一種改進的數據流最大頻繁項集挖掘算法*
2014-09-14 02:51:13吳毛毛
計算機工程與科學 2014年5期
胡 健,吳毛毛
(江西理工大學信息工程學院,江西 贛州 341000)
一種改進的數據流最大頻繁項集挖掘算法*
胡 健,吳毛毛
(江西理工大學信息工程學院,江西 贛州 341000)
提出了一種基于DSM-MFI算法的改進算法DSMMFI-DS算法,它首先將事務數據按一定的全序關系存入DSFI-list列表中;然后按排序后的順序存儲到類似概要數據結構的樹中;接著刪除樹中和DSFI-list列表中的非頻繁項,同時刪除窗口衰退支持數大的事務項;最后采用自頂向下和自底向上的雙向搜索策略來挖掘數據流的最大頻繁項集。通過用例分析和實驗表明,該算法比DSM-MFI算法具有更好的執行效率。
數據挖掘;數據流;界標窗口;最大頻繁項集;窗口衰減支持數
1 引言
頻繁模式的挖掘是關聯挖掘的核心和基礎[1],是影響挖掘算法效率的一個決定性的因素,它是產生關聯規則的基礎[2]。因此,在頻繁模式[3~5]挖掘方面取得的任何進展都將對關聯挖掘以至于其它數據挖掘任務的效率產生重要的影響。
由于最大頻繁項集[6~9]中隱含著全部的頻繁項集,因此可以將計算頻繁項集的問題轉化為計算最大頻繁項集。在某些應用中,只需要最大頻繁項集而并不需要所有的頻繁項集,這樣,研究直接計算最大頻繁項集的算法顯示出重要意義。
最近,數據庫和數據挖掘繼續集中到一個新的數據模型中,數據到達是以數據流的形式。在很多應用中,實時產生了大量的數據流,比如從一個傳感器網絡到另一個傳感器數據傳輸產生的數據;各個連鎖店事務數據的流入;Web記錄和在Web上的點擊流;在網絡監控和交通管理的測量評估數據等[10]。本文就是基于這個背景提出了一個有效挖掘數據流中最大頻繁項集的算法。
2 相關工作
Giannella C等人[11]提出了FP-stream算法來挖掘數據流上多個時間粒度的頻繁模式,該方法應用傾斜時間窗口策略以精細的時間粒度保存數據流上最近的頻繁模式信息,而以粗糙的時間粒度保存歷史的頻繁模式。馬達等人[12]在一種基于壓縮FP-樹的最大頻繁項集挖掘算法中提出一種剪枝策略并結合FP-樹的結構,并根據Patricia-樹的原理設計出PFP-樹,對數據庫進一步壓縮降低內存。敖富江等人[13]提出一種新的基于文法順序的FP-Tree的最大頻繁項單遍挖掘算法FPMFI-DS,該算法采用混合搜索空間順序策略,利用子集等級剪枝策略來壓縮搜索空間的大小;同時提出了能夠在線更新挖掘滑動窗口內數據流的最大頻繁項集FPMFI-DS+算法。在界標窗口模型中,文獻[14]提出了一種基于界標窗口模型的最大頻繁項集的挖掘方法。S-FP-MFI算法[15]是一種基于FP樹的改進的數據流最大頻繁項集挖掘算法,它是根據條件模式基的項目數對條件模式基進行動態排序,用來減少函數調用的次數。基于事務矩陣挖掘最大頻繁項集的方法AFMI[16]利用了迭代精簡事務矩陣的方法來發現事務數據中的最大頻繁項集,并提出了滑動窗口中的數據流最大頻繁項集AFMI+算法。頻繁模式樹的約束最大頻繁項集快速挖掘算法[17]能夠刪除不滿足約束條件的項集,由于不需要生成候選項目集,所以效率很高。Li Hua-fu等人[18]首先提出的DSM-FI算法通過將事務數據存儲到概要數據結構中,建立IsFI-forest,將每個項的投影子集存儲到DHT表中,采用自頂向下的搜索策略來發現頻繁項集。但是,該算法在刪除一個非頻繁項集時需要遍歷整個項集前綴頻繁項目森林(IsFI-forest),當森林結構復雜時,需要刪除很多非頻繁項集,需要很多次遍歷森林,消耗的時間很多。對于較長的非頻繁項集也要建立DHT表,同時要將各個子集投影到IsFI-forest中去,這樣不僅使存儲空間加大,而且還造成刪除耗時。
本文提出的DSMMFI-DS(Dictionary Sequence Mining Maximal Frequent Itemsets over Data Streams)算法是基于DSM-MF算法[1]提出來的,DSMMFI-DS算法先對流入的數據流按一定順序排序(本文是按一種全序關系)存入DSFI-list(Dictionary Sequence Frequent Item List)列表中,并且按這個順序存儲到DSSEFI-tree樹中;接著刪除DSFI-list列表中的非頻繁項對應在DSSEFI-tree樹中的項;然后刪除DSFI-list列表中的非頻繁項;最后在當前的概要數據結構中利用自頂向下和自底向上的雙向搜索策略發現最大頻繁項集。
3 問題的定義及相關知識
3.1 問題定義
