Hadoop副本放置策略
2013-11-26 01:50:32邵秀麗王亞光李云龍劉一偉
智能系統學報 2013年6期
關鍵詞:策略
邵秀麗,王亞光,李云龍,劉一偉
(1.南開大學 信息技術科學學院,天津300071;2.北京大學數學科學學院,北京100871)
為提高系統的可靠性,解決不可預知的災難以及硬件錯誤對系統造成的損失,云存儲系統采用分布式副本技術來存儲數據.
哥倫比亞大學的Ko等[1]提出了一種自穩定、全分布、異步可升級的算法來放置副本,算法的目標是在網絡中的結點上放置數據對象的多個副本,從網絡中的任意一個結點出發都能夠通過最短的路徑訪問到任意的副本;加州大學伯克利分校的Chen等[2]開發設計了一個動態、高效及可升級的內容分發網絡SCAN(sealable content aeeess network).SCAN 采用Testry進行路由和定位,使用沿路緩存算法進行副本放置;德克薩斯大學的MadhukarR等提出了一種協作的緩存放置算法[3],即給定一組協作的緩存、緩存之間的網絡距離以及從每個緩存到每個對象的訪問頻率的預測,決定在哪里放置對象,從而使平均訪問開銷最小化;Karger等[4]提出了能適應節點數量的動態變化的一致性哈希算法,但它只適用于存儲節點同構的情況,當節點的存儲容量和處理能力有差異時,數據將不能夠均勻地分布到系統當中.
云存儲系統的典型代表是Hdfs[5],它需將每個存儲數據塊的副本放置在多個機架的多個節點上,存儲數據塊的副本放置策略將直接影響數據存儲的均衡性以及訪問數據塊的速度.Hdfs系統采用隨機選擇節點的副本放置策略,該策略在系統運行一段時間后會造成數據分布不均衡的問題,降低數據的可靠性和讀取性能.因此,本文提出了基于節點使用率選擇存儲節點的Hdfs副本放置策略的改進算法,引入了客戶端存儲閾值,允許副本在放置過程中穿越多個機架,以實現各節點數據存儲的相對均衡,實驗驗證了改進策略的有效性.
1 副本放置策略的相關概念
內容為研究Hdfs的副本放置策略,先介紹相關概念如下:
1)獲取集群信息:Hdfs的NetworkTopology類實現對其拓撲結構的操縱,該類中包含添加、刪除和獲取節點信息等函數.比如,Hdfs通過調用NetworkTopology類的chooseRandom來隨機獲取一個節點的信息,通過調用getNumOfLeaves來獲取所有節點的數目.
2)集群拓撲(機架與節點):將Hdfs部署在多臺服務器上就形成了一個Hdfs的集群.如樹狀拓撲結構的Hdfs集群,樹根是一個大型交換機,交換機之下可以是多個二級交換機,可以把每一個二級交換機設置為一個機架,每個機架之下連接多個節點.
Hdfs管理員可編寫腳本文件來配置每個節點屬于哪一個機架.在進行機架配置時,應將相同交換機下的節點設置為同一個機架就可實現合理的配置.
一般把組成Hdfs集群的每一個服務器稱為一個節點,對文件讀寫的客戶端而言,其所在節點稱為本地節點,其他節點為遠程節點.就某一具體節點而言,稱該節點所在的機架為本地機架,其他機架為遠程機架.
3)隨機函數:Hdfs的NetworkTopology類中有保存所有節點信息的ArrayList.Hdfs在選擇副本放置位置時,調用隨機選擇函數chooseRandom,從n中隨機選擇一個數對應ArrayList中的節點就被選中為副本存儲的節點.該函數是只有2個參數的重載函數,第1個參數是選擇節點的范圍,它可以是某個機架,默認為整個集群;第2個參數是不能選擇節點的范圍,默認為空,可以設置為某個機架.
4)Hdfs在進行副本選擇過程中,有可能出現參數不合格或內存異常等現象,一旦出現運行異常,chooseRandom函數就會把異常信息返回客戶端該函數的調用者.
2 Hdfs默認副本放置策略
如圖1所示,Hdfs的副本放置策略是將每一個數據項的副本放置在多個節點上.在客戶端運行的節點上放置第1個副本,在客戶端的遠程機架上隨機選擇一個節點放置第2個副本,在第2個副本所在機架上隨機選擇一個節點放置第3個副本.
