哈薩克語阿拉伯文與斯拉夫文間的智能轉換
2014-04-03 07:34:12薩合多拉木巴拉克古麗拉阿東別克
計算機工程與應用 2014年18期
關鍵詞:規則
薩合多拉·木巴拉克,古麗拉·阿東別克
Sahdolla MUBARAK,Gulila ALTENBEK
新疆大學 信息科學與工程學院,烏魯木齊 830046
College of Information Science&Engineering,Xinjiang University,Urumqi 830046,China
隨著全球經濟一體化發展,中國和中亞國家的經濟貿易往來日益頻繁,哈薩克斯坦是一個很重要的合作伙伴,哈薩克語成為兩國之間經濟文化交流的重要載體。由于居住在不同地區的哈薩克族長期受到不同文化、不同歷史等一些因素的影響,形成了基于同一語言的兩種文字的特殊情況,阻礙了兩國經濟文化交流的深入發展。所以開發解決這個問題的計算機轉換系統的意義很大,本文研究在Windows環境下,哈薩克語兩種文字間智能轉換的實現。
1 兩種文字的特點
阿拉伯字母哈薩克語是以阿拉伯字母為基礎的拼音文字,共有33個音(音位),其中9個是元音,24個是輔音,有些字母有兩種書寫形式,有些有四種書寫形式,根據詞里的位置,書寫形式發生變化。拼寫時由右向左寫,詞和詞之間必須留有一定的空隙[1]。語音方面的特點是元音和諧和輔音同化規律,元音和諧指的是前后元音和諧,即在本族固有詞匯中,前后兩組元音不能出現在同一個單詞中;輔音同化的特點是詞中相鄰的兩個輔音,前一輔音影響后一輔音,隨即后一輔音又導致前一輔音發生變化,稱為輔音的相互通話,即同時出現輔音的前進與后退通話。
斯拉夫字母哈薩克文(西里爾文)是哈薩克族于1940年開始使用的,以斯拉夫字母為基礎的文字。這種文字形式共有37個音素,42個字母。除原有的斯拉夫字母之外,還增加了9個字母,這9個字母不出現在俄語詞里,是哈薩克語特有的字母。另外還有13個字母用來拼寫外來語(俄語)借詞時使用。因此,斯拉夫字母哈薩克標準文一般只有31個音素,從語言歷史來看,哈薩克語固有詞中,實際上只有24或25個音位[2]。
2 系統的主要工作
2.1 基本字母的轉換(一對一)
斯拉夫字母哈文有37個音,42個字母,阿拉伯字母哈文有35個音,33個字母。這兩種文字之間大部分(32個字母)是一一對應的關系,根據哈薩克語詞的構成規則來對特殊情況進行一些處理之后,采用對應字母相互轉換的方法來設計系統。