從大的數據庫中挖掘最大頻繁項集是關聯挖掘的一個重要問題。這個問題是Bayardo首先提出來的。問題的定義如下[1]:設Ψ={i1,i2,…,in}是一系列的數據,in稱作項目。設數據庫DB是一系列的交易事務,DB的大小用|DB|表示。一個事務T有m個項目,可以表示成T={i1,i2,…,im},k-項集就是包含有k個項目的集合,表示為{x1,x2,…,xk}。一個項目集X的支持度就是指在這個數據庫中所有包含X項的總項目數占這個數據庫項目總數的百分比,X項目的支持度用sup(X)表示。如果sup(X)>minsup,那么X就被稱作頻繁項集,minsup是用戶自定義的最小支持度值,它的范圍是[0,1]。所有頻繁項集集合用FI(Frequent Item)表示。如果一個頻繁項集不是任何一個頻繁項集的子集,那么就把它叫做最大頻繁項集,一系列最大頻繁項集的集合用MFI(Maximal Frequent Itemsets)表示。本文目的就是找到所有支持度比用戶給定的最小支持度大的最大頻繁項集。
定義1[19]設數據流DS={w1,w2,…,wN},其中wi(?i=1,2,…,N)的i是每一個基本窗口的標識,N是最后一個基本窗口的標識。它是一個連續的、無窮的基本窗口序列,每個基本窗口含有固定數目的事務,〈T1,T2,…,Tk,…〉,Tk={i1,i2,…,im},Tk(K=1,2,…)稱為事務。
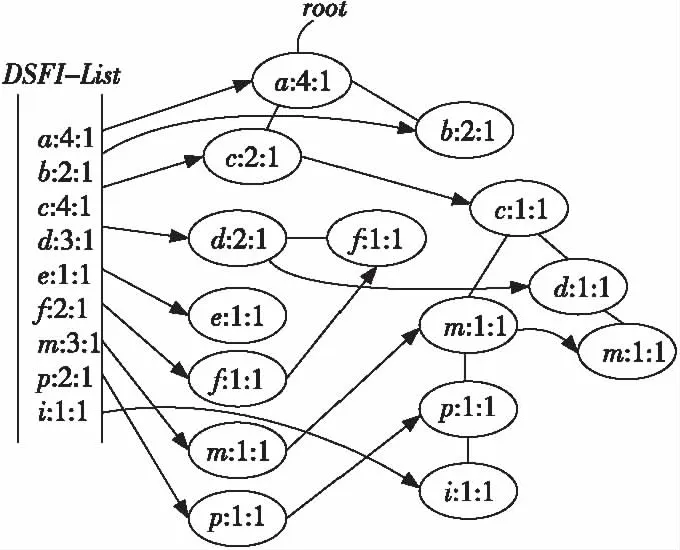
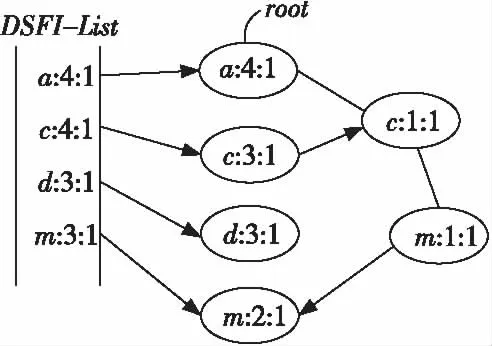
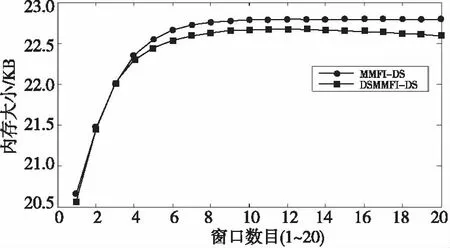
定義2設用戶給定的支持度s和允許偏差ε(0<ε 3.2 窗口衰退支持數 由于數據流的流動性與連續性,在一段界標窗口內的事務數量可能很大甚至無限,數據流中蘊含的知識會隨著窗口的推移而發生變化。而在實際的數據流應用中,最近產生事務所蘊含的知識往往要比歷史事務的知識有價值得多。因此,在數據流頻繁模式挖掘時,人們更希望挖掘出最近產生事務的頻繁模式或者是最大頻繁模式,而忽略那些歷史事務的模式。 本文應用窗口衰減模型逐步衰減歷史事務模式支持數的權重,并由此來區分新產生事務與歷史事務的模式。如果記模式支持數在單位窗口內的衰退比率為衰減因子cf(0 (1) DSMMFI-DS算法先把每個窗口的事務數據存儲到一個新的概要數據結構[19]—改進的前綴頻繁項目樹DSSEFI-tree中;然后根據DSFI-list列表中計算的每個項目的支持數,從DSSEFI-tree中刪除不頻繁項,接著刪除DSFI-list列表中的非頻繁項并將DSSEFI-tree樹存儲到DSSEFI-forest森林;最后根據用戶需求或者需要遍歷DSSEFI-forest森林挖掘相應項的最大頻繁項集。 4.1 概要數據結構 為了適應滑動窗口內最大頻繁項集的挖掘,本節設計了一種前綴概要項目樹DSSEFI-tree,與DSM-MFI中的SFI-tree相比,除了存儲項目名字item_name、窗口的標識window_count、項目的支持數node_count、指向DSFI-list表中的相同節點的指針node_link和指向DSSEFI-tree樹中具有相同項目名字的節點item_brother外,還增加了一個參數就是窗口衰退支持數parameter,該參數主要記錄著每個項隨著窗口的移動所代表的權重,當parameter很大時說明該項不是最近窗口的項,我們可以盡早將該項從樹結構中刪除掉。 同時,為概要項目樹DSSEFI-tree設計了一個頭項列表DSFI-list,該列表與DSM-MFI算法中的FI-list相比,除了具有存儲項目名字item_name、窗口的標識window_count、項目的支持數node_count、指向DSSEFI-tree樹中的相同節點的指針node_link和指向DSSEFI-tree樹中具有第一個相同項目名字的節點item_brother外,也增加了窗口衰退支持數parameter,由這個參數我們就可以很快知道樹中存儲的哪些項是已經過期的,可以很方便地將此項刪除。 4.2 增量更新DSSEFI-tree樹 由于數據流不斷地流入,內存的存儲空間有限,需要實時地對樹進行更新,及時刪除不頻繁項集和過期的項,同時要及時返回用戶查詢的結果。由于樹本身在存儲時是按照頭項列表中的全序關系進行存儲的,不受項到來的先后順序影響,在對項進行操作時也比較方便。再根據用戶設定的最小支持度和窗口衰退支持數閾值,在每一個窗口到來之后就對樹進行一次更新,這樣可以很快地將樹中的不頻繁項集和已經過期的項集剪枝掉,在節省內存空間的同時提高了查詢的效率。假設新的窗口事務數據TDS(i)=(a1,a2,…,aN)到來時,算法1是對樹DSSEFI-tree的更新。 算法1增量更新樹DSSEFI-tree 輸入:事務數據TDS(i)=(a1,a2,…,aN),用戶設定的最小支持度s,用戶設定的窗口衰退支持數閾值p,用戶允許的最大誤差率ε(0,s); 輸出:更新后的樹DSSEFI-tree。 (1) ifDSFI-list=?,then {window_count=1; (2)foreachaj,將aj的item_name、window_count和node_link插入到DSFI-list中; (3)endfor (4) 為樹DSSEFI-tree構造根節點root; (5)foreachaj,將aj的item_name、window_count、node_count、node_link、item_brother和parameter插入到DSSEFI-tree中;} (6)endfor (7)endif (8)else{ window_count=i; (9)foreachaj按全序插入到DSFI-list中; (10) if有相同item_name的項itemthenitem.parameter=aj.parameter; (11)endif (12)foreachDSFI-list中的每個項ai對應的parameter項進行更新:parameter=cf(P,Ti-1)×cf+c; (13)ifai.parameter≥p,將ai從樹DSSEFI-tree中刪除,接著從DSFI-list中刪除; (14)endif (15)ifai.node_count (16)endif (17)endfor (18)endfor (19)} (20)}endelse 4.3 最大頻繁項集的挖掘算法 更新完樹DSSEFI-tree后,我們根據需求來對數據流進行操作,查找相應項的最大頻繁項集。本文設計一個改進的雙向搜索策略tb-btMFI(top-bottomandbottom-topselectionofMaximalFrequentItems)[20],雙向搜索從DSSEFI-tree樹中發現最大頻繁項集,其中設計一個監控參數monitor,讓自頂向下搜索和自底向上搜索同步進行,可以及早發現不頻繁項,提高挖掘效率。 算法描述:自頂向下搜索,設置monitor的值為0,對每一個項x,將x所在的最長路徑中所有項合并形成最大頻繁候選項集存儲在M1中(假設為k項集),對這個最長的項集進行支持度計算,如果它滿足用戶給定的最小支持度,則它是最大頻繁項集,并將這個最大頻繁項集加入到MFI中,令monitor為1,轉到自底向上搜索,如果M2中某項是MFI的子集,則從M2刪除此項;如果不滿足,則對x和其他項進行任意組合形成k-1項集存儲在M1中,令monitor為1,轉到自底向上搜索,如果M2中某項是MFI的子集則從M2刪除此項。依次進行下去,直到M1為空為止。自底向上搜索,如果monitor的值為1,從樹的葉子節點開始對x項進行相鄰兩短項集組合,存儲在M2中,搜索到L層時仍然保留L-1層中的項,然后對組合的項集進行支持度計算,對第L層上的某個項目集X,若X是MFS中某頻繁項目集的子集,則不對X進行支持度計算,令monitor的值為0,轉到自頂向下搜索;否則,對X進行支持度計算,若X是第L層中的頻繁項目集,則從M2中刪除X在L-1層中的所有項目子集,否則刪除X,令monitor的值為0,繼續自頂向下搜索;若第L-1層中的某個頻繁項目集y在第L層上的所有超集均為非頻繁項目集,則將y加到MFS中并從M2中刪除y,令monitor值為0,繼續自頂向下搜索。如果monitor的值為1,則處理完第L層上的每一個項目集,如果monitor的值為1,則生成L+1層上的候選頻繁項目集,依次類推,直到M2為空。如算法2所示。 算法2tb-btMFI算法 輸入:更新后的DSSEFI-tree樹,當前窗口標識N,最小支持度s,用戶允許的最大誤差率ε; 輸出:最大頻繁項集MFI。 (1)令MFI=?,M1=?,M2=?,monitor=0; (2)for(k=n;k≥1;k--) (3){ (4)M1={路徑中包含Xi項目的組成最大候選頻繁項集X}; (5) 計算各候選頻繁項集的支持度; (6)if候選項集∈MFIthenM1=M1-X,monitor=1,轉到(13); (7)else計算候選項集X的支持度; (8)ifX.node_count≥s·X.SLorX.node_count<ε·X.SLthen (9) MFI=MFI∪{X},monitor=1,轉到(13); (10)elseM1=M1-{X},monitor=1,轉到(13); (11)} (12)ifM1={?