一種基于變鄰域搜索的啟發式聚類算法
2015-01-01 03:10:38陳家俊徐華麗
皖西學院學報 2015年5期
金 萍,陳家俊,徐華麗
(皖西學院信息工程學院,安徽 六安237012)
0 引言
聚類分析是數據挖掘的重要任務,是一種典型的無監督學習方法,成為對數據進行合理歸類的重要手段[1-2]。聚類是根據數據的某些屬性,按照預先定義的相似度將數據劃分成若干類,并最大化類內數據對象的相似性,而最小化類間數據對象的相似性,以發現數據中隱藏的有用信息。直到目前為止還沒有相關文獻給出聚類的統一定義。基于不同的應用目的,研究者們采用不同的模型定義聚類問題。本文研究以組合優化模型定義的聚類問題,它是求解數值型數據聚類的重要方法,有著廣泛的應用背景。

所有可能的M集合就構成了該類聚類問題的搜索空間CX,窮舉CX中的每個結果就能獲得最優聚類結果。文獻[3]已經證明,即使在K=2的情況下,該聚類問題也是NP-難解的,即不存在多項式時間的精確算法能求得聚類問題的全局最優解。研究者們往往采用能在較短時間內獲得可接受解的啟發式搜索(heuristic search)方法來求解該類聚類問題,并設計了經典啟發式聚類算法,如K-means[1]、K-mediods[2]、PAM[4]及CLARANS[5]等。圖1給出了啟發式聚類算法的搜索示意圖。從圖1中可以看出,初始解A和初始解B引導算法收斂于不同質量的聚類結果。這說明啟發式聚類算法對初始解十分敏感。
變鄰域搜索在搜索過程中,通過系統地改變鄰域結構來拓展搜索范圍,獲得局部最優解,再基于已獲得局部最優解重新系統地改變鄰域結構擴展搜索范圍,以尋求另一個局部最優解。由于變鄰域在搜索過程中不斷地重構搜索鄰域,有效地避免了局部最優解的困擾,能很好地提高搜索算法的質量。

圖1 啟發式聚類算法搜索空間示意圖
本文引入變鄰域搜索技術改進現有啟發式聚類算法初始解敏感問題,給出了一種基于變鄰域搜索的啟發式聚類算法HC_VNS(Heuristic Clustering Algorithm based on Variable Neighborhood Search)。該算法:(1)從給定數據D中選取K 個數據對象構成初始解Morg;(2)對于初始解Morg中的每個中心點,從數據集D-Morg中選擇其KN個最近鄰居,構造與其對應的可變搜索鄰域VNS;(3)以初始解Morg為搜索起點,引導啟發式聚類算法在VNS中搜索新的聚類中心Mlocal;(4)如果Mlocal優于Morg,則用Mlocal替換Morg,并迭代執行(2)~(3)直到達到預定目標,否則,繼續在VNS中搜索聚類結果Mlocal;(5)依據產生的中心點集合,將D中剩余數據對象分配到與其最近中心點所表示的簇中,產生最終聚類結果C。實驗結果表明,變鄰域搜索對提高啟發式聚類算法質量非常有效。
本文的組織結構如下:第1節介紹本文背景知識;第2節介紹基于變鄰域搜索的啟發式聚類算法框架;第3節給出了實驗及實驗結果分析;最后總結全文。
1 背景知識
給定包含N個數據對象的數據集D={x1,…,xi,…,xN}和任意聚類中心點集合M,其最近鄰居和可變鄰域的構造方法描述如下。
定義1 給定數據集D和聚類中心點集合M={m1,…,mk,…,mK},則mk∈M 的KN 個最近鄰居定義為:

其中xi∈D-M,σ為閥值參數,用于選擇KN個最近鄰居,“-”為集合減運算。
定義2 給定數據集D和聚類中心點集合M,M的可變搜索鄰域VNS定義為:

定義3 給定數據集D,初始解(即K個聚類中心點)Morg及其對應的可變搜索鄰域VNS,啟發式聚類算法HC_VNS的聚類結果定義為:

其中C(mk)是以mk為中心的聚類。
2 基于變鄰域搜索的啟發式聚類算法框架
本節介紹基于變鄰域搜索的啟發式聚類算法HC_VNS算法框架及時間復雜度分析。
2.1 HC_VNS算法框架
算法1 HC_VNS
輸入:數據集D,聚類個數K
輸出:聚類結果C
(1)從數據集D中任選K 個數據對象構成初始中心點Morg;
(2)for(p=1;p<=P;p++)
(a)根據定義1~2,構造 Morg的可變搜索鄰域VNSorg;
(b)以Morg為搜索起點,調用現有啟發式聚類算法在VNSorg中搜索新的聚類中心Mlocal;
(c)如果Mlocal優于Morg,則 Morg←Mlocal;
否則繼續在VNSorg中搜索新的Mlocal;
(3)以步驟(2)產生的Morg聚類中心,將數據集D數據對象分配給與其最近的聚類中心,產生聚類結果C={Cm1,…,Cmk,…,CmK};
(4)返回聚類結果C。
算法1給出了HC_VNS算法框架。該算法主要包含3個步驟:選擇初始解、迭代構造可變搜索鄰域和啟發式聚類。HC_VNS算法的具體步驟:(1)從給定數據D中選取K個數據對象構成初始解Morg(聚類中心點);(2)對于初始解Morg中的每個中心點mk∈M org,k=1,…,K,從數據集D-Morg中選擇mk的KN 個最近鄰N(mk)={xi},構造可變搜索鄰域VNSogr={N(m1),…,N(mk),…,N(mK)};(3)以初始解Morg為搜索起點,引導啟發式聚類算法在VNSorg中搜索聚類中心Mlocal;(4)如果 Mlocal優于Morg,則Morg←Mlocal,并迭代執行(2)~(3)直到達到預定目標,否則,繼續在VNSorg中搜索聚類結果Mlocal。最后將D中剩余數據對象分配給與其最近的聚類中心,產生聚類結果C。
2.2 時間復雜度分析
算法HC_VNS的時間消耗主要集中在可變鄰域構造與啟發式搜索2個部分。對于任意給定的數據集D,dist()函數采用歐幾里德距離,算法可先計算每個數據對象的相似度,耗時O(N2),其后可直接依據該相似度構建可變鄰域。步驟(a)對Morg中的每個數據對象,選擇與其最近的KN個鄰居,構造可變搜索鄰域VNSorg,需耗時O(K*KN)。步驟(b)以Morg為搜索起點,調用現有啟發式聚類算法在VNSorg中搜索新的聚類中心,其耗時與調用算法及VNSorg的規模有關。現有的啟發式聚類算法中K-means算法時間消耗與VNSorg的規模呈線性關系,而其它算法如PAM、K-medoids和CLARANS算法的時間消耗與VNSorg規模呈平方關系,即步驟(b)的時間消耗最多為O(K*KN2)。步驟(2)通過P次迭代執行可變鄰域構建與啟發式搜索,以完成搜索更優聚類中心的目的,其時間復雜度為O(P*K*KN2)。步驟(3)將數據集D的N 個數據對象分配給與其最近的聚類中心,產生聚類結果C,其時間消耗最多為O(K*N)。
綜上所述,算法HC_VNS的總消耗為:O(N2+P*((K+1)*KN+P*K*KN)2),其中相似度計算步驟通常可以在預處理階段完成,因此本文提出的算法時間消耗為O(P*((K+1)*KN+P*K*KN2))。
3 實驗結果及性能分析
3.3 性能評價標準
本文使用文獻[6]給出了一種兼顧簇內相似性與簇間相異性的內部質量衡量方式來評價HC_VNS算法性能。
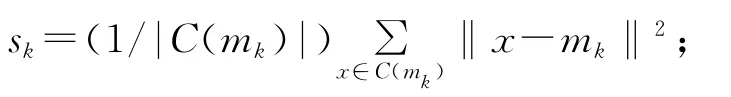

