基于概念格的關(guān)聯(lián)規(guī)則在排產(chǎn)管理的應(yīng)用
2014-04-03 01:45:24張曉,龍偉,盧斌
計(jì)算機(jī)工程與應(yīng)用 2014年9期
張 曉,龍 偉,盧 斌
ZHANG Xiao,LONG Wei,LU Bin
南昌大學(xué) 信息工程學(xué)院,南昌 330031
School of Information and Engineering,Nanchang University,Nanchang 330031,China
1 引言
汽車沖壓廠在生產(chǎn)過程中,具有混線生產(chǎn)、多品種以及多工藝的特征,近幾年來,隨著生產(chǎn)信息管理系統(tǒng)的廣泛使用,沖壓廠積累了大量的生產(chǎn)歷史數(shù)據(jù),但是目前該系統(tǒng)大部分僅限于查詢、統(tǒng)計(jì)等功能,無法發(fā)現(xiàn)數(shù)據(jù)中存在的關(guān)系和規(guī)則,導(dǎo)致了“數(shù)據(jù)爆炸但知識(shí)貧乏”的現(xiàn)象[1]。而數(shù)據(jù)挖掘技術(shù)[2-3]能有效從這些大量復(fù)雜的數(shù)據(jù)中找到有用的規(guī)則和信息,并將它們轉(zhuǎn)化為知識(shí)表示,為管理人員在生產(chǎn)排產(chǎn)中提供理論依據(jù)。
關(guān)聯(lián)規(guī)則[4-5]是數(shù)據(jù)挖掘中的一個(gè)重要分支,描述了數(shù)據(jù)間的潛在關(guān)系,Apriori算法是經(jīng)典的關(guān)聯(lián)規(guī)則算法,目前很多常見的關(guān)聯(lián)規(guī)則挖掘算法都是在此算法的基礎(chǔ)上加以改進(jìn)的,但其生成頻繁項(xiàng)集過程復(fù)雜,對(duì)規(guī)則的可視化存在不足。本文重點(diǎn)分析了基于概念格[6-7]的關(guān)聯(lián)規(guī)則在生產(chǎn)信息數(shù)據(jù)中的應(yīng)用,通過概念的內(nèi)涵和外延及泛化和特化之間的關(guān)系來表示知識(shí),通過量化概念格尋找關(guān)聯(lián)規(guī)則,并與經(jīng)典的Apriori算法進(jìn)行對(duì)比,能非常容易實(shí)現(xiàn)規(guī)則的可視化,不需要計(jì)算頻繁項(xiàng)目集,就能容易獲取用戶感興趣的規(guī)則,提高了挖掘效率。根據(jù)找到的關(guān)聯(lián)規(guī)則,指導(dǎo)企業(yè)作出排產(chǎn)方案[8],達(dá)到優(yōu)化排產(chǎn),降低庫存,提高產(chǎn)品生產(chǎn)效率和增強(qiáng)企業(yè)競(jìng)爭(zhēng)力的目的[9-10]。
2 汽車沖壓廠排產(chǎn)管理分析
汽車沖壓廠的生產(chǎn)管理是以科室為單位進(jìn)行的,其生產(chǎn)流程為:首先,制造科人員根據(jù)沖壓廠的庫存數(shù)據(jù)、零件需求、訂貨成本、訂貨周期、持有成本、缺貨率等信息,計(jì)算沖壓件可支撐天數(shù),從大到小排列生成一張排產(chǎn)信息表。然后由科室排產(chǎn)人員對(duì)相應(yīng)零部件安排好加工生產(chǎn)線、班次和工序次序。其次由技術(shù)科對(duì)沖壓件在生產(chǎn)過程中的技術(shù)要求作出規(guī)劃。最后沖壓車間根據(jù)排產(chǎn)信息和技術(shù)要求進(jìn)行沖壓件的生產(chǎn),并填寫生產(chǎn)數(shù)據(jù)信息,質(zhì)管科對(duì)生產(chǎn)過程中所有產(chǎn)品的質(zhì)量進(jìn)行監(jiān)測(cè),并由設(shè)備科維護(hù)或維修設(shè)備。
