基于AssiStudy的形成性評價系統及學生進程監測*
2015-06-04 06:38:04孟凡茂
現代教育技術 2015年5期
孟凡茂
(臨沂大學 外國語學院,山東臨沂 276005)
一 引言
在最近的計算機輔助評價(Computer-Assisted Assessment,CAA)系統中,評價策略是基于每道題的正確答案,該答案在學生答案(Students Answers,SAs)評價中被用作參考答案(Reference Answer,RA)。RA和SAs之間的相似性是根據詞的共現,通過傳統的信息檢索(Information Retrieval,IR)技術來確定,尤其是處理較長文本時,這種方法通常很有效,這是因為相似的長文本往往同現詞的頻率高。然而,在較短的自由文本答案中,詞的同現可能很少或沒有,意思卻近似。同時,RA不應是唯一的,因為一個問題可能會有多個不同的答案[1]。其次,另外一個負面因素是沒有考慮到教師的評價標準,僅僅考慮的是RA和SAs之間的相似度。
為此,我們研發了輔助學習(Assisted Study,AssiStudy)系統作為學生的形成性評價工具,該系統能幫助教師設計和評價考試并監測學生的進展情況。在自動評價答案的過程中,該系統依據單詞及其POS標簽,對每個問題都自動生成幾種RAs,這樣,學生所提交的答案就可以與幾種RAs進行比對,從而確保了更為準確的判分;通過各種自然語言處理(Natural Language Processing,NLP)技術,AssiStudy先將RA和SAs轉換成更易處理的規范形式,通過在RA中搜索SAs的近似詞,進行單詞匹配運算,并根據SA和RA之間的共有詞義,計算出近似得分,這種方法更適合于用來評估內容相似而相同詞幾乎不共現的簡短答案。
二 CAA的方法綜述
自20世紀60年代以來,CAA就一直是一個不斷發展的開發領域。CAA系統評估論述題答案的方式分為三類:形式、內容或者二者兼有。目前CAA系統中最為重要的方法是統計法(Statistical)、潛在語義分析法(Latent Semantic Analysis,LSA)和自然語言處理法。最初的CAA系統的評價方法主要用來捕捉文本結構的相似性;之后的CAA都基于LSA,超出了對簡單共現詞的分析,采用兩種解決問題的途徑,即基于語料庫技術和代數法來識別比較兩個措辭不同的文本之間的相似性;最近的CAA都是基于NLP技術,能夠進行智能分析,捕獲自由文本文檔的語義信息。但是,絕大多數CAA系統從兩個維度評分,而且,這些系統所采用的方法差別很大。最近,教育數據挖掘(Educational Data Mining,EDM)應運而生。EDM具備四項功能:學習建模、輔導、信息存儲和評價[2]。為了既支持評價也支持預備基架,通過結合文本回放標記所研發的模型、環境對學生的探究技能做出推論,這種方法能夠對學生日志文件和教育數據挖掘迅速地進行人工編碼。
以上這些系統都不適于我們的用途,因為它們只能處理英文文本,而且需要學習大量的文本。為此,我們創建了AssiStudy系統,該系統通過廣泛應用文本預處理技術和詞匯網路(WordNet)數據庫,極力減弱對大型語料庫的需求,從而公平地評價內容簡短的文本答案。
