OLAP在大學生首次職業類型選擇中的應用研究
2014-03-01 06:13:14王善勤孟龍梅王小林
吉林化工學院學報 2014年9期
王善勤,孟龍梅,王小林
(1.滁州職業技術學院信息工程系,安徽滁州239000;2.安徽工業大學計算機學院,安徽馬鞍山243032)
隨著信息技術的發展和大學生職業類型選擇相關數據量的增長,聯機事物處理技術已無法同時滿足高效作業和決策支持的需求,造成了海量數據與信息“孤島”的并存[1].近年來,對職業生涯領域的研究工作,國外已經比較深入全面[2],對職業、職業類型選擇及職業價值觀等方面做了深入地研究,國內在此方面的研究相對較淺、單一.國內外專家學者對OLAP技術在各行各業進行應用研究,但對國內大學生首次職業類型選擇的應用研究還是空白.目前,安徽工業大學的王善勤、王小林、陳業斌已對高職學生職業類型選擇數據倉庫進行了研究與構建.鑒于此,以安徽工業大學、滁州學院、滁州職業技術學院近三年畢業生首次選擇的職業類型與個人先天因素作為數據源來構建的數據倉庫為基礎,以OLAP技術為手段,建立了大學生首次職業類型選擇預測模型,對大學畢業生首次職業類型選擇進行預測與指導,能夠更好地為職業規劃指導師做好學生職業類型選擇指導工作提供依據參考.
1 OLAP介紹
聯機分析處理(OLAP)的概念最早是由關系數據庫之父 E.F.codd于1993年提出的:OLAP是使分析人員、管理人員或執行人員能夠從多角度對信息進行快速、一致、交互地存取,從而獲得對數據的更深入了解的一類軟件技術[3].OLAP主要是用來對用戶當前的及歷史的數據進行分析,完成大量的查詢操作,對時間的要求相對不高.OLAP的步驟如圖1所示.
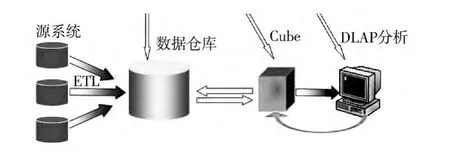
圖1 OLAP的步驟
2 數據預處理
如果數據倉庫中存在臟數據,決策分析系統也就失去根基.由于現實世界數據常存在含有噪聲、不完全的和不一致的現象,提高數據的質量是非常重要的[4].因此數據預處理是整個OLAP過程中一個非常重要的步驟.此文研究分析的數據來源于已構建好的數據倉庫,對數據倉庫中的數據集市數據進行進一步清洗,根據業務需要進行數據轉換.由于人的氣質、興趣、性格、職業類型做個絕對區分是一件比較復雜的事,所以在對數據進行OLAP之前必須針對先天因素影響下大學生職業類型選擇的主題進行數據的預處理.
2.1 數據清洗
(1)數據通常存在的問題.噪聲數據是指數據中存在著錯誤或異常的數據[5].比如,被測試人在心情最低谷或最高漲的時候,進行測試,數據可能存在一定波動,當情緒正常時,沒有參加測試,導致數據特別低(高).不完整數據是指感興趣的屬性沒有值[6].例如,有的工作人員在就業質量跟蹤調查時,沒有詳細統計就業崗位、在其崗位發展情況及綜合滿意度等.
(2)數據清理處理方法有平滑噪聲數據、填補遺漏的數據、識別或去除異常值及解決不一致問題幾種.例如存在問題的數據會給整個OLAP的過程注入無色無味的“毒藥”,會導致數據模型出現“畸形”,雖然OLAP過程大都能處理噪聲數據,但挖掘分析工作的重點常放在怎么避免結果過分逼近實驗數據上.
2.2 數據轉換
數據轉換是把一種格式的數據轉換為另一種格式的數據,并進行規范化,構成一個適合聯機分析處理的描述形式.此研究中數據轉換主要包括以下幾點:
(1)合計處理:對數據進行總結或合計操作,如學生氣質分值進行合計測試操作得到最后平均分值.
(2)規格化:有關屬性按比例進行縮放,將其定格在特定的小區域中.
