基于NoSQL的PDM圖文檔存儲
2015-03-24 08:01:26夏秀峰徐四鵬
制造業自動化 2015年3期
夏秀峰,徐四鵬
XIA Xiu-feng1,2, XU Si-peng1
(1.沈陽航空航天大學 計算機學院,沈陽 110136;2.沈陽航空航天大學 遼寧省通用航空重點實驗室,沈陽 110136)
0 引言
圖文檔是指與產品相關的信息中以圖檔或文檔形式存在的非結構化數據,如設計任務書、設計規范、三維模型、技術文件、各種工藝數據文件、制造資源文件、合同文件、技術手冊、使用手冊等,是制造類企業產品數據管理的主要信息資源。
現有的PDM(Product Data Management,產品數據管理)圖文檔存儲幾乎全部采用關系數據庫(RDB)和文件系統集成的方式實現。隨著MBD(Model Based Definition,基于模型的定義)技術的實施和PLM(Product lifecycle management,全生命周期管理)的應用,企業中的用戶幾乎“全員參與”。在圍繞三維模型的整個生命周期中包括需求、分析、設計、實施等環節會產生大量的圖文檔,這些數據隨著時間推移、產品型號增加等因素的影響,逐步呈現大數據態[1],基于RDB的PDM系統在高擴展性、高并發訪問和高可用性等方面存在的問題將會日顯突出——服務器和用戶終端機越來越“高檔”、存儲設備數量和容量越來越大、用戶訪問速度越來越慢、數據備份時間越來越長。
近年來,出現了以NoSQL為底層的云存儲系統[2],它既滿足高并發讀寫性能需求,又適用于服務器彈性擴展的需求。同時,考慮到部分圖文檔文件較大,而HDFS(Hadoop Distributed File System)能夠支持海量數據存儲,且易擴展,適合那些有著超大數據集的應用程序,可以很好地支持百MB及GB級的大文件。本文重點研究PDM圖文檔的存儲策略,將NoSQL數據庫加入以HDFS為基礎的企業私有云存儲平臺中,組建存儲資源網。
1 相關工作
采用數據庫方法存儲非結構化數據已有先例。文獻[3]采用RDB作為存儲底層,將非結構化數據直接存儲于數據表中,實現了非結構化數據和元數據的分離式存儲和統一管理。文獻[4]將文件數據分塊存入RDB,并對存儲過程和執行SQL語句直接存儲兩種方法進行效率分析得出最佳分塊大小。然而,由于RDB擴展困難,在用戶增多的情況下不能提供高性能服務。文獻[5]脫離關系數據庫存儲思想,采用非關系數據庫存儲非結構化數據,為云存儲提供了一種思路。文獻[2]中提出基于企業私有云的PDM系統結構,采用NoSQL數據庫作為底層數據支持環境,結構如圖1所示。