三 AssiStudy系統架構
鑒于服務導向式架構(Service-Oriented Architectures,SOA)[3]的各種優點(如:模塊化、互操作性和可擴展性),我們研發了一個以SOA為基礎的系統進行形成性評價和終結性評價。該AssiStudy體系結構主要由以下四個層所組成:
客戶端應用程序層(Client Application):該層用來處理數據和流程的安全性和隱私;
業務層(Business):該層包含了AssiStudy的主要模塊,每一個模塊都包含一組可用的核心服務,在不同層級中分離業務邏輯將會使得AssiStudy具有模塊化和靈活性;此外,該層能夠以一種簡易且靈活的方式更新業務邏輯;
服務層(Service):在該層中,可通過服務注冊中心直接調用域名Web服務;
資源層(Resource):該層包含了AssiStudy的基礎結構資源,即數據庫以及與域相關的系統和工具,譬如:學校信息系統和協作學習工具,其中每個系統和資源都有一組Web服務。
AssiStudy作為通用而又靈活的系統得以開發。說它通用是因為它能夠應用于任何領域的研究,該系統的創建目的就是處理不同的知識領域;同時,它又是靈活的,因為它既可以作為一個獨立系統,也可以通過Web服務,增加新模塊或特殊種類的應用程序。圖1所描繪的就是該系統架構的概貌。
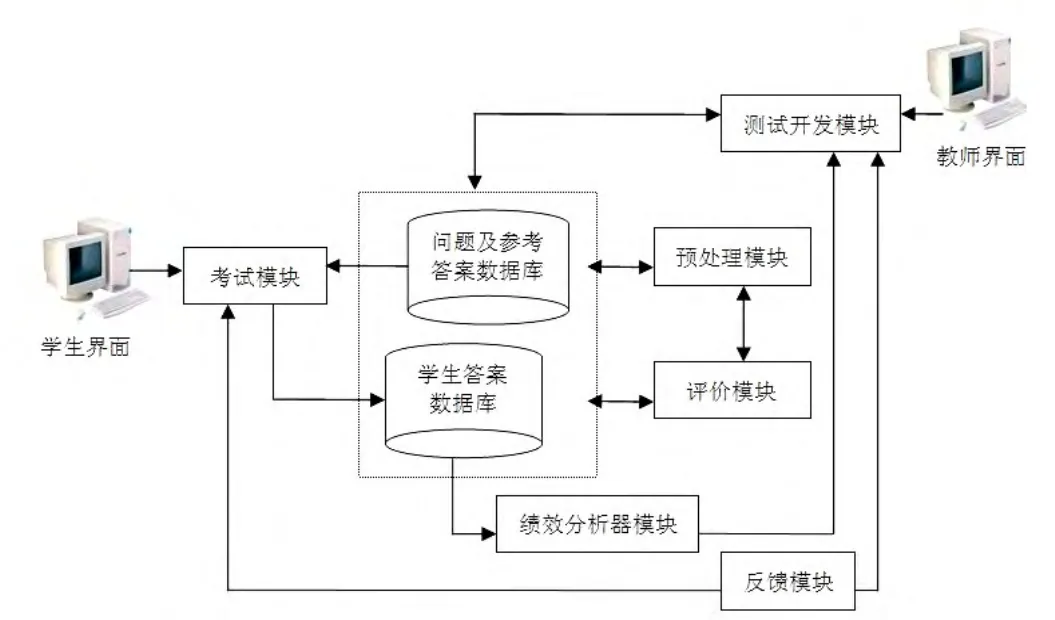
圖1 AssiStudy系統體系結構
1 測試開發模塊
通過該模塊,教師可以查詢在以前的考試判分中涉及某一個特定方面的所有問題,這些問題都被存儲在問題及RA(Question&RA)數據庫中。此外,教師有可能查閱每道題目的難度級別,當然,這種難易度的判別要基于之前的考試中學生的得分情況。再者,對于某個指定的題目,教師對學生所做的所有考題及得分都有訪問權限,這樣教師在考前就能了解他們要評估的學生對于不同考題內容的準備情況,從而,就能更為恰當地評價每個班級的考試情況。
考試評估由AssiStudy完成,之后老師再進行核查。一個班級的考試評判一旦完畢,其中的問題以及與此相關的所有信息都會被存儲到問題及參考答案(Question&RA)的數據庫中,在其后的訓練考試時就可據此加以說明。SAs都存儲在學生答案數據庫(Student Answer Repository)中;獲得滿分的論述題的SAs也存儲在Question&RA的數據庫中,以便在將來的評價程序中進行應用。Question&RA的數據庫非常重要,因為AssiStudy系統中幾乎所有模塊的成功與否在很大程度上取決于該數據庫的優劣。
2 考試模塊
