融合句義結構模型的微博話題摘要算法
2015-07-11 10:10:12羅森林賈叢飛原玉嬌潘麗敏
浙江大學學報(工學版) 2015年12期
林 萌,羅森林,賈叢飛,韓 磊,原玉嬌,潘麗敏
(北京理工大學 信息與電子學院,北京100081)
微博的出現深刻改變了人們的信息交流方式.以新浪微博為例,截至2014年6月,微博月均活躍用戶數為1.565 億人,微博平均日活躍用戶數為6970萬人[1].熱門話題是微博中正在熱議的新鮮話題,用戶查詢一個熱門話題,得到的是按照熱門程度或發表時間排序的所有相關微博.然而,由于微博數量龐大,用戶得到的信息經常是不完整的,甚至是不相關的或者是重復的,信息獲取的效率很低,對微博進行摘要能大大提高信息獲取的效率.
多文檔自動摘要技術其處理對象為結構完整、書寫規范、條理清楚的長文本.微博篇幅短小(140字以內),用詞不規范,缺失長文檔的結構信息,并包含大量垃圾內容和垃圾用戶.直接利用已有的多文檔摘要技術對其摘要存在嚴重的特征稀疏和結構缺失問題.這些問題導致抽取特征不足以準確描述文本內容,抽取的句子與話題的中心發生漂移,生成的摘要與主題相關度下降,大大影響摘要生成的效果[2-4].提高生成摘要與話題的相關度問題具有十分重要的意義.
1 相關工作
多文檔自動文摘技術經過多年發展已經出現了很多方法和技術.具有代表性的方法有基于詞頻的方法(如:SumBasic[5]和MEAD[6])、基于概率淺層語 義 分 析(probabilistic latent semantic analysis,PLSA)[7]和淺層狄利克雷分布(latent Dirichlet allocation,LDA)[8-9]的方法、基于圖的方法(如:Lex-PageRank[10]算法,這種方法已經成功應用到了Google PageRank中)以及基于其他機器學習[11-12]的方法等.
然而,這些方法大都是針對長文本的詞項特征進行統計分析處理.微博篇幅短小,單條微博的關鍵詞一般只有十幾個甚至幾個,關鍵詞特征稀疏.單條微博內關鍵詞的重復率不明顯,缺失長文檔的結構信息.因此,傳統自動摘要技術將失去原有效果,需要結合微博特性與傳統自動摘要技術的優點來進行微博話題摘要.
近年來,以Twitter[13-15]為代表的英文社會化短文本摘要逐漸獲得科研人員的關注.2010 年Sharifi等[16]提出將包含主題詞的最常使用詞匯鏈作為摘要,這種方法獲得的摘要只是包含主題詞的一句話,信息并不全面.2011年,Harabagiu等[17]通過構建復雜事件的發展結構模型和用戶行為模型來生成微博復雜事件的摘要.Chakrabrti[18]使用隱馬爾可夫模型學習微博事件的隱藏狀態,對高度結構化重復出現的話題(如:運動賽事)進行摘要.Inouye等[19]在文獻[16]的基礎上提出一種基于聚類的Hybird TF-IDF摘要方法.這種方法計算詞的TF(term frequency)值是該詞在語料庫中出現的次數與語料庫中出現的詞數的比值,而在計算IDF(inverse document frequency)值時,又將每篇微博作為一個單獨的文檔對待,計算方法為出現該詞的微博總篇數除以語料中的微博總數.實驗證明,Hybrid TF-IDF取得的效果優于一些主流的摘要方法(如:MEAD、LexRank[20]、TextRank[21]).中文的微博摘要處于剛剛起步階段,可以查閱的資料較少.2011年,武漢大學的何炎祥[2]等提出一種輕巧新穎的LN 算法(light N-tree algorithm),以樹的形式將話題以摘要的方式展現給用戶,但不能形成可讀性文摘.2013年,Bian等[22]引入微博文本的配圖作為新的特征,提出一種新的概率生成模型MMLDA(multimodal LDA)來發現微博話題的子主題并進行摘要.
目前的研究大多基于詞形、詞頻等統計信息進行特征抽取,忽略了句子的句義成分以及成分之間的關系特征,對微博內容挖掘深度不夠,導致僅僅基于詞形匹配的相似度計算方法無法準確計算句子的內容相似.同時,在選擇句子時,沒有抽取句子之間的隱藏語義聯系,未充分利用句子所處的子主題信息,導致抽取的句子與主題的相關性較差.本文針對以上問題提出融合句義結構模型[23]的微博話題摘要方法.
2 句義結構模型及句義分析
句義結構模型以現代漢語語義學為基礎,是從句義角度研究句子的成分以及成分之間關系的句義結構化表示模型.句義結構分為句型層、描述層、對象層和細節層4個層次,包含的句義成分有句義類型、話題、述題、謂詞和項等.其中,項又分為基本項與一般項,項的功能用語義格表示,一共有7個基本格和12個一般格.句義結構模型的基本形式[24]如圖1所示.
句義分析是由句義結構模型分析得到句子的結構信息和語義信息.其具體方法是根據句義結構模型基本框架,分別處理不同語義格的對象成分以及語義格結構信息,主要語義格類型說明如表1所示.
