神經網絡和模板匹配在自動打分系統中的應用
2015-02-24 05:14:26徐富新黃玉秀
計算機工程與應用 2015年5期
徐富新,王 晶,黃玉秀,王 洲
中南大學 物理與電子學院,長沙 410083
1 引言
隨著計算機和信息技術的快速發展,數據的計算處理技術突飛猛進,手工輸入數據的速度和準確度顯然已經不能夠滿足需要,這樣就促使自動識別技術快速發展。對于數據內容有雜物或者印刷質量不好的數據,字符特征的提取成了關鍵點,而特征提取的好壞直接影響到識別率的高低[1]。傳統模式識別方法的發展遇到了前所未有的困難,而神經網絡的并行性、容錯能力和學習性能,使它在解決識別問題上不再拘泥于選取特征參數,而對綜合的輸入模式進行訓練和識別,針對字符的平移、旋轉和尺度變化,可以通過構造具有不變性結構的網絡模型,或者用神經網絡提取字符的不變性特征及BP學習算法,利用圖像識別原理,將需要識別的數據先轉化為圖像文件,對圖像處理、進一步識別出結果并輸出,就顯得靈活方便[2-3]。
目前,實驗報告一般采用等級評分制度,比如采用1~5五個等級,當這五個等級不夠用的時候會在數字后面加上一個加號“+”或減號“-”表示優于或次于該成績,如4+、5-,故本文將系統加以改進,使其能識別擴展等級這樣的數字字符。
2 系統整體設計
從過去實驗報告成績錄入效率低的角度出發,本課題在系統的總體結構設計上,首先采用圖像處理將采集到的字符圖片特征提取出來[4],然后利用改進神經網絡算法將字符識別出來,并驗證它的可執行性。該系統主界面是采用基于MFC的Visual C++面向對象化編程語言編寫的。該自動打分系統的整體設計框架見圖1。
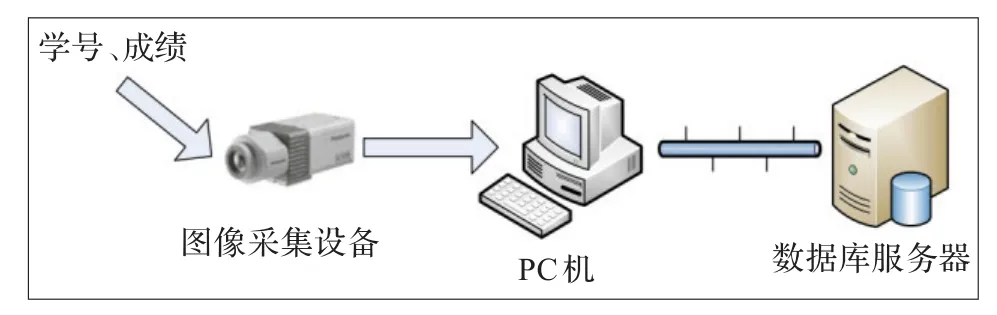
圖1 系統整體設計框圖
圖片采集可以利用掃描儀、照相機、CCD攝像機等電子設備將識別的數據轉換成圖像文件,本實驗中利用CCD攝像機將成績報告輸入到電腦中。首先下載安裝CCD攝像機驅動,裝好后用USB數據線將CCD攝像機連接到電腦,將實驗報告朝下放在CCD攝像機上,點擊“CCD攝像機和照相機向導”,文件格式選擇.bmp,選擇圖片保存位置,便可得到報告成績的圖片。實驗報告中學號、成績的每個字符大小長8 mm,寬5 mm。
該自動打分系統的實現過程分兩部分,圖像預處理和數字字符識別模塊。先是對圖片進行預處理,然后對提取出來的數字、字符特征進行識別,輸出識別結果并保存到數據庫,此部分主要在VC++6.0軟件上實現。
3 圖像預處理
獲取的成績報告圖片處理的總體流程框圖如圖2。
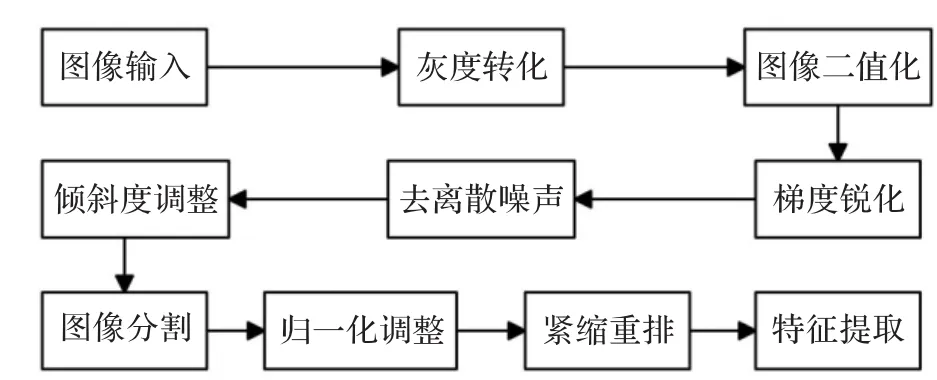
圖2 圖像處理總流程框圖
3.1 圖像二值化
該識別系統是針對實驗報告成績識別的設計。識別前,先要對圖片二值化處理[5],本系統采用給定閾值法,設置圖像處理的固定閾值為128(取0~255的中間值),逐行掃描圖片中各點像素值,大于固定閾值的將其強制設定為255,小于固定閾值的將其強制設定為0。