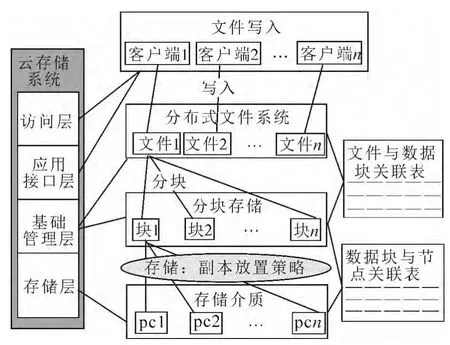
圖1 副本放置策略Fig.1 The placement policy of duplication
分布式文件系統[6-7]的副本放置策略確定每一個數據塊應該存放的位置,數據塊與節點之間的關聯被記錄在數據塊與節點關聯表中,數據塊最終會被存放在存儲層的各個節點上.
2.1 Hdfs默認副本放置策略的流程
Hdfs的分塊存儲文件在選擇副本放置位置時,綜合考慮了數據存儲的可靠性、數據讀寫的帶寬和負載均衡等因素.如將一個數據塊所有副本都存儲在一個節點上,則存儲過程中所占用的帶寬是最小的,因為這可以減少數據塊的網絡傳輸,但該方案不提供有效的冗余備份,一旦該節點發生故障,則該節點中存儲的這一數據塊及其所有副本都會丟失.因此,Hdfs對任意一數據塊不在同一個節點上放置多個副本,而是將副本盡可能分散存放[8-9].圖2給出了Hdfs默認的副本放置策略流程,其中標注了本文所實現的對副本放置策略的改進工作,Hdfs默認的副本放置策略選擇3個節點,可以選擇多個節點放置副本.
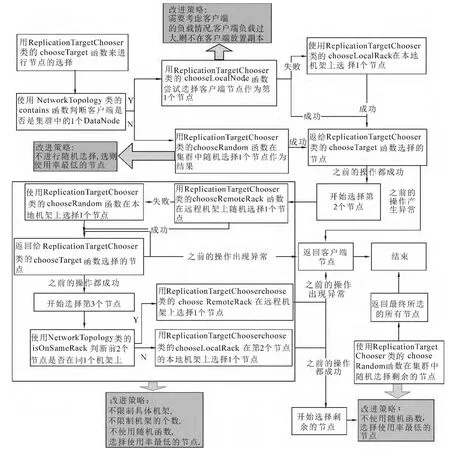
圖2 默認副本放置策略Fig.2 The flowchart of default replica placement
1)HdFs副本放置策略是調用ReplicationTarget-Chooser類的chooseTargrt函數來實現的.開始使用NetworkTopology類的contains函數,contains函數通過判斷客戶端所在根節點與集群的根節點是否一致來判斷客戶端是否在集群中.
2)如果客戶端是集群中的一個節點,則調用ReplicationTargetChooser類的 chooseLocalNode函數來嘗試選擇客戶端節點作為第1個節點.
3)客戶端存儲嘗試失敗時則調用ReplicationTargetChooserchooser類的chooseLocalRack函數,在客戶端節點所在機架隨機選擇一個節點作為第1個節點,然后將這個節點的信息傳給ReplicationTargetChooserchooser類中的chooseTargrt函數,且將這個節點的信息記錄在ReplicationTargetChooserchooser類中的一個DatanodeDescriptor類型的數組results中.
4)如果客戶端不是集群中的節點,則使用ReplicationTargetChooser類的chooseRandom函數在集群中隨機選擇一個節點作為第1個節點,且將這個選擇的節點記錄在數組results中.
5)ReplicationTargetChooser類的chooseRemoteRack函數在第1個節點的遠程機架上隨機選擇一個節點作為第2個節點.如果在遠程機架上選擇節點失敗,則使用ReplicationTargetChooser類的chooseLocalRack函數在第1個節點的本地機架上隨機選擇一個節點作為第2個節點.將第2個節點記錄在ReplicationTargetChooserchooser類中DatanodeDescriptor下的數組results中.
6)選擇第3個節點,如果前2個節點是在同一個機架上,則使用 ReplicationTargetChooser類的chooseRemoteRack函數在前2個節點的遠程機架上選擇一個節點.如果所選擇的前2個節點并不在同一個機架上面,則使用ReplicationTargetChooser類的chooseLocalRack函數在第2個節點的本地機架上隨機選擇一個節點作為第3個節點,且存儲第3個節點信息在數組results中.
