最小權重有向頻繁子圖挖掘
2013-11-26 07:11:20任威
鐵路計算機應用 2013年7期
任 威
(鐵道部經濟規劃研究院 經濟管理咨詢部,北京 100038)
面對海量的圖數據時,挖掘滿足最小支持度的頻繁子圖是人們感興趣的。當前圖挖掘的熱點在于有向圖,即在大量的有向頻繁圖中挖掘出一種性質更優的圖。本文介紹一類特殊的頻繁子圖—最小權重有向頻繁子圖,它滿足最小支持度閾值,并且所包含的邊和頂點的權重之和在所有同構子圖中是最小的,本文提出的挖掘方法用于處理此類頻繁子圖,在廠區鐵路運輸分析研究中有實際應用。根據廠區鐵路分布規模小、運輸密度高的特點,用加權有向圖表示某廠區鐵路線路網結構,不同標記頂點表示不同類型的車間,不同標記的有向邊表示不同的廠區鐵路線,頂點和邊的權重表示對應的運輸成本,權重越小成本越小。權重之和最小的子圖是運輸成本最小的廠區鐵路網結構,是在海量路網結構中要尋找的目標。
關于挖掘頻繁子圖的算法可以分為兩部分:(1)寬度優先算法(BFS),采用apriori性質枚舉出現的子圖以保證滿足最小支持度,有代表性的是AGM[1]和FSG[2]兩種算法,分別針對頂點和邊進行擴展,但會產生大量復制圖,效率不高。(2)深度優先算法(DFS),包括gSpan,FFSM和GraphGen等,通過擴展頻繁邊來逐步得到頻繁子圖。Han和Yan提出的gSpan[3]對標記圖進行挖掘,但無法避免子圖同構測試,FFSM算法[4]巧妙地將子圖擴展問題轉化為矩陣操作,降低了算法復雜度。GraphGen算法[5]運用圖論理論,將子圖擴展轉化為子樹擴展,進一步提高了算法效率。
以上是無向圖的挖掘,Li Yuhua等人提出的mSpan[6]針對有向圖進行挖掘,收效良好。Masaki Shinoda等人提出的GWF-mine算法[7]考慮了權重因素,將其作為挖掘條件。
針對廠區鐵路運輸線路結構的研究,挖掘的是既帶有方向標識,也帶有權重的圖數據。本文提出的算法針對此特殊圖數據集進行挖掘,達到了預期目的,在第1種算法基礎上,提出了第2種改進算法。
1 基本概念
定義1(子圖):設G=(V, E)是一個圖,設V'?V和E'?E,若對E'中任意一條邊eij={vi, vj},都有vi∈N'和vj∈N',則稱G'=(V', E')是G的一個子圖。
定義2(子圖同構):設圖G=(V, E)和G'=(V', E'),若存在一一映射g:vi→v'i,且e={vi,vj}是 G的一條邊,且僅當e'=(g(vi),g(v'i))是G'一條邊,則G與G'同構。
定義3(圖規模):有向圖中節點與兩個節點之間單個或成對有向邊(計數為1)的數量和。
2 最小權重有向頻繁子圖挖掘算法
本文提出兩種算法,第1種算法WDSpan先挖掘出頻繁子圖,再考慮權重,采用鄰接矩陣比較法篩選最小權重頻繁子圖。第2種算法MWD以加入權重的支持度閾值作為挖掘和剪枝的條件,通過同構測試和平均權重的比較更新,既保證了結果的正確性和完整性,又減少了存儲空間,起到了改進效果。

圖1 權重有向例圖
2.1 WDSpan