其中,制造科人員如何根據(jù)已有信息作出高效的排產(chǎn)計(jì)劃是生產(chǎn)過程的關(guān)鍵。其他科室人員都是根據(jù)該排產(chǎn)計(jì)劃來作業(yè)生產(chǎn),排產(chǎn)計(jì)劃愈合理,沖壓廠的生產(chǎn)效率愈高,企業(yè)績效愈好[11]。因此,本文重點(diǎn)研究了如何利用數(shù)據(jù)挖掘中基于概念格[12-13]的關(guān)聯(lián)規(guī)則技術(shù)來實(shí)現(xiàn)優(yōu)化排產(chǎn)的目的[14]。
2.1 關(guān)聯(lián)規(guī)則概述
關(guān)聯(lián)規(guī)則既可以發(fā)現(xiàn)不同事物間的新規(guī)律,又能檢驗(yàn)事物間隱藏的相互關(guān)系、依存性和關(guān)聯(lián)性。若兩個(gè)或多個(gè)變量的取值之間存在某種規(guī)律性,就稱為關(guān)聯(lián)。關(guān)聯(lián)規(guī)則挖掘技術(shù)用于發(fā)現(xiàn)數(shù)據(jù)庫中屬性之間的有意義的聯(lián)系,旨在尋找在同一事件中出現(xiàn)的不同事物的相關(guān)性。關(guān)聯(lián)規(guī)則挖掘問題就是在事物數(shù)據(jù)庫中找出具有用戶給定的最小支持度和最小置信度的關(guān)聯(lián)規(guī)則,關(guān)聯(lián)規(guī)則挖掘問題可以分為以下兩個(gè)子問題:
(1)生成頻繁項(xiàng)集:其任務(wù)是生成所有滿足最小支持度閥值的項(xiàng)集,這些項(xiàng)集被稱為頻繁項(xiàng)集。
(2)生成規(guī)則:其任務(wù)是從上一步生成的頻繁項(xiàng)集中提取所有高置信度的規(guī)則。
其中第一個(gè)問題是關(guān)聯(lián)規(guī)則的核心問題,相對(duì)生成頻繁項(xiàng)集而言,規(guī)則的生成則比較簡單和直接。通常,生成頻繁項(xiàng)集所需的計(jì)算開銷要遠(yuǎn)遠(yuǎn)大于規(guī)則生成所需的計(jì)算開銷。一般來說關(guān)聯(lián)規(guī)則挖掘算法主要是對(duì)第一部分提出來的。
2.2 概念格定義
(1)形式背景
對(duì)于一個(gè)三元組K(U,A,I),其中U表示對(duì)象集合,A表示屬性集合,I表示對(duì)象U和屬性A之間的二元關(guān)系。如果存在(u,a)∈I,說明對(duì)象u具有屬性a。當(dāng)X*={a|a∈A,?x∈X,xIa},X?U;B*={x|x∈U,?a∈B,xIa},B?A 。若 ?X*=B 且 B*=X ,稱 (X,B)為一個(gè)形式概念。 X定義為概念(X,B)的外延,B定義為概念(X,B)的內(nèi)涵。概念的外延是指概念覆蓋的所有對(duì)象之集,概念的內(nèi)涵是指所有對(duì)象所共有的屬性。
(2)概念格
屬性和對(duì)象之間的關(guān)系用概念格來表示,在概念格的結(jié)點(diǎn)之間,有一種偏序關(guān)系存在,若有C1(X1,B1)和C2(X2,B2),則 C1<C2必然有 B1<B2,這一種偏序關(guān)系說明 C1(X1,B1)是 C2(X2,B2)的高級(jí)概念,或者說 C1(X1,B1)是C2(X2,B2)的一個(gè)泛化。對(duì)于形式背景 (U,A,I),在關(guān)系I中,只存在著唯一的偏序集,這個(gè)偏序集產(chǎn)生的格結(jié)構(gòu),稱為概念格。所以,一個(gè)形式背景只可能產(chǎn)生唯一的概念格。