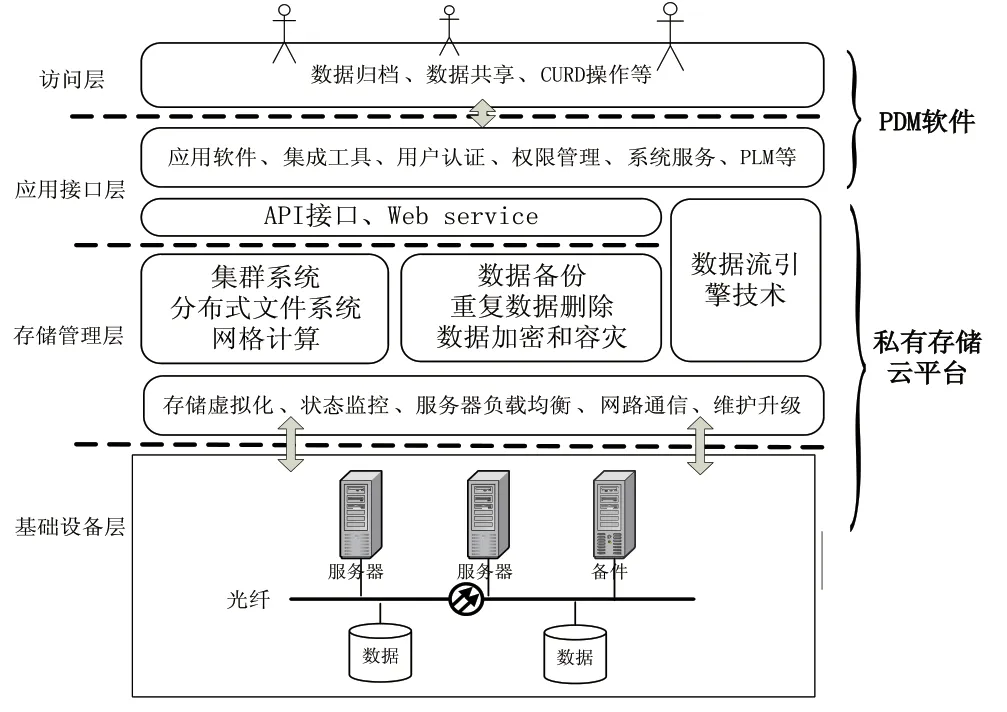
圖1 私有云存儲四層結構模型
云存儲的核心是應用軟件與存儲設備相結合,以實現存儲設備向存儲服務的轉變,用戶通過云存儲便能使用整個云存儲系統提供的數據訪問服務。但面對大量類型多樣的非結構化數據,單一的存儲系統不能提供高效的訪問能力。文獻[6]分析了關系數據模型和NoSQL數據模型各自的特點,提出了一種可以解決云計算中海量數據存儲管理問題的新數據模型。文獻[7]根據存儲系統執行操作的響應時間將非結構化數據自適應的存儲至相應的存儲子系統中。
2 圖文檔存儲模型
2.1 設計思想
在上述基于企業私有云的PDM系統結構的基礎上,借鑒分布式系統的存儲模型,將圖文檔的元數據(即描述該圖文檔的數據)和圖文檔數據分離,所有文件的元數據信息均保存至NoSQL數據庫中進行管理,圖文檔數據則分布存儲至以NoSQL和HDFS為支撐的私有云存儲中。數據分布存儲模型如圖2所示。
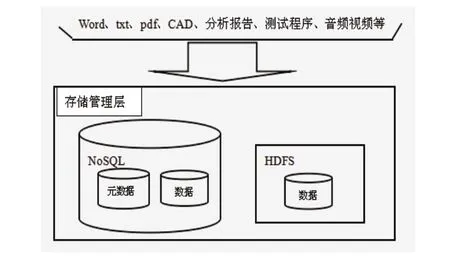
圖2 圖文檔存儲模型
存儲模型充分考慮了圖文檔的存儲需求和現有技術的結合。圖文檔類型多樣,而且數據大小極不規律,小則幾百字節,大則幾個G字節,因此存儲系統不僅需滿足高效存儲和低成本存儲,還需滿足小文件的快速響應及大文件的高吞吐量存取。對于文件數據,NoSQL和HDFS均是將數據劃分成統一的塊進行存儲,NoSQL的分塊大小一般在幾個M字節以下,支持高并發讀寫及海量存儲,但當文件太大時,數據所對應的元數據的數據量就會增多,造成存儲空間的極大浪費。而HDFS默認的數據塊的分塊大小是64M,可以很好地支持百MB及GB級的大文件,但由于它是以一定延時為代價來滿足高數據量吞吐而設計的,因此并不適用于低延遲訪問,且由于HDFS在對文件數據存儲管理時,需將文件系統的元數據放置在內存中,所能容納的文件數目由HDFS的內存大小決定,當小文件過多時,將占用大量元數據,降低了系統的存取能力和存取效率。
綜合以上情況,存儲模型采用NoSQL和HDFS共同支撐數據存儲,既可以減輕NoSQL的負擔,充分利用存儲空間,又能保證系統的高效存取,提高HDFS的元數據利用率。
2.2 存儲系統綜合評判模型
