分布式文件系統的應用研究
2014-12-23 11:34:36崔力升
科技視界 2014年2期
崔力升
(信陽職業技術學院,河南 信陽464200)
1 Google文件系統
Google文件系統(Google File System,GFS),它能運行在不可靠硬件設備上,對PB級別海量的數據進行處理,并且能同時多個用戶并發訪問服務器集群。文件系統中存放的數據絕大部分采用追加新數據而非覆蓋現有數據的方式進行寫操作。除了考慮到這些需要和技術特點后,GFS也考慮了分布式文件系統的共性設計目標:高可用性,大容量數據存儲和調度,簡單的負載均衡和冗余。
圖1是Google文件系統的文件架構圖。
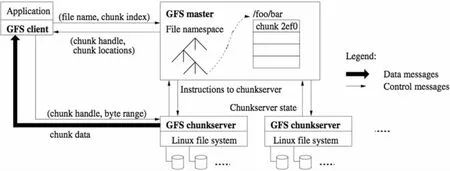
圖1 GFS架構
2 Hadoop文件系統
Hadoop分布式文件系統 (Hadoop Distributed File System,HDFS)是一個設計為用在普通硬件設備上的分布式文件系統。將其運行于計算機集群上,完成海量數據的計算,還包含了一個分布式文件系統HDFS(Hadoop Distributed File System)。
Hadoop具有如下優勢:
1)具有更高的可用性,可以容忍多個節點同時失效
2)具有更好的可擴展性,而且能夠實現在線的動態擴展
3)分布式的元數據管理,消除集中管理的瓶頸
4)采用類似于內存數據庫的方式存儲元數據,提供了元數據的訪問速度
5)配置簡單,方便管理,具有很好的實用性
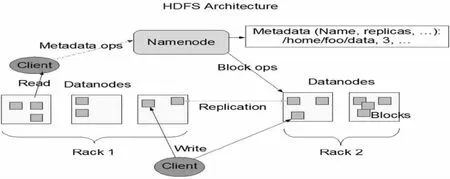
圖2HDFS架構