3.2 去離散噪聲
在實驗報告掃描或者傳輸過程中會出現一些雜亂的離散點,可能是由于儀器等原因造成的。這些離散點并不是所需要的數據信息,并且會妨礙對數據信息的提取,所以要進行去噪聲處理。在本系統中,直接掃描圖片中離散的黑點,逐行逐列掃描整個圖像,當掃描到黑點時,就判斷它與周圍黑點的連接關系,如果與它連接的周圍的黑點的個數大于特定數值時,就判定它不是離散點,否則就判定它是離散點。如果檢測到離散點就刪除,也就是將其像素值強制賦值為255,即白色。
3.3 圖像分割
從實驗報告上獲取的圖片是關于學號和成績,是一串的數字字符,這樣不利于分別對每個數字字符進行特征值提取。當把每個數字字符都分割[4]成單獨的圖片后,提取其特征值就是該數字字符的特征值信息。首先從上往下逐行掃描,當遇到黑點時,把此行定為字符大致頂端。說大致是因為并不是所有字符的上端都在同一水平線上。再從圖片底部逐行向上掃描,當遇到黑點時,將此行定為字符的大致底端。第二步是在確定的大致頂部和底部之間,逐列從左往右搜索。當搜索到黑點時,將此列作為該字符的左端;繼續向右搜索,當掃描到某一列沒有黑點時,將前一列作為該字符的右端。重復上述搜索過程,直到搜索到最后一個字符的右端。接下來是確定每個字符確切的上下邊緣,方法類似以上搜索過程,在每個字符已經確定的左右邊緣內,從上往下逐行掃描,當遇到黑點時,將此行作為該字符的確切上邊緣;同樣從下往上逐行掃描,當掃描到黑點時,將此行作為該字符的確定下邊緣。重復上述步驟,直到找到所有字符的確切上下邊緣。到此為止,已經掃描出了每個字符相對確定的上下左右邊緣,為了不至于損壞字符邊緣的像素值,需要將各邊緣分別向外擴一個像素點作為各字符新的邊緣。
圖3是進行字符分割后的圖片,處理后的圖片中,在分割后的字符周圍加上了藍色的外框,主要是為了方便觀察,其不影響之后其他的圖像處理過程。

圖3 字符分割后處理后的字符
3.4 歸一化調整
實驗報告中的學號和成績均為手寫字符,可能有大有小,分割之后雖然確定了其邊界,但大小依然不一。由于數據結構不一樣,使得特征值提取就不能夠統一。將圖片中各像素值按一定的比例關系插值映射到新的圖像中去。新圖像的尺寸是統一確定的尺寸,新圖像的尺寸可以根據自己的需要來設定。
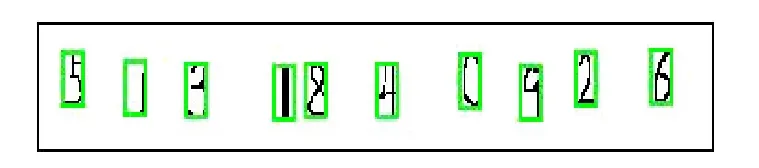
圖4 標準歸一化處理后的字符
3.5 特征提取
本系統中采用的是逐像素特征提取法,這種方法比較簡單且運行速度快,就是對圖像逐行逐列進行掃描,當掃描到黑點時就記錄該點像素值為1,當掃描到白點時就記錄該點像素值為0。直到掃描完整個圖像,就統計完了所有的特征值,特征值數量與圖像中像素點數量相同,掃描結果存儲在一個二維數組中,便可得到所需要的數字圖像特征。
4 成績識別及存儲
本文采用了BP神經網絡識別和模塊識別兩種識別方式。
