支持文件重刪的HDFS分布式備份系統研究
2014-01-16 09:21:10王建輝石宇良
電子設計工程 2014年4期
關鍵詞:系統
王建輝,石宇良
(北京工業大學 軟件學院,北京 100022)
隨著現代化的飛速發展,傳統行業逐漸進入自動化辦公時代。人們工作和生活中需要的信息量猛增[1],現有的硬件備份不能有效解決當今動不動就達上PB的數據[2]。需要解決的問題有:如何降低構建大型備份系統的硬件成本,提高現有線性備份的磁帶庫恢復特定數據速度等。采用分布式存儲備份數據的優點可以解決該問題,避免傳統備份系統的一些缺點[3]。計算機行業最著名的分布式存儲系統即HDFS(Hadoop Distributed File System)。HDFS的最大優點是可以輕松處理海量數據。
云備份服務是一個低成本高效率的方案,用來有效地對大型企業的數據備份提供保護。盡管云備份有著許多優勢,但潛在的問題一直存在。一個最主要問題是云服務采用大規模的集群節點構成,節點之間大量的數據傳輸備份等操作嚴重的消耗了有限的網絡帶寬,導致網絡瓶頸[4]。傳統存儲也存在HDFS所不具備的優勢,最重要的一點即重復數據刪除技術,簡稱重刪技術,它是將大量文件分塊,刪除相同的文件塊,只備份非重復數據,達到數據壓縮的效果[5]。
如果把重復數據刪除的技術應用到HDFS上,將可以最大限度的發揮HDFS存儲能力。將更多的數據壓縮,充分利用網絡帶寬傳輸和存儲介質空間。研究方法結合開源架構的HDFS與OPEN DEDUP,設計實現了基于分布式存儲的支持數據重刪技術的備份系統DDFS(Deduplication Distributed File System),該系統充分利用分布式系統的存儲能力,替代原有磁盤與磁帶的備份機制,滿足用戶的數據備份容災。
1 結構體系
傳統備份方案主要分為LAN-Base和LAN-Free備份[6]。Lan-Base備份中的生產服務器與備份服務器之間采用以太網連接,其最大的缺點是備份時占用了生產服務器的網絡帶寬,影響線上實時業務的性能。LAN-Free備份克服LAN-Free的缺點,采用FC光纖線連接網絡設備,備份時不占用主業務帶寬,能夠有效地提高備份效率,但其缺點是硬件設備成本太高。
為了滿足原有網絡不改變的情況下,大大降低增加存儲設備的成本,采用HDFS良好的節點擴展性與重刪技術的結合。如圖1所示。
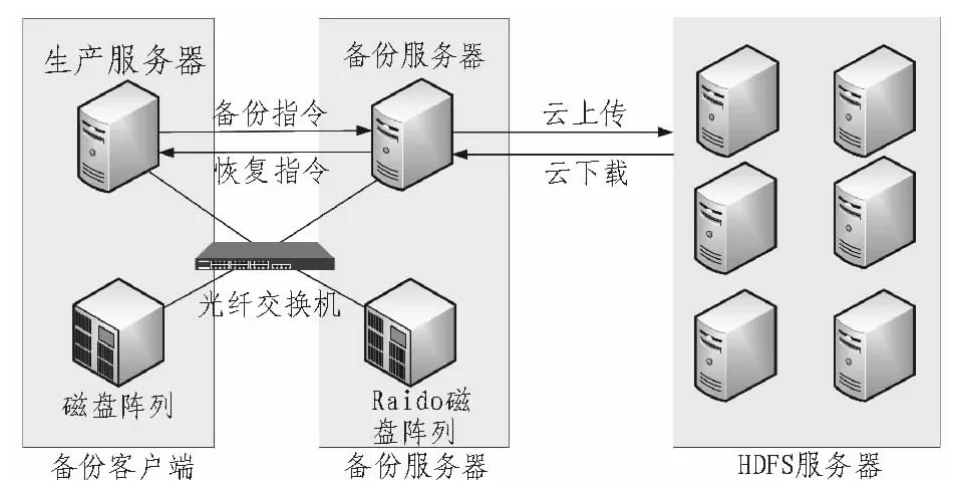
圖1 DDFS系統結構圖Fig.1 DDFS System structure
