編譯原理課程教學中的詞法分析及其應用
2013-12-29 00:00:00王峰張浩軍閻娟侯惠芳
計算機教育 2013年17期
摘要:針對編譯原理課程中的詞法分析,介紹相關原理,重點探討詞法分析技術在非編譯系統中的廣泛應用。通過實際應用的分析,加深學生對理論知識的理解,提高學生對編譯原理課程重要性的認識,調動學生的學習積極性和主動性。
關鍵詞:編譯原理;詞法分析;實際應用
1.詞法分析概述
詞法分析是編譯過程的第一個階段,其主要任務是對構成源程序的字符流進行掃描和分解,把它識別為一個個具有獨立意義的最小語法單位,即單詞,從而產生一個個的單詞序列,用于語法分析。執行詞法分析的程序稱為詞法分析程序或掃描程序,它按構詞規則識別單詞,將作為字符串的源程序改造成為單詞符號串。單詞一般采用形如<單詞類別,單詞自身值>的二元組形式表示,其中單詞類別是語法分析需要的信息,而單詞自身值則是其他編譯階段需要的信息。編譯程序是在單詞的級別上來分析和翻譯源程序的,因此詞法分析是整個編譯的基礎。詞法分析程序除了識別單詞這個基本任務外,還可完成以下任務:對源程序進行處理,如組織源程序的輸入、刪除注釋、空格及無用符號;行、列計數;列表打印源程序;發現并定位詞法錯誤;建立、查填符號表。
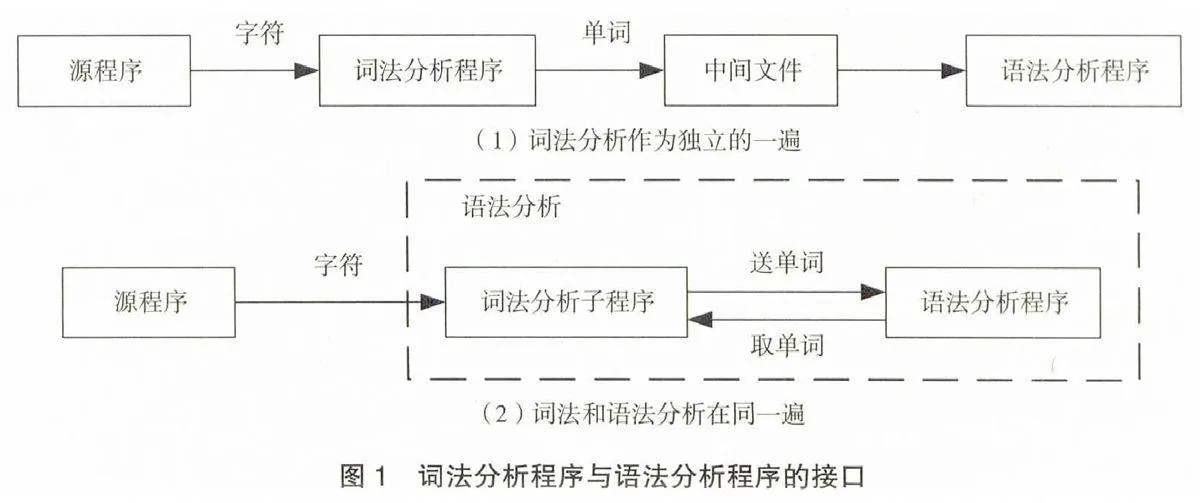
詞法分析程序與語法分析程序的接口方式有兩種,如圖1所示。(1)詞法分析作為獨立的一遍,將字符流的源程序變為單詞序列輸出到中間文件上,此中間文件作為語法分析的輸入繼續編譯;(2)詞法和語法分析在同一遍,即將詞法分析作為語法分析的一部分,把詞法分析程序設計為一個子程序,每當語法分析程序需要單詞時,就調用該子程序。為了使整個編譯程序的結構更簡潔、清晰和條理化,便于使用自動構造工具,提高編譯效率,以及增強編譯程序的可移植性,通常采用第1種接口方式,即把詞法分析從語法分析中獨立出來。
程序設計語言的詞法描述機制是正規表達式,識別機制是有窮自動機。詞法分析程序可以通過手工編寫和自動生成兩種方式來構造:手工編寫需要借助狀態圖來實現;而自動生成的原理是將正規式轉換為有窮自動機,即首先將單詞描述成正規式,然后把正規式轉換為一個NFA(不確定有窮自動機),進而轉換為相應的DFA(確定有窮自動機)。Lex(Lexical Analyzer)是美國Bell實驗室研制的一個詞法分析程序的自動生成工具,此后,GNU工程推出的Flex(Fast Lex)對Lex進行了擴充,使用它們可以很方便地構建詞法分析程序。
2.詞法分析的典型應用
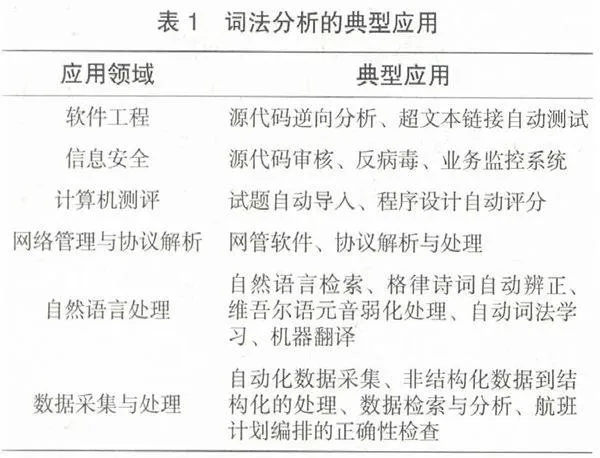
詞法分析技術在軟件工程、信息安全、計算機測評、網絡管理與協議解析、自然語言處理以及數據采集與處理等領域得到了廣泛應用,見表1。
2.1軟件工程
詞法分析的主要任務是對構成源程序的字符流進行掃描,然后根據構詞規則識別單詞符號,這正是源代碼逆向分析過程中必不可少的一步。因此,詞法分析被廣泛應用于軟件逆向工程中的源代碼逆向分析,以獲得逆向分析后續工作所需的單詞符號的各類信息。
利用詞法分析可以實現B/S構架應用系統和三層構架應用系統中超文本鏈接的自動測試。超文本詞法分析主要根據超文本的詞法和關鍵詞,分析查找超文本文件的鏈接類和應用類鏈接關鍵詞,確定超文本的調用關系,完成各類鏈接分析(href、src、cite和background),并將分析結果存儲到數據庫中。測試時對設定的目錄進行分析處理,列出根目錄下的文件和目錄結構,并對目錄下的HTML文件進行詞法分析,接著對分析后的鏈接標記進行分類、字符解析與轉換等處理,然后進行鏈接的分析預驗證,最后統計頁面文件大小和生成不同的分析報告。基于超文本詞法分析的超文本鏈接自動測試不僅可提高鏈接測試的覆蓋率,而且可有效提高測試驗證的效率和準確性,降低超文本鏈接的測試驗證工作量。
