片上光電互連的多核系統(tǒng)仿真方法
2015-07-11 10:09:56于績洋華幸成楊建義
浙江大學(xué)學(xué)報(工學(xué)版) 2015年11期
于績洋,劉 鵬,華幸成,馬 驤,楊建義
(浙江大學(xué) 信息與電子工程學(xué)院,浙江 杭州310027)
隨著多核(Multicore)系統(tǒng)處理器數(shù)量的增加,網(wǎng)絡(luò)與互連結(jié)構(gòu)變得越來越重要;對于未來片上多核處理器結(jié)構(gòu)如何選擇設(shè)計片上網(wǎng)絡(luò)目前還是未解決的問題.
在多核互連結(jié)構(gòu)中,隨著節(jié)點數(shù)量的增加,傳統(tǒng)電互連技術(shù)逐漸顯示出帶寬不足、功耗過大等問題.相比之下,光互連技術(shù)具有時延低、傳輸帶寬大、功耗開銷少等優(yōu)點.如何在成熟的電互連技術(shù)基礎(chǔ)上,配合光互連結(jié)構(gòu),實現(xiàn)可擴展的片上光電互連拓?fù)浣Y(jié)構(gòu),發(fā)揮光器件與電器件各自的優(yōu)勢,提高吞吐率,有著重要的研究意義.
在研究片上互連結(jié)構(gòu)時,通常有2種方式,硬件模擬與軟件仿真.傳統(tǒng)的硬件仿真設(shè)計方法,存在著開發(fā)周期長、實現(xiàn)成本高、靈活性不夠等方面的不足.而軟件模擬的方法靈活性好,可以在設(shè)計初期對某個結(jié)構(gòu)進(jìn)行快速評估.在面向多核互連的系統(tǒng)設(shè)計時,用軟件模擬對系統(tǒng)性能進(jìn)行快速評估,成為一種有效的解決方案.
目前比較成熟的軟件模擬方法已經(jīng)可以對片上多核網(wǎng)絡(luò)系統(tǒng)進(jìn)行較為準(zhǔn)確的評估,但是由于光子和電子不同的物理性質(zhì),已有的典型網(wǎng)絡(luò)仿真無法準(zhǔn)確的得到片上光電互連的性能特點.例如Chan等[1]提出的PhoenixSim 工具基于器件的物理層特性,提供了硅光器件參數(shù)化模型;但PhoenixSim 只對硅光器件建模,忽略了光電轉(zhuǎn)換模塊,未對頻率響應(yīng)特性進(jìn)行建模.Sun等[2]提出的DSENT 工具可以依據(jù)光電技術(shù)參數(shù),構(gòu)建片上網(wǎng)絡(luò)單元的框架結(jié)構(gòu),實現(xiàn)對光電片上互連網(wǎng)絡(luò)的面積和功率評估;但是DSENT 不支持處理器的系統(tǒng)仿真,缺少存儲器功耗模型.Miller等[3]提出的Graphite工具實現(xiàn)了光電互連的系統(tǒng)級仿真,但由于采用了松同步機制,不能做到周期級的精確仿真,限制了在體系結(jié)構(gòu)探索研究方面的作用.
本文提出了一種面向光電互連系統(tǒng)的仿真方法,通過對光電器件的獨立精確建模,使得器件庫與功能模型、時序模型和成本模型協(xié)同工作;增加對多線程編程的支持,擴展了仿真規(guī)模,實現(xiàn)16 至256核光電互連系統(tǒng)的周期級精確仿真.
1 相關(guān)工作
學(xué)術(shù)界對片上互連網(wǎng)絡(luò)的建模已進(jìn)行了深入研究,提出了不同的片上網(wǎng)絡(luò)的時序、功耗和面積模型,開發(fā)了模擬仿真工具.Chien等[4]提出了路由元件的時間和面積模型,將該模型曲線匹配到一個特定的過程,但沒有證明這個模型隨著工藝技術(shù)的規(guī)模變化是否能繼續(xù)適用.Orion[5]為電網(wǎng)絡(luò)中的路由和鏈路構(gòu)件提供了參數(shù)化的功率和面積模型.但是Orion沒有為路由和鏈接提供參數(shù)化的功率和面積模型,缺少路由元件的延遲模型.DSENT[2]在光電片上網(wǎng)絡(luò)設(shè)計中,依據(jù)電光技術(shù)里的參數(shù),構(gòu)建片上網(wǎng)絡(luò)構(gòu)造單元的框架,可對光電片上聯(lián)接做跨層次的面積和功率評估.但是DSENT 不支持處理器的系統(tǒng)仿真.
在光電互連仿真方面,PhoenixSim[1]用于協(xié)助研究者在考慮器件物理層特性的基礎(chǔ)上探索硅光子片上網(wǎng)絡(luò).PhoenixSim 提供了光器件細(xì)致的參數(shù)化模型,并利用模塊化、層次性強的NED 語言在基本元件的基礎(chǔ)上形成高層網(wǎng)絡(luò)元件甚至是整個網(wǎng)絡(luò).但是PhoenixSim 在處理網(wǎng)絡(luò)能耗方面并沒有把光和電結(jié)合起來,它依賴Orion處理所有電路由和鏈路的能耗,在光電接口電路(如調(diào)制器,接收器)中使用固定能耗,無法觀測到由晶體管技術(shù)、數(shù)據(jù)速率和調(diào)諧情景變化帶來的很多動態(tài)特性.Graphite[3]是一個并行化、分布式的多核模擬器.仿真模型包括功能模型和性能模型,支持程序級的仿真,對處理器、程序行為、線程、網(wǎng)絡(luò)層進(jìn)行建模,集成McPAT[6]和DSENT 接口,評估能耗和面積.Graphite利用C++類的繼承調(diào)用,實現(xiàn)與光網(wǎng)絡(luò)的連接,光器件作為網(wǎng)絡(luò)層模型的子模型,從而實現(xiàn)從頂?shù)降椎南到y(tǒng)設(shè)計空間探索平臺.但是Graphite采用的是松同步(LaxP2P)機制,在并行仿真時,Graphite會將存儲操作的順序要求放寬至幾千個機器周期,這樣做提高了仿真速度,卻損失了仿真精度,不能做到周期級精確的仿真.
