面向眾核GPU加速系統的網絡編碼并行化及優化
2014-09-12 11:17:14唐紹華
計算機工程與應用 2014年21期
關鍵詞:優化
唐紹華
湖南工程職業技術學院信息工程系,長沙 410151
◎網絡、通信、安全◎
面向眾核GPU加速系統的網絡編碼并行化及優化
唐紹華
湖南工程職業技術學院信息工程系,長沙 410151
網絡編碼允許網絡節點在數據存儲轉發的基礎上參與數據處理,已成為提高網絡吞吐量、均衡網絡負載和提高網絡帶寬利用率的有效方法,但是網絡編碼的計算復雜性嚴重影響了系統性能。基于眾核GPU加速的系統可以充分利用眾核GPU強大的計算能力和有效利用GPU的存儲層次結構來優化加速網絡編碼。基于CUDA架構提出了以片段并行的技術來加速網絡編碼和基于紋理Cache的并行解碼方法。利用提出的方法實現了線性隨機編碼,同時結合體系結構對其進行優化。實驗結果顯示,基于眾核GPU的網絡編碼并行化技術是行之有效的,系統性能提升顯著。
網絡編碼;圖形處理器(GPU);并行;計算統一設備架構(CUDA);優化
1 引言
網絡編碼在提高網絡吞吐量、改善負載均衡、減小傳輸延遲、節省節點能耗、增強網絡魯棒性等方面均顯示出其優越性[1]。因此,網絡編碼一經提出便引起了國際學術界的廣泛關注,其理論和應用已廣泛應用于分布式文件存儲[2]、P2P系統[3-4]、無線網絡[5]。然而,現實網絡環境的非確定性[6]、網絡編碼的計算復雜性[7]等因素嚴重影響了系統整體性能,使得網絡編碼技術的實用性不強。因此,網絡編碼優化成為推動網絡編碼技術更具實用性的重要手段[8-9],其中,優化網絡編碼的計算通信開銷更是研究的熱點,包括網絡編碼算法的構造設計以及基于硬件的網絡編碼加速[7,10-12]。
雖然研究者在利用GPU加速網絡編碼方面進行了較為深入的研究,也取得了可喜的成績。但是,他們的工作都傾向于最大化GPU計算資源的利用率,GPU計算資源耗費不少,然而并行網絡編碼系統的效率并不高;同時,對結合GPU體系結構和存儲層次而展開的優化工作也尚有不足。本文的工作將致力于結合眾核GPU體系結構設計高效的并行網絡編碼算法和面向GPU存儲層次對并行網絡編碼進行優化。