4.1 BP神經網絡識別
BP神經網絡也即反向傳播神經網絡,它是多層網絡[6],一般至少有3個層,一個輸入層、一個輸出層、一個或多個隱含層,它主要包括信號正向傳播和誤差信號反向傳播兩部分,正向傳播:輸入信號從輸入層經過隱含層傳向輸出層,此過程中網絡權值固定不變,當期望輸出值與網絡系統輸出值差別較大時,進入誤差的反向傳播階段;反向傳播:輸入層向隱含層再向輸入層傳輸誤差信息并調整網絡權值,反復反饋調整,使輸出層輸出逐漸逼近期望輸出值[7]。
4.1.1 BP算法的改進
(1)信號正向傳播過程
設輸入層、隱含層和輸出層結點數分別為m、n和l,則感知器的輸出為:

其中netk為輸出層第k個神經元的輸入加權和[8]。
那么,當網絡的輸出與期望輸出不相等時,及存在輸出誤差,則定義網路的第k個輸出神經元的誤差函數Ek為:

其中dk為第k個神經元期望的輸出結果。
網絡的能量函數(總的輸出誤差)為:

(2)誤差反向傳播過程
利用誤差反饋,通過調整權值和閾值,使網絡在能量達到最小時趨于穩定狀態[9]。
根據前面推導,能量函數和輸出層之間權值關系為:
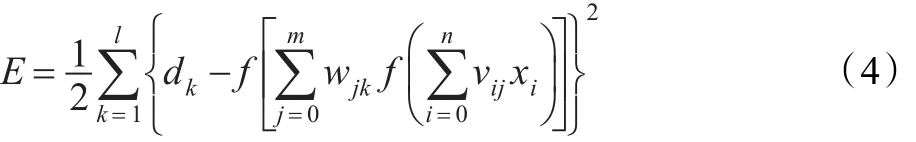
可見能量函數E是各層權值wjk和wij的函數,調整權值即可改變誤差E,使用梯度下降法對其進行調整,取常數η(0<η<1)為調整的步長,及網絡訓練中的學習速率,則可以得到網絡權值的調整量:
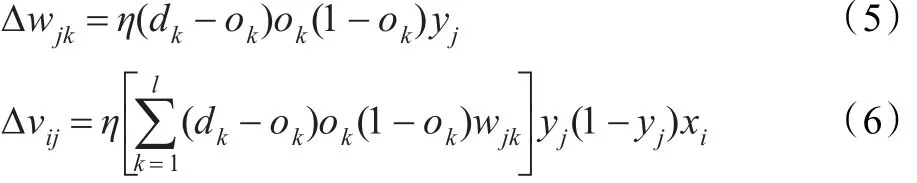
其中δk表示輸出層的誤差,δj表示隱含層的誤差。
(3)加動量項
在修正網絡權值時,不僅考慮誤差在梯度上的作用,而且考慮在誤差曲面上變化趨勢的影響,標準BP算法在權值調整中,只按t時刻誤差的梯度方向調整[10],而沒有考慮t時刻以前的梯度方向,從而常使訓練過程發生振蕩,收斂變慢。為提高網絡的訓練速度,可以在權值調整公式中增加一動量項。

式中,α稱為動量系數,一般有0<α<1。從前一次權值調整中取出一部分疊加到本次調整量中,α影響這個調整量的大小,對于t時刻的調整起到阻尼的作用。
4.1.2 手寫數字及“+-”字符的識別
BP神經網絡數字識別的實現主要包括樣本訓練、字符特征輸入以及識別等過程,首先輸入一個樣本參數,讓網絡系統學習并記憶數據信息中各特征值。樣本的選擇要有代表性,在程序中采用樣本圖片的形式,訓練完后即可用它對數字及字符進行識別。
其具體流程如圖5所示。

圖5 BP神經網絡數字識別過程流程圖
4.2 模板匹配識別
模板匹配法是圖像識別中最具有代表性的方法之一。本文為待識別的樣品提取25個特征值[11],輸送到分類器跟已有的標準模板特征值進行比較,用最小距離法判定所屬類。這種最小距離是依據近鄰原則,是依據同類物體在空間中具有聚類特性的原理進行區分的[12],是一種最簡捷的分類方法。
4.2.1 圖像的最短距離法
