二分類數(shù)據(jù)缺失多重填補(bǔ)分析及應(yīng)用*
2014-03-10 05:25:11山西醫(yī)科大學(xué)公共衛(wèi)生學(xué)院衛(wèi)生統(tǒng)計教研室030001陳培翠張翠仙羅天娥劉桂芬
中國衛(wèi)生統(tǒng)計 2014年3期
山西醫(yī)科大學(xué)公共衛(wèi)生學(xué)院衛(wèi)生統(tǒng)計教研室(030001) 張 耀 陳培翠 張翠仙 羅天娥 劉桂芬
二分類數(shù)據(jù)缺失多重填補(bǔ)分析及應(yīng)用*
山西醫(yī)科大學(xué)公共衛(wèi)生學(xué)院衛(wèi)生統(tǒng)計教研室(030001) 張 耀 陳培翠 張翠仙 羅天娥 劉桂芬△
目的闡明四種填補(bǔ)方法(multiple imputation,M I)的基本原理,實(shí)例介紹縱向研究二分類缺失數(shù)據(jù)多種填補(bǔ)方法的應(yīng)用。方法對比分析簡單填補(bǔ)、分層填補(bǔ)、考慮個體差異的填補(bǔ)及考慮個體、抽樣的多重填補(bǔ)等四種填補(bǔ)方法;模擬證實(shí)幾種OR取值的敏感性分析。結(jié)果進(jìn)行大樣本(N=10000)模擬研究表明:簡單多重填補(bǔ)分析會降低檢驗效能,不能客觀反應(yīng)兩樣本的差異;考慮先前信息的分層多重填補(bǔ)會擴(kuò)大I型錯誤;若只考慮個體變異,僅模擬一個數(shù)據(jù)集,所得結(jié)論不穩(wěn)定;在考慮個體、抽樣和填補(bǔ)差異后模擬的多重填補(bǔ)數(shù)據(jù)集,當(dāng)OR≈2時,所得統(tǒng)計量基本接近真值;實(shí)例驗證,經(jīng)高血壓知曉干預(yù)后,尚不能認(rèn)為兩區(qū)的吸煙率有差別。結(jié)論不考慮前次觀察數(shù)據(jù)以及OR值的影響,一味地把缺失值當(dāng)作該事件發(fā)生處理,會加大I型錯誤;只有綜合考慮個體、抽樣和填補(bǔ)差異,多重填補(bǔ)數(shù)據(jù)集的估計結(jié)果才更具穩(wěn)健性。
多重填補(bǔ) 縱向研究 二分類數(shù)據(jù)缺失 效果評價
數(shù)據(jù)缺失是縱向研究中普遍存在的問題,盲目地對缺失數(shù)據(jù)進(jìn)行處理,會喪失原資料蘊(yùn)藏的信息,甚至得出錯誤的結(jié)論。公共衛(wèi)生研究中,有關(guān)藥物依賴、酗酒、吸煙等針對個體縱向監(jiān)測的干預(yù)效果的評價,二分類數(shù)據(jù)缺失是多見的一種形式。有關(guān)二分類缺失數(shù)據(jù)處理的統(tǒng)計方法,已有非技術(shù)性文獻(xiàn)發(fā)表[1],但由于這些方法未能在標(biāo)準(zhǔn)分析軟件中方便實(shí)施,其研究尚有較大空間。本文擬針對二分類數(shù)據(jù)缺失多重填補(bǔ)問題介紹四種方法。
原理與方法
對于本文,形如nabcd,下角標(biāo)中第一個值a表示前一觀測時間點(diǎn)t0的觀測結(jié)果是否存在某種行為,賦值:是=1,否=2;下角標(biāo)b表示最后觀測時點(diǎn)是否缺失,賦值:是=1,否=2;下角標(biāo)c表示最后一次觀測結(jié)果是否存在某種行為,賦值:是=1,否=2;d表示分組情況;下角標(biāo)“.”表示兩水平行或列的合計;t0表示首次觀測某種行為時刻,t1表示干預(yù)后終點(diǎn)觀測時刻。
1.二分類數(shù)據(jù)缺失多重填補(bǔ)原理
(1)簡單多重填補(bǔ)法(simple M I)
對單一時間點(diǎn),不考慮前一時刻t0觀測結(jié)果,根據(jù)最終觀測結(jié)果二分類效應(yīng)變量如吸煙與否,是否有數(shù)據(jù)缺失,可列成四格表,其優(yōu)勢比OR=(n11/n12)/(n21/n22),式中n22表示非吸煙組觀察單位數(shù);n21表示吸煙組非缺失個體數(shù),缺失值n12和n11是未知的,其推算式記作:

