大數據關鍵技術在數字文化資源統一揭示與服務平臺中的應用
2015-03-14 07:10:22薛堯予國家圖書館北京100081
圖書館理論與實踐 2015年12期
●薛堯予(國家圖書館,北京100081)
大數據關鍵技術在數字文化資源統一揭示與服務平臺中的應用
●薛堯予(國家圖書館,北京100081)
[關鍵詞]大數據;分布式處理;數據挖掘;非結構化數據
[摘要]針對目前主流的大數據處理技術進行分析,研究其在數字資源揭示與服務平臺中的應用方法,分析和構建了Hadoop、Memcached、Cassandra、協同過濾等技術在數字文化資源統一揭示與服務平臺中的應用模式,以期為相關研究提供參考。
隨著大數據時代的來臨,我們所創造和產生數據的急速增長,數據量之巨大已經遠超我們想象。一方面,現有的工具逐漸顯露出結構的局限性;另一方面,大數據所帶來的不可估量的價值引領我們重新認識這個世界。
數字圖書館作為數字信息和知識的保存及服務中心,本身就擁有大量的數據庫、電子書、紙質圖書轉換的數字圖書,以及各種音視頻等數字文化資源,且隨著數字圖書館建設的進一步開展,將會生產和保存更多的數據。如,2013年國家圖書館已擁有874.5TB的數字資源,資源檢索與揭示系統(國圖使用文津搜索系統)中目前已整合超過2億條元數據。此外,國家圖書館各業務系統和讀者服務系統中每天都產生大量的系統日志和讀者行為等數據。如何對數字圖書館的大量數字資源進行整合分析,并使其得到合理、深度揭示和服務已經成為擺在我們面前的一項重要課題。
本文依托于數字文化資源統一揭示與服務平臺,對大數據關鍵技術進行研究,構建合理的應用模式,通過分布式處理技術實現數據從原始狀態到可用狀態的處理與準備,并建立可靠的分布式緩存系統,提高檢索效率。對檢索到的資源進行詳情展示,同時基于大規模數據挖掘與推薦技術的實現對資源關聯及用戶行為中的隱含信息加以合理利用,提高平臺的使用體驗。
1大數據關鍵技術
1.1 Hadoop分布式處理技術
Hadoop是目前應用最為廣泛的分布式系統基礎架構,其技術框架中主要包含了MapReduce編程模型和HDFS文件系統,二者緊密集成并構成Hadoop分布式計算的理論基石,[1]該架構主要用在基于計算機集群環境的大規模數據分布式處理。同時,Hadoop分布式處理技術在實現層面不同于傳統的并行計算,對于開發人員沒有很高的技術要求,只要熟悉Hadoop所定義的模型結構及實現方法,即可進行大規模數據并行處理的開發。Memcached分布式內存對象緩存技術可在動態應用中將數據庫負載大幅度降低,合理分配資源,加快訪問速度,[2]常與Hadoop架構配合,共同構建大規模、高吞吐量的數據處理系統。
以Hadoop為核心的分布式系統架構,具有可靠性高、效率高、擴展性好等優勢。首先,在HDFS系統中對數據會保留多個副本,當數據在處理或者存儲過程中出現損失或者丟失,因其他副本的存在,系統會針對丟失數據的分布情況進行重新部署,從而實現高可靠性。其次,架構中的MapReduce模型可以通過并行方式保證系統的運算速度,從而實現高效率。此外,由于這種架構對集群中單臺計算機性能沒有太大要求,較底端的服務器或者普通PC即可滿足其計算要求,因此是分布式數據處理平臺的優選架構。
1.2非結構化數據庫技術
隨著各種數據種類和數據量的急劇增長,數據的非結構化也逐漸成為我們面臨的重大挑戰,單純使用關系型數據庫已經無法滿足實際業務中出現的越來越多的非結構化、半結構化數據,這就催生了MongoDB、Cassandra、Hbase等非關系型數據庫技術。
MongoDB雖然是為了處理半結構化數據而產生的,但是,其查詢功能幾乎可以和關系型數據庫相媲美,同時,數據庫結構又較關系型數據庫松散,可以看做一個將非關系型和關系型數據庫特性結合的較為完美的數據庫。Cassandra是典型的分布式非關系型數據庫,具有很強的擴展性和讀寫性,與MongoDB一樣都是目前較為流行的數據庫。HBase也是Hadoop家族中的一員,是基于HDFS的分布式數據庫,在高性能讀寫大規模數據方面具有優勢。