根據學生的狀況以及教師在先前的模塊中所限定的內容,訓練考試會從Question&RA庫中隨機選擇考試題目。假如大一新生在第一學期首次考試,該系統將根據學生的檔案信息,試題會依據前面所述的五個話題方面的內容自動生成,但其中每個話題的問題數量和難度由AssiStudy界定。學生已做過的試題及得分都被記錄下來,并計算出學生對每個話題的定性得分(低、中或高),這些信息都被存儲在Student Answer Repository中。另外,Question&RA的數據庫中儲存了很多試題,除了其他的屬性外,每一道題都被標識出其內容歸屬、難度和分數,根據這些信息和一定程度的隨機化,AssiStudy將會自動從Questions&RA庫中挑選試題,為每位學生設計出訓練試題。評估訓練考試僅靠AssiStudy系統完成,糾錯則需由反饋模塊中所設立的解釋來彌補。
3 預處理模塊
(1)檢測專有名詞:在英文文本情況下,檢測單詞開頭首字母是否大寫;
(2)刪除標點符號:該項任務就是要刪除所有特殊字符并將所有字母轉換為小寫,除非是專有名詞。特殊字符是指不屬于單詞的一些符號(如:標點符號),但單詞的重音符號予以保留,以免誤認為是拼寫錯誤;
(3)校正單詞拼寫錯誤:用來檢查拼寫錯誤的校正器是Jspell[4];除了檢測錯誤拼寫外,Jspell會提示正確的單詞,拼寫錯誤的單詞會被正確的單詞替換;
(4)刪除無用詞:無用詞與內容無關,刪掉它不影響句子的語義;
(5)詞干提取:在這個階段,將個別單詞簡化為其基本型或詞干,一個單詞的基本型即是其詞根或詞元;
(6)文本標記:該項任務就是給單詞標注詞性(Part of Speech,POS)標簽,此項操作也是由Jspell[7]完成;這種分類要求對標注相同POS的單詞進行對比;一個單詞可能會有多個POS標簽,依照其出現的語境而定;正是由于各種不同的可能詞性,該Jspell形態分析器會給每個單詞標注可能的POS標簽;為了避免詞性標注的模糊性,在編輯程序中將呈現規范標準的RAs,這樣,教師就可以正確地選擇每個單詞的POS標簽,而其他標簽會自動刪除;
(7)同義詞:一個詞的同義詞列表取決于其POS標簽,每一個單詞會有一個與其POS標簽相關的同義詞列表,把涉及該單詞的所有同義詞以及它們的POS標簽添加到RA中,從而完全相同的RA會產生幾種解釋;一個單詞與其每一個同義詞之間的匹配得分是通過WordNet.pt詞匯數據庫[5]分析它們之間的最短路徑得出,為了測量兩個單詞之間的語義關聯度,前人已通過語義網絡信息研究出了多種測量方法。本研究中,鑒于在WordNet層次結構方面相對較高的計算效率,我們選擇了Leacock&Chodorow(L&Ch)的測量方法,L&Ch相似度的計算公式為:
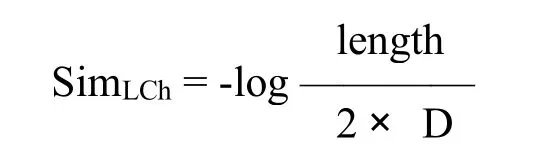
該公式中,length指通過計數節點所得的兩個概念之間最短路徑的長度,D代表分類的最大深度。
4 評價模塊
該模塊能夠自動得出一個分數,并由此根據規范的RA和 SA的意義顯示出這兩者之間的相似性,從而勝過簡單的詞匯匹配。這一目標的實現是在計算出SA和 RA之間總的語義相似度之后,根據相應的RA的語義相似度,構建SA向量。根據SA向量和RA之間的距離,RA就是該單位向量,如圖2所示。
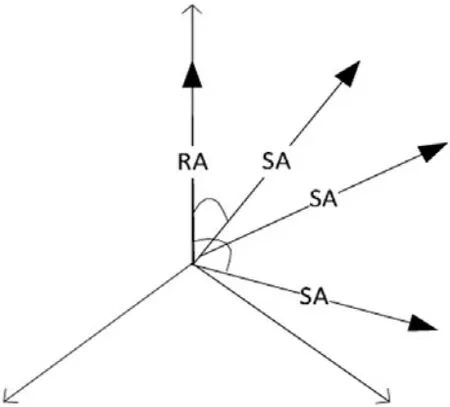
圖2 空間向量模型
SA向量和RA向量之間的相似度取決于歐幾里得(Euclidean)點積,公式如下:

5 反饋模塊
AssiStudy提供的反饋由學生得分和RA中所收集的答案信息構成。為此,SA中遺漏或不完整的要點會在RA中得以搜索,而且相關的分數以及詳細的解釋會得以呈現。AssiStudy自動反饋的其中一大優點就是學生獲知反饋迅捷,即測試提交完畢學生即可獲得反饋,如此能促進學生更加深入的學習;而教師能夠看到每位學生的答卷及評語,了解學生的得分情況,同時,也能知道全班遺漏的最為重要的知識點,從而能夠迅速獲悉整個班級的學習情況。
6 表現分析器模塊
該模塊是基于統計和數據挖掘(Statistics and Data Mining)技術研發,其設計目的是分析有關評判結果的數據。我們研發了幾種數據挖掘模式來洞察學生有關訓練考試成功與否的情況。最為有用的模式通過k平均聚類算法(Clustering Algorithm K-means)[6]獲取,這樣就能獲悉哪些問題難哪些問題易,并通過信息分析,修改問題的難易度。而使用C4.5分類算法(Classification Algorithm C4.5)[7],對學生訓練考試進行分析,就能推斷出學生或班級對于即將來臨的評價考試的準備狀況。另外,通過關聯規則Apriori算法(Association Rule Algorithm Apriori)[8],就能發現訓練試題與學生最終成績之間的關系,從而了解學生對哪些問題準備得更好。
四 評價與分析
為了檢查AssiStudy系統在提高過關率方面的有效性,我們進行了一次測試。表1顯示:使用AssiStudy的學生平均過關率比不使用該系統的學生的過關率高(t=57.65,df=533,p<0.05),因此,通過AssiStudy能提高通過率。
同時,我們也對考試自動評價與教師評價進行了對比。表2顯示了2012-2013學年4次考試中教師評分和系統評分情況。

表1 經過AssiStudy訓練和沒有經過訓練的過關學生數量對比
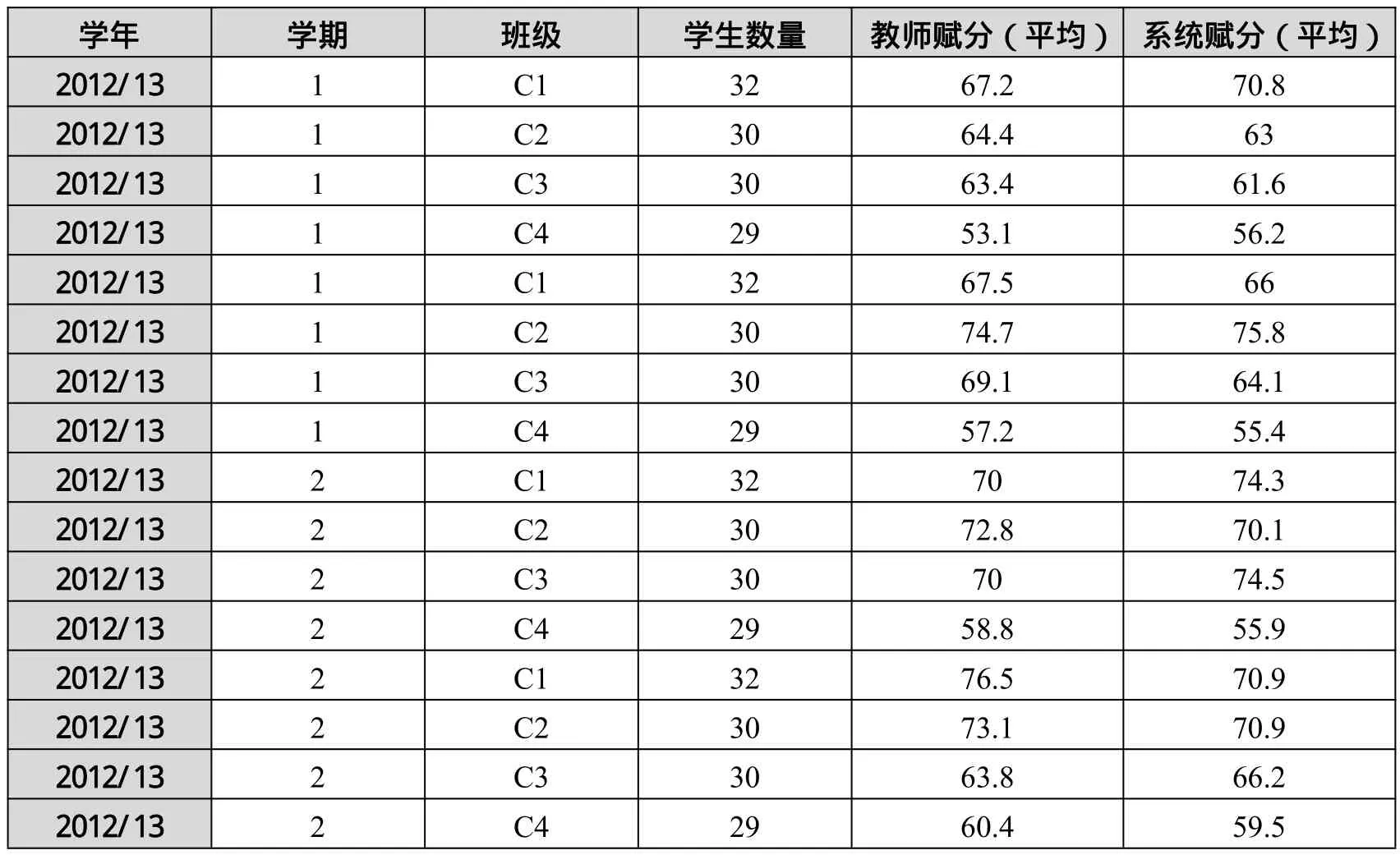
表2 2012-2013學年考試中的分值情況
結果顯示:對于不同的考試評分,教師判分與系統判分差別并不太大;教師評判與系統評判之間的皮爾遜相關系數(Pearson correlation)為0.88。
AssiStudy系統的誤差分析顯示,誤差分為兩類:漏判(False Negatives,FN)和誤判(False Positives,FP)。當考試得分比應得分數低時,就會發生FN;而FP是指判分過高。一般而言,如果系統與教師判分不匹配,通常是因為教師判分略高,這是因為SA太抽象或比RA短少,而在這種情況下,AssiStudy系統判分會比預期的分數低,這是因為系統的判分標準是基于詞的匹配,而且,有些SAs在RA中無匹配的格式所致,但是,教師卻能根據SAs推斷出學生對于所學的理解程度,從而,判分時給出較高的分數,這樣就增大了系統評價與教師評價之間的差異;而當學生不知道問題答案,碰巧又寫出了一些與RA相匹配的單詞時,系統判分最易發生FP。
五 結論