}then退出; (13)for(k=0; k<=L; k ++){ (14)M2={包含xi項的相鄰兩項組成的候選頻繁項集X} (15)ifX∈MFIthen (16)M2=M2-X,monitor=0,轉到(2); (17)if在第k-1層的項X是第k層的子集then (18)M2=M2-X,monitor=1,轉到(2); (19) 計算各項目X的支持度; (20)ifX.node_count≥ s·X.SLorX.node_count< ε·X.SLthen (21) MFI=MFI∪{X},monitor=1,轉到(2); (22)elseM2=M2-X,monitor=1,轉到(2); (23)} (24)ifM2={?}then退出; (25)endfor 5.1 算法的復雜性分析 (1)時間復雜度。 (2) 對于MMFI-DS算法:(1)在SEFI-tree構造和維護算法中,算法需把T×N個項目插入到SEFI-tree中,刪除一個不頻繁項目,算法需刪除此不頻繁項在EIS-tree中節點的個數,設其數目為C3。(2)在發現最大頻繁項集的算法中,MMFI-DS算法的時間復雜度為[19]: T×N+C1×C3+C2× (3) 對于DSMMFI-DS算法:(1)在DSSEFI-tree樹的增量更新中,算法也要把T×N個項目插入到DSSEFI-tree中,刪除一個不頻繁項目,算法需刪除此不頻繁項在DSSEFI-tree中節點的個數,設其數目為C4。(2)在發現最大頻繁項集的算法中,DSMMFI-DS算法的時間復雜度為: T×N+C1×C4+C2× (3) (2)空間復雜度。 DSM-MFI算法在內存中需要保存FI-list表、OFI-list表和SFI-tree樹;MMFI-DS算法在內存中需要保存FI-list表、OFI-list表和EIS-tree樹;DSMMFI-DS算法在內存中保存DSFI-list表和DSSEFI-tree樹。DSM-MFI算法和MMFI-DS算法都用了投影子集的方法,將投影子集項存放在OFI-list表中,這樣占用了一定大小的內存空間,DSMMFI-DS算法用DSFI-list表來存放頻繁一項集,一方面,不需要存儲每個項目的投影子集,就節省了內存的空間,另一方面因用DSSEFI-tree樹結構的存儲經過全序排序后樹的分支少,結構簡單,同時在節點數據域中增加了監控參數monitor,這樣可以盡早地刪減已經過期的或者對用戶沒有意義的頻繁項,從而更節省了內存的開銷。假設頻繁1-項目的樹為k,DSM-MFI算法需要存儲2k個節點,MMFI-DS算法需要存儲C×k(C為常數)個節點,DSMMFI-DS算法則需要存儲C×r個節點(r為k個頻繁項集刪除過期或者用戶不感興趣的項后剩下的頻繁項目樹r≤k),顯然,C×r≤C×k<2k,所以DSMMFI-DS算法比DSM-MFI算法和MMFI-DS算法在相同環境中處理同樣數據流更節省內存空間。 5.2 用例分析 假設某一數據流W1=[c,f,a,d,e,p,m;f,c,d,a;m,a,b,c,d;b,c,a,m,p,i],從窗口中讀入完數據存儲到DSFI-list中的結構。 如圖1所示,假定用戶給定的最小支持度為3,從DSFI-list中刪除,然后根據DSFI-list列表中的順序存儲到DSSEI-tree中的結構,如圖2所示。 同樣地用DSM-MFI算法得到的SFI-tree樹存儲結構如圖3和圖4所示。 Figure 1 Tree storage structure of DSSEFI-tree after DSMMFI-DS algorithm reads the data streams圖1 DSMMFI-DS算法讀取完數據流后 DSSEFI-tree樹存儲結構 Figure 2 Tree storage structure of DSSEFI-tree after DSMMFI-DS algorithm removes not frequent itemsets圖2 DSMMFI-DS算法刪除不頻繁項集后的 DSSEFI-tree樹存儲結構 Figure 3 Tree storage structure of SFI-tree after DSM-MFI algorithm reads the data streams圖3 DSM-MFI算法讀取完數據流后 SFI-tree樹存儲結構 Figure 4 Tree storage structure of SFI-tree after DSM-MFI algorithm removes not frequent itemsets圖4 DSM-MFI算法刪除非頻繁項集后的 SFI-tree樹存儲結構 從上面的結構圖我們可以看到,MMFI-DS算法由于沒有對讀入的數據流進行排序,那么它的有些計數少的項目存儲到EIS-tree樹中可能成為根節點,這樣我們在用自頂向下的算法搜索時發現最大頻繁項集時會花費更多的時間來計算項目的支持度;另一方面,由于沒有進行排序,那么頻繁項目在存儲時可能分布在樹的各個分支中,這樣在存儲空間方面又會造成浪費。在DSM-MFI算法里,不但要存儲IsFI-forest,而且還要存儲每個項的投影子集,在同樣多的事務數據下需要更多的內存來存儲。