(3)Hasse圖
Hasse圖用一種簡明有效的圖將概念格中的偏序集關(guān)系表示出來,能夠非常完整直觀地表示出所有概念結(jié)點(diǎn)之間外延和內(nèi)涵以及泛化和特化的關(guān)系,是表示概念格最通用的方法。
3 基于概念格的關(guān)聯(lián)規(guī)則在排產(chǎn)管理的應(yīng)用
3.1 數(shù)據(jù)準(zhǔn)備
5個(gè)科室管理人員分別從不同的入口把數(shù)據(jù)采集到生產(chǎn)信息管理系統(tǒng)各個(gè)子系統(tǒng)數(shù)據(jù)庫中,期間產(chǎn)生了許多冗余的、不規(guī)范的、錯(cuò)誤的和不一致的數(shù)據(jù),如果把這些數(shù)據(jù)直接用于數(shù)據(jù)挖掘,那么需要花費(fèi)大量的時(shí)間,所以在數(shù)據(jù)挖掘之前必須做好對(duì)數(shù)據(jù)的清洗等工作,為數(shù)據(jù)挖掘準(zhǔn)備好數(shù)據(jù)。
到目前為止,沖壓車間生產(chǎn)的汽車零部件有1305多種,產(chǎn)品生產(chǎn)總記錄數(shù)超過30萬。如果對(duì)數(shù)據(jù)庫的所有數(shù)據(jù)進(jìn)行分析,得到的關(guān)聯(lián)規(guī)則支持度可能會(huì)非常低,甚至得不到關(guān)聯(lián)規(guī)則,因此,本實(shí)例中選取某特定車型零部件產(chǎn)品序號(hào)為T074的生產(chǎn)信息數(shù)據(jù)作為數(shù)據(jù)挖掘庫,對(duì)同一產(chǎn)品序號(hào)進(jìn)行挖掘,在實(shí)際應(yīng)用中,用戶可以選擇其他產(chǎn)品車型或字段屬性生成數(shù)據(jù)挖掘庫。
在收集到的生產(chǎn)信息數(shù)據(jù)中有很多屬性,但是其中有一些與數(shù)據(jù)挖掘關(guān)系不大,或數(shù)據(jù)本身沒有挖掘意義。例如產(chǎn)品名稱等屬性,這些屬性值是唯一性的,沒有什么挖掘意義,而數(shù)據(jù)量又很大,可以直接刪除,從而壓縮搜索空間。另外還有像日期之類的屬性,沒有分類的意義,可以剔除這些數(shù)據(jù),達(dá)到精簡數(shù)據(jù)規(guī)模的目的。同時(shí),對(duì)不完整的、有噪聲的和不一致的字段或數(shù)據(jù)進(jìn)行清理,具體操作為填充某些空缺的字段值,消除多個(gè)表中的不一致,構(gòu)造一些字段以便概化,對(duì)某些數(shù)字型字段進(jìn)行離散化的歸約工作等,以確保數(shù)據(jù)的有效性。
經(jīng)過數(shù)據(jù)預(yù)處理后,為了說明問題,數(shù)據(jù)集中最終確定的生產(chǎn)信息數(shù)據(jù)表中包含了7個(gè)相關(guān)屬性(ID,生產(chǎn)線,班次,工序次序,庫存數(shù)量,缺貨率,核對(duì)完工數(shù))。根據(jù)相關(guān)標(biāo)準(zhǔn),把核對(duì)完工數(shù)、庫存數(shù)量和缺貨率是否達(dá)標(biāo)作為規(guī)則的結(jié)果(Y表示最優(yōu),N表示不是),其部分?jǐn)?shù)據(jù)如表1。
為了方便數(shù)據(jù)的表述,對(duì)表1中屬性“生產(chǎn)線”用字母a表示,具體值A(chǔ)1、A2分別用1、0表示;屬性“班次”用字母b表示,具體值白班、晚班用1、0表示;以此類推形式化表1中的數(shù)據(jù)。本文中為了說明基于概念格的數(shù)據(jù)挖掘在汽車沖壓工序應(yīng)用的可行性及高效性,選取其中的6組數(shù)據(jù)(分別用 ui(i=1,2,3,4,5,6)表示)來說明問題,最終用來闡述問題的部分?jǐn)?shù)據(jù)如表2所示。