若將缺失均看作是吸煙,n12=0,n11=n1(“.”表示行或列合計所有缺失個體),則OR值趨于+∞。顯然,關(guān)于OR值更合理的假設(shè)是有限的。當(dāng)n21/n22值已知,若設(shè)定OR值,由式(1)可估算出缺失數(shù)據(jù)中吸煙與非吸煙的觀察單位數(shù)。同理將式(1)轉(zhuǎn)換為:
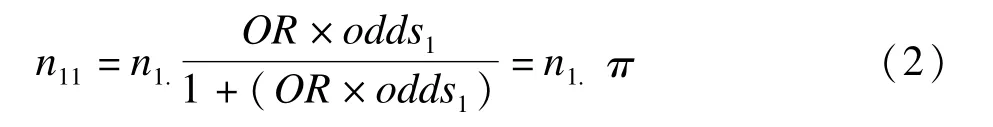
式(2)中,odds1:實(shí)際觀察到吸煙個體的優(yōu)勢(n21/n22);π:優(yōu)勢比為OR值時,數(shù)據(jù)缺失者中吸煙者所占比例,即n11=n1.π。
(2)考慮先前信息的分層多重填補(bǔ)
考慮先前信息的多重填補(bǔ)(consider previous information MI)中,LOCF(last observation carried forward)是目前眾多研究中常用的填補(bǔ)技術(shù),因其原理不合邏輯被廣泛批評[2],它是將最后一次得到的干預(yù)效應(yīng)作為其觀察終點(diǎn)。按終點(diǎn)觀測前一時刻t0觀察結(jié)果分層,設(shè)某層數(shù)據(jù)缺失值中吸煙者所占比例為πi,即

式中,oddi:第i層(i=1,2,…,k)終點(diǎn)非缺失個體吸煙者的優(yōu)勢。
(3)考慮個體差異的多重填補(bǔ)
盡管分層多重填補(bǔ)考慮了前一時間點(diǎn)觀測結(jié)果對本次結(jié)果的影響,但仍沒有考慮由于個體變異對觀察結(jié)果的影響。若在分層條件下再考慮個體變異的多重填補(bǔ)(consider individual variation M I)可用潛變量logistic回歸模型[3]表示:
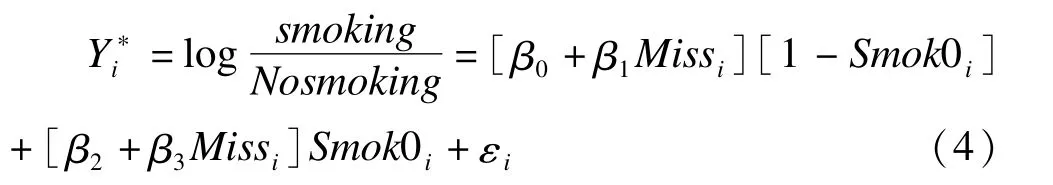
式中,εi:個體差異;Miss:數(shù)據(jù)缺失=1,反之賦值為0;Smok0i:當(dāng)前次觀察結(jié)果為吸煙者,賦值為1,反之為0;β0表示t0時刻不吸煙,t1時刻非缺失其吸煙的優(yōu)勢對數(shù)值;β2:表示t0時刻吸煙,t1時刻非缺失其吸煙的優(yōu)勢對數(shù)值;β1表示t0時刻不吸煙,t1時刻缺失其吸煙的優(yōu)勢比對數(shù)值,β3:表示t0時刻吸煙,t1時刻缺失其吸煙的優(yōu)勢比對數(shù)值(可通過設(shè)定的OR值來表示)設(shè)為個體i的潛變量,記臨界值為γ,如果Y*>γ,Y=1,否則Y=0。通過設(shè)置logistic回歸模型臨界值γ=0,假定誤差εi服從標(biāo)準(zhǔn)logistic分布(均數(shù)=0,方差為π2/3)[4],對原缺失數(shù)據(jù)按式(4)進(jìn)行合理填補(bǔ),即可將個體變異考慮入填補(bǔ)過程,使具有相同協(xié)變量的受試者賦有不同的吸煙概率,該填補(bǔ)也稱為隨機(jī)回歸填補(bǔ)[5]。
(4)考慮樣本變異的多重填補(bǔ)
基于填補(bǔ)過程中考慮樣本的變異(consider sampling variation M I),可用常規(guī)logistic回歸來預(yù)測二分類結(jié)果。t0時刻非吸煙個體分層回歸參數(shù)的方差協(xié)方差估計如下:
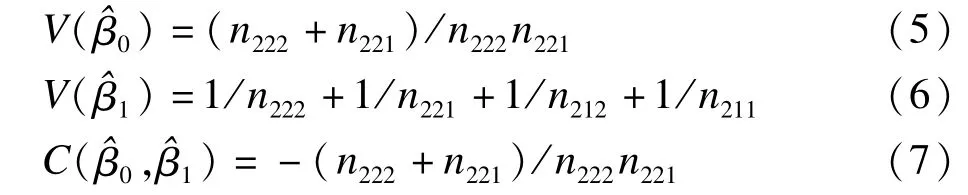
