基于GPGPU 的JPEG2000 圖像壓縮方法*
2013-12-22 06:05:54李玉峰崔迎煒
電子器件 2013年2期
關鍵詞:優化
李玉峰 ,吳 蔚,王 愷,崔迎煒
(1.東南大學移動通信國家重點實驗室,南京210096;2.沈陽航空航天大學電子信息工程學院,沈陽110136;3.北京方天長久科技有限公司,北京100085)
隨著多媒體技術在計算機科學領域應用的廣泛普及,圖像壓縮技術成為現代數字圖像傳輸、處理、存儲中的關鍵技術。不論是在網絡傳輸等方面,還是在移動通信等領域都有著重要的意義和用途。JPEG2000 是在JPEG 基礎上提出的一項新的靜態圖像壓縮標準,同JPEG 壓縮標準相比,不但在壓縮性能上做了優化,能夠以更高的壓縮比率壓縮圖像數據。而且也具有同時支持有損壓縮和無損壓縮的優勢。由于圖像像素可以看成二維數組[1],而計算二維數組則相當于計算大量不相關的數據,特別是質量較高的原始位圖,利用傳統CPU 串行的結構特點處理會消耗大量時間,無法滿足圖像壓縮在現代多媒體技術應用方面的實時性要求。在硬件實現方面,傳統的圖像壓縮一般采用DSP 和FPGA 等硬件平臺來實現,但是DSP 和FPGA 等硬件的實現,要求研究人員需要對硬件內部結構有深入的研究,并且在移植性方面也存在著一定的困難。然而通用計算圖形處理器(GPGPU)的推出,除了傳統GPU 所擁有的圖形處理架構以外,GPGPU 還增加了并行計算架構,該架構為計算密集型處理和高強度并行加速計算提供了可能。NVIDIA 公司為其GPGPU 提供了全新的軟硬件開發平臺CUDA(Compute Unified Device Architecture),利用CUDA 技術在GPGPU 上優化JPEG2000 圖像壓縮核心算法同在CPU 上實現其算法相比較,在計算速度上有了顯著提升,很大程度的提高了圖像壓縮的效率。
1 JPEG2000 圖像壓縮方法
JPEG2000 圖像壓縮標準同JPEG 相比,最大的不同是在算法方面做了進一步的改進[2]。首先,它摒棄了JPEG 采用的以離散余弦變換(DCT)為主的區塊編碼方式,而是選擇了以離散小波變換(DWT)為主的全幀多解析編碼方式,以此來減少圖像中包含的數據冗余信息,避免了在低比特率的情況下JPEG 壓縮標準會產生方塊噪聲的缺點。其次,在熵編碼算法方面,JPEG2000 采用優化截斷的嵌入式塊編碼(EBCOT)算法,取代了JPEG 的哈夫曼編碼算法。
JPEG2000 核心編碼系統主要包括七個模塊,如圖1 所示,首先對預處理后的原始圖像進行正向小波變換得到小波系數,然后根據具體需要對變換后的小波系數進行量化;接著將量化后的小波系數劃分成碼塊,對每一個碼塊進行獨立的嵌入式編碼;得到的所有碼流按照率失真最優原則分層組織;最后按照一定的碼流格式對這些不同質量的層打包后輸出壓縮碼流,即完成了整個圖像的壓縮過程。
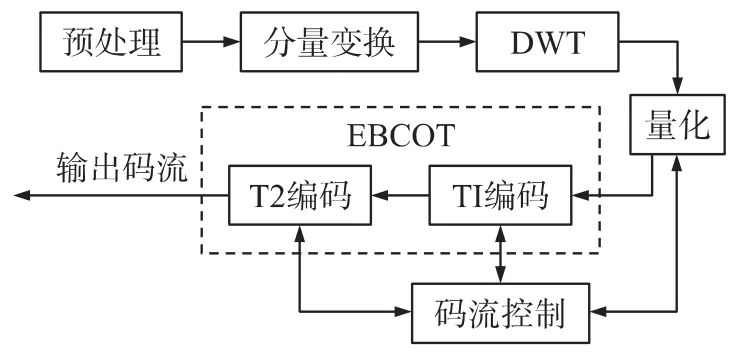
圖1 JPEG2000 核心編碼器原理
2 GPGPU 技術及CUDA 平臺
2.1 GPGPU 技術
隨著3D 時代的到來,龐大的3D 圖形數據計算量已經遠遠超出了傳統CPU 的計算能力范圍。為此,圖形處理器GPU 隨之產生,GPU 是專門為圖形計算而設計的,同CPU 相比,GPU 有高浮點運算性能,高帶寬,高效并行計算的諸多優勢。但如此強大的計算能力僅用于圖形渲染,這對于計算資源來說無疑是一種浪費[3]。為了充分利用GPU 強大的計算能力,同時滿足除圖形計算以外的其他科學計算領域的需求,通用計算圖形處理器GPGPU(General Purpose GPU)應運而生,并且已經取得了巨大的成果。