2數字文化資源統一揭示與服務平臺
數字文化資源統一揭示與服務平臺是一個綜合性平臺,運行各類應用系統,并通過平臺融合為一個整體。它是資源的匯集地、檢索的門戶、服務的調度站。[3]平臺匯集各類文化資源元數據共1000萬條,分別由6家單位提供,這些資源涉及城市文化、歷史文化、戲曲、舞蹈、旅游等,包括圖書、期刊、圖片、視頻、靜態三維及活態三維等多種類型。[4]平臺搜索引擎可以支持各種不同類型的文化資源元數據,按照分布式集群架構搭建系統運行環境,根據元數據的數量實現系統規模的動態伸縮,從而實現對文化資源的統一揭示和服務。不同類型的文化資源元數據可以根據語義、分類、主題等進行數據關聯和調用,打通不同類型數字資源的信息孤島,實現文化資源的深度揭示。通過平臺導引系統的調度功能,對分布在不同物理區域的文化資源數字對象進行展示。依托數字文化資源統一揭示與服務平臺,將建立貫通各類文化機構的多種類型文化資源的數字化應用示范,打造基于互聯網、數字電視平臺、移動終端的數字文化資源應用展示,實現各類文化資源的集中管理、深度揭示、統一檢索和聯合展示,為用戶獲取各類文化資源提供新的服務模式。數字文化資源統一揭示與服務平臺的搭建過程中,需要完成四個關鍵環節:數據收集與處理、分布式檢索、元數據調用及展示、用戶行為信息挖掘與利用。
3大數據關鍵技術在平臺的應用
數據處理能力、檢索的效率是評價一個資源揭示與服務平臺的重要指標。以往的資源揭示與服務系統,多是基于關系型數據庫進行數據處理與檢索,非常適用于點查詢以及小部分數據的分析處理,對數據的結構有嚴格要求。在大數據環境下,這樣的系統結構顯然已經無法滿足大批量數據處理與檢索的需求,因此,我們考慮采用分布式處理技術搭建平臺的數據處理與檢索支撐部分,將多種類型、結構各異的數據存放于分布式系統中,以便進行大批量的、涵蓋整個數據集的分析與處理,同時利用分布式緩存技術構建索引,提升檢索效率。
平臺索引項的建立通過分布式緩存系統實現,但是對于資源詳情數據、書評、書封等項的展示來說,并不需要大量的計算,因此并沒有納入分布式計算體系中,而是采用非結構化數據庫實現,一方面減少分布式體系的計算壓力,另一方面可以使得資源展示更加豐富。
用戶通過平臺進行資源檢索時,如果系統能夠通過對用戶及資源數據進行分析,利用數據挖掘方法,將隱含在用戶信息、資源關聯、用戶訪問日志等數據中的信息挖掘出來,并根據這些信息向用戶推薦其最需要的資源,將在很大程度上提升用戶體驗。
3.1基于Hadoop的分布式數據處理
采用Hadoop結構構建分布式計算集群,完成數字資源重要性計算、索引構建、數據挖掘等大規模計算,進行數據處理,提高檢索質量。Hadoop框架中分布式計算通過MapReduce過程實現(見圖1)。
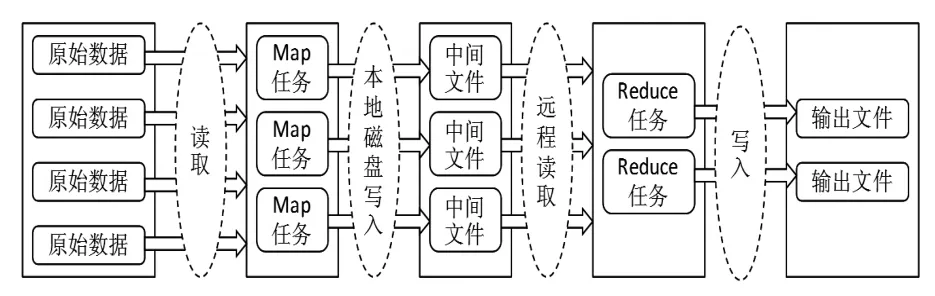
圖1 MapReduce執行過程
首先,系統將原始數據集讀取后進行分割,其中若有單個數據文件較大,尤其是大到影響檢索效率時,也會將其分割成較小文件,每個被分割的數據文件會對應一個Map操作。程序運行時,多個副本按照Master-Worker結構啟動,一個Master程序對應多個Worker程序,由Master為Worker分配Map或者Reduce操作任務。分配到任務的子程序將自動讀取分割后的文件,并對該文件執行預先定義好的、與文件對應的Map操作(在Hadoop框架中有一個已經封裝好的Mapper類,通過它來實現Map操作過程的定義),從而對數據進行分析處理,生成鍵值對并存至內存。固定時間間隔后,內存中的結果集被分割成多個子集,由系統將這些子集寫入系統硬盤形成中間文件,并在Master程序中記錄子集所寫入的位置。