存儲模型是以文件大小作為依據進行數據劃分,實現小文件存儲至NoSQL,大文件存儲至HDFS。為有效減小決策的主觀性和不確定性,本文設計了存儲系統評判模型,通過對多個代價指標進行綜合評判,確定文件最優存儲位置。下面給出模型的形式化描述。
設文件大小為L,存儲系統為m,定義代價綜合評判值為該文件的存儲時間代價、讀取時間代價和文件分塊元數據(即描述文件分塊的數據,與文件元數據區分)占用空間代價的加權平均值,用Cost(L,m)表示,則有:
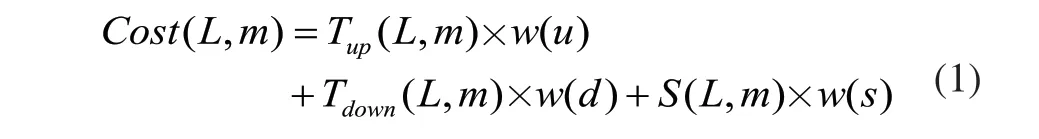
其中,w(u)+w(d)+w(s)=1,0<w(u),w(d),w(s)<1,m=1,2。Tup(L,m)、Tdown(L,m)、S(L,m)分別表示大小為L的文件在存儲系統為m的存儲時間代價、讀取時間代價和文件分塊元數據占用空間代價,w(u)、w(d)、w(s)分別為對應權值,m=1表示HDFS,m=2表示NoSQL,本文選用NoSQL之中的文檔型數據庫MongoDB進行實驗研究,因此這里m=2時表示MongoDB。
由于評價指標是定量的,所以在綜合評價前應先進行統一量綱的處理。式(1)中時間代價單位取ms(毫秒),空間代價單位取Byte(字節),相應的數值表示代價評分,數值越小表示代價越小。模型中選取分塊元數據占用空間代價作為評判指標是因為文件數據的存儲是將文件分塊后對一個或多個文件分塊和分塊對應的元數據的存儲,不同存儲系統對文件分塊的管理所需元數據空間代價不同。
本文設計的存儲平臺部署在一個高速交換網絡中,所以在計算存取代價時,網絡影響因素可以忽略不計。CPU頻率、內存等計算機系統因素也會對存取代價產生影響,但是這類因素很不穩定,難以通過調節這些因素來改進存取效率,因此也忽略這些因素。
在HDFS中,文件的存儲時間和讀取時間均包括啟動代價StartCost()和數據傳輸代價TransferCost(),數學表達分別如下:
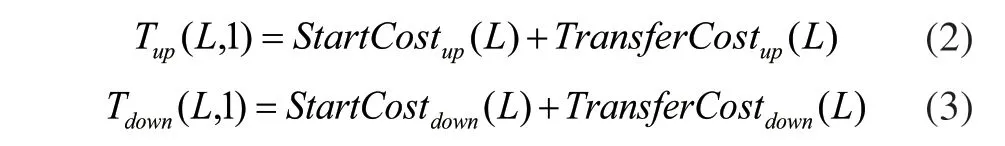
每一個文件、文件夾和Block需要占據150Byte 左右的空間,因此單個文件塊元數據占用至少300Byte。元數據的空間代價可表示如下:
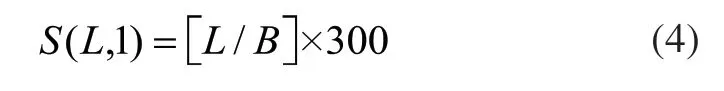
其中,B為HDFS塊大小,默認為64MB,[L/B]向上取整表示文件分塊塊數。
對于MongoDB,GridFS是其上的一種輕量級分布式文件存儲規范,它是將大文件對象分割成多個小的chunk(文件片段),利用了MongoDB的分布式存儲機制來實現文件存儲,適用于大量尺寸較小的文件,它的數據分塊大小C一般為256kB,文件分塊的元數據一般占用25Byte。則有:

由于所有文件的元數據均存儲至MongoDB,在對HDFS和MongoDB的代價綜合評判時考慮的是文件數據的存儲,因此對于MongoDB的文件存儲代價主要是指對文件分塊和與之相對應的分塊元數據的存儲。存儲時間包括文件分塊I/O時間和分塊提交數據庫所有時間,如式(6):
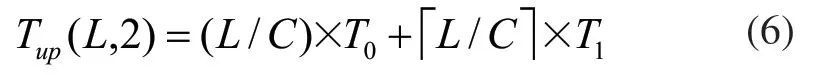
其中,T0表示文件分塊I/O所用時間,T1表示每個文件分塊提交數據庫所用時間。
讀取時間主要包括文件分塊的查詢時間和傳輸時間,其數學表達為:
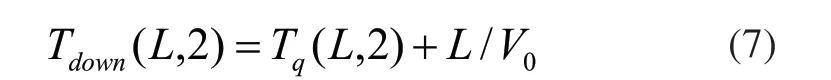
其中,Tq(L,2)表示對于文件分塊總的查詢時間,V0表示使用MongoDB時文件數據的傳輸速度。
式(1)中各指標的權值可以利用層次分析法(AHP)[8]進行計算。AHP是美國運籌學家托馬斯薩迪提出的一種層次權重決策分析方法,是對定性問題進行定量分析的一種簡便、靈活而實用的多準則決策方法。具體計算步驟如下。
步驟1:構造比較矩陣A。ai(i=1,2,3)表示評判指標。
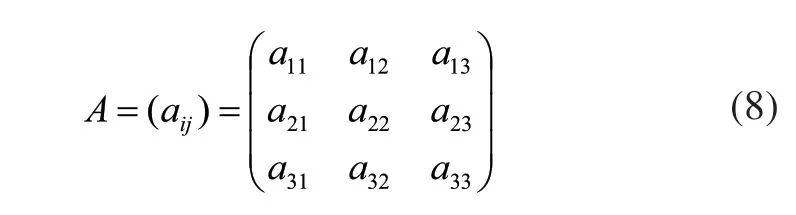
其中:

步驟2:構造判斷矩陣B:
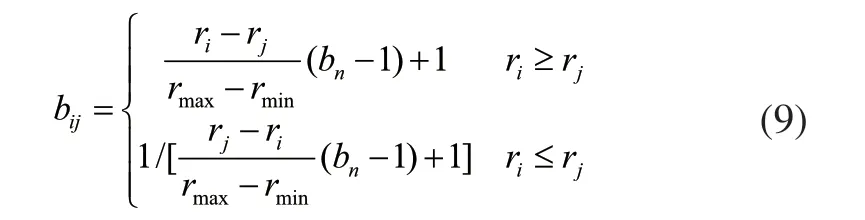
式中:
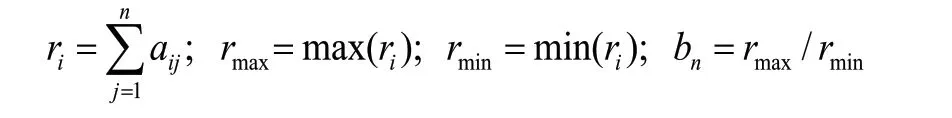
步驟3:計算出B的特征值和特征向量,將特征向量歸一化處理即得到與指標對應的權值。
在PDM系統中,對文件主要有上傳、下載、讀取等操作,由于讀取文件是最頻繁的操作,因此認定Tdown是最重要的,按照存儲模型設計思想,S次之,Tup重要性最弱。經計算,3個指標的權值如表1所示。
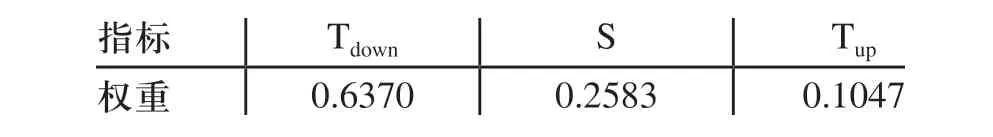
表1 各指標權值
3 實驗及結果分析
實驗環境為:三臺機架服務器和一個磁盤陣列。三個機架服務器中,一個為12核、24線程、16G內存,型號為A620r-G;另兩個機架服務器為24核、48線程、64G內存,型號為A840r-G;磁盤陣列有10T容量,型號為DS200-N10。在服務器上,搭建MongoDB和HDFS的云環境,HDFS包含1個namenode節點、1個snamenode和8個datanode節點,MongoDB由1個路由進程、1個配置服務器和6個分片節點構成。Hadoop軟件版本為1.2.1。MongoDB的版本為2.4.8。Java版本為jdk1.7.0_40。