GPGPU 的硬件是采用單指令多數據SIMD(Single Instruction Multiple Data)的結構,同時將圖形處理架構和并行計算架構完美結合[4],這使得GPGPU 不僅能夠作為圖形顯卡用于圖形渲染的本職工作,同時更大程度上涉足其他非圖形的科學計算領域,充分發揮其強大的并行計算能力。如圖2所示,一個硬件GPGPU 芯片是由多個流多處理器SM(Stream Multiprocessor)組成,每個流多處理器包含8 個流處理器SP(Stream Processor)和兩個特殊功能單元SFU(Special Function Unit)以及一些片內存儲器資源,例如共享存儲器(shared memory)和寄存器(Register)等。

圖2 GPGPU 硬件結構模型
如圖3 所示。其中寄存器是高速存儲器,與硬件結構對應,每個流處理器擁有一個私有的32 bit寄存器。共享存儲器的訪問速度幾乎同寄存器一樣快,但是存儲空間較小,按照當前硬件支持,其默認大小為16 K,可被同一個線程塊中的所有線程讀寫訪問。在利用GPGPU 并行加速計算時需要根據不同存儲器的訪問速度和功能特點對存儲器進行合理分配,這是提高GPGPU 計算性能的關鍵。

圖3 GPGPU 硬件SM 結構
2.2 CUDA 平臺
CUDA 是NVIDIA 公司在2007 年6 月推出的專門為其GPGPU 產品設計的異構開發平臺,從此也徹底改變了GPGPU 并行計算的命運。CUDA 提供了硬件直接訪問接口,無需像傳統GPGPU 開發需要借助于Open GL 和Direct X 等圖形學API 來實現。同時,CUDA 對廣泛使用的C 語言進行了擴展,更進一步降低了GPGPU 并行加速計算的編程難度,使開發人員能夠很容易地從C 語言的應用開發過渡到GPGPU 的應用開發。CUDA 提供了與GPGPU 的SIMD 結構相對應的單指令多線程SIMT(Single Instruction Multiple Thread)異構編程執行模型[5],如圖4 所示。CUDA的分層次線程結構包括線程(Thread)、線程塊TB(Thread Block)和網格(Grid)。每個網格由一定數量的線程塊組成,而每一個線程塊最多包含512 個線程。一個CUDA 程序由運行在Host(CPU)端的程序和運行在Device(GPU)端的程序組成。Host 端執行串行指令用來調度任務分配,Device 作為Host 的協處理器執行并行計算部分,在Device 端執行的程序稱為Kernel(內核)函數,Kernel 以一個Grid 的形式執行。一個簡單的Device 程序需要完成以下兩個過程:(1)在kernel 函數調用之前,需要將所需處理的數據從主機內存(Host Memory)復制到Device 端的全局存儲器(Global Memory)中;(2)計算完成后,將計算結果從全局存儲器返回到主機內存。CUDA 并行加速計算的實質是將一個任務分割成多個相互獨立的任務塊,利用成千上萬的線程對任務塊同時進行處理,從而提高整個任務的計算速度[7]。因此,將圖像數據分割成數據塊,利用CUDA 技術能夠更進一步提高JPEG2000 圖像壓縮的速度。
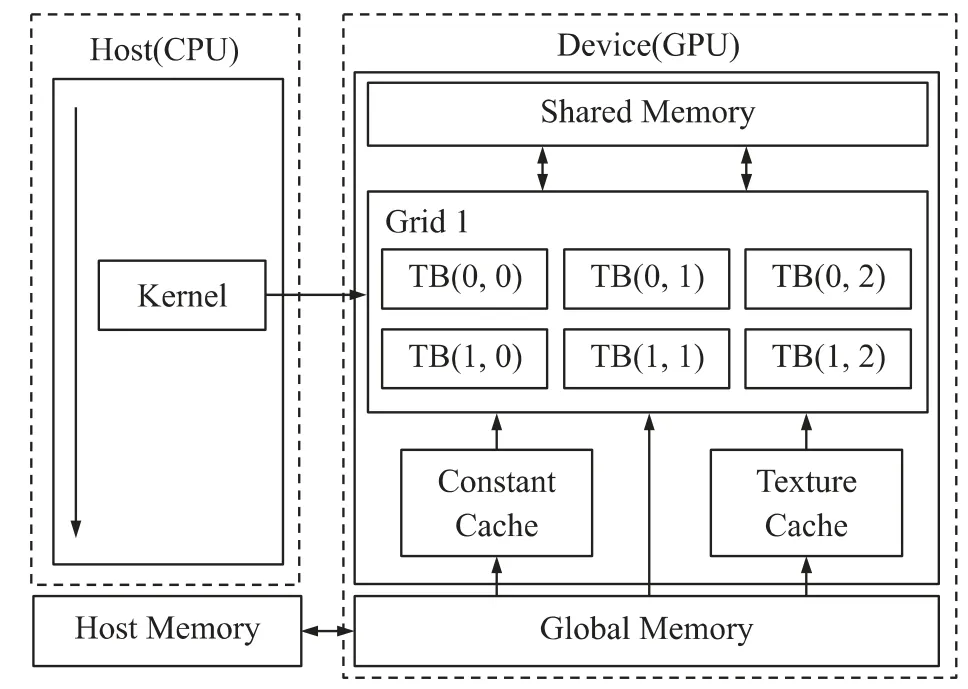
圖4 CUDA 異構編程執行模型
3 DWT 在GPGPU 上的實現
JPEG2000 標準中采用的離散小波變換算法有2 種:5/3 整數型小波提升算法和9/7 浮點型小波提升算法,其中5/3 小波提升算法適用于有損壓縮和無損壓縮,實現算法如下:

在較低比特率的情況下,9/7 浮點型小波提升算法能夠發揮出最優越的性能,在有損壓縮時推薦使用。同5/3 小波提升算法相比,9/7 小波提升算法比較復雜,如下:

其中:
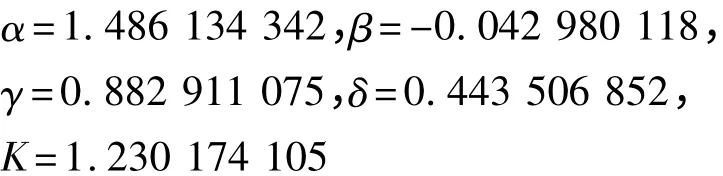
3.1 CUDA 程序核心步驟實現
由JPEG2000 的小波變換算法可知,真正涉及到大量的數據運算是在一維行列變換的時候[7-8]。因此可以確定,將基本的行變換和列變換提升操作設計成kernel 函數,通過GPU 調用完成計算。其他部分工作任務均交給CPU 完成[9]。由此可以得出如圖5 所示的小波變換CPU-GPU 異構并行實現任務分配原理圖。

圖5 DWT 的異構并行實現原理圖
該過程的具體實現步驟如下:
(1)在CPU 端分配主機內存空間X 和Y 分別用于存放輸入圖像數據和壓縮后的輸出圖像數據,將圖像數據讀取到CPU 內存,調用庫函數中的cudaMalloc在設備端分配兩個完全相同的全局存儲器空間(顯存)X1和X2;cudaMalloc((void**)&d_Data,sizeof(unsigned char)* dataSize);//分配輸入顯存空間X1cudaMalloc((void**)&d_new,sizeof(unsigned char)* dataSize);//分配輸出顯存空間X2;
(2)通過調用庫函數中的cudaMemcpy 函數將CPU 內存中的圖像數據拷貝至GPU 端已設置好大小的全局存儲器空間X1,供其進行后續小波列變換計算;cudaMemcpy(d_Data,h_Data,sizeof(unsigned char)* dataSize,cudaMemcpyHostToDevice);
(3)初始化輸入數據,設置執行參數及所需共享存儲器大小,將分段的圖像數據從全局存儲器X1中拷貝至已經設置好的共享存儲器中,對其中的數據進行小波提升變換,以9/7 小波變換為例,其流程如圖6 所示。由于提升小波操作需要多個Thread同時進行處理來實現并行加速,由提升算法可知,每個Thread 一次只能處理2 個數據,然而在接下來的計算中需要用到前一步提升計算的結果。為了確保計算結果的準確性,在每一步提升計算操作完成之后都需要調用線程同步函數__syncthread(),用來等待所有的Thread 全部完成之前的提升操作以后,再進行后續的計算。然后將計算結果按順序存入之前設置好的顯存空間X2中;
__shared__unsigned char space_s1[16][16];
//聲明未處理數據的Shared Memory 空間
__shared__unsigned char space_s2[16][16];
//聲明處理后數據的Shared Memory 空間

圖6 9/7 小波提升kernel 流程
(4)將上一步驟中的結果數據按照相同的方法操作,進行一維小波行變換,將計算結果存入已空置的全局存儲器空間X1中;
(5)按照小波分解等級控制,重復小波提升變換過程,直至將所有等級的小波提升變換過程全部完成,最后將全局存儲器的結果圖像數據返回到CPU主機內存中,釋放GPU 顯存空間和CPU 內存空間。
cudaMemcpy(h_Image,d_new,sizeof(unsigned char)* dataSize,cudaMemcpyDeviceToHost);
cudaFree(d_new);//釋放GPU 顯存空間
Free(&(img));//釋放CPU 內存空間
3.2 共享存儲器優化
由于全局存儲器讀取速度較慢[10],若將待處理數據存儲在全局存儲器中進行反復存取,則會大幅度的降低程序執行的效率。然而共享存儲器擁有較快的讀取訪問速度,因此選用共享存儲器的優化策略來加速DWT 算法。但當多個線程對共享存儲器的同一位置讀取數據時,會產生Bank conflict,影響執行性能,所以在優化過程中必須避免Bank conflict。