同理,t0時刻吸煙個體分層回歸參數(shù)的方差協(xié)方差估計類似;我們用表示t0時刻非吸煙者估計的參數(shù)向量的估計方差-協(xié)方差;假定從均數(shù)為和方差-協(xié)方差為的總體中進(jìn)行隨機(jī)抽樣得到的參數(shù)。按上述過程,同樣可獲得t0組吸煙者的回歸系數(shù)同理,從均數(shù)為(即t0組吸煙者回歸系數(shù)向量為和方差-協(xié)方差矩陣總體中進(jìn)行隨機(jī)抽樣得到的參數(shù)(即用n1ij代替n2ij估計得到參數(shù))模型表述如下:
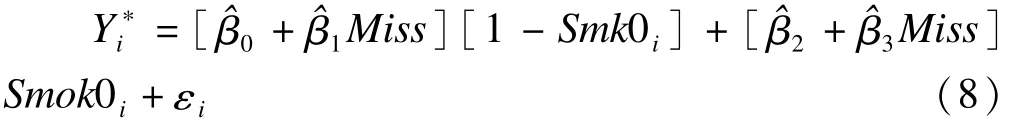
將連續(xù)潛變量Y*轉(zhuǎn)化為二分類變量yi,與前規(guī)則相同,進(jìn)行多次重復(fù)隨機(jī)填補(bǔ),建立多個模擬數(shù)據(jù)集,即可對感興趣的效應(yīng)變量進(jìn)行統(tǒng)計分析與評價。
有關(guān)上述四種方法的模擬證實(shí),無論采用不同的OR值,還是隨機(jī)獲得填補(bǔ)100次的模擬數(shù)據(jù)集,均可采用SAS9.2編程來實(shí)現(xiàn)。
2.大樣本模擬研究
進(jìn)行大樣本(N=10000)模擬研究表明:簡單多重填補(bǔ)分析會降低檢驗效能,不能客觀反應(yīng)兩樣本的差異;考慮先前信息的分層多重填補(bǔ)會擴(kuò)大I型錯誤;考慮個體差異的多重填補(bǔ)所得結(jié)果極不穩(wěn)定;考慮個體變異樣本變化的多重填補(bǔ)分析結(jié)果最接近真實(shí)值,且OR≈2時,所得統(tǒng)計量基本接近真值。
實(shí)例研究
1.六社區(qū)吸煙干預(yù)數(shù)據(jù)缺失情況分析
以全國社區(qū)高血壓規(guī)范化管理項目太原分中心研究數(shù)據(jù)為例,收集2007-2008年間太原市迎澤區(qū)(師范中心社區(qū)、廟前社區(qū)和棉花巷社區(qū))與杏花嶺區(qū)(東華苑社區(qū)、敦化坊社區(qū)和杏花嶺社區(qū))管理的518例高血壓患者為研究對象;根據(jù)項目組對高危患者實(shí)行社區(qū)高血壓三級管理要求,一年內(nèi)應(yīng)進(jìn)行六次隨訪;以基線調(diào)查中非藥物治療是否吸煙為t0時刻觀測結(jié)果,以第五次隨訪吸煙狀況為干預(yù)后終觀測結(jié)果。經(jīng)兩地區(qū)基線資料吸煙率比較,χ2=0.914,P=0.339,尚不能認(rèn)為兩區(qū)患者的吸煙率有差別。按項目規(guī)范管理要求,經(jīng)對患者每月集中實(shí)施高血壓知識、態(tài)度和行為等規(guī)范管理干預(yù)后,進(jìn)行干預(yù)效果評價。
通過對兩區(qū)六個社區(qū)第五次終隨訪結(jié)果吸煙情況分析可知,迎澤區(qū)實(shí)施三級規(guī)范化管理的高血壓患者261例,第五次檢測中數(shù)據(jù)缺失95例,缺失比例36.40%;杏花嶺區(qū)管理257例,第五次檢測中數(shù)據(jù)缺失132例,缺失比例51.36%,兩組缺失數(shù)據(jù)平均占高血壓規(guī)范管理患者的43.8%。
2.二分類數(shù)據(jù)缺失四種多重填補(bǔ)方法對比研究
(1)簡單多重填補(bǔ)法分析

表1 兩區(qū)終隨訪數(shù)據(jù)缺失關(guān)系分析
由基線資料分析,迎澤區(qū)吸煙率75/166=45.1%,杏花嶺區(qū)吸煙率71/125=58.8%,經(jīng)Pearson卡方檢驗χ2=3.851,P=0.0498,可認(rèn)為兩地區(qū)吸煙率有差別。若采用簡單多重填補(bǔ),將缺失個體均假設(shè)為吸煙,迎澤區(qū)和杏花嶺區(qū)的吸煙率分別為(75+95)/261=65.13%和(71+132)/257=78.99%,經(jīng)兩區(qū)終隨訪吸煙率比較χ2=12.331,P<0.01,盡管統(tǒng)計分析結(jié)論一致,但卡方值有很大的差別。