2.2 復合音的轉換(一對多或多對一)
西里爾文中有些字母是由兩個音構成的復合音,這些詞在哈薩克固有詞里沒有音位。例如:程序把文章從斯拉夫字母哈文轉換為阿拉伯字母哈文的過程中,讀到這四個字母中的任何一個時,先把這個字母拆分成對應的兩個斯拉夫字母,再進行轉換。阿拉伯文轉換為斯拉夫文時,因為這些詞一般只出現在俄語借詞中,所以用對應庫來解決這個問題。
2.3 軟音符號ь和硬音符號ъ
這兩個非音素字母是不發音的。它們多是從俄語或是經俄語傳入哈薩克語的單詞中出現,阿拉伯字母哈文沒有這兩個音符[3]。從斯拉夫字母哈文轉換為阿拉伯字母哈文的過程中,由于阿拉伯字母和斯拉夫字母的發音相同,所以轉換時就采用了忽略這兩個符號的方法。而對于從阿拉伯字母哈文轉換為斯拉夫字母哈文的過程中,由于沒有如何加入這兩個音符的具體規則,所以采用建立對應詞匯庫來解決這一問題。
2.4 “И”和“Й”
哈薩克斯拉夫文中有“Й”和“И”兩個字母,而在阿拉伯字母哈文中這兩個字母都用同一個來代替,這就產生了到底在什么時候用Й,什么時候用И的問題。一般情況下輔音后面跟“И”,元音后跟“Й”。所以在單詞中出現有時,檢查它的前一個字母是元音還是輔音。
2.5 標點符號
阿拉伯字母哈文采用阿拉伯文標點符號的記法,而斯拉夫字母哈文中采用的是與英文字母相同的標點符號記法。兩種標點符號中除了如表1所列的三個標點符號之外的其他標點符號是一樣的。
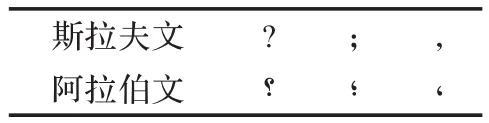
表1 兩種字母的標點符號
2.6 阿拉伯字母哈薩克文中的編碼錯誤問題
這個問題是本系統要解決的主要問題。在斯拉夫字母哈薩克文到阿拉伯字母哈薩克文的轉換過程中由于斯拉夫文是怎么讀就怎么寫,所以不出現字母的形變現象。但在阿拉伯字母哈薩克文中的一個詞中,如果有三個字母中的任何一個出現,則使得這個單詞中的前元音符號不能寫,所以單詞里應寫為的四個字寫成,但發音不變。例如:“人生)這個單詞中第一個字母是,在這個單詞后加后綴時,因為后綴中出現了”這個字母,所以第一個字母的寫法發生變化,寫成字母了,所以輸入員輸入時直接輸入了。最后阿拉伯字母哈薩克文轉換為斯拉夫文時轉換成了
3 哈薩克語中詞的組成結構
