基于鄰域粗糙集的入侵檢測集成算法
2014-04-03 01:45:38魏峻
計算機工程與應用 2014年10期
關鍵詞:檢測
魏 峻
WEI Jun
陜西理工學院 數學與計算機科學學院,陜西 漢中 723000
School of Mathematics and Computer Science,Shaanxi University of Technology,Hanzhong,Shaanxi 723000,China
1 引言
入侵檢測是一種重要的主動網絡安全技術,可有效發現來自網絡外部與內部誤操作引起的攻擊,它與防火墻等靜態安全技術配合使用,有效提高網絡的安全性。
入侵檢測領域獲得的數據具有自身的特點:(1)非線性特點;(2)高維數特點;(3)高噪聲與高冗余特點;(4)連續型特點。以上的這些特點導致了通常的模式分類算法不能有效地應用于入侵檢測領域。針對數據非線性以及復雜性的特點,使得數據往往并不服從一些已知分布,這就使得傳統的分類方法并不能很好地應用于該領域,機器學習方法通過對樣本的訓練來掌握數據背后所掩蓋的規則,因而被廣泛應用于入侵檢測領域。其中神經網絡和支持向量機是兩種常用的對非線性問題非常有效的處理方法。但是神經網絡本質是一種局部搜索方法,易陷入局部極小化,收斂速度較慢及拓撲結構難確定等不足。而支持向量機是建立在統計學習理論基礎上,以結構風險最小化為原則的機器學習方法,具有結構簡單、全局優化、收斂速度快及泛化性能好的優點,能很好地解決非線性問題。陳光英等[1-4]采用SVM進行入侵檢測,獲得了較好效果,顯示了SVM優于其他分類算法的性能。但是支持向量機的分類性能往往受到參數影響,不同的參數所獲得的分類性能也不一樣,單個分類器所獲得的結果易陷入局部最優,這就使得這種單一分類器存在可靠性與穩定性差的問題,為解決這個問題,引入了集成技術[5-8]。集成技術是使用一系列分類器進行學習,并使用某種規則把各分類結果進行合成從而獲得比單個分類器有更好學習效果的一種機器學習方法。采用多分類器集成,各個基分類器可能在解空間的不同局部區域進行搜索,其最終合成的搜索結果往往是共同趨于某個實際目標,既提高了算法的穩定性與可靠性,又增強了算法的泛化性能。
