基于語義細胞的語音情感識別
2015-07-11 10:09:28孫凌云何博偉楊智淵
浙江大學學報(工學版) 2015年6期
孫凌云,何博偉,劉 征,楊智淵
(1.浙江大學 現代工業設計研究所,浙江 杭州310027;2.中國美術學院 設計藝術學院,浙江 杭州310024)
語音是用來表示語言的聲音符號,是人類相互交流、傳遞情感的重要媒介之一.語音情感識別是情感計算領域的重要研究方向,其目標是通過語音信號識別說話者的情感狀態,最終實現自然、友好和生動的人機交互.語音情感識別技術可以用于交互式教學、智能車載系統以及智能家電等諸多領域,如:Schuller等[1]研發的在線電影和計算機教程應用程序中,系統根據檢測到的情感信息對用戶做出響應;Jones等[2]將語音情感識別技術用于車載系統,合成與駕駛人情感匹配的提示語音以增強駕駛體驗.使用語音特征數據訓練分類器是目前語音情感識別系統的主要做法.語音特征有韻律學特征、基于譜的特征和音質特征3大類[3],通常包括基頻、能量、時長以及頻譜系數等.
提取語音特征后,語音情感識別任務一般通過模式識別分類器解決.常用的模式識別算法包括支持向量機(support vector machine,SVM)[4]、人工神經網絡(artificial neutral network,ANN)[5]、隱馬爾可夫模型(hidden Markov model,HMM)[6-7]、高 斯 混 合 模 型 (Gaussian mixture model,GMM)[8]、k-近鄰(k-nearest neighbor,k-NN)[9]以及Boosting[10]等.每種分類器都有其特性,如:基于k-NN 的分類器由于其非參數化的特點,分類器計算簡單、易實現;基于SVM 的分類器需要相對較長的訓練時間,但是學習后泛化能力較好,對于處理小樣本數據表現出較好的性能.不同分類器在不同語料庫和語音特征設定下的性能存在差異,因此有研究混合使用不同的分類器,結合不同分類器的特性以提高最終的識別準確率及識別魯棒性.黃永明等[11]使用GMM 和SVM 構造層疊式識別結構,分別訓練產生和判別階段的識別模型,獲得了最高81.5%的識別準確率.蔣丹寧等[12]利用概率神經網絡(probabilistic neural network,PNN)和HMM分別對統計、時序特征處理并融合識別結果,在特征融合后,識別準確率得到有效提高.
人們對語音情感的描述是基于模糊認知的一種主觀描述與感性認知,是對模糊現象的描述.上述大多數分類器進行分類工作時,往往并未考慮情感表達模糊概念的認知過程,例如:SVM 分類器著眼于在高維空間精確劃分2種情感對應語音特征數據的界限;ANN 分類器的隱含層結構通過學習數據的分類規則進行分類.
語義細胞理論由Tang等[13]提出,其基礎是模糊計算和原型理論,主要思想如下:概念并非由形式規則或映射來表示,而是由其原型來表示,概念范疇則基于同原型的相似性來判定.語義細胞理論已被應用于預測Mackey-Glass時間序列以及太陽黑子問題,其性能優于Kim&Kim 和自回歸模型算法[14].語義細胞具有透明的認知結構,符合人類學習概念的認知過程,有堅實的認知心理學基礎與嚴格的數學定義,具備描述模糊概念的先天優勢.語音情感識別是模糊概念領域中的典型問題,語音中的情感分類(如:憤怒、驚奇)是一種模糊概念,難以憑借具體規則進行界定.而通過原型表達概念的語義細胞由于其不依賴具體分類規則的特點,適用于語音情感識別.
本文提出基于語義細胞的語音情感識別算法,使用語音情感特征數據訓練語義細胞模型作為分類器,并與k-NN、GMM 以及SVM 算法進行比較.
1 語義細胞理論
1.1 語義細胞模型
一個語義細胞模型L 是一個三元組<P,d,δ>.其中,P 為概念的原型集合(prototypes);d 為概念所在論域Ω 上的一個距離函數,用于刻畫語義細胞的半徑或邊界;δ為正實數域R+上的一個概率密度函數,用于刻畫語義細胞半徑的密度分布.直觀上來看,一個語義細胞模型L 的認知結構可以概括為一個語義細胞核與一個語義細胞膜.其中,語義細胞核對應典型實例集合P,而語義細胞膜則體現了概念的邊界(由d 刻畫);由于認知上的主觀不確定性,概念的邊界也具有不確定性(由δ刻畫).在此給出語義細胞模型的定義.
