基于改進多樣性密度的性別識別
2015-04-11 14:05:38顧明亮張世形
計算機工程與應(yīng)用 2015年7期
關(guān)鍵詞:分類
顧明亮 ,張世形 ,鮑 薇
1.江蘇師范大學(xué) 物理與電子工程學(xué)院,江蘇 徐州 221116
2.江蘇師范大學(xué) 語言科學(xué)學(xué)院,江蘇 徐州 221116
1 引言
20世紀90年代,Dietterich等[1]在對藥物活性預(yù)測問題的研究中,提出了多示例學(xué)習(xí)的概念,其目的是通過對已知適合或不適合制藥的分子進行分析來構(gòu)建一個學(xué)習(xí)系統(tǒng),以盡可能準(zhǔn)確地預(yù)測某種分子是否適合制造藥物。此后,國內(nèi)外很多學(xué)者對該問題進行了研究,并應(yīng)用于其他領(lǐng)域:Maron[2]將多示例學(xué)習(xí)應(yīng)用于股票投資中的個股選擇問題;Ruffo[3]將多示例學(xué)習(xí)應(yīng)用于數(shù)據(jù)挖掘;Andrews[4]、Huang[5]、Yang[6]、Zhang 等[7]分別將多示例學(xué)習(xí)用于圖像檢索;Chevaleyre等[8]用多示例學(xué)習(xí)研究了Mutagenesis問題并取得了理想成果。在多示例學(xué)習(xí)中,訓(xùn)練樣本的歧義性比較特殊,使得多示例學(xué)習(xí)模型與傳統(tǒng)的機器學(xué)習(xí)模型有很大差別。多示例學(xué)習(xí)的這種獨特性質(zhì)和良好的應(yīng)用前景,使得多示例學(xué)習(xí)被稱為與監(jiān)督學(xué)習(xí)、非監(jiān)督學(xué)習(xí)和強化學(xué)習(xí)并列的第四種機器學(xué)習(xí)框架。
多示例學(xué)習(xí)(multi-instance learning)問題可描述為:假設(shè)訓(xùn)練數(shù)據(jù)集中的每個數(shù)據(jù)是一個包(bag),每個包是一組示例(instances)集合,有一個訓(xùn)練標(biāo)記,而包中的示例沒有標(biāo)記。如果一個包被標(biāo)記為負包(negative bag),即用戶不感興趣的訓(xùn)練樣本,則包中的每一個示例為負例;如果包被標(biāo)記為正包(positive bag),即用戶感興趣的樣本,則包中至少一個示例為正例。學(xué)習(xí)算法通過對多個包組成的訓(xùn)練數(shù)據(jù)集進行學(xué)習(xí),生成一個分類器,以盡可能正確地對訓(xùn)練集外的未知包(unseen bag)進行預(yù)測。多示例學(xué)習(xí)框架可以用圖1來表示。

圖1 多示例學(xué)習(xí)框架示意圖
