基于CUDA的GPU條件分支分歧聚合優化策略
2014-10-24 22:25:12劉素芹安仲奇楊娜利王俊爽
中國石油大學學報(自然科學版) 2014年3期
劉素芹,王 鑫,安仲奇,楊娜利,王俊爽
(中國石油大學計算機與通信工程學院,山東青島 266580)
近年來由GPU作為加速部件的異構計算系統和技術,如CUDA[1]產生并得到發展。GPU擅長的SIMD(single instruction multiple data)執行方式提高了系統的計算效率,但當程序出現條件分支分歧時,會部分或完全退化成串行執行,性能損失嚴重。條件分支是控制程序執行流的基本方式,易大量出現,并且算法越復雜,對分支的利用就會越頻繁。因此,需要優化GPU對條件分支的處理以更充分地發揮其并行計算的潛力。目前的研究主要集中在硬件層面設計線程調度器方面[2-5],對普通用戶而言實現難度較大,而利用現有體系結構從軟件層面優化條件分支處理流程方面的研究還較少,因此筆者探索實現難度較低、可操作性較強的優化方法。
1 GPU條件分支處理機制分析
1.1 基于CUDA的GPU處理條件分支的機制
基于CUDA的GPU執行沒有分支的語句時,線程束(warp[6])中的線程按照SIMD的方式步調一致地執行,而遇到條件分支分歧時,處理過程則有所不同。對于較簡單的IF-ELSE語句,PTX[7]匯編器將PTX語句只編譯為GPU斷言指令。此時GPU的斷言設置指令處理IF語句的條件部分,并根據判斷結果設置斷言寄存器的各位,從而啟用或禁用對應的SIMD道。當執行IF內部的語句時,操作被廣播至所有SIMD道,但只有斷言寄存器設為啟用的道執行操作并流出結果,設為禁用的道并不執行操作也不保存結果。ELSE部分處理方式與之類似。分支語句執行結束后,SIMD道不再受斷言影響,繼續一致地執行后續指令。當SIMD線程中的所有道都選擇了相同的路徑時,不被執行的另一路徑的指令將被直接跳過。
對于復雜控制流如嵌套條件語句,則需要混合使用斷言指令、GPU分支指令和同步指令。此時,當分支分歧時,棧條目被壓入分支同步棧,SIMD道轉到目標指令執行。當分支收斂時,棧條目彈出,SIMD道轉回棧條目地址且斷言寄存器還原為上一層嵌套的掩碼。
1.2 條件分支對計算性能的影響
SIMD執行方式處理條件分支時性能損失往往是顯著的。如果條件分支嵌套較深,可能導致多數SIMD道空閑,比如假設每條分支路徑的長度相同,兩層嵌套將使效率降低至25%,三層嵌套進一步降低至12.5%。在最壞情況下,所有SIMD元素將串行執行,以 Fermi[8]架構為例,每兩個時鐘周期(SIMD線程寬度為32,執行單元寬度為16)只能有一條SIMD道流出有效結果,其他道都被阻塞[9]。下列IF語句和IF-ELSE語句是造成SIMD執行性能損失的兩種基本條件分支語句結構。
(a)IF語句:

(a)只有一條分支路徑,如果某一SIMD線程中的任意SIMD道需要執行IF內部的語句,則同一SIMD線程中所有的SIMD道都會經過這個分支路徑,只是斷言寄存器設為禁用的道不執行實際操作,因此部分計算資源閑置,性能有顯著損失。(b)相當于兩個(a)情況的疊加,同一SIMD線程中只有當所有SIMD道都選擇相同的路徑時才會少走一路分支路徑,其他情況下所有SIMD道都會經過兩個分支路徑,程序性能損失為(a)的兩倍。
