面向軟件構件的網頁爬蟲技術研究
2014-04-29 00:44:03賽買提·艾力玉素甫·艾白都拉
電腦迷 2014年9期
賽買提·艾力 玉素甫·艾白都拉
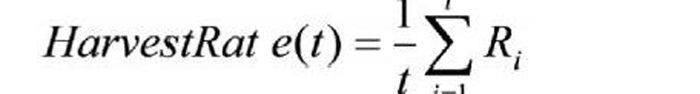
摘 要 面向構件的垂直搜索引擎是該領域內的一個研究熱點。本文介紹面向構件的主題爬蟲的設計與實現,提出一種基于URL的面向構件的主題爬行算法,該爬行算法以構件資源在構件庫網站的所處的位置,對URL隊列進行優先級計算。對頁面相關性判別,采用刻面關鍵詞出現的頻率來計算。實驗結果表明該方法可行而且更有效。
關鍵詞 軟件構件 構件描述 主題爬蟲 相關度計算
中圖分類號:TP3 文獻標識碼:A
0引言
軟件復用是解決軟件危機的一條切實可行的途徑。軟件構件技術是軟件復用的主要形式,也是當前軟件復用研究的熱點。成功的實施軟件復用,需要大量而豐富的軟件構件資源。目前在Internet上已有大量的構件資源,但在實際工作中想迅速找到適用的構件是非常困難的,傳統的通用搜索引擎并不能對這些構件進行有效的搜索。
垂直搜索引擎技術的出現與發展為實現Internet上構件資源的搜索提供了解決思路和技術保證。垂直搜索引擎只抓取索引特定主題的信息,可以向用戶提供更加專業化、個性化的搜索服務,可大幅度提高某個主題信息的查全率和查準率,有效地解決了通用搜索引擎對某個主題覆蓋率過低的憋端。
然而,目前市場上并沒有出現面向構件的垂直搜索引擎,學術界對構件的存儲與檢索仍然停留在單一構件庫的層面。在Internet已經普及的今天,傳統的單一的構件庫技術顯得有些滯后,如果能為軟件復用人員提供一個語義豐富檢索方便的構件檢索平臺,必將有助于基于構件的軟件開發方法在實踐上的普及應用。
1國內外研究現狀
為了利用Internet上豐富的構件資源,幫助開發人員獲取所需的構件,研究人員開始探討如何在Internet上獲取構件。
卡耐基梅隴大學的Seacord等人提出了Agora系統來在Internet上獲取構件。該系統由若干個Agent組成,這些Agent分別用來獲取如JavaBean、ActiveX等不同形式的構件。Extreme Harvest通過語法結合語義的方式來對Internet上的構件進行過濾,尋找滿足用戶需要的構件資源。MoReCOTS則是利用元搜索引擎技術并以構件提供網站為內容來源向用戶提供一個構件檢索接口。Chen等人提出了一種構件獲取方法SE4SC,該方法是首先定義一個構件描述模型SCDM,并利用網絡爬蟲在Internet上抓取其它滿足SCDM格式要求的構件。