多示例學(xué)習(xí)提出后,國內(nèi)外很多學(xué)者對該問題進行了研究,并提出了很多有效的算法:Maron等[9]提出了多樣性密度(Diverse Density,DD)算法;Zhang等[10]將多樣性密度算法與EM算法結(jié)合起來,提出了EM-DD算法;Ramon等[11]構(gòu)造了多示例神經(jīng)網(wǎng)絡(luò);Zhou等[12]通過使用特殊的誤差函數(shù),提出了BP-MIP算法。
多樣性密度算法對后來的研究影響很大,很多學(xué)者都在此算法的基礎(chǔ)上進行了研究。戴宏斌[13]、王春燕[14]、陳綿書等[15]以及龍哲[16]分別運用多樣性密度算法進行了圖像檢索方法的創(chuàng)新與應(yīng)用。目前,還沒有學(xué)者將多樣性密度算法應(yīng)用于語音識別中。本文利用多樣性密度算法能夠有效發(fā)掘語音信號內(nèi)在規(guī)律和分布的特點,并提出Instances-k近鄰分類算法,探索了一種語音性別識別的方法。
2 多樣性密度算法及其改進
2.1 多樣性密度算法
1998年,Maron等[9]提出了多樣性密度算法。在該算法中,給出了多樣性密度的概念,并規(guī)定在屬性空間中某點周圍出現(xiàn)的正包數(shù)越多,且負包示例出現(xiàn)得越遠,則該點的多樣性密度越大。多樣性密度點示意圖如圖2所示。
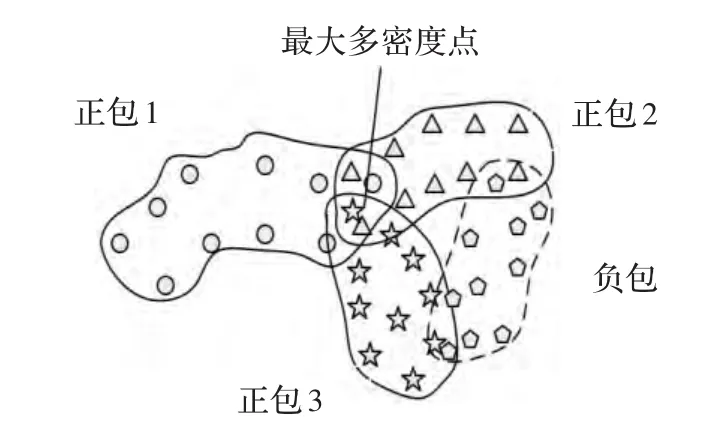
圖2 多樣性密度點示意圖
令代表第i個正包,代表第i個負包,則代表第i個正包中第j個示例的第k個屬性,代表第i個負包中第j個示例的第k個屬性。對于特征空間內(nèi)的任一點t,假設(shè)目標(biāo)概念點的概率為:
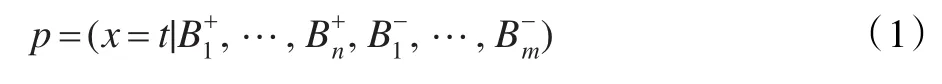
假設(shè)各包是條件獨立的,根據(jù)貝葉斯定理,上式可化為:
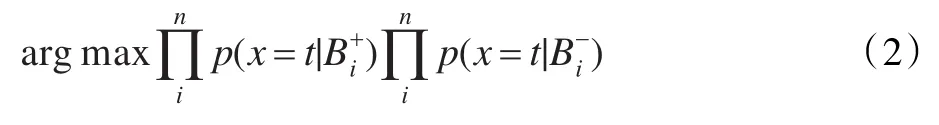
在實際應(yīng)用中,Maron使用了“noisy-or”模型,上式可化為:
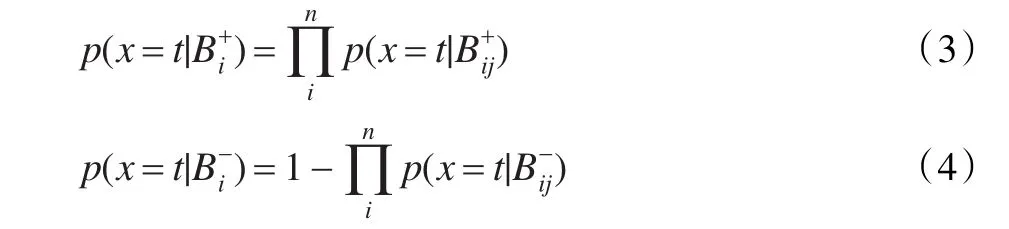
其中:
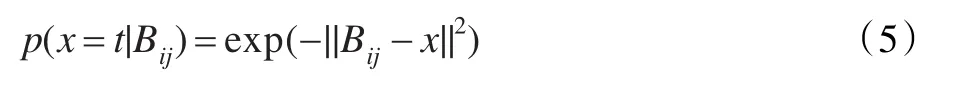
Zhang和Goldman提出了EM-DD算法[10],他們將DD算法與EM算法相結(jié)合來求解目標(biāo)特征t。EM-DD算法首先假設(shè)一個初始目標(biāo)特征h;然后E步從訓(xùn)練集的每個示例包中選出最靠近h的示例組成一個集合;再在M步中,采用梯度搜索法對E步中獲得的集合進行計算,得到一個新的使多樣性密度最大的特征點h′,用h′代替h。重復(fù)E步和M步到算法收斂為止。由于DD算法要進行多次梯度下降搜索來求解多樣性密度點,計算時間比較長,效率不高,而EM-DD算法將多示例轉(zhuǎn)變?yōu)閱我皇纠岣吡怂阉餍省?/p>