而DSMMFI-DS算法在讀入時對項目按一定的順序排序后,那么它們共享的前綴個數就多了,使樹的存儲結構得到了簡化,節省了存儲空間;另一方面,在挖掘最大頻繁項集時也由于共享的前綴個數多,所以會在較短的時間里發現最大頻繁項集。 實驗在CPU為Intel Pentium(R) Dual-Core 3.20 GHz、內存為2.00 GB、操作系統為Windows 7 Ultimate的PC機上進行,所有的實驗程序均采用Visual C++ 6.0實現。實驗中的模擬數據由IBM數據生成器產生,為了符合數據流產生的特點,我們設定產生10 000 k條數據項,其中1 k表示1 000條數據項,同時我們設定每個窗口的事務數據以及其他所有參數都使用默認值。用戶設定的最小支持數為0.1%,最大允許誤差ε固定為0.1Xs。對DSM-MFI和DSMMFI-DS兩種算法執行時的時間和占內存空間進行比較,圖5顯示DSMMFI-DS算法比DSM-MFI算法的執行時間要少,一方面DSMMFI-DS算法不需要為每個項建立投影,另一方面在發現最大頻繁項集時DSMMFI-DS采用雙向搜索策略,所以DSMMFI-DS算法比DSM-MFI算法的執行效率要高。圖6顯示DSMMFI-DS算法比DSM-MFI算法在運行時所占的內存空間要小,特別是在隨著窗口數目增多時,這種效果更明顯: (1)DSM-MFI需要為每個項做投影,內存需要存儲每個項的投影子集; (2)每個項在建立相應的樹時沒有進行排序,那么樹的分支也會比較多,存儲時需要更多的內存空間; (3)DSMMFI-DS算法會根據每個項的窗口衰減支持數,及時將支持數小的項刪除。因此,DSMMFI-DS算法所占的內存空間比DSM-MFI要小。 Figure 5 Execution time of DSM-MFI algorithm and DSMMFI-DS algorithm圖5 DSM-MFI算法和DSMMFI-DS算法執行時間 Figure 6 Memory of DSM-MFI algorithm and DSMMFI-DS algorithm圖6 DSM-MFI算法和DSMMFI-DS算法存儲內存 MMFI-DS算法也是對DSM-MFI算法的改進,為了驗證MMFI-DS算法和DSMMFI-DS算法的優越性,也對MMFI-DS算法進行了實驗對比。如圖7和圖8所示。 Figure 7 Execution time of MMFI-DS algorithm and DSMMFI-DS algorithm圖7 MMFI-DS算法和DSMMFI-DS算法執行時間 Figure 8 Memory of MMFI-DS algorithm and DSMMFI-DS algorithm 圖8 MMFI-DS算法和DSMMFI-DS算法存儲內存 通過實驗可以看出,DSMMFI-DS算法比MMFI-DS算法的執行效率更高。在圖7中,由于DSMMFI-DS算法采用的是全序關系存儲數據,與數據到來的時間順序沒有關系,在存儲上更節省時間;而MMFI-DS算法沒有按一定的順序存儲,在進行挖掘操作時需要花費很多時間來搜索。在圖8中,在窗口數目比較小時,MMFI-DS算法和DSMMFI-DS算法的存儲空間相差不大,但是隨著窗口數目的不斷增多,DSMMFI-DS算法更具有優越性,占用的內存空間小,主要是因為DSMMFI-DS算法能夠及時地將不頻繁項集從樹中刪除。 本文提出了改進的界標窗口內數據流最大頻繁項集挖掘算法DSMMFI-DS,該算法采用了按全序排序存儲,不需要對每個項進行投影,并存儲投影子集;該算法在發現最大頻繁項集時采用自頂向下和自底向上的雙向搜索策略,能快速發現最大頻繁項集,最后該算法存儲每個項的窗口衰退支持數,根據設定的窗口衰退支持數閾值能夠盡早地刪除那些支持數小的項,節省了內存空間。通過實驗得出DSMMFI-DS算法比DSM-MFI算法和MMF-DS算法具有更好的執行效率。 [1] Li H, Lee S, Shan M. Online mining (recently) maximal frequent itemsets over data streams[C]∥Proc of the 15th International Workshops on Research Issues in Data Engineering:Stream Data Mining and Applications, 2005:11-18. [2] Han J,Kamber M.Data mining:Concept and techniques[M].2nd edition. San Fransisco:Higher Education Press, 2001. [3] Pan Yun-he,Wang