在光電互連結(jié)構(gòu)的探索方面,Briere等[7]開發(fā)出片上光網(wǎng)絡(luò)的SystemC模型,用SystemC框架對片上光網(wǎng)絡(luò)進(jìn)行模擬,解決了設(shè)備調(diào)速和網(wǎng)絡(luò)層面功耗的問題.Optisim[8]系統(tǒng)級模型器可對基于板和簇的計算系統(tǒng)中的光互連進(jìn)行模擬.O'Connor等[9]為異質(zhì)的光集成電路提出了一個鏈路層仿真環(huán)境.但這些研究工作對于底層細(xì)節(jié)的仿真不足,無法評估光電互連對于體系結(jié)構(gòu)層次上的影響.Corona[10]采用的是光總線結(jié)構(gòu),該結(jié)構(gòu)基于光波導(dǎo)的波分復(fù)用特性,無需路由無需交換,是一種共享傳輸通道的結(jié)構(gòu);ATAC[11]結(jié)構(gòu)也是基于光總線的分層網(wǎng)絡(luò);這2項研究工作對光電互連網(wǎng)絡(luò)進(jìn)行了結(jié)構(gòu)上的探索.
本文結(jié)合光電器件庫的精確建模,構(gòu)造了面向多核的片上光電互連系統(tǒng)的仿真框架;仿真模型包括功能模型、時序模型和成本模型,實現(xiàn)了多核光電互連系統(tǒng)的周期級精確仿真;利用多線程技術(shù)對構(gòu)造的仿真框架進(jìn)行規(guī)模擴展,支持16至256核系統(tǒng)的仿真,探索了多核光電互連系統(tǒng)設(shè)計空間,并采用系統(tǒng)仿真框架對ATAC和Corona拓?fù)浣Y(jié)構(gòu)進(jìn)行性能評估.
2 系統(tǒng)仿真概述
與硬件設(shè)計相比,采用軟件的方法對目標(biāo)結(jié)構(gòu)進(jìn)行系統(tǒng)建模,具有開發(fā)周期短、容易修改、靈活性性高等優(yōu)點,更適合在較短時間內(nèi)對大量設(shè)計方案進(jìn)行評估.因此研究人員中通常會借助軟件手段對目標(biāo)系統(tǒng)進(jìn)行建模,以觀察目標(biāo)應(yīng)用在模擬環(huán)境中執(zhí)行時的行為特征,并對其硬件設(shè)計的正確性和性能進(jìn)行評估.
模型的思想是用軟件模擬器進(jìn)行體系結(jié)構(gòu)設(shè)計的關(guān)鍵,本文對多核互連系統(tǒng)進(jìn)行了3個方面的建模,以驗證目標(biāo)設(shè)計的正確性,并對目標(biāo)結(jié)構(gòu)進(jìn)行性能、功耗和面積等評估,如圖1所示.
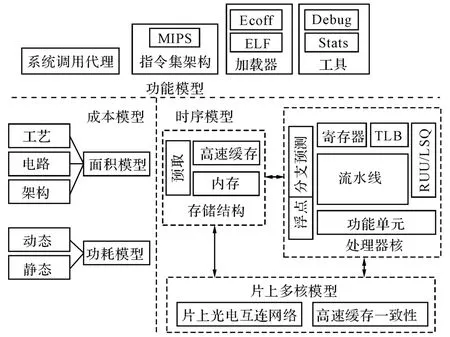
圖1 功能模型、時序模型與成本模型Fig.1 Functional model,timing model,and cost model
功能模型主要實現(xiàn)了對目標(biāo)可執(zhí)行文件(MIPS體系結(jié)構(gòu))的加載,對目標(biāo)指令集的解釋執(zhí)行,以及對MIPS/Linux標(biāo)準(zhǔn)系統(tǒng)調(diào)用的代理.
時序模型的功能包括:1)處理器的執(zhí)行時序特點,如指令調(diào)度、指令亂序執(zhí)行、分支預(yù)測等特性,以及流水線中的取指、分發(fā)、發(fā)射、執(zhí)行、寫回和提交過程;2)存儲層次結(jié)構(gòu),包含片上高速緩存(Cache)和片外存儲器模型;3)互連模型,支持片上光電互連網(wǎng)絡(luò)和高速緩存一致性協(xié)議.
成本模型的功能是評估系統(tǒng)的功耗以及面積開銷.功耗開銷包括動態(tài)功耗和靜態(tài)功耗;面積開銷的評估考慮了工藝技術(shù)、電路結(jié)構(gòu)和體系架構(gòu)3個層面.
本文按照層次化、軟硬件協(xié)同設(shè)計與仿真的策略,對多核系統(tǒng)進(jìn)行了3個方面的建模.這3個模型在功能上相互獨立,但又有著內(nèi)在的聯(lián)系:功能模型負(fù)責(zé)系統(tǒng)級建模,使得可執(zhí)行應(yīng)用程序與硬件仿真器相兼容;時序模型描述了片上多核系統(tǒng)的執(zhí)行細(xì)節(jié),使得模擬器在目標(biāo)體系結(jié)構(gòu)建模上與硬件設(shè)計保持一致;成本模型通過功耗、面積的準(zhǔn)確建模,能夠有效地評估設(shè)計方案.