1.3 GPU條件分支優化的研究現狀
條件分支分歧對計算性能的影響主要是由GPU底層的處理方式造成的,因此現有優化方法多傾向于設計某種新硬件機制來重新調度SIMD道,避免在SIMD線程內發生分支分歧,使其在每步計算中更充分地利用計算資源。DWF(dynamic warp formation)[10]和 DWS(dynamic warp subdivision)[11]即為兩種硬件機制:DWF的硬件調度器在每個時鐘周期分析SIMD線程,將執行相同分支路徑的SIMD道整合生成新的SIMD線程;DWS則是將SIMD線程分解為子線程,子線程被獨立調度并交替執行。Zhang等[12]提出了一種在運行時重新映射SIMD線程數據的方法,由于需要昂貴的CPU-GPU數據通信,整體優化效果有限。
以上優化方案都是硬件層面的優化,雖然較為有效,但對于一般的GPU計算用戶實現難度較大。因此,有必要探討實現難度更低,可操作性更強的優化方法。本文中針對這一問題利用現有體系結構在軟件層面進行優化,以期能在一定程度上優化條件分支分歧。
2 聚合優化策略的設計方案
從軟件層級入手,探索提升每步SIMD執行的有效處理比重的方法,提出了利用“聚合”思想的SIMD分支優化策略,該策略針對的具體情形如下列代碼所示。

由于分支條件不能在編譯時確定,所以只有程序運行時才能決定線程的走向。此種情形由于GPU的執行方式使得執行某條路徑時只有選擇該路徑的SIMD道進行實際計算,其他道被阻塞,而分支處于循環體內部導致任意時刻都有大量資源閑置。
鑒于此,聚合策略的主體思想是:在每步循環中,采用某種機制將不同SIMD道中選擇相同路徑的條件分支“聚合”到同一步循環中,力求提高每次循環的有效處理比重。為此,在具體實施過程中可以用不同的實現策略,本文著重對循環推遲和循環提前兩種實現策略進行討論。
2.1 基于循環推遲的聚合優化策略
循環推遲的做法是在每一步循環中,SIMD線程中的所有SIMD道只執行一條分支路徑,另一條分支路徑則被“掛起”,并被推遲到后續的循環中,與下一步循環合并后再擇機執行。此前未執行的SIMD道與即將執行的SIMD道就“聚合”到了同一步SIMD執行中。這樣做使得每次循環只執行了一條路徑,另一條路徑直接跳過,因此所用時間是串行執行兩條分支路徑的一半,從而使SIMD執行的總數少于未優化之前。
圖1給出了一個SIMD線程常規分支執行與采用循環推遲策略后分支執行的兩種不同情況的對比示例。其中假設SIMD線程寬度為4,循環次數為3,帶下標的T和F分別代表條件判斷為真(True)和為假(False)的不同路徑,下標的左起第一位數代表的是在未優化的情況下第幾次循環的編號,第二位數代表的是SIMD道的編號。
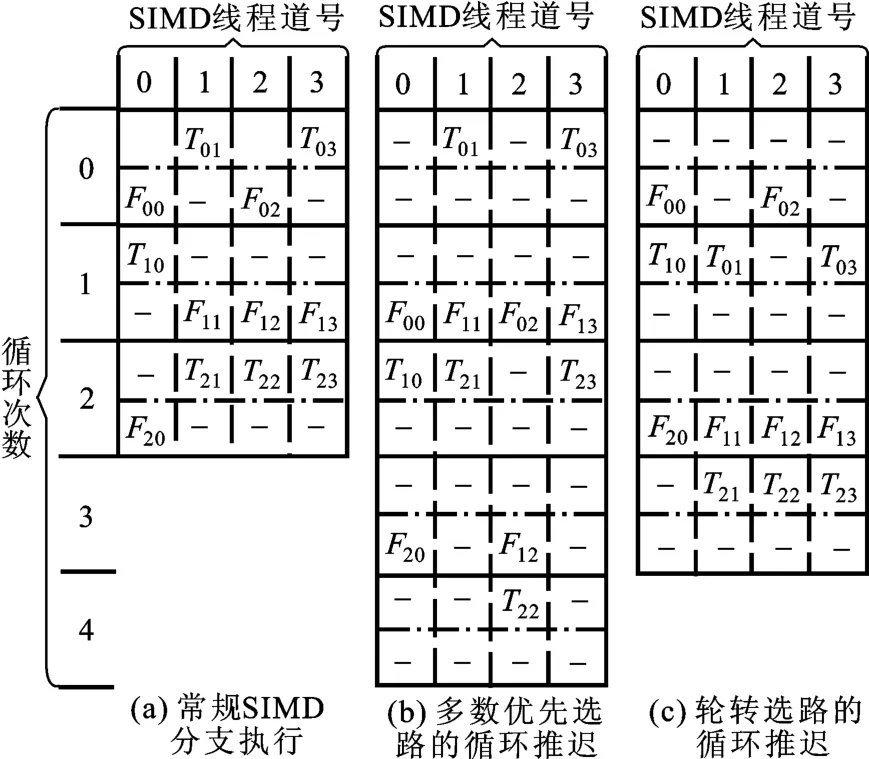