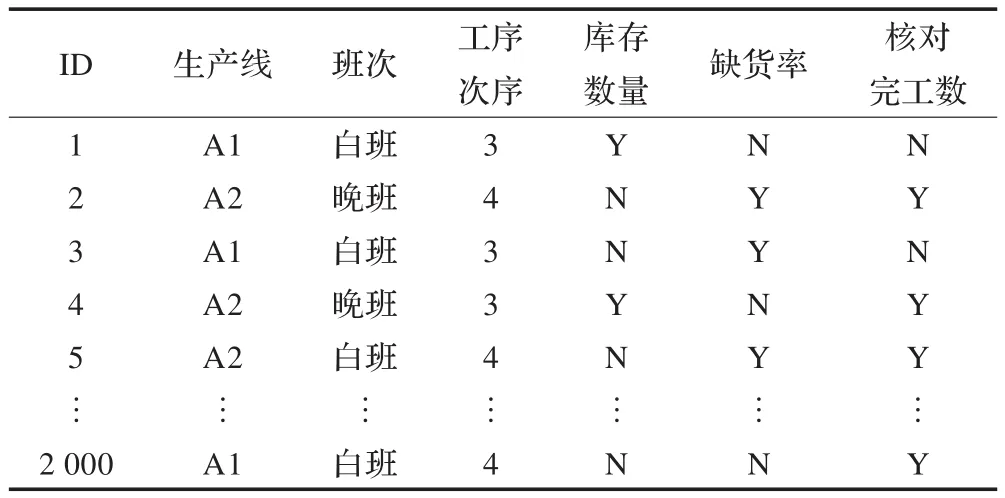
表1 生產(chǎn)信息數(shù)據(jù)表
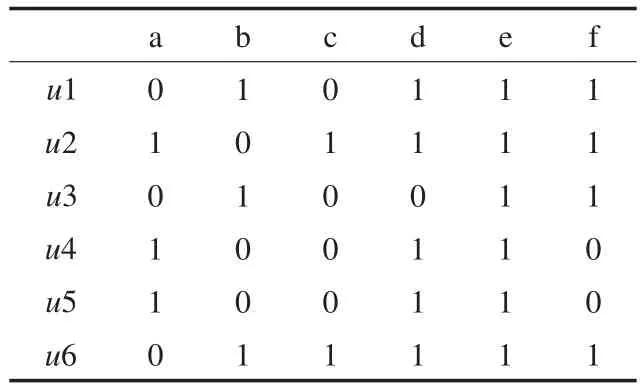
表2 生產(chǎn)信息數(shù)據(jù)簡化表
3.2 關(guān)聯(lián)規(guī)則挖掘
本文首先利用經(jīng)典的Apriori算法對(duì)表2中的數(shù)據(jù)進(jìn)行關(guān)聯(lián)規(guī)則挖掘,然后使用量化概念格生成關(guān)聯(lián)規(guī)則,并將挖掘結(jié)果進(jìn)行對(duì)比分析,利用生成的關(guān)聯(lián)規(guī)則給制造科人員排產(chǎn)提供理論依據(jù)。
3.2.1 Apriori算法挖掘
Apriori算法是經(jīng)典的關(guān)聯(lián)規(guī)則算法,其核心是基于頻集理論的遞推方法。該算法使用一種稱作逐層迭代的候選產(chǎn)生測(cè)試的方法,K項(xiàng)集用于探索產(chǎn)生K+1項(xiàng)集。將Apriori算法應(yīng)用于上述準(zhǔn)備好的數(shù)據(jù)中,并且設(shè)置支持度為0.04和置信度為0.45,具體實(shí)現(xiàn)過程如下:
產(chǎn)生1-候選項(xiàng)CX(1),設(shè) rx∈CX(1),如果對(duì)任意ry∈D都存在sup(rx=>ry)<0.04,則稱rx是非頻繁的,將rx從CX(1)中刪除,否則,如果conf(rx=>ry)≥0.45,則說明規(guī)則rx=>ry符合條件。CX(1)刪除所有非頻繁項(xiàng)集后構(gòu)成1-頻繁集L1。
在L1的基礎(chǔ)上,利用Apriori性質(zhì)壓縮搜索空間,由連接和剪枝生成2-候選項(xiàng)集CX(2),掃描事物數(shù)據(jù)庫,利用與上述相同的方法,并根據(jù)最小支持度和最小置信度找到滿足條件的關(guān)聯(lián)規(guī)則,刪除所有非頻繁項(xiàng)集后生成2-頻繁集 L2。
這一過程反復(fù)進(jìn)行,直到生成K-頻繁項(xiàng)集Lk,并且不可能再生成滿足最小支持度的k+1項(xiàng)集為止。
最后產(chǎn)生的有效關(guān)聯(lián)規(guī)則如表3所示。
3.2.2 構(gòu)造概念格
對(duì)于表2中的形式背景,利用分而治之方法來構(gòu)造Hasse圖,即首先將表2中的形式背景進(jìn)行拆分,分解得到兩個(gè)小的形式背景,然后分別對(duì)各個(gè)小的形式背景構(gòu)造概念格,最后將兩個(gè)小形式背景構(gòu)造的概念格進(jìn)行合并[15-16]。其構(gòu)造算法的偽代碼如算法1所示。
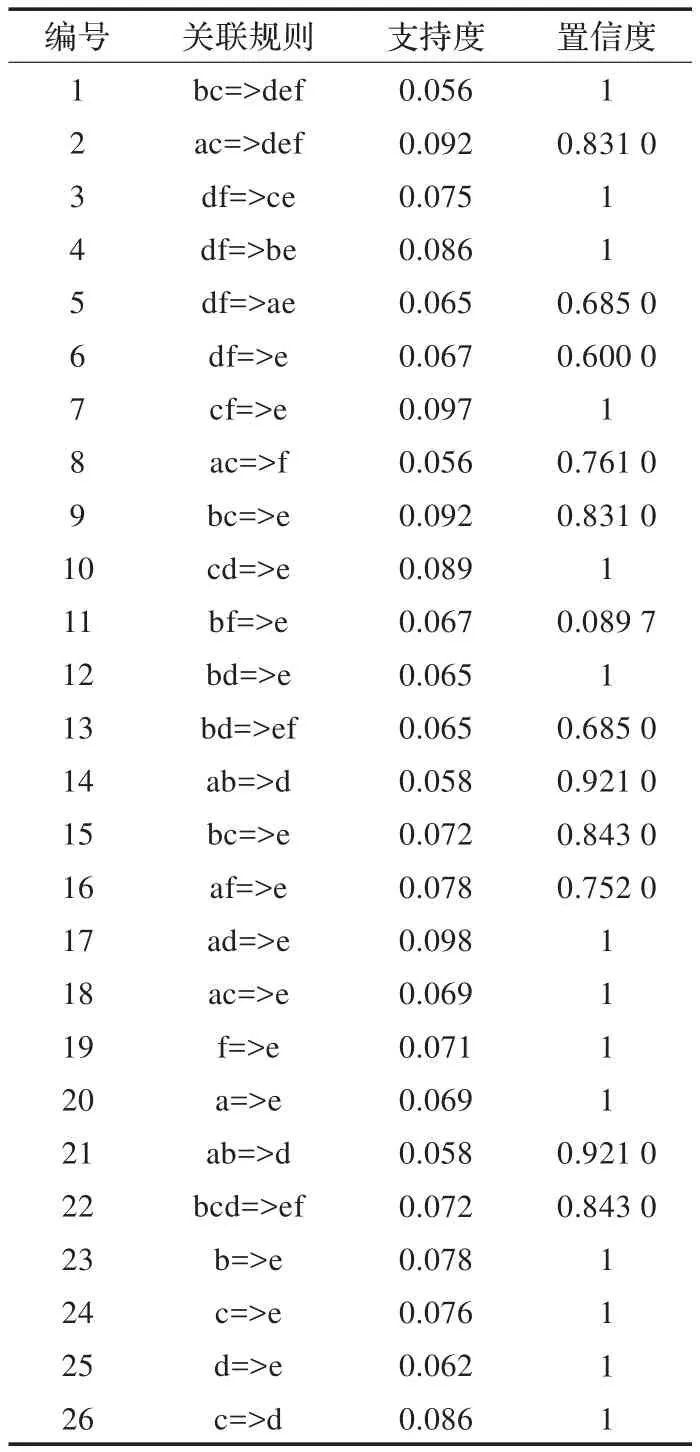
表3 基于Apriori算法的關(guān)聯(lián)規(guī)則
算法1

本例中采用橫向拆分與縱向合并的策略來構(gòu)造最終的Hasse圖。采用分治策略構(gòu)造概念格可以有效地簡化構(gòu)造過程的復(fù)雜性,同時(shí)提高構(gòu)造效率。本文設(shè)定屬性的閥值個(gè)數(shù)為4,即由屬性個(gè)數(shù)大于或等于4的構(gòu)成形式背景1,其余屬性個(gè)數(shù)小于4的屬于形式背景2,拆分后得到的兩個(gè)小形式背景分別如表4、表5所示。