AssiStudy系統不僅可以作為對學生考試的形成性評價工具,也能幫助教師創建并評價考試,還可以監控學生的學習進展狀況。實驗證明,采用AssiStudy系統進行訓練的學生比不參與的學生會獲得更高的成績,考試通過率大大提高;而對于教師而言,該系統的研發非常實用,因其能大大減輕教師閱卷的工作量。
[1]Noorbehbahani F,Kardan A A.The automatic assessment of free text answers using a modified BLEU algorithm[J].Computers&Education,2011,(2):337-345.
[2]Pe?a-Ayala A.Educational data mining:a survey and a data mining-based analysis of recent works[J].Expert Systems with Applications,2014,(4):1432-1462.
[3]Al-Smadi M,Gutl C.SOA-based architecture for a generic and flexible e-assessment system[A].In Education engineering(EDUCON),2010 IEEE[C].2010:493-500.
[4]Sim?es A M,Almeida J J.Jspell.pm–a morphological analysis module for natural language processing[A].In Actas do XVII Encontro daAssocia??o Portuguesa de Linguística[C].Lisbon,2001:485-495.
[5]Marrafa P,Amaro R,Chaves R P,et al.WordNet.PT new directions[A].In Proceedings of GWC.2006,(6):319-320.
[6]Hartigan J A,Wong M A.Algorithm AS 136:a k-means clustering algorithm[J].Journal of the Royal Statistical Society,Series C(Applied Statistics),1979,(1):100-108.
[7]Quinlan J R.C4.5:Programs for machine learning Morgan Kaufmann,1993,(1):235-240.
[8]Agrawal R,Imieli_nski T,Swami A.Mining association rules between sets of items in large databases[J].ACM SIGMOD Record,1993,(2):207-216.
猜你喜歡
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