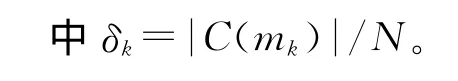
3.2 實驗結果
根據上述算法實現步驟,進行實驗仿真:實驗平臺采用Intel Core I5 3.3GHz CPU\4G 內存計算機,在Windows XP環境下用Matlab7.5實現算法HC_VNS以 及 對 比 算 法 K-means、NHCA[7]、CIGC[8]、ABRAC[9]。算法NHCA采用噪聲法重構搜索空間,降低局部最優解對啟發式聚類算法的影響。算法CIGC采用共有信息構建初始解,引導啟發式聚類算法在解空間進行搜索。而ABRAC算法則引入近似骨架概念設計新的啟發式聚類算法,提高聚類質量。這3個改進的啟發式聚類算法被成功地應用于標注挖掘[10-11],不確定數據挖掘[12],推薦系統[13]等領域。
本文分別在1個人工實驗數據集和5個經典的真實數據集上進行了實驗。
(1)人工實驗數據集
因為通過比較輸入數據與輸出數據,可以更精確地評價聚類結果,本文首先在人工實驗數據集上進行實驗。表1給出了人工數據集Dataset1的基本情況。

表1 Dataset1
圖2給出了算法HC_VNS及其對比算法K-means、NHCA、CIGC和ABRA在Dataset1上的實驗對比結果。從圖中可以看出,經典啟發式聚類算法K-means獲得的Q(C)值明顯高于其它對比算法,這說明K-means算法受到局部最優解的影響很大。算法NHCA采用噪聲平滑技術“填平”搜索空間中的局部最優解“陷阱”,降低啟發式聚類算法過早收斂概率,提高聚類質量,因此該算法的質量要明顯優于K-means算法質量。CIGC算法利用多個局部最優解的共同信息,產生優化的初始解,并以此初始解來引導啟發式聚類算法收斂于更優結果。ABRA算法則利用局部最優解和全局最優解分布的“大坑”特征,引入骨架概念設計啟發式聚類算法。NHCA、CIGC、ABRA和HC_VNS都采用了不同的優化技術來避免局部最優解對算法的影響,從而達到提高聚類質量的目的。

圖2 5種對比算法在Dataset1上的實驗結果
為了比較5種算法的效率,本文在數據集Dataset1上運行對比算法,獲得的時間消耗如圖3所示。從圖中可以看出K-means算法基本與數據集的規模呈線性增長關系,而其它優化算法NHCA、CIGC和ABRA則幾乎呈平方量級增加。造成這個現象的原因是:優化算法NHCA、CIGC和ABRA需要在數據集D上多次運行啟發式聚類算法獲得局部最優解,然后采用不同的優化策略進行算法質量改進,因此耗時較大。HC_NVS的時間消耗比K-means算法還要低一些,這是因為HC_NVS每次進行變鄰域重構和啟發式搜索都是在數據對象的KN個鄰居中進行,因此大大減少了時間消耗。

圖3 5種對比算法在Dataset1上的時間消耗對比
(2)實際數據集
為了驗證算法HC_VNS處理實際數據集的能力,本文從http://archive.ics.uci.edu/ml/datasets.html網站上下載了5個真實數據集進行實驗,數據集描述如表2所示。表2所示數據集包含規模、屬性和簇3個屬性,分別表示該數據集包含數據對象個數,數據對象的屬性個數以及該數據集包含的聚類個數。每個數據集屬性取值都是實數或整數。

