多機器人系統強化學習研究綜述
2015-01-07 07:59:44張文旭戴朝華
西南交通大學學報 2015年4期
馬 磊, 張文旭, 戴朝華
(西南交通大學電氣工程學院,四川成都610031)
多機器人系統強化學習研究綜述
馬 磊, 張文旭, 戴朝華
(西南交通大學電氣工程學院,四川成都610031)
強化學習是實現多機器人對復雜和不確定環境良好適應性的有效手段,是設計智能系統的核心技術之一.從強化學習的基本思想與理論框架出發,針對局部可觀測性、計算復雜度和收斂性等方面的固有難題,圍繞學習中的通信、策略協商、信度分配和可解釋性等要點,總結了多機器人強化學習的研究進展和存在的問題;介紹了強化學習在機器人路徑規劃與避障、無人機、機器人足球和多機器人追逃問題中的應用;最后指出了定性強化學習、分形強化學習、信息融合的強化學習等若干多機器人強化學習的前沿方向和發展趨勢.
多機器人系統;強化學習;馬爾科夫決策過程;計算復雜度;不確定性
多機器人合作是近年自動化與控制領域發展的前沿方向[1].多機器人的研究與應用體現出了廣泛的學科交叉,涉及眾多的課題,目前已在工業、農業、商業、太空與海洋探索、環境監測、災害救險、國防等領域獲得越來越多的關注與應用.
要實現多機器人靈活和有效的行為選擇能力,保證它們之間的協作關系,僅依靠設計者的經驗和知識,很難獲得多機器人系統對復雜和不確定環境的良好適應性[2].為此,必須在機器人的規劃與控制中引入學習機制,使機器人能夠在與環境的交互中,具有一定的識別、判斷、比較、鑒別、記憶和自行調整的能力.
機器學習是研究如何使用機器來模擬人類學習活動的一門學科,強化學習(reinforcementlearning,RL)作為機器學習的一種重要手段,可以使機器人與復雜的動態環境建立起一種交互關系.其嘗試獲得知識的過程與人類的學習十分相似,因此獲得了廣泛的關注,被認為是設計智能系統的核心技術之一[3].
多個機器人可以通過協作完成單個機器人無法解決的復雜任務.協作是多機器人系統的核心,但并非機器人與生俱來的特性.人類的許多協作行為都是通過后天不斷的學習獲得的,因此,多機器人也可以通過學習來增強和改進自身的能力,提高團隊的協作行為與效率.多機器人系統的學習并不是單個機器人學習的簡單疊加.事實上,多機器人系統的學習過程直接依賴于學習系統中多個機器人的存在和交互,是一個復雜的交互學習過程,需要考慮到它們之間的協商、信度分配及局部性等多方面因素.
本文第1節首先介紹強化學習的基本思想和理論框架,并在第2節將相關概念擴展到多機器人強化學習.在第3節中,針對局部可觀測性、計算復雜度和收斂性等方面的固有難題,圍繞學習中的通信、策略協商、信度分配和可解釋性等內容總結多機器人強化學習的研究進展和存在的問題.第4節介紹強化學習的在多機器人系統中的若干典型應用.最后指出多機器人強化學習的前沿方向及發展趨勢和面臨的挑戰,以期促進相關研究.
1 強化學習理論與方法
1.1 強化學習原理
經典的強化學習基于馬爾科夫決策過程(Markov decision process,MDP),介于監督式學習和無監督式學習之間,以一個單獨的學習系統為載體進行.如圖1所示,學習系統(機器人、個體(Agent))通過與環境的即時交互來獲得環境的狀態信息,并通過反饋強化信號對所采取的行動進行評價,利用不斷地試錯和選擇,進而逐步改進從狀態到動作的映射策略,達到學習的目的.在強化學習的過程中,所有系統和環境狀態都被認為具有馬爾科夫性,即當前的狀態只取決于上一時刻的狀態和動作.這一假設大大簡化了決策過程的復雜性.

圖1 強化學習框架Fig.1 Framework of reinforcement learning
1.2 強化學習方法
1.2.1 瞬時差分法
對于一個還未完全了解的系統,可以通過學習過去的經驗預測其未來行為.瞬時差分法(temporal difference,TD)[4]基于這一思想,結合了動態規劃與蒙特卡洛算法,通過預測當前動作的長期影響(即預測未來回報)將獎懲信號傳遞到動作中.最簡單的TD算法是一步TD算法(TD(0)),個體獲得瞬時獎賞值僅向后回退一步,即只迭代修改了相鄰狀態的估計值,迭代表式為

式中:β為學習率;V(st)和V(st+1)分別為個體在t和t+1時刻訪問狀態st和st+1時估計的狀態值函數;rt+1為瞬時獎賞值;γ為折扣因子.
個體獲得瞬時獎賞值可以向后回退任意步,則形成TD(λ)算法,其表達式為
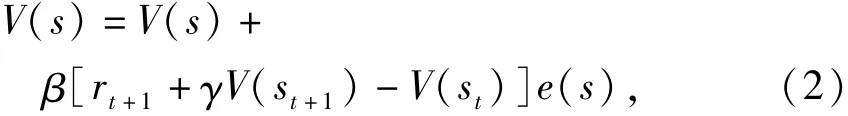
式中:e(s)為狀態s的選舉度,可通過式(3)計算:

式中:λ為折扣速率;

在當前狀態歷史的t步,如果一個狀態被多次訪問,則其e(s)越大,表明其對當前獎賞值的貢獻越大.式(4)為式(3)的遞歸形式:

與TD(0)算法相比,TD(λ)算法在收斂速度上有很大提升.但是,由于其在遞歸過程中的每個時間步都要對所有的狀態進行更新,所以當狀態空間較大時,難以保證算法的實時性.近年來,很多學者都對其做了研究,代表性工作有:文獻[5]提出一種基于核心的在線選擇TD(OSKTD)學習算法,通過對值函數進行在線稀疏化和參數更新兩個過程,用以處理大規模連續的強化學習問題;文獻[6]證明了任意的表格型折扣回報TD(λ)學習算法的概率收斂性;文獻[7]研究了TD(λ)學習算法均方差與的函數關系,給出了一定假設下的表達式,針對采用線性值函數逼近的TD(λ)學習算法.
1.2.2 Q-學習
文獻[8]提出了一類通過引入期望的延時回報,求解無完全信息的馬爾科夫決策過程類問題的方法,稱為Q-學習(Q-learning).Q-學習是一種模型無關的基于瞬時策略的強化學習方法,提供機器人在馬爾科夫環境中,利用經歷的動作序列執行最優動作的一種學習能力.Q學習算法的基本形式為:

其中:Q*(s,a)表示機器人在狀態s下才用動作a所獲得的獎賞折扣總和;γ為折扣因子;P(s,a,s′)表示概率函數.最優策略為狀態s下選用Q值最大的行動a.
不同于TD算法,Q-學習迭代時采用狀態-動作對的獎賞和Q(s,a)作為估計函數,而不是TD算法中的狀態獎賞V(s),這樣在每次學習迭代時都需要考察每個行為,可確保學習過程收斂[9].Q-學習可以根據TD(λ)算法的方法擴展到Q(λ)算法.