采用gSpan算法框架,定義最右頂點,最右路徑,前向邊和后向邊,前向擴展和后向擴展以及最右擴展[5],核心是深度優先方法,搜索最小DFS編碼,稱為基本下標,記為dfs(s)。
對圖1進行DFS標記,頂點間存在單向和雙向邊,對不同的邊給予不同的標記,以0代表雙向邊,1代表與前向邊有相同方向的邊,_1代表與后向邊有相同方向的邊。
圖2是權重有向圖的3種不同的DFS標記,加粗表示前向邊,其余為后向邊。頂點采用字母(數字)表示方法,字母表示頂點類別,括號中的數字表示頂點訪問順序,邊上的字母表示有向邊類別(雙向邊中兩條有向邊的類型相同),數字表示有向邊的方向。以(C)為例,μ1是起始頂點,μs是最右頂點,最右路徑為 μ1— μ2—μ4—μ5。
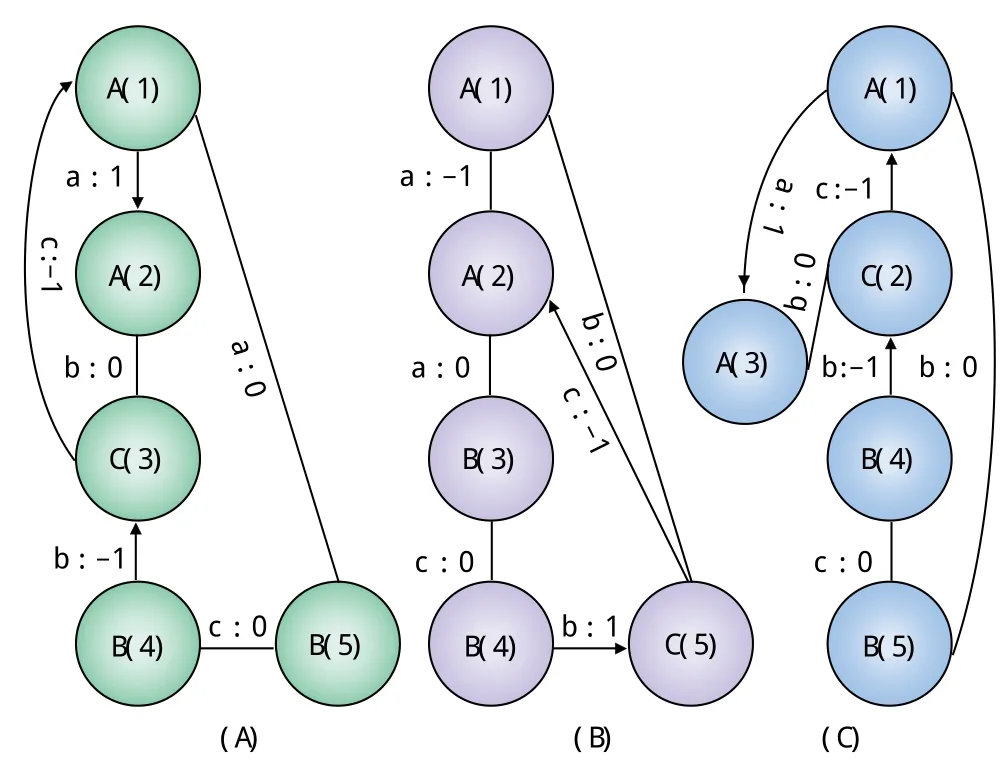
圖2 3種不同的DFS標記
對每個DFS標記,定義邊序組織有向邊,邊序是在給出頂點訪問順序的基礎上,所有后向邊出現在該頂點前向邊之前,若此頂點沒有前向邊,則把它的后向邊放在上一個訪問節點前向邊之后。基于邊序可將加下標的有向圖轉換為邊的序列。
定義4(DFS編碼序):若存在某個圖數據的兩種不同DFS編碼,γ1={e11e12…e1n}和γ2={e21e22…e2m},其中eij表示圖γi遍歷的第j條邊,γ1和γ2的線性序由下例條件決定:
(1)γ1=γ2,當且僅當 m=n,且 e1i=e2i,其中1≤ i≤ n。

或者:n (3)γ2? γ1其他情況 序列排序規則為:令邊序? T占據第1優先級,邊的起始頂點標記占據第2優先級,方向標示(1 ? 0? _1 )占據第3優先級,邊的標記占據第四優先級,邊的終止頂點標記在最末級。上面 3種 DFS編碼的第 1條邊 (μ1μ2A 1 a A)、(μ1μ2A _1 a A)和(μ1μ2A _1 c C)中,? T無差別,起始頂點μj無差別,方向標示1? _1,所以得到γ1? γ2? γ3,γ1就是要找的基本下標。與圖2對應的不同的DFS編碼如表1所示。 表1 3種不同的DFS編碼 使用標準鄰接矩陣把權重有向圖的權重表示為方陣中的元素,主對角線上的元素表示有向圖節點權重,其余各點表示特定兩節點間有向邊的權重。圖1記錄為下面的鄰接方陣。 對任意頂點,如果點權重與和它有關聯的邊權重太大,表示運輸成本過大,要將其剪枝。假設權重關聯最大閾值不能超過20,頂點i的相關權重計算公式為:(ai1+ai2+…ain)+(a1i+a2i+ani)_aii,上例中,5個頂點權重分別為16、12、19、15、15,小于最大權重閾值。為了簡便,判斷一個圖是否可以剪枝,先求出鄰接矩陣的1_范數和∞_范數并相加,若小于規定的頂點權重關聯最大閾值,則必然滿足條件;否則計算每個頂點的權重關聯值來逐一比較。 可比較的鄰接矩陣一定有相同結構,只需把非零處的權重相加求和再比較大小即可,不用遍歷整個矩陣。 2.1.1 算法描述(gSpan) 輸入:權重有向圖數據集WDGD,最小支持度閾值min_sup,DFS編碼 S。 輸出:頻繁子圖集合S。 (1)put S、T←φ'S,為頻繁子圖集合。