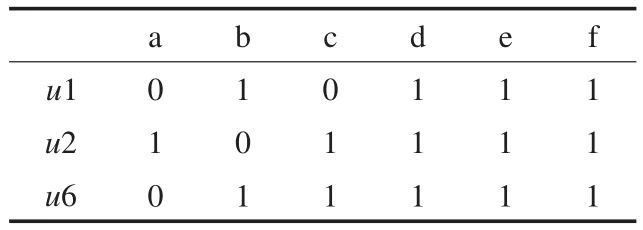
表4 形式背景1
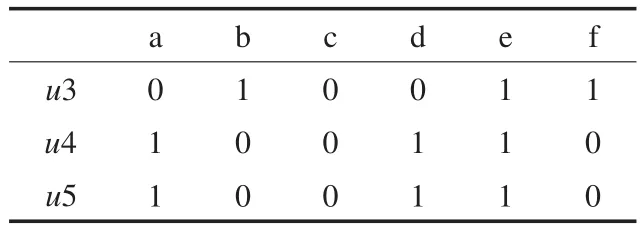
表5 形式背景2
首先對(duì)表4和表5兩個(gè)小形式背景分別構(gòu)造相應(yīng)的概念格,構(gòu)造子概念格的算法偽代碼如算法2所示。
算法2


按照上述算法最終得到的子形式背景的Hasse圖分別如圖1、圖2所示。

圖1 形式背景1對(duì)應(yīng)的Hasse圖
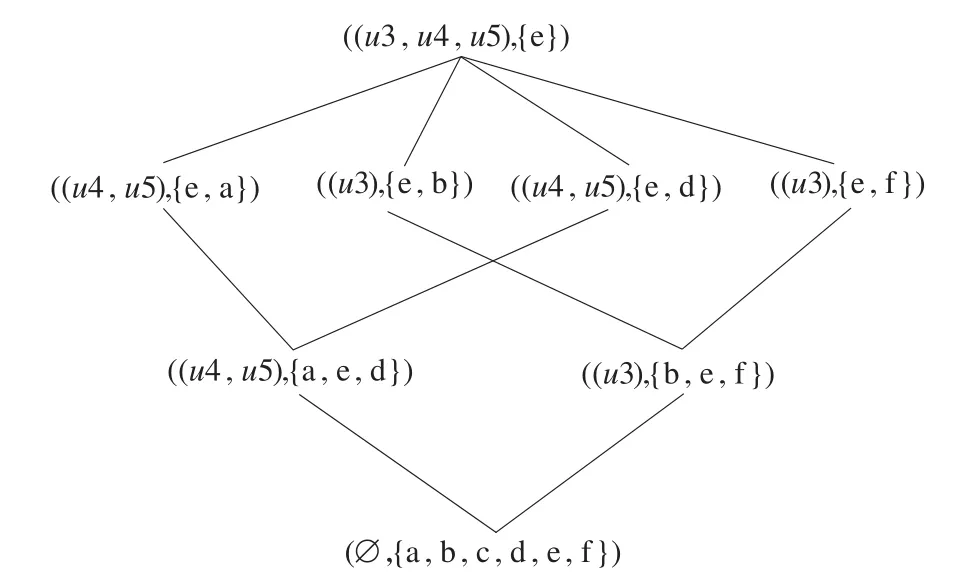
圖2 形式背景2對(duì)應(yīng)的Hasse圖
然后按自上而下的順序?qū)D1和圖2中的概念格進(jìn)行合并,其合并算法的偽代碼如算法3所示。
算法3


根據(jù)算法3得到最終合并后的總體概念格,其對(duì)應(yīng)Hasse圖如圖3所示。
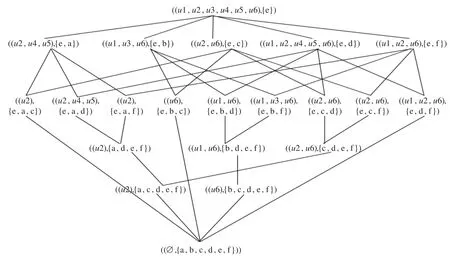
圖3 概念格的整體Hasse圖
3.2.3 基于概念格生成關(guān)聯(lián)規(guī)則
概念格作為數(shù)據(jù)挖掘和提取關(guān)聯(lián)規(guī)則的有效工具,直接通過所有概念格結(jié)點(diǎn)之間的泛化和特化關(guān)系來提取規(guī)則,得到數(shù)量較少的、用戶感興趣的、容易理解和能有效反映真實(shí)情況的關(guān)聯(lián)過則。為了簡化實(shí)現(xiàn)過程,可以用計(jì)數(shù)值來表示每個(gè)概念格結(jié)點(diǎn)的外延。如果外延個(gè)數(shù)大于最小支持度計(jì)數(shù),則說明該結(jié)點(diǎn)的內(nèi)涵就是一個(gè)頻繁項(xiàng)集。因此,在進(jìn)行概念格的關(guān)聯(lián)規(guī)則挖掘之前,首先把概念格進(jìn)行形式上的改變,即用計(jì)數(shù)值來表示概念格結(jié)點(diǎn)的外延個(gè)數(shù),這種概念格就稱為量化概念格。該表示方法具有諸多優(yōu)點(diǎn),主要表現(xiàn)在:在每個(gè)概念格結(jié)點(diǎn)中包含有外延計(jì)數(shù)值,不需考慮外延所包含的具體信息,因此,在只考慮外延計(jì)數(shù)值的情況下,能快速高效地計(jì)算關(guān)聯(lián)規(guī)則的置信度和支持度。本例中概念格的整體Hasse圖量化之后如圖4所示。
從量化概念格中生成關(guān)聯(lián)規(guī)則是數(shù)據(jù)挖掘中的關(guān)鍵,概念格中各個(gè)結(jié)點(diǎn)生成的關(guān)聯(lián)規(guī)則依賴于其雙親結(jié)點(diǎn)。
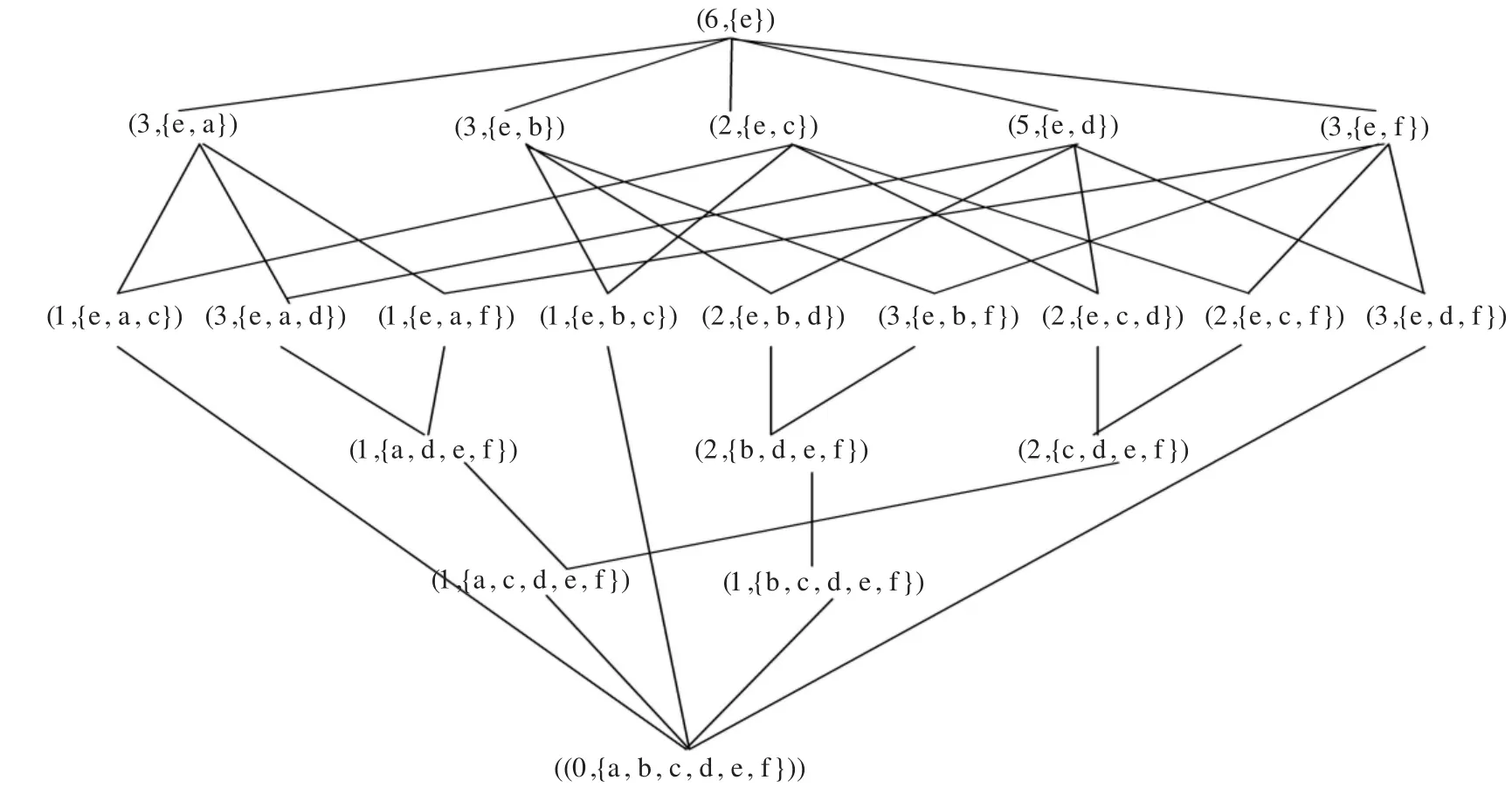
圖4 量化概念格
(1)如果結(jié)點(diǎn) C(X,B)只有一個(gè)雙親結(jié)點(diǎn) C1(X1,B1),則C蘊(yùn)含規(guī)則的前件為(B-B1),對(duì)于?p∈(B-B1),存在的蘊(yùn)含規(guī)則為 p=>B-p。例如,對(duì)于圖4中第二層的第一個(gè)結(jié)點(diǎn)(3,{e,a}),其只有一個(gè)雙親結(jié)點(diǎn)(6,{e}),那么滿足條件,因此該結(jié)點(diǎn)產(chǎn)生的規(guī)則前件是(B-B1)={e,a}-{e}={a},所存在的關(guān)聯(lián)規(guī)則:a=>e。