DDFS系統采由3部分組成:備份客戶端,備份服務器,HDFS服務器。備份客戶端主要放在需要備份的服務器上,如:生產服務器,備份源端等。其主要作用是接受用戶備份請求,收集備份數據,與備份服務器建立通訊,傳輸備份文件。備份服務器用來處理來自客戶端的數據,并對文件重刪操作、加密、壓縮等操作,最后上傳HDFS分布式存儲,歸檔數據。可以認為備份服務器是中轉數據流的重要橋梁。HDFS服務器用于存放由備份服務器處理后的數據。由于HDFS有著高容錯、極高可擴展性,副本備份策略、高并發處理數據的能力等,極易作為海量數據的存儲地。DDFS框架備份/恢復流程如圖2所示。
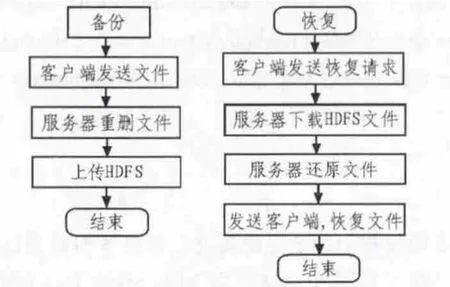
圖2 DDFS備份/恢復結構圖Fig.2 DDFS Backup/Recovery structure
DDFS采用三層架構的優點:
1)備份服務器采用標準LAN-Free架構,可以無縫地與現有備份環境相容,便于擴展。
2)備份服務器的存儲介質采用Raid0的方案,利用Raid0磁盤陣列的高并發讀寫的優勢,提高備份/恢復速度。
3)備份服務器加入數據重刪技術,并與壓縮結合,大大降低了備份數據的大小,從而減少網絡傳輸的數據量與存儲硬盤的成本。
4)數據存儲介質端采用HDFS分布式文件系統,利用HDFS自帶的文件備份系統,克服了Raid0陣列的不支持數據備份的劣勢。
5)DDFS全部采用開源架構,便于愛好者研究與優化。
2 系統的設計與實現
2.1 客戶端模塊設計
備份客戶端主要功能:接受備份請求、搜集備份數據、數據發送,獲取備份信息和恢復數據。核心設計思想是讓客戶端與服務器進行通訊,傳輸數據。
2.2服務端模塊設計
備份服務器端主要對數據進行重刪,壓縮,備份,恢復等操作,是整個備份系統的核心。采用開源存儲架構Open Dedup進行修改集成。整個服務器存儲介質采用運行硬盤IO極快的Raid0磁盤陣列。如圖3所示。
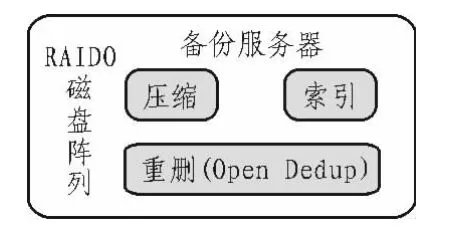
圖3 備份服務器模塊結構圖Fig.3 Backup server module structure
2.2.1 文件索引
采用開源架構Lucene建立文件索引。Lucene是Apache開源機構提供的一個檢索工具包,可以建立高效的文件索引,便于以及其快的速度從大量文件中查詢信息。在備份系統中高效的索引意味著可以快速查詢出是否有備份了相同的文件,減少重刪的時間。由于Lecene中存在Field(域)的概念,對于每一個備份文件信息,采用表1中的數據類型存儲。
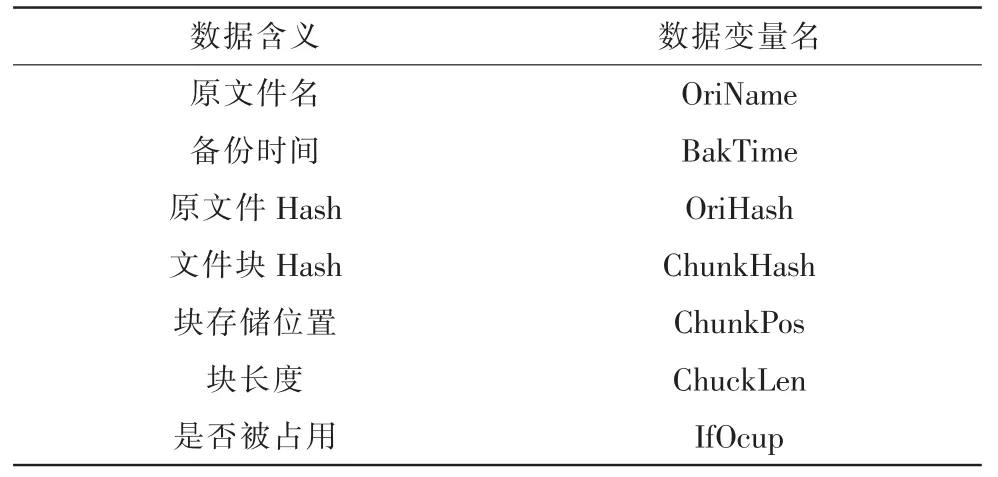
表1 文件索引結構Tab.1 File index structure
塊存儲位置和快長度:用來將一個文件拆分成的多個文件塊并合并成一個大文件,保存塊位置和塊長度便于文件恢復。由于備份計算Hash值時需要把一個文件分成很多小文件塊,這樣帶來的是備份了大量的小文件塊,對于本來就性能差的硬盤IO來說是不可以接受的。因此,將大量小文件合成一個大文件,并記錄每個文件的起始位置和長度,便于恢復。既滿足降低了文件IO與傳輸壓力,又方便文件恢復時的查找。經在普通個人電腦測試Lucene建立1 500個文件索引僅需要 2 s,查詢只有 5 μs。