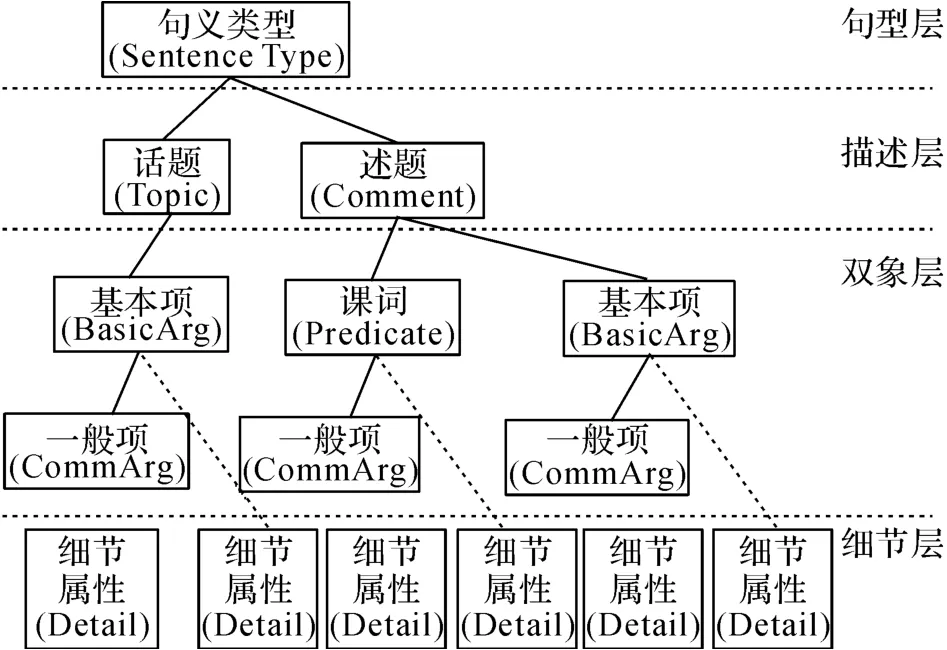
圖1 句義結構模型的基本形式Fig.1 Basic form of sentential semantic model

表1 主要語義格類型說明Tab.1 Description of main semantic cases
3 算法原理
針對現有方法生成摘要內容冗余度高的問題,本文從準確計算句子內容相似性的角度出發,利用句義結構模型分析語義項和項之間的依存關系抽取句子的句義特征,擴充句子的語義維度,利用句義特征準確表達語句信息及句子內容的相似性,抽取句子時根據句子內容相似性有效控制文摘冗余度.針對現有摘要方法抽取的句子與子主題相關性差的問題,本文從挖掘句子之間的隱藏語義聯系及子主題信息的角度出發,提出抽取句子關聯特征的方法.關聯特征表示句子與話題的語義聯系度,利用關聯特征增強相似語句的語義聯系.綜合加權句子的語義特征和關聯特征,抽取子主題內的關鍵句子,得到話題的摘要.
本方法將文檔集合分句,句子清洗,分詞和詞性標注得到預處理結果,對預處理結果分別計算語義權值和關聯權值.在計算語義權值時,統計預處理結果中所有實詞出現的句子頻率,按句子頻率從大到小排序,選擇前N 個詞作為主題詞的種子詞,加入哈工大同義詞林擴展版(HIT IR-Lab Tongyici Cilin(Extended))進行擴展,得到擴展后的主題詞表.結合主題詞表分析句子的語義特征,包括詞性詞法特征和句義結構特征,對各個特征線性加權,得到句子的語義權值.在計算關聯權值時,需要先對預處理結果進行句子相似度計算,得到句子兩兩之間的語義相似值,構建相似度矩陣,劃分子主題類.利用句子兩兩之間的語義相似值,計算句子與類內及類外其他句子的語義相似度,得到句子的關聯權值.最后對句子的語義權值和關聯權值綜合加權,得到句子的最終權值.最后依次選擇子主題內權重最大的句子作為文摘句.所提出算法的原理圖如圖2所示.
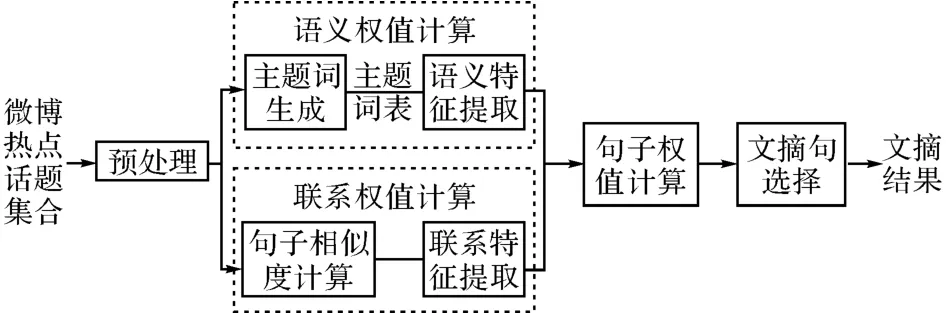
圖2 所提出算法的原理圖Fig.2 Schematic diagram of proposed algorithm
3.1 預處理
分句、句子清洗是預處理的第一步.將微博中內嵌鏈接URL、表情符號和@后的用戶名從原始語料庫中刪除.采用中科院提供的中文分詞軟件“ICTCLAS”[24],按照北京大學詞性標注規范對數據集進行分詞.將有效詞(名詞、動詞、形容詞、數詞、時間詞等實詞)數量小于4 的句子去除.預處理原理圖如圖3所示.
3.2 語義權值計算
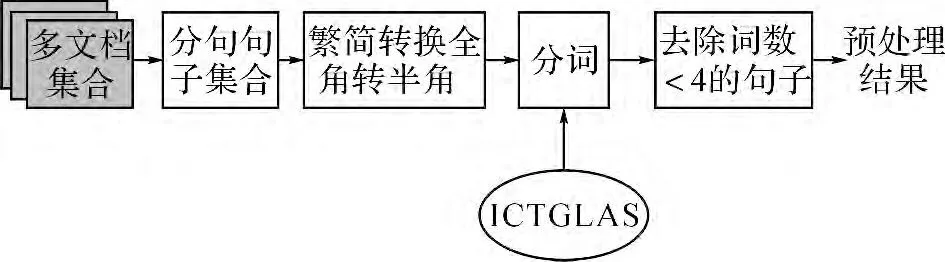
圖3 預處理原理圖Fig.3 Schematic diagram of preprocessing
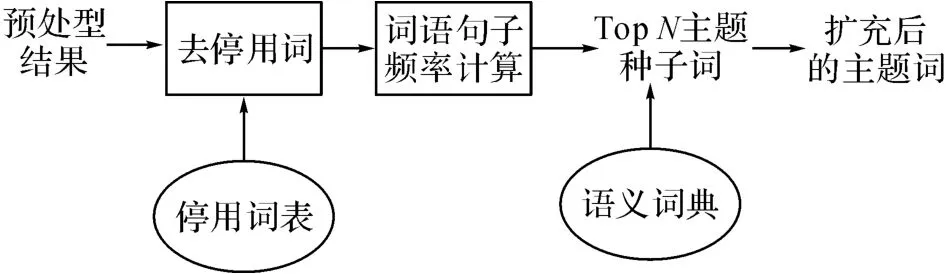
圖4 主題詞生成原理圖Fig.4 Schematic diagram of topic generation module
3.2.1 主題詞生成 主題詞生成原理圖如圖4所示.將所有實詞按句子頻率從大到小排序,選擇前N 個詞作為主題詞的種子詞,加入哈爾濱工業大學同義詞林擴展版進行擴展,得到擴展后的種子詞.擴展版的同義詞林包含77 343條詞語,按照五層樹形結構組織到一起.對詞義進行有效擴展,或者對關鍵詞做同義詞替換可以明顯改善信息檢索、文本分類和自動問答系統的性能.本文利用第5級分類對種子詞進行擴展分別按照詞義相等和詞義相關2大類別擴展種子詞.