Jin-long,Xu Cong-fu.State of the art on frequent pattern mining in data streams[J].Acta Automatica Sinica, 2006,32(4):594-602. (in Chinese) [4] Meng Cai-xia. Research on mining frequent itemsets in data streams[J].Computer Engineering and Applications, 2010,46(24):138-140. (in Chinese) [5] Zhuang Bo,Liu Xi-yu,Long Kun.TWCT-stream:Algorithm for mining frequent patterns in data streams[J]. Computer Engineering and Applications, 2009,45(20):147-150. (in Chinese) [6] Yan Yue-jin.Research on mining algorithms of maximal frequent item sets[D]. Changsha:National University of Defense Technology,2005. (in Chinese) [7] Yan Yue-jin, Li Zhou-jun, Chen Huo-wang. A depth-first search algorithm for mining maximal frequent itemsets[J].Journal of Computer Research and Development, 2005,42(3):462-467. (in Chinese) [8] Huang Shu-cheng,Qu Ya-hui.Survey on data stream classification technologies[J].Application Research of Computers, 2009,26(10):3604-3609. (in Chinese) [9] Ji Gen-lin,Yang Ming,Song Yu-qing, et al.Fast updating maximum frequent itemsets[J].Chinese Journal of Computer, 2005,28(1):128-135. (in Chinese) [10] Li Hua Fu,Lee Suh Yin.Mining frequent itemsets over data streams using efficient window sliding techniques[J].Expert Systems with Applications, 2009,36(2,Part 1):1466-1477. [11] Giannella C, Han Jia-wei, Pei Jian, et al. Mining frequent patterns in data streams at multiple time granularities[M]∥Data Mining:Next Generation Challenges and Future Directions,Cambridge:MIT, 2003. [12] Ma Da,Wang Jia-qiang.A compressed FP-tree based on algorithm for mining maximal frequent itemsets[J].Journal of Changchun University of Science and Technology(Natural Science Edition), 2009,32(3):457-461. (in Chinese) [13] Ao Fu-jiang,Yan Yue-jin,Liu Bao-hong, et al.Online mining maximal frequent itemsets in sliding window over data streams[J].Journal of Sytem Simulation, 2009,21(4):1134-1139. (in Chinese) [14] Li Hai-feng,Zhang Ning. Maximal frequent itemsets mining method over data stream[J].Computer Engineering, 2012,38(21):45-48. (in