可追蹤供應鏈中非確定性RFID數據處理方法
2015-10-10 07:53:19謝東肖杰郭廣軍江彤
中南大學學報(自然科學版) 2015年5期
關鍵詞:一致性
謝東,肖杰,郭廣軍,江彤
?
可追蹤供應鏈中非確定性RFID數據處理方法
謝東1, 2,肖杰3,郭廣軍4,江彤1
(1. 湖南人文科技學院計算機科學技術系,湖南婁底,417000;2. 中南大學信息科學與工程學院, 湖南長沙,410083;3. 湖南第一師范信息技術系,湖南長沙,410205;4. 婁底職業技術學院電子信息工程系, 湖南婁底,417000)
針對可追蹤供應鏈應用系統中大量非確定性RFID數據不能被有效處理的問題,通過分析RFID應用的關鍵特征,根據非確定性數據的比例來調整滑動窗口,采用不同策略處理不同類型的非確定性數據,提出可處理各種類型非確定性數據的清洗方法;根據對象在供應鏈中出現的位置及其連續性來區分多讀、漏讀和不完整數據,基于對象在物流節點中移動路徑對應的有向圖進一步提出可適應對象分組和獨立移動的處理算法。研究結果表明:提出的方法具有良好的清洗效果、存儲效率以及查詢性能,在不同參數條件下能有效地支持對象路徑查詢。
供應鏈;無線射頻識別;非確定性數據
無線射頻識別(RFID)技術[1]是對物體貼上具有唯一標示符的電子產品標簽(electronic product code,EPC),再進行無線識別的方法,能自動被RFID閱讀器識別并生成大量數據,被廣泛應用于供應鏈管理(supply chain management, SCM)中[1]。RFID應用跨越多個企業來獲取RFID對象的屬性和位置數據,根據對象在不同時期的位置信息(數據血統)來追蹤其歷史軌跡和位置。盡管大多數RFID數據是精確的,但由于RFID閱讀方位感知的敏感、干擾、閱讀部件故障和一些環境因素,RFID原始數據往往是不完整、不精確甚至是錯誤的。