常。通過構建的神經網絡和遺傳算法優化得到的數學模型,預測結果如表1和表2所示。

表1 瓦斯含量預測

表2 預測結果與真實值比較
2)采用基于神經網絡和遺傳算法的瓦斯含量預測方法,平均誤差值分別為 0.43、1.48、0.82、0.5、0.51,平均誤差為5.61%,低于國家8%的要求。其中誤差低于8%的數據占全部數據的80%。可見,預測效果比較好。
3 結論
由于各礦區的地質構造及礦井的煤層賦存情況的差異性,導致瓦斯含量的主控因素也不相同,瓦斯含量的預測必須針對特定環境構建特定模型。本文構建了以煤層埋藏深度、煤層厚度、頂板巖性、上覆基巖厚度、頂板30m砂巖比等5個參數為輸入量,瓦斯含量為輸出量的神經網絡模型,并結合所建模型,采用遺傳算法對神經網絡模型進行優化計算。試驗結果表明,煤層瓦斯含量預測效果,應用前景良好。
[1]付華,康海潮,梁明廣.基于BP網絡和D-S證據理論的瓦斯監測系統的研究[J].工礦自動化,2011,37(8):159-161.
[2]王鶴,邵良杉,邱云飛.基于蟻群神經網絡的煤礦瓦斯含量預測煤礦瓦斯含量預測模型[J].微計算機信息,2011(5):197-198.
[3]崔小彥.基于RBF神經網絡與蟻群算法的瓦斯預測模型研究[D].阜新:遼寧工程技術大學,2009.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