HDFS是主/從結構的。一個集群有一個名字結點,也就是主控制服務器,負責管理文件系統的名字空間并協調客戶對文件的訪問。還有很多數據結點,一般一個物理結點上部署一個,負責它們所在的物理結點上的存儲管理。HDFS開放文件系統的命名空間,用戶能夠以文件的形式在上面存儲數據。在HDFS中,也是以塊的形式儲數據(同GFS一樣,文件被分成塊來存儲),這些數據塊存儲在一組數據結點中。名字結點執行文件系統的名字空間操作(比如打開、關閉、重命名文件或目錄,還決定數據塊到數據結點的映射)。數據結點負責提供客戶的讀寫請求。名字結點對數據結點的數據塊進行統一調度。
Hadoop分布式文件系統中的MapReduce是核心計算模型,它有一個基本要求:待處理的數據集可以分解成許多小的數據集,而且每一個小數據集都可以完全并行地進行處理。
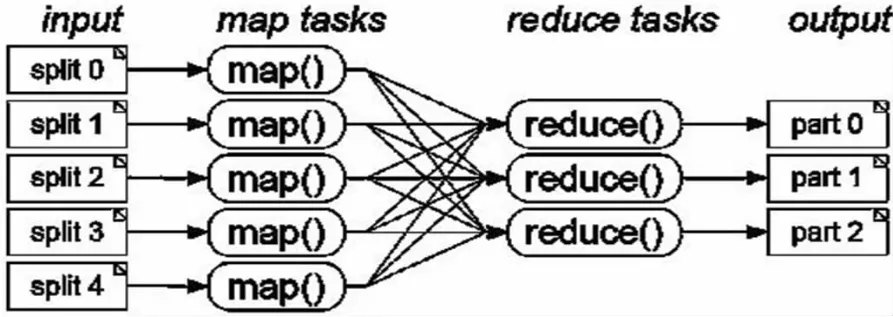
圖3
圖3中說明了用MapReduce處理海量數據的流程,將大數據分解為成百上千的小數據,各個數據分別由集群中的某一個結點生成中間結果,又有大量的結點對中間結果進行計算處理,形成最終結果。
3 Google文件系統和Hadoop文件系統對比
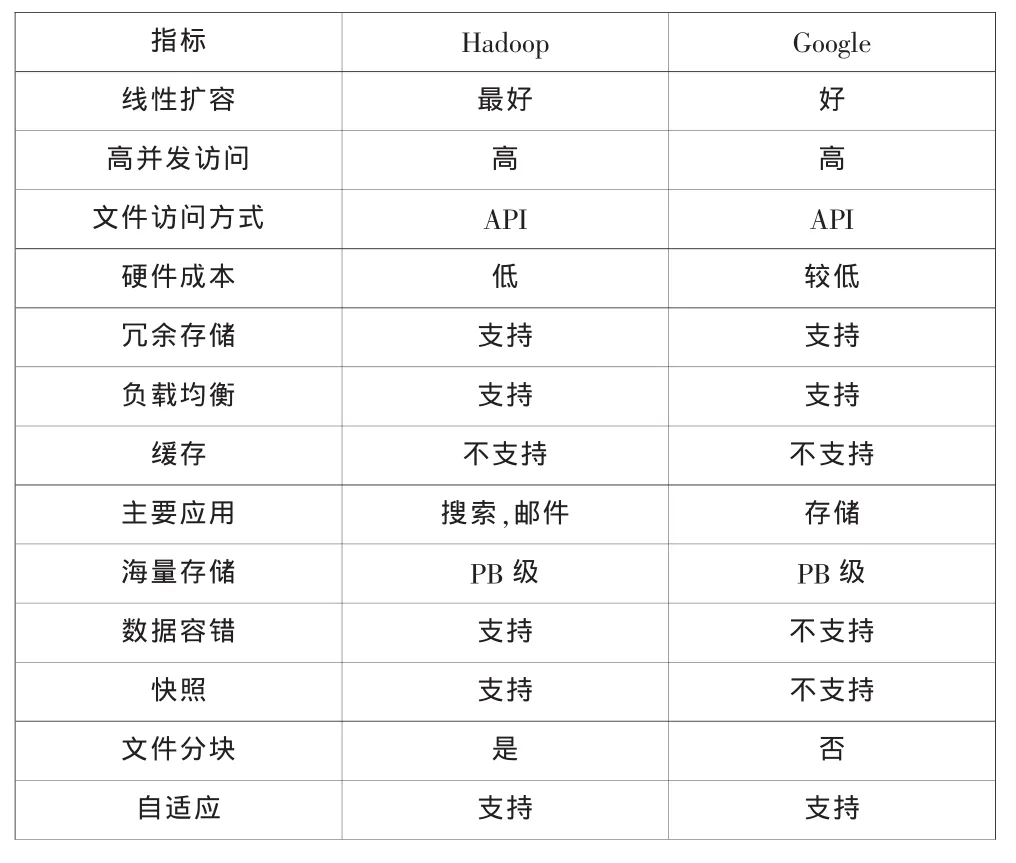
表1
盡管Google分布式文件系統和Hadoop分布式文件系統在自己的優勢上各具特色,所以對Google分布式文件系統和Hadoop分布式文件系統在實際應用中的各種性能上進行對比。
[1]苗放,葉成名,劉瑞,孔祥生.新一代數字地球平臺與“數字中國”技術體系架構探討[J].2007,6.
[2]郭曦榕,苗放,王華軍,劉瑞,等.基于G/S模式架構的數字旅游服務平臺研究[J].遙感技術與應用,2009.
[3]郭曦榕,苗放,王華軍,許義興,等.空間信息G/S網絡訪問模式體系架構初探[J].計算機應用與軟件,2009.