2.2信息安全
C/C++語言中許多庫函數存在安全漏洞,攻擊者常常利用這些函數產生的漏洞來進行緩沖區溢出、格式化字符串溢出和競爭條件等攻擊。源代碼審核技術通過對軟件代碼進行分析,從特征數據庫里抽取感興趣的內容進行上下文分析,并對可能存在危險的代碼位置進行報警,從而能在編碼階段及時發現和修正軟件源代碼中存在的安全漏洞。詞法分析能夠完成自動化的快速漏洞檢測,是源代碼審核中的一項重要技術,它通過對自定義的漏洞模型與根據待分析源程序確定的程序模型進行分析比較,驗證程序模型是否滿足漏洞模型的條件。其實質是訪問包含在危險函數數據庫中的函數(如gets、strcpy、scanf、printf、sprintf、snprinff等)來尋找可能存在的危險,當有潛在危險符合數據庫特征時,就會發出警告。目前最具代表性的詞法檢測工具包括ITS4、Rats和FlawFinder等。
某些嵌入網頁的病毒通過插入無效的字符即可得到病毒變種,利用Lex和Yacc等工具可以得到查殺此類病毒的有限自動機軟件,即虛擬機。這種方式的查病毒虛擬機在進行詞法規則分析時對“空格、注釋”等信息置之不理,因此不會影響對病毒代碼的定位。
在業務監控系統中可通過報警規則來描述用戶所提出的報警條件,并結合詞法分析技術在系統運行過程中對報警規則進行匹配。如基于銀行業務系統的網絡安全審計和監控系統,采用報警規則設計和詞法分析方法,能夠快速、準確地判斷是否為可疑交易和大額交易。
2.3計算機測評
利用自動化的手段將已有試題文檔導入在線考試系統時,為保證錄入試題的準確性和保密性,提高試題錄入的效率,可通過詞法分析將試題文本打斷為孤立的單詞,進而將各個單詞進行歸類和封裝(包括單詞種類、行號、起始位置、內容等信息)。之后,利用封裝后的單詞對象,使用預定義的語法樹進行匹配和驗證。同時,單詞表對整個過程涉及的臨時數據進行存儲和必要支持。
在程序設計自動評分系統中,當考生的程序不能成功運行時說明程序存在語法錯誤,可先對考生的源程序進行詞法分析,即掃描源程序,生成單詞文件;然后根據此文件進行語法分析,在保證不對考生程序正確部分產生破壞的前提下,盡最大可能將考生程序修改正確,并對新程序進行編譯鏈接和測試,從而避免考生因編程中的很小失誤而導致大量丟分的問題。如果仍不能編譯運行,則可依據正規表達式描述的知識要點進行匹配,使得即使錯誤嚴重或結果不正確的程序也能得到應得的分數,從而使評分結果更接近于人工閱卷。
此外,對某類文本范疇的試題,在一定復雜度范圍內通過對文本的詞法掃描、文法定義、語義分析、等價替換等技術將標準答案與錯誤答案按特定文法規則進行語義轉換后產生唯一等價表達式,通過對轉換后的規范表達式進行比較,檢查考生答案是否與標準答案等價。
2.4網絡管理與協議解析
在網絡管理系統中,不同運營商通常對網絡設備有不同的實際需求,如對于網管設備告警信息的內容和格式有不同的要求。如果針對這些不同的需求開發不同的網管版本,會成倍增加軟件開發和運行維護的成本。為靈活適應各種需求,網管軟件通常給出一套腳本語言,用戶把特定的需求用腳本語言寫入—個腳本文件中,然后網管軟件在運行時動態分析腳本文件,獲取用戶的特定需求并把結果顯示在界面上。實現這一方案的關鍵是腳本文件中關鍵字的識別,這可以利用Flex等工具生成的詞法分析器來完成。網管軟件只需要定義腳本文件中用到的所有關鍵字,并在程序中實現對于關鍵字的處理即可,從而可以減少網管軟件設計和編碼的工作量,提高網管編程的效率。