圖1 使用基于循環推遲的聚合優化策略的示例Fig.1 A branch execution example using converging optimization strategy based on loop postpone
常規執行時,如圖1(a),每次循環內要依次將所有分支路徑都執行一次,從本例來說,共有6步SIMD執行(每個循環包含兩次SIMD執行)。采用了循環推遲的策略后,如(b)和(c)所示,雖然循環次數都有所增加,但是整體的SIMD執行步數卻都有所減少(空路徑被直接跳過,執行時間忽略不計),最多也與未優化時相等。假設兩條分支路徑中的指令數目相同,則聚合后(b)情況執行的指令數降低了16.7%,(c)情況則降低了33.3%。
從上圖的例子中不難看出,當遇到分支分歧時“掛起”的分支路徑選擇的不同,會導致最終的聚合效果不同,因此循環推遲策略的關鍵是在每次循環中如何選擇要執行的路徑。此處采用了兩種較為簡單的路徑選擇策略:多數優先策略和輪轉策略。
多數優先策略是在每次分支分歧時選擇包含最多SIMD道的分支路徑執行,即選擇執行計算單元使用率最高的路徑。由于本文討論的條件分支有兩條路徑,所以這樣使得多數循環中SIMD執行的有效道數必然大于等于SIMD總道數的一半,如圖1(b)中第0~3次循環,從而提高SIMD計算單元的使用率,減少SIMD執行的總次數,達到縮短計算時間的目的,并且整個執行過程不會破壞每個SIMD道原有的循環執行順序。但本策略可能導致處于冷門路徑的SIMD道遲遲得不到執行,如圖1(b)中第2號道的第4次循環,本文中稱這種現象為道饑餓。道饑餓現象的存在可能會造成最后幾步循環中只有少數SIMD道執行實際操作,一定程度上限制了循環推遲的聚合效果,實際實現中可以采用周期性暫停本聚合策略來觸發冷門路徑的執行以緩解道饑餓現象。
輪轉策略是在每次循環中遇到分支分歧時,交替的選擇條件判斷為真或為假的路徑執行,并將另一條路徑掛起和推遲到下一步循環中,從而達到聚合的效果,提高計算效率,如圖1(c)所示(采用先假后真交替循環)。這樣雖然在最初幾次循環中聚合效果不如多數優先策略,但是每次循環中有效執行的SIMD道數卻較為均等,且多數情況下超過SIMD總道數的一半,同時還避免了道饑餓現象。不足之處是如果SIMD線程的所有SIMD道在某次循環中都選擇相同路徑,而此時根據輪轉策略恰好輪轉到了另一條路徑(此處稱這種現象為“空載”),會導致無用執行,實際實現中遇到上述情況要切換分支走向。
這兩種策略實現起來都非常方便,可以利用CUDA本身提供的統計各SIMD道狀態的函數來實現,并且所引入的開銷也可忽略不計。
影響循環推遲優化效果的因素有以下4點:
(1)如果分支指令規模小于實現循環推遲的指令規模,那么其帶來的收益可能不足以抵消本身的開銷,甚至會導致性能損失。
(2)暫時阻塞分支同樣會阻塞相關SIMD元素對循環體中后續非分支代碼的執行,如若分支指令數量相比后續非分支指令較少,循環推遲可能無法帶來理想的改進。
(3)分支被執行的頻率、SIMD元素分支變向的頻率等因素會影響循環推遲的效果。本文所采用的多數優先策略和輪轉策略相對簡單,其改進效果依賴具體的分支模式。