Chinese) [15] Hu De-min, Zhao Rui-ke. An improved algorithm for mining maximum frequent itemsets[J].Computer Applications and Software, 2012,29(12):186-188. (in Chinese) [16] Zhang Yue-qin, Chen Dong. Mining method of data stream maximum frequent itemsets[J].Computer Engineering, 2010,36(22):86-90. (in Chinese) [17] Hua Hong-juan, Zhang Jian, Chen Shao-hua. Mining algorithm for constrained maximum frequent itemsets based on frequent pattern tree[J].Computer Engineering, 2011,37(9):78-80. (in Chinese) [18] Li H, Lee S, Shan M. An efficient algorithm for mining frequent itemsets over the entire history of data streams[C]∥Proc of the 1st International Workshop on Knowledge Discovery in Data Streams, held in conjunction with the 15th European Conference on Machine Learning (ECML 2004) and the 8th European Conference on the Principles and Practice of Knowledge Discovery in Databases (PKDD 2004), 2004:1. [19] Mao Yi-min,Yang Lu-ming,Li Hong, et al. An effective algorithm of mining maximal frequent patterns on data stream[J]. Chinese High Technology Letters, 2010,3(3):100-107. (in Chinese) [20] Song Yu-qing,Zhu Yu-quan,Sun Zhi-hui, et al.An algorithm and its updating algorithm based on FP-tree for mining maximum frequent itemsets[J].Journal of Software, 2003,14(9):1586-1592. (in Chinese) 附中文參考文獻: [3] 潘云鶴,王金龍,徐從富.數據流頻繁模式挖掘研究進展[J].自動化學報,2006,32(4):594-602. [4] 孟彩霞.面向數據流的頻繁項集挖掘研究[J].計算機工程與應用,2010,46(24):138-140. [5] 莊波,劉希玉,隆坤.TWCT-Stream:數據流上的頻繁模式挖掘算法[J].計算機工程與應用,2009,45(20):147-150. [6] 顏躍進.最大頻繁項集挖掘算法的研究[D].長沙:國防科學技術大學,2005. [7] 顏躍進,李舟軍,陳火旺.一種挖掘最大頻繁項集的深度優先算法[J].計算機研究與發展,2005,42(3):462-467. [8] 黃樹成,曲亞輝.數據流分類技術研究綜述[J].計算機應用研究,2009,26(10):3604-3609. [9] 吉根林,楊明,宋余慶,等.最大頻繁項目集的快速更新[J].計算機學報,2005,28(1):128-135. [12] 馬達,王佳強.一種基于壓縮FP-樹的最大頻繁項集挖掘算法[J].長春理工大學學報(自然科學版),2009,32(3):457-461. [13] 敖富江,顏躍進,劉寶宏,等.在線挖掘數據流滑動窗口中最大頻繁項集[J].系統仿真學報,2009,21(4):1134-1139. [14] 李海峰,章寧.數據流上的最大頻繁項集挖掘方法[J].計算機工程,2012,38(21):45-48. [15] 胡德敏,趙瑞可.一種改進的最大頻繁項集挖掘算法[J].計算機應用與軟件,2012,29(12):186-188. [16] 張月琴,陳東.數據流最大頻繁項集挖掘方法[J].計算機工程,2010,36(22):86-90. [17] 花紅娟,張健,陳少華.