3 系統(tǒng)實現(xiàn)
3.1 模擬器
本文在模擬器基礎(chǔ)框架的選擇和設(shè)計過程中,充分考慮了模擬器在精度和速度上的需求,選擇了SimpleScalar[12]模擬器工具集為基礎(chǔ)框架,對基于SimpleScalar的多核軟模擬器[13]進(jìn)行修改,使其支持MIPS體系結(jié)構(gòu)[14]的建模.在Cache模型方面,采用了基于目錄的一致性協(xié)議(modified,exclusive,shared,and invalid,MESI)來滿足多核共享Cache的一致性需求.在互連方面,用Popnet[15]實現(xiàn)底層結(jié)構(gòu)的片上網(wǎng)絡(luò)模型,并模擬了核間對有限網(wǎng)絡(luò)資源的競爭.對于應(yīng)用程序多線程模型的支持則是通過一組多線程函數(shù)庫完成,支持對線程的創(chuàng)建、管理、同步和通信.本文使用McPAT[6]作為該多核模擬器的功耗評估工具.網(wǎng)絡(luò)評估方面,Popnet[15]的作用是為模擬器提供數(shù)據(jù)傳輸服務(wù),模擬器自身的消息產(chǎn)生機制及工作過程對Popnet透明,Popnet僅負(fù)責(zé)提供可靠的數(shù)據(jù)傳輸服務(wù).如圖2所示為其工作流程.
Popnet與處理器核模擬器通過接口函數(shù)相互協(xié)作,其工作過程主要有以下幾個步驟.1)當(dāng)訪問Cache或進(jìn)行目錄操作時,會產(chǎn)生目錄事件.把這些目錄事件放入目錄隊列,同時判斷數(shù)據(jù)包的源節(jié)點注入端口的狀態(tài),并同時獲取注入的虛通道標(biāo)號.2)處理器核模擬器將數(shù)據(jù)包注入到Popnet網(wǎng)絡(luò)中,數(shù)據(jù)包中包含數(shù)據(jù)包編號、消息類型、時間信息、地址信息和數(shù)據(jù)信息等.3)消息會在Popnet網(wǎng)絡(luò)中傳輸,傳輸過程由Popnet完全控制.4)當(dāng)目的地址的路由器收到數(shù)據(jù)包后,將目錄隊列中的事件與該數(shù)據(jù)包的信息進(jìn)行對比.5)如果隊列中有一個事件與該數(shù)據(jù)包匹配,則將該事件取出隊列放入目錄先進(jìn)先出隊列.6)最后網(wǎng)絡(luò)節(jié)點會檢查目錄先進(jìn)先出隊列.當(dāng)數(shù)據(jù)包成功到達(dá)目的節(jié)點后,Popnet通知模擬器此消息已成功傳輸.當(dāng)有數(shù)據(jù)包產(chǎn)生并被注入到Popnet 中之后,Popnet 會根據(jù)數(shù)據(jù)包的類型(META 型或DATA 型)以及源節(jié)點、目標(biāo)節(jié)點的位置,自動安排合適的路由以及相應(yīng)的光電鏈路,完成數(shù)據(jù)包的傳輸.
3.2 多線程編程
為了方便用戶編程,軟件模擬器需要提供一套應(yīng)用程序接口(API),以及部分操作系統(tǒng)的功能(如系統(tǒng)調(diào)用),對應(yīng)用程序提供支持[16].由于不同的多核體系結(jié)構(gòu)(如分布式和共享式)所適用的同步方式、通信模式等不同,需要模擬器提供合適的編程模型,配合物理層硬件結(jié)構(gòu),使應(yīng)用程序能夠高效地執(zhí)行.
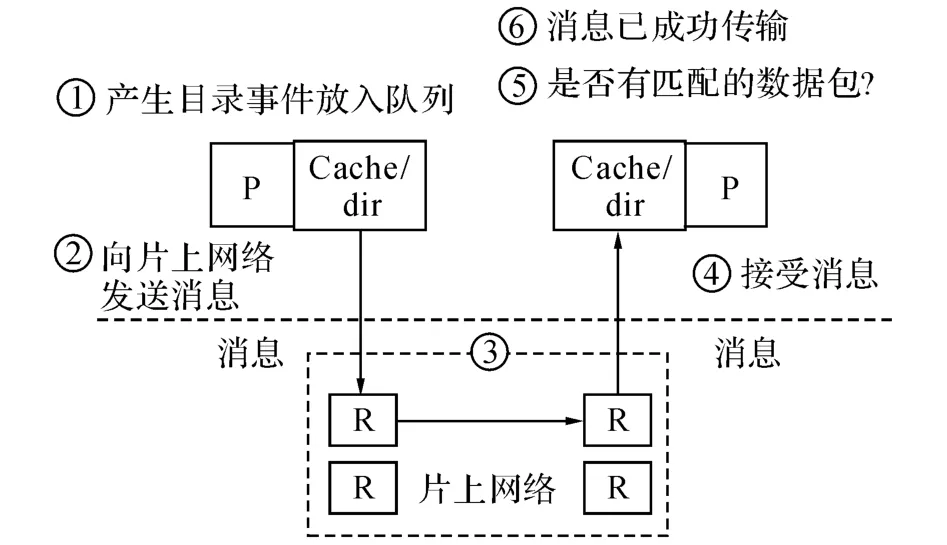
圖2 消息傳遞流程Fig.2 Message passing process
本文設(shè)計了一套完整的接口函數(shù),提供對物理層硬件的操作支持;同時采用用戶級虛擬化技術(shù),提供多線程編程和系統(tǒng)調(diào)用功能的支持.在編程模型方面,本文構(gòu)造了一套兼容Pthread[17]的應(yīng)用程序接口.該接口運行于模擬器上,隱藏并行處理器的細(xì)節(jié),利用多線程模型進(jìn)行任務(wù)調(diào)度,提供給程序員并行表達(dá)的方法,是底層體系結(jié)構(gòu)與上層應(yīng)用程序之間的橋梁.程序員可以利用該應(yīng)用程序接口中定義的一系列方法,實現(xiàn)創(chuàng)建線程、部署屏障、加解鎖互斥量和回收線程等功能,從而實現(xiàn)多線程的任務(wù)調(diào)度與同步.該應(yīng)用程序接口中主要的函數(shù)名稱及其功能描述如表1所示.