(4)循環推遲可能破壞原有的優化的內存訪問模式,導致性能的下降。
2.2 基于循環提前的聚合優化策略
循環提前的做法是將原本由兩次循環完成的任務“聚合”到一次循環中完成。這種策略適用于同一SIMD道執行流中第N次循環與第N+1次循環所選擇的分支路徑不同的情況,假設程序只有兩個不同的分支路徑T路徑和F路徑,如圖2(a)和圖2(c)所示,當遇到這兩種情形時,可以考慮將第N+1次循環提前到第N次循環中執行,如圖2(b)和圖2(d)所示,從而充分利用每一次循環。
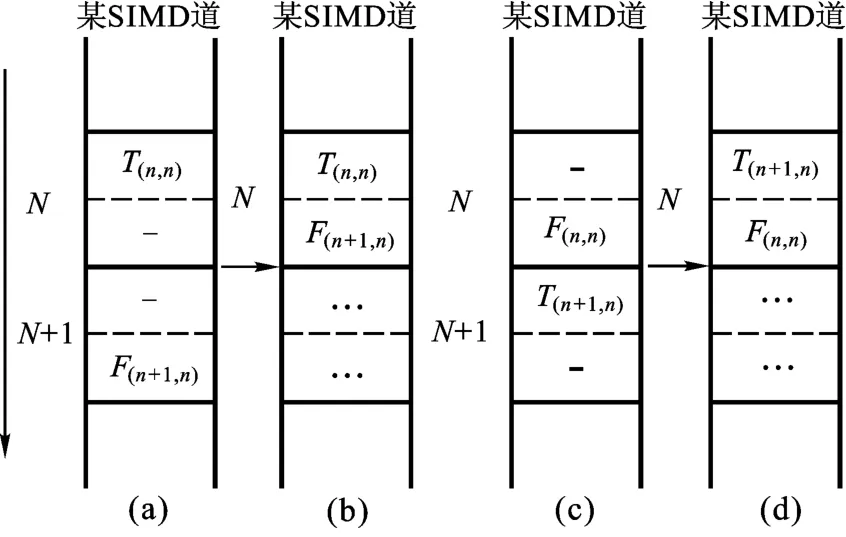
圖2 基于循環提前的聚合優化策略的適用情況Fig.2 Circumstances converging optimization strategy based on loop advance targets
循環提前策略的效果依賴于原有程序路徑選擇的情況,圖3給出了兩個使用基于循環提前的聚合優化的兩個示例,每個示例中SIMD線程寬度為4,循環次數為4。
示例1在使用了本策略后聚合效果達到了理想狀態,如果兩條分支路徑中的指令數大致相當,則優化后的指令數降為原來的50%。示例2在使用了本策略后聚合效果較為一般,并非所有的相鄰的循環都能使用循環提前策略,但總體性能仍然有一定提升,優化后的指令數降為原來的75%。最壞情況下SIMD線程中的某些道在整個循環過程中都只選擇走同一條分支路徑,本策略則在這些道上不起作用,程序受這些道拖累性能沒有任何提升,還有可能下降。
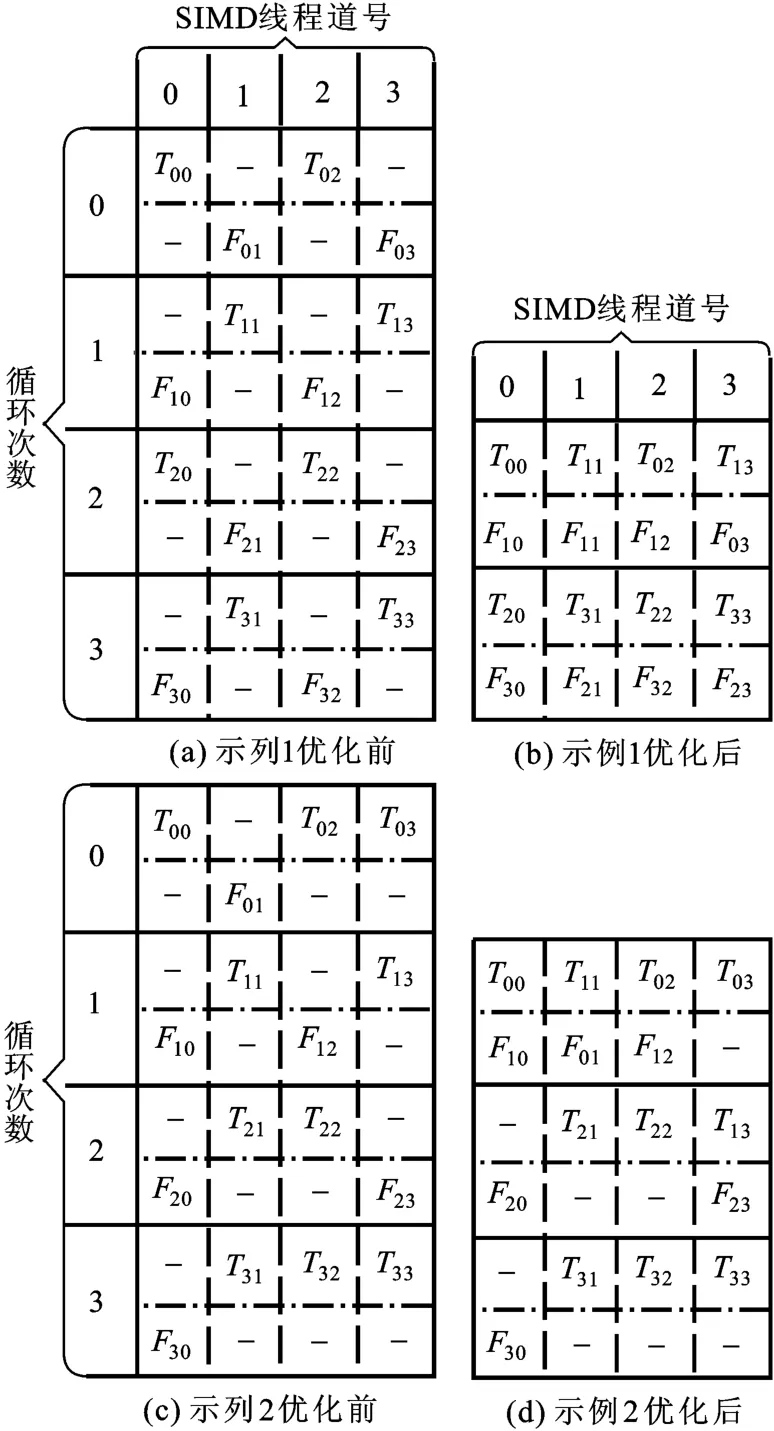
圖3 使用基于循環提前的聚合優化策略的兩個示例Fig.3 Two branch execution examples using converging optimization strategy based on loop advance
策略的實現可以通過改造原有條件分支的執行模式,判斷相鄰兩次循環中條件分支的路徑走向,然后調整分支的執行來實現,引入的開銷也不大。由于循環提前可能會調換相鄰兩步循環的次序,因此需要滿足如下條件才能保證執行結果的正確:
(1)每步循環中各分支語句不依賴上一步循環的結果,即循環的先后次序可交換。
(2)條件分支語句內的兩個不同分支之間不能出現相互依賴。
(3)循環中條件分支以后不能直接出現非分支代碼。
條件(3)的原因主要是,循環提前策略合并了相鄰的兩步循環,從而減少了循環的次數,導致分支代碼之后的非分支代碼執行的次數也相應減少,無法與之前未優化的程序保持一致。如一定要有非分支代碼,則可以將非分支代碼整體拷貝或封裝成函數后分別移入到條件分支的不同路徑中。影響循環提前優化效果的因素有循環推遲中的(1)、(3)、(4)條。此外,從圖3的分析也可看出,實際優化效果依賴于程序中的分支出現圖2中兩種情況的比例。
3 聚合優化策略的實現