非確定性RFID數據類型一般包括:1) 由于閱讀角度、信號閉塞、信號盲區等因素,難以獲取對象確定位置導致漏讀數據;2) 由于不同的RFID閱讀器可能存在交叉的閱讀區域,同一個RFID對象可能被不同的RFID閱讀器讀取,從而具有不同位置的非一致性數據;3) 閱讀器在閱讀區域可能獲取不存在的信號,這種信號被識別為并不存在的RFID對象,導致多讀數據;4) 有源的RFID閱讀器可能在不同時間間隔內頻繁地讀取沒有移動的RFID對象,從而產生具有不同時間戳但具有相同位置信息的冗余數據;5)非完整數據表現為RFID對象數據沒有出現在供應鏈中的某些位置,主要原因為假貨在某個供應鏈節點進入供應鏈或RFID對象被偷。以上這些問題導致用戶查詢難以直接在非確定性RFID數據上進行操作。由于傳統的ER模型難以表達RFID數據的時序性,Wang等[2]提出了DRER模型,將RFID數據分為基于事件和基于狀態2種類型,并進一步考慮了移動閱讀器,細化了應用場景并建模[3]。然而,這些工作涉及多個相關位置的路徑查詢,需要對存儲數據進行多次自連接,導致效率較低,且沒有考慮非確定性數據。基于時間平滑的策略[4]通過靜態窗口來填補漏讀數據,但無法根據數據的實時特性去靈活調整窗口大小。Jeffery等[5]提出了一種自適應時空平滑過濾器,但填補效果較差。谷峪等[6]通過監控物體所在小組的動態分析來實現數據清洗,但需要先進行數據清洗才能被RFID應用使用。粒子濾波[7]從能直接觀測的明顯狀態(如RFID閱讀器的位置)推測不能直接觀測的隱藏狀態(如物流對象位置),但重采樣階段會損失樣本的有效性和多樣性,導致定位不準。文獻[8]和[9]分別采用高斯混合分布和時變的圖模型來獲取數據的非確定性,但在移動手持機環境下,仍然定位不準。上述方法均只針對漏讀,未考慮不一致數據。基于可能世界語義的非確定性數據管理[10]。PCQA語義[11]建立非一致性數據[12]的所有可能世界語義和所有可能一致性的子集,但假定數據是獨立的。謝東[14]在可能世界語義基礎上發展了一種可擴展的非確定性數據處理平臺,在高層應用上能直接對非確定性數據進行處理,但這些方法都沒有考慮漏讀數據。以上工作均沒有考慮所有類型的非確定性數據,在這些數據形成的海量可能世界實例上難以有效地進行涉及多個相關位置的路徑追蹤。