表1 主要接口函數(shù)Tab.1 API functions
一般來說,應(yīng)用程序編程需要符合如圖3所示的格式.其中計算內(nèi)核段(Compute kernel)是應(yīng)用程序的主體計算部分,可以包含互斥鎖.在臨界區(qū)(Critical section)既可以改變局部變量,又可以操作全局變量.編程時,可以將所需執(zhí)行的代碼直接替換到計算內(nèi)核段.
3.3 器件庫

圖3 編程示例Fig.3 Example of programming in API functions
片上光電互連網(wǎng)絡(luò)的構(gòu)建主要有光器件和電器件2方面,一般來說,建立硅光鏈路通常包括:1)激光器,用于產(chǎn)生光信號;2)微環(huán)諧振腔,常見于調(diào)制器、濾波器和光開關(guān)之中;3)光波導(dǎo),用于傳輸光信號;4)光接收器,即光探測器,用于接收光信號并轉(zhuǎn)換成電信號.
光器件模型僅提供功耗計算方法,不對網(wǎng)絡(luò)功能實現(xiàn)提供服務(wù).為了使光學(xué)器件庫具有良好的結(jié)構(gòu)和清晰的派生、繼承關(guān)系,在LioeSim[18]中提出了的器件建模方法,對光學(xué)器件進(jìn)行分類,并依據(jù)光學(xué)器件之間關(guān)系,規(guī)劃了光學(xué)器件庫的代碼類.本文采用LioeSim 的器件建模方法,通過分析目標(biāo)器件的工作原理及其功能特性,明確模型所要輸出的各類特征值(例如功耗、面積、損耗等),以及與之相關(guān)的工藝參數(shù).如表2所示列舉了光學(xué)器件庫中主要器件類的工藝參數(shù)選擇以及建模的主要內(nèi)容[19-21].
3.4 分簇方法
在光電互連的片上系統(tǒng)中,通常會將若干個處理器劃分為一個簇,簇內(nèi)節(jié)點之間仍舊采用傳統(tǒng)的電互連方式,而簇與簇之間通過環(huán)形光網(wǎng)絡(luò)相連,這樣既可以發(fā)揮光互連時延低、帶寬大、功耗小的優(yōu)點,又保留了原先電互連的可擴展性.光電互連系統(tǒng)的分簇方法如圖4所示,每個簇內(nèi)有一個中心路由器,當(dāng)消息的源節(jié)點和目的節(jié)點在同一個簇內(nèi)時,消息直接通過簇內(nèi)的電網(wǎng)絡(luò)傳遞;當(dāng)消息需要從一個簇傳到另一個簇時,該消息首先通過電網(wǎng)絡(luò)傳輸?shù)街行穆酚善鳎偻ㄟ^光網(wǎng)絡(luò)傳輸?shù)搅硪淮氐闹行穆酚善鳎詈笤偻ㄟ^電網(wǎng)絡(luò)抵達(dá)目的節(jié)點.

表2 光學(xué)器件庫建模Tab.2 Modeling for optical devices

圖4 分簇方法示意圖Fig.4 Clustering method
3.5 功耗計算模型
器件的功耗是一個與運行相關(guān)的參數(shù),在不同的負(fù)載情況下,光電互連網(wǎng)絡(luò)的功耗會有所區(qū)別,功耗的計算需要器件庫與片上網(wǎng)絡(luò)模擬器(Popnet)交互完成.本文保留了Popnet電功耗計算的功能,同時增加了光器件功耗的計算.對分簇后的電功耗進(jìn)行重新規(guī)劃和計算,增加了對中心路由器的電功耗計算;將模擬器的工作頻率目標(biāo)結(jié)構(gòu)的工作頻率進(jìn)行了統(tǒng)一,并建立了光傳輸帶寬、電傳輸帶寬、電光調(diào)制器速率與波分復(fù)用(wavelength division multiplexing,WDM)通道個數(shù)之間的關(guān)系.
光器件庫提供功耗計算方法,并不對網(wǎng)絡(luò)功能實現(xiàn)提供服務(wù).如圖5所示為功耗計算的模型.在仿真過程中,網(wǎng)絡(luò)模擬器會根據(jù)光電互連網(wǎng)絡(luò)的運行情況,統(tǒng)計各類器件的使用頻率與次數(shù),并將統(tǒng)計結(jié)果作為參數(shù)傳遞給器件庫;器件庫模型會根據(jù)這個參數(shù),結(jié)合器件的工藝參數(shù),計算出動態(tài)功耗;同時,器件庫還會根據(jù)全局配置參數(shù)(如時鐘頻率、溫度等)計算各類器件的靜態(tài)功耗.最后器件庫將這2部分功耗反饋給網(wǎng)絡(luò)模擬器,完成功耗計算的整個流程.