利用圖像之間的最短距離作為判別函數的原理為:對于一個待識別的樣本X=(a1,a2,…,an),計算X與訓練集中某樣本Xj(0<j<m,m為訓練集中的樣本個數)之間的距離:

待計算完所有的樣品和模板的距離后,找出最小的距離值所對應的模板類別,樣本所屬的類別判別為此類別。
對于加減號“+-”的識別,根據計算的特征值,首先判斷是否存在加減符號,當最后一個字符的左右邊界相差不超過1的時候,程序判斷為缺省加減符號。若是存在加減符號,判斷特征值是是否大于0.3,若大于0.3,符號判別為加號,反之判斷為減號[13]。
系統分類器所使用的訓練集特征庫,是通過數字模板添加功能建立的。這也意味著,系統的訓練集特征庫是可增加的,并不是一成不變的。一般樣品庫的個數為特征數的5~10倍,這里特征總數為5×5=25,每一種數字就需要至少75個標準樣品,可想而知數目已經不少了。如果N值過小,不利于不同物體間的區別。樣品的處理方法和實際應用是一樣的,先定位字符的上下左右邊界,再對此范圍進行5×5的分割,計算小范圍黑色像素所占的比值[14]。
程序首先獲取需要添加模板的數字,然后判斷該數字是否已經擁有250個樣品了,如果是則放棄添加樣本,否則在該數字已有樣本數目加1,然后把該字符的25個特征值增加到數字對應的位置。
4.2.2 圖像顯示與抓取的軟件實現
在進行此功能模塊開發時,第一步創建一個視頻預覽窗口。在創建視頻捕捉窗口之后,將其顯示在系統人機交互界面的對話框中的適當位置。先在對話框中預放置一個圖片控件,調整其大小和位置,然后將視頻捕捉窗口放置在該控件的位置處[15]。
對于視頻幀的截取,將數據拷貝到剪貼板上,再通過DIB(Device Independent Bitmap)操作獲取內存中圖像數據首地址,進行后續的圖像數據處理。系統中顯示的效果如圖6所示。
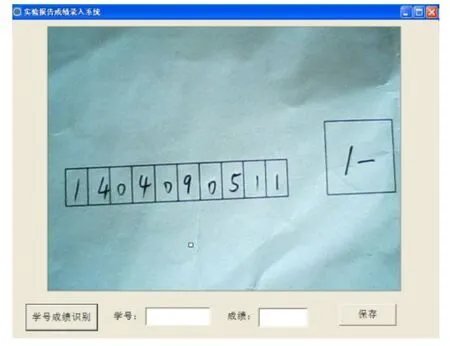
圖6 圖像采集效果
4.3 系統測試及兩種方法識別結果的比較
經過實驗可以看到,BP神經網絡和模板匹配兩種方法的字符識別系統都可以對數字及加減號“+-”進行正確識別。識別效果如圖7所示,識別結果在圖下方的學號、成績欄給出。

圖7 系統識別的實現圖
隨機選取了5 000份實驗報告進行檢測,無論是學號的識別還是成績的識別,利用神經網絡識別正確率高達99.3%,且識別一份成績報告需30 s左右,使用同一樣本,而模塊匹配識別的在保證正確率91.4%的基礎上,從圖像采集到識別結果的顯示大約使用時間3 s,較神經網絡速度提到了10倍。另一方面,人工輸入一份實驗報告成績至少需要1 min,而可見實驗報告自動打分系統,大幅提高了數據輸入的工作效率和準確率,具有一定的實用性。
4.4 學號成績的存儲
設置兩個字段studentnumber和score,分別代表學號和成績,然后在操作系統中創建要使用的ODBC數據源,在程序中添加與此數據庫相關聯的MFC ODBC類,調用CRecordView類的AddNew成員函數把學號與成績增加到記錄中。如圖8,即是識別結果的保存。