定義1 語義細胞模型.一個模糊概念Li=about Pi對應的語義細胞模型可以表示為三元組<Pi,di,δi>.其中,Pi是 概 念Li的 一 組 原 型;di是在Ω 域上的距離函數,對任意X,Y∈Ω,di(X ,Y )?d (X ,Y );δi是定義在[0,+∞)上 的 概 率 密 度 函數,有
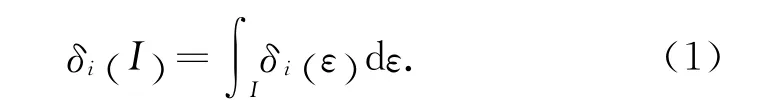
該概率密度函數定義如下:
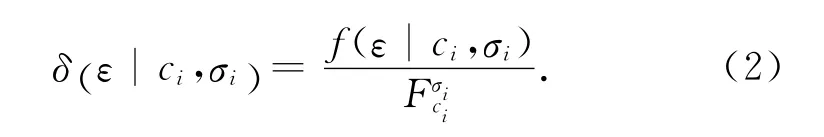
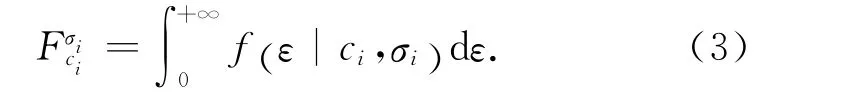
一般地,函數f 為正態分布的概率密度函數,即
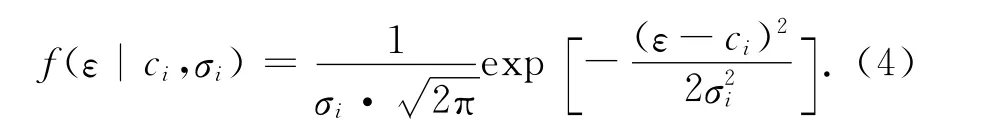
定義2 語義細胞模型正鄰域函數.對任意X ∈Ω,X 與語義細胞模型Li=〈Pi,di,δi〉的正鄰域函數μLi(X )定義如下:
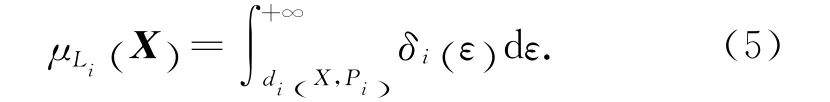
根據式(5)計算給定測試例X∈Ω 與單個語義細胞模型Li的正鄰域函數值,該函數值表明X 是Li所描述概念集合一員的隸屬度.
1.2 語義細胞混合模型
單個語義細胞模型通常無法表示復雜概念.對于一個復雜概念,可以通過構造由多個語義細胞構成的語義細胞混合模型(information cell mixture model,ICMM)進行描述.
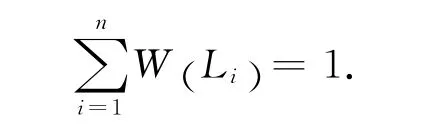
定義4 混合模型正鄰域函數.對任意X∈Ω,X 與語義細胞混合模型的正鄰域函數為
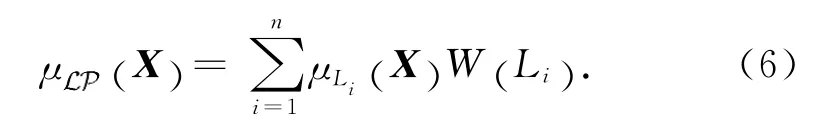
基于上述概念及定義,構造一種訓練算法,稱為語義細胞更新算法[13].該算法從一組數據集DB ={X1,X2,…,XN}中訓 練 構造混合模 型,目 標 是優化目標函數J,使語義細胞能覆蓋盡可能多的觀測數據:
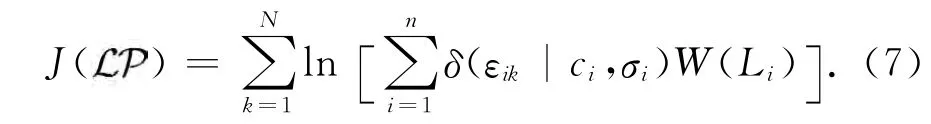
式中:εik=d (Xk,Pi).