3.6 仿真規(guī)模擴展
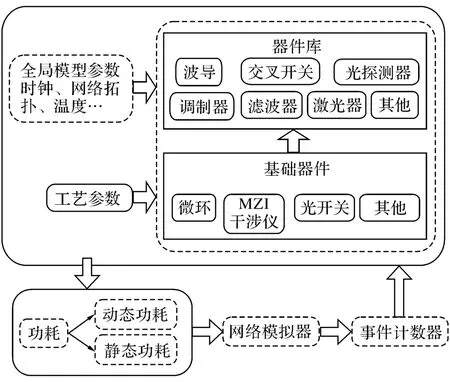
圖5 功耗計算模型Fig.5 Power consumption calculation model
為了擴展系統(tǒng)仿真規(guī)模,本文利用多線程機制,將每個簇內(nèi)的仿真交給一個線程來處理.模擬器在完成初始化工作以及相應(yīng)的快速執(zhí)行模式之后,進(jìn)入多線程并行執(zhí)行.對于每一個目標(biāo)機器周期,各個時序仿真線程(線程_00,線程_01,…線程_15)并行運行,每個線程對應(yīng)一個分簇內(nèi)的處理器核(例如256核16分簇的情況,共有16個線程,每個線程對應(yīng)16個核).完成一個目標(biāo)機器周期的時序仿真之后,各線程會進(jìn)行一次同步,等待片上網(wǎng)絡(luò)線程完成消息處理.然后由片上網(wǎng)絡(luò)線程通知各個時序仿真線程,開始下一個機器周期的仿真.如圖6所示為該過程的示意圖,仿真過程中采用了周期同步機制(即每一個機器周期都進(jìn)行了同步),因此可以做到周期級的精確仿真.

圖6 多線程運行示意圖Fig.6 Multi-thread operation
3.7 仿真流程
應(yīng)用程序在模擬器上運行通常會有以下的流程:1)準(zhǔn)備階段.模擬器讀取系統(tǒng)配置文件,對處理器核、存儲系統(tǒng)、片上網(wǎng)絡(luò)等進(jìn)行配置;讀取程序的可執(zhí)行文件及運行參數(shù).2)快速執(zhí)行階段.該階段的主要功能是完成評測程序自身的一些初始化工作.3)時序仿真階段.應(yīng)用程序開始并行運行,這個階段的模擬是周期精確的,即每個周期內(nèi)處理器以及片上網(wǎng)絡(luò)所進(jìn)行的操作、行為都會被模擬.4)性能統(tǒng)計.當(dāng)應(yīng)用程序運行完畢或者仿真到達(dá)指定的指令數(shù)后,進(jìn)入性能統(tǒng)計階段,對運行時的功耗、面積、時延等參數(shù)進(jìn)行統(tǒng)計.
4 實驗
4.1 實驗方法
基于本文構(gòu)造的方法進(jìn)行多核系統(tǒng)仿真,目標(biāo)系統(tǒng)包含256個MIPS32[14]處理器,頻率為1GHz,采用45nm COMS工藝,處理器與總線頻率比為5∶1,存儲系統(tǒng)的最小訪問延遲為105個處理器核周期,多核系統(tǒng)的配置如表3所示.
由于在多核系統(tǒng)中除了處理器節(jié)點之外,還需要存儲控制器,因此對于256核的系統(tǒng)來說,實際配置的Mesh網(wǎng)絡(luò)是18×18的規(guī)模.Popnet的初始配置參數(shù)以及光學(xué)器件的主要參數(shù)分別如表4和表5所示.本文針對256節(jié)點下的不同分簇大小的普通光電互連網(wǎng)絡(luò)、ATAC[22]結(jié)構(gòu)以及Corona[10]結(jié)構(gòu)進(jìn)行了仿真對比,并選取了SPLASH-2[23]以及PARSEC[24]中的部分程序作為評測程序,如表6所示.
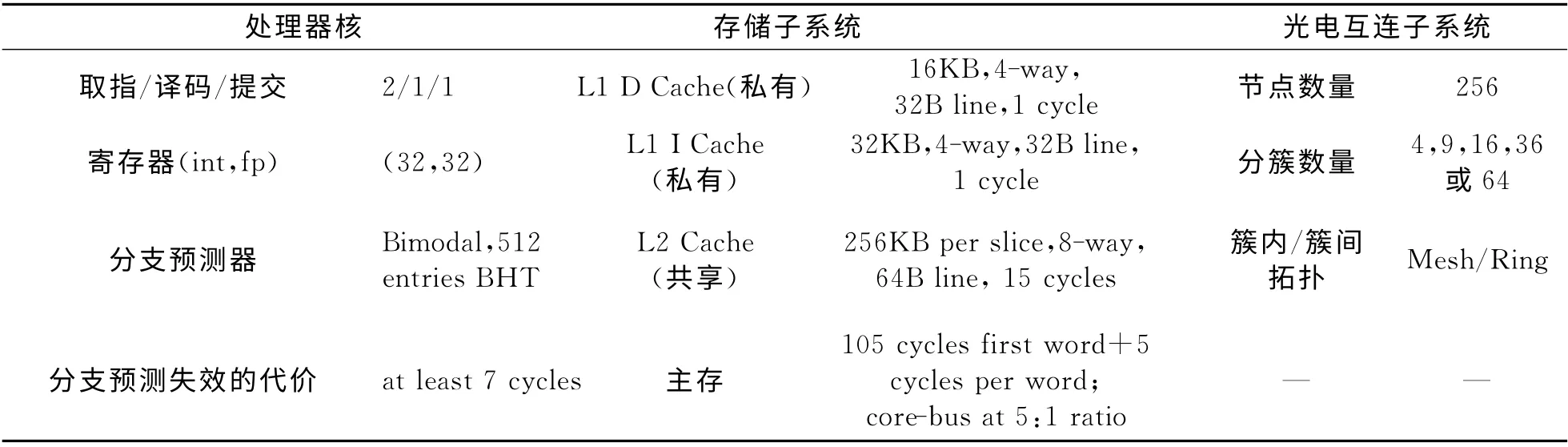
表3 多核系統(tǒng)配置表Tab.3 System configuration

表4 Popnet參數(shù)配置Tab.4 Popnet configuration

表6評測程序Tab.6 Benchmarks

表5 光學(xué)器件參數(shù)Tab.5 Parameters for optical devices
4.2 實驗結(jié)果分析
4.2.1 分簇大小對網(wǎng)絡(luò)性能的影響 對于3.4節(jié)所述的光電互連網(wǎng)絡(luò)來說,當(dāng)分簇的規(guī)模比較小,即簇內(nèi)節(jié)點數(shù)量較少時,簇內(nèi)電網(wǎng)絡(luò)的負(fù)載會降低,而簇間光網(wǎng)絡(luò)會變得更為繁忙;反之,當(dāng)分簇的規(guī)模較大,即簇內(nèi)節(jié)點數(shù)量較多時,節(jié)點間的通信主要集中在簇內(nèi)的電網(wǎng)絡(luò)上,而簇間的光網(wǎng)絡(luò)會變得相對空閑.為了探究不同分簇對光電互連網(wǎng)絡(luò)性能的影響,本文將256個節(jié)點的系統(tǒng)分別劃分為4、9、16、36和64個簇等若干種情況,并對其進(jìn)行了性能評估.