T為使s最右擴展一次后的結果集; (2)if s≠dfs(s) then ; (3)return; (4)put S←s; (5)遍歷WDGD一次,找出所有可使S最右擴展的邊e,put T←s+e; (6)用DFS詞典序對T排序; (7)for each T中的頻繁s+e,do; (8)對s+e重復s的擴展過程。 2.1.2 算法描述(WDSpan) 輸入:頻繁子圖集合S,單獨頂點的權重關聯最大閾值t。 輸出:最小權重頻繁子圖集合C 。 (1)計算S中每個子圖s的1-范數和 ∞-范數,相加求和,if 和小于t,則放在C1中; (2)記和大于t的子圖s= {v1, v2, …, vn}; (3)For i=1, 2, …, n 計算每個頂點的關聯權重w1, w2, …, wn若他們都小于t,則放在C1中; (4)對同構的矩陣,找到權重和最小的,記為 s1,put C ← s1。 WDSpan中,第1步是挖掘,第2步根據權重來剪枝和篩選,得到最小權重頻繁子圖,但會出現很多權重很大的頻繁子圖作為中間結果再剪枝,使算法復雜度偏高。對此缺陷,本文根據權重圖特點,把圖數據的權重和支持度閾值相結合作為剪枝標準,以圖1為例來說明新的剪枝計算方法。 定義5(平均權重):一個權重有向圖,圖規模為n,則它的平均權重為每個點和成對或單向有向邊權重之和除以n,即(vi+eij)/n,其中vi(i∈1, 2, …, m)表示m個頂點的權重,eij(i, j∈1, 2, …,m)且i< j表示單獨或成對有向邊的權重,eij= (vi·aij+vj·aij)/(vi+vj) 。 計算得:圖1的規模為11,平均權重約為2.84。 定義6(平均權重支持度閾值—MWeight):一個圖數據的平均權重和它出現在圖數據庫中支持度計數的乘積。 平均權重支持度閾值是一個對圖數據剪枝的標準,給定子圖的支持度計數和平均權重支持度閾值,采用以下兩個條件進行剪枝。 (1)sup(G) (2)MWeight(G)≥MWeight(G3)所有的平均值, G3表示已挖掘出的兩個頂點和有向邊組成的規模為3的子圖,是有實際意義的最小子結構。 第(2)條表示若某個子圖的MWeight不比規模為3的“小”子圖的平均值小,則再對它進行擴展也不能得到感興趣的子圖(反單調性)。 首先,計算得到所有G3的平均權重支持度閾值的平均值。采用深度優先策略,獲得1—權重頻繁子圖并按權重由小到大排序,從最小點進行擴展,按照由小到大順序依次將頻繁有向邊連接到頂點上,形成2—權重頻繁子圖。按照權重排序把頻繁頂點連接到頻繁有向邊上,可以形成G3,計算所有G3的平均權重支持度閾值再求平均值,就可以得到剪枝條件(2)。如此再挖掘G4、G5直到Gn,總是把頻繁頂點連接到原圖上,滿足最小支持度閾值,再計算平均權重支持度閾值,進而剪枝。 子圖擴展總是將權重最小的有向邊和頂點連接到原子圖中,但它可能并不出現在圖數據庫中,需進行子圖同構測試。比較從不同權重擴展的生成子圖的平均權重,尋找生成的最小權重子圖作為下次擴展的首選,如圖3所示。 