基于實體詞典與機器學習的基因命名實體識別*
2015-03-14 06:16:12夏光輝李軍蓮阮學平
醫學信息學雜志 2015年12期
夏光輝 李軍蓮 阮學平
(中國醫學科學院醫學信息研究所 北京 100020)
?
基于實體詞典與機器學習的基因命名實體識別*
夏光輝 李軍蓮 阮學平
(中國醫學科學院醫學信息研究所 北京 100020)
將實體詞典以特征的形式引入到機器學習模型中,提出一種基于實體詞典與機器學習的基因命名實體識別方法,在GENIA 3.02語料上進行實驗。測試結果表明引入實體詞典特征后,在獲得較高實體識別準確率的同時,優化CRFs識別模型的時間復雜度,提高系統識別效率。
實體詞典; 機器學習; 基因命名實體; 命名實體識別
1 引言
現階段計算機的廣泛普及以及互聯網技術的快速發展,使得信息的采集和傳播變得簡便、快捷,大量的信息開始以驚人的速度涌現,從而導致了“信息爆炸”現象產生。為了應對“信息爆炸”所帶來的嚴峻挑戰,人們迫切需要利用自動化工具以便于能夠迅速而準確地從海量的信息資源中找尋最相關的信息,命名實體識別(Named Entity Recognition)正是為了應對這種挑戰,滿足信息處理時的需求而產生的。命名實體識別是自然語言處理中的核心技術,也成為自然語言處理的一個主要方向,在信息提取、信息檢索、主題分類、知識發現等方面具有重要應用。生物醫學的迅速發展,特別是2001年人類基因組工程草圖的發表,與生物醫學領域相關的科學數據呈指數級別增長,各種形式的生物醫學文獻和文本信息也迅速增長,這些文獻數據隱藏著豐富的生物醫學知識,因此,如何讓生物醫學研究人員從海量的相關文獻中便捷地捕獲生物醫學信息變得迫在眉睫。基因、蛋白質等是生物體的主要組成部分,同時也是生命科學研究的主要對象,從醫學文獻中抽取基因、蛋白質等實體名稱進一步發現它們之間的作用和關系具有非常重要的意義。基因命名實體是指遺傳學領域具體的或抽象的實體,如基因名、DNA名、RNA名等。通常情況下,基因名稱和蛋白質名稱是一致的,只是具體的實例有區別;在文獻中,作者經常也不會對基因和蛋白質作嚴格的區分;有的研究表明,當文獻中出現的基因、蛋白質以及mRNA等名稱時,即使是生物醫學領域的專家,其正確區分基因和蛋白質實體的一致率也只有78%[1]。因此,本研究所指的基因命名實體實際上包括了基因和蛋白質兩類命名實體。基因命名實體識別方法包括基于詞典的方法、基于規則的方法等,由于基因命名實體名稱的復雜性和多樣性,目前基因命名實體識別的總體效果要比新聞領域等通用命名實體識別的準確性低很多。本文嘗試基于詞典與機器學習相結合的方法進行基因命名實體識別,以改進其準確性和實用性。
2 實體詞典構建與機器學習實體特征構建
2.1 概述
基于詞典的基因命名實體識別方法中,詞典是核心,詞典的完備程度對基因命名實體識別效果具有決定性作用;而基于機器學習的基因命名實體識別方法,需要構建基因命名實體的各種獨特特征,通過統計語料中各種特征的出現頻率,計算其作為基因命名實體的條件概率,最終對命名實體的類型做出預判。因此,實體詞典生成與機器學習實體特征構建既是本文提出的基于詞典與機器學習的基因命名實體識別方法的基礎,也是基于詞典與機器學習的基因命名實體識別過程的關鍵步驟。
2.2 實體詞典構建
從美國國立醫學圖書館研究和開發的醫學一體化語言系統(Unified Medical Language System,UMLS)的133種語義類型中選擇“Gene or Genome”、“Nucleic Acid, Nucleoside, or Nucleotide”、“Amino Acid, Peptide, or Protein”3種語義類型抽取與基因、蛋白質相關的術語作為基因實體詞典的來源[2]。具體術語量,見表1。