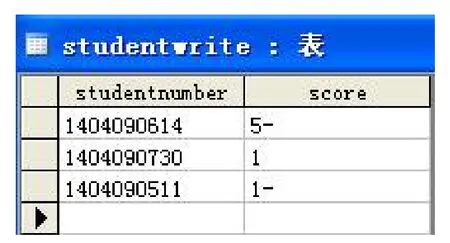
圖8 識別結果的保存
5 總結
本文中設計的系統是針對實驗報告中手寫學號和成績字符的識別,設計過程先對獲取的實驗報告字符圖片進行一系列的預處理,然后用BP神經網絡和模板匹配方法對其進行識別,最后對設計好的系統進行實驗。在整個系統的設計以及實現過程中,識別圖像預處理和識別的方法在現階段無論是原理還是實現都已經很成熟了,字符的定位是最關鍵的一步,也是最難的一步。本文所用的字符定位起始位置修改參數是經過多次實驗得出來的,符合大部分拍攝情況實驗結果表明,該識別系統已經能在很大程度上進行手寫數字和簡單字符的識別,識別率比較高,相對手動輸入成績速度有了很大的提高。該自動成績錄入系統經驗證已經可以應用到高校實驗室的試用階段。
[1]蘇彥華.Visual C++數字圖像識別技術典型案例[M].北京:人民郵電出版社,2004.
[2]馬耀名,黃敏.基于BP神經網絡的數字識別研究[J].信息技術,2007(4):87-88.
[3]杜選,高明峰.人工神經網絡在數字識別中的應用[J].計算機系統應用,2007(2):21-22.
[4]周妮娜,王敏,黃心漢,等.車牌字符識別的預處理算法[J].計算機工程與應用,2003,39(15):220-221.
[5]朱小燕,史一凡,馬少平.手寫體字符識別研究[J].模式識別與人工智能,2000,13(2):174-180.
[6]王春,劉波,周新志.采用BP神經網絡的車牌字符識別方法研究[J].中國測試技術,2005,31(1):26-28.
[7]武強,童學鋒,季雋.基于人工神經網絡的數字字符識別[J].計算機工程,2003(14):174-180.
[8]湯茂斌,謝渝平,李就好.基于神經網絡算法的字符識別方法研究[J].微電子學與計算機,2009,26(8):91-93.
[9]楊慶雄.基于神經網絡的字符識別研究[J].信息技術,2005(4):92-96.
[10]陳蕾,黃賢武,仲興榮,等.基于改進BP算法的數字字符識別[J].微電子學與計算機,2004,21(12):127-130.
[11]顧晨勤,葛萬成.基于模板匹配算法的字符識別研究[J].通信技術,2009,42(3):220-222.
[12]王軍,王員云.基于模板匹配的聯機手寫數字識別[J].現代計算機,2008,25(3).
[13]荊鐘,何明.基于最小錯誤率的貝葉斯決策在手寫英文字母分類識別中的應用[J].遼寧工業大學學報,2009.
[14]湯群芳,俞斌.基于神經網絡和DSP技術的離線數字識別系統[J].電子測試,2009,12(6):16-20.
[15]楊淑瑩.圖像模式識別:VC++技術實現[M].北京:清華大學出版社,2005.