2 基于語義細胞的語音情感識別
2.1 基于單層語義細胞的識別算法
首先采用基于單層語義細胞的識別算法(single-layered information cell,IC-S)進行語音情感識別.基于語義細胞理論,定義每個情感分類為一個模糊概念集合,內含若干個能最大程度代表該情感的子概念(語義細胞),如圖1所示.情感的認知過程即語義細胞混合模型=〈L,W〉的更新過程.
識別過程分為訓練、測試階段,如圖2所示.首先對輸入的語音音頻信號提取語音情感特征數據.
訓練階段:使用語義細胞更新算法,用M 種情感語音的特征數據生成M 個語義細胞混合模型i(i=1,2,…,M).
測試階段:使用式(6)分別計算待測語音的特征向量(X)與M 個混合模型i(i=1,2,…,M)的隸屬度μi(X )(i=1,2,…,M).再使用決策方法根據隸屬度值判斷該語音所屬的情感分類:本文取隸屬度值最大的分類為判定的情感分類.
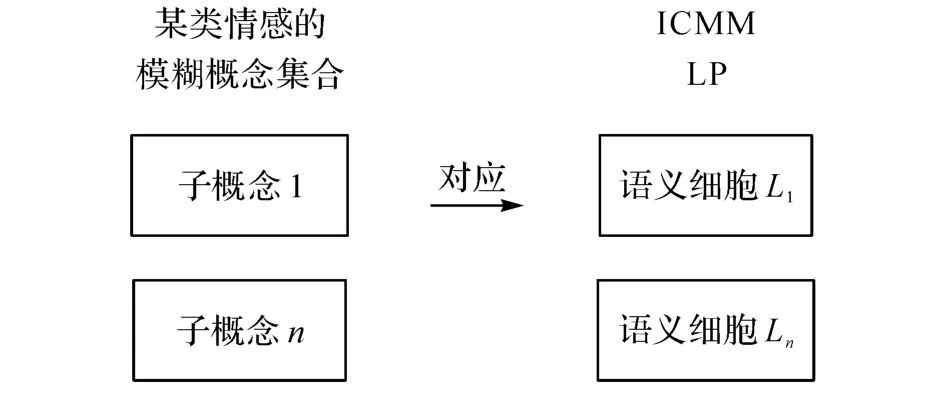
圖1 語音情感到ICMM 的映射Fig.1 Mapping from speech emotion to ICMM
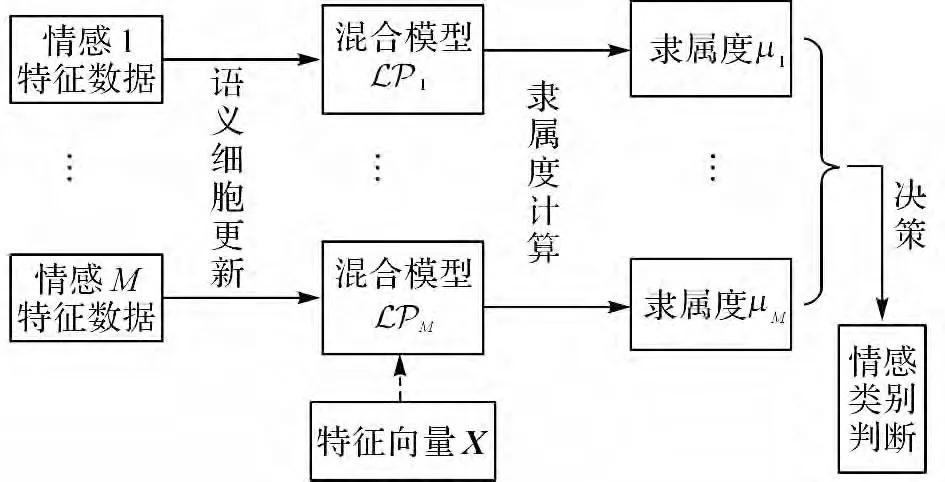
圖2 基于情感隸屬度的語音情感識別算法Fig.2 Speech emotion recognition algorithm based on emotion membership
2.2 基于雙層語義細胞的識別算法
2.2.1 識別流程 不同的個體說話方式不盡相同,表述自身情感的方式也有差異.Campbell[15]通過研究100名說話人各30min的對話語音數據,發現各被試者的發音時長、暫停、韻律分布雖然總體特性相同,但是其時序模式的變化并不一致.Gupta等[16]先區分性別,再提取語料中的情感特征,并使用樸素貝葉斯分類器進行語音情感識別,結果表明:識別準確率比區分性別前提高了3.57%.基于上述原因,本文采用“說話人識別-說話人情感識別”的雙層結構進行語音情感的識別,該方法稱為基于雙層語義細胞的識別(dual-layered information cell,C-D)算法.