通過分析哈薩克語詞的組成結構,結合《現代哈薩克語問答》,《哈薩克語語法知識》[4]發現哈薩克語中詞的構成是有一定規則的。因此,本文以詞的形式結構規則為核心,再加一些限定條件,分析了哈薩克語中詞的內部構成規則。
在哈薩克語的固有詞(包括一些早期外來語借詞)中,前一音節的元音同后一音節的元音在舌位的前后,同時在唇形方面互相制約,存在著明顯的調諧,匹配的現象。詞干和附加成分之間也如此,通常把多音節詞里元音的這種調諧,匹配叫做元音和諧,而把這種模式叫做元音和諧律[5]。
哈薩克語的元音和諧律在音節之間以元音的前后和諧為基礎,輔以圓唇元音和諧。哈薩克語元音按舌位的前后分類如表2所示。
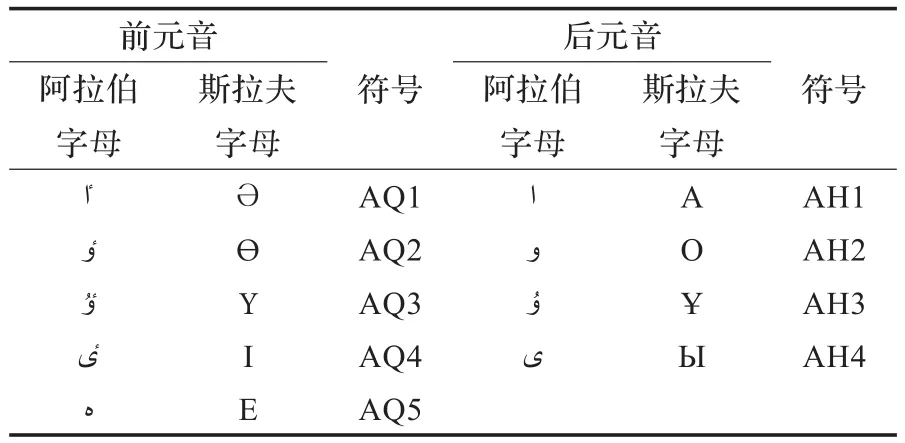
表2 哈薩克語元音按舌位的前后分類
3.1 后元音的和諧
如果詞的前一音節里的元音是后音,那么后續音節(包括附加成分)里的元音也只能是后元音。
哈薩克語固有詞里后元音和諧的模式,在文字上表現為:后元音后只能出現。
3.2 前元音的和諧
如果詞的前一音節里的元音是前元音,那么后續音節(包括附加成分)里的元音也只能是前元音。
哈薩克語固有詞里前元音和諧的模式,在文字上表現為:前元音后只能出現
3.3 外來詞的詞根和后綴的和諧
哈薩克語在形成和發展過程中吸收了大量的外來詞,它們不受上述的哈薩克語元音和諧律的限制[7],所以本文中用數據庫來解決這個問題。但對這些外來詞后后續的附加成分遵守元音和諧律。
外來詞借詞綴加附加成分時,根據詞的最后一個音節元音的性質來調配后續音節里的音節。如果外來詞的最后一個音節里的元音是后元音,那么附加成分里的元音都是后元音字母,如果前元音,那么附加成分里元音都是前元音字母。
3.4 特殊字母組
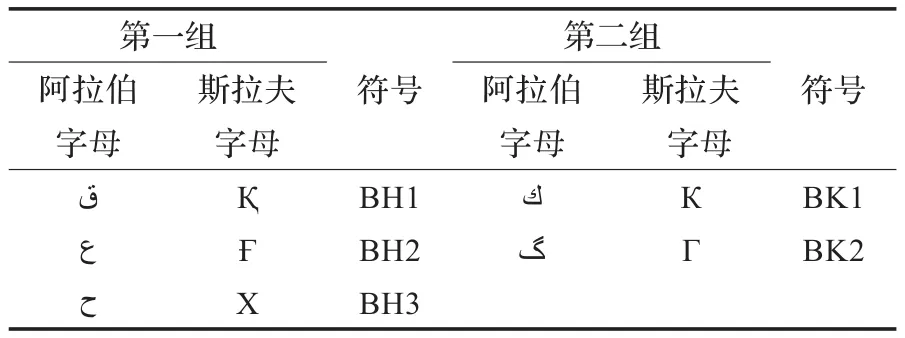
表3 特殊字母組對應表
4 哈薩克語詞的構成規則集的建立
結合以上哈薩克語詞的結構規則和構形附加成分集,建立了哈薩克語詞的結構規則集,形式化表示如下幾種。
4.1 詞中第一個音節后后續的音節的規則集
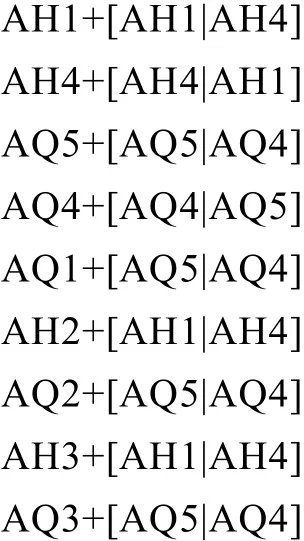
4.2 外來詞的最后一個音節后后續的附加成分的音節規則集
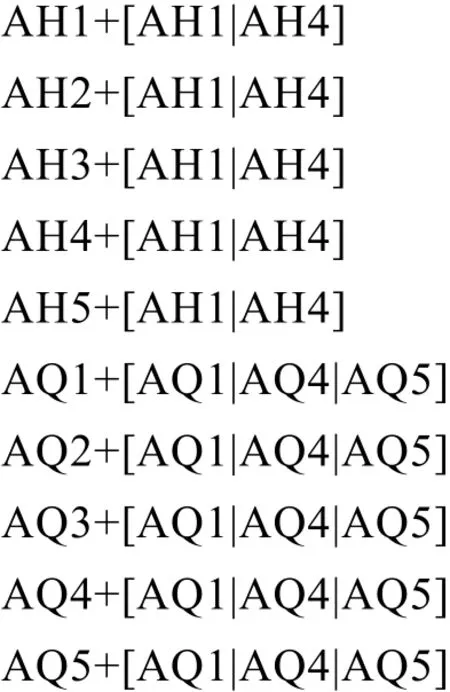
4.3 特殊字母組的音節規則集