2.3 數據屬性的選擇及預處理后數據
選擇數據的屬性,是在已有屬性集的基礎上構建新的屬性.屬性選取標準在決策樹領域可分屬性間相互獨立的選擇方法、屬性之間相互關聯的選擇方法兩類.文中使用屬性間相互獨立的選擇方法來確定關于大學生先天因素及首次選擇職業類型情況的數據表屬性,共有1個ID屬性,5個普通屬性,其中序號表示ID屬性,性別屬性表示學生的性別、氣質表示學生的氣質類別、性格表示學生的性格類別、興趣表示學生興趣類別、職業類型表示大學生首次選擇的職業類型.
對先天因素影響下大學生首次職業類型選擇為主題的數據信息進行預處理后,選取89條典型的樣本記錄.為了便于描述,序號字段屬性改為自動編號,種子值為1,增量值為1.如圖2所示.

圖2 “先天”條件下首次職業類型選擇信息
3 分析工具提供的算法在職業類型選擇中的應用
從目前企業的應用上來看,OLAP分析大多是通過使用OLAP工具來實現的,目前國內流行的OLAP工具主要有下列產品:Cognos(Powerplay)、Hyperion(Essbase)、微軟(Analysis Service)、MicroStrategy.綜合考慮大學生職業類型選擇需求和研究團隊的現狀,選用了微軟(Analysis Service)作為聯機處理分析工具.
3.1 分析工具提供的決策樹算法在首次職業類型選擇中的應用
微軟數據分析工具提供的決策樹算法是一種混合算法,它綜合了多種不同的創建樹的方法,并支持多種分析任務.本文使用Microsoft工具提供的決策樹算法在學生先天因素中找出性別、性格、氣質、興趣四個方面對首次職業類型選擇影響度情況,并能挖掘分析出相應規則.
3.1.1創建“先天”職業類型選擇模式的 OLAP模型
在Analysis Manager樹視圖的“挖掘結構”中建立挖掘結構;通過挖掘結構向導,選擇決策樹挖掘技術;指定定型數據;為挖掘結構命名,根據算法名命名為“決策樹算法”,即建立完成“決策樹算法”挖掘結構.
3.1.2 設置挖掘參數
在挖掘模型編輯器中,包含顯示模型和模型列的表,還包含一個屬性窗口中.用挖掘模型編輯器,可為每個模型設置算法特有的參數.右鍵單擊“Microsoft_Deccision_Trees”,在彈出的菜單中選擇“設置算法參數”.決策樹算法通過控制所生成的挖掘模型的性能和準確性.這些參數可控制樹的增長、樹的形狀和輸入/輸出屬性的設置.下面給出本算法的參數作一些分析與設置.
(1)COMPLEXITY_PENALTY,此參數控制決策樹的增長.值越小,則分叉數越多;值越大,則分叉數越少.在本次挖掘中,事務表中有六個字段屬性,符合要求的數據量不是很大,我們將此參數設置的比較小,即COMPLEXITY_PENALTY=0.01,進而控制樹的生長.
(2)MINIMUM_SUPPORT,此參數確定在決策樹中生成拆分所需的葉事例的最少數量.默認值為10.如果數據集非常大,則可能需要增大此值,以避免過度定型.比如將這個參數值設為6,表示任拆分而產生的子節點的個數至少有5個.由于職業類型有6種,經處理后數據量不是很大,我們將此參數值設置為1,即 MINIMUM_SUPPORT=1.
(3)SCORE_METHOD,此參數確定用于計算拆分分數的方法.該參數有三種可能的取值:SCORE_METHOD=1,說明該算法使用信息熵控制樹的增長.SCORE_METHOD=3,說明該算法使用Bayesian with K2 Prior方法,表示樹的節點中可預測屬性的每一個狀態增加一個常量,而無用考慮該屬性在樹中所處的層次.SCORE_METHOD=4,這是告訴算法使用Bayesian Dirichlet Equivalent(BDE)with uniform prior方法,這種取值也是默認值,根據樹節點的層次為每一個可預測的狀態增加權支持度.由于我們在建模過程中,使用的是信息熵的算法,因此選擇該參數值為1,即SCORE_METHOD=1.
(4)SPLIT_METHOD,此參數確定用于拆分節點的方法,該參數控制樹的形狀.該參數有三種可能的取值:SPLIT_METHOD=1,(Binary)指示無論屬性值的實際數量是多少,樹都拆分為兩個分支.SPLIT_METHOD=2,(Complete)指示樹可以創建與屬性值數目相同的分叉.SPLIT_METHOD=3,(Both)指定 Analysis Services可確定應使用binary還是 complete,以獲得最佳結果.這種取值也是默認值.