可見把缺失值均看做吸煙(或不吸煙)的假設(shè),給兩區(qū)高血壓知曉干預(yù)效果的評價解釋帶來較大的困惑。因兩區(qū)數(shù)據(jù)缺失比重不同,這樣將數(shù)據(jù)缺失值都看作吸煙,顯然不合理。若考慮數(shù)據(jù)缺失與吸煙率的關(guān)系,分別將OR取值設(shè)為1、3、5、7(即缺失數(shù)據(jù)的吸煙優(yōu)勢是已觀測個體的1倍、3倍……),若OR=1,則π=1×[(71+75)/(54+91)]/(1+1×[(71+75)/(54+91)])=0.502,即當(dāng)缺失與吸煙關(guān)系獨(dú)立;表明缺失數(shù)據(jù)中吸煙率50.2%,則迎澤區(qū)缺失數(shù)據(jù)中吸煙數(shù)為n11=95×0.502=47.69;同理,不同OR取值條件下,可填補(bǔ)杏花嶺區(qū)缺失數(shù)據(jù)中吸煙與非吸煙觀察單位數(shù),見表2。

表2 4種邊際OR取值對兩組吸煙率的影響分析
表2簡單填補(bǔ)法分析結(jié)果可見,邊際OR取值不同,對分析結(jié)果有影響,隨邊際OR值的增大,更趨于得出兩組吸煙率差別有統(tǒng)計學(xué)意義的結(jié)論。
(2)分層多重填補(bǔ)分析
若考慮第一時點(diǎn)(基線)與終觀測結(jié)果間的關(guān)聯(lián)性,即基于t0時刻吸煙(Smok0)信息進(jìn)行分層分析,結(jié)果整理如表3。

表3 按Smok0分層多重填補(bǔ)分析
表中,基線調(diào)查不吸煙者中,終隨訪結(jié)果迎澤區(qū)缺失n21.y=n212y+n211y=62,杏花嶺區(qū)缺失n21.x=n212x+n211x=64;同理,基線調(diào)查為吸煙者中,迎澤區(qū)缺失n11.y=n111y+n112y=33,杏花嶺區(qū)缺失n11.x=n111x+n112x=68。仍假定OR=1,π1=(141/137)/[1+(141/137)]=0.2303;π2=0.9292。進(jìn)行不同OR取值假定下的分層填補(bǔ),結(jié)果對比見表4。

表4 兩區(qū)不同OR取值分層多重填補(bǔ)結(jié)果分析
表4OR取值分別為1,3,5,7的分層多重填補(bǔ)結(jié)果表明,OR=1時,表明數(shù)據(jù)缺失與效應(yīng)變量間關(guān)系相互獨(dú)立,而OR=7表明兩者間關(guān)聯(lián)性較強(qiáng)。結(jié)果可見,簡單填補(bǔ)法更易把分析結(jié)果推斷為有統(tǒng)計學(xué)意義,而分層填補(bǔ)在數(shù)據(jù)缺失與效應(yīng)變量有關(guān)聯(lián)時,它可更客觀地反映出分層OR值遠(yuǎn)比邊際OR值的影響小,也即干預(yù)后效應(yīng)變量是否有統(tǒng)計學(xué)意義,其結(jié)果也取決它與缺失數(shù)據(jù)間的關(guān)聯(lián)性,即將缺失值均看做吸煙的假設(shè)掩蓋了OR取值的影響。
(3)考慮個體變異的多重填補(bǔ)分析
假定誤差分布服從均數(shù)=0,方差為π2/3的logistic分布[4],按式(4)來擬合logistic回歸模型,對所產(chǎn)生的數(shù)據(jù)集進(jìn)行分析,模擬分析結(jié)果見表5。

表5 考慮個體變異四種OR取值兩組結(jié)果比較
考慮個體變異,OR分別取值1、3、5、7時分析結(jié)果對比表明,由于存在個體變異,不能單純考慮OR取值對數(shù)據(jù)缺失與效應(yīng)變量間關(guān)系的影響,尚應(yīng)計算考慮個體變異情況下含有數(shù)據(jù)缺失信息吸煙的概率,它是目前填補(bǔ)方法中既考慮邏輯關(guān)系,又考慮分析效果解釋的首選方法。
(4)考慮個體變異樣本變化的多重填補(bǔ)分析