由于入侵檢測數據具有高維性,且含有大量的噪聲與冗余屬性,這些屬性的存在會降低檢測的效果和效率,所以屬性約簡是提高入侵檢測性能的有效途徑。其中粗糙集是一種常用且有效的屬性約簡方法。蔡忠閩等[9-13]把粗糙集引入到入侵檢測中,進一步提高檢測效果。但傳統粗糙集不能直接處理連續型數據,需要對連續型數據離散化,這一處理過程必然會帶來信息丟失,影響檢測效果。鄰域粗糙集(Neighborhood Rough Set)[14-18]是對經典粗糙集理論的改進,它能夠直接處理連續型數據,而不需要事先對連續數據進行離散化處理,這就避免了離散化過程帶來的信息損失問題,使獲得的屬性子集具有更強的泛化性能。
基于以上分析,首先采用Bagging算法[19]進行訓練樣本擾動,然后利用具有不同半徑的鄰域粗糙集模型進行特征擾動實現屬性約簡,這樣既能增大訓練子集的差異性,又能獲得具有較高精度的訓練子集,然后在這些訓練子集上訓練支持向量機基分類器,最后根據各基分類器的檢測精度進行加權集成。通過在KDD99數據集上進行仿真實驗來驗證算法的有效性和實用性。
2 鄰域粗糙集模型
粗糙集[9]是一種刻畫不完整性和不確定性的數學工具,能有效地分析不精確、不一致、不完整等各種不完備的信息,還可以對數據進行分析和推理,從中發現隱含的知識,揭示潛在的規律。其中,粗糙集在屬性約簡方面有著重要的應用。但是粗糙集理論只能針對離散數據進行處理,所以對于連續型數據首先要進行離散化,即使采用較好的離散化方法,也不能避免離散化過程所帶來的信息損失。鄰域粗糙集[14-18]是一種對于連續性的數據可以直接處理的方法,它不需要事先對連續型數據進行離散化處理,可直接用于知識約簡等問題。因此,為保證入侵檢測的準確性,本文采用鄰域粗糙集方法進行屬性約簡。
鄰域決策系統 NDT=<S,A=G∪D,V,f>,其中 S={s1,s2,…,sm}是樣本集,稱為樣本空間。G={g1,g2,…,gn}是屬性集,稱為條件屬性。D={L}是一個輸出特征變量,稱為決策屬性,L表示所屬樣本的標記。Va表示屬性a∈G∪D的值域,f是一個信息函數,可表示為f:S×(G∪D)→V ,其中。