表2 真實數據集
圖4給出了5種對比算法在5個實際數據集上的實驗結果。本文提出的HC_VNS和改進的啟發式聚類算法NHCA、CIGC、ABRA都能較好地處理真實數據,獲得較高質量的聚類結果,明顯優于傳統聚類算法K-means的聚類結果。但是在數據集BC、PRHD、CBD以及QM上的聚類結果不是太好,造成這個現象的原因是隨著數據維度的不斷增加,相似度的誤差越來越大,影響了啟發式聚類算法的效果。
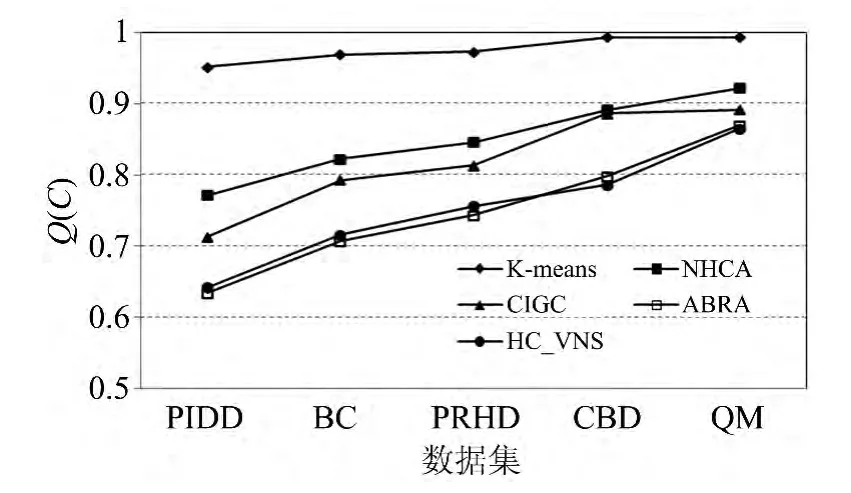
圖4 5種對比算法在真實數據集上的實驗結果
4 結語
本文利用可變鄰域搜索的優點,設計了一種基于可變鄰域搜索的啟發式聚類算法,給出了算法框架,并分別在人工數據集和實際數據集上驗證了算法的效率和效果。實驗結果表明,可變鄰域搜索對提高啟發式聚類算法質量十分有效。
[1]Maimon O.,Rokach L.Data Mining and Knowledge Discovery Handbood[M].Spring,2010.
[2]孫吉貴,劉杰,趙連宇.聚類算法研究[J].軟件學報,2008,19(1):48-61.
[3]Drinesa P.,Frieze A.,Kannan R.Clustering Large Graphs Via the Singular Value Decomposition[J].Machine Learning,2004,56(1-3):9-33.
[4]Kaufman L.,Rousseeuw P.J.Finding Groups in Data:an Introduction to Cluster Analysis[M].John Wiley &Sons,1990.
[5]Ng R.,Han J.CLARANS:A Method for Clustering Objects for Spatial Data Mining.IEEE Trans on Knowledge and Data Engineering[J],2002,14(5):1003-1016.
[6]宗瑜,江賀,張憲超,等.空間平滑搜索CLARANS算法.小型微型計算機系統[J].2008,29(4):667-671.
[7]金萍,宗瑜,李明楚.一種噪聲啟發式聚類算法[J].合肥工業大學學報,2009,32(6):786-790.
[8]金萍,宗瑜,李明楚.共有信息導向的啟發式聚類算法[J].計算機工程與應用,2010,46(31):50-53.
[9]宗瑜,江賀,李明楚.近似骨架導向的歸約聚類算法[J].電子與信息學報,2009,31(12):2953-2957.(EI檢索)
[10]Xu G.D.,Zong Y.,Jin P.,et al.KIPTC:a Kernel Information Propagation Tag Clustering Algorithm[J].Journal of Intelligent Information System,2015,45(1):95-112.
[11]Rong P.,Xu G.D.,Peter D.,et al.Group Division for Recommendation in Tag-Based Systems[C].CGC 2012:399-404.
[12]金萍,宗瑜,曲世超,等.面向不確定數據的近似骨架啟發式搜索算法[J].南京大學學報:自然科學版,2015,1(51):197-205.
[13]Li X.,Xu G.D.,Chen E.H.,Zong Y.Learning Recency Based Comparative Choice towards Point-of-interest Recommendation[J].Expert System and Application,2015,42(9):4274-4283.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
山東青年(2016年1期)2016-02-28 14:25:25
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