表1 詞典信息
2.3 機器學習實體特征構建
2.3.1 概述 實體特征是指基因文本中能正確區分基因實體的字符特征,特征構建是否合理、有效,直接關系到基因命名實體能否被正確地識別。實體特征能夠準確地表征命名實體的特點,為命名實體的識別提供有效信息。由于基因命名實體的獨特特點,當前已有很多研究者提出了各種各樣的特征,而基于統計的機器學習模型的識別效果依賴于特征的質量和數量。本文通過對文獻中基因命名實體的特點進行分析,結合目前在生物醫學實體識別領域構建的特征類型[3-6],構建了13大類基因命名實體的特征。
2.3.2 單詞特征(Word Features) 單詞是文本自動分析和實體標注的基本單位,單詞特征能夠反映基因命名實體的語言信息,是基因命名實體識別最核心、最重要的特征。
2.3.3 構詞特征(Word Structure Feature) 本文根據當前詞是否由大小寫字母、數字、連字符(-和/)、希臘字母、羅馬數字、引號、括號等字符組成構建了構詞特征,共包括18種子特征,以此來識別文本中當前詞是否為基因命名實體。18種構詞子特征,見表2。

表2 構詞特征的18種子特征
2.3.4 關鍵詞特征(Keywords Feature) 關鍵詞是指在基因命名實體中出現頻率較高的單詞。通過判斷當前詞是否為關鍵詞,可以識別可能出現在當前詞附近的命名實體。
2.3.5 詞綴特征(Affix Feature) 詞綴是一種附著在詞根或詞干的語素,為規范詞素,不能單獨成字。黏附在詞根前面的詞綴稱為前綴,黏附在詞根后面的詞綴稱為后綴。在基因命名實體中,同一類物質一般會有相同的前后綴,如一般蛋白質名稱都是以“ase”結尾。
2.3.6 詞形特征(Morphlogy Feature) 基因命名實體是一類特異性非常高的命名實體,其通常具有相同的詞形。因此,根據詞形特征可以判別當前詞是否屬于基因命名實體。目前通用的詞形特征表示方法是將大寫字母替換為A,小寫字母替換為a,數字替換為0,其他字符替換為x。
2.3.7 邊界詞特征(Boundary Word Feature) 邊界詞是指命名實體的第一個和最后一個單詞。大部分基因命名實體是由多詞組成的,利用邊界詞信息可以提高邊界識別能力,減少復合性基因命名實體的識別錯誤率。
2.3.8 一元詞特征(Unary Feature) 基因命名實體中存在大量僅由一個單詞構成的實體,即一元詞,如IGF2、IL-2A等。以一元詞是否出現作為特征,可為當前詞是否為基因命名實體提供準確、有效的信息。
2.3.9 嵌套詞特征(Nested Feature) 詞與語素按一定規則組合起來構成的合成詞即為復合詞。在本文中,包含了嵌套結構的基因實體都是復合詞,即此類基因命名實體的組成部分也是一個獨立的基因命名實體,如基因命名實體“NF-kappaB element”中包含基因命名實體“NF-kappaB”,這種嵌套結構增加了實體邊界的識別難度。本文將基因命名實體中的嵌套結構單獨標識出來,作為嵌套詞特征識別基因命名實體,以減少命名實體邊界識別的錯誤率。
2.3.10 停用詞特征 (Stop Word Feature) 在信息檢索中,為節省存儲空間,提高搜索效率,在處理自然語言數據(或文本)之前或之后會自動過濾掉某些字或詞,這些字或詞即被稱為停用詞。在英文中,存在一部分單詞是沒有實際意義的,如“a”、“was”、“can”等這類詞雖然出現頻率較高,但是會嚴重影響搜索引擎的查準率,并降低搜索引擎的檢索效率。在在遺傳學領域,這類停用詞對命名實體識別同樣會帶來負面影響,因此可以將文本中的停用詞作為特征,減少識別過程中無用信息的干擾。
2.3.11 通用詞特征(Common Word Feature) 通用詞是指使用頻率比較高、單詞本身也具有實際意義,但是在各個專業領域都通用的單詞。這類詞不能反映基因領域的獨特特點,也不是基因命名實體的組成部分,因此基因命名實體識別時意義不大,可以忽略這類詞。
2.3.12 上下文特征(Context Feature) 上下文信息是指基因實體前一個詞和后一個詞的單詞信息,利用上下文信息可以提高基因實體邊界識別能力。
2.3.13 詞性特征(Part of Speech Feature) 詞性指作為劃分詞類的根據的詞的特點,英語詞匯可分為名詞、動詞、代詞、形容詞、副詞、數詞、冠詞、介詞、連詞、感嘆詞等詞性,通過詞性特征有助于識別命名實體。自然語言處理中,一般利用詞性標注器對文本進行詞性標注,目前生物醫學領域常用的詞性標注器包括Stanford POS
tagger[7]、MedPost[8]、GENIA tagger[9]等,其中GENIA Tagger的訓練語料由新聞領域的Wall Street Journal語料以及生物醫學領域的GENIA語料和PennBiolE語料組成,對生物醫學文獻的詞性標注效果較好,因此本文實驗中也采用GENIA Tagger[10]工具包來獲取單詞的詞性。
2.3.14 詞典特征(Dict Feature) 傳統基于詞典的命名實體識別是在識別過程中完全依賴詞典,一般使用不同的詞典匹配方式在所構建的詞典中查找字符串。本文是以機器學習模型作為基因命名實體識別的主要方法,而在識別過程中,將詞典以特征的形式引入到機器學習模型當中。因此,本文基于基因實體詞典構建了詞典單詞特征、詞典一元詞特征和詞典嵌套詞特征。
3 實體標注實現流程
本文是將外部詞典以特征的形式引入機器學習方法中,基于詞典和統計機器學習相結合的方法識別基因命名實體的實現流程,見圖1。圖1中上面的實框內表示的是構建詞典特征的過程。首先構建基因實體識別所需要的詞典資源;然后參照條件隨機場(Conditional Random Fields, CRFs)識別模型的語料格式,對詞典資源進行格式轉換并提取特征,形成詞典特征集合;最后將詞典特征集合作為特征加入到訓練語料進行訓練獲得識別模型。圖1中下面的虛框表示的是基于CRFs的基因命名實體識別過程。首先將GENIA 3.02語料庫轉換為純文本格式,按照特征規則提取語料的多維特征值;然后將詞典特征集合加入訓練語料中,結合語料中提取的特征生成多特征的基于CRFs的基因命名實體識別模型;最后用生成的模型標記測試語料完成基因命名實體識別任務。