2網頁爬蟲的設計
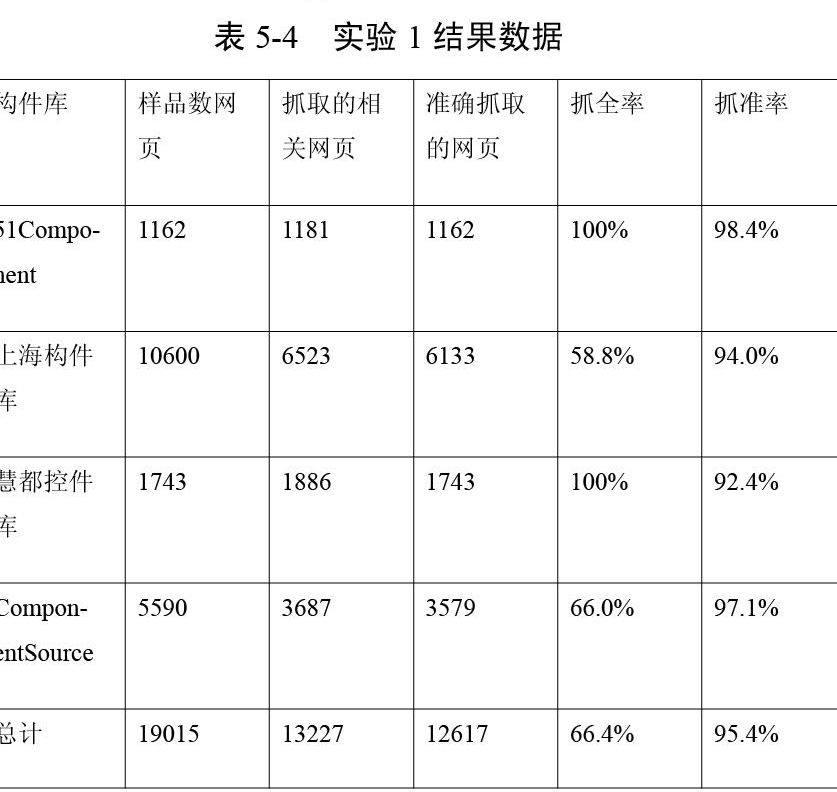
圖1是面向構件的主題爬蟲系統結構圖。爬蟲從種子URL開始,向服務器發送HTTP 請求,請求URL 對應的資源,分析下載的頁面,提取鏈接,將鏈接加入URL 隊列,以便后續讀取。
2.1頁面的相關度計算
通過觀察發現構件庫網站對構件的描述用<刻面,術語>二元組,而且所使用的刻面關鍵字比較集中,如圖2所示。本文通過刻面關鍵字在網頁中的出現頻率來計算網頁的主題相關度。文檔包含的關鍵詞越多,頁面的相關性就越高。如果關鍵詞數量大于指定的闊值,則網頁與主題相關,否則網頁與主題無關。
2.2主題爬行算法
一般網站結構可分為兩種,即扁平式結構和樹形結構。扁平式結構是指把全部的網頁存儲在相應網站的根目錄下的結構,這種結構總體上來說比較適用于一些小型的網站。另一種結構就是樹形結構,在樹形結構,首先是根目錄下分成很多的子目錄,之后在各個子目錄下分別存儲從屬于該目錄下的網頁文件。很顯然,樹形結構可以非常方便的列出某一網站的內容架構,因此,樹形結構也是大型網站必定會使用的結構方式。
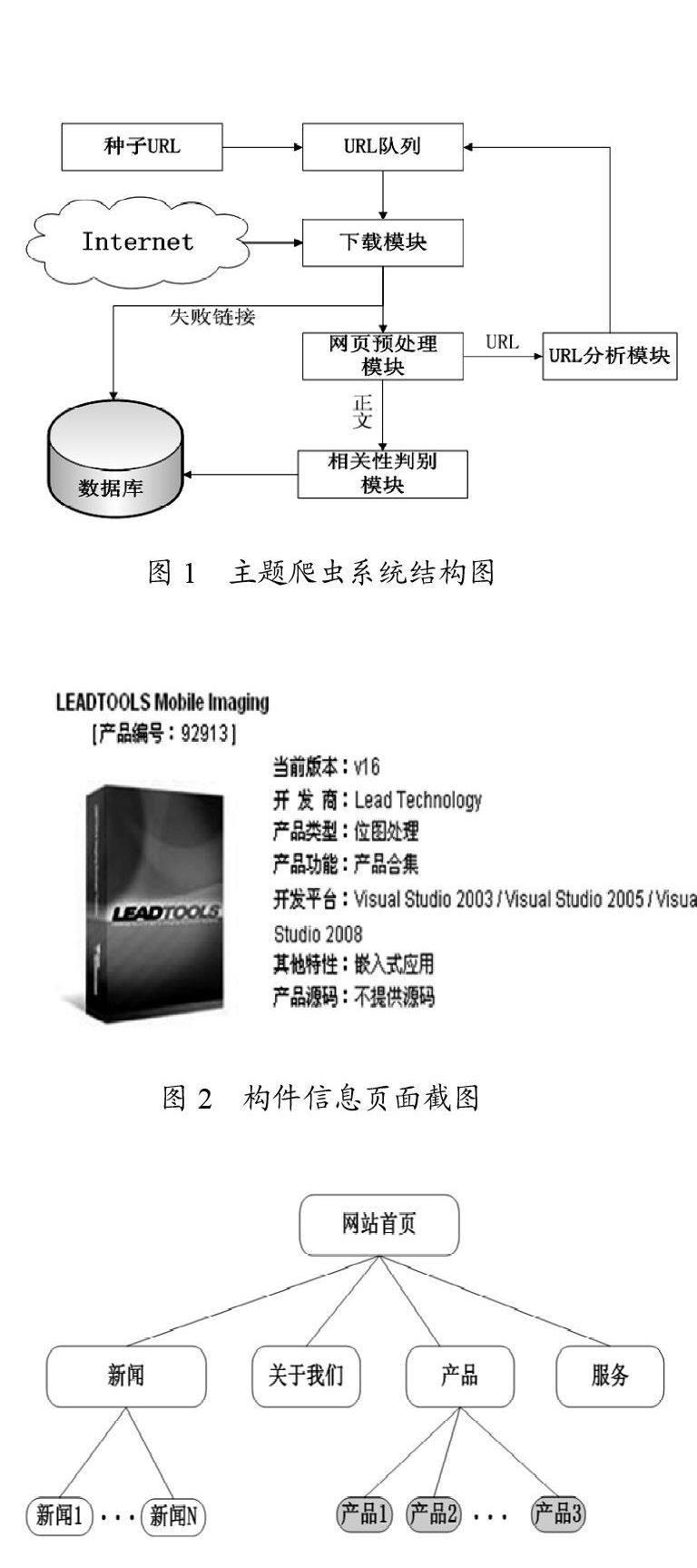
通過觀察分析,得知構件庫網站結構大致相同,圖3是構件庫網站的結構示意圖。從圖中可以看出爬蟲要尋找的主題網頁都集中在一個目錄下,而且位置相對固定。本文采用構件庫網站的這一特性來計算待爬行URL的重要度。
主題爬行算法的本質是對待爬行URL進行調度策略,使得爬蟲在更短的時間、更節省網絡資源的條件下,抓取更多的主題相關網頁。由于構件頁面分布特性、構件庫網站異構性、錨文本相似度計算的困難性等問題,不可能對全部待爬行URL進行優先級計算。本小節提出了一個在構件庫網站內對URL進行重要度計算的方法,其基本思想是爬蟲從種子網頁開始,獲取網頁中的子鏈接,如果抓取的子鏈接與父鏈接的域名相同,則計算它的重要度,重要度大于闊值%[,則進入URL隊列。如果子鏈接與父鏈接域名不同,則丟棄。
該爬行算法通過比較待爬行URL和主題相關網頁的URL來計算待爬行URL的重要程度。首先根據待爬行URL和主題相關網頁的URL畫出結構圖,然后計算待爬網頁存儲目錄和主題相關網頁存儲目錄之間的路徑長度。待爬行URL的重要度大小用如下公式計算:
(1)
該爬行算法使用的相關網頁的URL值是一同種子給出。
3實驗結果分析