接下來,分配到Reduce操作的Worker程序會按照操作指示讀取(往往是遠程的)對應的中間文件,并在讀取后由該Worker程序對結果集執行排序操作,如果結果集太大,排序可通過另外的排序程序實現。執行Reduce操作的Worker程序會對排序后的結果進行遍歷,并對來自相同鍵值的執行結果合并,并最終形成輸出結果。當所有被分配任務(Map操作和Reduce操作)的Worker程序執行完后,Master程序會將結果返回系統主程序,進而執行其他操作。
3.2基于Memcached的分布式緩存
Memcached常被用來加速應用程序。對一個web應用來說,很多情況下返回的信息都是相同的,從數據源(數據庫或文件系統)重復加載十分低效。在介紹分布式緩存系統前,有必要簡要介紹一下平臺的搜索集群結構。集群采用文檔分布式策略,每臺索引服務器的行為類似于整個文檔集的一小部分數據的搜索引擎,根節點通過父節點把查詢消息的拷貝發送到每臺核心搜索集群中的服務器,每臺搜索服務器返回檢索結果及相應分數,通過父節點和根節點歸并和排序,最后由根節點合并為一個相關排序表,返還給前端展示頁面。
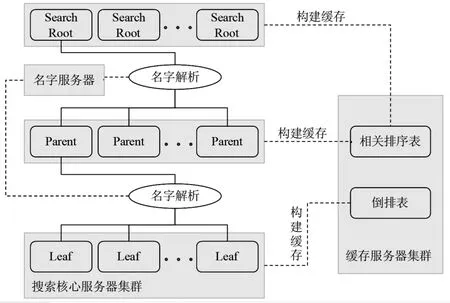
圖2分布式緩存系統結構
平臺的緩存服務采用的是Memcached分布式緩存集群系統,在各個層面均有構建。在父節點和根節點層面,緩存的是相關排序表;在搜索核心集群上,緩存的是倒排表。在大規模語料庫中,使用密集計算來處理查詢,相關排序表被計算出來后,通過緩存可提高整個系統的性能。根服務器會根據圖書館標準的類別體系對檢索結果進行分類,根服務器、父節點和搜索核心節點通過統一的名字服務器管理各自的地址信息,采用ZooKeeper實現同步服務、配置維護和命名服務等分布式應用(見圖2)。
3.3基于Cassandra的資源詳情展示
平臺的資源詳情顯示功能基于Cassandra結構實現,Cassandra數據結構中主要有:Column、SuperColumn、ColumnFamily、Keyspaces、Row,其中Keyspace 是ColumnFamily的容器。一個Keyspace相當于關系型數據庫中的一個數據庫,ColumnFamily相當于關系型數據庫中的表,每個ColumnFamily包含許多Row,每個Row包含Key及其關聯的一系列Column。Column 是Cassandra中最小的數據單元,是三元的數據類型,包含:name,value和timestamp。SuperColumn可以想象成Column的數組,包含一個name以及一系列相應的Column。
平臺前端顯示資源詳細信息所用的元數據保存在Cassandra,如果前端從Cassandra讀取數據失敗,會嘗試從Hbase中進行讀取。多媒體數據和書評數據也保存在Cassandra中,如前端顯示書封的圖片和書評時可直接從Cassandra中獲取。
平臺中Cassandra設計了兩個數據中心,其目的是為了讓另外一個數據中心有一套完整的數據備份,當一個數據中心無法正常工作時候,第二個數據中心可以頂替,并幫助損壞的數據中心恢復數據。
3.4基于協同過濾的資源推薦
目前,許多網站都已經使用了協同過濾推薦技術,如Amazon、Google等。不同的協同過濾之間有很大的不同,筆者在選取協同過濾算法時,綜合考慮了基于用戶協同過濾算法[5]和基于項目協同過濾算法[6]的優缺點,形成基于用戶和項目相結合的協同過濾算法。