首先,將全局存儲器中的圖像數據分割成(n+1)×(n+1)個數據塊DB(Data Block),同時創建相同數目的線程塊TB(Thread Block),將線程塊一一映射到分割后的每一個數據塊,如圖7 所示。為每個TB 聲明一塊共享存儲器空間,用于存放映射到線程塊內的每個線程需要執行的數據塊中的數據。

圖7 共享存儲器數據存取優化
利用共享存儲器訪問速度快這一優點,按照如上方法,將全局存儲器中的源圖像數據分塊復制到共享存儲器以后,線程塊內的每一個線程直接對共享存儲器內對應的數據進行計算,這樣就避免了可能出現的Bank conflict。此外,在CUDA 程序優化時,要保證訪問全局存儲器時需要滿足合并訪問條件,該條件同樣是優化CUDA 程序性能的重要因素之一。同時,還需考慮計算精度、訪存延遲、計算數據量等多方面因素[11]。
4 實驗平臺及測試結果分析
測試所需的軟硬件環境如下所示:
CPU:Intel E7400 酷睿雙核2.80 GHz CPU,主頻2 800 MHz,主機內存為2 GB;
GPU:采用NVIDIA GeForce GTX 560 Ti 設備,流多處理器數量8 個,CUDA 流處理器數量384 個,核心頻率822 MHz,流處理器頻率1 645 MHz,顯存頻率4 008 MHz,顯存容量1 024 MB,顯存帶寬128 GB/s,顯存位寬256 bit,計算能力2. 1,總線接口PCI-E 2.0x16;
編程環境:GPU 硬件驅動版本為301.42,使用CUDA4. 1 版本的編程環境,windows 7 操作系統,VS2010。
由于CPU 上和GPGPU 上的JPEG2000 圖像壓縮均是按照傳統定義來實現的。因此,圖像的壓縮質量基本上是相同的,通過對CPU 和GPGPU 上測試時間進行比較分析,實驗結果分析詳見表1。
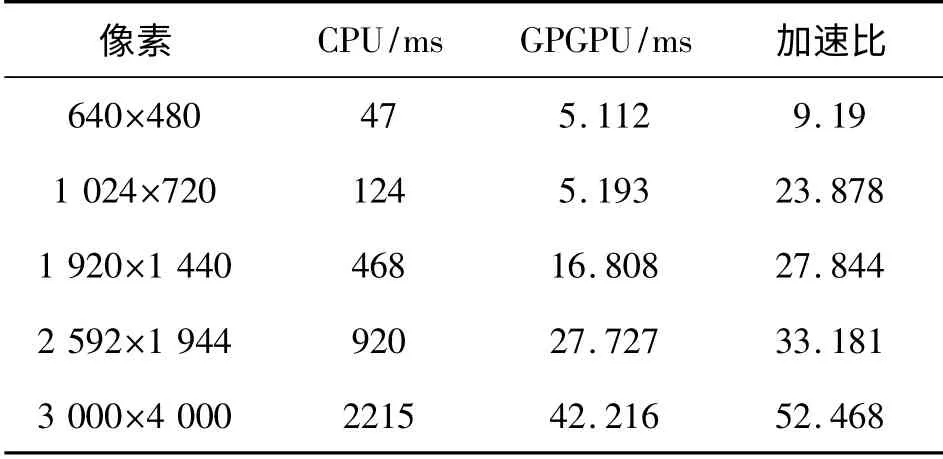
表1 DWT 在CPU 和GPGPU 上的時間對比
從實驗數據可以看出,同未經過優化的CPU 測試結果相比,對于所需處理數據相對較少的像素為640×480 的圖像來說,計算速度提高了9 倍多,相比之前的研究—基于CUDA 的小波Mallat 算法及提升方案的設計與研究[12]中對于像素為512×512 的圖像其提升小波算法的計算時間為6.785 ms,可見優化后的DWT 提升算法的計算速度有所提升。而對于所需處理數據較多的圖像來說,計算速度提高超過了50倍。顯而易見,經過CUDA 優化的JPEG2000 靜態圖像壓縮標準中的DWT 算法在GPGPU 上的計算時間要遠遠小于CPU 的計算時間,并且隨著計算數據量的增加,CPU 的運算時間呈現大幅度增長趨勢,而GPGPU 的計算時間增長較小。從加速比也可以看出,隨著數據量計算的增加,GPGPU 表現出更優越的加速計算性能。
此外,由于基于GPU 的JPEG2000 圖像壓縮已經有了不少研究成果,為了證明本實驗所選用的方法在原有的結果上做了相應的優化改進。選用之前普遍使用的NVIDIA GT 240 GPU 進行DWT 提升計算測試,并與本實驗的測試結果進行對比,如表2 所示。

表2 DWT 在不同GPU 上的測試時間對比
由以上測試結果可以看出,本實驗的優化方法在一定程度上取得了相應的效果。盡管如此,由于CUDA 程序的優化還需要結合指令流優化等多種因素。因此,在以后的程序優化工作中,還需要綜合考慮各種優化原則進行反復試驗,權衡各方面因素得出一個盡量接近最優的優化結果。