3.2.2 語義特征提取 分析句子的語義特征,是計算句子內容重要性的關鍵步驟.現有研究一般只用到句子的詞法特征和句法特征,對句子內容的挖掘僅限于詞、句法層次.本研究不僅使用傳統的詞法句法特征,并加入句子的句義結構特征.句義結構特征可以增加句子的分析深度,能夠更好地表達句子的深層含義,對更有效地挖掘句子內容.
句義結構模型是對句子語義層次的分析,是句義的形式化表達.句義結構模型中的話題、謂詞、述題等信息可以體現一個句子的核心內容,此外句義結構模型中各個句義成分之間的關系對句子的語義表達也很有意義.本文使用的語義特征如表2所示.
特征項F1及F2為句子有效詞的統計特征.一般認為名詞(noun)、動詞(verb)比其他詞性更重要,賦權重為2,其余詞性權重為1.話題、謂詞、述題特征是句子的核心內容,若該句的以上特征在主題詞表內,則說明該句的核心內容跟主題相關,出現的詞數越多則該句與主題的聯系越緊密,越能表達主題中心的意義.一般項的句義功能是描述基本項和謂詞,對其表達的內容作進一步說明和補充.將句子一般格中包含的主題詞選為特征,作為對一般項和謂詞的補充.句子的語義權重值計算方法如下.
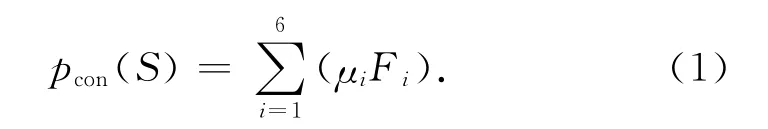
式中:pcon(S)是句子S 的語義權重值,Fi和μi 分別代表語義特征的值和該特征的加權系數.

表2 句子語義特征Tab.2 Semantic features of sentences
3.3 聯系權值計算
3.3.1 句子相似度計算 由于句子長度的限制,單個句子的關鍵詞一般只有幾個,特征尤其稀疏,僅僅基于詞形匹配的方法無法準確衡量句子內容的相似度.在句義結構的基礎上,使用LDA 主題模型,對單個句子的關鍵詞進行擴充,從而解決由于句子長度限制特征嚴重缺失所帶來的無法計算句子相似度的問題,并在句義層面計算句子的內容相似度.
句子相似度計算的原理圖如圖5所示.輸入是預處理后的所有句子,輸出是句子兩兩之間的相似值.其中,句義結構分析模塊利用BFS-CSA[23]分析句子得到句義結構;劃分詞語模塊是根據句義結構中的成分,將詞語劃分成基本格、一般格和謂詞;LDA 分析模塊通過計算劃分好的語義格得到知識庫;擴充句子維度模塊通過使用知識庫的信息對句子中的格進行擴充,得到新的表示向量;句子相似度計算模塊通過計算擴充后的句子向量的余弦相似度,得到2個句子間的相似值.
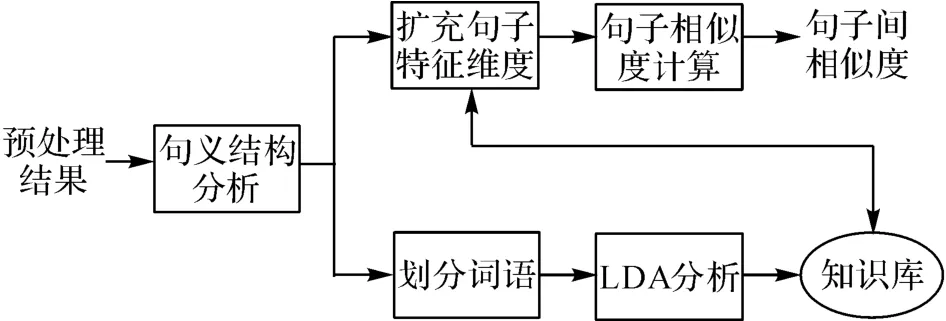
圖5 句子相似度計算原理圖Fig.5 Schematic diagram of sentence similarity calculation
根據句義結構理論,句義包括話題和述題.話題是被描述的成分;述題是語義表達的描述成分,同時考慮句子的主干(基本格)和修飾成分(一般格).本研究將知識庫分為3類:話題(基本格)知識庫、述題(基本格和謂詞)知識庫和一般格知識庫.話題知識庫中的詞語來源于文集中句子話題下的基本格,用于對句子中話題下的基本格詞語進行擴充,述題知識庫中的詞語來源于文本集中句子述題下的基本格和謂詞,用于對述題下的基本格詞語和謂詞進行擴充,一般格知識庫中的詞語來源于句子中的一般格,用于對句子中所有一般格詞語進行擴充.
按照Blei[26]提出的理論,使用LDA 主題模型計算得到同一主題(Topic)下的詞語具有相似的屬性或意義,因此,本文利用LDA 對3組不同的詞語集合分別計算不同主題下的概率,最后將句子中話題(基本格)、述題(基本格和謂詞)和一般格下的詞語分別選擇對應知識庫所在主題下的其他詞語作為特征向量上該詞的維度擴充,擴充維度的取值計算公式如下:

式中:V 為擴充詞語的取值,n 為待擴充詞在句子中出現的次數,w 為待擴充詞在相應主題下的概率取值.
對句子的話題和述題分別進行擴充,得到句子的話題向量和述題向量,分別計算句子的話題相似度和述題相似度,對2個相似度進行加權得到最終的句子相似度:
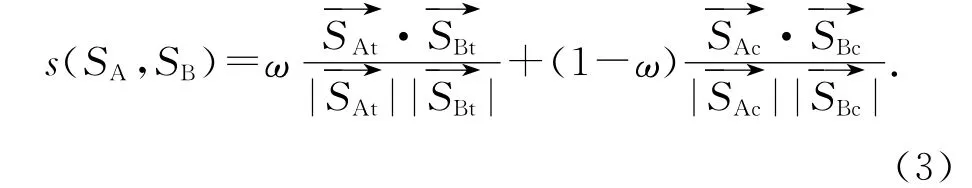
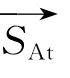
以0.1為步進值調整ω,得到摘要的ROUGE評價指標如表3所示.由表3可得,當ω=0.5時,即當話題和述題的權重相等時,ROUGE 評價指標得分最高.以ROUGE-1 指標為例,當ω 從0.5 開始向0(1)方向減小(增大)時,ROUGE-1指標為逐步減小的趨勢(見圖6),說明話題和述題是綜合衡量句子意義的2個方面,偏向于任何一方,句子相似度的計算值都不能完全表達句子的意義.由實驗結果可知,ω 的最佳取值為0.5.