識別過程分為訓練、測試2 個階段.在訓練階段,系統首先提取所有語料庫中音頻數據的特征向量.經預處理(預加重濾波、降維)后,分別利用各說話人所有情感的語音數據訓練每個說話人的混合模型(P),然后訓練每個說話人處于不同情感狀態下語音數據的混合模型(E),如圖3所示.
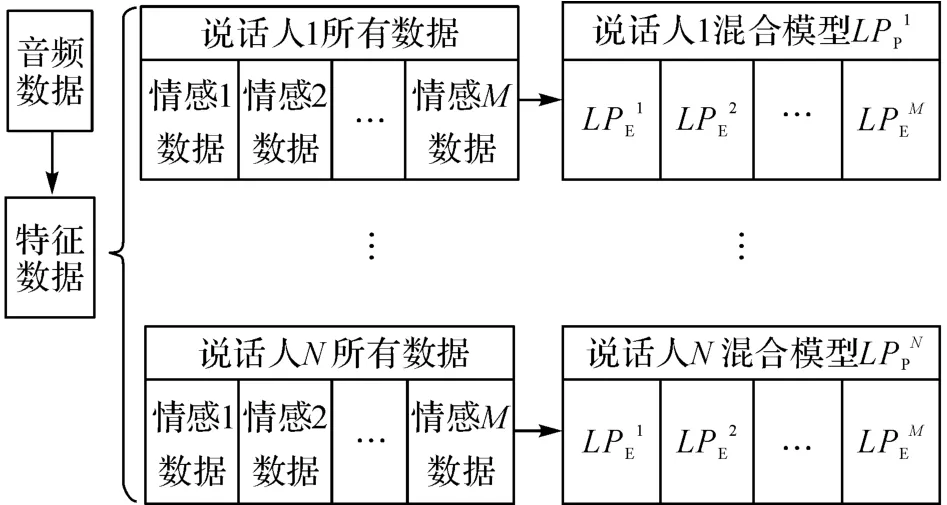
圖3 IC-D算法的訓練過程Fig.3 Training procedure of IC-D algorithm
在測試階段,系統使用與訓練過程相同的方法對測試例X 的音頻數據進行特征向量提取及預處理.使用X 與每個說話人、每個說話人不同情感的混合模型(P、E)計算各自的正鄰域函數(隸屬度)值μ (X ):N 名說話人M 種情感分類共N +N×M 個隸屬度值.使用決策方法根據隸屬度值進行決策,依照各隸屬度的大小給出最終所屬情感類型的判定.
本研究采用加權投票法作情感類型決策.利用下式計算測試例X 屬于某種情感e 的支持度:
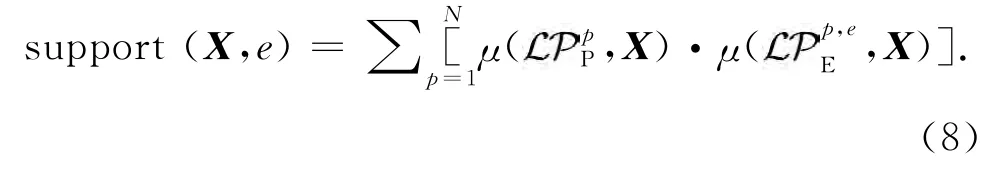
即測試例X 屬于某種情感e 的支持度由其所屬說話人的隸屬度及該說話人情感的隸屬度共同決定.式(8)中為訓練集說話人p 的混合模型,為訓練集中說話人p 情感類型e 的混合模型.
2.2.2 識別算法 IC-D 模型訓練算法、IC-D 語音情感識別算法如下,其中數據集DB 為將音頻數據經過情感特征提取、預處理后的特征數據.
算法1 IC-D 模型訓練算法.
輸入:數據集DB;混合模型的階數n1、n2.
1)初始化數據集:將數據集根據N 名說話人分為N 類,記作DB{p},p=1,2,…,N;再根據各自的M 種情感類型分為M 類,記作DB{p,e},p=1,2,…,N,e=1,2,…,M.共計N+N×M 個子集;
2)FOR p=1,2,…,N DO
a)訓練DB{p}的n1階混合模型pP;
b)FORe=1,2,…,M DO
i.訓練DB{p,e}的n2階混合模型:pE,e;
c)ENDFOR
3)ENDFOR
算法2 IC-D 語音情感識別算法.