近年來,Q-學習算法得到廣泛關注.文獻[10]提出一種基于最小二乘支持向量機的Q-學習方法,由一個最小二乘支持向量回歸機(LS-SXRM)和一個最小二乘支持向量分類機(LS-SVCM)構成,LS-SXRM用于逼近狀態-動作對的值函數映射,LS-SVCM用于逼近連續狀態空間到離散動作空間的映射;文獻[11]將流形學習中計算復雜度較小的LE方法引入啟發式Q學習中,提出了一種基于譜圖理論的啟發式函數設計方法;文獻[12]提出一種保真概率的Q-學習(fidelity-based probabilistic q-learning,FPQL)方法,在學習迭代過程中采用保真度幫助學習過程和行動概率的選擇,以此來平衡強化學習中策略的試探與利用的關系.
Sarsa(state-action-reward-state-action)算法[13]是Q-學習算法的一種特殊在線策略形式.Q-學習采用值函數的最大值進行迭代,Sarsa采用實際的Q值進行迭代.另外,Sarsa算法的每個學習步,機器人都依據當前Q值確定下一狀態時的動作,Q-學習中需要依據修改后的Q值確定動作.Sarsa算法的更新規則為

1.2.4 Actor-Critic學習算法
上述3種學習算法具有一個共同特點,即僅對MDP的值函數進行估計,行為選擇策略則由值函數的估計完全確定.為了同時對值函數和策略進行估計,文獻[14]提出了Actor-Critic學習算法,采用TD學習算法實現值函數的估計,并利用一種策略梯度估計方法進行梯度下降學習.文獻[15]進一步研究了求解連續行為空間MDP最優策略的Actor-Critic學習算法.
2 多機器人的強化學習方法
與單個機器人相比,多機器人的強化學習更注重機器人之間學習知識、經驗等的交互.在有多個機器人參與的協作過程中,考慮到環境的不確定性與局部可觀測的影響,它們與環境的交互擴展至局部可觀測馬爾科夫決策過程(POMDP)和分布式局部可觀測馬爾科夫決策過程(DEC-POMDP).學習過程不再具有馬爾科夫性,每個時刻都需要通過考慮自身及隊友的歷史信息及經驗來進行學習和判斷,在這種情況下,學習的難度與計算復雜度都遠高于單機器人的強化學習.DEC-POMDP的求解是一個NEXP(non-deter-ministic exponential time)問題[6].
多機器人的強化學習分為集中式和分布式.集中式的強化學習將所有機器人看作一個整體,利用一個全局學習單元,采用經典的強化學習方法進行學習,然后將策略分配給每個機器人.其常用于調度問題,例如電梯組[17]和異構機器[18]等調度問題.分布式強化學習要復雜得多,又可以分為獨立強化學習(reinforcement learning individually,RLI)與群體強化學習(reinforcement learning in group,RLG),是當前研究的主要課題.在學習系統中,如果每個機器人的學習不考慮其他機器人的狀態,稱之為獨立強化學習,其協作過程可以稱為自私型或者完全自私型;如果每個機器人在學習過程中,既考慮自身及任務,還要考慮到隊友可能的行動與策略,通過學習和推理后得到一個利于團隊的個體策略,則稱為群體強化學習,其協作過程為協作型或完全協作型.
多機器人分布式強化學習中,所有機器人在追求一個共同的目標過程中彼此通信、合作.每個機器人在與環境的交互中,由于獲取信息而改變自身狀態和周圍環境,在學習過程中又受到其他機器人的知識、信念、意圖、經驗等的影響,這在狀態局部感知情況下尤為突出,其結構如圖2所示.多機器人強化學習難點就在于如何協調它們間的知識和學習,以及如何在保證學習速度的前提下加強它們之間的協作.
單個機器人強化學習的思想和算法可以通過組合狀態、組合動作、策略分配等方法,實現在多機器人強化學習中延續和擴展.一些代表性工作有:文獻[19]提出了一種基于多個體并行采樣和學習經驗復用的改進算法,在探索階段,通過多個體并行采樣,快速收集模型信息;在利用階段,通過保留最優值函數的方式復用算法的學習經驗,提高了算法迭代計算值函數的效率;文獻[20]依靠局部通信和計算,設計了一種網絡環境中基于MDP的分布式Q-學習算法,并證明了該算法的漸進收斂性;文獻[21]設計了一種分布式的核強化學習方法,首先通過添加虛擬機器人領隊實現編隊控制,再利用強化學習算法來優化編隊控制策略;文獻[22]提出了一種多個體的合作樹框架,定義兩種樹枝權重來描述個體是否參與合作,然后利用強化學習算法求解聯合行動的策略.

圖2 多機器人學習與交互方式Fig.2 Learning and interactive mode of robots
3 多機器人強化學習存在的問題
在多機器人的強化學習中,隨著參與機器人數量的增加,它們之間的交互關系愈加繁雜.客觀環境會帶來局部可觀測及不確定性等問題,每一個機器人在考慮自身局部信息的情況下,還需要考慮隊友的信息,需要考慮機器人行為對環境的影響;求解多機器人的強化學習計算難度更高,解決目標問題時存在維度災難問題;利用現有算法,求解強化學習的手段會引出多機器人通信、策略協商及團隊信度分配等問題.所有問題圍繞著強化學習的核心:學習速度與收斂性,呈現出一個相互關聯的邏輯關系,如圖3所示.
在隆重紀念改革開放40年的日子里,我們認認真真地總結一下自己走過的路,認認真真借鑒一下歷史和他人的正面經驗和反面教訓,是非常有必要的。我們理應在改革開放今天與明天的偉大事業中,力求有所作為!我們做人就清清白白地做人,做官就規規矩矩地做官,做事就扎扎實實地做事,做學問就正正經經地做學問!中國優秀傳統文化的重要內容之一是“三不朽”——立德,立功,立言,我們要學習實踐“三不朽”。
3.1 局部可觀測與環境不確定性
描述一個智能系統面臨的環境可以從五方面進行分析[23],其中狀態部分可知(partial observation)和不確定性(uncertainties)在多機器人的研究
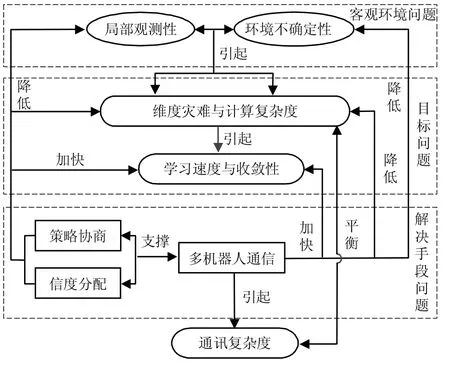
圖3 問題邏輯關系Fig.3 Logic of problems
中尤為突出.
由于每個機器人的感知能力和范圍有限,以及復雜環境中突發情況等因素的存在,機器人獲得的信息往往帶有局部性和不確定性,這在大規模的多機器人系統中更是難以避免.因此,克服狀態局部感知與不確定性,是多機器人強化學習的重要研究方向.一些代表性工作有:文獻[24]結合了MaxQ算法和分層強化學習算法,首先通過MaxQ學習獲得環境特征,然后綜合局部選擇并制定多機器人在未知環境下的合作策略;文獻[25]利用學習壓力領域作為一種手段來評估強化學習算法在多個體學習進程,研究了部分可觀察模型有限分析隨機過程框架,以長期的平均預期收益為實際策略.
在學習過程中,每個機器人都需要考慮系統的不完整信息和其他個體的不確定因素,目前多數針對局部觀測的研究都使用POMDP,但是該模型是研究團隊中每個機器人的局部性后才考慮機器人間的協作的.作者認為,DEC-POMDP模型將單個機器人的局部性擴展到了所有機器人,使得多個機器人間的局部性得到交互,可以更好地還原它們在復雜未知環境中的學習和協作過程.目前多機器人的強化學習與DEC-POMDP的結合還不多見,是一個值得研究的方向.