圖1 實體識別流程
4 結果與分析
4.1 評測指標
采用準確率P(Precision)、召回率R(Recall)和F測評值(F-measure) 對實驗結果進行評估。準確率和召回率是命名實體識別領域常用的系統評測指標,其中準確率衡量正確識別的基因命名實體占所有識別出的基因命名實體的比例,召回率衡量正確識別的基因命名實體占評測語料中標注的所有命名實體的比例。準確率和召回率是相互矛盾、相互對立的兩個評測指標,一般而言,準確率升高,召回率降低;召回率升高,準確率降低。因此,通常采用二者的綜合加權指標F測評值來評估識別性能。準確率、召回率和F測評值的計算公式如下:

(1)

(2)
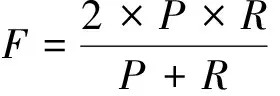
(3)
式中,P表示基因命名實體識別的正確率;R表示召回基因命名實體的能力;TP(True Positives)表示正確地識別為基因命名實體的數目;FP(False Positives)表示錯誤地識別為基因命名實體的數目;FN(False Negative) 表示錯誤地識別為非基因命名實體的數目。
4.2 基因實體識別的特征選擇
命名實體識別系統需要構建豐富的特征集合以準確識別文本中的基因命名實體,選用的特征越具有基因命名實體的獨特性,就越能提高基因命名實體識別系統的識別能力;但是選擇的特征越多,系統識別的時間復雜度就越大。由于特征之間相互耦合,實際上并不是構建的所有特征都能夠提高命名實體的識別能力,不合適的特征組合不僅無法區分基因命名實體和非基因命名實體,反而會降低單一特征對基因命名實體的識別能力,導致基因命名實體識別系統的識別性能下降。因此,本文嘗試通過單獨最優特征組合法,按識別性能的高低依次選取特征,構建一個數量少、質量高、時間復雜度合適的特征集合,以提高CRFs模型的識別效果。
4.3 基于機器學習的基因命名實體識別結果
本文實驗中,依據單獨最優特征組合法,選取 [F0(單詞特征)、F33(詞性特征)、F31(通用詞特征)、F23(四字符后綴特征)、F22(三字符后綴特征)、F5(數字字母順序組合)、F30(停用詞特征)、F7(包含連字符)、F3(大小寫字母組合)、F21(四字符前綴特征)]10個特征識別系統可以得到最大的F測評值(80.56%)。因此,由這10個特征構建的特征集合是單獨最優特征組合法的最優特征集合,見表3。