基于用戶的協同過濾算法,首先,要對用戶屬性進行分類,進而根據結果尋找最接近的用戶,也就是尋找最近“鄰居”,最終根據“鄰居”屬性集合對用戶進行推薦。在評分過程中,評價依據來自于兩方面:對用戶基本信息進行評價,即顯性評價;對用戶瀏覽、檢索、評論等行為信息進行評價,即隱性評價。計算近鄰時,較常用的算法是相似性算法。基于項目的協同過濾算法,以預推薦的項目為基礎,這些項目集合由系統預先分為若干類別,然后計算出與用戶經常使用的項目相近的項目集合,向用戶進行推薦。項目集合的類別往往是由上至下的倒樹型結構,大類別在上,細分類別在下。在計算相似性時,同類項目之間相似度加權高于類間項目相似度加權。
利用基于用戶的協同過濾算法進行資源推薦時,需要分析用戶對于資源的使用情況,得到能代表用戶使用偏好的屬性集合,這一過程往往決定于系統對用戶行為信息的收集程度,這使得推薦結果具有較大隨機性。而基于項目的協同過濾,由于推薦來自于資源本身的特性,結果較為精確,較容易準確把握用戶需求,但不利于發掘一些隱含于相似用戶屬性中信息,范圍較窄。將兩種算法進行結合會得到更好的推薦效果。如:一位用戶為化學專業學生,當他檢索“高等數學”時,通過基于項目的協同過濾,系統將會推薦《高等數學概論》《高等數學名師指點》等與高等數學相關的一些資料。如果結合基于用戶的協同過濾,系統就會將另外一些化學專業學生檢索過的《化工原理》《高分子化學》等資源推薦出來,推薦的結果集將更契合用戶需求。
多數大數據處理技術都是在原有數據處理技術基礎上結合了新的應用場景和應用方法。同時,云計算技術近幾年的興起和成熟,也為大數據處理技術的發展奠定了堅實的理論基礎。研究這些技術在數字資源揭示與服務方面的應用,能夠提高數字資源管理效率,使數字資源的組織模式更為有序,從而支撐數字資源更為深層、全面地揭示,使讀者得到更高效的數字資源檢索、展示服務。
[參考文獻]
[1]The Hadoop Distributed File System:Architecture and Design[EB/OL].[2013-10-29].http://hadoop. apache.org/docs/r0.18.0/hdfs_design.pdf.
[2]Memcached website[EB/OL].[2013-10-29].http: //memcached.org/.
[3]魏大威.數字文化資源統一揭示與服務平臺架構研究[J].圖書館學研究,2014(5):56-62.
[4]梁蕙瑋,薩蕾.國家數字文化資源統一揭示與服務平臺的資源整合研究[J].圖書館學研究,2014(2):54-58.
[5]Sarwar B, et al. Analysis of recommendation algorithms for E-commerce[C].Proceedings of the 2nd ACM Conferenceon Electronic Commerce,New York,ACM Press,2000:158-167.
[6]Sarwar B,etal.Item-basedcollaborativefilteringrecommendation algorithms[C]// Proceedings of the 10th International World Wide Web Conference.Hong Kong: ACMPress,2001:285-295.
[收稿日期]2015-02-02[責任編輯]劉丹
[作者簡介]薛堯予(1982-),男,高級工程師,研究方向:數字圖書館,圖書館大數據研究。
[基金項目]本文系國家科技支撐計劃項目“文化資源數字化關鍵技術及應用示范”(項目編號:2012BAH01F01)的研究成果。
[文章編號]1005-8214(2015)12-0096-04
[文獻標志碼]A
[中圖分類號]G250.73
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
信息通信技術(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