圖1 CUDA執行模型
2 眾核GPU體系結構及CUDA編程模型
CUDA(Computing Unified Device Architecture,CUDA)是NVidia為適應GPU通用計算而推出的一種高性能GPU體系架構,支持CUDA的GPU是一塊具有可擴展處理器數量的處理器陣列,與傳統GPU最大的區別在于,它擁有片內共享存儲空間用以減小片外訪存延遲[13]。CUDA執行模型以CUDA硬件架構為基礎,如圖1所示。
CUDA源程序由運行于host(CPU)上的控制程序和運行于device(GPU)上的計算核心(kernel)兩部分組成。每一個kernel由一組相同大小的線程塊(thread block)來并行執行,同一線程塊里面的線程通過共享存儲空間來協作完成計算,線程塊之間是相互獨立的。運行時,每一個線程塊會被分派到一個流多處理器(Streaming Multi-processor,SM)上運行,一個SM包括8個線程處理器(Threaded Processor,TP)和一段大小為16 KB的共享存儲空間(Shared Memory),另外,GPU還提供了一定數量的全局的只讀的紋理Cache和常量Cache[14]。
3 基于CUDA架構的并行網絡編碼
網絡編碼的本質是賦予節點計算能力以提高鏈路帶寬的利用率。圖2(b)闡述了網絡編碼的基本原理,圖中s是信源,x和y是信宿,假設各邊的帶寬均為1 bit/s,現要將2比特數據a和b同時從s傳到x和y。s與x和y之間均分別存在兩條獨立路徑,若采用傳統路由方法,如圖2(a)所示,由于存在共有鏈路wz,a和b不能同時在wz上傳輸;若采用網絡編碼方法,在節點w上對a和b執行異或操作并轉發,則節點x可以通過a⊕b⊕a計算解碼得到b,同理y也可以解碼得到a,從而提高了帶寬利用率。
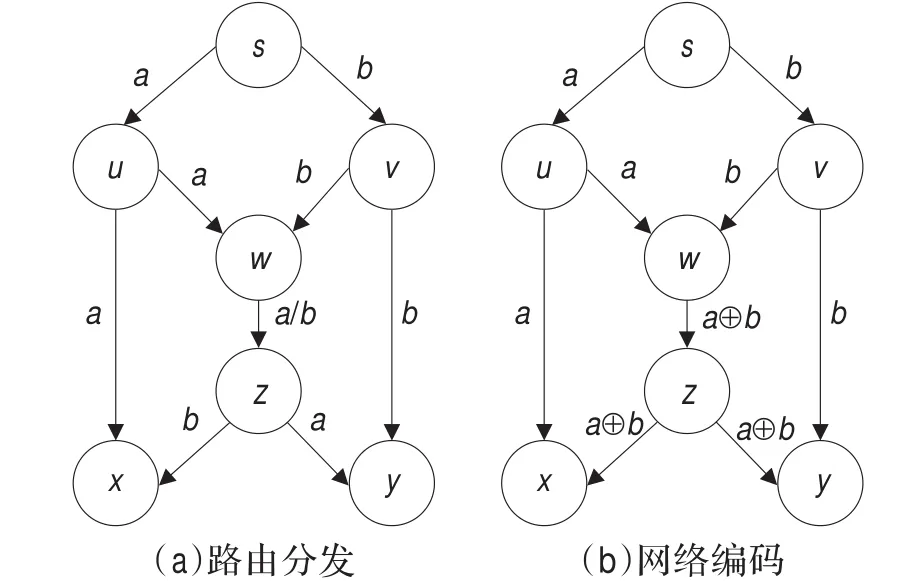
圖2 路由分發與網絡編碼比較
網絡編碼按照節點輸出和輸入的關系可劃分為線性網絡編碼和非線性網絡編碼,根據編碼系數生成的隨機性可劃分為隨機網絡編碼和確定網絡編碼[1],實用的網絡編碼系統大多采用隨機線性編碼[2-3,6-7,9-12]。然而,隨機網絡編碼計算復雜度較高,嚴重影響了編碼系統的性能,為此,本文基于眾核GPU加速的系統設計并實現了并行的隨機網絡編碼算法,并且有效利用GPU存儲層次對其進行優化,使得隨機網絡編碼系統的性能有了顯著性的提升。
3.1 隨機線性編碼
所謂線性網絡編碼就是將節點傳送信息線性映射到一個有限域內,利用線性關系實現編譯碼的過程[9]。通信網絡G(V,E)中,信源s∈V的輸入數據b被分割為n個數據片段b1b2…bn,每個片段含有k個字節。一個網絡節點可以在有限域內獨立地選擇一組隨機編碼系數c1c2…cn,生成一個k字節的編碼片段X,即

由于每個編碼片段X是原始數據片段的一個線形組合,因此編碼片段可以由線形組合中的參數集唯一確定。當一個節點接收到n個線性無關的編碼片段[X1,X2,…,Xn]T,就可以進行解碼。
根據每個原始片段的系數構造一個n×n的系數矩陣C,C的每一行對應于一個編碼片段的系數,然后利用C解碼得出原始片段。

在方程(2)中,可以利用高斯消元法計算矩陣C的逆,再與X相乘,其復雜度為ο(n2·k)。其中,當C是行線性無關時,C的逆存在。
3.2 片段編碼并行化
正如文獻[7,10-12]中歸納的:線性編碼的主要性能瓶頸集中于有限域上的乘法操作和循環計算每個片段中n×k個字節的乘加操作。因此,優化加速有限域上的乘法、循環乘加操作對提高網絡編碼的性能至關重要。文獻[7,10-12]都采用將有限域上的乘法操作轉換為基于對數和指數的并行查表,即