(5)FORCE_REGRESSOR,此參數強制算法將指定的列用作回歸量,此參數只用于預測連續屬性的決策樹.因為我們前期對數據進行大量操作,連續屬性已轉換成離散的屬性,所以此參數此處不做設置.
3.1.3 生成和部署
在開發窗口選擇“生成”菜單中的“部署”命令,出現“處理進度”提示框,提供有關處理操作的一些狀態信息.當處理完成后,可看到處理步驟的細節信息.現在數據挖掘模型部署好后,可以使用這些模型對大學生首次職業類型選擇進行深入分析研究,挖掘出相應規則供來預測新畢業生職業類型選擇情況.
3.1.4 分析研究挖掘出的職業類型選擇模型
微軟Analysis Services為每一個數據挖掘的算法都提供一個自己的查看器.“數據挖掘查看器”提供的實際模型視圖有兩種基本的類型,即圖和表.
(1)職業類型選擇測評依賴關系
依賴關系網絡顯示決策樹模型中所有屬性之間的關系,這些屬性派生自決策樹模型的內容.如圖3所示.圖中線上編號代表各維度與職業類型之間存在關聯強度排序,由此可看出職業類型選擇受興趣影響最強,依次是性格、氣質、性別.
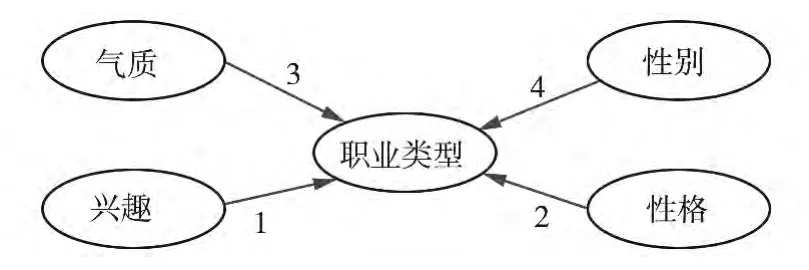
圖3 決策樹模型依賴關系
(2)挖掘模型
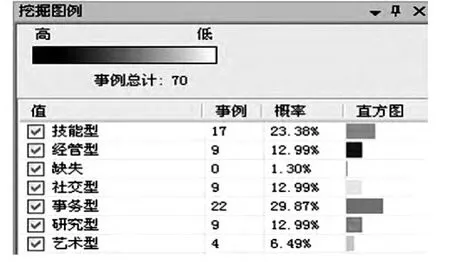
圖4 挖掘圖例
技能型、經管型、社交型、事務型、研究型、藝術型,下面給出大學生首次職業類型選擇社交型決策樹模型,如圖5所示.
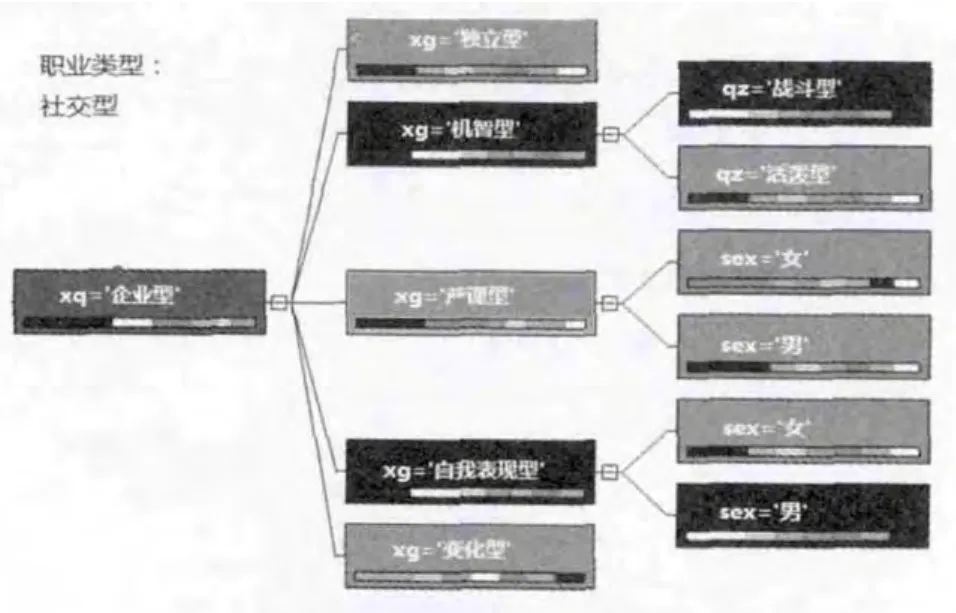
圖5 職業類型為社交型的典型決策樹模型
圖5中的樹是水平擺放的,最左邊是分類節點較突出分類因素;節點著色各有不同,著色深的節點是支持事例較多的.決策樹的模型所反映出來的規則非常容易理解,每一條從最左邊節點到最右邊的葉子節點就是一條規則.