2.2.2 重刪
重刪技術現主要用于數據備份領域。簡單地說,首先把文件分塊,檢驗每塊是否相同。如果數據是第一次備份,文件會被存儲在存儲介質里[7]。如果不是,重刪技術只對前未被存儲的文件塊進行保存[8]。如果需要備份的文件塊與已備份的文件塊相同,則不備份此塊,而用指針指向重復的數據,記錄備份信息,便于恢復。重刪主要應用在客戶端或者服務器端,各有優缺點。為了備份框架清晰,減少備份環境網絡帶寬占用,采用客戶端重刪的方法。
Open Dedup框架支持定長模塊切,每個分塊長度設定可以從4k到128k。重刪效果與分塊長度成反比,分塊越少,文件去重效果越好。同時,較小的文件切分塊會需要更大的內存支持。分塊長度可以按照實際應用來調節,對于備份系統中的文件主要類型不同的應用,實際長度不同。備份采用兩個方案:一個方案是采用文件系統過濾技術,檢查和只備份修在一個周期內改過的文件。另一個是采用重刪技術,將一個備份文件切分成大量的小文件塊,用來Hash計算每個文件塊的唯一指紋,對比并刪除重復的文件塊來達到重刪的目的。
文件塊的Hash值計算采用Rabin指紋算法(Rabin fingerprint)進行文件分塊,計算每個文件塊的Hash。同時與已經存儲到備份介質中的數據的Hash值進行比對,如果不相同則把文件塊保存,如相同則在原有文件塊對應的信息“是否被占用”中累加1,對新文件建立索引,并將文件備份路徑的指針指向已備份的文件。如圖4所示。
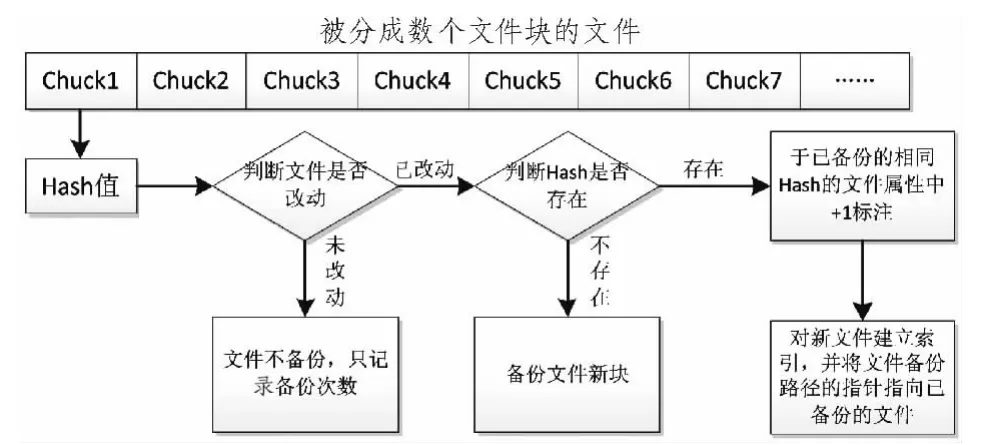
圖4 文件重刪流程圖Fig.4 File deduplication flowchart
2.2.3 HDFS
采用HDFS作為最終數據存儲介質,是因為HDFS是采用了廉價的硬件環境,提供了高并發性,高擴展性,高容錯性的存儲平臺。
1)高吞吐量,由于HDFS采用分布式存儲,大量的節點組合成一個對外的存儲平臺,這就保證了其有著高并發讀性。由于數據分布在集群中的每個節點,當讀取數據時,系統可以并發的從每個節點上分段并行讀取文件,大大增加了獲取文件的速度。數據備份系統一個重要指標即是容災速度。如果出現生產事故,需要數據還原,HDFS所提供的幾乎無上限吞吐量一定能滿足需求。
2)高擴展性,由于采用廉價的硬件作為集群節點,所以當需要擴充存儲空間時只需要增加節點電腦數量即可。而且HDFS的提供不用重啟服務就可識別新加入的節點,并將其自動擴展到整個集群中。如果備份量下降,還可以將集群中的節點撤出,節約資源。