從策略的設計來看,要實現聚合優化策略勢必會引入新的條件分支判斷,這雖然會在局部影響到程序運行的效率,但其影響十分有限。因為這些額外的條件分支當中只包含很少的代碼,且多為復制和比較等簡單運算,計算時間十分短暫。本文將其歸結為“實現優化策略所需的指令規模”。只有當原有的分支指令規模接近或小于“實現優化策略所需的指令規模”時才可能導致性能的損失。在需要采用聚合優化策略的情況下,主要分支路徑中的指令規模要遠大于“實現優化策略所需的指令規模”,所以優化主要分支所帶來的程序效率的提升要大于策略的開銷。
3.1 基于循環推遲的聚合優化策略的實現
實現基于循環推遲的聚合策略的關鍵是實現兩種選擇路徑的策略,然后根據路徑選擇策略的結果掛起或執行某些線程,其主體的示意性代碼如下:

多數優先策略的實現可以使用線程束投票函數__ballot()和整數處理函數__popc()。__ballot()函數可以檢查線程束中所有線程的斷言狀態并搜集至一個32位整數中,如果第n個線程的斷言值與參數值相同,那么返回的整數的第n位為1。__popc()能夠返回32位整數中位1的數目。使用這兩個函數可以找出被多數SIMD線程執行的分支路徑,進而實施多數優先策略。
輪轉策略的實現方法比較直接,只需在循環中周期性地調轉分支走向即可。為避免“空載”分支路徑被執行的情況,可以利用線程束投票函數__all()和__any()來進行判斷。如果所有SIMD線程的斷言狀態與參數相符,那么__all()返回非零值。如果SIMD線程中存在斷言狀態與參數相符的元素,那么__any()將返回非零值。利用這兩個函數可以在循環出現“空載”路徑時切換分支走向。
3.2 基于循環提前的聚合優化策略的實現
由于循環提前策略需要考慮相鄰兩步循環所選的分支路徑才能決定循環是否需要提前,因此在循環體中分支語句之前需要計算出相鄰兩步循環中的分支條件。然后據此判明是圖2中的哪種具體情況,再對不同的情況分別采用不同的提前模式,處理過程的示意性代碼如下:


代碼中將每次循環中條件分支中所要用到的不同的變量統稱為環境變量,可以是從某處讀取的數據,也可以是通過對循環變量i進行計算得到的數值等各種各樣的數據,但不能是循環之間相互依賴的數據。mode用于控制優化策略模式,其取值為0、1、2。0代表無法對循環進行提前,循環按原有順序執行。1代表圖2(b)中先F路徑后T路徑的模式,此時需要將第N+1次循環中的T路徑提前到本次進行,因此需要將循環變量以及各環境變量調整到第N+1次循環時的狀態,之后再執行第N次循環中的F路徑,此時又需要將循環變量和各環境變量重新調整回來,當兩個路徑都執行完畢之后再把循環變量遞增1。2代表圖2(a)中先T路徑后F路徑的模式,同樣也需要類似的在兩次循環的不同循環變量和環境變量之間進行切換。
4 試驗結果及分析
試驗采用的GPU加速設備是GeForce GT 550M(GF108),擁有兩顆SIMD核心,每個核心有48道,單精度峰值計算性能為284.16GFlops。軟件環境是CUDA toolkit 5.0。
4.1 基于循環推遲的聚合優化策略試驗