本文作者考慮所有類型的非確定性數據,在基于一階邏輯的非一致性數據處理方法[15]和非確定性RFID數據模型[16]等工作基礎上,通過分析RFID對象的關鍵特征,提出一種非確定性數據處理方法,根據漏讀與多讀、冗余和非一致性數據的比例來調整滑動窗口,采用不同策略處理漏讀、多讀、冗余、非一致性和非完整性(假貨與對象被偷)數據,并根據對象在供應鏈中出現位置及其連續性來識別多讀、漏讀和非完整數據;通過建立表達對象路徑的有向圖,進一步提出可適應對象分組和獨立移動的處理算法,處理后的數據在不同參數條件下能有效地支持包括跟蹤、追蹤、聚集、循環和長路徑等對象路徑查詢。
1 非確定性RFID數據的處理方法
1.1 基于RFID的供應鏈
基于RFID的供應鏈流程如圖1所示。其中,可能是一個多讀數據,但并不存在;被重復讀取,在沒有改變位置的情況下將生成冗余數據;被漏讀,需要根據相關信息來推斷它的位置;被2個閱讀器同時讀取,具有2個不同的位置;假貨在供應鏈中游加入;在倉庫被偷;特別地,多讀、假貨與對象被偷類似,都不存在于供應鏈的某些位置。
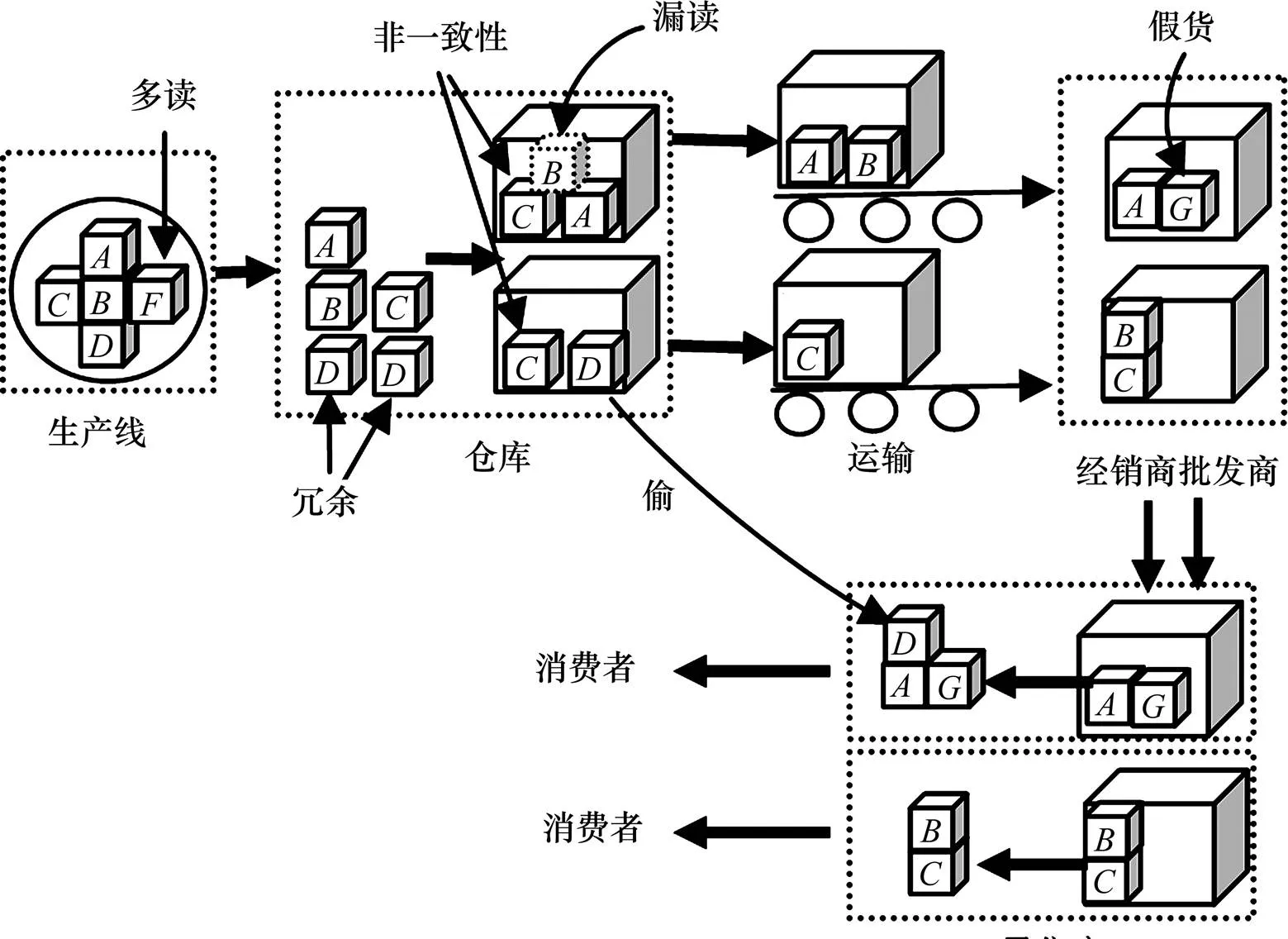
圖1 基于RFID的供應鏈
RFID應用是類似的,具有非確定性、不同位置的時序相關性、相同位置的對象相關性和粗粒度。基于這些特點,本文給出了如下定義。
定義1 RFID閱讀。RFID閱讀是一個具有唯一EPC的RFID對象tagID在timestamp時間點被閱讀器讀取,表示為rd=(tagID, timestamp,readerID)。
定義2 RFID數據流。RFID數據流是多個具有唯一EPC的RFID對象tagID在timestamp時間點被readerID閱讀器讀取,表示為=(rd, rd, …, rd),其中rd=(tagID, timestamp, readerID)。
本文總結了幾類基本實體:具有唯一EPC的RFID對象、閱讀器和位置。這些實體產生的數據分為部署數據、閱讀數據和概略數據。部署數據在RFID應用部署時就被獲取,這些數據相對穩定、確定,如位置和閱讀器數據等;閱讀數據為RFID閱讀器讀取的數據;概略數據為通過處理閱讀數據后生成的面向用戶查詢的數據。