2.2 多樣性密度算法的改進
2.2.1 雙類別多樣性密度
雙類別多樣性密度的定義:在多類別訓(xùn)練樣本集合中,將A類訓(xùn)練樣本包標(biāo)記為正,其他類別樣本包標(biāo)記為負,通過EM-DD算法計算,得到A類樣本的正最大多樣性密度點PA;反之,將A類樣本包標(biāo)記為負,其他類樣本包標(biāo)記為正,則得到A類樣本的負最大多樣性密度點NA。如果待測未知包為A類樣本包,則未知包中包含距離點PA最近和距離點NA最遠的示例。
雙類別多樣性密度的基本思想是對多類別訓(xùn)練樣本集進行兩類多次標(biāo)記,以獲取訓(xùn)練樣本集的內(nèi)在規(guī)律與分布特點。假設(shè)樣本集合包含A、B、C三類數(shù)據(jù),以{A,B,C}樣本集合為例,PA、PB、PC分別代表A、B、C的正最大多樣性密度點,NA、NB、NC分別代表A、B、C的負最大多樣性密度點,則各最大多樣性密度點的標(biāo)記方式如表1。

表1 A、B、C的雙類別多樣性密度點的標(biāo)記方式
假設(shè)男性最大正、負多樣性密度點為PM、NM,女性最大正、負多樣性密度點為PF、NF,則男、女信號的最大正、負多樣性密度點通過圖3表示方式得到。
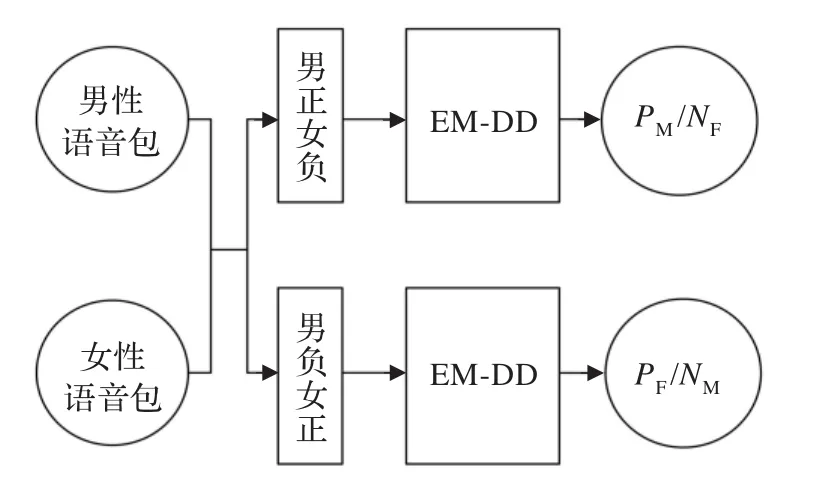
圖3 男、女信號的最大正、負多樣性密度點
語音信號中只包含男、女兩類信號,男性信號的最大正多樣性密度點PM也是女性信號的最大負多樣性密度點NF,同樣,點PF和點NM也為同一點。在語音識別技術(shù)中提取的語音特征往往是多維的:如32維、64維甚至是128維,因此很難在平面上描繪出樣本數(shù)據(jù)在空間中的具體分布。為了既形象又簡便地描繪多樣性密度算法原理,本文在繪圖時將多維數(shù)據(jù)“降維”至二維數(shù)據(jù),此時在樣本空間中點PM和點PF組成的雙點語言模型如圖4。
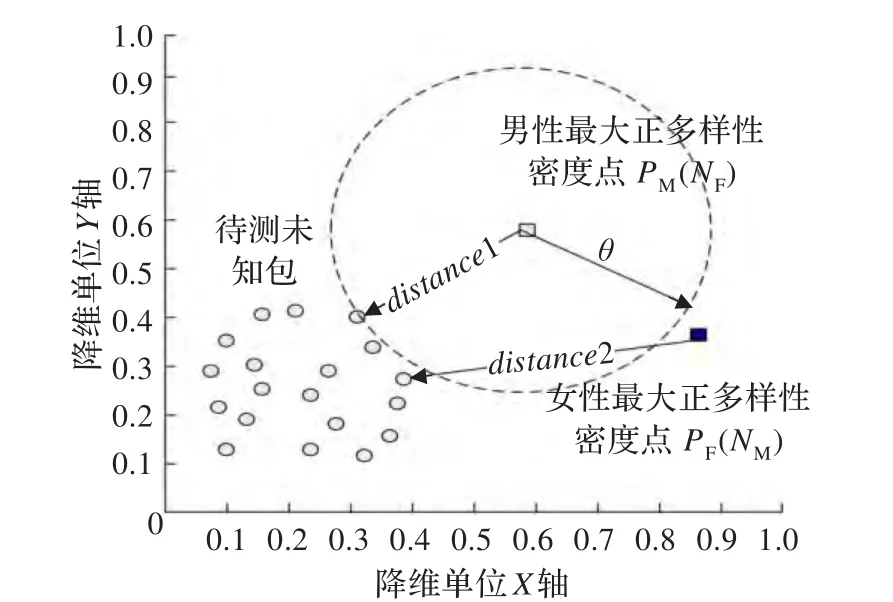
圖4 雙點模型下的分類判決
需要說明的是:在實際樣本空間中,圖4中虛線圓并不是一個平面圓,而是一個多屬性球,屬性數(shù)與提取的語音特征的維數(shù)相同。圖5和圖6采用同樣的描述方式。
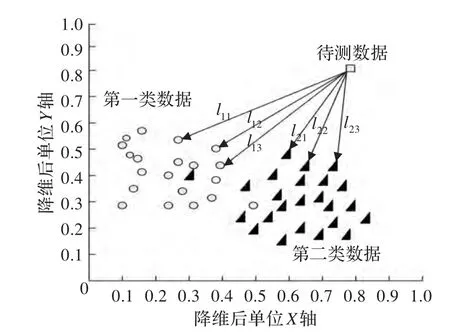
圖5 k近鄰分類算法
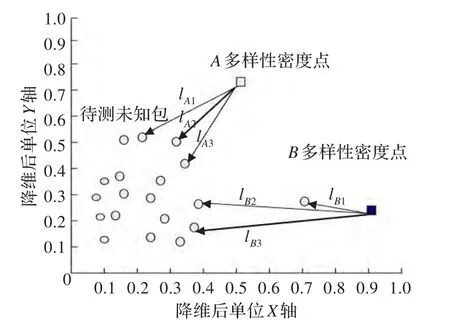
圖6 Instance-k近鄰分類算法
在傳統(tǒng)的單點模型中,對未知包進行分類判決時,首先需要大量計算示例空間中最近示例到多樣性密度點的距離作為參考數(shù)據(jù),然后人為地設(shè)置閾值θ。假設(shè)未知包中示例到男性樣本的多樣性密度點的最小Hausdorff距離為distance1,則判決公式如下:

在雙點模型下進行分類判決時,首先計算出示例空間中未知包中示例到兩類別多樣性密度點的最小Hausdorff距離distance1、distance2,然后比較距離的大小關(guān)系,具體判決準(zhǔn)則如下:

雙點模型下的判決不需要進行大量實驗來人為設(shè)置閾值θ,減小了系統(tǒng)的運算次數(shù),節(jié)省了時間,提高了系統(tǒng)的效率。
2.2.2 Instance-k近鄰分類算法
Instance-k近鄰算法的思想來自于理論上比較成熟的k近鄰分類算法。在k近鄰分類算法中,如果一個樣本在特征空間中的k個最鄰近樣本中的大多數(shù)屬于某一類別,則該樣本也屬于這個類別。圖5為k近鄰分類算法示意圖。
Instance-k近鄰分類算法:在示例空間中,選取未知包中距離各多樣性密度點最近的k個示例,計算這k個示例到各點的Hausdorff距離并求和,未知包屬于Hausdorff距離之和最小的那一類。圖6為Instance-k近鄰分類算法示意圖。
假設(shè)示例空間中存在三個多樣性密度點Pa、Pb、Pc,未知包中最近k個示例到各多樣性密度點的距離表示如下:
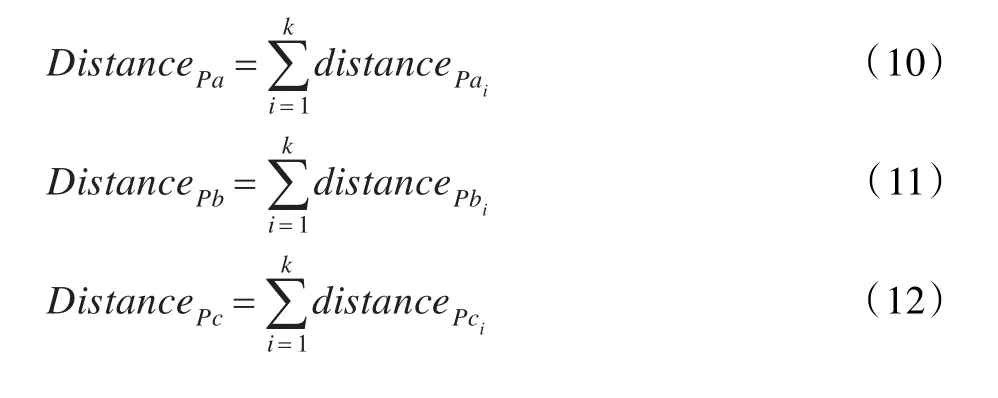
未知包類別屬于距離最小的多樣性密度點所屬類別:

當(dāng)Instance-k近鄰分類算法中k=1時,其實就是示例最近鄰分類算法。由圖5可以知道,在示例空間中,如果未知包中存在野點示例,最近鄰分類算法會受到野點示例的影響而錯誤分類。Instance-k近鄰分類算法可以有效地減小示例野點對分類判決的影響,從而盡可能正確地對未知包進行預(yù)測。
3 實驗設(shè)計與分析
本實驗語音全部采用國際標(biāo)準(zhǔn)OGI(Oregon Graduate Institute)語音數(shù)據(jù)庫。OGI語音數(shù)據(jù)庫包含11種國家的語言,每種語言都包含男女語音信號,本實驗只選取普通話。訓(xùn)練集共80人,其中男性42人,女性38人;訓(xùn)練語音時長約3 840 s,其中男性約1 920 s,女性1 920 s;測試集時長約500 s,男女性各250 s。訓(xùn)練集和測試集不交叉,采樣頻率為8 kHz,量化比為16 bit。訓(xùn)練集用于多樣性密度點的訓(xùn)練,測試集用于系統(tǒng)的測試。
3.1 語音包的生成
在多示例學(xué)習(xí)中,包的生成至關(guān)重要,本文語音包的生成分為三個步驟:首先,計算機讀取語音信號后進行預(yù)處理和特征提取;然后將特征集均勻切分為n段,其中n即為包的個數(shù);最后,采用k-means算法將每段特征向量集聚類為k個特征向量作為包中示例,k即為包中示例個數(shù)。圖7是包生成的原理框圖。