本文以視頻文件為例,首先通過實驗1獲取不同長度的文件在HDFS的啟動代價以及存儲時間和讀取時間,計算出每塊數據塊的上傳和下載傳輸速度。然后再通過實驗2獲取文件在MongoDB的存儲時間和讀取時間,并將之與實驗1數據進行對比。最后給出HDFS和MongoDB的代價綜合評判值對比。
實驗1選取文件長度為275k、679k、1.04M、1.5 9 M、2.5 7 M、3.5 5 M、4.5 3 M、5.5 4 M、5.9 9 M、7.3 2 M、9.5 1 M、1 5.4 M、1 9.6 M、2 4.9 M、3 2.1 M、3 5.0 M、3 9.2 M、4 6.5 M、53.5M、60.8M進行存儲和下載,并且在不同的時段重復這樣的實驗10次。分別統計啟動代價、存儲時間和下載時間,并計算出兩種情況下傳輸不同文件長度的速度,結果如圖3所示。
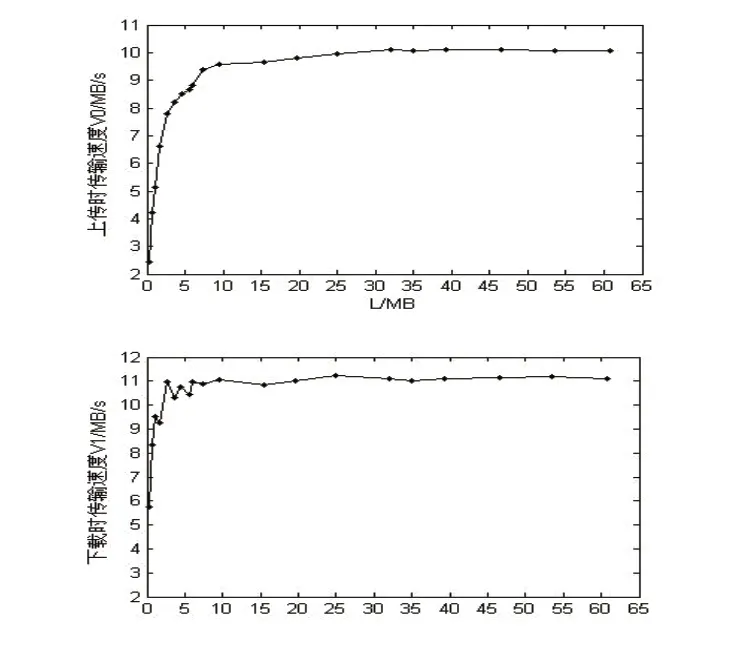
圖3 HDFS下文件上傳和文件下載時傳輸速度
經實驗測得上傳啟動代價在734ms~766ms范圍內,下載啟動代價在820ms~860ms范圍內。從圖3和圖4中可以看出,傳輸速度隨著文件大小的增加不斷提高,下載的傳輸速度在文件大小為3.55M以后穩定在11M/s左右,上傳時的傳輸速度在25M以后開始穩定在10MB/s左右,在15M~20M之間上傳速度約9.7MB/s。
實驗2分別統計MongoDB下文件存儲時間和讀取時間。取長度為275k、679k、1.04M、1.59M、2.57M、3.55M、4.53M、5.54M、5.99M、7.32M、9.51M、15.4M、19.6M、24.9M、32.1M、35.0M、39.2M、46.5M、53.5M、60.8M的視頻文件進行存儲和讀取,并且在不同的時段重復這樣的實驗10次。統計平均值,將最終實驗結果與實驗1得到的存儲時間和下載時間進行比較,如圖4所示。
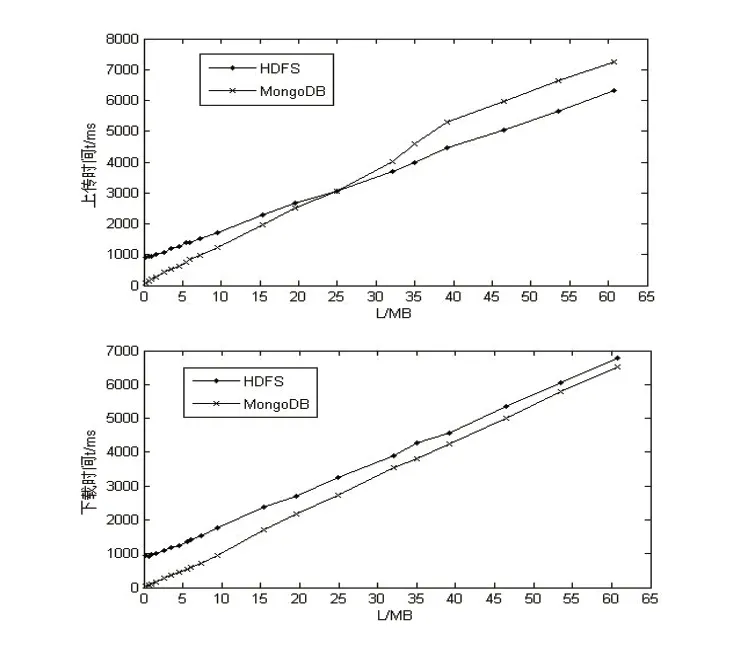
圖4 HDFS和MongoDB文件上傳時間和下載時間對比
MongoDB具有小文件存取優勢,存儲效率在25M以后低于HDFS,而文件讀取效率一直高于HDFS。
通過上述實驗數據計算出各存儲系統的代價綜合評判值,其中元數據占用存儲空間代價可以直接計算得出。對比結果如圖5所示。