本節從中文構件庫上海構件庫、51Component、慧都控件庫和英文構件庫ComponentSource網站選擇某一構件主題相關網頁作為種子網頁。其實驗結果表1所示。實驗結構表明,該爬行算法對構件產品的抓全、抓準率比較高,達到了預期的目的。通過公式2計算,收獲率(HarvestRate)達到了34.6%。
(2)
4總結
隨著軟件產業的迅速發展,軟件復用技術,尤其是基于構件的軟件復用技術正逐步走向成熟,構件及構件庫作為基于構件的軟件開發的基礎設施,正逐步得到軟件開發人員的重視,互聯網上出現的構件庫以及提供眾多構件資源的網站,為軟件開發者提供了更高的思路。本文正是這一背景下,研究了面向構件的主題爬蟲。
基于URL的爬行算法對種子網頁的選取要求比較嚴格,種子網頁越多,抓取網頁數量越多,構件庫網站構件數量越多,收獲率就越高。該爬行算法比較適用于專業構件庫網站中的構件抓取。但Internet上散落存在的構件資源的獲取還沒真正得到解決。
參考文獻
[1] M.Douglas Mcilroy. Mass-Produced Software Components.in NATO Conference on Software Engineering 1968.88~98.
[2] R.C.Seacord,S.A.Hissam,K.C.Wallnau. Agora:A Search Engine for Software Components.IEEE Internet Computing.1998,VOL.6(2):62~70.
[3] Oliver Hummel, Colin Atkinson. Supporting Agile Reuse Through Extreme Harvesting.8th International Conference, XP 2007:28~37。
[4] 鄭瑾,王斌,陳松喬.Java Bean構件檢索引擎.計算機工程.2003,Vol.29(20):45~46.
[5] 劉金紅,陸玉良.主題網絡爬蟲研究綜述.計算機應用研究.2007,Vol.24 (10):26-29.
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
中國衛生(2015年12期)2015-11-10 05:13:38
現代企業(2015年9期)2015-02-28 18:56:50
警察技術(2015年3期)2015-02-27 15:37:09
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
土木建筑工程信息技術(2013年2期)2013-10-17 03:14:12