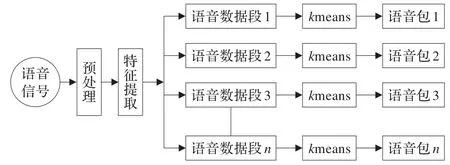
圖7 包生成原理圖
其中,預(yù)處理中所用的預(yù)加重濾波器為1-0.95z-1,窗函數(shù)為Hamming窗,語音信號幀長取256點,幀移為128點;由于MFCC特征是性別分類中最具區(qū)別性的參數(shù)之一,特征提取時提取語音信號的42維MFCC特征,包括對數(shù)能量、倒譜系數(shù)、一階差分系數(shù)和二階差分。訓(xùn)練包集由所有訓(xùn)練語音連接組成,包的最優(yōu)個數(shù)n和包中示例數(shù)k將通過實驗進行選擇;每一測試包由持續(xù)時長2.5 s的測試語音生成,示例數(shù)與訓(xùn)練包中的示例數(shù)相等。
3.2 實驗結(jié)果與分析
在尋找最優(yōu)數(shù)量的包數(shù)和示例數(shù)時,首先固定示例為32,比較不同包數(shù)對性別識別系統(tǒng)的影響。圖8表明當(dāng)訓(xùn)練包的數(shù)目不足200時,同一類別的最大多樣性密度點不容易被發(fā)現(xiàn),識別率不高;當(dāng)訓(xùn)練包數(shù)為200時,識別率最高,分別為男性93%、女性94%;當(dāng)訓(xùn)練包數(shù)大于200時,系統(tǒng)識別精度略有下降且趨于穩(wěn)定。綜合考慮計算成本與識別率,訓(xùn)練包數(shù)目設(shè)為200。

圖8 包數(shù)對性別識別系統(tǒng)的影響
考察示例數(shù)對性別識別系統(tǒng)的影響時,固定包數(shù)為200,改變示例的數(shù)量。觀察圖9可以知道,隨著示例數(shù)的增加,識別率會先提高后下降,且系統(tǒng)對示例數(shù)非常敏感。當(dāng)示例數(shù)設(shè)為32時,系統(tǒng)的平均識別率最高。
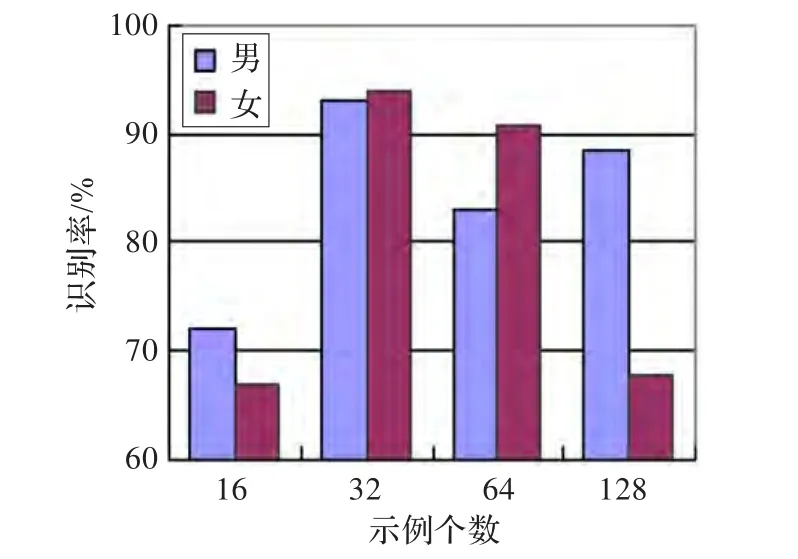
圖9 示例數(shù)對性別識別系統(tǒng)的影響
確定了訓(xùn)練包數(shù)目為200,示例數(shù)為32后,考察Instance-k近鄰分類算法中k的選擇對系統(tǒng)的影響。從圖10可以看出,隨著k的增加,識別率先提高后下降。當(dāng)k等于3時,系統(tǒng)識別率達到最高值:男性97%,女性98%,提高了系統(tǒng)的識別率。但是,隨著k值的增加,識別率也在不斷下降。
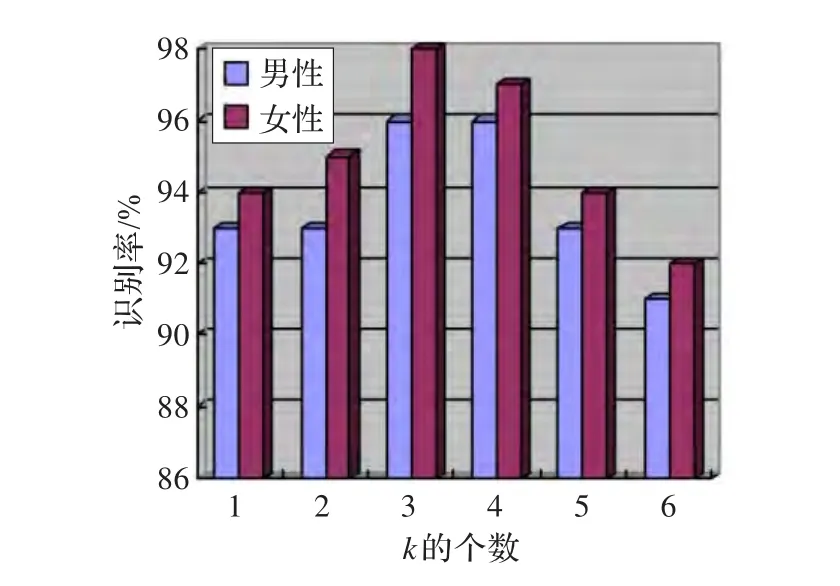
圖10 k值對性別識別系統(tǒng)的影響
Instance-k近鄰分類算法的作用是減小野點示例對分類判決的影響,但隨著k值的增加,即參與計算的示例數(shù)增加,與多示例學(xué)習(xí)中利用未知包中單一示例進行判決的差異性變大,判決結(jié)果可能會出現(xiàn)錯誤,圖10證明了這一點。
