基于GLR算法的英語長難句句法分析的探討
2015-02-20 08:07:23鄭燕娥鄭志明
安陽師范學院學報 2015年2期
鄭燕娥,鄭志明
(1.仰恩大學 工程技術學院, 福建 泉州 362014; 2. 湄洲灣職業技術學院, 福建 莆田 351254)
?
基于GLR算法的英語長難句句法分析的探討
鄭燕娥1,鄭志明2
(1.仰恩大學 工程技術學院, 福建 泉州 362014; 2. 湄洲灣職業技術學院, 福建 莆田 351254)
[摘要]英語長難句是英漢翻譯的一大障礙點,其復雜結構的有效識別和分析直接關系到英漢翻譯質量。基于此,對英語長難句的句法分析技術進行研究,提出基于GLR算法的長難句拆分策略。將長難句拆分為不同層次的片斷,利用GLR算法識別與分析各片斷中的簡單短語,提煉出句子的主干結構,為生成譯文做好鋪墊;同時對錯誤拆分的情形進行糾正,從而有效提高了句法分析的合理性。 實驗結果表明,該拆分策略在長難句的句子結果拆分上具有較好的合理性。
[關鍵詞]長難句拆分策略;GLR算法;句法分析
引言
當前兩大主流的句法分析技術為短語句法分析和依存句法分析。前者以短語結構分析為主,后者側重于分析句子成分構成以及各句子成分之間的依存關系。歸結起來,句法分析的重點在于詞法、結構消歧和分析句子成分構成、上下文關系等。英語長難句分析的難點是如何確定句子主干結構以及各修飾成分間的關系,而解決問題的最佳方法是對長難句進行拆分,拆分后的片斷長度變短且各片斷結構相對簡單,為長難句句法分析提供了有利條件。
本文采用基于GLR算法的長難句拆分策略進行句法分析,其基本思想為:(1)對句子進行詞性標注。(2)依據語言學知識,確定并列連詞、從句引導詞以及相應的標點符號為拆分點,精簡句子成分,將包含了拆分點但不應該被拆分的句子成分進行合并,然后對合并后的句子成分進行詞性重新標注。(3)依據剩余的拆分點將長難句拆分為不同層次的片斷,多片斷并行操作有利于提高英漢翻譯的執行效率。(4)利用GLR算法對各片斷中的簡單短語進行識別與分析,確定短語的中心詞,提煉出句子的主干結構,為生成譯文做好鋪墊。(5)用正則表達式匹配已歸類的錯誤情形,對錯誤拆分進行糾正,有效提高了句法分析的合理性。
1詞性標注
詞性也稱為詞類,在很大程度上能夠反映句子的結構。詞性標注就是判定句子中每個詞的語法范疇、確定其詞性并進行恰當標記的行為[1]。詞性標注對長難句拆分時準確把握句子的結構發揮了重要作用。下面是利用斯坦福大學研發的詞性標注工具對一個長句(Eg1)中每個詞進行詞性標注后得到的形式:
Eg1: In_IN the_DE online_JJ classroom_NN,_, people_NN communicate_VB with_IN each_PRP other_PRP mainly_RB?by_IN writing_VBG and_IN voice_NN chat_NN,_,?but_CC it_RPP$is_VB very_RB important_JJ that_WDT students_NN have_VB no_JJ difficulty_NN using_VBG writing_NN to_IN express_VB their_PRP opinions_NNS._.