如果 ?si∈S且 B∈G,樣本 si在 B中的鄰域為δB(si),則 δB(si)={sj|sj∈S,ΔB(si,sj)≤δ},其中 δ是一個預設的閾值,ΔB(si,sj)是在B中的一個測度函數。設s1和 s2是 G={g1,g2,…,gn}中的兩個樣本,f(s,gi)表示樣本s在第i維屬性gi的值,則Minkowsky距離可定義為
給定鄰域決策表 NDT,X1,X2,…,Xc是具有決策屬性類別值 1到 c的樣本集,則,所以 X1,X2,…,Xc是 S 的一個劃分,表示由屬性子集B?G產生的包括樣本xi的鄰域信息粒度,則決策屬性D關于屬性子集B的下近似和上近似表示為:
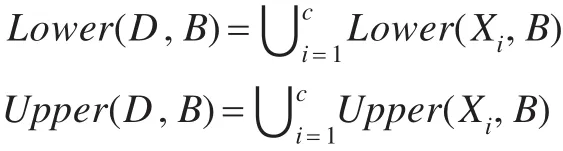
設a∈B,則屬性的重要度定義為:
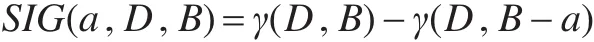
鄰域粗糙集屬性約簡算法偽代碼:
輸入:NDT=<S,A=G∪D,V,f>、鄰域半徑 δ
輸出:約簡子集red
(1)?a∈G,計算鄰域相關度;
(2)令 red=?;
(3)對每一個 ai∈G-red ,計算
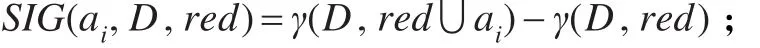
(4)選擇 ak,使其滿足
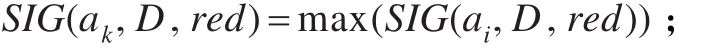
(5)若 SIG(ak,D,red)>0,則 red=red∪ak,且返回到(3)繼續執行;否則輸出約簡子集red。
3 算法思想與框架
多分類器集成是提高分類性能的有效方法,為獲得理想的集成效果,必須保證各基分類器間有足夠的差異性,且分類器之間能形成互補,所以基分類器之間的差異性是集成的關鍵之一。要增強分類器之間的差異性,產生差異性較大的訓練子集是一種有效的方法。Bagging[19-21]是基于有放回重采樣技術的一種集成算法,從原始訓練集中隨機抽取若干樣本組成訓練子集,訓練子集的規模與原始訓練集相當,訓練樣本允許重復選取。這樣原訓練集中某些樣本可能在新的訓練子集中出現多次,而另外一些樣本可能一次也不出現,由此可以產生具有較大差異性的訓練子集。