4 結(jié)束語
利用雙類別多樣性密度算法構(gòu)造了一個雙點語言模型,并在分類階段提出了Instance-k近鄰分類算法,進行了語音性別識別。實驗結(jié)果表明:采用改進多樣性密度算法的多示例學(xué)習(xí)在語音性別識別上是可行的,系統(tǒng)的平均識別率最終達到了97%。
另外,在多示例學(xué)習(xí)問題中,包的生成方法非常關(guān)鍵,將直接影響學(xué)習(xí)算法的分類結(jié)果。因此,在今后的研究學(xué)習(xí)中,將繼續(xù)探究語音信號的包生成問題,將作為多示例學(xué)習(xí)應(yīng)用于其他語音信號處理中。
[1]Dietterich T G,Lathrop R H,Lozano P T.Solving the multiple-instance problem with axisparallel rectangles[J].Artificial Intelligence,1997,89(1/2):31-71.
[2]Maron O,Ratan A L.Multiple-instance learning for natural scene classification[C]//Proceedings of ICML,Madison,USA,1998:341-349.
[3]Ruffo G.Learning single and multiple instance decision tree for computer security applications[D].Torino:University of Turin,2000.
[4]Andrews S,Hofman T,Tsochantaridis I.Multiple instance learning with generalized support vector machines[C]//ProceedingsofAAAI/IAAI,Edmonton,Canada,2002:943-944.
[5]Huang X,Chen S C,Shy M L,et al.User concept pattern discovery using relevance feedback and multiple instance learning for content-based image retrieval[C]//Proceedings of MDM/KDD2002 Workshop,Edmomton,Canada,2002:100-108.
[6]Yang C,Lozano P T.Image database retrieval with multipleinstance learning techniques[C]//Proceedings of ICDE,San Diego,USA,2000:233-243.