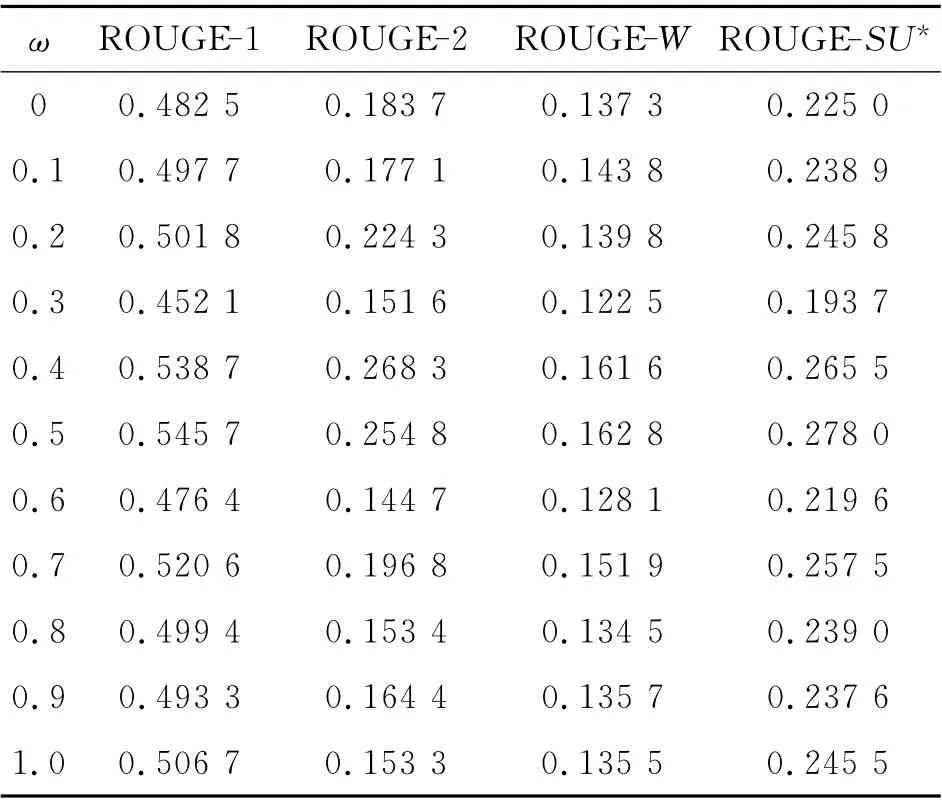
表3 參數ω 的選擇實驗結果Tab.3 Results of parameter selection experiments ofω
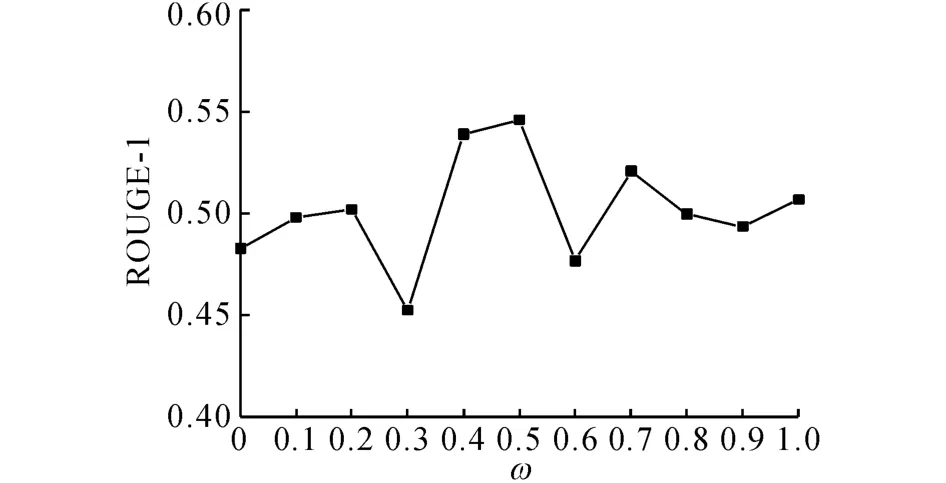
圖6 ROUGE-1值隨ω的變化趨勢圖Fig.6 Diagram ofω-changing trend of ROUGE-1
3.3.2 關聯特征提取 通過句子相似度計算出句子兩兩之間的語義相似值,構建句子的n 維空間向量表示:
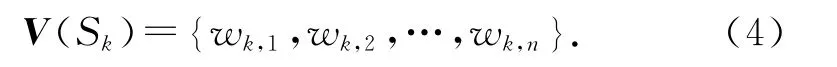
式中:空間中的每一維wk,j是句子Sk對Sj的相似度值,j=1,2,…,n.子主題是圍繞中心主題發生的現象、后果以及原因等的說明,是對中心主題不同側面的描述.利用構建的句子特征空間對語料中所有的句子進行K-means聚類,劃分子主題.對于本文所使用的語料庫,每一個話題下的子主題數目一般不多于10個.因此,設定初始聚類中心為10,并將類內句子數量小于總量5%的類作為噪音去除,剩余的類作為子主題劃分結果.