圖3 (a)最小權重子圖 圖3 (b)最小權重子圖 圖3(a)權重為2.58,圖3(b)權重為2.28,挖掘時先得到上面的生成子圖,但要將圖3(b)作為下一步擴展的首選子圖。 2.2.1 算法描述(MWD) 輸入:權重有向圖數據集WDGD,最小支持度閾值min_sup 輸出:最小權重有向頻繁子圖集合C (1)找到所有1—頻繁子圖,按照權重由小到大進行排序(頂點和有向邊分別排序), put G1←所有1—頻繁子圖。G1={v1, v2, …, vm; e1, e2, …,en}; (2)put Gk→φ(k=3, 4, …, l), l 是 WDGD中最大圖規模; (3)put Hk→φ(k=3, 4, …, l) ; (4)找到所有3—頻繁子圖,對不同構的子圖,找到有最小平均權重的那些子圖,記為min_g3,同理,其他K—頻繁子圖不同構的最小平均權重子圖記為min_gk-1; (5)Put G3← min_g3; (6)for k=4, 5, …, l for每個vi和ejdo ; join min_gk-1+ ej,+ min_gk-1+ vi; (7)if MWeight(min_gk-1+ ej)≥ MWE(所有3—頻繁子圖權重和的平均值)剪枝; (8)if MWeight(min_gk-1+ vi)≥MWeight(所有3—頻繁子圖權重和的平均值)剪枝; (9)find min_gk-1+ ej以及min_gk-1+ vi中平均權重最小的子圖,put them→Gkput others →Hk; 性能測評實驗的平臺是Pentium IV 2 GHz CPU,2 GB內存,硬盤為300 G,操作系統Windows server 2008,實驗用MATLAB環境編寫。實驗所用的數據來自人工模擬合成的關于廠區鐵路結構數據集。表2列出了數據模擬使用到的參數和含義。 表2 實驗數據參數及意義 采用的有向圖數據集表示為D10KT30-L50I10E50F20,實驗對兩種算法在挖掘的完整性和運行效率上進行了比較分析。 圖4(a)、(b)分別給出在不同的支持度閾值下,兩種算法發現頻繁子圖的數目和最小權重頻繁子圖的數目。增大,兩種算法的運行時間逐漸接近。 圖4 (a)WDSpan的子圖數目對比 圖4 (b)MWD的子圖數目對比 圖4 (c)運行時間對比 本文針對權重有向圖數據集,提出兩種挖掘最小權重頻繁子圖的算法。采用電腦人工合成數據集進行性能分析實驗,表明兩種算法都可以保證挖掘結果的正確性和連通完整性。得到最小權重有向頻繁子圖,是運輸成本最小且有一定出現比例的廠區鐵路線結構模型。分析原因,改變設計,可以降低廠區鐵路運輸成本。 進一步分析發現,MWD的性能要優于WDSpan,表現為更少的運行時間和更小的存儲空間。但是MWD算法也有不足,如不可避免子圖同構測試,每一次擴展都要和其他擴展結果通過比較平均權重找到最小權重頻繁子圖。 橫坐標表示遞增的最小支持度閾值,表示挖掘到的頻繁子圖數目呈遞減趨勢。隨著最小支持度閾值的增大,原來頻繁的子圖有可能變為不頻繁被剪枝,造成頻繁子圖數目減少。 