[7]Zhang Q,Goldman S A,Yu W,et al.Content-based image retirveal using multiple-instance learning[C]//Proceedings of ICML,Sydney,Australian,2002:682-689.
[8]Chevaleyre Y,Zucker J D.Solving multiple-instance and multiple-part learning problems with decision trees and decision rules:application to the mutagenesis problem[C]//Proceedings of LNAI,Berlin,German,2001:204-214.
[9]Maron O,Ratan A L.A framework for multiple-instance learning[C]//Proceedings of NIPS,Cambridge,USA,1998:570-576.
[10]Zhang Q,Goldman S A.EM-DD:an improved multipleinstance learning technique[C]//Proceedings ofNIPS,Cambridge,USA,2001:1073-1080.
[11]Ramon J,Raedt L D.Multi-instance neural networks[C]//Proceedings of ICML,Stanford,USA,2000:53-60.
[12]Zhou Z H,Zhang M L.Neural networks for multi-instance learning[C]//Proceedings of ICIIT,Beijing,2002:455-459.
[13]戴宏斌,張靈敏,周志華.一種基于多示例學(xué)習(xí)的圖像檢索方法[J].模式識別與人工智能,2006,19(2):179-185.
[14]王春燕,袁津生.一種結(jié)合多示例學(xué)習(xí)的圖像檢索方法[J].計算機系統(tǒng)應(yīng)用,2010,19(6):212-215.
[15]陳綿書,楊樹媛,趙志杰,等.多點多樣性密度算法及其在圖像檢索中的應(yīng)用[J].吉林大學(xué)學(xué)報:工學(xué)版,2011(5):1456-1460.
[16]龍哲.基于多樣性密度的多示例學(xué)習(xí)方法[J].工業(yè)控制計算機,2012,25(7):73-74.
猜你喜歡
西北民族大學(xué)學(xué)報(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