3.2 維度災難與計算復雜度
多機器人協作過程中,環境是在多個機器人的聯合動作下進行狀態遷移的.強化學習方法采用狀態-動作的映射來表示行為策略,由于復雜環境的不確定性影響和機器人感知的局部性,因而不可避免地出現學習策略隨狀態、動作的維數呈指數增長的現象,即“維數災難”.
“分而治之”是解決復雜問題的重要手段[26].分層強化學習(hierarchical reinforcement learning,HRL)基于這一思想,對問題空間進行結構化分解或分層,代表性工作有文獻[27-29].另外,文獻[30]提出一種基于分層強化學習的多機器人任務分解方法,在每個機器人的運動范圍基礎上,假設存在一個位置坐標負載(load position),負載類似于運動中的障礙,通過逐漸減小位置坐標負載來分解任務.文獻[31]基于分層理論,通過研究多個體的分層狀態表達、狀態-行動抽象空間和社會結構,將其嵌入學習過程,并量化搜索過程,達到減小計算復雜度和提高強化學習效率的目的.其余解決維數災難問題的方法還有狀態聚類法[32]、有限策略空間搜索法[33]、值函數近似法[34]等.但目前的方法仍存在學習效率不高、收斂性難以保證等缺點[35].
作者研究了一致性算法與多個體決策過程的結合[36],探索了一致性收斂對策略空間規模的影響、策略空間的化簡和最優策略搜尋方法,并尋求一種新的方法來刪減、合并冗余和沖突的策略,以此緩解維度災難并降低計算復雜度.
3.3 學習速度與收斂性
強化學習速度較慢的主要原因是沒有明確的教師信號.個體在與環境的交互過程中,完全采用試探的方法,僅依靠外部的評價來調整自己的行為,這勢必需要經過一個漫長的學習過程.這是強化學習的固有難題.
文獻[19]提出在學習的不同階段復用以前的學習經驗,通過設定初始值函數融入模型先驗知識的方法,提高了算法的收斂速率;文獻[37]將歐拉向前微分計算方法與強化學習算法相結合,提出一類非線性不確定動態系統基于強化學習的最優控制方法,較好地解決了連續狀態-動作空間的泛化問題,提高了非線性系統的學習效率;文獻[38]通過Q-學習獲取協作行為準則,使多機器人在預知的環境中相互協作,縮短了學習時間;文獻[39]提出一種基于啟發式的快速多個體強化學習算法(HAMRL),利用啟發式函數表示初始行動策略,從前期經驗中提取特征或從觀察中學習.另外,文獻[40]提出了利用經驗回放(experience replay)思想提高強化學習的學習效率.文獻[41]提出一種基于Actor-Critic結構的積分強化學習(integral reinforcement learning,IRL)方法,利用經驗回放更新Critic的權重,以此來求解IRL的Bellman方程,提高學
習收斂速度.
3.4 學習中的通信
由于無法獲得全局的環境信息,處于復雜和未知環境中的多機器人很難進行正確的學習,容易根據自身獲得的局部信息,做出多余或有沖突的策略,因此通信是重要的提高學習速度和質量的手段.
多機器人間協作的通信可以分為隱式與顯式通信.隱式通信利用機器人的行為對產生環境的變化來影響其他機器人的行為.當某一個機器人做出特定的動作或達到指定的位置時,相當于告訴其他機器人一個之前約定好的信息,但是這種方式可以傳遞的信息量有限,并且不能保證其他機器人都觀測到,因此只能用于比較簡單的學習模型中.顯式通信指機器人間通過硬件通信設備直接通信,是當前主要的在線學習手段.文獻[42]研究了多移動機器人通信仿真系統設計方案,側重于反映通信網絡的拓撲變化情況.文獻[43]研究了基于強化學習的通信在多個體合作中的應用.
目前大多數多機器人系統仍然采用集中通訊方式,該方式存在通訊消耗大、延遲明顯等缺點,因此,如何降低多機器人系統對通信的依賴程度也是一個重要的問題.作者認為,可以在網絡化多機器人學習系統中應用一致性方法[44],通過局部通訊,以較少的通訊代價實現信息傳輸和共享.目前,專門針對通訊代價或通訊復雜度的研究還不多見.文獻[45]將通訊復雜度定義為通訊次數和一致性收斂精度的函數,并研究了確定性和隨機(Gossip)一致性算法要求的通訊復雜度,提出了一種在Gossip算法中通訊復雜度的凸優化方法.事實上,通訊復雜度是分布式計算中的一個重要問題,文獻[46]提出了一種通訊復雜度最優和時間復雜度幾乎最優(almost optimal)的Gossip算法,通過挑選若干“協調者(coordinators)”承擔主要的決策任務,避免了節點之間的冗余信息交換.
3.5 策略協商
協商的思想產生于經濟活動中的理論,主要用于資源競爭,任務分配和沖突消解等問題中.文獻[47]指出,在當前還不足以成功地將人類的協商技巧程序化的情況下,機器人在協商過程中通過學習不斷更新策略是一個有效的辦法.
在協商策略的研究中,對于機器人如何獲得合適的策略有兩種解決方案,一種方案是在機器人初始化時配置足夠的策略,這意味著需要先驗描述所有可能的情況及其解決辦法,但是,對于大多數的實際應用來說這是不可能做到的.另外一種方案是機器人自身具有學習能力,能夠從協商過程中獲取經驗.在多個體系統的強化學習中,個體間交換即時狀態、學習片段或學習策略,都可以提高個體的學習和任務完成效率[48].文獻[49]在多機器人協作的MaxQ學習方法中引入π心智演算過程,構建起具有學習與通信能力的機器人心智狀態模型,對機器人主體的公共知識、信念、目標、意圖、承諾、信任、知識更新等進行了定義,并構建起多機器人主體協商模型.文獻[50]研究了多個體協商決策過程,設計了一種基于Q-學習的第n步多主體協商算法,多個體之間通過協商未來的行動,來選擇最優的聯合策略.
協商過程中信息交互量越大,協商效果越好.以適當的通訊為代價實現個體間的信息交換和共享,加強多機器人之間的協商,是提高決策效率的重要手段,故有必要研究通訊代價和學習效果之間的平衡.
3.6 信度分配問題
信度分配問題(credit-assignment problem,CAP)是實現強化學習的一個難點,主要需要考慮如何根據系統性能的改變,合理地將獎懲分配到學習系統中每個行為動作上,可以分為結構分配(structure-CAP,SCAP)和時間信度分配問題(time-CAP,TCAP)[51-54].
對于多機器人學習,該問題(multi-robot credit assignment,MCA)變得更加復雜,首先要考慮結構信度分配問題.當一個由多個機器人的合作任務完成時,如果全部回報由最后一個執行動作的機器人獲得,則只有這一個機器人可以進行學習,是不利于機器人團隊的,要考慮如何合理地將回報分配給參與合作的機器人.但是,如果僅按照機器人的貢獻來分配,也會存在一些問題,比如在異構多機器人合作中,某次偶然出現高性能的機器人會得到較多的回報,使其性能評價逐漸增強,而影響到團隊中真正擁有高性能并需要強化的機器人.目前主要的可行方法是將任務分解為子任務,然后根據每個子任務的重要性及執行的機器人進行評判.文獻[55]研究了噪聲環境中的多個體信度分配問題,利用強化學習算法消除噪聲對回報值的影響;文獻[56]利用配置評判個體(critic agent)的方法研究了信度分配問題.