1.2 處理框架
圖2所示為非確定性RFID數據的處理框架。RFID閱讀器從多個數據流讀取EPC數據,根據已存在閱讀數據的非確定性比例來指定一個滑動窗口;然后根據已有的閱讀數據推斷讀取的數據是否存在漏讀數據,存儲RFID對象的EPC、位置和時間戳到RFID數據庫中(其中,非一致性、多讀和冗余數據也需要被存儲到RFID數據庫中),并進一步修改非一致性數據,清洗多讀和冗余數據。
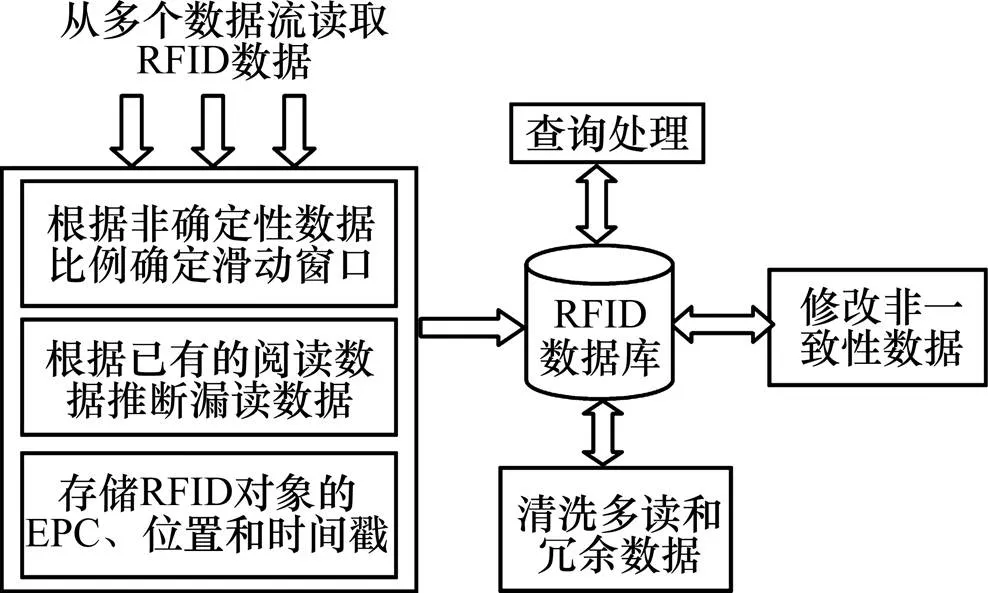
圖2 非確定性RFID數據處理框架
滑動窗口顯著地影響冗余、非一致性、多讀和漏讀數據的比例。若選擇大的窗口,則能獲取RFID對象更多的信息,但容易導致更多的冗余、非一致性和多讀數據產生;若選擇小的窗口,則可以減少冗余、非一致性和多讀數據的產生,但容易產生更多的漏讀數據。SMURF[5]難以有效地確定一個自適應的窗口,本文提出1個滑動窗口策略去調整冗余、非一致性、多讀和漏讀數據的比例。
不同比例下的滑動窗口如圖3所示。當漏讀頻繁發生時(從1到2),Stream A趨向于有1個更大的窗口;而當冗余、非一致性和多讀現象頻繁發生時(從2到3),Stream C趨向于有1個更小的窗口;Stream B是相對適中的,趨向于平衡2類閱讀。根據漏讀比例,小窗口需要適當放大。根據冗余、非一致性和多讀比例,大窗口需要適當減小。采用如下公式調整滑動窗口:
1.3 數據推斷
閱讀數據(,) 一般可生成反映RFID對象狀態的存儲形式(,,in,out),其中[in,out]表示EPC在位置的停留時間。不同非確定性數據處理的推斷規則如下:
定義3 推斷規則(INFERRING RULE)被采用模式(PATTERN)-條件(CONDITION)-操作(ACTION)形式:
其中:為非確定性數據類型;為該類型屬于何種具體情況;為執行的推斷操作。
推斷不同類型的非確定性數據如圖4所示。
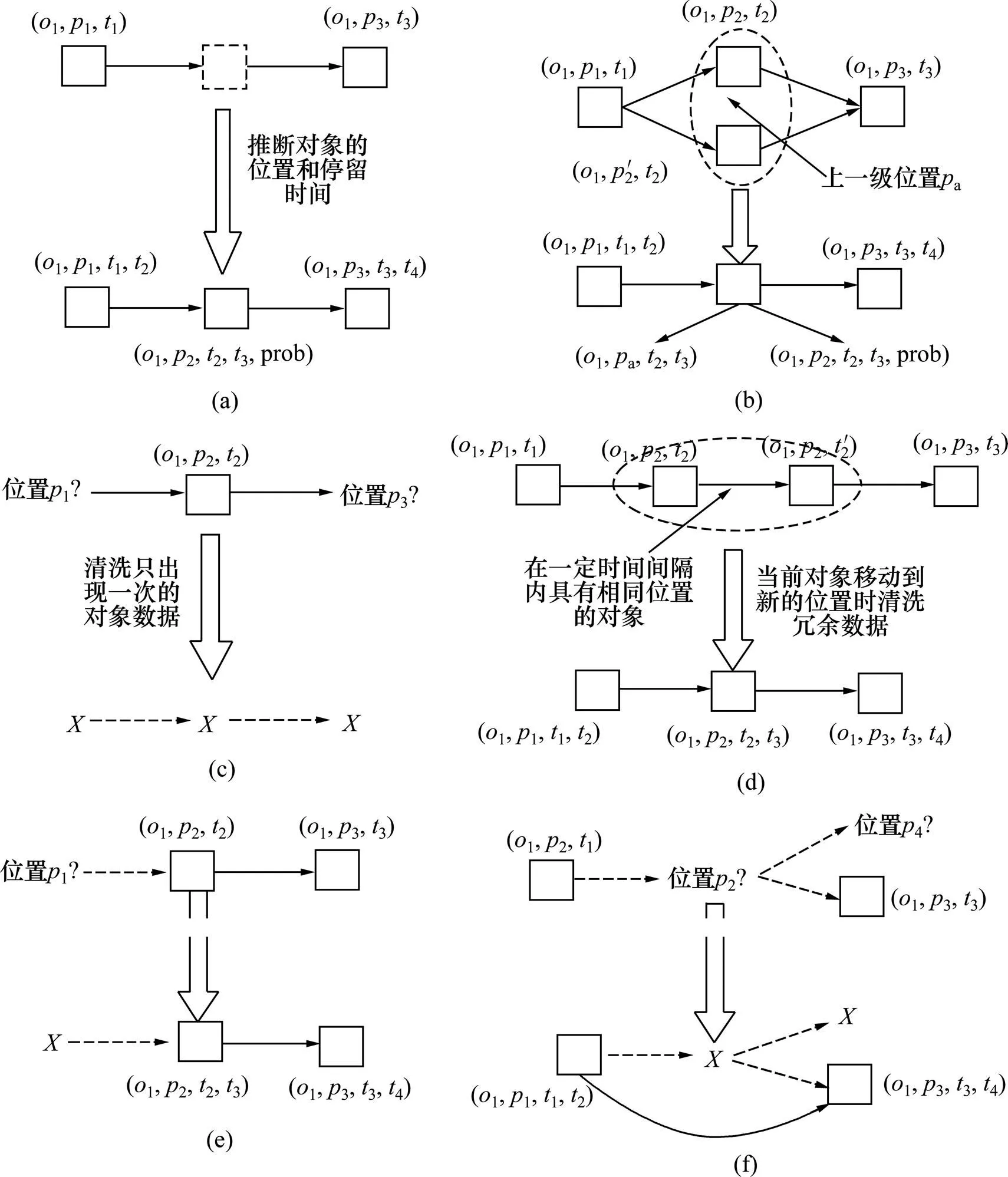