利用Bagging技術產生的每個bootstrap訓練子集,由于大量噪聲及冗余屬性,采用具有不同半徑的鄰域粗糙集進行屬性約簡,一方面可以剔除噪聲和冗余屬性,使獲得的分類器具有較高的精度;另一方面使用不同半徑的鄰域粗糙集對bootstrap訓練子集進行約簡,相當于將訓練子集映射到不同的特征空間,這樣進一步加大了訓練子集的差異性,從而使得最終獲得的分類器具有較高的精度和較大的差異性。
基分類器合成也是影響集成性能的重要因素,投票法是目前最常用且容易理解的一種合成方法,主要有大多數投票和加權投票兩種。大多數投票可視為加權投票法中所有基分類器權值均等的特殊情況。如果采用大多數投票方法,當出現兩個或兩個以上類標簽同時得到最大投票數時,就會產生決策沖突,因此需要一些方法來作為沖突消解策略,比如基于閾值的較多數投票法。大量研究表明,大多數投票是最常用的集成策略,但并不是最好的,因為它獲得的結果不可能優于任何一個基分類器。而加權投票法能夠獲得比大多數投票法更好的識別率。基分類器的權重分配與基分類器在訓練集上的預測精度相關聯的,設第i個分類器權重為bi,則有成立時,其最終決策為樣本屬于第k類。其中,pi為第i個分類器在訓練集上的預測精度,采用文獻[22]中的權重計算方法,且充分使用各分類器的先驗信息,可使得集成系統的識別精度最大化。
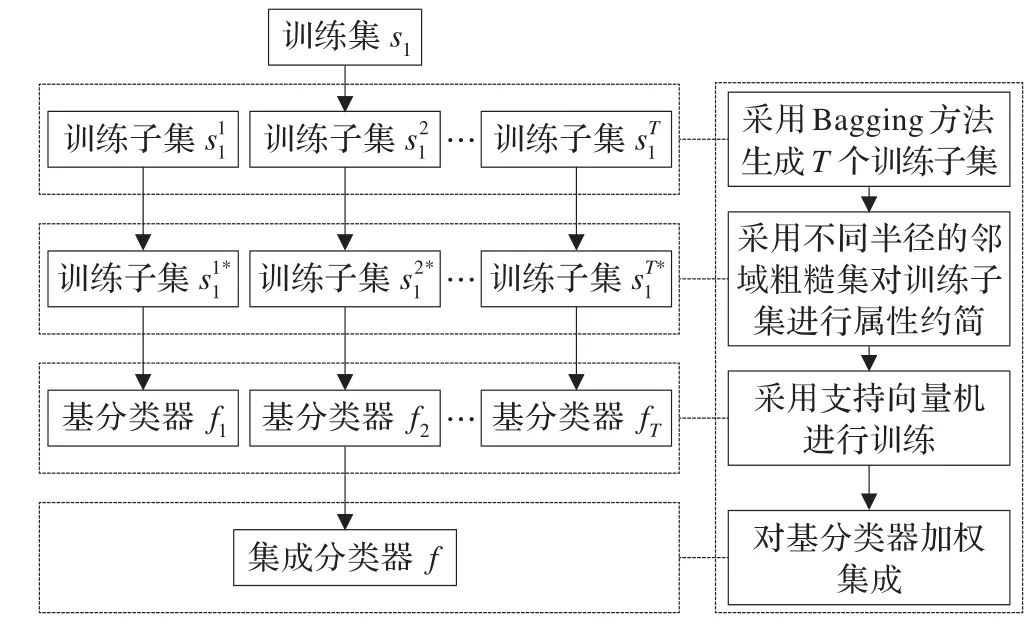
圖1 算法框架圖
4 算法步驟
輸出:集成分類器 f。
步驟1 fori=1:T
(1)從訓練集s1中進行有放回重采樣生成bootstrap訓練子集
end
步驟2以 fi在訓練集上的精度構造權重,對生成的T個基分類器進行加權集成。
5 仿真實驗
5.1 實驗數據
實驗采用KDD CUP 99(10%)數據集。從訓練集隨機抽取1000個樣本(含攻擊樣本195個)組成訓練集,如表1所示。從測試集隨機抽取800個樣本(含攻擊100個)組成測試集。為檢驗本文算法對未知攻擊的檢測效果,加入訓練集中沒有的未知攻擊10種,如表2所示。
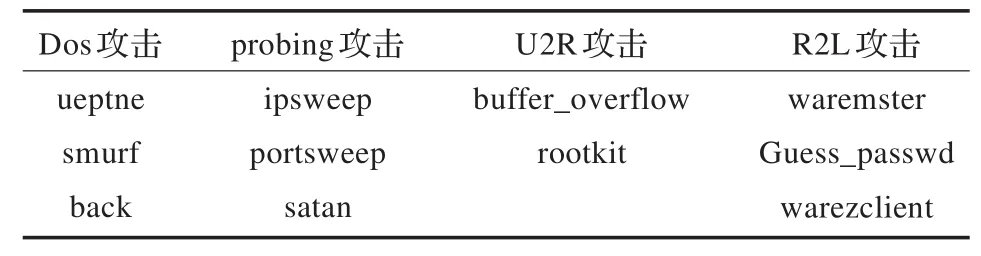
表1 訓練集攻擊類型分布
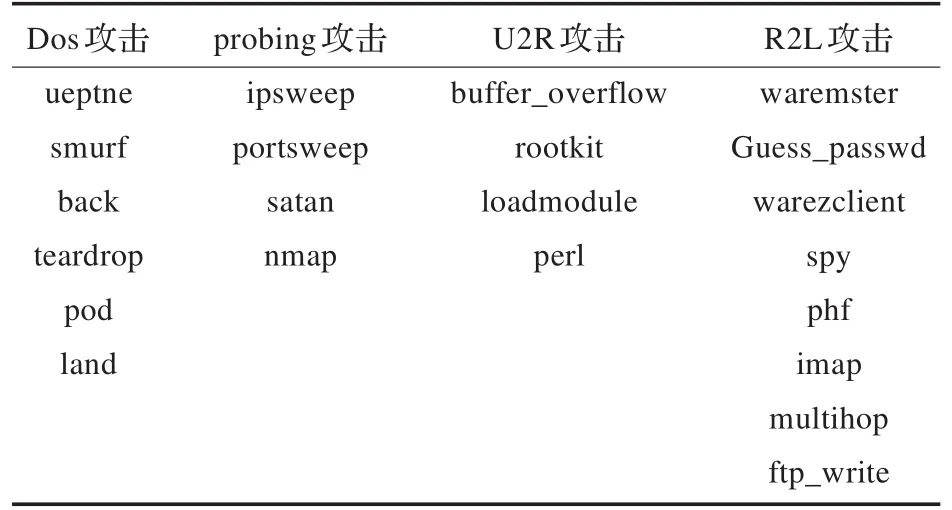
表2 測試集攻擊類型分布