在考慮個體變異的情況下,重復(fù)隨機(jī)填補(bǔ)過程100次生成多重填補(bǔ)數(shù)據(jù)集,并進(jìn)行兩區(qū)干預(yù)后吸煙率的比較。

表6 考慮個體變異和四種OR取值樣本變化情況的兩組比較
填補(bǔ)進(jìn)行100次,OR取值為1、3、5、7時,計算檢驗統(tǒng)計量與對應(yīng)的P值。需要注意的是,相同OR取值時,其卡方值均小于沒有考慮個體、抽樣和填補(bǔ)差異的卡方值,P值均大于表4、表5的概率P值。由此可知,同時考慮抽樣、隨機(jī)填補(bǔ)和個體變異,且OR取值低于5時,兩區(qū)高血壓規(guī)范管理對吸煙知行干預(yù)效果尚不能認(rèn)為有差別;而OR取值不同對應(yīng)的敏感性分析結(jié)果有差別。
小 結(jié)
二分類數(shù)據(jù)缺失的處理方法有多種,常規(guī)分析多將未觀測到的結(jié)果看作是二分類結(jié)果中的任一種結(jié)局(如視為吸煙),這樣不僅“保守”,且顯然不符合邏輯。“前面觀測結(jié)果決定終觀察結(jié)果”的LOCF分析,在OR值大于3時,更易得出差別有統(tǒng)計學(xué)意義的結(jié)論;考慮前觀測結(jié)果對后干預(yù)效果的關(guān)聯(lián)性時,隨OR取值增大,更有可能得出差別有統(tǒng)計學(xué)意義的結(jié)果。若僅考慮個體變異,只模擬單個數(shù)據(jù)集進(jìn)行缺失數(shù)據(jù)分析,在OR取值不同的情況下,均可見統(tǒng)計結(jié)果不穩(wěn)定。當(dāng)考慮個體、抽樣和多重填補(bǔ)變異,采用多重填補(bǔ)其分析結(jié)果解釋更符合實(shí)際。因此推知,考慮個體變異、樣本變化的多重填補(bǔ)方法是以上四種方法中值得推崇的缺失數(shù)據(jù)分析方法。
高血壓知行干預(yù)后吸煙缺失多是因受試者主觀因素造成的,其數(shù)據(jù)缺失個體大多是干預(yù)后仍處于吸煙狀態(tài),因此認(rèn)為吸煙與數(shù)據(jù)缺失間的假設(shè)是合理的。通過OR取值為1、3、5、7的多重填補(bǔ)100次模擬證實(shí),隨OR取值增大,更易得出差別有統(tǒng)計學(xué)意義的結(jié)論,即可認(rèn)為該數(shù)據(jù)缺失與OR取值有關(guān)聯(lián)。而考慮個體、抽樣和多重填補(bǔ)變異時,當(dāng)吸煙優(yōu)勢比較大(OR取值大于5),才有可能得出兩區(qū)干預(yù)效果差別有統(tǒng)計學(xué)意義的結(jié)論,分析結(jié)果更具說服力,結(jié)論更穩(wěn)健。
總之,單一終點(diǎn)二分類數(shù)據(jù)缺失,考慮個體、抽樣和填補(bǔ)差異的影響進(jìn)行多重填補(bǔ)是二分類缺失數(shù)據(jù)分析值得推崇的一種方法。本方法類似于加權(quán)估計方程處理缺失數(shù)據(jù)[6-7]的原理,利用已觀測到的信息對缺失數(shù)據(jù)賦予合理權(quán)重,進(jìn)而進(jìn)行填補(bǔ);考慮前次觀測情況以及優(yōu)勢比OR取值的影響,對干預(yù)后單時點(diǎn)干預(yù)效果進(jìn)行評價的影響是值得關(guān)注的。有關(guān)考慮個體、抽樣和多重填補(bǔ)差異的多時點(diǎn)干預(yù)效果評價中結(jié)構(gòu)數(shù)據(jù)缺失的分析方法研究有待進(jìn)一步探討。
1.Abraham W.T.,Russell D.W.M issing data:a review of currentmethods and applications in epidemiological research.Curr Opin Psychiatry,2004,17:315-321.