句子的關聯特征表示句子與話題的語義聯系度,可以通過加權計算該句與不同子主題中其他句子的語義重合度得出.句子Sk對Sj的語義重合度R(Sk,Sj)定義為句子Sj的語義權重值Pcon(Sj)與Sj對Sk的句子相似度值s(Sk,Sj)的乘積:
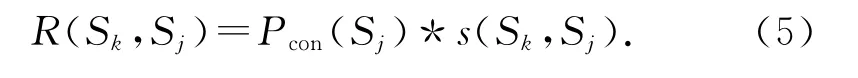
構建無向圖G(S,E),圖中的每個節點S 對應一個語句,邊E(Si,Sk)表示語句Si與Sk的句子相似度值.節點S 的度d 是與S 相連的邊的數目,反映了S 包含信息的重要程度:d 越大,則對應語句所關聯的語句數目越多,那么這個句子所包含的信息越重要;反之亦成立.如果一個節點的度比較大,那么與之相關聯的語句也相應地比較重要.令節點S的初始值為句子的內容權重值,通過計算其他句子對該句的語義重合度得到句子的聯系權重值.考慮到同一個子主題下句子聯系緊密,設加權系數為1,不同子主題下句子的加權系數由子主題的平均句子內容權重得出
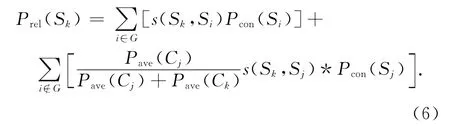
式中:Prel(Sk)為句子Sk的關聯權重值.若Sk和Si屬于同一個子主題(i∈G),則加權系數為1;若Sk和Sj分屬不同子主題(i?G),加權系數為Pave(Cj)/(Pave(Cj)+Pave(Ck)).其中Pave(Cj)、Pave(Ck)分別為句子所屬子主題的句子平均語義權重值.
3.4 句子權值計算
在計算句子重要性時,現有方法大都偏重于挖掘句子本身的內容,而忽略了句子所處“環境”的影響.一個好的文摘句,內容上不僅要緊扣主題,同時也應該與語料庫中的其他句子聯系緊密.本文所用的句子權重計算方法不僅考慮了句子的語義信息同時考慮了句子的關聯特征.句子Si的最終權值為:
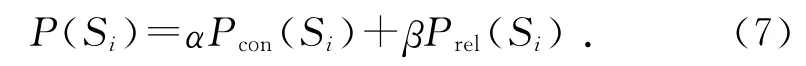
式中:α+β=1,參數α 調整語義權值和聯系權值的權重.為了得到選擇參數α 的最佳取值,α 從0開始以0.1為步進變化到1,得到當壓縮比為1.5%時,ROUGE-1的取值變化如圖7所示.由圖7可知,當α=0.1時ROUGE-1的取值最高.
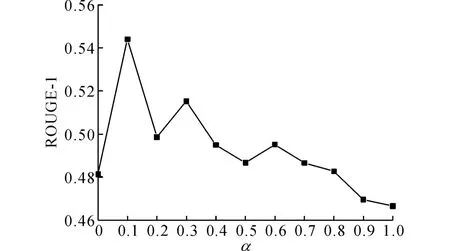
圖7 參數α 選擇實驗Fig.7 Parameter selection experiments ofα
3.5 文摘句選擇
句子選擇模塊根據子主題的重要程度從高到低對子主題排序,確定子主題的抽取順序和抽取句子數,并根據句子的重要性和冗余度在子主題內抽取文摘句.子主題的重要性與兩方面因素有關:1)子主題包含的句子數目,句子數目越多說明該子主題在文檔集合中出現的頻率越高;2)子主題包含句子的重要程度,子主題中平均句子權重越大,該子主題越重要.子主題打分策略如下:
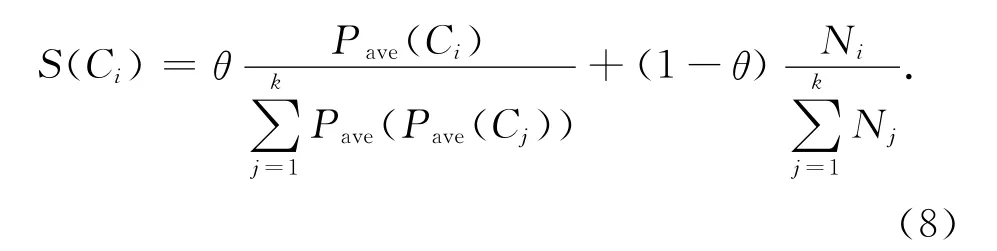
式中:S(Ci)為子主題Ci的得分,Pave(Ci)為子主題Ci的句子平均權值,k 為子主題個數,Ni為子主題Ci包含的句子個數.參數θ用于調整子主題內句子平均權值和句子數目的權重,一般認為兩者同樣重要,本文取θ=0.5.
根據壓縮比,從不同子主題內抽取相應數量的句子生成摘要.子主題句子抽取個數由該子主題的重要程度決定:
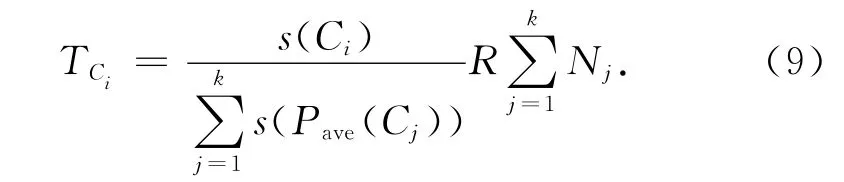
式中:TCi表示子主題Ci的句子抽取個數,R 代表壓縮比的值,Nj表示不同子主題內句子的數目.
在選擇文摘句時,不僅要保證選擇的句子與主題的相關度高,也要保證該句與已選文摘句之間的冗余度盡可能小,從而避免包含同一條重要信息的句子反復出現在文摘里.句子選擇的具體過程如下:

4 實驗及分析
4.1 數據源
實驗數據采用自然語言處理與中文計算會議(NLP&&CC)2013年中文微博觀點要素抽取評測語料[27].該語料包含2013年3月的微博話題,實驗數據的具體描述如表4所示.