從圖5中可以看出文件大小在15M~20M時,二者的代價綜合評判值基本持平。以上實驗是存儲系統低負載下對單文件的存取,數據分塊的搜索時間很短,可以忽略不計,將求得的各參數代入模型,當二者代價綜合評判值相等時得出文件長度為17MB。考慮到在MongoDB存儲的文件越大,分塊數就會越多,勢必會增加數據庫負擔,同時增加文件分塊的搜索代價,因此設置文件存儲閾值不應超過17MB,當文件大小低于存儲閾值時,將數據存儲至MongoDB,反之則存入HDFS。
該存儲評判模型確定的閾值可以實現存儲平臺在快速響應和高吞吐量之間的平衡,面對大中型企業海量圖文檔數據存儲,可以有效實現數據的均衡分布,既滿足大文件高吞吐量存取,又能滿足小文件的及時響應。對于小型企業,在大文件不是海量的情況下,可以考慮僅以MongoDB作為底層數據支持開發PDM系統。
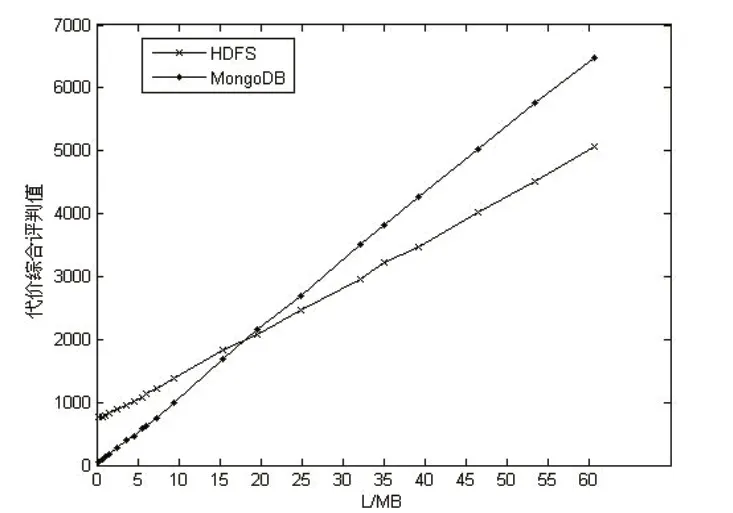
圖5 代價綜合評判值對比
4 結束語
傳統基于RDB的PDM圖文檔存儲系統已無法滿足海量數據存儲需求。針對圖文檔妥善存儲問題,本文結合NoSQL和HDFS面對不同類型非結構化數據存儲優勢,提出一種代價綜合評判模型,兼顧快速響應和高效存儲,通過實驗并結合多維屬性決策理論得出文件存儲閾值。在云存儲環境下,NoSQL數據庫存儲技術為PDM圖文檔存儲提供了一種新思路,下一步將對查詢進行優化,以實現對文件及文件塊的快速搜索。
[1] 夏秀峰,趙小磊,孔慶云.MBE與大數據給PDM帶來的思考[J].制造業自動化,2013,10(35):70-72.
[2] 申德榮,于戈,王習特,聶鐵錚,寇月.支持大數據管理的NoSQL系統研究綜述.軟件學報,2013,24(8):1786-1803.http://www.jos.org.cn/1000-9825/4416.htm.
[3] 謝華成,陳向東.面向云存儲的非結構化數據存取[J].計算機應用,2012,32(7):1924 -1928,1942.
[4] 宋國兵,陳奇.文件數據的數據庫Blob存儲及效率分析[J].計算機工程與設計,2010,31(21):4625-4626.
[5] 張艷霞,豐繼林,郝偉,單維鋒,沈焱萍.基于NoSQL的文件型大數據存儲技術研究[J],制造業自動化,2014,03(3):27-28.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