在通信協議解析與處理中,可以借鑒自動生成詞法分析器的實現思想,先將通信協議采用正規式集的方式進行形式化描述,然后由一個狀態圖生成程序產生對應這些正規式的狀態圖,最后由一個主控程序根據狀態轉換圖對接收到的數據幀進行分析識別,輸出用戶希望的數據格式。采用形式化描述的方法對協議進行描述,可以實現與協議無關的協議解析和處理,避免針對不同通信協議均要編寫相應的解析和處理程序,從而使協議的解析和處理具有更好的靈活性和普適性。如利用PCCTS工具中的DLG根據詞法描述文件生成詞法分析程序,從輸入的字符流中識別詞法描述文件中定義的記號;再利用其中的ANTLR根據語法描述文件定義的語法規則生成語法分析程序,在此過程中調用DLG生成的詞法分析程序來識別具體的記號,從而實現SIP、MGCP和H.248/GEGACO等通信協議的解析和處理。
2.5自然語言處理
詞法分析是各種自然語言處理系統中首要的源語言分析模塊,是進行句法分析、語義分析的基礎。
詞法分析是自然語言檢索中一項十分重要的工作,它同時應用于用戶提問分析和源文本處理。詞法分析首先對文本、網頁等進行詞語切分,然后通過詞頻統計和詞出現位置的判斷,在文本和網頁中提取主題詞和概念詞。之后利用多個關鍵詞的布爾邏輯運算構成檢索式,在索引庫中逐個進行匹配。由于它能夠根據詞的位置關系發掘出詞的修飾限定關系,因此與傳統基于關鍵詞的檢索方法相比,其檢索內容的相關度更高。
借助計算機信息技術,按照中華古典詩詞一些聲韻格式要求對提交的詩詞作品進行可有限追溯的詞法分析,可以實現自動智能審查辨別,并反饋訂正建議,從而幫助詩詞創作者更好地運用計算機工具創作出符合格律的好作品,進一步弘揚中華詩詞文化傳統。
通過詞法分析可以從語素中獲得許多語言學信息,比如在維吾爾文詞根與附加成分切分法的基礎上,通過分析維吾爾文詞的詞法結構和音節結構,可以實現對維吾爾語元音弱化現象的算法處理。
自動詞法學習通過機器學習等方法從語料中自動獲取計算機算法能使用的構詞和構形的規律。詞法分析利用自然語言中形態學的規律對給出的句子進行詞匯級處理,隨后自動詞法學習方法能從未經加工的文本中學習詞法分析處理的數據,從而很容易地獲得目標語言中的各種形態變化規律,并把這些規律用形式化的語言表示成各種正則表達式的形式。
詞法分析是機器翻譯的第一階段,當源語言文本送人計算機后,首先要進行詞法分析,即對送人的文本進行斷句、切分,識別出單詞、標點、數字等句子的基本成分,并確定它們的形態和詞性。這也是完成計算機翻譯過程的基礎和關鍵階段,它為后續句法分析和目標語生成創造了條件,其準確程度的高低直接影響著句法分析的準確率和譯文的準確性。
2.6數據采集與處理
數據采集的主要工作是獲取設備上傳的文件,根據預先定義的格式進行解碼,然后把解碼成功得到的數據存人數據庫。在此過程中會遇到數據格式跨平臺、需求變更等問題。針對數據格式的通用和跨平臺問題,可采用XDR(ExternalData Representation Standard,外部數據描述標準)等跨平臺的數據格式來解決;針對需求變更問題,可以使用針對XDR等數據描述語言的詞法分析器把對數據描述的解析變成動態的。這樣,對于經常變化的數據格式描述,通過動態解析的方式避免了編譯和靜態鏈接,同時把業務邏輯的概念變得更通用,將原先的給定數據描述解析數據變為現在的解析數據描述和數據,從而使數據采集的功能更通用。