輸入:含K 條觀測值的數據集DB={Xk:k=1,2,…,K};N 名說話人的混合模型,p=1,2,…,N;N 名說話人M 類情感的混合模型,p=1,2,…,N,e=1,2,…,M.
輸出:測試數據所屬情感分類的預測值Yk,k=1,2,…,K.
1)FORk=1,2,…,K DO

2)ENDFOR
3 語音情感識別實驗
3.1 實驗設定
識別實驗在Windows 8.1(64 位)操作系統中進行,識別算法使用Matlab 實現.為降低過擬合(over-fitting)現象對結果的影響,實驗時采用10倍交叉檢驗(corss-validation)法.
3.1.1 語料庫 為測試算法在不同語料庫中的性能,分別使用CASIA 漢語情感語料庫[17]及SAVEE英 語 情 感 語 料 庫[18].CASIA 庫 共 使 用1 200 句 語句,包含憤怒、害怕、高興、悲傷、驚訝以及中性6類情感,由4名說話人(2男2女)錄制,每類情感每人50句語句.SAVEE 庫共使用360 句語句,包含憤怒、厭惡、害怕、高興、悲傷以及驚訝6種情感,由4名男性說話人錄制,每類情感每人15句語句.
3.1.2 情感特征 實驗中從語音提取的特征有384維,包括聲學特征及韻律學特征,共5 類:能量方均根、1~12階梅爾頻率倒譜系數(Mel-frequency cepstral coefficient,MFCC)、過零率、濁音度以及F0倒譜基頻.每類特征通過分幀提取,同時計算其1階差分系數(first order delta coefficient).計算上述特征的12項統計值:最大值、最小值、范圍(最大值-最小值)、最大值幀位置、最小值幀位置、算術均值、線性擬合斜率/截距/平方誤差、標準差、三階偏度系數(skewness)以及四階峰度系數(kurtosis).
特征值的提取使用OpenSMILE 工具[19].在提取特征值前使用預加重濾波器進行濾波,其傳遞函數為 H (z) =1-0.97z-1.
為避免數據維度過高帶來的維度災難問題,使用 主 成 分 分 析 法(principle components analysis,PCA)對提取出的特征進行降維,將CASIA 庫的數據降至80維,SAVEE庫的數據降至45維.
3.2 實驗結果
3.2.1 不同參數下的識別結果 根據定義4,基于語義細胞的語音情感識別算法IC-S及IC-D 需要給定混合模型的階數n作為輸入參數.參數的個數即識別算法的層數:IC-S算法為單層識別,需要一個階數n;IC-D算法為雙層識別,每層的階數分別記作n1、n2.
參數值的改變會對實驗結果造成影響.階數的增大會導致存儲語義細胞所需的空間線性增大,導致識別速度的降低,因此本研究根據語料庫的數據量選取如下參數進行測試:
1)IC-S:n =1,2,3,4,5;
2)IC-D:n1=1,2,3,4,5;n2=1,2,3;
實驗結果通過F 值(F-score)評判來權衡結果的準確率α及召回率β:

2種識別算法的測試結果如圖4、5所示.實驗結果表明:1)在使用單層識別算法IC-S時,混合模型階數n =1 時結果最優,其F 值為0.447(CASIA),0.438(SAVEE);2)在使用雙層識別算法IC-D時,使用CASIA 語料庫得到的最優參數為n1=3,n2=1(F=0.652),使用SAVEE語料庫得到的最優參數為n1=1,n2=1(F=0.548),但是2個語料庫在n2=1時,F 值隨參數n1變化不明顯(CASIA:0.629~0.652,SAVEE:0.509~0.548).