5.2 算法評價標準
本文用檢測率、誤報率作為評價入侵檢測系統性能的指標。

5.3 實驗結果與分析
5.3.1 鄰域粗糙集半徑與入侵檢測精度
首先使用鄰域粗糙集對訓練集s1進行屬性約簡,然后采用支持向量機在約簡后的訓練集上訓練分類器,并在測試集s2上進行測試。實驗重復20次,取其平均值作為實驗結果。
鄰域粗糙集模型是由實數空間中的每一個點形成一個δ鄰域,而δ鄰域則成為描述空間中任意概念的基本信息粒子。鄰域的大小反映了人們對數值屬性中噪聲數據的容忍程度,所以鄰域半徑δ是影響鄰域粗糙集模型性能的重要因素。不同的半徑導致檢測精度的差異,本文將鄰域半徑取在[0.01,0.5],以0.01為步長,每取一個半徑,則獲得一個屬性子集,共產生50個屬性子集。
圖2和圖3分別直觀地顯示了入侵檢測率、誤警率與鄰域半徑之間的關系。從圖2可以看出半徑在[0.01,0.24]之間,其入侵檢測率保持在80%左右,而當半徑增加到[0.27,0.48],檢測率大幅提高,大概在91%左右,說明鄰域半徑對檢測率的影響是比較顯著的。從圖3看到,半徑在[0.01,0.48]之間,其誤警率基本保持在2%左右,而0.48之后,誤警率大幅增加。
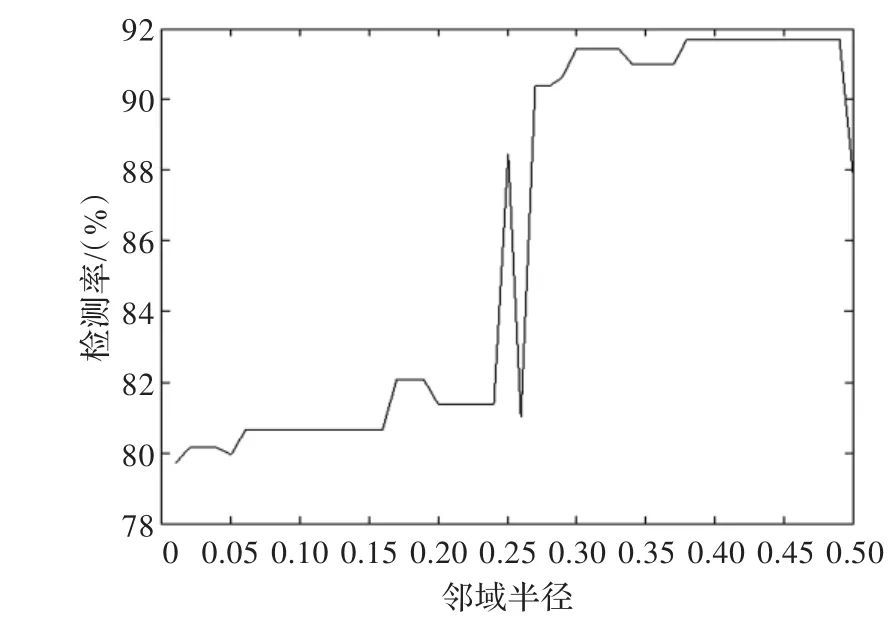
圖2 鄰域粗糙集半徑與入侵檢測率關系
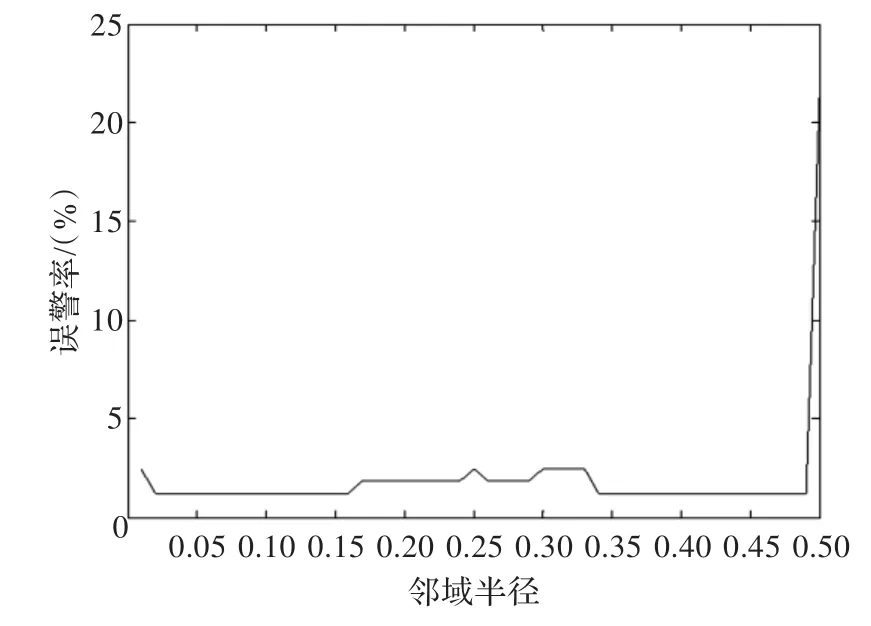
圖3 鄰域粗糙集半徑與入侵誤警率關系
綜上可得,當鄰域半徑在[0.35,0.48]之間,其檢測率較高,同時誤警率達到較低的狀態,這說明較小的δ鄰域使得粗糙集的邊界區域較窄,正域較大,所以分類精度較高。當然,鄰域的大小與所研究對象的內在特性有著密切關系,所以不能在任何情況下都取較小的δ。
5.3.2 算法的檢測率與誤警率
在訓練集s1上采用本文方法進行SVM集成,并在測試集s2上驗證算法的有效性和優越性。同樣實驗重復進行20次,取其平均值作為實驗結果。
表3給出了利用本文算法所得到的入侵檢測率及誤警率結果。其中“平均”表示參加集成的多個基分類器檢測率(或誤警率)的平均結果;“最優”表示參加集成的多個基分類器中檢測率最高(或誤警率最小)的結果;“集成”表示利用本文算法所得到的集成結果。