將有限域上的對數和指數預先計算好存儲起來,將有限域上的一次乘法操作轉換為三次查表和一次加法操作。
在計算受限的系統中,上述過程將昂貴的乘法操作轉換為相對廉價的查表和加法操作,對系統的性能有一定的提升。但是,在存儲受限的GPU結構中,訪存查表很可能比乘法計算的延遲更大,并且,將有限域上的對數表和指數表緩存起來對共享存儲空間的壓力太大并且訪存沖突、復用率等因素也值得考慮;即使在計算受限的結構中,可以更加激進地將有限域上的一次乘法操作轉換為一次查表完成。
支持CUDA的GPU雖然擁有一定的片內共享存儲空間用以減小片外訪存延遲,但是共享存儲空間受限只有16 KB,并且顯式地分派管理數據極易引起訪存沖突。但是,支持CUDA的GPU擁有數以百計的計算核,計算比訪存更有優勢。因此,基于片段的并行編碼將采用啟動數以千記的線程同時編碼的方法來分攤昂貴的乘法開銷。
在支持CUDA架構的GPU上,最直接的并行算法就是將每一個數據片段都交付給一個獨立的線程去處理,這樣只要數據片段足夠多,就可以啟動大量的線程來同時執行,因此,可以將片段劃分得足夠小,以獲得啟動更多的線程。片段的大小為1 bit不合適,數據片段沒有實際意義;數據通常以字節為單位,那么以字節為單位似乎更合理。但是片段太小只會浪費計算資源,更重要的是會增加線程之間的通訊開銷。由于現有的支持CUDA的GPU計算核的字長為32位,因此,選擇片段的大小為2個字節,不夠的可以在末尾補0,這樣兩個大小為2個字節的數據相乘,其結果在有效范圍內,并且數據精確度高。
設輸入數據b被可以分割為n個大小為2個字節數據片段b1b2…bn,將每一個片段都分派給一個線程來處理,則所需要的線程數目為:

若設置每個線程塊包含512個線程,則所需要的線程塊的數目為:

并行編碼的流組織過程如圖3所示。圖3中演示了一個線程塊中512個線程并行加載數據和進行數據編碼的過程。在CUDA架構中同一個線程塊內的線程在編譯調度時會被分派到同一個流多處理器上,因此它們共享一個大小為16 KB的共享存儲空間(Shared Memory)。在并行編碼中使用共享存儲空間加載原始數據片段,處理完后直接存放在共享存儲空間,通過有效使用共享存儲空間可以減少數據的存取訪問時間。
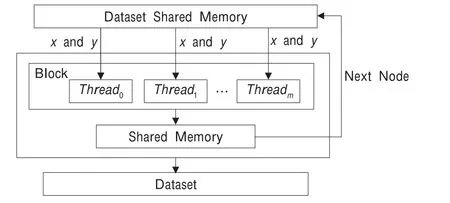
圖3 并行編碼
3.3 主機協作并行解碼
正如文獻[7]中歸納的:解碼過程與編碼相比具有更高的計算復雜度,最為關鍵的是解碼過程內在的并行性更少,后面節點的解碼依賴于前面節點的解碼結果,因此節點之間還必須同步。文獻[10]提出了一種漸進式的高斯-約當消元法來提高解碼效率;Shojania等人在文獻[7,11]中也是采用高斯-約當消元法來解碼,不同的是,他們建議將GPU與CPU協作起來進行解碼。基本方法是:由CPU生成隨機系數,在GPU上計算矩陣的逆并解碼。