表3 單獨最優特征組合法的最優特征集合(%)
實驗中,分別構建所有特征模板和最優特征模板,并分別處理訓練語料和測試語料,用不同的特征集合構建的識別系統的時間復雜度,見表4。可知,利用構建的最優特征集合,不但系統性能提高了1.19%,達到了80.56%,而且時間復雜度大大降低,這充分體現了特征選擇對機器學習識別模型的重要性。

表4 不同特征集合的時間復雜度比較
4.4 基于實體詞典和機器學習相結合的基因命名實體識別結果
本文主要研究的問題是將基于統計的機器學習方法和基于詞典的方法相結合應用于基因命名實體識別領域。本文試驗中,在特征集合中加入詞典單詞特征、詞典一元詞特征和詞典嵌套詞特征,分別計算單詞特征與詞典的3個特征聯合的識別效果。各詞典特征的實驗結果,見表5。可見與單獨考慮單詞特征相比,3個詞典特征加入后,都能在一定程度上提升基因命名實體識別的性能。本實驗中,對新加入的詞典特征仍按照單獨最優特征組合法重新構建最優特征集合,最終構建的最優特征集合對應的6個特征為[F0(單詞特征)、F33(詞性特征)、F36(詞典單詞特征)、F31(通用詞特征)、F23(四字符后綴特征)、F22(三字符后綴特征)]。加入詞典特征訓練得到的CRFs統計學習模型對測試語料做出預測,得到的實驗結果,見表6。

表5 詞典特征的識別結果(%)
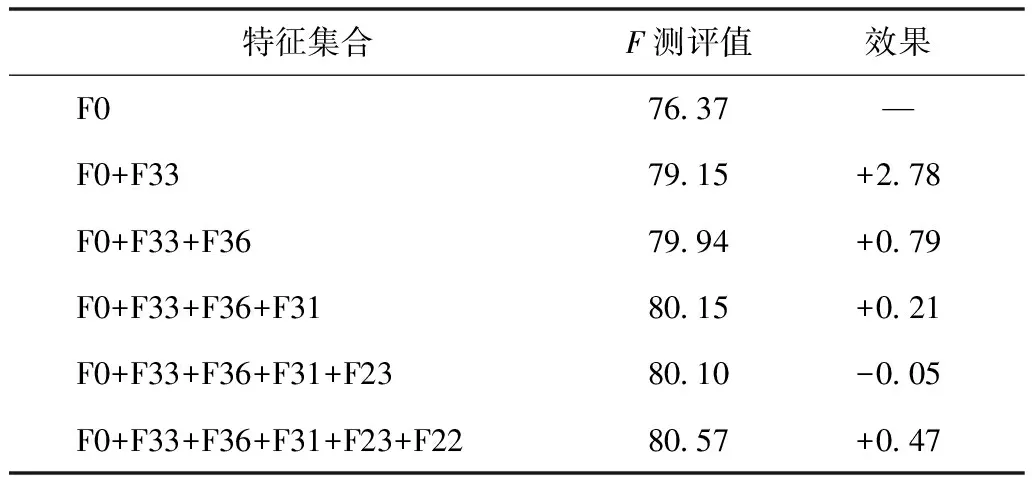
表6 加入詞典特征的最優特征集合(%)
由表7可見,加入詞典特征后,CRFs識別模型的識別收斂速度有明顯的提升,只需要考慮[F0、F33、F36、F31、F23、F22]6個特征,CRFs識別模型就能獲得較高的F測評值,超過了不加入詞典特征時取得的最高F測評值,這在一定程度上優化了CRFs識別模型的時間復雜度,見表7,為CRFs識別模型從小規模的實驗測試走向大規模工程化應用提供了條件。