在實際應用中,一個動作的成功或失敗可能需要一段時間以后才能知道,所以強化信號往往是一個動作序列中以前的某個動作引起的響應,也就是所謂的延遲回報.回報被延遲得越多,學習算法就需要越多的嘗試,收斂時間會越長,這就是時間信度分配問題.回報函數的設計對于強化學習算法的學習性有重要的意義,逆強化學習(inverse RL)[57]在近年來得到了關注[26].逆強化學習的思想就是利用已有的經驗數據來學習MDP的回報函數,從而實現回報函數的自動設計.目前逆強化學習的研究已經取得了若干成果[58-59].但是,回報函數與經驗知識的融合依舊存在一些問題,比如,如何評判過去經驗是否有價值、如何判斷環境的變化與經驗的關系等問題,還有待深入研究和完善.
3.7 可解釋性
機器學習的另一個問題是得到的模型的可解釋性差[60].可解釋性和實際應用密切相關,機器人通過學習解決一些具體的問題時,需要領域的專家能夠理解模型,能夠理解“為什么”這個模型能夠對未知樣本做預測.在求解學習問題時可能得到多個解,如果使用其一直以來所遵循的“輸入輸出滿足”原則,可能建立的多個模型獲得多個解,則需要以對問題世界可解釋性來分辨其優劣.
4 多機器人強化學習的應用
對于多自主移動機器人系統,強化學習是實現具有自適應性、自學習能力的智能機器人的重要途徑,這也為解決智能系統的知識獲取這個瓶頸問題提供了一個可行之法[35].
4.1 機器人路徑規劃與避障
移動機器人的路徑規劃是指在有障礙物的工作環境中,如何尋找一條從給定起點到終點的適當的運動路徑,使機器人在運動過程中能安全、無碰地繞過所有障礙物[61],一般可以歸結為面向路徑長度、所需時間、能量消耗等多目標的優化問題.
復雜環境下機器人路徑規劃是強化學習的主要應用領域之一.文獻[62]利用強化學習方法學習局部導航行為,通過矢量量化(vector quantization,VQ)來表示空間狀態的一般化方法,從而獲得多個體的狀態空間;文獻[63]基于迪科斯徹算法(Dijkstra's algorithm),設計了結合強化學習的多機器人最優路線算法;文獻[64]利用波爾茲曼(Boltzmann)分布與Q-學習方法的結合,Q-學習算法用來解決低維路徑規劃問題,玻耳茲曼策略采用統計概率和模擬退火法,避免多機器人的策略陷入局部最優并提供全局最優解,減少數量的探索和加快收斂的過程;文獻[65]結合波爾茲曼分布與基于動態規劃的Q-學習方法(QVDP),研究了多個體路徑規劃及延遲問題.
4.2 多機器人任務分解
多機器人任務分配(multi-robot task allocation,MRTA)是保證多機器人協調的重要因素,任務分配的好壞將直接影響整個多機器人系統協作的效率,并關系到每個機器人能否最大限度發揮自身的能力.
近年來,強化學習在多機器人任務分配的問題中也受到廣泛的關注.文獻[66]基于強化學習算法,提出一種智能合作控制框架,用于解決多個無人機(UAV)的任務分配問題;文獻[67]分析多衛星協同任務規劃問題的數學模型,提出了一種多衛星強化學習算法,引入了約束懲罰算子和多衛星聯合懲罰算子,對衛星個體原始的效用值增益函數進行改進,以求解多衛星協同任務分配策略;文獻[68]結合強化學習,設計了一種空置鏈調度(vacancy chain scheduling,VCS)的多機器人資源分配過程,依賴于優化配置模式來擺脫不直接機器人交互作用的影響;文獻[69]提出一種多個體的分布式并行多任務分配算法,每個個體先通過利益分享學習(profit sharing learning,PSL)方法進行學習,然后利用通訊和協商來分配每次任務的真實工作量.
4.3 機器人足球
機器人足球比賽是典型的開放式、分布式、動態的、實時的多機器人系統,其中涉及到的技術包括機器人學、機電一體化、多機器人協作、決策與對策、人工生命和傳感器數據融合等,是人工智能與機器人領域的應用基礎研究課題.本文主要從機器人的高層決策方面闡述強化學習的應用.
文獻[70]研究了基于動作預測的多個體強化學習算法,使用樸素貝葉斯分類器來預測其他個體的動作,并引入策略共享機制來交換多個體所學習的策略;文獻[71]使用重復Q-學習和經驗復用Sarsa算法進行了機器人足球守門員的實驗;文獻[72]通過策略梯度強化學習方法來尋找機器人足球賽中的最優策略;文獻[73]研究了強化學習在機器人足球賽中的決策機制,并利用分層的思想改進每個機器人的個體行為.對于大規模強化學習系統,通過融入恰當的知識(knowledge)和建議(advise),可以有效提高系統的學習效率.文獻[74-75]分別將基于知識的核回歸(knowledge basedkernelregression,KBKR)和優先級(preference KBKR)算法引入到強化學習系統中,并將其應用于機器人足球仿真比賽中.
4.4 多機器人追逃問題
多機器人追逃問題是多機器人系統的典型應用,在搜救和對抗領域有重要實用價值,常被用于評價多機器人協作方法的性能.
代表性的工作有:文獻[76]采用強化學習方法更新回報值并在追擊者間傳播,從而獲得最優捕獲時間;文獻[77]引入關聯規則數據挖掘方法進行任務分配,針對各逃逸者建立相應的追捕聯盟,降低了策略空間的復雜度,基于不同狀態下的獎勵差異提出了一種分段式強化學習方法,利用其作為已知環境下追捕問題的模型求解追捕聯盟的協作追捕策略;文獻[78]采用了基于模型的Rmax學習算法解決多機器人追逃問題;文獻[79]基于分層強化學習研究了多機器人追逃算法,將學習過程分解為高層與低層兩個階段,并設計學習機制以平衡兩個學習階段的值函數.
作者在前期工作中[80],假設了環境不確定性與機器人的局部觀測性,在DEC-POMDP框架下對多機器人追逃問題進行了數學描述,將其用8元組建模,并采用分布式濾波對逃逸者的運動狀態進行估計,在此基礎上更新追擊者的回報值和策略空間,再進行追擊決策.下一步研究會將通訊代價、追擊者信息可信度和回報值等因素統一到該模型中.
5 多機器人強化學習的前沿方向與挑戰
根據任務的具體特點,尋求適當的多機器人系統的學習、決策和控制方法,使其能夠在復雜環境中高效、可靠地完成給定任務,是多機器人系統研究所面臨的巨大挑戰和機遇.
5.1 分形學習
分形理論是非線性科學理論中的一個分支,用以描述復雜、混沌現象背后的規律性,揭示局部與整體之間的關系.分形理論認為,整體的復雜性遠遠大于部分,而分形中任何一個相對獨立的部分,在一定程度上都是整體的再現和相對縮影(分形元),人們可以通過認識部分來認識整體.分形學習(fractal learning)利用系統的自相似性,通過對數據集分形維數的計算,提取出相關規則、建立相應的模型,并為以后的行為提供指導,行為的反饋信息又可以用來修正更新規則或模型,進而使系統的性能不斷優化.如何將分形學習與多機器人相結合,以及如何突破分形學習的應用范圍約束以及簡化分形維數的計算等都還需要不斷地探索和完善[81].