各種分簇情況下的網(wǎng)絡(luò)平均時延如圖7所示,網(wǎng)絡(luò)時延N 是指一個數(shù)據(jù)包從源節(jié)點產(chǎn)生開始,通過網(wǎng)絡(luò)傳輸?shù)竭_(dá)目的節(jié)點的過程中,所使用的時間,由時鐘周期的個數(shù)表示.平均時延越小,說明數(shù)據(jù)包在網(wǎng)絡(luò)上傳輸?shù)迷娇?由圖7可見,隨著分簇個數(shù)的增加,網(wǎng)絡(luò)的平均時延明顯減小.這是由于分簇越多,簇內(nèi)的電網(wǎng)絡(luò)規(guī)模越小,簇間的光網(wǎng)絡(luò)承擔(dān)更多傳輸任務(wù),光網(wǎng)絡(luò)高帶寬、低時延的特性,提升了網(wǎng)絡(luò)傳輸速率.
網(wǎng)絡(luò)的電功耗P1以及光功耗P2分別如圖8和9所示.分簇后,網(wǎng)絡(luò)的電功耗會降低,同時會消耗一部分光功耗.與其他分簇結(jié)構(gòu)相比,64 分簇的電功耗較大,這是由于64 分簇的網(wǎng)絡(luò)平均時延較小,完成相同的任務(wù)所需的時間變短了,因此系統(tǒng)功率會上升.在4分簇和9分簇的網(wǎng)絡(luò)中,光功耗相較于電功耗非常低,而36和64分簇網(wǎng)絡(luò)中,光功耗則相對較大,這是由于光網(wǎng)絡(luò)采用廣播形式,光源的輸出功率與光網(wǎng)絡(luò)節(jié)點數(shù)成平方關(guān)系.在評測程序中,cholesky評測所產(chǎn)生的電功耗和光功耗都比較大,這是由程序的行為特性導(dǎo)致的,該評測程序節(jié)點之間的數(shù)據(jù)交換非常頻繁,使得光電網(wǎng)絡(luò)占用率提升,導(dǎo)致功耗增大.相比電器件功耗,光器件的功耗比較小.因此,利用光互連功耗低的特性,可以節(jié)省系統(tǒng)的總體功耗.
如圖10所示顯示了網(wǎng)絡(luò)中消息傳遞的平均跳數(shù)H,由圖可見,分簇越多,消息的平均跳數(shù)越小.這是因為分簇越多每個簇的規(guī)模就越小,出簇的數(shù)據(jù)包所占的比例會增大;由于出簇的數(shù)據(jù)包都是經(jīng)過光網(wǎng)絡(luò)傳輸,且只需要一個機器周期就能送達(dá)目的節(jié)點所在的分簇,因此分簇越多,相應(yīng)的平均跳數(shù)越小.
從前面的時延和功耗分析可以看出,在提高網(wǎng)絡(luò)傳輸速率的同時,通常會帶來能耗的上升.為了衡量網(wǎng)絡(luò)傳輸?shù)男埽疚膶怆娀ミB網(wǎng)絡(luò)的能量時延積EDP(Energy-delay product)進(jìn)行了評估,如圖11所示.EDP越小,說明網(wǎng)絡(luò)的效能越高.可見,對于256核光電互連網(wǎng)絡(luò),采用36分簇時所獲得的效能最好,9 分簇的平均效能與不分簇的情況(EMesh)較為接近,4分簇的網(wǎng)絡(luò)效能較差.
4.2.2 幾種典型網(wǎng)絡(luò)結(jié)構(gòu)的對比 為了對比相同分簇條件下不同網(wǎng)絡(luò)結(jié)構(gòu)對網(wǎng)絡(luò)性能的影響,本文在256節(jié)點16分簇和64分簇2種情形下,實現(xiàn)了ATAC[22]網(wǎng)絡(luò)結(jié)構(gòu)和一種類似于Corona[10]總線機制的crossbar結(jié)構(gòu).
ATAC的簇內(nèi)電網(wǎng)絡(luò)分為EMesh 和BNet 2部分.其中BNet為簇內(nèi)廣播網(wǎng)絡(luò),用于從中心節(jié)點下行到簇內(nèi)其余節(jié)點.BNet采用奇偶2個小型子網(wǎng)實現(xiàn),將數(shù)據(jù)包按照簇內(nèi)目的地址分為奇偶2組,并使用相對應(yīng)的BNet網(wǎng)絡(luò)進(jìn)行廣播.EMesh網(wǎng)絡(luò)為簇內(nèi)的電Mesh網(wǎng)絡(luò),用于簇內(nèi)正常的消息傳輸,及簇內(nèi)節(jié)點將數(shù)據(jù)包傳輸至中心節(jié)點.