將32個SIMD線程(共32×48個CUDA線程)加載至同一SIMD核,以保證算術流水線滿載,避免指令級并行變化對性能的影響。每個SIMD線程中,各道的分支走向相互獨立,由 CURAND[13]庫通過偽隨機算法生成。每條分支路徑內部包含一系列數據依賴的混合乘加(fused-multiply-add,FMA)運算,并可通過改變混合乘加運算的多少來調節分支指令-非分支指令比(核函數中,分支路徑內指令數/分支路徑外指令數)。試驗對不同的分支指令-非分支指令比分別使用多數優先和輪轉兩種選路策略進行優化,并與未經優化的分支執行進行比較,得出加速比(優化前執行時間/優化后執行時間),試驗數據結果如圖4所示。
從圖4中可以看出,當分支指令-非分支指令比較小時,由于聚合本身所帶來的開銷,加速比低于1,隨著分支指令規模的提升,加速比逐步提升。多數優先策略測試取得的最佳加速比為1.152,輪轉策略測試取得的最佳加速比為1.256。由于多數優先策略需要定期處理道饑餓現象,所以在多數情況下加速比低于輪轉策略。
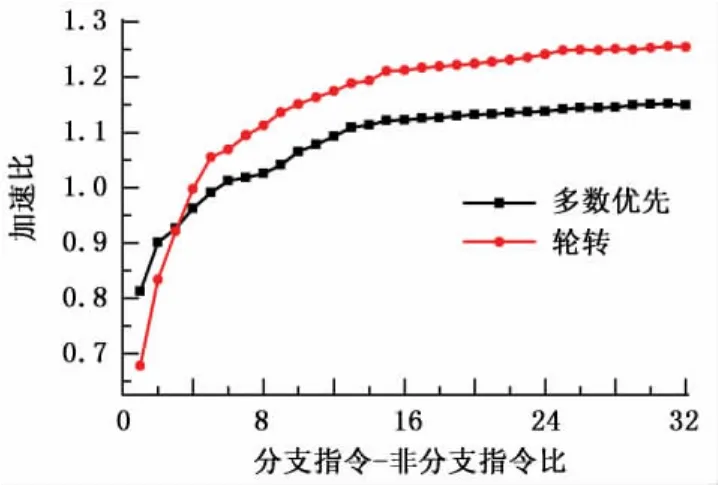
圖4 基于循環推遲的聚合優化對性能的影響Fig.4 Performance impact of converging optimization strategy based on loop postpone
4.2 基于循環提前的聚合優化策略試驗
加載的SIMD線程配置和分支路徑內的運算與基于循環推遲的聚合優化策略相同,且同時滿足基于循環提前的聚合優化策略的3個前提條件,針對條件(3)需要將循環內部原本位于條件分支語句后的非分支代碼封裝成函數移入條件分支內部。此處將這些函數稱為非分支代碼函數,并仍將其視作非分支代碼。
循環提前的效果除了依賴于分支指令-非分支指令比,還依賴于循環中出現圖2中兩種情況的比例。此處將能夠提前的循環數與循環總數的比值稱為可提前比。由于同一SIMD道中每兩個相鄰循環都選擇不同路徑時也只有50%的循環可以提前,因此可提前比最大是0.5,最小是0,并且加速效果取決于可提前比最低的SIMD道。理想情況下,若只考慮分支代碼,則可提前比與加速比的關系為

為更直觀反應本策略的有效性,在這里用線程號threadIdx和循環變量i使所有SIMD道中的可提前比一致,試驗時取了間隔相等的6個值。同時為了代表一般性,利用CURAND偽隨機算法生成分支走向,試驗數據結果如圖5所示。
需要說明的是,圖中每條曲線的前兩個點的分支指令-非分支指令比是0.25和0.5,第三個點是1,以后每次遞增1。在不同的可提前比情況下,隨著分支代碼-非分支代碼比的增加,程序的加速比都在逐步提升并趨近于只有分支代碼時的理想情況。當程序中可提前比過低且分支指令少于非分支指令時,本策略產生的額外開銷將導致程序的加速比低于1。
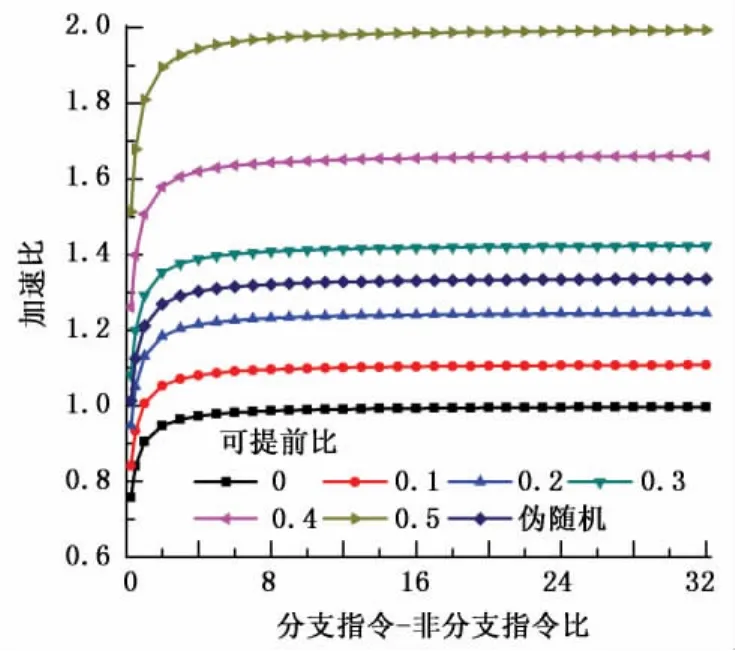
圖5 基于循環提前的聚合優化對性能的影響Fig.5 Performance impact of converging optimization strategy based on loop advance
5 結束語