5.2 模糊強化學習
模糊理論具有對復雜不精確知識較強的表達能力,以及對實際問題較好的處理能力,且易于先驗知識的加入,使之一直受到研究者的重視,并在實際中取得了廣泛應用.比如在復雜未知環境下,利用模糊強化學習的移動機器人導航應用等[82-84].但是,對多機器人的模糊強化學習研究還比較少見,在模糊不確定環境下,采用模糊理論可以使得多機器人獲得更多信息,為學習和決策過程提供更有彈性的空間,以便采取更加靈活的回報值和行動策略,提高學習效率.
5.3 定性強化學習
定性推理源于對物理現象的常識推理,是一種從物理系統的結構描述出發,導出行為描述和功能描述.定性推理可充分利用定性及不完全、不精確的信息來推理系統的定性行為,給出易于理解的行為描述和因果解釋,為信息不完全的復雜系統產生行為預測,便于先驗知識的加入,從而加快推理過程[85].文獻[86]通過建立系統的定性模型,提出一種基于定性模糊網絡的強化學習知識傳遞方法,并利用定性模糊網絡抽取基于定性動作的次優策略的共同特征獲得與系統參數無關知識.如何將定性推理應用于強化學習是一個誘人的研究方向,比如通過局部傳播在較高層次上給出系統的宏觀描述、結合灰色系統理論和定性推理構建灰色定性強化學習策略,以及從知識運用的角度論證強化學習理論的完備性等問題都需要深入研究[86].
5.4 遷移強化學習
遷移學習(transfer learning)考慮了任務之間的聯系,利用過去的學習經驗加速對于新任務的學習,可以分為行為遷移和知識遷移.行為遷移通常意味著將先前學到的策略或者某些公共的“子過程”用于新任務的學習,這一類技術側重于挖掘、利用不同任務的解決方案之間的相似性.知識遷移技術注重對任務本身的理解,并試圖學習解決問題的一般原理,因此知識遷移技術更多地涉及知識表示、規則提取等內容[87].文獻[88]利用拉普拉斯特征映射能保持狀態空間局部拓撲結構不變的特點,對基于譜圖理論的層次分解技術進行了改進,提出一種基函數與子任務最優策略相結合的強化學習混合遷移方法;文獻[89]提出了一種局部約束模型(partially constrained model,PCM)下的遷移學習方法,可以更好地處理狀態-行動策略.多機器人的遷移學習可以擴展傳統的強化學習方法,考慮如何將多個機器人間不同的學習任務相互關聯,以及獲得更多的知識表示、規則提取等內容,可以作為今后的研究方向.
5.5 結合信息融合的強化學習
結合信息融合,實現值函數估計的強化學習是一個新的研究方向.文獻[90-91]將卡爾曼濾波與TD算法結合起來,提出一種卡爾曼瞬時差分法(Kalman temporal different,KTD)算法,引入了一個值函數估計問題的狀態空間,通過卡爾曼濾波器融合值函數的近似過程;文獻[92]提出了基于Q-學習的KTD-Q學習算法和基于Sarsa算法的KTDSarsa算法,通過信息融合的強化學習算法,可以更好地處理在線學習、有效樣本、非定常性和非線性等問題.但噪聲模型的選擇與如何融入KTD模型,以及KTD如何由MDP擴展至POMDP依舊是一個開放性問題,而且在結合多機器人上的研究還比較少見,是一個值得深入探究的領域.
5.6 多目標強化學習
傳統的強化學習中,所有機器人都為達成一個共同目標而協作.多目標強化學習(multi objective reinforcement learning,MORL)考慮的是多個機器人在合作中,可能會面對兩個或兩個以上的目標,每個目標都有自己的回報值,目標間可能相關也可能沖突,需要研究學習任務間的協調與決策等問題[93].文獻[94]提出一種基于最大集合期望損失的多目標強化學習算法,在平衡各個目標的前提下選擇最佳聯合動作以產生最優聯合策略,并應用到機器人足球射門局部策略訓練中;文獻[95]利用MORL算法擴展了多個體蒙特卡羅樹型檢索(Monte-Carlo tree search)中的的連續決策問題.文獻[96]提出了一種新的多任務學習方法,通過學習潛在的形函數來獲取相關領域的知識,用人造回報來增大任務的回報函數.但是,多目標強化學習在使用非線性函數泛化時,依然存在算法不穩定、不收斂等問題,尚需深入研究.
6 結束語
多機器人的強化學習是一個年輕而充滿活力的研究領域,結合了博弈論和最優搜索等內容,涉及到多機器人的群體體系結構、感知與多傳感器信息融合、通信與協商、運動規劃、任務分配、沖突消解、系統實現等許多方面,為多機器人在缺少或只有局部先驗知識的情況下,解決非線性、隨機策略任務提供了一個有力的方法論和一系列算法.
本文簡要介紹了強化學習的基本思想與理論框架,對基于強化學習的多機器人研究現狀作了概述,以期促進相關研究.應當指出,強化學習的本質是一種試錯反應式的學習,并不能理解事物之間的因果聯系,更無法歸納出一般事物的發展規律.當前的研究重點在于對分布式強化學習的算法研究,但其在多機器人的合作應用尚不充分.在今后的發展中,仍然需要在理論和應用方面開展創新研究,增強機器人的分析、歸納、推測、任務分解等方面的學習能力,以此更好地理解多個機器人之間的關系,使其協作更加緊密,結構信度分配更加合理,從而達到更高的智能層次.
[1] MURRAY R M,ASTROM K M,BODY S P,et al.Future directions in control in an information-rich world[J].IEEE Control Systems Magazine,2003,23(2):20-23.
[2] 陳學松,楊宜民.強化學習研究綜述[J].計算機應用研究,2010,27(8):2834-2844.CHENXuesong,YANGYimin.Reinforcement learning:surveyofrecentwork[J].Application Research of Computers,2010,27(8):2834-2844.
[3] WIERING M,OTTERLO M V.Reinforcement learning state-of-the-art[M].Berlin:Springer-Verlag,2012:3-42.[4] SUTTON R S.Learning to predict by the methods of temporal differences[J].Machine Learning,1988,3(1):9-44.
[5] CHEN Xingguo,GAO Yang,WANG Ruili.Online selective kernel-based temporal difference learning[J].IEEE Transactions on Neural Networks and Learning Systems,2013,24(12):1944-1956.
[6] ZOU Bin,ZHANG Hai,XU Zongben.Learning from uniformlyergodicMarkovchains[J].Journalof Complexity,2009,25(2):188-200.
[7] YU Huizhen,BERTSEKAS D P.Convergence results for some temporal difference methods based on least squares[J].IEEE Transactions on Automatic Control,2009,54(7):1515-1531.
[8] WATKINS C,DAYAN P.Q-learning[J].Machine Learning,1992,8(3):279-292.
[9] 沈晶,程曉北,劉海波,等.動態環境中的分層強化學習[J].控制理論與應用,2008,25(1):71-74.SHEN Jing,CHENG Xiaobei,LIU Haibo,et al.Hierarchicalreinforcementlearningindynamic environment[J].Control Theory&Applications,2008,25(1):71-74
[10] 王雪松,田西蘭,程玉虎.基于協同最小二乘支持向量機的Q學習[J].自動化學報,2009,35(2):214-219.WANG Xuesong,TIAN Xilan,CHENG Yuhu.Q-learning system based on cooperative least squares support vector machine[J].Acta Automatica Sinica,2009,35(2):214-219.
[11] 朱美強,李明,程玉虎,等.基于拉普拉斯特征映射的啟發式Q學習[J].控制與決策,2014,29(3):425-430.ZHU Meiqiang,LI Ming,CHENG Yuhu,et al.Heuristically accelerated Q-learning algorithm based on Laplacian eigenmap[J].Control and Decision,2014,29(3):425-430.