其中單詞后面緊跟以“_”起始的大寫字母組合便是對應單詞的詞性,詞性標注前預先進行詞性編碼,詞性編碼如下所示。
介詞——IN 連詞——CC 引導詞——WDT 定冠詞——DE
名詞——NN、NNS(名詞單復數)、NNR、NNRS(專有名詞單復數)
形容詞——JJ、JJR(比較級)、JJS(最高級)
副詞——RB、RBR(比較級)、RBS(最高級)
動詞——VB、VBD(過去式)、VBN(過去分詞)、VBG(現在分詞)、
VBZ(一般現在時第三人稱)、VBP(一般現在時非第三人稱)
代詞——PRP(人稱代詞)、PRP$(物主代詞)
2合并不應該被拆分的句子成分
根據語言學知識,將拆分點大致分為三大類:標點符號、并列連詞和從句引導詞。標點符號主要包含逗號、冒號、分號,但句號、括號、引號、問號、感嘆號除外;并列連詞指的是表示并列、轉折、選擇、因果等關系的單連詞或復合連詞,如but、or、so that等;從句引導詞如which、in which、that等。對包含拆分點但不應該被拆分的固定搭配詞組以及簡單短語(比如名詞性短語、形容性短語、動副短語等),采用正則表達式與相應的模式庫進行模式匹配,如果匹配,則將相應成分合并為僅帶一個詞性的“詞”,實現簡化句子結構和減少誤拆。下面是某個句子的部分成分合并后的形式:
such|as_COM milk,|bread,|card|and|flower_NN
其中as可作連詞,屬于拆分點,那么such as之間有可能被拆分,milk,bread,card and flower 也包含了拆分點(逗號和連詞and),也有可能被拆分,由于such as是固定搭配、用逗號和and連接的幾個名詞是名詞性短語不應該被拆分,所以將他們分別合并為一個詞,COM和NN為他們合并后的詞性。
3句子拆分
經過初步處理影響拆分合理性的一些因素,依據剩余的拆分點將長難句拆分為不同層次的片斷。表示邏輯關系的并列連詞拆分得到的片斷的層次級別比從句引導詞高,對于從句中包含子從句,則依據句子邏輯順序劃分相應的子層,多片斷并行操作有利于提高英漢翻譯的執行效率,然而拆分后的片斷不能保證都滿足合理性要求。例如,Eg1例子經初步合并成分后按剩余拆分點可劃分為6個片斷,其中片斷④是誤拆,因為and可連接兩個并列句子或并列詞組,如果連接的是兩個并列詞組,則不應當被拆分。句子拆分的層次結構圖如圖1所示。
4短語識別與分析——GLR算法
GLR算法是一種擴充的LR分析算法,引入圖棧和分析森林有效解決了LR算法無法處理的歧義問題,而且其分析速度較快,在簡單句法分析上具有很大的優勢。
本文利用GLR算法對各片斷中的簡單短語進行識別與分析,簡單短語一般是以名詞相關的短語或動詞性短語為主,因而構造兩個多出口的分析表分別用于分析這兩大類短語,通過引入符號映射實現短語邊界的自動識別,確定短語的中心詞,提煉出句子的主干結構,為生成譯文做好鋪墊。
GLR算法基于擴充的上下文無關文法[2],是一個五元式 G= (VT,VN,VF,P,S),其中VT為非空有限終結符集;VN為非空有限非終結符集,且VT與VN的交集為空;VF為約束函數集,是一個非空有限集,只有當條件滿足時才能用產生式進行規約;P為產生式集,且P→
GLR算法分析的步驟[3]如下:
(1)初始化。狀態O入棧,分析指針指向待分析的輸入符號,清除終止標志。
(2)符號映射。如果沒有終止標志,利用映射函數將當前輸入符號映射為分析表終止符。
(3)查ACTION表判定下一個動作將執行哪種操作:
①如果是移進,則將當前狀態及當前符號入棧,分析指針下移;
②如果是規約,則調用約束函數檢查是否滿足規約條件,若條件滿足,則構造從符號棧彈出的節點所組成的句法樹,并將其壓入符號棧,然后將狀態棧中的各中間狀態彈出,通過查看GOTO表,將新狀態壓入狀態棧,同時將中心詞指針指向相應的中心詞,若條件不滿足,則設置終止標志;
③如果是終止,指的是指針對分析表終結符的“報錯”,不屬于分析失敗,把當前輸入字符重新映射到分析表終止符后繼續分析,然后設置終止標志;
④如果是接受,則可識別的短語完成分析,將符號棧頂句法樹彈出,返回;⑤如果是出錯,指的是指針對分析表終止符的“報錯“,屬于分析失敗,恢復初始狀態,返回;
(4)依次繼續執行下一個動作,直到分析結束。
5糾正錯誤拆分
長難句的錯誤拆分主要歸因于片斷邊界的錯誤識別,通常出現在標點符號處、and或or處、連接詞處、從句右邊界處。本文通過對錯誤情形的分析和歸類,選定6個語言學特征作為判定的依據,它們分別為:句子的長短、是否以標點結尾、是否以 and 或 or 起始、是否含有謂語動詞、是否以連詞起始、是否以引導詞起始。如果符合錯誤拆分的情形,則將相應的片斷進行合并,實現了錯誤拆分的糾正,進而提高句法分析的合理性。 錯誤拆分部分情形如表1所示。
表1錯誤拆分部分情形及糾正方法
6實驗結果分析