Corona的總線機制可簡要描述為競爭機制,即接收端使用固定的波長,發(fā)送端通過總線傳輸數(shù)據(jù)包時,需要將電信號調(diào)制成指定接收端的固定波長的光信號.Corona的競爭機制采用異步、微環(huán)令牌的實現(xiàn)方法.本文對此結(jié)構(gòu)進(jìn)行了一定程度的化簡,在原有的光網(wǎng)絡(luò)基礎(chǔ)上將廣播機制更改為類似于Corona總線機制的crossbar網(wǎng)絡(luò)結(jié)構(gòu),并引入競爭處理機制.
通過對比16分簇時3種不同互連結(jié)構(gòu)(即普通分簇、ATAC以及Corona),可以分析不同結(jié)構(gòu)對系統(tǒng)性能的影響.雖然ATAC 結(jié)構(gòu)時延較普通的16分簇結(jié)構(gòu)小(圖7),Corona結(jié)構(gòu)功耗較普通的16分簇結(jié)構(gòu)小(圖8、圖9),但總的來說,ATAC 結(jié)構(gòu)和Corona結(jié)構(gòu)的效能只是略好于原來的16 分簇(圖11).ATAC結(jié)構(gòu)時延小但功耗大;Corona結(jié)構(gòu)時延大但功耗小;普通16分簇結(jié)構(gòu)的時延和功耗性能處于兩者之間.這主要是因為,ATAC 結(jié)構(gòu)是廣播的,所以時延較小,功耗較大;而Corona結(jié)構(gòu)引入了總線競爭,所以時延較大,而功耗較小.

圖7 256核不同分簇的平均時延Fig.7 Average delay for 256-node system
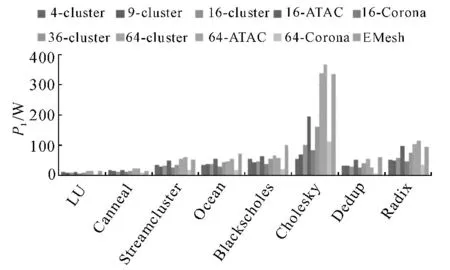
圖8 256核不同網(wǎng)絡(luò)結(jié)構(gòu)的電功耗Fig.8 Electric Power for 256-node system
通過對比64分簇時的3種不同互連結(jié)構(gòu)可以看出,64 分簇的ATAC 在平均時延上有比較明顯的優(yōu)勢,同時帶來的功耗增長并不顯著;而64分簇的Corona可以同時降低電功耗和光功耗,減小了能量時延積.
總體來說,光電互連網(wǎng)絡(luò)的平均時延會隨著分簇個數(shù)的增加而減小,但是光電互連網(wǎng)絡(luò)的效能并不隨著分簇個數(shù)的增加而一直提高,當(dāng)分簇個數(shù)過多時,網(wǎng)絡(luò)功耗也會變得較大,引起效能的惡化.對256核來說,采用36分簇的光電互連網(wǎng)絡(luò)所獲得的平均效能最好.在分簇個數(shù)相同的條件下,ATAC結(jié)構(gòu)的時延小但功耗大;Corona結(jié)構(gòu)功耗小,但時延大;普通總線結(jié)構(gòu)的時延和功耗性能處于兩者之間,3種結(jié)構(gòu)的平均效能差別不大.

圖9 256核不同網(wǎng)絡(luò)結(jié)構(gòu)的光功耗(不包含光源的功耗)Fig.9 Optical power for 256-node system(laser power not included)

圖10 256核不同網(wǎng)絡(luò)結(jié)構(gòu)中消息的平均跳數(shù)Fig.10 Average hop count for 256-node system
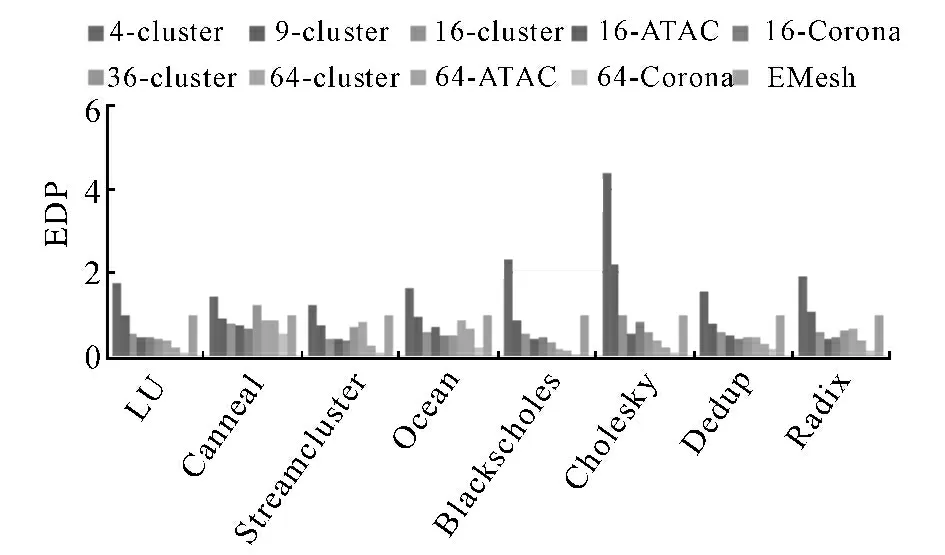
圖11 256核不同分簇的能量時延積Fig.11 Energy-delay product for 256-node system
5 結(jié) 語
本文提出了一種面向多核的光電互連系統(tǒng)的仿真方法,對光電器件進(jìn)行了物理層精確建模,實現(xiàn)器件庫與功能模型、時序模型和成本模型協(xié)同工作;通過周期同步機制和多線程擴展機制,實現(xiàn)了16 至256核光電互連網(wǎng)絡(luò)的周期級精確仿真.本文提出的光電互連系統(tǒng)仿真方法可探索不同的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu),并評估整體系統(tǒng)性能.