7)最終將results中的所有節點返回給副本選擇函數的調用者.
2.2 Hdfs副本放置策略的缺陷
Hdfs默認副本放置策略綜合考慮了多方面的因素,在可靠性、讀寫效率,負載均衡方面都做了一定的權衡,是一個比較優秀的副本放置策略,但Hdfs采用隨機選擇的副本放置策略.該策略沒有考慮到節點負載的情況,在數據均衡方面比較薄弱,這使數據損壞時需要恢復的數據塊數量可能會很多,數據讀取的速度會受到影響等問題.
針對這一問題,Hdfs提供了解決方案——均衡器[10].均衡器(balancer)是一個Hdfs的守護進程,啟動之后,它會將數據塊從負載較高的節點移到相對空閑的節點,從而達到重新分配數據塊的目的,最終達到整個集群的數據塊分布均衡.在數據塊重新分配的過程中,均衡器會盡量將一個數據塊的復本分散到不同機架,以提高數據塊的冗余,降低數據損壞的可能性.
Hdfs集群的管理員決定是否啟動均衡器,啟動后,會根據管理員設定的閥值來對集群進行均衡處理.閥值是每個節點的使用率(該節點上已經使用的空間和節點的空間容量之間的比值)和集群的使用率(集群中已使用的空間和集群的空間容量之間的比值)之間的差值,默認的閥值是10%,管理員在啟動均衡器的時候,可以指定閥值的大小.在任何時刻,集群中只能運行一個均衡器.
均衡器雖然可以解決數據塊分布不均衡的問題,但是存在著明顯的問題:
1)均衡器對于集群數據塊均衡的調節具有滯后性,它必須要在系統的不均衡狀況超過閥值之后,才會進行調節.
2)均衡器的運行和數據塊的移動需要耗費一定的資源,很可能一個數據塊剛剛寫入到集群中,就因為均衡性而被移動,這種情況下集群的資源使用是很低效的.
3 Hdfs副本放置策略的改進
Hdfs默認的副本放置策略存在的不足,以及Hdfs提供的均衡器存在一些不盡人意的地方,本文提出了對其改進的低使用率優先(low rate first)副本放置策略.
3.1 改進副本放置的流程
圖3是副本放置改進策略的流程.
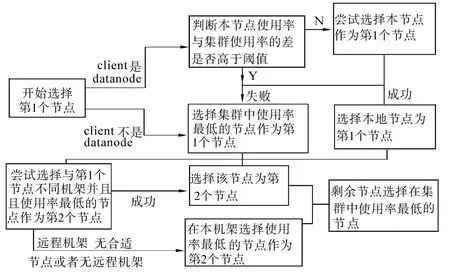
圖3 基于3副本放置策略的改進Fig.3 The improved placement strategy based on three replicas
1)考慮到數據寫入帶寬問題,依然在客戶端所在的節點上寫入第1個副本,但考慮了該節點的負載情況,即如果本地節點的負載超過了管理員指定的閥值,則選擇集群中使用率較低的節點來放置副本.
2)除第1個副本在閥值滿足的情況下放在本地節點上之外,其余所有的副本放置位置的選擇,都是采用優先選擇集群中比較空閑的節點的方式,以避免在負載較高的節點上繼續存儲數據.
3)為提高數據塊的冗余,盡可能地將數據存儲在至少2個機架上,本地機架上存儲第1個副本,第2個副本選擇與第1個節點不同的機架進行存儲.因為Hdfs是一次寫入、多次讀取的設計思想,在數據寫入的時候穿越多個機架,雖然寫入帶寬可能會有所降低,但是提高了集群的數據塊分布均衡,有利于文件的讀取和程序的運行.
4)為提高數據的冗余,保持每個節點只存儲一個副本的規則.Hdfs的默認副本放置策略是一個節點最多放置一個副本,如果副本的數量超過節點的總數,則集群中最多只放置與節點同樣數目的副本.低使用率優先的放置策略依然堅持這個原則,每個節點最多只放置一個副本.
盡管當發生故障時,此策略會影響恢復數據速度,而且每存儲一個副本時都需要調用函數獲取節點信息,并判斷該節點是否可以存儲副本,這會降低運行速度及安全性.但考慮到Hdfs默認放置策略的副本放置的最終狀態很難被控制,它在數據均衡方面的缺點比較明顯,而這會帶來一系列的問題,比如數據損壞時需要恢復的數據塊數量可能會有很多,數據讀取的速度可能會受到影響等因素,本文提出的對于Hdfs默認副本放置策略的改進方法有相對優勢.