3)高容錯性,由于硬盤存在故障率,雖然不高,但是一旦出了問題,數據無法恢復將造成損失。HDFS有著數據備份副本策略。一旦數據上傳到集群上,數據就會自動備份,并把數據分發到不同的物理位置的節點上[9]。其自帶的數據一致性校驗可以確保文件數據不會損失。
3 性能測試
3.1 測試環境
由于備份客戶端性能需求較低,所以采用一臺筆記本電腦(CPU:I5M 雙核 2.67 GHz,內存:2 GB,硬盤 5 400 轉/分)。備份服務器采用一臺臺式電腦 (CPU:I5 3470四核3.2 GHz,內存:4 GB,硬盤7 200轉/分X2 Raid0)。HDFS集群采用3臺臺式電腦(CPU:I5 650雙核 3.2GGHz,內存 2 GB,硬盤7 200 轉/分)。
測試數據采用ZIP壓縮包(1GB,1個文件)和大量文件(1GB,1500個),采用一次全量備份和一次微小改動的增量備份進行測試。HDFS備份策略默認為3。
3.2 測試結果
測試主要針對不同數量文件的備份時間,備份文件重刪比進行了著重對比。如表2所示。
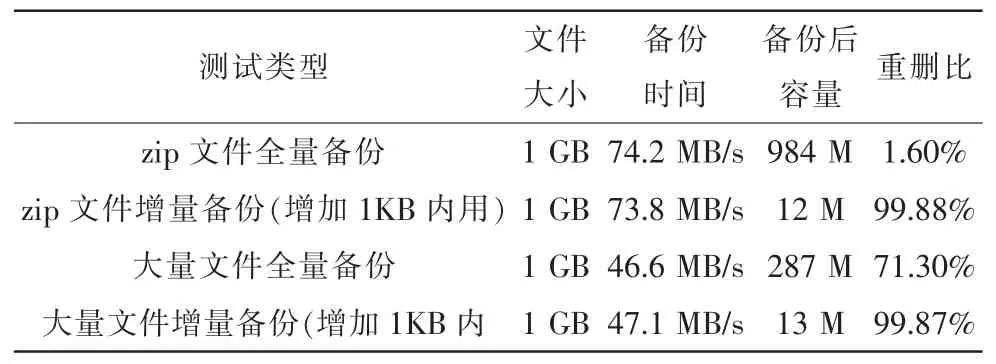
表2 測試結果Tab.2 Measurement result
3.3 分析
由表2可知,對于已經壓縮過的文件,如:ZIP,RAR等壓縮包,重刪效果不好,幾乎無法再次重刪。對于含有大量未壓縮文件的重刪效果很好,可以達到70%以上的重刪。對于增量備份可以只備份修改過的文件,大大增加了重刪效果。最終放在HDFS上的文件備份,在3個備份策略的情況下,備份2 GB(HDFS中為6 GB)文件、總的備份空間最好情況下可以節省到864 MB,節省率57%。備份服務器采用Raid0架構的雙硬盤陣列,在備份速度上可以達到70 MB/s。經測試如果采用單7 200轉/分的硬盤,備份速度將下降到37 MB/s。可以證明在服務器端采用更高性能的硬盤IO,將提高整個備份效果。大量小文件在IO上消耗了大量時間,實際備份速度不如單個大文件快。由于采用1 000 M網絡帶寬,HDFS節點間網絡帶寬未占滿,瓶頸出現在備份服務器端。
4 結 論
綜上所述,介紹了基于重復數據刪除技術與HDFS存儲系統結合的DDFS應用。傳統LAN-Free備份硬件投入高,HDFS存儲占用空間多。但在云備份時代,DDFS在備份效率和存儲占用率這兩個硬性指標上有著不錯的表現。借助HDFS分布式平臺的擴展能力,重刪的數據壓縮能力,有效控制了數據備份的成本。同時存在像對特定文件重刪率低、重刪性能不高、文件分塊不科學、不支持斷點備份、快照等問題,將成為DDFS下一步的研究對象。
[1]郭東,杜勇,胡亮.基于HDFS的云數據備份系統[J].吉林大學學報,2012,50(1):101-105.GUO Dong,DU Yong,HU Liang.HDFS based cloud data backup system[J].Journal of Jilin University,2012,50 (1):101-105.