對比(a)和(b)兩幅圖,WDSpan產生頻繁子圖的數目遠多于MWD產生的數目,而它們產生的最小權重頻繁子圖數目卻差不多,說明兩種算法挖掘結果是相當的,但后者產生更少的中間產物,需要較少的存儲空間,算法性能更好。 圖4(c)給出了在不同的支持度閾值下,WDSpan和MWD的運行時間對比。支持度較小時,兩種算法運行時間相差很大,隨著支持度的 [1]Inokuchi A, Washio T, Okada T. An apriori-based algorithm for mining frequent substructures from graph data[C]. Proc.of the PKDD 2000. LNAI 1910, 2000:13-23. [2]Michihiro Kuramochi, George Karypis. An Efficient Algori thm for Discovering Frequent Subgraphs[J]. IEEE TRAN SACTIONS ON KNOWLEDGE AND DATA ENGINEE RING, VOL. 16, NO. 9, SEPTEMBER 2004. [3]Yan Y, Han J. gSpan: Graph-Based substructure pattern mining[C]. Proc. of the 2002 Int’l Conf. on Data Mining (ICDM 2002).Maebashi, 2002. [4]Han J, Wang W, Prins J. Efficient mining of frequent subgraphs in the presence of isomorphism[C]. Proc. of the IEEE Int’l Conf.on Data Mining (ICDM 2003). 2003. [5]LI XT , LI JZ .An efficient frequent subgraph mining algorithm[J]. Journal of Software, Vol.18, No.10, October 2007. [6]LI Yuhua. A Directed Labeled Graph Frequent Pattern Mining Algorithm based on Minimum Code[C]. Third International Conference on Multimedia and Ubiquitous Engineering.2009. [7]Masaki Shinoda, Tomonobu Ozaki.Weighted Frequent Subgraph Mining inWeighted Graph Databases[C]. 2009 IEEE International Conference on Data Mining Workshops.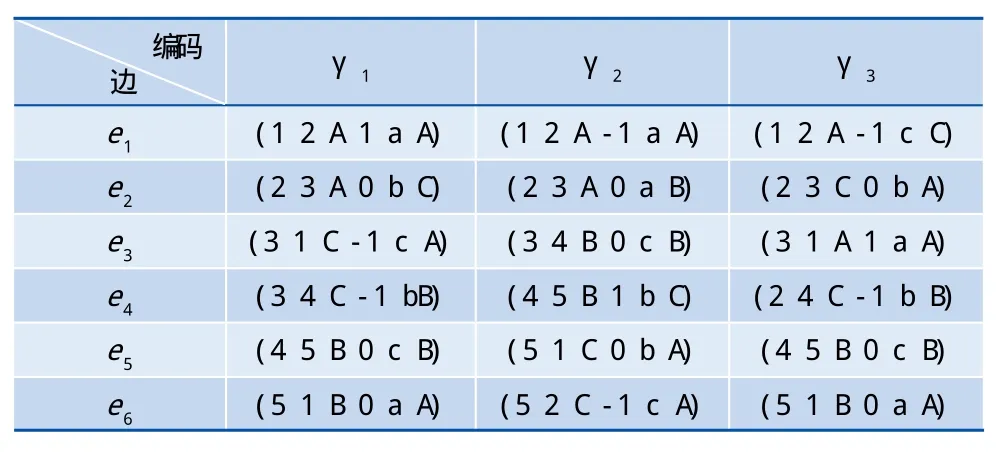

2.2 算法MWD



3 實驗結果與分析




4 結束語