3.2.2 與其他算法的比較 選取k-NN、GMM 和SVM 算法與本研究提出的2種識別算法進行比較,具體設定如下:
1)k-NN:k-近鄰分類器,近鄰數k=5,一對多決策(one-vs-all);
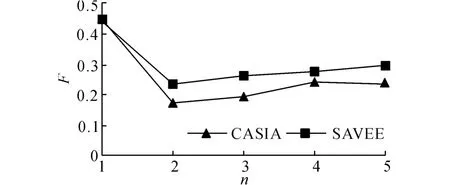
圖4 ICMM 階數n的變化對IC-S算法識別結果的影響Fig.4 Impact of variation of ICMM order non recognition results using IC-S algorithm
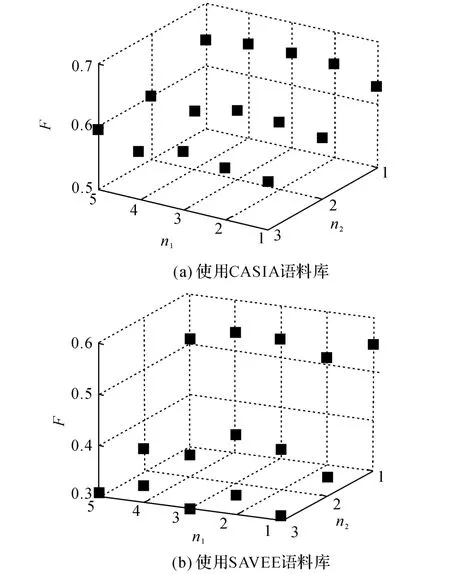
圖5 ICMM 階數(n1,n2)的變化對IC-D 算法識別結果的影響Fig.5 Impact of variation of ICMM order(n1,n2)on recognition results using IC-D algorithm
2)GMM:高斯混合模型分類器,高斯分量數為5,一對多決策;
3)SVM:基 于 徑 向 基(radial basis function,RBF)核函數的支持向量機,一對一決策(one-vsone);
4)IC-S:本研究提出的基于單層語義細胞的識別算法,混合模型階數n=1;
5)IC-D:本研究提出的基于雙層語義細胞的識別算法,混合模型的階數分別為n1=3,n2=1;
在2種語料庫上實驗的結果如表1、2所示,識別結果采用F 值給出.

表1 CASIA語料庫的識別結果(F 值)Tab.1 Emotion recognition results on CASIA corpus(F-score)

表2 SAVEE語料庫的識別結果(F 值)Tab.2 Emotion recognition results on SAVEE corpus(F-score)
本研究提出的2種識別算法的對比實驗結果證明了上文關于說話人特質不同影響情感識別準確率的假設.由表1、2 可以看出,IC-S算法的識別性能(CASIA:0.450,SAVEE:0.421)與其他方法相比有所不足,但是IC-D 算法的識別性能(CASIA:0.650,SAVEE:0.541)略優于SVM 算法(CASIA:0.590,SAVEE:0.539),顯著優于k-NN 算法(CASIA:0.547,SAVEE:0.454)及GMM 算法(CASIA:0.542,SAVEE:0.452).
整體而言,各算法識別CASIA 語料庫時的性能比識別SAVEE 語料庫時好,這種結果與訓練集數量、情感類型以及語料的錄制環境有一定關系.與另外3 種算法類似,本文方法在識別“憤怒”、“中性”、“驚訝”情感時性能相對較好,在識別CASIA語料庫中的“害怕”、“悲傷”情感和SAVEE 語料庫中的“中性”情感時性能較為一般.
在存儲空間需求方面,基于語義細胞的2種識別方法均具備對存儲空間需求低的優勢.如圖6所示為10倍交叉驗證第一折時各算法的模型存儲所用存儲空間大小Η.由圖6可知,IC-S/IC-D占用存儲空間明顯小于另外3種方法:CASIA語料庫模型為13KB/57 KB(SVM:758KB)、SAVEE 語料庫僅需5KB/24KB(SVM:125KB).由此可見,雖然IC-D算法采用了二層識別結構,所建立的模型比其他數據庫多,但是其建立的所有混合模型總數據量仍然小于其他算法.
不同識別算法在交叉檢驗測試階段的耗時(ttest)如圖7所示.由圖7可知,與k-NN 及GMM 算法相比,IC-S算法耗時較短,而IC-D算法耗時較長.