(a) 漏讀數據;(b) 非一致性數據;(c) 多讀數據;(d) 冗余數據;(e) 非完整性數據(假設);(f) 非完整性數據(對象被偷)
1) 漏讀數據。對象1通過位置-1,2和3,但在位置2時未檢測到。可以根據RFID對象的移動歷史和位置關系來推斷,若與對象1一起的其他RFID對象從位置1到3必須通過位置2,則可以推斷對象1也通過了位置2,并獲得在位置2的停留時間及概率,如(1,2,2,3,)。
2) 非一致性數據。對象1從1到3,可能被2個不同的閱讀器讀取,從而形成具有2個不同位置2和′2的非一致性數據。可以采用2種方法推斷:一種是類似于漏讀數據的推斷,根據RFID對象的移動歷史和位置關系來推斷,如(1,p,2,3,);另一種是根據RFID應用的粗粒度特點,把包含2個不同位置2和2的上一級位置a代替當前非一致性位置,如 (1,a,2,3)。
3) 多讀數據。不存在的對象1在位置2被讀取,且1也不會在其他位置出現,可以表示為->->。但如果一個RFID對象在離開生產線后馬上被偷,由于被偷RFID對象也與多讀數據一樣都只出現1次,那么可能被誤認為是多讀數據,因此,需要進一步區分。多讀數據需要被定期清洗。
4) 冗余數據。位置沒有改變的RFID對象在不同的時間間隔內被讀取,如對象1在時間戳2和′2上被讀取2次。由于1可能在下一個位置被漏讀,推斷其漏讀位置需要最近的位置信息,因此,需要保存最近的位置信息,直到對象1到達新的位置為止。
5) 非完整性數據(假貨)。假貨在供應鏈中下游混入正常的產品中,但假貨不會出現在生產線上。如假貨1出現在位置2和3,但1沒有在位置1出現,表示為->2->3。在供應鏈中只出現1次的假貨沒有意義,假貨進入零售商上游就必須被讀取2次,而直接進入零售商則不需要貼EPC。由于假貨實際存在,出現2次以上假貨數據不會被清洗,此外,克隆假貨的EPC可能出現在生產線上,因此,克隆假貨和正品可能同時出現在供應鏈中或者不同時出現,該EPC可能形成2條歷史軌跡,克隆假貨形成的歷史軌跡在位置上往往不連續。