5 結束語
通過JPEG2000 圖像壓縮算法分別在CPU 和GPGPU 兩種不同的處理器上的實現可以得出,在科學計算領域,特別是針對類似圖像壓縮這種數據之間相關性不大的大規模密集型的浮點型數據計算時,利用CUDA 平臺在GPGPU 上并行加速實現能夠表現出更大的性能優勢。盡管當前GPGPU 并行加速計算還受到一些諸如兼容性、算法移植和優化等方面的技術難點限制,但是GPGPU 并行計算擁有的巨大潛力和無可比擬的性能優勢已經受到了世界各行業領域的廣泛關注,相信基于GPGPU 并行計算必將成為今后的發展方向。
[1] 郭靜,陳慶奎.基于CUDA 的快速圖像壓縮[J].計算機工程與設計,2010,31(14):3302-3304,3308.
[2] ISO/IEC 15444 - 1 Information Technology:JPEG2000 Image Coding System[S].USA:ISO/IEC,2002.
[3] 張舒,褚艷麗, ,等. GPU 高性能計算之CUDA[M]. 中國水利水電出版社,2009:12.
[4] NVIDIA Corporation. NVIDIA CUDA Programming Guide,version 3.0,2010.
[5] John D O,David L,Naga G,et al. A Survey of General-Purpose Computation on Graphics Hardware[J]. Computer Graphics Forum,2007(26):80-113.
[6] 宋曉麗,王慶.基于GPGPU 的數字圖像并行化預處理[J]. 計算機測量與控制,2009,17(6):1169-1171.
[7] Ding W,Wu F,Li X,et al. Adaptive Directional Lifting-Based Wavelet Transform for Image Coding[j]. IEEE Trans Image Processing,2007,16(2):416-428.
[8] 宋凱,臧晶. 圖像處理中小波提升方案和Mallat 算法的比較[j].微處理機,2004,10(5):39-41.
[9] Joaquín Franco,Gregorio Bernabé,Juan Fernández,et al. A Parallel Implementation of the 2D Wavelet Transform Using CUDA[J].IEEE Computer Society,2009,111-118.
[10] Sunpyo Hong,Hyesoon Kim. Ananalytical Model for a GPU Architecture with Memory-Level and Thread-Level Parallelism Awareness[J].ACM Sigarch Computer Architectu Renews,2009,37(3):152-163.
[11] Han T D,Abdelrahman T S.High-Level GPGPU Programming[J].Parallel and Distributed Systems,IEEE Transactions on,2011,2(1):78-90.
[12] 孫自龍.基于CUDA 的小波Mallat 算法及提升方案的設計與研究[D].華中科技大學,2011:37-39.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