在軟件層級提出兩種利用“聚合”思想的SIMD分支優化策略,將不同SIMD道中選擇相同路徑的條件分支“聚合”到了同一步循環中。壓縮了GPU執行SIMD操作的實際次數,提高了GPU硬件在每次SIMD操作時的利用率。試驗表明,在滿足一定條件下能夠取得較為理想的加速比,與現有的硬件層面的優化方案相比實現難度較低。本策略對分支結構有所要求,因此在一般性方面還存在不足。另外還可能存在一些影響優化效果的其他因素需進一步改進。
[1] NVIDIA.CUDA[EB/OL].[2013-05-12].https://developer.nvidia.com/cuda-downloads.
[2] NARASIMAN V,SHEBANOW M,LEE C J,et al.Improving GPU performance via large warps and two-level warp scheduling[C]//Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture.New York:ACM,c2011.
[3] DIAMOS G,ASHBAOGH B,MAIYURAN S,et al.SIMD re-convergence at thread frontiers[C]//Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture.New York:ACM,c2011.
[4] BRUNIE N,COLLANGE S,DIAMOS G.Simultaneous branch and warp interweaving for sustained GPU performance[C]//Proceedings of the 39th International Symposium on Computer Architecture.Washington:IEEE Computer Society,c2012.
[5] FUNG W L,AAMODT T M.Thread block compaction for efficient SIMT control flow[C]Proceedings of the 17th International Symposium on High Performance Computer Architecture(HPCA).Washington:IEEE Computer Society,c2011.
[6] NVIDIA.CUDA C Programming Guide 5.0[EB/OL].[2013-05-12].http://docs.nvidia.com/cuda/cuda-cprogramming-guide/index.html.
[7] NVIDIA.NVIDIA Compute:Parallel Thread Execution ISA Version 3.0[EB/OL].[2013-05-12].http://docs.nvidia.com/cuda/parallel-thread-execution/index.html.