從表3中可以看出,采用本文算法所得到的檢測率(即“集成”)總體要比基分類器的平均檢測率提高5%左右,而且集成值與基分類器的最優值相近,甚至超過最優值,說明集成算法的有效性。本文算法獲得的誤警率整體上降低了3%左右,而且集成值大部分都超過了基分類器的最優值,說明本文算法對于降低誤警率有著顯著的效果。另外,隨著基分類器個數的增加,其檢測率和誤警率基本相似,所以可以減少基分類器的個數來進一步提高算法的時間、空間效率以及降低算法的復雜度。
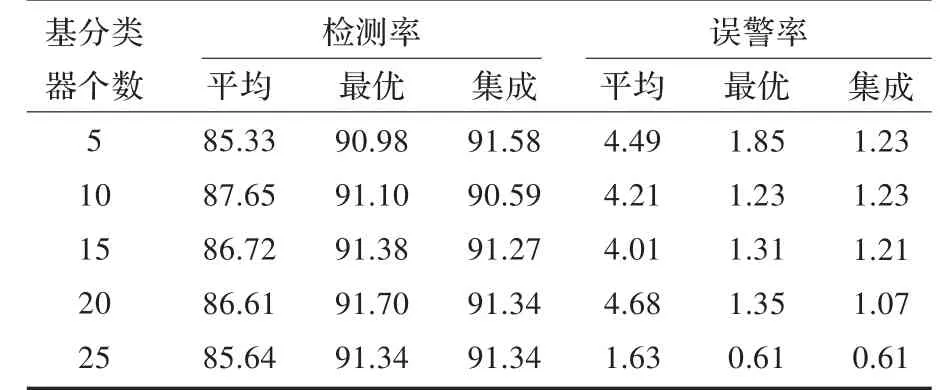
表3 本文算法的實驗結果 (%)
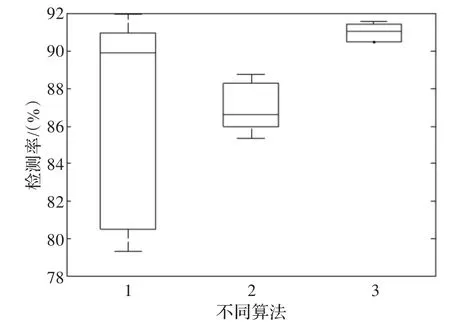
圖4 不同算法檢測率箱線圖
圖4顯示了不同算法的穩定性。橫坐標“1”表示各基分類器的入侵檢測率,“2”表示各基分類器的入侵檢測率的平均值,“3”表示各基分類器的集成檢測率。
從圖4看到,“3”(即“集成”)的穩定性最好,而且其檢測率高于“2”(即“平均”)。說明本文算法在穩定性以及精確率兩方面都超過其他算法。
表4給出算法1(SVM)、算法2(鄰域粗糙集+SVM)和本文算法在已知、未知攻擊上的檢測率。本文算法相對于其他算法,對已知攻擊數據的檢測率平均提高約8%,而對于未知攻擊數據的檢測率平均提高約13%,說明該算法不僅對已知攻擊檢測有效,而且對未知攻擊的檢測依然有較好的效果,充分說明該算法具有較強的泛化性能。
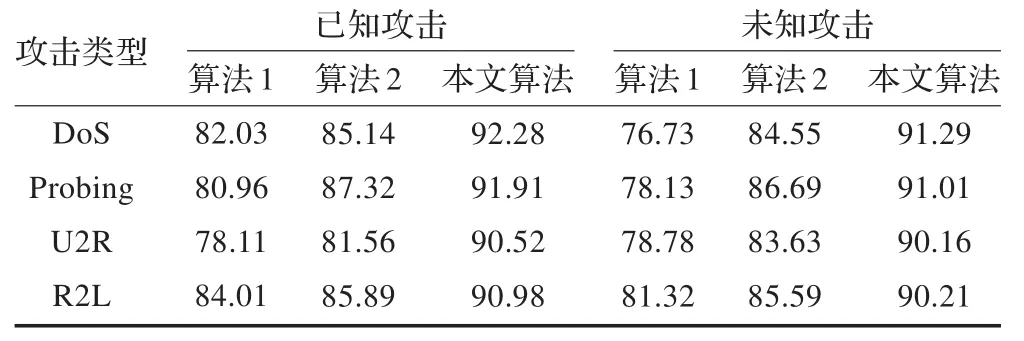
表4 不同算法對已知、未知攻擊的檢測率 (%)
6 結束語
入侵檢測數據往往具有噪聲和冗余屬性,并且部分屬性數據具有連續型特點,為了克服連續屬性離散化過程中帶來的信息損失,本文采用鄰域粗糙集模型進行屬性約簡,并結合Bagging技術設計集成算法,在KDD99數據集上的仿真實驗結果表明本文算法可以進一步提高入侵檢測率,并同時降低誤警率,該算法具有較強的泛化性能和魯棒性。
[1]陳光英,張千里,李星,等.基于SVM分類機的入侵檢測系統[J].通信學報,2002,23(5):51-56.