(2)如果結(jié)點(diǎn) C(X,B)有兩雙親結(jié)點(diǎn) C1(X1,B1)和C2(X2,B2),則對(duì)于 ?p1∈(B1-B1∩B2)?p2∈(B2-B1∩ B2),存在蘊(yùn)含規(guī)則為 p1p2=>B-p1p2。例如圖4中,第三層第二個(gè)結(jié)點(diǎn)(3,{e,a,d})的雙親結(jié)點(diǎn)為(3,{e,a})和(5,{e,d}),則

因此該結(jié)點(diǎn)的規(guī)則為ad=>e。
(3)如果結(jié)點(diǎn) C(X,B)有 n 個(gè)雙親結(jié)點(diǎn) C1(X1,B1),C2(X2,B2),…,Cn(Xn,Bn),則對(duì)于?p∈(B-B1∪B2∪…∪Bn),存在蘊(yùn)含規(guī)則為 p=>B-p。
(4)前面三種方法產(chǎn)生的關(guān)聯(lián)規(guī)則都是概念格結(jié)點(diǎn)與其雙親結(jié)點(diǎn)間的聯(lián)系,置信度全部是1。但概念格結(jié)點(diǎn)內(nèi)涵里也有可能存在強(qiáng)關(guān)聯(lián)規(guī)則,需要進(jìn)一步計(jì)算。例如對(duì)于圖4中第三層的最后一個(gè)結(jié)點(diǎn)(3,{e,d,f}),有|X|/|X1|=3/5=0.6,所以存在強(qiáng)關(guān)聯(lián)規(guī)則df=>e,且置信度為0.6。
根據(jù)上述算法依次計(jì)算各結(jié)點(diǎn)產(chǎn)生的關(guān)聯(lián)規(guī)則,最終由圖4所示的量化概念格得到的關(guān)聯(lián)規(guī)則如表6所示。
3.3 結(jié)果分析
由上述分析可知,根據(jù)量化概念格的Hasse圖,能夠非常容易獲得各個(gè)頻繁項(xiàng)目集,相比Apriori算法更加簡捷直觀。比較表5和表6的數(shù)據(jù),可以看到,通過量化概念格的挖掘得到了20條關(guān)聯(lián)規(guī)則,與Apriori算法相比減少了6個(gè)規(guī)則,但是這6條規(guī)則均可由已經(jīng)產(chǎn)生的規(guī)則推倒得到,基于概念格的關(guān)聯(lián)規(guī)則挖掘只需掃描一次概念格結(jié)點(diǎn)就能生成規(guī)則,經(jīng)典的Apriori算法則需要多次掃描事物數(shù)據(jù)庫,效率較低。因此,該算法在結(jié)果和效率上都比Apriori算法更優(yōu)。
對(duì)于表6中的數(shù)據(jù)進(jìn)行分析,例如選取規(guī)則bc=>def,表示班次和工序次序會(huì)對(duì)庫存數(shù)量、缺貨率和核對(duì)完工數(shù)的影響程度為100%,即會(huì)產(chǎn)生比較重要的影響。這與人們的直觀認(rèn)識(shí)也比較近似,班次、工序次序等安排合理,庫存數(shù)量、缺貨率和核對(duì)完工數(shù)才能達(dá)標(biāo)。另外選取規(guī)則ac=>def,規(guī)則的置信度為83.1%,說明生產(chǎn)線、工序次序會(huì)影響最后的庫存數(shù)量、缺貨率和核對(duì)完工數(shù)。因此,在只考慮生產(chǎn)線、班次、工序次序、庫存數(shù)量、缺貨率和核對(duì)完工數(shù)屬性,不考慮其他各種具體復(fù)雜影響因素的情況下,必須合理安排生產(chǎn)線、班次、工序次序等信息,才能較好地完成工作量。例如,對(duì)于產(chǎn)品序號(hào)為T074的零件,給定一定生產(chǎn)計(jì)劃量:把計(jì)劃量分為6個(gè)階段,分別以字母順序進(jìn)行排序,表示為{A:(0~199)件,B:(200~399)件,C:(400~599)件,D:(600~799)件,E:(800~999)件,F(xiàn):(1000件及以上)},同理,將庫存數(shù)量表示為:{A:(0~99)件,B:(100~199)件,C:(200~299)件,D:(300件及以上)},為了保證缺貨率和核對(duì)完工數(shù)都完全達(dá)標(biāo),針對(duì)本文中分析的6個(gè)屬性,可得到如表7所示的生產(chǎn)計(jì)劃排產(chǎn)情況。