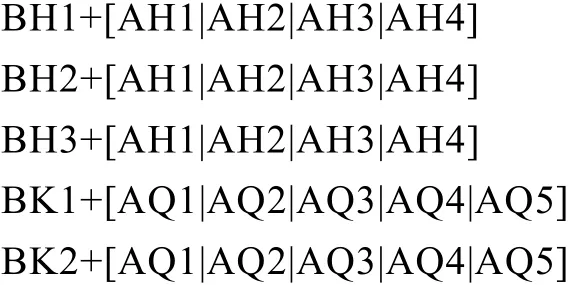
5 哈語兩種文字轉換系統
5.1 阿拉伯字母哈薩克文轉換為斯拉夫字母哈薩克文
由于標準Unicode建立前,新疆哈薩克文輸入法采用不同的Unicode代碼來表示哈薩克文,所以在程序執行阿拉伯字母哈薩克文轉換成斯拉夫字母哈薩克文前,需要先將各種不同的輸入法轉換為統一標準Unicode格式。然后把已載入的文本切成單詞,并進行詞干提取。接下來從第一個詞干開始從數據庫里找對應的斯拉夫文詞,如果找到了,替換對應的斯拉夫文,根據詞干最后音節的情況對后綴進行操作。如果從數據庫中找不到對應斯拉夫文詞,那么根據上述的規則對整個單詞(包括詞干和后綴)進行修正編碼錯誤問題等操作。程序流程如圖1所示。
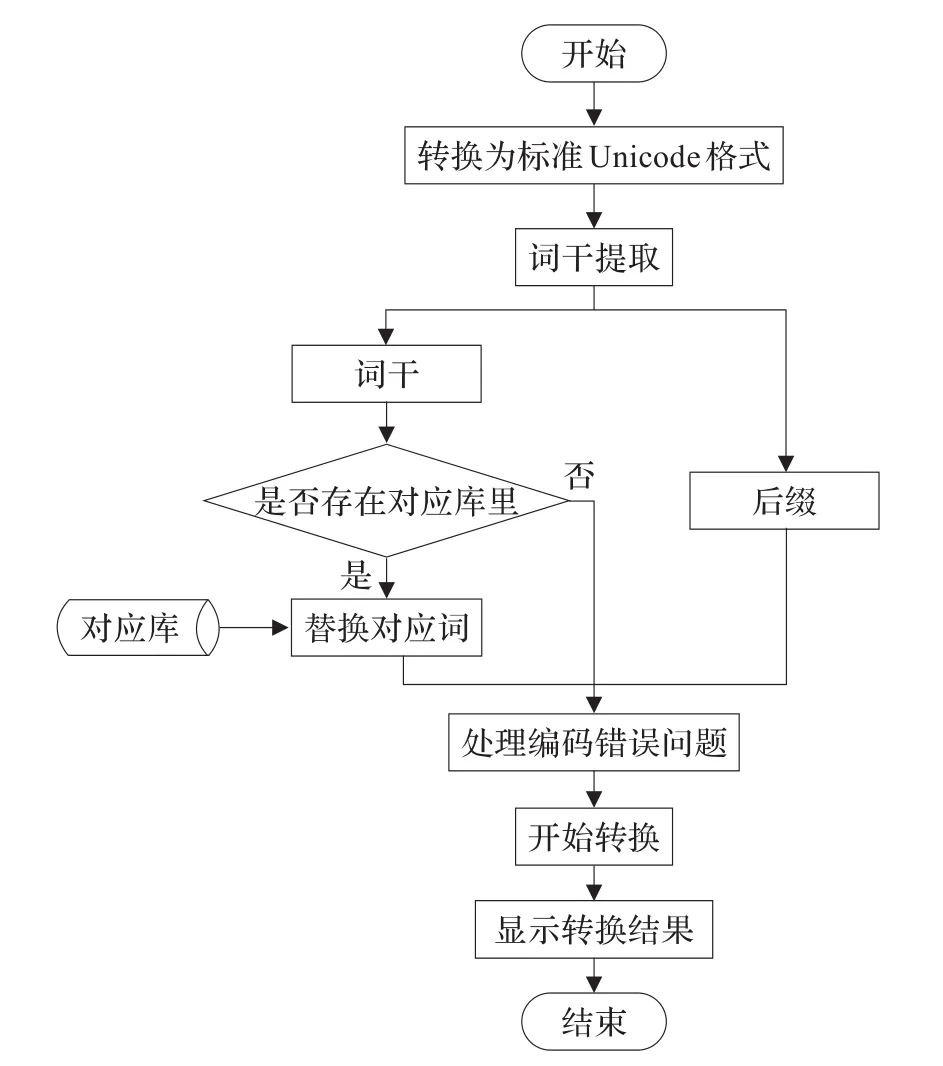
圖1 阿拉伯字母哈薩克文轉換為斯拉夫字母哈薩克文程序流程圖
5.2 斯拉夫字母哈文轉換為阿拉伯字母哈文
42個斯拉夫字母哈文中32個字母是和哈薩克阿拉伯字母一一對應的,7個字母是多對一對應的,也就是這7個字母的每一個對應哈薩克阿拉伯字母的2字母。還有兩個不發音的音符,軟音符號和硬音符號,它們在阿拉伯字母哈文中沒有對應的字母,所以把文本從斯拉夫字母轉換成阿拉伯字母時忽略了這兩個音符。
6 實驗結果及分析
6.1 實驗結果
系統利用基于規則的方法,采用C#編寫阿拉伯字母哈薩克文與斯拉夫字母哈薩克文間相互智能轉換系統,系統界面如圖2所示,使用哈薩克語小學語文(共有5個年級的課文)進行了測試,共有65 461個單詞的文章進行轉換后2 930個單詞出現了錯誤,準確率為95.5%。
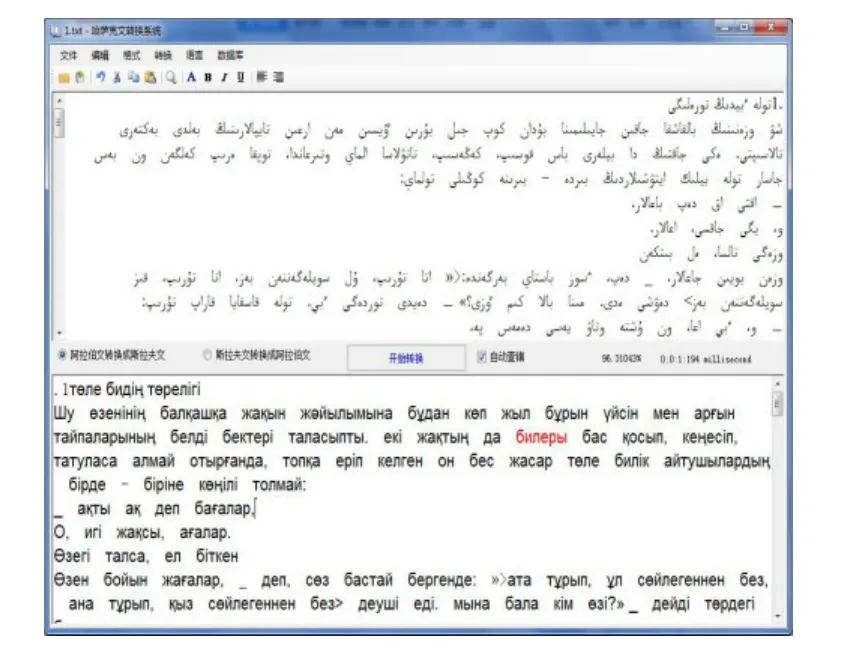
圖2 程序基本的操作界面
6.2 分析
從實驗結果來看,采用的方法基本令人滿意,但準確率尚需近一步提高。該方法還沒有達到很高的轉換效率,主要原因有以下幾個方面:
(1)軟音符號導致的問題,阿拉伯字母哈薩克文的軟音符號導致上述的編碼錯誤問題,還加上阿拉伯字母哈語本身存在的語法問題,給哈薩克語自然語言處理工作帶來很大的麻煩,本系統中也是因為這個問題下降了正確率。
(2)數據庫完整性問題,數據庫包括外來詞,人名,地名,機構名等信息。因為中國哈薩克人和哈薩克斯坦哈薩克人對一些同一個事物有不同的名稱,例如:手機,馕等詞都有不同的名稱,這些詞不可能靠規則來轉換。解決這個問題需要很長的時間和人力才能實現。