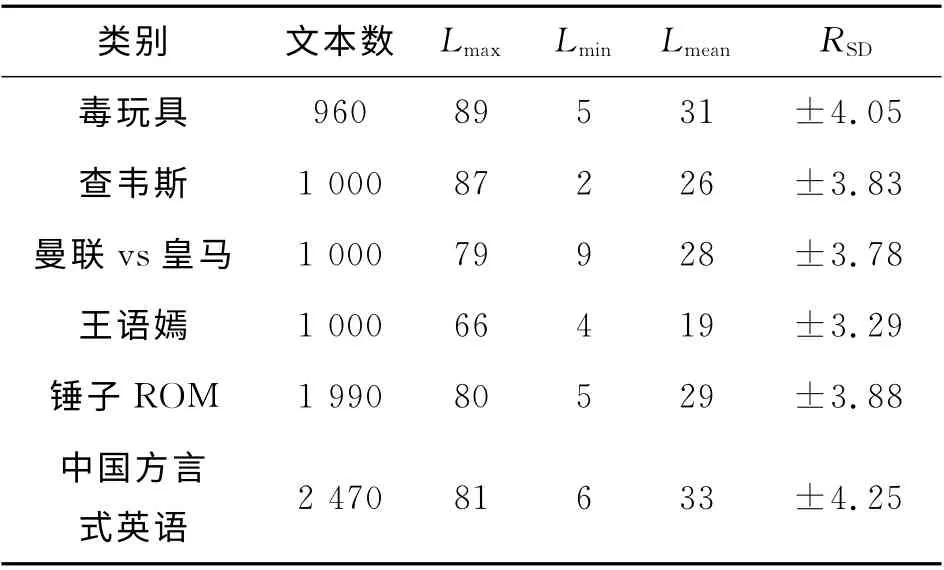
表4 微博摘要實驗數據表Tab.4 Experimental data of weibo summarization
表中,文本有效長度是指經過分詞去除停用詞后,每篇微博包含的詞的個數,Lmax為文本有效長度的最大值,Lmin為文本有效長度的最小值,Lmean為文本有效長度的平均值,RSD表示同一類別下句子文本有效長度的標準差.由北京理工大學信息系統及安全對抗實驗中心對每個話題生成壓縮比為0.5%、1.0%和1.5%的3篇標準摘要.生成過程如下:每3人對同一話題文本集提取不同壓縮比的人工摘要,然后由自然語言處理小組的10名博士、碩士對3份人工摘要進行評價并計算平均得分:將平均得分最高的摘要作為標準摘要放入標準摘要集,如果得分相同則都放入標準摘要集中.
4.2 評價方法
本文采用多文檔摘要的通用評價方法ROUGE[28]toolkit(版本號v1.5.5)作為評價標準.ROUGE方法通過計算候選摘要與標準摘要的詞單元重合度來區分候選摘要的質量,計算的值包括ROUGE-N、ROUGE-W (本 研 究 取W =1.2)和ROUGE-SU*等:
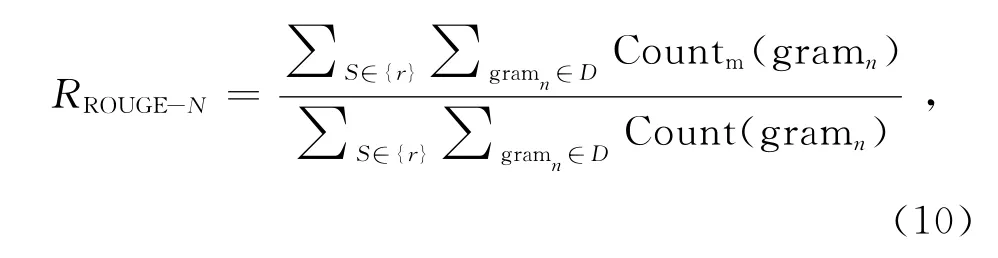
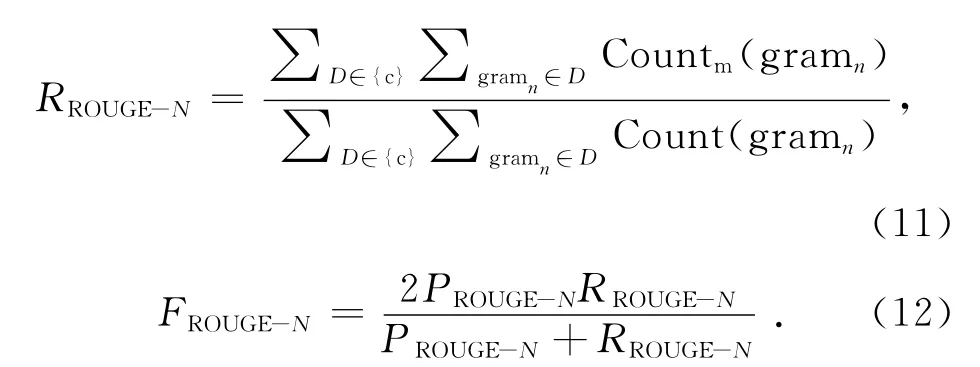
式中:n代表n-gram 的長度,D 表示文檔,其中下標r表示文檔屬于標準摘要,c表示文檔屬于待評價摘要,Countm(gramn)表示同時出現在待評價摘要和標準摘要的n-gram 的個數,Count(gramn)為標準文摘中的n-gram 個數.
4.3 實驗結果及分析
4.3.1 關聯特征 為了驗證引入句子關聯特征對摘要結果的提升,在壓縮比為1.5%的條件下,采用單因子變量法,令Pcon(Si)加權系數α=0.1保持不變,β從0開始以0.05 為步進調整,以加權系數的比值β/(α+β)為自變量,得到ROUGE-1的取值變化如圖8所示.
由圖8所示可知,當β/(α+β)=0時,即不考慮句子的關聯權重,只考慮句子本身的語義權重,ROUGE-1為0.466 58,加入句子關聯權重特征,ROUGE-1值有明顯的改善.當β(α+β)≤0.9 時,ROUGE-1值呈現上升趨勢,且均明顯優于僅考慮語義權重的ROUGE-1 取值;當β(α+β)>0.9 比時,若繼續增加關聯權重的值,ROUGE-1值呈現下降趨勢,當β(α+β)=1.0時即當關聯權重占比遠大于語義權重時,ROUGE-1=0.481 25.實驗結果說明:所提出的句子權值計算方法,在深入理解句子本身語義的基礎上,可以有效量化該句與語料庫中其他句子之間的語義聯系.綜合考慮句子內外部特征的權值計算方法,有利于豐富句子的特征維度,準確描述文本內容與話題的相關度,合理利用句子內外部語義特征,使同類數據內聚性增強、噪音影響減弱,對于選擇關鍵文摘句以及減少文摘的冗余度都很有意義.
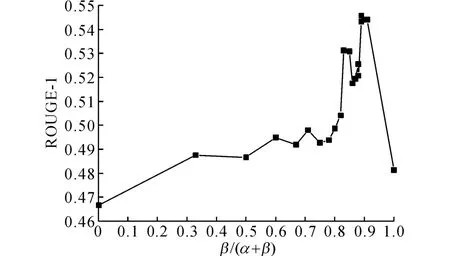
圖8 ROUGE-1值隨加權系數比值的變化趨勢圖Fig.8 Curve of ROUGE-1as weighted coefficient ratio changes
4.3.2 對比實驗 為了驗證所提出方法的有效性,建立了2個對照方法與本文方法進行對比實驗.