表6 基于量化概念格的關(guān)聯(lián)規(guī)則
本文只選取了部分?jǐn)?shù)據(jù)來說明問題,闡述了該方案的可行性,對(duì)于實(shí)際應(yīng)用中的更多數(shù)據(jù),也能采用同樣的分析方法,通過概念格理論構(gòu)造量化概念格,然后從量化概念格中挖掘關(guān)聯(lián)規(guī)則。對(duì)關(guān)聯(lián)規(guī)則和支持度、置信度逐一進(jìn)行分析,明顯發(fā)現(xiàn)其中隱藏的、人們感興趣的、對(duì)生產(chǎn)調(diào)度有用的信息,然后為管理人員作出排產(chǎn)計(jì)劃提供理論依據(jù),從而指導(dǎo)人們進(jìn)行生產(chǎn),達(dá)到優(yōu)化排產(chǎn)、提高生產(chǎn)效率的目的。
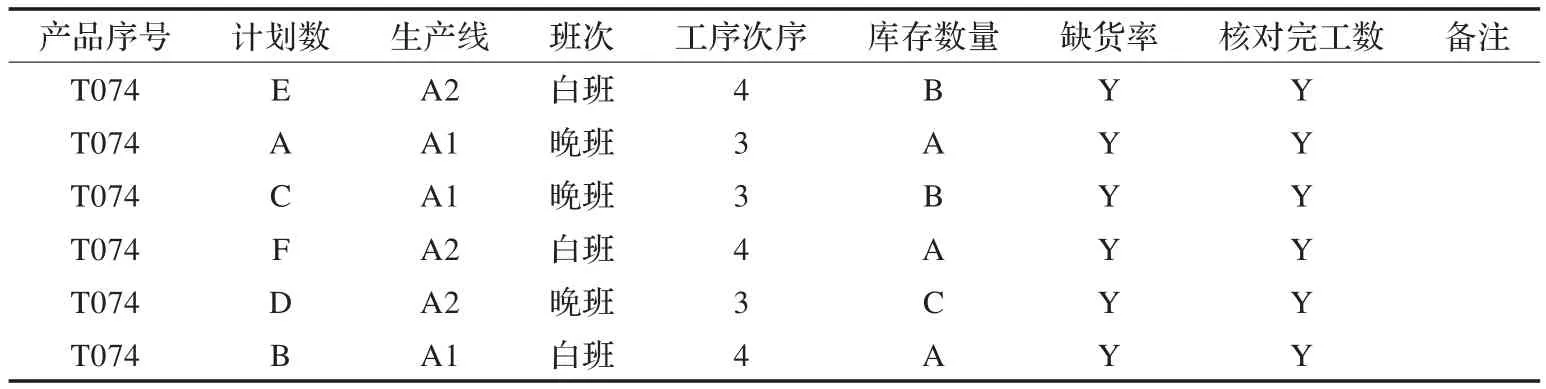
表7 生產(chǎn)計(jì)劃排產(chǎn)表
4 結(jié)論
根據(jù)汽車沖壓廠生產(chǎn)數(shù)據(jù)特點(diǎn)和需求分析,為了優(yōu)化排產(chǎn)和解決生產(chǎn)數(shù)據(jù)量巨大的問題,提出了適合于沖壓廠實(shí)際情況的基于概念格的關(guān)聯(lián)規(guī)則挖掘算法。根據(jù)企業(yè)計(jì)劃,在總體上實(shí)現(xiàn)優(yōu)化排產(chǎn)、改善企業(yè)整體管理水平、提高企業(yè)業(yè)績的目的。首先利用Apriori算法得到關(guān)聯(lián)規(guī)則,然后重點(diǎn)研究了基于概念格的關(guān)聯(lián)規(guī)則在汽車排產(chǎn)管理的應(yīng)用,通過對(duì)比分析可知,采用量化概念格,比Apriori算法更加簡捷、直觀、高效,并且易于理解,能有效實(shí)現(xiàn)規(guī)則的可視化。但是本文只是研究了基于概念格的關(guān)聯(lián)規(guī)則在汽車廠排產(chǎn)管理上的應(yīng)用,討論了數(shù)據(jù)挖掘中的關(guān)聯(lián)規(guī)則技術(shù),在以后的工作中,將深入研究概念格在其他問題上的應(yīng)用,為更多的數(shù)據(jù)挖掘提供理論方法和現(xiàn)實(shí)依據(jù)。
[1]中國統(tǒng)計(jì)網(wǎng).Sybase數(shù)據(jù)分析與管理技術(shù)之四大法寶[EB/OL].(2012-02-05).http://www.itongji.cn/news/0205MR012.html.
[2]Michael J A B,Linoff G S.數(shù)據(jù)挖掘[M].袁衛(wèi),譯.北京:中國勞動(dòng)社會(huì)保障出版社,2004.
[3]胡可云,田鳳占,黃厚寬.數(shù)據(jù)挖掘理論與應(yīng)用[M].北京:清華大學(xué)出版社,北京交通大學(xué)出版社,2008.
[4]文拯.關(guān)聯(lián)規(guī)則算法的研究[D].長沙:中南大學(xué),2009.
[5]高飛.關(guān)聯(lián)規(guī)則挖掘算法研究[D].西安:西安電子科技大學(xué),2001.