3.2 改進策略實現的核心類
副本放置改進策略會優先考慮在使用率比較低的節點上放置數據,這通過對Hdfs中負責副本放置節點選擇的類ReplicationTargetChooser的改進來完成;該類在Hdfs中的作用是當有新增數據塊或數據塊位置變動的時候,NameNode會調用該類來確定數據塊放置的位置.ReplicationTargetChooser類使用chooseTarget函數來選擇副本放置的節點,圖4描述了放置k個副本重寫chooseTarget函數來實現的策略改進.
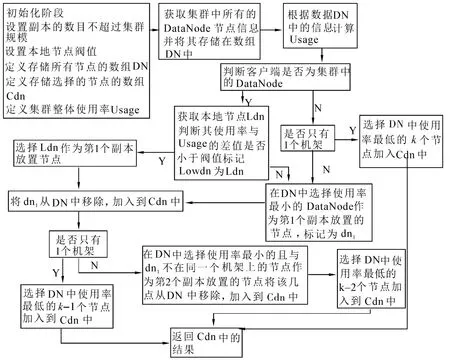
圖4 基于K副本放置策略的改進Fig.4 The improved placement strategy based on K replicas
1)函數的初始化階段:首先調用NetworkTopology類中的getNumOfLeaves函數來獲取集群的大小,控制副本數目不超過集群的大小,如果設置的副本的數目超過集群的大小,則設置副本數目為集群大小.
2)管理員可設置本地節點閥值,默認值為0.1,改進后的Hdfs在配置文件中為用戶設置閥值提供了接口,在 Hdfs.xml文件中可以通過為 dfs.replication.threshold設置值來實現閥值的控制,閥值的范圍在0~1,0表示本地節點的使用率必須小于等于集群的使用率才會在本地節點上放置數據塊的副本;1表示不考慮使用率,一定要在本地節點上放置數據塊的副本.
3)使用 Configuration類的getFloat函數配置文件中的閥值.但如果用戶沒有設置閥值或者設置的閥值不合理,chooseTarget函數依然使用默認閥值進行副本的選擇.
4)在重寫的chooseTarget函數中需定義一個DataNodeDescriptor類型的數組DN來存儲全部節點的信息,DataNodeDescriptor是Hdfs中用于描述DataNode信息的類,chooseTarget函數可以通過操縱DataNodeDescriptor的對象來獲取一個節點的信息,包括節點ID、節點名稱、節點全部存儲空間和節點已經使用的存儲空間等.另外,還需定義DataNode-Descriptor類型的數組results來存儲已選擇的節點,同時定義集群的存儲空間使用率Usage.
5)使用NetworkTopology類中的getLeaf函數可以獲取集群中所有節點的信息,將返回的所有節點信息存儲在數組DN中,然后可以根據DN中的信息計算集群的整體存儲空間的使用率Usage.在獲取所有節點信息之后,并不對數組DN進行任何處理,比如排序、建堆等.雖然考慮到后面的算法中需要多次取得DN中使用率最小的節點,但考慮客戶端和不同機架,因此該問題又與經典TopK問題相似且稍有不同.一般副本個數K默認為3,如果在客戶端上放置一個副本,選擇另外2個副本的計算復雜度為O(2N -3).
6)初始化后選擇節點,先通過Hdfs調用chooseTarget函數,使用NetworkTopology類中的contains函數判斷客戶端節點是否在集群中,如果不在,則不在客戶端上放置副本.否則還需進一步判斷客戶端節點的使用率與集群使用率的差值,如果差值小于閥值,則在客戶端上放置第1個副本,否則不在客戶端上放置副本.使用ReplicationTargetChooser類的is-GoodTarget判斷客戶端節點是否可用,才能確定是否在客戶端節點上放置一個數據塊.
7)如果客戶端不可用,則在DN中選擇使用率最低的節點來嘗試放置副本,如節點不可用,則將該節點標記為暫時不可選擇,然后繼續在其他節點中選擇一個使用率最低的節點,直到選擇到合適的節點為止.
8)機架數目對副本放置節點的算法有一定的影響,使用NetworkTopology類的getNumOfRacks函數來獲取機架的數目,則在DN中選擇一個使用率最小的節點作為第1個副本放置的節點.選擇第1個節點后,將其從DN中移除,加入到results數組中.