Hybird TF-IDF 是Inouye等[19]于2011 年 提出的一種基于聚類的微博話題摘要方法,該方法已被證明比一些主流的多文檔摘要方法效果要好.SumBasic[5]是經典的多文檔摘要方法,在DUC06測評大會上按代表性指標排序排名第三,并已獲得應用.在壓縮比分別為0.5%、1.0%、1.5%的條件下,3組系統的FROUGR-N值實驗結果如表5、6和7所示.
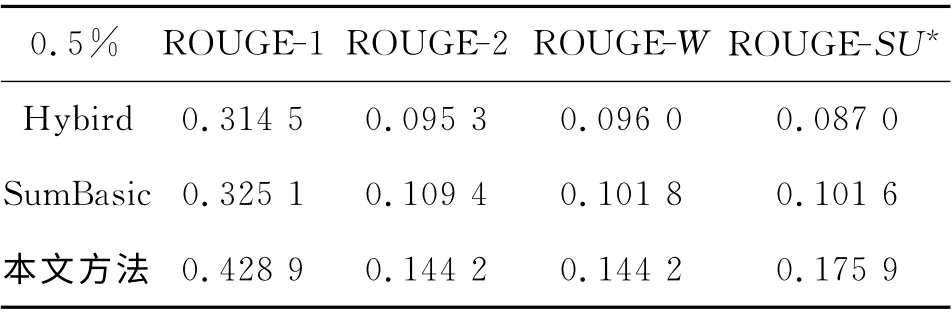
表5 壓縮比為0.5%的對比實驗結果Tab.5 Contrast experiments results with compress ratio at 0.5%
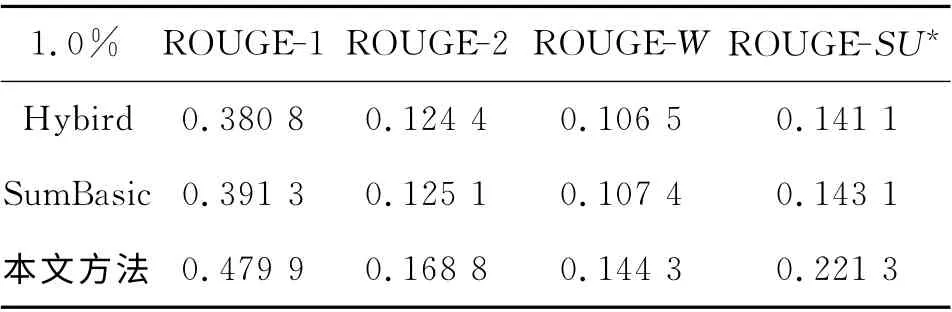
表6 壓縮比為1%的對比實驗結果Tab.6 Contrast Experiments Results with Compress Ratio at 1.0%

表7 壓縮比為1.5%的對比實驗結果Tab.7 Contrast experiments results with compress ratio at 1.5%
由表5~7可知,本文提出的微博話題摘要方法在ROUGE-1,ROUGE-2、ROUGE-W、ROUGESU*的評價指標下平均表現最優,4個指標的值與對比方法相比均有明顯提高.相比于Hybrid TFIDF、SumBasic等基于詞形詞頻的短文本摘要方法,本文生成的摘要在兼顧冗余度的同時與話題更相關,綜合表現ROUGR 值更高.這表明分析句子的句義結構,提取句義特征項和項之間的依存關系可以深入挖掘句子的語義信息,深化了句子分析層次,所提取的句義特征增強了語義特征的表達能力,有效避免了信息丟失;構建相似度矩陣劃分子主題的方法使類內語義相關性增大,同類數據內聚性增強,有效降低了噪聲的影響;綜合考慮句子內部語義特征和外部關聯特征的句子權重計算方法,豐富了句子的特征表示,全面考慮句子的語義環境,從而提升了摘要與話題的相關度.
在壓縮比為0.5%~1.5%時,壓縮比越大,系統的性能越好.這是由于人工抽取標準摘要的隨機性比較大,而壓縮比提高、數據量變大在一定程度上克服了這種隨機性,使得最終得到的摘要更加合理而使評價效果有所提高.
4.3.3 泛化能力實驗 當壓縮比為0.5%、1.0%和1.5%時,計算系統對不同話題的ROUGE 評價指標.因篇幅所限,圖9僅展示壓縮比為1.5%的實驗結果.

圖9 系統泛化能力實驗結果Fig.9 System performance on different topics
由圖9可知,系統在不同話題下的評價結果存在一定的差異.一方面是由于人工抽取標準摘要的隨機性,另一方面是因為不同話題子主題的結構不同.由ROUGE評價指標來看,6個話題的ROUGE-1值 均 在0.45 以 上,ROUGE-2、ROUGE-W 均 在0.10以上,ROUGE-SU*均在0.15以上.因此,本文方法處理不同話題的泛化能力較好,適用范圍較廣.
4.3.4 實例分析 以話題“查韋斯”為例,分別采用Hybird TF-IDF方法和本文方法進行摘要實驗,在壓縮比為0.5%的條件下得到摘要結果如表8 所示.可知,Hybird TF-IDF 生成的摘要包含子主題較少,內容較片面,摘要的冗余度也較大.本文方法生成的摘要覆蓋了話題的多個子主題,內容較全面,摘要冗余度較小,因而本文方法在語義上生成的摘要效果更優.

表8 2種不同方法得到的“查韋斯”話題摘要結果對比Tab.8 Comparison of generated summaries from topic“Chávez”using two different methods
5 結 論
利用句義結構模型深化了句子分析層次,提取的句義特征增強了語義特征的表達能力,可以有效避免信息丟失.同時,所提出的句子權重計算方法綜合考慮了加權句子內部語義特征和外部關聯特征,使得同類數據的內聚性增強,語義相關性增大,有效降低了噪聲的影響,從而使得生成的摘要與話題相關度更高.此外,本文方法處理不同話題的泛化能力較優,適用范圍較廣.
下一步研究的重點是引入句子結構項之間的依存關系作為特征,完善句義結構模型的特征體系,提高文摘句抽取效果,從而生成更高質量的微博話題摘要.