基于頻繁模式樹的約束最大頻繁項集挖掘算法[J].計算機工程,2011,37(9):78-80. [19] 毛伊敏,楊路明,李宏,等.一種有效的數據流最大頻繁模式挖掘算法[J].高技術通訊,2010,3(3):100-107. [20] 宋余慶,朱玉全,孫志揮,等.基于FP-Tree的最大頻繁項目集挖掘及更新算法[J].軟件學報,2003,14(9):1586-1592. HUJian,born in 1967,PhD,professor,his research interests include knowledge engineering and knowledge discovery, and software engineering. 吳毛毛(1987-),男,江西鷹潭人,碩士生,研究方向為數據挖掘。E-mail:wumaomao2010@163.com WUMao-mao,born in 1987,MS candidate,his research interest includes data mining. Animprovedalgorithmforminingmaximalfrequentitemsetsoverdatastreams HU Jian,WU Mao-mao (Institute of Information Engineering,Jiangxi University of Science and Technology,Ganzhou 341000,China) Based on the algorithm of DSM-MFI, an improved algorithm, named DSMMFI-DS (Dictionary Sequence Mining Maximal Frequent Itemsets over Data Streams), is proposed. Firstly, it stores transaction data into DSFI-list in alphabetical order. Secondly, the data are stored sequentially into the tree similar to the summary data structure. Thirdly, non-frequent items in the tree and DSFI-list are removed, and the transaction items with the maximum count of window attenuation supports are deleted. Finally, the strategy (top-down and bottom-up two-way search) is used to mine maximal frequent itemsets over data streams, and case analysis and experiments prove that the algorithm DSMMFI-DS has better performance than the algorithm DSM-MFI. data mining;data stream;landmark windows;maximal frequent itemsets;window attenuation support count 1007-130X(2014)05-0863-08 2012-12-03; :2013-04-03 TP274.2 :A 10.3969/j.issn.1007-130X.2014.05.030 胡健(1967-),男,江西贛州人,博士,教授,研究方向為知識工程與知識發現、軟件工程。E-mail:1050023437@qq.com 通信地址:341000 江西省贛州市客家大道156號 Address:156 Kejia Avenue,Ganzhou 341000,Jiangxi,P.R.China4 算法描述
5 算法的復雜性分析與用例分析
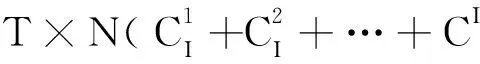
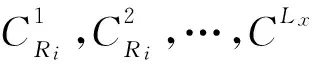
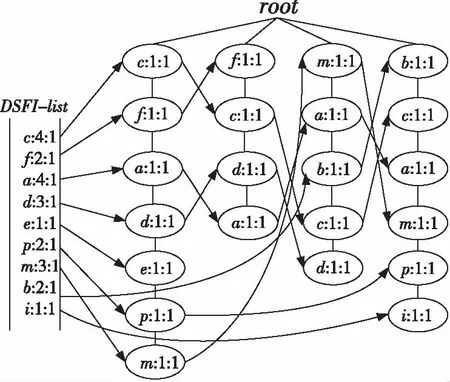
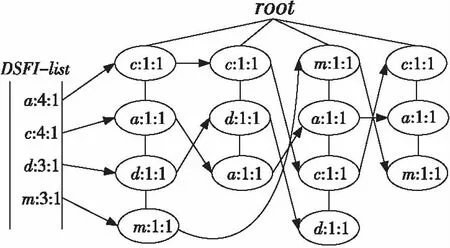
6 實驗結果和分析

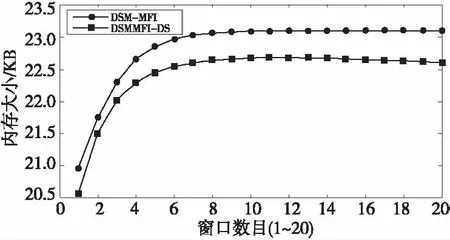
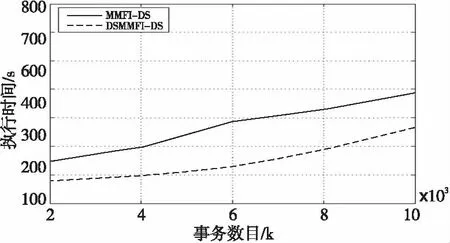
7 結束語