表1 支持CUDA的GPU存儲結構
CPU與GPU協作進行解碼是一個明智的選擇,但是,CPU還可以承擔系數矩陣求逆的任務,然后將C-1傳遞給顯存,因為矩陣求逆和GPU計算kernel可以異步執行,即,CPU將編碼kernel啟動后可以執行主機上的矩陣求逆,等待編碼結束后可以在最短時間內將CPU計算的逆矩陣傳遞給顯存。考慮到C-1的復用性高,還可以進一步將其緩存起來,在支持CUDA的GPU中,紋理Cache專門為二維空間位置而優化過并且C-1無需更新,所以將C-1直接綁定緩存至紋理存儲空間。
考慮到網絡解碼過程內在并行性的特點,并行網絡解碼將參考文獻[13]中tiled模式的矩陣乘法來解碼。
4 面向體系結構的并行編碼優化
面向GPU結構的編程需要顯式管理分派數據,因此結合GPU體系結構,尤其是有效利用GPU的存儲層次進行優化對整個系統的性能提升尤為重要,因此,下面將面向GPU的體系結構對并行網絡編碼系統進行優化。
4.1 有效利用GPU存儲層次
CUDA線程可在執行過程中訪問多個存儲器空間的數據,如表1所示。
共享存儲空間(Shared Memory)的有效使用是CUDA應用優化最常用、最容易想到的存儲優化技術,這是因為共享存儲器位于流多處理器片上,并且它為一個線程塊內的線程共享,為同一線程塊內的線程之間的通信提供了便利,同時,與全局存儲器相比,其速度要快得多。但是,共享存儲器的存儲空間大小有限,并且對數據的分派管理不當,會引起存儲體沖突,這時訪存就必須序列化,降低了有效帶寬。因此,并行編譯碼時,謹慎使用共享存儲器很有必要。
并行編碼過程中,使用共享存儲空間存放中間數據結果,為后面的數據處理做準備,可以避免數據在全局存儲空間來回傳遞,有效減少了訪存延遲,并且簡化了中間流的管理;并行解碼過程中,可以將系數矩陣的逆復制給每一個流多處理的共享存儲器,可以避免同一個線程塊里面的線程重復訪問全局存儲器。考慮到共享存儲器的空間受限并且作用廣泛,解碼過程將求助于其他優化方法。
4.2 基于設備運行時組件加速乘法操作
如前面所述,文獻[7,10-12]都采用將有限域上的乘法操作轉換為基于對數和指數的并行查表來避免乘法操作,本文通過大量線程并行來分攤乘法操作的開銷。同時,CUDA運行時庫支持的設備運行時組件中包括了幾乎所有的數學標準庫函數[11]。這些設備運行時組件會被映射到GPU上的一條指令或一個指令系列,這些設備組件內部的數學函數是標準庫函數精確度較低但速度更快的版本,但是,加法和乘法是符合IEEE規范的[11],因此精度與標準庫函數相同。
因此,設備運行組件支持的數學函數__fmul_(x,y)和__fadd_(x,y)將嘗試應用于網絡編碼計算中以進一步改善系統性能。
4.3 基于紋理Cache并行解碼
紋理Cache其實就是全局存儲器的一個特定區域。但是,紋理Cache空間是被緩存的,因此紋理獲取僅需在緩存內容失效時才讀取一次全局存儲器,否則只需讀取紋理緩存即可。同時,紋理緩存已為二維空間位置而優化過,通過只讀的紋理Cache也可以緩存無需更新的系數矩陣的逆,并且紋理Cache專門為二維空間位置而優化過[11],有利于存儲二維的數據結構。因此,并行解碼過程中,將主機計算好的系數矩陣的逆存儲在紋理Cache中,可以充分利用紋理Cache的優勢,加快各個線程對系數矩陣逆的訪問,基于紋理Cache的并行解碼過程如圖4所示。

圖4 基于紋理Cache并行解碼
5 實驗評估與性能分析
為了驗證基于GPU架構的并行網絡編碼系統的有效性和高效性,在Nvidia GTX280實驗平臺上模擬了網絡編碼過程,其中GTX280的主要參數如表2所示。測試的原數據大小包括16 KB、32 KB、64 KB和128 KB;評估了并行編碼速度和基于紋理Cache解碼帶寬兩個主要的性能指標。

表2 Nvidia GTX280的相關配置
5.1 基于紋理Cache并行解碼
圖5顯示了編碼片段大小對編碼運行速度的影響,由圖5可以發現,片段越小(1 Byte),雖然可開發的并行性越多,但是編碼速度卻遠低于期望值;編碼片段大小選擇為2個Byte,雖然可開發的并行性似乎減少了,但是性能卻表現較好;編碼片段大小選擇為4個Byte時所表現出來的性能與選擇為2個Byte時差別不大,同時,由于受到GPU計算核字長的限制,片段大小超過2個Byte后,計算的精確度就很難保證了。由圖5可以得出,片段并不是越大越好,也不是越小越好,這是因為,并行粒度的大小與計算資源的利用率以及線程間的通信息息相關,只要充分利用計算資源就好,并不是所有計算資源都忙起來就好,當然也不能讓它們處于空閑。因此,實驗數據也說明選擇片段大小為2個Byte是正確的、高效的。

圖5 片段大小對編碼時間的影響
5.2 基于片段的并行編碼速度
為了驗證基于片段的并行網絡編碼的高效性,標識文獻[7,10-12]采用將有限域上的乘法操作轉換為基于對數和指數的并行查表的技術進行編碼的方法為TB(Table-Based);標識本文提出的基于片段并行編碼的方法為Frag;Frag方法是一個原生的并行技術,并沒有對其結合GPU結構進行優化;因此,標識經過優化的片段并行方法為Frag+Opt,這些優化方法主要包括面向GPU體系結構的一些優化技術,主要包括:基于設備運行時組件加速乘法操作和有效利用共享存儲空間優化線程間通信和簡化中間流管理。
圖6和表3顯示了基于片段的并行編碼及其優化技術對編碼性能提升的影響,基于片段的并行編碼與基于查表的編碼方法相比較,性能提升顯著,但是面向GPU體系結構的優化對編碼速度的提升并不是很明顯,這是因為并行編碼的性能瓶頸不在于乘法操作到底是多少個周期內完成,同時,由于選擇的片段大小為2 Byte,其乘法操作符合GPU字長的要求,因此不需要分割數據進行循環乘加運算,也減少了進程間通信的機會。因此,面向GPU結構的優化在此對性能的提升不明顯,但是這些優化方法可以推廣至其他GPU應用中。