9)在選擇第2個節點的時候,在DN中選擇使用率最小的節點,然后使用 NetworkTopology類的isOnSameRack函數判斷它與選取的第1個節點是否在相同的機架上.如果這2個節點不在一個機架上,則選擇這個節點作為第2個副本存放的節點,否則,重新選擇DN中其他節點中使用率最小的節點,直到找到這樣的節點為止.選擇第2個節點之后,將其從記錄未被選擇節點的數組DN中移除,加入到記錄已選擇節點的數組results中.
10)繼續上述步驟選擇其他節點.
11)函數執行過程中,使用java中的try來嘗試運行,若chooseTarget函數的運行沒有出現異常,則最終將存儲已選擇節點的數組results返回給函數的調用者.若執行過程中出現不可處理的異常,則在catch語句中處理異常,返回客戶端節點.
4 實驗結果與分析
為了比較Hdfs默認的和本文改進的副本放置策略,本文實現了由2部分組成的測試程序:1)負責模擬一個節點運行的DataNode類,該類記錄了模擬節點的惟一標識、容量、使用量、數據塊數量以及機架標識;2)模擬系統運行的NameNode類,包括對于Data-Node的初始化、設置閥值、設置副本放置策略和數據寫入等內容的模擬.在模擬的過程中,并不進行真實的數據的讀寫,只是對于數據讀寫后的結果進行模擬記錄.在NameNode類中初始化所有的節點,每個節點初始的容量是1 T,used和blockNum被設置為0.該程序模擬寫入過程,設置寫入數據塊的大小和模擬數據的分塊.對于每一個劃分的數據塊,程序運行相應的副本放置策略函數,選擇3個節點用于放置劃分的數據塊.然后循環處理直到數據塊的寫入完成.
寫入所有數據后,可根據模擬節點的使用情況計算不同的副本放置策略的數據存儲均衡性.本文使用標準差來衡量副本放置的均衡性,所使用的數據是所有DataNode的使用率,也就是每個節點的使用容量used與總容量capacity之間的比值.設集群中一共有n個節點,所有節點的使用率分別為X1,X2,..,Xn-1,Xn.節點使用率的平均值X2+…+Xn-1+Xn)/n,標準差
本文實驗一測試了機架數目對于算法的影響,分別使用默認的策略和改進后的策略,模擬測試在500個節點上寫入大小不同的數據后,系統的存儲均衡情況,寫入文件大小為100 G條件下的節點使用率的標準差.
從圖5中可以看出,對于默認的副本放置策略,機架數目在3個以內的時候,機架的個數對于系統的均衡性會有一定的影響,但是差別在0.02%以內.當機架數目超過3個以后,機架數目對于系統均衡性的影響會在0.005%以內.而對于改進后的副本放置策略,機架的數目對于集群的均衡性影響會變得更小,在0.002%以內.所以,機架的個數對于2種副本放置策略的影響都很小.通過圖5可以看出,改進后的副本放置策略受到的影響更小,在不同機架個數情況下,都有更好的均衡性.
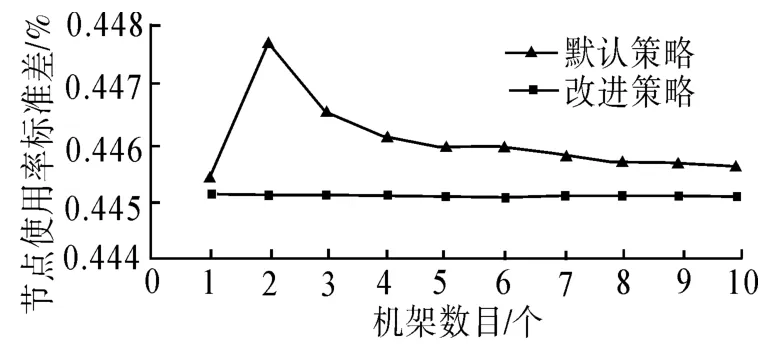
圖5 機架數目對于算法的影響Fig.5 The impact of the algorithm based on the number of rack
實驗二測試隨著寫入數據的增加,不同副本放置策略下集群存儲的均衡性.實驗選擇在500個節點、5個機架的條件下,分別使用默認的副本放置策略和改進后的副本放置策略,寫入 1 G、10 G、100 G、1 T、10 T和100 T的數據,測試集群的副本均衡情況.