3.1.5 挖掘準確性分析
微軟的商業智能開發平臺提供“挖掘準確性圖表”窗格,以用來衡量所創建模型的質量和精確性.圖6是決策樹算法挖掘模型的提升圖,此圖顯示了挖掘模型的整體預測準確性與理想模型的對比.此圖的橫坐標表示比較預測的測試數據集的百分比,縱軸表示準確預測的百分比.從圖中可以觀測到一條對角線,使用50%的數據來獲得50%的目標,此挖掘模型總體準確度是相當高的.

圖6 決策樹算法挖掘模型的提升圖
此決策樹模型在50%的數據中的預測準確率為47.14%,當數據量是100%時,此模型的預測準確率達到94.29%.
3.1.6 結果分析
從以上挖掘結果可以分析出,大學生首次職業類型選擇與興趣存在很大內在的關聯度.由此得出結果,興趣對大學首次職業類型選擇影響最大.通過對學生興趣、性格、氣質、性別情況預測大學生的首次職業類型選擇情況進行數據挖掘分析.大學生為了更好做好首次職業類型選擇,要加強自己興趣培養,進而做好職業規劃,最終能實現“人職匹配”.從分析可看出,個人性格、氣質對高職學生職業類型選擇也有一定影響,性別對職業類型選擇影響并不是很大.
3.2 分析工具提供的關聯規則算法在職業類型選擇中的應用
在Analysis Manager中創建模型及相關設置如上,這里不在贅述,直接分析結果.3.2.1 職業類型選擇測評依賴關系
依賴關系如圖7所示.連接線上數字表示關聯強度,1表示是最強,8表示最弱.
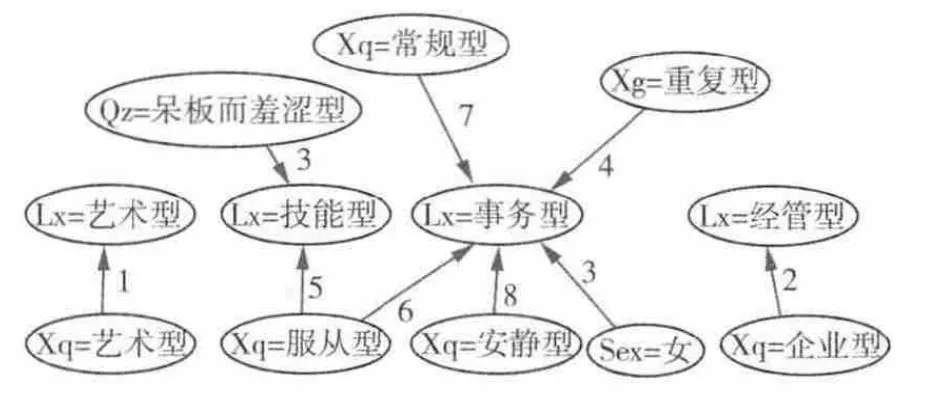
圖7 關聯規則模型依賴關系
3.2.2 挖掘模型
圖8顯示了大學畢業生職業類型選擇關聯規則模型.
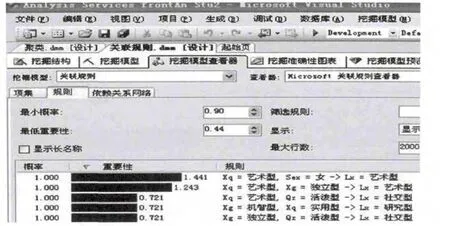
圖8 關聯規則模型
3.2.3 挖掘準確性分析
圖9給出關聯規則模型的提升圖.圖9展示了這個挖掘模型的提升圖,從圖中可以看出,準確度良好.此實際決策樹模型在50%的數據中的預測準確率分別為47.14%,而當數據量達到100%時,該模型的預測準確率為68.57%.