[6]何超,程學(xué)旗,郭嘉豐.面向分面導(dǎo)航的層次概念格模型及挖掘算法[J].計(jì)算機(jī)學(xué)報(bào),2011,34(9):1589-1602.
[7]畢強(qiáng),滕廣青.國外形式概念分析與概念格理論應(yīng)用研究的前沿進(jìn)展及熱點(diǎn)研究[J].現(xiàn)代圖書情報(bào)技術(shù),2010,26(11):17-23.
[8]潘燕.數(shù)據(jù)挖掘在汽車銷售企業(yè)CRM中的應(yīng)用[J].計(jì)算機(jī)時(shí)代,2011(11):35-36.
[9]Adomavicius G,Tuzhilin A.Using data mining methods to build customer profiles[J].Computer,2001,34(2):74-82.
[10]Chen Ming-Syan,Han Jiawei,Yu P S.Data mining:an overview from a database perspective[J].IEEE Transactions on Knowledge and Data Engineering,1996,8(6):866-883.
[11]Ngai E W T,Xiu L,Chau D C K.Application of data mining techniques in customer relationship management:a literature review and classification[J].Expert Systems with Applications,2009,36(2):2592-2602.
[12]Qu K S,Liang J Y,Wang J H,et al.The algebraic properties of concept lattice[J].Journal of Systems Science and Information,2004,2(2):271-277.
[13]Eklund P,Villerd J.A survey of hybrid representations of concept lattices in conceptual knowledge processing[C]//Lecture Notes in Computer Science,2010,5986:296-311.
[14]畢建新.基于APS的企業(yè)生產(chǎn)線調(diào)度系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)[D].沈陽:東北大學(xué),2011.
[15]滕廣青,董立麗,田依林,等.基于概念格的社區(qū)用戶知識(shí)需求模型研究[J].情報(bào)科學(xué),2013,29(1):108-122.
[16]胡立華,張繼福,張素蘭.一種基于剪枝的橫向分塊概念格構(gòu)造算法[J].小型微型計(jì)算機(jī)系統(tǒng),2011,32(7):1394-1399.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當(dāng)代陜西(2021年17期)2021-11-06 03:21:36
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學(xué)苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版)(2016年9期)2017-01-15 13:52:02
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