為驗證拆分策略的有效性,本文利用Java語言編寫測試代碼,建立詞庫,該詞庫中包含了5張表,分別用于存儲四六級單詞、固定搭配、拆分點、名詞性相關短語、動詞性短語。從新視野大學英語讀寫教程第一冊課本中挑選100個長難句進行測試,分別將成分合并、拆分得到的片斷、錯誤拆分糾正、句子主干結構等信息輸出。通過分析與統計,得到實驗結果如表2所示。
其中識別總數為利用正則表達式進行詞庫匹配得到的全部的句子成分的數量,實際存在數為長難句中實際存在的句子成分的數量,正確識別數為程序正確識別出的句子成分的數量;正確率=正確識別數/識別總數*100%,召回率=正確識別數/實際存在數*100%。實驗結果表明,基于GLR的拆分策略在長難句的句子結構拆分上具有較好的合理性。
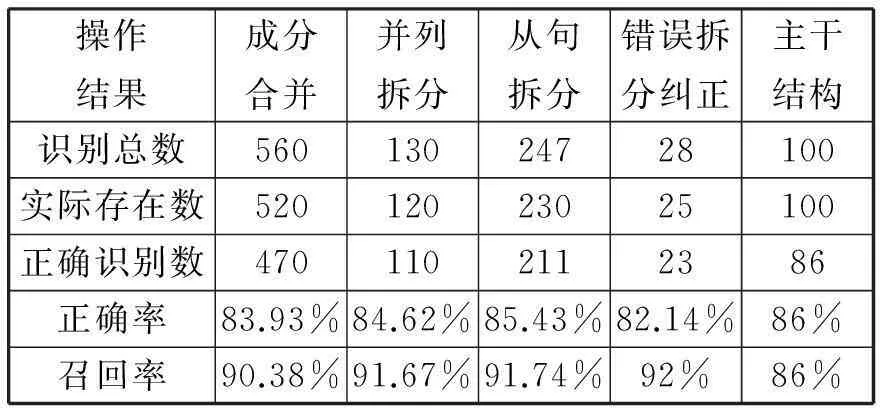
表2 實驗結果
7結語
本文主要針對長難句復雜結構進行簡化分析,利用GLR算法對片斷中的短語進行識別和分析,確定其中心詞,為生成譯文做好鋪墊,同時對錯誤拆分的情形進行糾正,能夠提高句法分析的合理性,為譯文生成合理框架提供借鑒。英漢句式結構存在差異[4],因而規定符合漢語表達習慣的譯文規則極其關鍵,今后會將對長難句生成譯文規則進行深入研究,進一步完善句法分析的形式化理論體系。
[參考文獻]
[1]左軍軍.英漢機器翻譯中長句分析技術的研究[D].遼寧:沈陽航空航天大學,2013.
[2]朱敬國,吐爾根-依布拉音,張路等.基于GLR算法的維吾爾語句法分析研究[J].現代計算機,2011(4):19-22.
[3]郭永輝,吳保民,王炳錫.一個基于GLR算法的英漢機器翻譯淺層句法分析器[J].計算機工程與應用,2004(34):124-129.
[4]支風寧.英漢句式結構對比[J].外語研究,2012(2):305-306.
[責任編輯:D]
English Long Sentence Syntactic Analysis based on GLR Algorithm
ZHENG Yan-e1, ZHENG Zhi-ming2
(1.YangEn University, Quanzhou 362014,China;
2.MeiZhouWan Vocational Technology College, Putian 351254,China)
Abstract:English long sentence is a big obstacle point in English Chinese translation,the effective identification and analysis of its complex structure directly related to the quality of English Chinese translation. Based on this,this paper researches on the syntax analysis technology of English long sentence, and proposes long sentence split strategy based on GLR algorithm. Long sentence will be split into different levels of fragments,and it uses GLR algorithm to identify and analyze the simple phrases in each fragment and then extracts the main sentence structure, paves the way for the target language generation;At the same time it corrects the cases of error split, so it effectively improves the rationality of syntactic analysis.The experimental results show that, the split strategy in long sentence structure split has better rationality.
Key words:long sentence splitting strategy;GLR algorithm;syntax analysis
[中圖分類號]TP391.1
[文獻標識碼]A
[文章編號]1671-5330(2015)02-0032-04
[作者簡介]鄭燕娥(1981—),女,福建仙游人,講師,主要從事數據庫與數據挖掘、智能算法研究。
[基金項目]2013年度仰恩大學科研培育計劃項目課題(KJ20143009)
[收稿日期]2015-02-25