[8] GLASKOWSKY P N.NVIDIA1s Fermi:the first complete GPU computing architecture[EB/OL].[2013-05-12].http://www.nvidia.com/object/fermi_architecture.html.
[9] CUI Z,LIANG Y,RUPNOW K,et al.An accurate GPU performance model for effective control flow divergence optimization[C]//Proceedings of the 26th International Symposium on Parallel& Distributed Processing.Washington:IEEE Computer Society,c2012.
[10] MENG J,TARJAN D,SKADRON K.Dynamic warp subdivision for integrated branch and memory divergence tolerance[C]//Proceedings of the 37th annual international symposium on Computer Architecture.New York:ACM,c2010.
[11] FUNG W W L,SHAM I,YUAN G,et al.Dynamic warp formation and scheduling for efficient gpu control flow[C]//Proceedings of the 40th Annual IEEE/ACM International Symposium on Microarchitecture.Washington:IEEE Computer Society,c2007.
[12] ZHANG E Z,JIANG Y,GUO Z,et al.Streamlining GPU applications on the fly:thread divergence elimination through runtime thread-data remapping[C]//Proceedings of the 24th ACM International Conference on Supercomputing.New York:ACM,c2010.
[13] NVIDIA.CUDA toolkit 5.0 CURAND guide[EB/OL].[2013-05-12].http://docs.nvidia.com/cuda/curand/index.html
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
數學大世界(2018年1期)2018-04-12 05:39:14