圖6 編碼速度比較圖
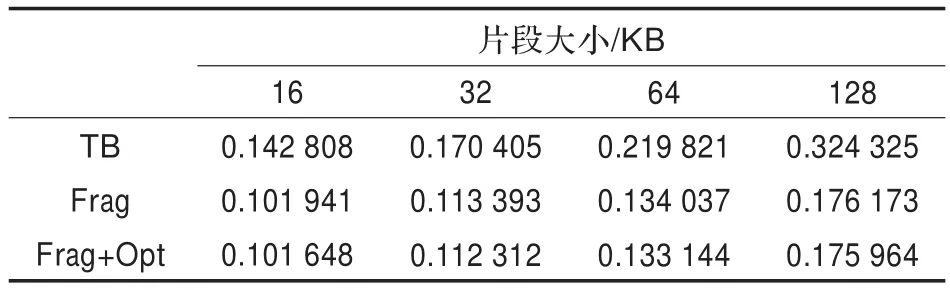
表3 編碼速度比較表
5.3 基于紋理Cache的并行解碼帶寬
圖7和表4顯示了紋理Cache對并行解碼性能的提升是顯著的。在不引入紋理Cache進行緩存優化的情況下,在平臺Nvidia GTX280下,每個線程塊運行512個線程時,其帶寬利用率與Shojania等人在文獻[11]中的相同配置下的表現相當;引入紋理Cache對系數矩陣的逆進行緩存優化后性能攀升顯著。性能提升的另外一個重要原因就是本文將隨機系數生成、矩陣求逆等任務都交給了主機,也減少了GPU的處理時間,主機協作對帶寬利用率的提升貢獻也不少。而Shojania等人在文獻[11]中只是將部分任務交給了主機。因此,紋理Cache緩存以及主機協作計算等都是并行解碼過程中帶寬利用率提升的重要原因。