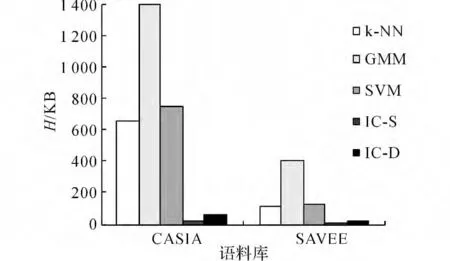
圖6 交叉檢驗第一折時5種算法模型所占的存儲空間Fig.6 Disk storage consumption of five algorithms at first fold of cross-validation
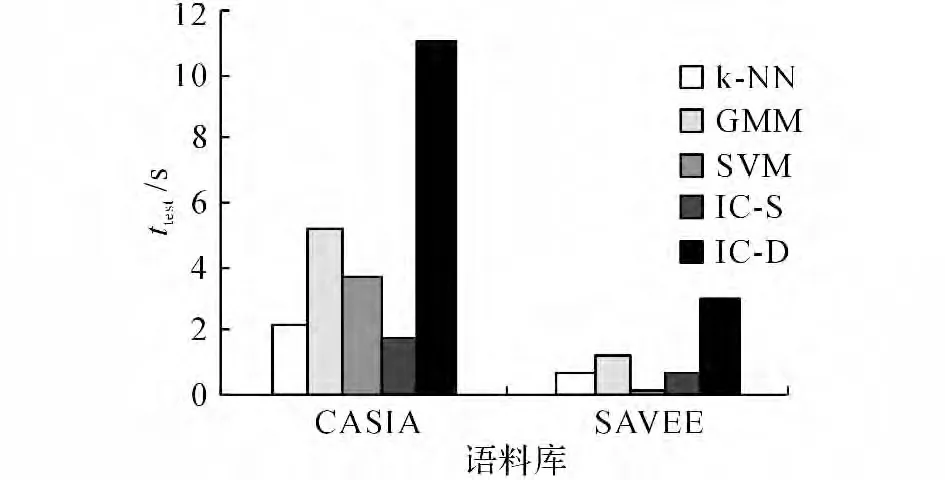
圖7 交叉檢驗情感識別用時Fig.7 Time consumption of cross-validation
3.3 討論
實驗結果表明:IC-S算法的識別性能相比其他方法有時間復雜度的優勢,IC-D 算法相比其他算法時間復雜度高;相比其他算法,這2種識別算法的空間需求明顯降低.
空間需求的優勢來源于語義細胞的“原型”概念.在訓練得到的每個混合模型中,僅需存儲n個語義細胞的特征數據(P)及每個語義細胞的參數(d,δ,W).通常情況下,每個混合模型內僅需數個原型P 即可覆蓋觀測值中的大部分數據.相比之下,傳統k-NN 算法需要存儲所有的特征數據,GMM 算法需要存儲各維度各高斯分量的參數,SVM 算法需要存儲用于分割超平面的支持向量.在常見的應用場景中,三者構成的識別模型數據量都大于本研究提出的IC-S及IC-D 算法的數據量.
關于時間復雜度方面,IC-S算法在情感識別時間上存在一定優勢,這種優勢依舊來源于原型的存儲.計算隸屬度時,通常達到最佳識別率僅需少量混合模型,當訓練集數據量較大時(如:使用CASIA語料庫),相比其他算法耗時更少.然而采用IC-D算法時所需混合模型的個數與第一層結構中的混合模型數量正相關(本文第一層為4個混合模型),情感識別的時間因此增加.盡管如此,對單條測試數據而言,IC-D平均耗時為9ms,實驗中最快的IC-S平均耗時為2ms.由此可見,在即時性要求不高的應用場景中,其運算時間的差別很難對用戶體驗造成影響.
4 結 語
本文提出了基于語義細胞理論的2種語音情感識別算法.在CASIA 及SAVEE語料庫上的實驗結果表明:IC-S算法用于語音情感識別時的精確度有限,但是在空間、時間復雜度上具有一定優勢;而IC-D 算法在保證與SVM 算法相似識別精準度的前提下,仍能有效降低存儲識別模型所需的數據量.這一特性揭示了本文算法在對于說話人分類較少的應用場景(如:遠程教學系統)以及說話人較為固定的場景(如:車載駕駛系統)中的應用優勢.此外,本文算法適用于對存儲空間敏感的應用場景,如嵌入式設備.
后續研究將圍繞下列方向展開:1)研究說話人分類方法,將IC-D 算法的說話人識別改進為說話人分類識別,提高算法的通用性;2)優化特征降維方法,使用特征選擇代替PCA 特征提取法,增加降維的針對性;3)融合多種分類器,利用不同分類器的特性優化識別準確率;4)采用并行識別架構.對不同情感分類的數據分組、并行計算模型參數,融合各組識別結果.
(
):
[1]SCHULLER B,RIGOLL G,LANG M.Speech emo-tion recognition combining acoustic features and linguistic information in a hybrid support vector machine-belief network architecture[C]∥IEEE International Conference on Acoustics,Speech,and Signal Processing,Proceedings(ICASSP'04).Montreal:IEEE,2004:1(1):577-580.
[2]JONES C M,JONASSON M.Performance analysis of acoustic emotion recognition for in-car conversational interfaces[M]∥Universal Access in Human-Computer Interaction. Ambient Interaction. Berlin Heidelberg:Springer,2007:411-420.