[2]Rashid F,Miri A,Woungang I.A secure data deduplication framework for cloud environments[C].Department of Computer Science,2012,12:81-87.
[3]SUN Zhe,SHEN Jun,YANG Jian-ming.A novel approach to data deduplication overthe engineering-oriented cloud systems[J].Integrated Computer Aided Engineering,2013,20(1):45-57.
[4]鄭勝利.容災備份系統中備份服務器及系統安全機制的研究與實現[D].武漢:華中科技大學,2011.
[5]Chun-I Fan,HUANG Shi-yuan,Wen-che Hsu.Hybrid Data Deduplication in Cloud Environment[C].Department of Computer Science and Engineering,2012,12:174-177.
[6]王歡,李戰懷,張曉.支持連續數據保護的云備份系統架構設計[J].計算機工程與應用,2012,48(1):90-93.WANG Huan,LI Zhan-huai,ZHANG Xiao.Design of cloud backup system architecture supporting continuousdata protection [J].Computer Engineering and Applications,2012,48(1):90-93.
[7]杜勇.基于HDFS的云數據備份系統的設計與實現 [D].吉林:吉林大學,2011.
[8]蘇艷森.分布式文件存儲平臺文件備份與恢復系統設計與實現[D].杭州:浙江大學,2008.
[9]肖笑.基于BCC算法的多機系統PSS參數優化設計[J].陜西電力,2012(12):51-54.XIAO Xiao.Optimal design of multi-machine power system stabilizer parameters based on bacterial colony chemotaxis algorithm[J].Shaanxi Electric Power,2012(12):51-54.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