[12] CHEN Chunlin,DONG Daoyi,LI Hanxiong.Fidelitybased probabilistic Q-learning for control of quantum systems[J].IEEE Transactions on Neural Networks and Learning Systems,2014,25(5):920-933.
[13] RUMMERY G,NIRANJAN M.On-line Q-learning using connectionist systems[D].Cambridge:University of Cambridge,1994.
[14] BARTO A G,SUTTON R S,ANDERSON C W.Neuronlike adaptive elements that can solve difficult learning control problems[J].IEEE Transactions on Systems,Man and Cybernetics,1983,13(5):834-846.
[15] LIN C T,LEE C S G.Reinforcement structure/parameter learning for neural-network based fuzzy logic controlsystem[J].IEEETransactionsonFuzzy System,2008,2(1):46-63.
[16] BERNSTEIN D S,GIVAN R.The complexity of decentralized control of Markov decision processes[J].Mathematics of operations Research,2002,27(4):819-840.
[17] CRITES R H,BARTO A G.Elevator group control usingmultiplereinforcementlearningagents[J].Machine Learning,1998,33(2/3):235-262.
[18] KIM G H,LEE C S G.Genetic reinforcement learning approach to the heterogeneous machine scheduling problem[J].IEEETransactionsonRoboticsand Automation,1998,14(6):879-893.
[19] 劉全,楊旭東,荊玲,等.基于多Agent并行采樣和學習經驗復用的E~3算法[J].吉林大學學報:工學版,2013,43(1):135-140.LIU Quan,YANG Xudong,JING Ling,et al.Optimalcontrol of a class of nonlinear dynamic systems based onreinforcementlearning[J].JournalofJilin University:EngineeringandTechnologyEdition,2013,43(1):135-140.
[20] KAR S,MOURA J M F,POOR H V.QD-Learning:a collaborativedistributedstrategyformulti-agent reinforcementlearningthroughconsensusplus innovations[J].IEEETransactionsonSignal Processing,2013,61(7):1848-1862.
[21] 吳軍,徐昕,連傳強,等.采用核增強學習方法的多機器人編隊控制[J].機器人,2011,33(3):379-384.WU Jun,XU Xin,LIAN Chuanqiang,et al.Multirobot formation control with kernel-based reinforcement learning[J].Robot,2011,33(3):379-384.
[22] FANG M,GROEN F C A,LI H.Collaborative multiagentreinforcementlearningbasedonanovel coordination tree frame with dynamic partition[J].EngineeringApplicationsofArtificialIntelligence,2014,27:191-198.
[23] BOWLING M,Multi agent learning in the presence of agentswithlimitations[D].Pittsburgh:Carnegie Mellon University,2003.
[24] CAI Yifan,YANG Simon X,XU Xin.A hierarchical reinforcement learning-based approach to multi-robot cooperationfortargetsearchinginunknown environments[J].Control and Intelligent Systems,2013,41(4):218-30.
[25] DICKENS L,BRODA K,RUSSO A.The dynamics of multi-agentreinforcementlearning[C]∥In19th EuropeanConferenceonArtificialIntelligence(ECAI).Lisbon:Univ Lisbon,FacSci,2010:367-372.
[26] 徐昕,沈棟,高巖青,等.基于馬氏決策過程模型的動態系統學習控制:研究前沿與展望[J].自動化學報,2012,38(5):673-687.XU Xin,SHEN Dong,GAO Yanqing,et al.Learning control of dynamical systems based on Markov decision processes:research frontiers and outlooks[J].Acta Automatica Sinica,2012,38(5):673-687.
[27] 沈晶,劉海波,張汝波,等.基于半馬爾可夫對策的多機器人分層強化學習[J].山東大學學報:工學版,2010,40(4):1-7.SHEN Jing,LIU Haibo,ZHANG Rubo,et al.Multirobot hierarchical reinforcement learning based on semi-Markovgames[J].JournalofShandong University:Engineering Science,2010,40(4):1-7.
[28] GHAVAMZADEH M,MAHADEVAN S.Hierarchical average reward reinforcement learning[J].Journal of Machine Learning Research,2007,8:2629-2669.
[29] ZUO Lei,XU Xin,LIU Chunming.A hierarchical reinforcementlearningapproachforoptimalpath tracking of wheeled mobile robots[J].Neural Computing&Applications,2013,23(7/8):1873-1883.
[30] KAWANO H.Hierarchical sub-task decomposition for reinforcementlearningofmulti-robotdelivery mission[C]∥In IEEE International Conference on Robotics and Automation(ICRA).Karlsruhe:IEEE,2013:828-835
[31] SUN Xueqing,MAO Tao,LAURA R.Hierarchical stateabstracted and socially augmented Q-Learning for reducingcomplexityinagent-basedlearning[J].Journal of Control Theory and Applications,2011,9(3):440-50.
[32] SINGH SP,JAAKOLAT,JORDANMI.Reinforcement learning with soft state aggregation[M].Cambridge:MIT Press,1995:361-368.
[33] MORIARTY D,SCHULTZ A,GREFENSTETTE J.Evolutionary algorithms for reinforcement learning[J].Journal of Artificial IntelligenceResearch,1999,11(1):241-276.
[34] BERTSEKAS D P,TSITSIKLIS J N.Neuro-dynamic programming[M].Belmont:Athena Scientific,1996:107-109.
[35] PALLOTTINO L,VINCENZO G S,BICCHIA.Decentralized cooperative policy for conflict resolution in multivehicle systems[J].IEEE Transactions on Robotics,2007,23(6):1170-1183.
[36] ZHANG Wenxu,CHEN Xiaolong,MA Lei.Online planningformulti-agentsystemswithconsensus protocol[C]∥In 33nd Chinese Control Conference.Nanjing:IEEE,2014:1126-1131.
[37] 陳學松,劉富春.一類非線性動態系統基于強化學習的最優控制[J].控制與決策,2013,28(12):1889-1893.CHEN Xuesong,LIU Fuchun.Optimal control of a classofnonlineardynamicsystemsbased onreinforcement learning[J].Control and Decision,2013,28(12):1889-1893.
[38] XIEMengchun.Representationoftheperceived environment and acquisition of behavior rule for multiagent systems by Q-learning[C]∥In 4th International ConferenceonAutonomousRobotsandAgents.Wellington:Inst of Elec and Elec Eng,2009:453-457.
[39] REINALDO A C B,MARTINS M F,RIBEIRO C H C.Heuristically accelerated multi agent reinforcementlearning[J].IEEETransactionsonCybernetics,2014,44(2):252-265.
[40] K-LIN L J.Self-improving reactive agents based on reinforcement learning,planning and teaching[J].Machine Learning,1992,8(3/4):293-321.
[41] MODARES H,LEWIS F L,NAGHIBI-SISTANI M B.Integral reinforcement learning and experience replay foradaptiveoptimalcontrolofpartially-unknown constrained-inputcontinuous-timesystems[J].Automatica,2014,50(1):193-202.
[42] 蔡自興,任孝平,鄒磊.分布式多機器人通信仿真系統[J].智能系統學報,2009,4(4):309-313.CAI Zixing,REN Xiaoping,ZOU Lei.A simulated communications system for distributed multi robots[J].CAAI Transactions on Intelligent Systems,2009,4(4):309-313.
[43] MARAVALL D,JAVIER D L,DOMINGUEZ R.Coordination of communication in robot teams by reinforcement learning[J].Robotics and Autonomous Systems,2013,61(7):661-666.