[3]韓文靜,李海峰,阮華斌,等.語音情感識別研究進展綜述[J].軟件學報,2014,25(1):37-50.HAN Wen-jing,LI Hai-feng,RUAN Hua-bin,et al.Review on speech emotion recognition[J].Journal of Software,2014,25(1):37-50.
[4]張瀟丹,黃程韋,趙力,等.應用改進混合蛙跳算法的實用語音情感識別[J].聲學學報,2014,39(2):271-280.ZHANG Xiao-dan,HUANG Cheng-wei,ZHAO Li,et al.Recognition of practical speech emotion using improved shuffled frog leaping algorithm [J].Acta Acustica,2014,39(2):271-280.
[5]GHARAVIAN D,SHEIKHAN M,NAZERIEH A,et al.Speech emotion recognition using FCBF feature selection method and GA-optimized fuzzy ARTMAP neural network [J].Neural Computing and Applications,2012,21(8):2115-2126.
[6]李翔,李昕,胡晨,等.面向智能機器人的Teager語音情感交互系統設計與實現[J].儀器儀表學報,2013,34(8):1826-1833.LI Xiang,LI Xin,HU Chen,et al.Design and implementation of speech emotion interaction system based on Teager for intelligent robot[J].Chinese Journal of Scientific Instrument,2013,34(8):1826-1833.
[7]LIN J C,WU C H,WEI W L.Error weighted semicoupled hidden Markov model for audio-visual emotion recognition[J].IEEE Transactions on Multimedia,2012,14(1):142-156.
[8]BHAYKAR M,YADAV J,RAO K S.Speaker dependent,speaker independent and cross language emotion recognition from speech using GMM and HMM[C]∥IEEE National Conference on Communications(NCC 2013).New Delhi:IEEE,2013:1-5.
[9]KHAN M,GOSKULA T,NASIRUDDIN M,et al.Comparison between k-NN and SVM method for speech emotion recognition[J].International Journal on Computer Science and Engineering,2011,3(2):607-611.
[10]PAN S,TAO J,LI Y.The CASIA audio emotion rec-ognition method for audio/visual emotion challenge 2011[C]∥Affective Computing and Intelligent Interaction.Berlin Heidelberg:Springer,2011:388-395.
[11]黃永明,章國寶,董飛,等.層疊式“產生/判別”混合模型的語音情感識別[J].聲學學報,2013,38(2):231-240.HUANG Yong-ming,ZHANG Guo-bao,DONG Fei,et al.Speech emotion recognition using stacked generative and discriminative hybrid models[J].Acta Acustica,2013,38(2):231-240.
[12]蔣丹寧,蔡蓮紅.基于語音聲學特征的情感信息識別[J].清華大學學報:自然科學版,2006,46(1):86-89.JIANG Dan-ning,CAI Lian-hong.Speech emotion recognition using acoustic features[J].Journal of Tsinghua University:Science and Technology,2006,46(1):86-89.
[13]TANG Y,LAWRY J.Information cell mixture models:the cognitive representations of vague concepts[M]∥Integrated Uncertainty Management and Applications.Berlin Heidelberg:Springer,2010:371-382.
[14]TANG Y,LAWRY J.Linguistic modelling and information coarsening based on prototype theory and label semantics[J].International Journal of Approximate Reasoning,2009,50(8):1177-1198.
[15]CAMPBELL N.Individual traits of speaking style and speech rhythm in a spoken discourse[M]∥Verbal and Nonverbal Features of Human-Human and Human-Machine Interaction.Berlin Heidelberg:Springer,2008:107-120.
[16]GUPTA S,MEHRA A.Gender specific emotion recognition through speech signals[C]∥IEEE International Conference on Signal Processing and Integrated Networks(SPIN).Noida:IEEE,2014:727-733.
[17]TAO J H,YU J,KANG Y G.An expressive mandarin speech corpus[C]∥The International Committee for the Co-ordination and Standardization of Speech Databases and Assessment Techniques.Bali Island:COCOSDA,2005.
[18]HAQ S,JACKSON P J B,EDGE J.Audio-visual feature selection and reduction for emotion classification[C]∥International Conference on Auditory-Visual Speech Processing(AVSP’08).Tangalooma:AVSP,2008:185-190.
[19]EYBEN F,W?LLMER M,SCHULLER B.Opensmile:the munich versatile and fast open-source audio feature extractor[C]∥ACM Proceedings of the international conference on Multimedia.Firenze:ACM,2010:1459-1462.
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
開放教育研究(2020年2期)2020-03-31 01:54:14
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