表7 最優特征集合的時間復雜度比較
5 結語
近幾年來,雖然基因命名實體識別在語料庫構建、詞典構建、特征構建、識別方法等方面取得了一定的進展,但由于基因命名實體的構詞形式復雜多樣,要使系統的識別性能達到可應用的程度仍面臨著巨大挑戰。因此,后續研究中可以在以下幾方面進一步探討:(1)構建規模更大、質量更高的語料庫。機器學習方法主要是通過統計訓練語料來得到相關參數并建立模型,因此語料庫所含基因實體越多、語料庫質量越高,建立的模型識別效果越好。 (2)提取深層次的實體特征,研究高效的特征表示方法。目前選取的單詞特征、詞性特征等只是對命名實體名稱或語法成分的一種匹配,只用到了表層的文本信息,無法有效地識別句子中隱含的實體信息。在后續研究中,應更注重利用文本中的句法知識等深層次的信息,提取文本中命名實體的共指特征,從而提高系統識別命名實體的能力。(3)研究詞典與機器學習方法更優的結合機制。基于詞典是命名實體識別的一種比較簡單的方式,完備的詞典可提高系統識別己知命名實體的能力。因此,一方面可以通過詞語原型化工具改進詞典匹配算法,以降低英文單詞的詞形變化對詞典特征構建的影響;另一方面還需要基于詞典構建更多的特征加入到機器學習方法中,以減少機器學習模型對語料庫的依賴,從而為基因命名實體識別系統從理論探索走向實際應用提供條件。
1 Hatzivassiloglou V, Duboue′ PA, Rzhetsky A. Disambiguating Proteins, Genes and RNA in text: a machine learning approach[J]. Bioinformatics, 2001, 1(1):1-10.
2 National Center for Biotechnology Information, U.S. National Library of Medicine. Semantic Network-UMLS?Reference Manual[EB/OL].[2015-02-10].http://www.ncbi.nlm.nih.gov/books/NBk9679/.
3 王琦.詞典和機器學習相結合的生物命名實體識別[D].大連:大連理工大學,2009.
4 鄭強.生物醫學命名實體識別研究[D]. 長沙:國防科學技術大學,2009.
5 黃浩煒.SVM與基于轉換的錯誤驅動學習方法相結合的生物實體識別[D]. 長沙:國防科學技術大學,2007.
6 周榮鵬. 生物醫學文獻中命名實體的識別[D]. 大連:大連理工大學,2009.
7 The Stanford Natural Language Processing Group. Stanford Log-linear Part-of-Speech Tagger[EB/OL].[2015-02-15].http://nlp.stanford.edu/software/tagger.shtml.
8 Smith L,Rindflesch T,Wilbur W J. MedPost: a part-of-speech tagger for bioMedical text[J].Bioinformatics,2004,20(14):2320-2321.
9 Tsuruoka Y,Tateisi Y,Kim J D, et al. Developing a Robust Part-of-Speech Tagger for Biomedical Text[J].Advances in Informatics Lecture Notes in Computer Science,2005, (374): 382-392.
10 Department of Information Science, Faculty of Science, University of Tokyo.GENIA Tagger:part-of-speech tagging, shallow parsing, and named entity recognition for biomedical text[EB/OL].[2015-02-15]. http://www.nactem.ac.uk/GENIA/tagger.
Gene Named Entity Recognition Based on Entity Dictionary and Machine Learning
XIA Guang-hui, LI Jun-lian, RUAN Xue-ping,
Institute of Medial Information, Chinese Academy of Medical Sciences, Beijing 100020, China
By introducing the entity dictionary into the model of machine learning in the form of characteristics, this article proposes a method of gene-named entity recognition based on entity dictionary and machine learning and experiments on corpus GENIT 3.02. As indicated by the test results, after the characteristics of the entity dictionary are introduced, while a higher accuracy rate of entity recognition is obtained, the time complexity of CRFs recognition model is optimized and the system's recognition efficiency is enhanced.
Entity dictionary; Machine learning; Gene named entity; Named entity recognition
2015-11-13
夏光輝,助理研究員,碩士,主要研究方向為醫學知識組織建設與利用、醫學文本信息檢索與處理,發表論文20篇。
國家科技支撐計劃項目(項目編號:2011BAH10B05)。
R-056
A 〔DOI〕10.3969/j.issn.1673-6036.2015.12.012
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
意林(繪英語)(2017年5期)2017-05-15 02:17:23