[44] 馬磊,史習智.多智能體系統中一致性卡爾曼濾波的研究進展[J].西南交通大學學報,2011,46(2):287-293.MA Lei,SHI Xizhi.Recent development on consensusbased Kalman filtering in multi-agent systems[J].JournalofSouthwestJiaotongUniversity,2011,46(2):287-293.
[45] YILIN M,BRUNO S.Communication complexity and energy efficient consensus algorithm[C]∥2nd IFAC Workshop on Distributed Estimation and Control in Networked Systems.Annecy:The IFAC Secretariat,2010:209-214
[46] KOWALSKI D R,GILBERT S.Distributed agreement withoptimalcommunicationcomplexity[C]∥Proceedings of the 21st Annual ACM-SIAM Symposium onDiscreteAlgorithms.Austin:Associationfor Computing Machinery,2010:965-977.
[47] DWORMAN G,KIMBROUGH S O,LAING J D.Bargaining by artificial agents in two coalition games:a studyingeneticprogrammingforelectronic commerce[C]∥Proceedings of Genetic Programming 1996 Conference.Stanford:MIT Press,1996:54-62.
[48] NUNES L,OLIVEIRA E.Cooperative learning using advice exchange[J].Adaptive Agents and Multi-Agent Systems,2003,2636:33-48.
[49] 柯文德,洪炳镕,崔剛,等.一種基于π-MaxQ學習的多機器人協作方法[J].智能計算機與應用,2013,3(3):13-17. KE Wende,HONG Bingrong,CUI Gang,et al.A cooperative method for multi robots based on π-MaxQ[J].Intelligent Computer and Applications,2013,3(3):13-17.
[50] JOB J,JOVIC F,LIVADA C.Q-learning by the nth step state and multi-agent negotiation in unknown environment[J].Tehnicki Vjesnik-Technical Gazette,2012,19(3):529-534.
[51] HOLLANDJ H.Properties of the bucket brigade[C]∥Proceedings of the 1st International Conference on Genetic Algorithms.Berlin:Springer-Verlag,1985:1-7.
[52] CHAPMAN K L,BAY J S.Task decomposition and dynamic policy merging in the distributed Q-learning classifiersystem[C]∥ProceedingsofIEEE International Symposium on Computational Intelligence in Robotics and Automation,CIRA.Monterey:IEEE Computer Society,1997:166-171.
[53] ONO N,IKEDA O,FUKUMOTO K.Acquisition of coordinatedbehaviorbymodularQ-learning agents[J].IEEEInternationalConferenceon Intelligent Robots and Systems,1996,3:1525-1529.
[54] BAY J S,STANHOPE J D.Distributed optimization of tacticalactionsbymobileintelligentagents[J].Journal of Robotic Systems,1997,14(4):313-323.
[55] RAEISY B,HAGHIGHI S G,SAFAVI A A.Active noisecontrolsystemviamulti-agentcredit assignment[J].JournalofIntelligent&Fuzzy Systems,2014,26(2):1051-1063.
[56] ZAHRA R,HAMID B.Addition of learning to critic agent as a solution to the multi-agent credit assignment problem[C]∥5th International Conference on Soft Computing,Computing with Words and Perceptions in System Analysis,Decision and Control.Famagusta:IEEE Computer Society,2009:219-222.
[57] NG A Y,RUSSELL S J.Algorithms for inverse reinforcement learning[C]∥Proceedings of the 17th International Conference on Machine Learning.San Francisco:Morgan Kaufmann,2000:663-670.
[58] RAMACHANDRAN D,AMIR E.Bayesian inversereinforcement learning[C]∥Proceedings of the 20th InternationalJointConferenceonArtificial Intelligence.Hyderabad:IJCAI,2007:2586-2591.
[59] MICHINB,JONATHANPH.Improvingthe efficiencyofbayesianinversereinforcement learning[C]∥IEEEInternationalConferenceon Robotics and Automation(ICRA).St Paul:IEEE,2012:3651-3656.
[60] 張長水.機器學習面臨的挑戰[J].中國科學:信息科學,2013,43(12):1612-1623.ZHANG Changshu.Challenges in machine learning[J].ScientiaSinica:Informationis,2013,43(12):1612-1623.
[61] 席裕庚,張純剛.一類動態不確定環境下機器人滾動路徑規劃[J].自動化學報,2002,25(2):261-175.XI Yugeng,ZHANG Chungang.Rolling path planning of mobile robot in a kind of dynamic uncertain environment[J].Acta Automatica Sinica,2002,25(2):261-175.
[62] MARTINEZ-GIL F,LOZANO M,FERNANDEZ F.Multi-agentreinforcementlearningforsimulating pedestrian navigation[C]∥In Adaptive and Learning Agents,International Workshop.Berlin:Springer-Verlag,2011,7113:54-69.
[63] ROKHLO M Z,ALI S,HASHIM M,et al.Multiagentreinforcementlearningforrouteguidance system[J].International Journal of Advancements in Computing Technology,2011,3(6):224-232.
[64] WANGZeying,SHIZhiguo,LIYuankai.The optimization of path planning for multi-robot system usingBoltzmannPolicybasedQ-learning algorithm[C]∥In IEEE International Conference on RoboticsandBiomimetics(ROBIO).Shenzhen:IEEE,2013:1199-204.
[65] MORTAZA Z A,ALI S,HASHIM S Z.Mohd,modeling of route planning system based on Q valuebaseddynamicprogrammingwithmulti-agent reinforcementlearningalgorithms[J].Engineering Applications of Artificial Intelligence,2014(29):163-177.
[66] GERAMIFARDA,REDDINGJ,HOWJP.Intelligentcooperativecontrolarchitecture:a framework for performance improvement using safe learning[J].Journal of Intelligent&Robotic Systems,2013,72(1):83-103.
[67] 王沖,景寧,李軍,等.一種基于多Agent強化學習的多星協同任務規劃算法[J].國防科技大學學報,2011,33(1):53-58.WANG Chong,JING Ning,LI Jun,et al.An algorithm of cooperative multiple satellites mission planning based on multi-agent reinforcement learning[J].JournalofNationalUniversityofDefense Technology,2011,33(1):53-58.
[68] DAHL T S,MATARIC M,SUKHATME G S.Multirobottaskallocationthroughvacancychain scheduling[J].Robotics and Autonomous Systems, 2009,57(6/7):674-687.
[69] SU Zhaopin,JIANG Jianguo,LIANG Changyong,et al.A distributed algorithm for parallel multi-task allocation based on profit sharing learning[J].Acta Automatica Sinica,2011,37(7):865-872.
[70] 段勇,崔寶俠,徐心和.多智能體強化學習及其在足球機器人角色分配中的應用[J].控制理論與應用,2009,26(4):371-376.DUAN Yong,CUI Baoxia,XU Xinhe.Multi-agent reinforcementlearninganditsapplicationtorole assignment of robot soccer[J].Control Theory&Applications,2009,26(4):371-376.
[71] ADAM S,LUCIAN B,BABU?KA R.Experience replay for real-time reinforcement learning control[J].IEEE Transactions on Systems,Man and Cybernetics Part C:Applications and Reviews,2012,42(2):201-212.
[72] MARTINR,THOMASG,ROLANDH.Reinforcementlearningforrobotsoccer[J].Autonomous Robots,2009,27(1):55-73.
[73] HWANG K S,CHEN Y J,LEE C H.Reinforcement learning in strategy selection for a coordinated multirobot system[J].IEEE Transactions On Systems Man and Cybernetics Part A Systems and Humans,2007,37(6):1151-1157.