利用詞法分析的良好識別性可以較好地解決非結構化文本庫到結構化關系數據庫的關鍵詞庫的建立問題。例如,中草藥資源信息的原始著錄數據形式非常復雜,文本數據不僅是變長的,而且其對象的詞描述不是簡單的關鍵詞而是長句或短文,這種數據的非結構化不利于數據的查詢和統計。為此,可利用詞法分析對原始著錄數據項進行拆分,提取有關關鍵詞,采用建立關鍵詞庫的方法來建立中草藥數據庫,從而實現數據的自動提取和關鍵詞庫的建立,并提高中草藥著錄數據的規范化存儲效率和數據查詢效率。
為解決RTI(RunTime Infrastructure,運行時間基礎設施)中FED(Federation Execution Data,聯邦執行數據)文件的解析效率和可重用性問題,可以將解析程序的數據提取模塊與解析處理模塊分離,同時在數據提取模塊中應用詞法分析和語法分析技術對FED文件進行解析優化。首先,用正則表達式將FED文件中所涉及的單詞符號進行形式化描述,定義出FED文件的詞法規則;同時,用LALR(1)文法表示符合相關標準的FED語法的所有狀態轉換,完成FED文件的語法規則;然后,借助Flex和Bison生成詞法分析程序和語法分析程序,再結合定義的解析處理規則最終生成解析程序。采用這種方案,可以將繁雜的解析處理程序的編寫簡化為可讀性較強的詞法分析文檔和語法分析文檔的編寫,提高程序的可讀性和可維護性,并且對于不同的解析要求,可以重用現有的大部分代碼;同時,對各種要求的FED解析處理程序只需掃描一次FED文件即可完成整個解析過程。此外,只需根據Flex和Bison的版本要求簡單修改詞法分析文檔和語法分析文檔,即可實現異構平臺的移植。因此,其效率、穩定性、可維護性、可重用性以及可移植性都明顯優于通常的FED文件解析方案。
Lex/Flex詞法分析工具除了構造編譯器的詞法分析程序外,還可以針對具有結構化輸入的程序構建輸入識別程序。例如,生物信息基本數據庫數量極多,數據存儲格式各異,處理方式也有所不同,因此常規的處理方法工作量極大。為此,利用詞法分析技術,針對不同格式的生物數據文件,只要構造相對應的正則表達式就可以使用Lex/Flex構建相應的識別程序,對文件中的數據進行檢索和分析。
為保證航班計劃編排的正確性,可以航班計劃編排規則為依據,采用詞法分析和語法分析技術對航班計劃編排結果進行自動檢查。將航班計劃等視為按民航特定規則編寫出來的“語言”,其中航班號、起止時間、起止地點、機型、機組等基本信息是該“語言”中的關鍵字,則可以首先采用詞法分析掃描航班計劃字符流,按照詞法規則識別出航班計劃中的各類單詞符號,檢查這些關鍵字是否符合其組成規則,并產生用于語法分析的符號序列,告訴語法分析這些單詞的組織順序。隨后按照語法規則,采用語法分析對詞法分析的結果進行處理,識別詞法分析給出的單詞符號序列是否為給定文法的正確句子,進而檢查其是否按照規定的詞序及格式編排,是否表達了正確的涵義,從而實現航班計劃編排規則的句法檢查。
3.結語
在編譯原理課程的詞法分析教學中,通過介紹詞法分析技術在軟件工程、信息安全、計算機測評、網絡管理與協議解析、自然語言處理以及數據采集與處理等非編譯領域中的廣泛應用,有助于提高學生對課程的重視程度和學習的積極性與主動性,加深學生對理論知識的理解,培養學生理論聯系實際的能力,激發學生的創造性思維,從而切實有效地提高學生的專業素質。