相比于傳統(tǒng)的電互連網(wǎng)絡(luò),光電互連片上網(wǎng)絡(luò)具有低功耗、高帶寬等特點.如何利用光網(wǎng)絡(luò)的特性提升片上網(wǎng)絡(luò)的性能,如何改進(jìn)存儲一致性協(xié)議使之適應(yīng)光電互連網(wǎng)絡(luò)的特性,是未來研究的重要方向.
(
):
[1]CHAN J,HENDRY G,BIBERMAN A,et al.Phoenixsim:A simulator for physical-layer analysis of chipscale photonic interconnection networks[C]∥Proceedings of the Conference on Design,Automation and Test in Europe.Dresden,Germany:European Design and Automation Association,2010:691-696.
[2]SUN C,CHEN C-H,KURIAN G,et al.DSENT :a tool connecting emerging photonics with electronics for opto-electronic networks-on-chip modeling [C]∥Proceedings of the 6th IEEE/ACM International Symposium on Networks on Chip.Lyngby,Denmark:IEEE,2012:201-210.
[3]MILLER J E,KASTURE H,KURIAN G,et al.Graphite:A distributed parallel simulator for multicores[C]∥Proceedings of the16th International Symposium on High Performance Computer Architecture.Bangalore,India:IEEE,2010:1-12.
[4]CHIEN A A.A cost and speed model for k-ary n-cube wormhole routers[J].Urbana,1993,51:61801.
[5]KAHNG A B,LI B,PEH L-S,et al.Orion 2.0:A fast and accurate noc power and area model for earlystage design space exploration[C]∥Proceedings of the Conference on Design,Automation and Test in Europe.Nice,F(xiàn)rance:European Design and Automation Association,2009:423-428.
[6]LI S,AHN J H,STRONG R D,et al.McPAT:an integrated power,area,and timing modeling framework for multicore and manycore architectures[C]∥Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture.New York,United State:IEEE,2009:469-480.
[7]BRIERE M,DROUARD E,MIEYEVILLE F,et al.Heterogeneous modelling of an optical network-on-chip with SystemC[C]∥Proceedings of the 16th IEEE International Workshop on Rapid System Prototyping.Montreal,Canada:IEEE,2005:10-16.
[8]KODI A K,LOURI A.Optisim:A system simulation methodology for optically interconnected HPC systems[J].Micro,IEEE,2008,28(5):22-36.
[9]O'CONNOR I,TISSAFI-DRISSI F,GAFFIOT F,et al.Systematic simulation-based predictive synthesis of integrated optical interconnect[J].IEEE Transactions on Very Large Scale Integration(VLSI)Systems,2007,15(8):927-940.
[10]VANTREASE D,SCHREIBER R,MONCHIERO M,et al.Corona:System implications of emerging nanophotonic technology [J].ACM SIGARCH Computer Architecture News,2008,36(3):153-164.
[11]PSOTA J,MILLER J,KURIAN G,et al.ATAC:Improving performance and programmability with onchip optical networks[C]∥Proceedings of 2010IEEE International Symposium on Circuits and Systems.Paris,F(xiàn)rance:IEEE,2010:3325-3328.
[12]AUSTIN T,LARSON E,ERNST D.SimpleScalar:An infrastructure for computer system modeling[J].Computer,2002,35(2):59-67.
[13]XUE J,GARG A,CIFTCIOGLU B,et al.An intrachip free-space optical interconnect[C]∥Proceedings of the 37th Annual International Symposium on Computer Architecture.Saint-Malo,F(xiàn)rance:ACM,2010:94-105.
[14]TRAN C,ANYANWU C,BALAKRISHNAN S,et al.The MIPS32 24KE Core Family:High-Performance RISC Cores with DSP Enhancements[R].Sunnyvale,United States:M.Technologies,2005.
[15]SHANG L.POPNET simulator[EB/OL].[2015-08-31].http://www.sanjuansw.com/pub/SJS%20125-300-13%20PopNet2%20Data%20Sheet.pdf.
[16]YU J Y,LIU P,WANG W D,et al.An efficient protocol with synchronization accelerator for multi-processor embedded systems[J].Parallel Computing,2013,39(9):461-474.
[17]BUTENHOF D R.Programming with POSIX threads[M].Indianapolis,United State:Addison-Wesley Professional.1997:35-44.
[18]MA X,YU J,HUA X,et al.LioeSim:a network simulator for hybrid opto-electronic networks-on-chip analysis[J].Journal of Lightwave Technology,2014,32(22):3699-3708.
[19]BARWICZ T,BYUN H,GAN F,et al.Silicon photonics for compact,energy-efficient interconnects[J].Journal of Optical Networking,2007,6(1):63-73.
[20]LI Z,ZHOU L,HU Y,et al.CMOS compatible silicon-based Mach-Zehnder optical modulators with improved extinction ratio[C]∥Proceedings of the International Photonics and Optoelectronics Meetings.Wuhan:International Society for Optics and Photonics,2011:833305-833306.
[21]YANG M,GREEN W M,ASSEFA S,et al.Nonblocking 4x4 electro-optic silicon switch for on-chip photonic networks[J].Optics express,2011,19(1):47-54.
[22]KURIAN G,MILLER J E,PSOTA J,et al.ATAC:a 1000-core cache-coherent processor with on-chip optical network[C]∥Proceedings of the 19th International Conference on Parallel Architectures and Compilation Techniques.Vienna,Austria:ACM,2010:477-488.
[23]WOO S C,OHARA M,TORRIE E,et al.The SPLASH-2programs:Characterization and methodological considerations[C]∥Proceedings of the 22nd annual international symposium on Computer architecture.Santa Margherita Ligure,Italy:ACM,1995:24-36.
[24]BIENIA C,KUMAR S,SINGH J P,et al.The PARSEC benchmark suite:characterization and architectural implications[C]∥Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques.Toronto,Canada:ACM,2008:72-81.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
哲學(xué)評論(2021年2期)2021-08-22 01:53:34
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