根據圖6顯示,使用改進后的副本放置策略進行副本放置位置的選擇,集群中數據塊的均衡性明顯好于使用默認的副本放置策略,在數據量比較小的時候這種優勢還不太明顯,但是在數據量比較大的時候,改進后的策略的好處就會更加明顯.可見,改進后的副本放置策略,在數據塊的均衡性方面有更加良好的表現.
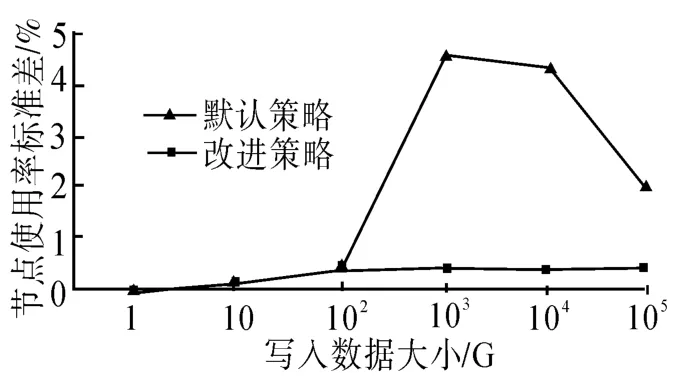
圖6 存儲數據量對于算法的影響Fig.6 The impact of the algorithm based on
本文提出的放置策略需獲取集群中所有節點的信息,且將其存儲在一個DataNodeDescriptor數組中,從而增加了時間和空間的開銷.另外要計算集群的整體使用率與選擇集群中使用率較小的節點,增加了線性的開銷.
5 結束語
本文基于節點存儲率對Hdfs中負責副本放置節點選擇的類ReplicationTargetChooser進行了改進,并部署了簡單實際環境進行了實驗,由于其實際環境受物理設備和其他異構條件等各種客觀因素的影響不大,所以,本文所提方案提高了Hdfs的數據塊放置的均衡性.但本文所提出的副本放置策略,關注的主要是集群中數據塊副本放置的均衡性,所考慮的因素主要是節點的使用率,而沒有考慮節點使用的價格、安全性、處理速度等.
[1]KO B J.Scalable service differentiation in a shared storage cache[C]//Proc of the 23rd International Conference on Distributed Computing Systems.Washington,DC,USA,2003:184-194.
[2]CHEN Yan.SCAN:a dynamic,scalable,and efficient content distribution network[C]//Proceedings of the International Conference on Pervasive Computing.Zürich,Switzerland,2002:282-286.
[3]KORUPOLU M R.Placement algorithms for hierarchical cooperative caching[C]//Proceedings of the Tenth Annual ACM-SIAM Symposium on Discrete Algorithms.PA,USA,1999:586-595.
[4]KARGER D,LEHMAN E,LEIGHTON T,et al.Consistent hashing and random trees:distributed caching protocols for relieving hot spots on the world wide web[C]//ACM Symposium on Theory of Computing.CA,USA,1997:654-663.
[5]BORTHAKUR D.The hadoop distributed file system:architecture and design[EB/OL].[2012-11-08].http://hadoop.apache.org/core/docs.
[6]GUY L,LAURE E,STOCKINGER H,et al.Replica management in data grids,GGF5[R].Global Grid Information Document,2002.
[7]STONEBRAKER M,ABADI D J,De WITT D J,et al.MapReduce and parallel DBMSs:friends or foes[J].Communication of the ACM,2010,53(1):64-71.
[8]魏青松,盧顯良,侯孟書.AdpReplica:自適應副本管理機制[J].計算機科學,2004,31(12):34-36.WEI Qingsong,LU Xianliang,HOU Mengshu.AdpRePlica:adaptive replica management mechanism[J].Computer Science,2004,31(12):34-36.
[9]楊曙鋒.分布式并行文件系統的副本管理策略[D].成都:電子科技大學,2003:23-31.YANG Shufeng.The Copies’management strategy of distributed parallel file system[D].Chengdu:University of Electronic Science and Technology of China,2003:23-31.
[10]BORDAWEKAR R,LANDHERR S,CAPPS D,et al.Experimental evaluation of the Hewlett-Packard Exemplar file system[C]//ACM Sigmetric SPerformance Evaluation Review.[S.l.]1997.
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:42
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:10
數學大世界(2018年1期)2018-04-12 05:39:14
幸福(2017年18期)2018-01-03 06:34:53
中國衛生(2016年8期)2016-11-12 13:26:50