[2]饒鮮,董春曦,楊紹全,等.基于支持向量機的入侵檢測系統[J].軟件學報,2003,14(4):798-803.
[3]廖建平,余文利,方建文.改進的增量式SVM在網絡入侵檢測中的應用[J].計算機工程與應用,2013,49(10):100-104.
[4]雷向宇,周萍.支持向量分類機在入侵檢測中的應用研究[J].計算機工程與應用,2013,49(11):88-91.
[5]陳濤.基于雙重擾動的支持向量機集成[J].計算機應用,2011,28(1):46-49.
[6]陳濤.基于加速遺傳算法的選擇性支持向量機集成[J].計算機應用研究,2011,32(2):57-61.
[7]常甜甜,趙玲玲,劉紅衛,等.多模式擾動模型動態加權SVM集成研究[J].計算機工程與應用,2011,47(6):196-198.
[8]徐沖,王汝傳,任勛益,等.基于集成學習的入侵檢測方法[J].計算機科學,2010,27(7):217-224.
[9]張義榮,鮮明,肖順平,等.一種基于粗糙集屬性約簡的支持向量異常入侵檢測方法[J].計算機科學,2006,33(6):64-68.
[10]趙曦濱,井然哲,顧明,等.基于粗糙集的自適應入侵檢測算法[J].清華大學學報,2008,48(7):1158-1168.
[11]劉其琛,施榮華,王國才,等.基于粗糙集與改進LSSVM的入侵檢測算法研究[J].計算機工程與應用,2012,48(8):48-52.
[12]陳濤.基于動態粗糙集約簡的選擇性支持向量機集成[J].計算機仿真,2012,43(2):328-331.
[13]Meng Z Q,Shi Z Z.A fast approach to attribute reduction in incomplete decision systems with tolerance relation based rough sets[J].Informstion Sciences,2009,17(16):2774-2793.
[14]胡清華,于達仁,謝宗霞,等.基于鄰域粒化和粗糙逼近的數值屬性約簡[J].軟件學報,2008,15(3):121-125.
[15]胡清華,趙輝,于達仁,等.基于鄰域粗糙集的符號與數值屬性快速約簡算法[J].模式識別與人工智能,2008,21(6):89-95.
[16]Hu Q H,Yu D R,Liu J F,et al.Neighborhood rough set based heterogeneous feature subset selection[J].Information Sciences,2008,178(18):3577-3594.
[17]趙暉.融合鄰域粗糙集與粒子群優化的網絡入侵檢測[J].計算機工程與應用,2013,44(12):328-331.
[18]趙暉.基于鄰域粗糙集與KNN的網絡入侵檢測[J].河南科學,2013,31(9):1404-1408.
[19]Breiman L.Bagging Predictors[J].Machine Learning,1996,24(2):123-140.
[20]陳濤.選擇性支持向量機集成算法[J].計算機工程與設計,2011,18(5):259-263.
[21]陳濤.一種新的支持向量機混合集成算法[J].科學技術與工程,2012,21(12):5312-5315.
[22]Kuncheva L I.Combining pattern Classifiers:Methods and Algorithms[M].USA:John Wiley&Sons.Inc,2004:33-34.
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