2.Siddiqui O,Hung HM.MMRM vs.LOCF:a comprehensive comparison based on simulation study and 25 NDA datasets.JBiopharm Stat,2009,19:227.
3.Donald H,Robin J,Hakan D.Analysis of binary outcomes w ith m issing data:m issing=smoking,last observation carried forward,and a little multiple imputation.Methods and techniques,2007,10:1565-1569.
4.Long JS.Regression Models for Categorical and Lim ited Dependent Variables.Thousand Oaks,CA:Sage Publications,1997:42.
5.Little RJA,Rubin DB.Statistical Analysis w ith M issing Data,2nd edn.New York:Wiley,2002.
6.張偉,馮萍,趙永紅.加權(quán)估計方程用于缺失數(shù)據(jù)的處理.中國衛(wèi)生統(tǒng)計,2013,30(3):435-437.
7.帥平,李曉松,周曉華.缺失數(shù)據(jù)統(tǒng)計處理方法的研究進(jìn)展.中國衛(wèi)生統(tǒng)計,2013,30(1):137.
(責(zé)任編輯:郭海強(qiáng))
The M ultiple Im putation and App lication in Binary LongitudinalM issing Data
Zhang Yao,Chen Peicui,Zhang Cuixian,et al(DepartmentofHealthStatistics,SchoolofPublicHealth,ShanxiMedicalUniversity(030001),Taiyuan)
ObjectiveTo clarify the basic principles of themultiple imputation(M I),wew ill introduce severalmethods w ith examples.MethodsCompare the analysis of four M Imodel,i.e.(1)simple M I.(2)Stratified M I.(3)The M Iwhich consider individual differences.(4)Perform the comprehensive analysis considering the individual,sampling and imputation.Carry outsensitivity analysis under different imputation sample,using SAS 9.2 to complete M I.ResultsLarge sample(N=10000)simulation show that:simple multiple imputation analysis w ill reduce the ability of performance test,it can not response the difference between two samples.themultiple imputation analysis which considering the previous information w ill expand type I error.If only considerate the individual variability and simulate a data set,the conclude w ill be not stable;considerate the individual variability,sampling,and filling difference,whenOR≈2,the statistics result are close to the true value.We finally still can not believe that the rate of smoking are unequal between the two areas though the example of hypertension awareness intervention.ConclusionWhen we regard them issing as the event,therew ill increase the probability of type Ierror.When we consider the difference of individual,sampling and multiple imputation,we w ill draw amore robust parameter estimation.
M I;Longitudinal study;Binary m issing data;Evaluation
*:國家自然科學(xué)基金項目(編號81172774);國家青年科學(xué)基金項目資助(81001294);太原市大學(xué)生創(chuàng)新創(chuàng)業(yè)專題(120164023)
△通信作者:劉桂芬,E-mail:liugf66@126.com
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
民用飛機(jī)設(shè)計與研究(2020年4期)2021-01-21 09:15:02
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
少兒科學(xué)周刊·少年版(2015年3期)2015-07-07 21:00:00
中國中醫(yī)藥現(xiàn)代遠(yuǎn)程教育(2014年11期)2014-08-08 13:23:44