[74] OLVI L M,SHAVLIK J W,EDWARD W W.Knowledgebasedkernelapproximation[J].The Journal of Machine Learning Research Archive,2004,5:1127-1141.
[75] RICHARD M,JUDE S,LISA T,et al.Giving advice about preferred actions to reinforcement learners via knowledge-based kernel regression[C]∥Proceedings ofthe20thNationalConferenceonArtificial Intelligence.Pittsburgh:AmericanAssociationfor Artificial Intelligence,2005:819-824.
[76] KWAK D J,KIM H J.Policy improvements for probabilisticpursuit-evasiongame[J].Journalof Intelligent&Robotic Systems,2013,74(3/4):709-724.
[77] LIJun,PANQishu,HONGBingrong.Anew approach of multi-robot cooperative pursuit based on association rule data mining[J].International Journal of Advanced Robotic Systems,2009,6(4):329-336.
[78] BOUZY B,M TIVIER M.Multi-agent model-based reinforcement learningexperimentsinthepursuit evasion game[D].Paris:Paris Descartes University,2008.
[79] LIU Shuhua,LIU Jie,CHENG Yu.A pursuit-evasionalgorithmbasedonhierarchicalreinforcement learning[J].Information:AnInternationalInterdisciplinary Journal,2010,13(3):635-645.
[80] ZHANG Wenxu,CHEN Xionglong,MA Lei.Multiagentsystempursuitwithdecision-makingand formationcontrol[C]∥32ndChineseControl Conference,Xi'an:IEEE,2013:7016-7022.
[81] 倪志偉,胡湯磊,吳曉璇,等.基于分形理論的一種新的機器學習方法:分形學習[J].中國科學技術大學學報,2013,43(4):265-270.NI Zhiwei,HU Tanglei,WU Xiaoxuan,et al.A novel machine learning approach based on fractal theory:Fractal learning[J].Journal of University of Science and Technology of China,2013,43(4):265-270.
[82] 陳衛東,朱奇光.基于模糊算法的移動機器人路徑規劃[J].電子學報,2011,39(4):971-974.CHEN Weidong,ZHU Qiguang.Mobile robot path planningbasedonfuzzyalgorithms[J].Acta Electronica Sinica,2011,39(4):971-974.
[83] JUANG C F,HSU C H.Reinforcement ant optimized fuzzy controller for mobile-robot wall-following control[J].IEEE Transactions on Industrial Electronics,56(10):3931-3940,2009
[84] 徐明亮,柴志雷,須文波.移動機器人模糊Q-學習沿墻導航[J].電機與控制學報,2010,14(6):83-88.XU Mingliang,CHAI Zhilei,XU Wenbo.Wallfollowing control of a mobile robot with fuzzy Q-learning[J].Electric Machines and Control,2010,14(6):83-88.
[85] 陳宗海,楊志華,王海波,等.從知識的表達和運用綜述強化學習研究[J].控制與決策,2008,23(9):961-968.CHEN Zonghai,YANG Zhihua,WANG Haibo,et al.Overview of reinforcement learning from knowledge expression and handling[J].Control and Decision,2008,23(9):961-968.
[86] 黃晗文,鄭宇.強化學習中基于定性模型的知識傳遞方法[J].計算機工程與科學,2011,33(6):118-124.HUANG Hanwen,ZHENG Yu.Knowledge transfer method based on the qualitative model in reinforcement learning[J].Computer Engineering&Science,2011,33(6):118-124.
[87] 王皓,高陽,陳興國.強化學習中的遷移:方法和進展[J].電子學報,2008,36(12A):39-43.WANG Hao,GAO Yang,CHEN Xingguo.Transfer of reinforcement learning:the state of the art[J].Acta Electronica Sinica,2008,36(12A):39-43.
[88] 朱美強,程玉虎,李明,等.一類基于譜方法的強化學習混合遷移算法[J].自動化學報,2012,38(11):1765-1776.ZHU Meiqiang,CHENG Yuhu,LI Ming,et al.A hybrid transfer algorithm for reinforcement learning based on spectral method[J].Acta Automatica Sinica,2012,38(11):1765-1776.
[89] BORJA F G,JOSE M L G,MANUEL G.Transfer learning with partially constrained models:application to reinforcement learning of linked multicomponent robot system control[J].Robotics and Autonomous Systems,2013,61(7):694-703.
[90] GEISTM,PIETQUINO.Kalmantemporal differences[J].JournalofArtificialIntelligence Research,2010,39:483-532.
[91] PIETQUIN O,GEIST M,CHANDRAMOHAN S,et al.Sampleefficienton-linelearningofoptimal dialoguepolicieswithKalmantemporal differences[C]∥InternationalJointConferenceon ArtificialIntelligence(IJCAI).Barcelona:InternationalJointConferencesonArtificial Intelligence,2011:1878-1883.
[92] GEIST M,PIETQUIN O.Revisiting natural actorcritics with value function approximation[J].Modeling Decisions for Artificial Intelligence,2010,6408:207-218.
[93] FERREIRA L A,COSTA R,CARLOS H,et al.Heuristicallyacceleratedreinforcementlearning modularization for multi-agent multi-objective problems[J].Applied Intelligence,2014,41(2):551-562.
[94] 劉全,李瑾,傅啟明,等.一種最大集合期望損失的多目標Sarsa(λ)算法[J].電子學報,2013,41(8):1469-1473.LIU Quan,LI Jin,FU Qiming,et al,A multiple-goal Sarsa(λ)algorithm based on lost reward of greatest mass[J].Acta Electronica Sinica,2013,41(8):1469-1473.
[95] WANG Weijia,SEBAG M.Hypervolume indicator and dominance reward based multi-objective Monte-Carlo tree search[J].Machine Learning,2013,93(2/3):403-29.
[96] SNEL M,WHITESON S.Learning potential functions and their representations for multi-task reinforcement learning[J].AutonomousAgentsandMulti-Agent Systems,2014,28(4):637-681.
(中文編輯:唐 晴 英文編輯:周 堯)
A Review of Developments in Reinforcement Learning for Multi-robot Systems
MA Lei, ZHANG Wenxu, DAI Chaohua
(School of Electrical Engineering,Southwest Jiaotong University,Chengdu 610031,China)
Reinforcement learning(RL)is an effective mean for multi-robot systems to adapt to complex and uncertain environments.It is considered as one of the key technologies in designing intelligent systems.Based on the basic ideas and theoretical framework of reinforcement learning,main challenges such as partial observation,computational complexity and convergence were focused.The state of the art and difficulties were summarized in terms of communication issues,cooperative learning,credit assignment and interpretability.Applications in path planning and obstacle avoidance,unmanned aerial vehicles,robot football,the multi-robot pursuit-evasion problem,etc.,were introduced.Finally,the frontier technologies such as qualitative RL,fractal RL and information fusion RL,were discussed to track its future development.
multi-robot systems;reinforcement learning;Markov decision process;computational complexity;uncertainties
TP181
:A
0258-2724(2014)06-1032-13
10.3969/j.issn.0258-2724.2014.06.015
2014-05-28
國家自然科學基金資助項目(61075104)
馬磊(1972-),男,教授,博士,研究方向為控制理論及其在機器人、新能源和軌道交通系統中的應用,
E-mail:malei@swjtu.edu.cn
馬磊,張文旭,戴朝華.多機器人系統強化學習研究綜述[J].西南交通大學學報,2014,49(6):1032-1044.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
家庭影院技術(2017年9期)2017-09-26 03:41:45
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