(3)哈薩克語詞的構成規則有待完善。本文主要講的是基于規則方法的轉換系統,完善的哈語構詞規則會更好地提高兩種文字形式間轉換。
7 結束語
本文分析并實現了哈薩克語兩種文字智能轉換的方法,建立了哈薩克語基本外來詞庫,為哈薩克文資料的傳播和交流提供了便利。該實驗方法從哈語最本質的特征出發,從宏觀上總結出一些規則,比較直觀地表達了哈語基本詞的構成規律,但該方法還沒有能夠解決哈語中外來詞的轉換。因此,下一步將完善對應庫,進一步改善哈語詞的構成規則,并嘗試規則和統計相結合的方法,提高哈語兩種文字間智能轉換系統的效率。
[1]阿里木賽依提·阿布力哈孜.哈薩克語入門[M].奎屯:伊犁人民出版社,2009.
[2]古麗扎達·海沙,古麗拉·阿東別克.我國哈薩克族詞匯與哈薩克斯坦詞匯間自動轉換的研究[J].計算機應用與軟件,2012,29(7):3-5.
[3]吳宏偉.從現代哈薩克語詞的構成看原始突厥語詞匯的特點[J].語言研究,1994,15(1):3-4.
[4]迪麗達.哈薩克語語法知識[M].奎屯:伊犁人民出版社,2010.
[5]努爾蘭.現代哈薩克語問答[M].奎屯:伊犁人民出版社,1998.
[6]張定京.現代哈薩克語實用語法[M].北京:中央民族大學出版社,2004.
[7]蔣宏軍.如何區分哈薩克語中的外來詞[J].伊犁師范學院學報:社會科學版,2011,18(2):1-2.
[8]黃中祥.哈薩克詞匯與文化[M].北京:中國社會科學出版社,2005.
猜你喜歡
作文周刊·小學一年級版(2022年28期)2022-05-30 10:48:04
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
法律方法(2019年3期)2019-09-11 06:26:16
中國外匯(2019年7期)2019-07-13 05:44:52
幸福(2018年33期)2018-12-05 05:22:42
環球飛行(2018年7期)2018-06-27 07:26:14
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
運動(2016年6期)2016-12-01 06:33:42