(
):
[1]Wikipedia.Sina Weibo[EB/OL].(2014-11-10)[2015-10-20].https:∥en.wikipedia.org/wiki/Sina_Weibo.
[2]HE Y,SU W,TIAN Y,et al.Summarizing microblogs on network hot topics[C]∥Proceedings of the 2011International Conference on Internet Technology and Applications(iTAP 2011).New York:Piscataway,2011:1-4.
[3]LONG R,WANG H F,CHEN Y Q,et al.Towards effective event detection,tracking and summarization on microblog data[M]∥ Web-Age Information Management.Berlin:Springer,2011:652-663.
[4]WILLIAN H,ZHANG Y.Threshold and associative based classification for social spam profile detection on Twitter[C]∥2013 9th International Conference on Semantics,Knowledge and Grids(SKG).New York:Piscataway,2013:113-120.
[5]VANDERWENDE L,SUZUKI H,BROCKETT C,et al.Beyond SumBasic:task-focused summarization with sentence simplification and lexical expansion[J].Information Processing and Management,2007,43(6):1606-1618.
[6]RADEV D R,JING H,STYS M,et al.Centroid-based summarization of multiple documents[J].Information Processing and Management,2004,40(6):919-938.
[7]SINGH M,KHAN F U.Effect of incremental EM on document summarization using probabilistic latent semantic analysis[C]∥Proceedings of the World Congress on Engineering(WCE 2012).Hong Kong:Newswood Limited,2012:2198.
[8]GAO D,LI W,OUYANG Y,et al.LDA-based topic formation and topic-sentence reinforcement for graphbased multi-document summarization[M]∥Information Retrieval Technology.Berlin:Springer,2012:376-385.
[9]ARORA R,RAVINDRAN B.Latent dirichlet allocation based multi-document summarization[C]∥Proceedings of the 2nd Workshop on Analytics for Noisy Unstructured Text Data.Singapore:ACM,2008:91-97.
[10]BINTI ZAHRI N A H,FUKUMOTO F,MATSUY-OSHI S.Link analysis based on rhetorical relations for multi-document summarization[J].IEICE Transactions on Information and Systems,2013,96(5):1182-1191.
[11]SUJATHA C,CHIVATE A R,GANIHAR S A,et al.Time driven video summarization using GMM [C]∥2013 4th National Conference on Computer Vision,Pattern Recognition,Image Processing and Graphics(NCVPRIPG).Piscataway:IEEE,2013:1-4.
[12]OLARIU A.Clustering to improve microblog stream summarization[C]∥2012 14th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing(SYNASC 2012).Timisoara:IEEE,2012:220-226.
[13]ZHANG R,LI W,GAO D,et al.Automatic Twitter topic summarization with speech acts[J].IEEE Transactions on Audio Speech and Language Processing,2013,21(3):649-658.
[14]KHAN M A H,BOLLEGALA D,LIU G,et al.Multitweet summarization of real-time events[C]∥2013International Conference on Social Computing(SocialCom).Washington DC:ASE/IEEE,2013:128-133.
[15]LIU F,LIU Y,WENG F L.Why is“SXSW”trending?Exploring multiple text sources for twitter topic summarization[C]∥Proceedings of the Workshop on Languages in Social Media(LSM 2011).Strasbourg:Association for Computational Linguistics,2011:66-75.
[16]SHARIFI B,HUTTON M,KALITA J.Summarizing microblogs automatically[C]∥2010Human Language Technologies Conference of the North American Chapter of the Association for Computational Linguistics,NAACL HLT 2010.Los Angeles: ACL,2010:685-688.
[17]HARABAGIU S M,HICKL A.Relevance modeling for microblog summarization[C]∥Proceedings of the 5th International Conference on Weblogs and Social Media.Menlo Park:AAAI,2011:514-517.
[18]CHAKRABARTI D,PUNERA K.Event summarization using Tweets[C]∥Proc of the 5th Int AAAI Conference and Social Media (ICWSM’11).Menlo Park:AAAI,2011:66-73.
[19]INOUYE D,KALITA J K.Comparing Twitter Summarization Algorithms for Multiple Post Summaries[C]∥Proceedings of the 2011IEEE Third International Conference on Privacy,Security,Risk and Trust and IEEE Third International Conference on Social Computing(PASSAT/SocialCom 2011).Boston:IEEE,2011:298-306.
[20]ERKAN G,RADEV D R.LexRank:graph-based lexical centrality as salience in text summarization [J].Journal of Artificial Intelligence Research,2004:457-479.
[21]MIHALCEA R,TARAU P.TextRank:bringing order into texts[C]∥Conference on Empirical Methods in Natural Language Processing (EMNLP),2004.Barcelona:ACL,2004:275-279.
[22]BIAN J,YANG Y,CHUA T.Multimedia summarization for trending topics in microblogs[C]∥22nd ACM International Conference on Information and Knowledge Management,CIKM 2013.San Francisco:ACM,2013:1807-1812.
[23]羅森林,韓磊,潘麗敏,等.漢語句義結構模型及其驗證[J].北京理工大學學報,2013,33(2):166-171.LUO Sen-lin,HAN Lei,PAN Li-min,et al.Chinese sentential semantic mode and verification[J].Transactions of Beijing Institute of Technology,2013,33(2):166-171.
[24]羅森林,劉盈盈,馮揚,等.BFS-CTC 漢語句義結構標注語料庫構建方法[J].北京理工大學學報,2012,32(3):311-315.LUO Sen-lin,LIU Ying-ying,FENG Yang,et al.Method of building BFS-CTC:a Chinese Tagged corpus of sentential semantic structure[J].Transactions of Beijing Institute of Technology,2012,32(3):311-315.
[25]張 華 平.ICTCLAS2013 版 [CP/OL].(2013-11-15)[2015-10-20].http:∥ictclas.nlpir.org/newsdownloads?DocId=352.
[26]BLEI D M,NG A Y,JORDAN M I.Latent dirichlet allocation[J].Journal of Machine Learning Research.2003,3(4/5):993-1022.
[27]中國計算機學會中文信息技術專業委員會.第二屆自然語言處理與中文計算會議技術評測結果[CP/OL].(2013-06-15)[2015-10-20].http:∥tcci.ccf.org.cn/conference/2013/pages/page04_evares.html.
[28]LIN C Y.Rouge:apackage for automatic evaluation of summaries[C]∥Text Summarization Branches Out:Proceedings of the ACL-04 Workshop.Barcelona:ACL,2004:74-81.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