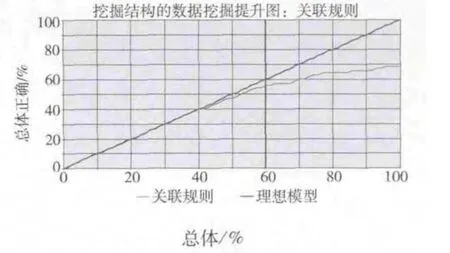
圖9 關聯規則模型的提升圖
3.2.4 結果分析
從以上挖掘結果可以分析出,大學畢業生職業類型選擇與個人先天因素存在一些內在的規則.由此同樣得出結果,興趣對大學生畢業生首次職業類型選擇影響最大,個人性格、氣質對高職學生職業類型選擇也有一定影響.
4 職業類型選擇數據挖掘規則提取及分析
通過對以上兩個模型進行分析,得出大學畢業生首次職業類型選擇與人的興趣、性格、氣質、性別有一定的關聯,提取支持率比較高的規則,可供職業規劃指導師參考、大學生首次職業類型選擇的決策支持;將上述結論應用到高等院校職業類型選擇專家指導系統中,也進一步推進高等院校職業規劃工作信息建設.興趣用Xq表示,性格用Xg表示,性別用Sex表示,氣質用Qz表示,職業類型用Lx表示;表示部分規則如下:
If Xq=企業型and Xg=嚴謹型and Sex=男then Lx=經管型
If Xq=企業型 and Xg=自我表現型 and Sex=女then Lx=經管型
If Xq=實用型and Xg=重復型and Qz=活潑型then Lx=事務型
If Xq=常規型and Qz=安靜型and Xg=服從型then Lx=事務型
If Xq=研究型and Xg=變化型and Qz=活潑型then Lx=研究型
If Xq=研究型and Xg=協作型and Qz=戰斗型then Lx=研究型
If Xq=藝術型and Sex=女then Lx=藝術型
If Xq=實用型and Qz=戰斗類型then Lx=社交型
If Xg=嚴謹型and Xq=實用型then Lx=社交型
If Xq=研究型and Xg=自我表現型then Lx=技能型
If Xq=實用型and Xg=獨立型and Xg=Qz=安靜型and Sex=男then Lx=技能型
If Xq=常規型and Qz=呆板而羞澀型then Lx=技能型
……
5 結 論
將OLAP技術應用到大學生首次職業類型選擇指導的實際工作中,為做好高校學生職業生涯規劃工作提供新思路.利用微軟數據分析工具提供的決策樹算法、關聯規則算法創建兩個模型并進行對比分析出學生的興趣、性格、氣質、性別與首次選擇的職業類型存在的潛在規律,挖掘出興趣對大學生首次職業類型選擇影響較大等許多有參考價值的成果.但仍存在研究數據不夠豐富、數據處理過程繁瑣等,所以還有待進一步研究.
[1] 張美虎,等.OLAP工具在企業決策支持系統中的應用[J].淮陰工學院學報,2009,(1):55-56.
[2] 康雁冰.職業發展與大學生職業規劃[J].創新與創業教育.2012,3(6):29-30.
[3] 容曉暉.基于數據挖掘的郵政業務量收系統改進方案研究[D].沈陽:東北大學,2009:6-7..
[4] 徐娟.基于數據挖掘技術的信用評估模型研究[D].合肥:合肥工業大學,2009:4-5.
[5] 馬勇.惡意網頁的分析及識別方法研究[D].天津:南開大學,2008:11-12.
[6] 周成義.數據挖掘技術在電子商務企業中的研究與應用[D].鞍山:遼寧科技大學,2007:3-4.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
下一代英才(酷炫少年)(2019年3期)2019-03-25 02:34:18
電子制作(2018年18期)2018-11-14 01:48:24
黃河之聲(2017年14期)2017-10-11 09:03:59
電力與能源(2017年6期)2017-05-14 06:19:37
山東工業技術(2016年15期)2016-12-01 05:31:22
信息通信技術(2015年6期)2015-12-26 01:16:46
電子設計工程(2014年18期)2014-02-27 12:00:13
中國火炬(2013年7期)2013-07-24 14:19:23