圖7 解碼帶寬比較圖

表4 解碼帶寬比較表
5.4 系統性能分析
分析圖6和圖7的實驗數據可以發現,Frag方法與TB方法比較,編碼的速度提升了2倍之多;基于紋理Cache的并行解碼的帶寬利用率也提升了近2倍。雖然這個加速比不是很高,但是它比較的對象是網絡編碼在GPU上優化后的實現版本,并不是與單核或多核CPU比較的結果,因此這個性能加速比還是可以接受的。
但是,從圖6還可以發現Frag+Opt方法與Frag方法比較,性能提升不明顯,這與設計的初衷是不統一的。為了充分發揮Shared Memory的效用,減輕Shared Memory的壓力而求助紋理Cache優化并行解碼,但是Shared Memory最后發揮的效用甚微,因此,Shared Memory可以嘗試用來緩存系數矩陣,因為訪問Shared Memory比訪問紋理Cache更有優勢。當然,基于紋理Cache緩存系數矩陣也有自己的優勢,它的空間比較大,可以緩存較大量的數據集,這是Shared Memory所不能比的。
同時,比較表2和圖6還可以發現,即使是基于紋理Cache優化后的帶寬利用率也是很低的,當然,這個帶寬利用率不能僅僅只與GPU內部的最大的可用帶寬比較,因為它還受限從CPU到GPU的數據傳輸速率。但是,比較表2和圖6至少可以說明基于GPU的并行網絡編碼系統的性能瓶頸在于存儲帶寬。如何進一步提高GPU存儲帶寬的利用率將會成為研究的難點。
總之,基于眾核GPU加速應用必須深入理解GPU的體系結構及存儲層次,權衡技術的利弊及相互影響,最大限度開發利用GPU的資源。
6 結束語
網絡編碼一經提出便引起了工業界和學術界的廣泛關注和認同,但是現實中網絡編碼的應用還遠未普及,在很大程度上是因為網絡編碼引入的計算開銷。基于眾核GPU加速的系統來優化加速網絡編碼可以有效緩解上述難題,但是,GPU結構是一種新涌現的高性能體系結構,如何更好地利用其強大的計算資源和可用的存儲帶寬、GPU與主機之間的通訊協作、GPU應用的自動優化技術等亟需更深入的研究。
[1]楊林,鄭剛,胡曉惠,等.網絡編碼的研究進展[J].計算機研究與發展,2008,45(3):400-407.
[2]Dimakis A G,Godfrey P B,Wainwright M,et al.Network coding for distributed storage systems[C]//Proceedings of the 26th Annual IEEE Conference on Computer Communications(INFOCOM 2007),Anchorage,USA,2007:2000-2008.
[3]Jafarisiavoshani M,Fragouli C,Diggavi S.Bottleneck discovery and overlay management in network coded Peerto-Peer systems[C]//Proceedings of the SIGCOMM Workshop on Internet Network Management,Kyoto,Japan,2007:293-298.
[4]Gkantsidis C,Miller J,Rodriguez P.Comprehensive view of a live network coding P2P system[C]//Proceedings of the 6th ACM SIGCOMM on Internet Measurement,New York,NY,2006:177-188.
[5]汪洋,林闖,李泉,等.基于非合作博弈的無線網絡路由機制研究[J].計算機學報,2009,32(1):54-68.
[6]Chou P.Practical network coding[C]//Proceedings of the Allerton Conference on Communication,Control,and Computing,Monticello,IL,2003:63-68.
[7]Shojania H,Li Baochun.Pushing the envelope:extreme network coding on the GPU[C]//Proceedings of the 29th IEEE International Conference on Distributed Computing Systems,Montreal,QC,2009.
[8]黃政,王新,Huang Z.網絡編碼中的優化問題研究[J].軟件學報,2009,20(5):1349-1360.
[9]Ho T,Medard M,Koetter R,et al.A random linear network coding approach to multicast[J].IEEE Transactions on Information Theory,2006,52(10):4413-4430.
[10]Shojania H,Li Baochun.Parallelized network coding with hardware acceleration[C]//Proceedings of the 15th IEEE International Workshop on Quality of Service,Chicago,IL:2007:1-9.
[11]Shojania H,Li Baochun,Xin W.Nuclei:GPU-accelerated many-core network coding[C]//Proceedings of the INFOCOM,Rio de Janeiro,Brazil,2009:459-467.
[12]Chu X W,Zhao K Y,Wang M.Massively parallel network coding on GPUs[C]//Proceedings of the IEEE Performance,Computing and Communications Conference,Austin,Texas,2008:144-151.
[13]NVIDIA.CUDA programming guide 2.0[S].NVIDIA Corporation,2008.
[14]甘新標,沈立,王志英.基于CUDA的并行全搜索運動估計算法[J].計算機輔助設計與圖形學學報,2010,22(3):457-460.
TANG Shaohua
Department of Information Engineering,Hunan Engineering Polytechnic,Changsha 410151,China
It is well known that network coding has emerged as a promising technique to improve network throughput, balance network loads as well as better utilization of the available bandwidth of networks,in which intermediate nodes are allowed to perform processing operations on the incoming packets other than forwarding packets.But,its potential for practical use has remained to be a challenge,due to its high computational complexity which also severely damages its performance.However,system accelerated by many-core GPU can advance network coding with powerful computing capacity and optimized memory hierarchy from GPU.A fragment-based parallel coding and texture-based parallel decoding are proposed on CUDA-enable GPU.Moreover,random linear coding is parallelizing using CUDA with optimization based on proposed techniques.Experimental results demonstrate a remarkable performance improvement,and prove that it is extraordinarily effective to parallelize network coding on many-core GPU-accelerated system.
network coding;Graphic Processing Unit(GPU);parallelizing;Compute Unified Device Architecture(CUDA); optimization
A
TP338.6
10.3778/j.issn.1002-8331.1403-0071
TANG Shaohua.Parallelizing network coding on manycore GPU-accelerated system with optimization.Computer Engineering and Applications,2014,50(21):79-84.
國家高技術研究發展計劃(863)(No.2012AA010905);國家自然科學基金(No.60803041,No.61070037);湖南省教育廳2012年度科技項目(No.12C1024)。
唐紹華(1980—),男,講師,工程師,研究領域為信息安全,計算機網絡,高性能計算。E-mail:tsh1181@163.com
2014-03-10
2014-04-28
1002-8331(2014)21-0079-06
CNKI出版日期:2014-07-11,http://www.cnki.net/kcms/doi/10.3778/j.issn.1002-8331.1403-0071.html
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