6) 非完整性數據(對象被偷)。圖4(f)顯示RFID對象在某一位置被偷,被偷對象可能重新進入該供應鏈,也可能永遠丟失。如對象1出現在位置1,但對象1在位置2被偷,因此,對象1在位置2沒有被讀取,1的軌跡可以表示為1->->(永遠丟失),或者重新在位置3進入,表示為1->->3。
1.4 多讀、漏讀和非完整性數據的區分
由于多讀、漏讀和非完整性數據都是在供應鏈中某些節點缺乏位置信息,而它們的處理方法不同,因此,需要區分這些數據。這些數據難以在閱讀器讀取時就立即區分。例如,對象1出現在位置1,對象1可能是多讀或者假貨。
圖5所示為多讀、漏讀和非完整性數據在供應鏈中可能出現的位置。漏讀數據可能出現在除生產線的任何位置;假貨只出現了供應鏈的中下游,不可能進入生產線,假貨也不會直接進入零售商,否則假貨無需貼上EPC,可直接銷售給消費者;RFID對象不可能在生產線上被偷,若被偷則一定發生在被貼簽之前,對象被偷可能發生在除生產線上的其他位置,也可能被偷后重新進入供應鏈;多讀數據可能發生在供應鏈的任意位置,在生產線上的非確定性數據只可能存在多讀數據。
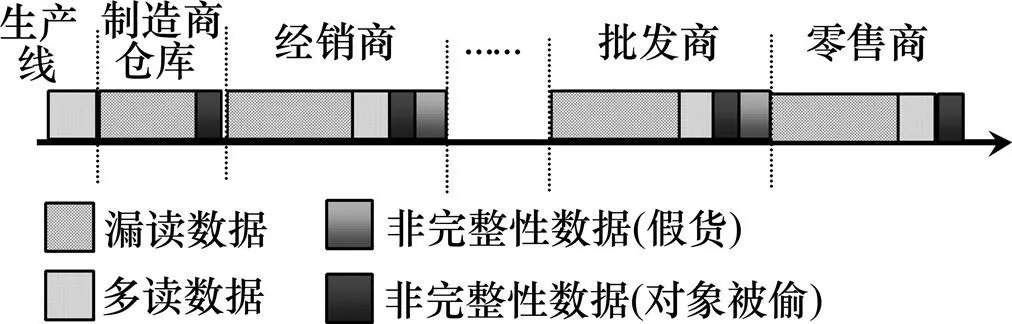
圖5 多讀、漏讀和非完整性數據在供應鏈中出現的位置
圖6所示為多讀、漏讀和非完整性數據的3種情況。
1) 情況A顯示1個閱讀數據只出現生產線上,這可能是多讀或者對象在離開生產線后馬上被偷。由于RFID對象在生產線寫入產品參數,因此,可以推斷多讀數據沒有相關參數,而被偷數據有相關參數。
2) 情況B顯示普通假貨的EPC在生產線上沒有信息,而克隆假貨在生產線上有相關信息,但缺乏連續位置信息。這是因為RFID對象在供應鏈中移動是連續的,具有相鄰的連續位置信息,而克隆假貨是突然出現在供應鏈中,因而缺乏相鄰的連續位置信息。
3) 情況C顯示RFID對象出現超過1次,但沒有出現在某些位置。這可能是因為RFID對象在某些位置被漏讀或者被偷的RFID對象重新進入供應鏈。漏讀的RFID對象一般消失在離散的位置,而被偷的RFID對象一般消失在連續的位置,且被偷的RFID對象將脫離原來的分組。因此,可以通過位置的連續性和分組情況來區分這2類情況。
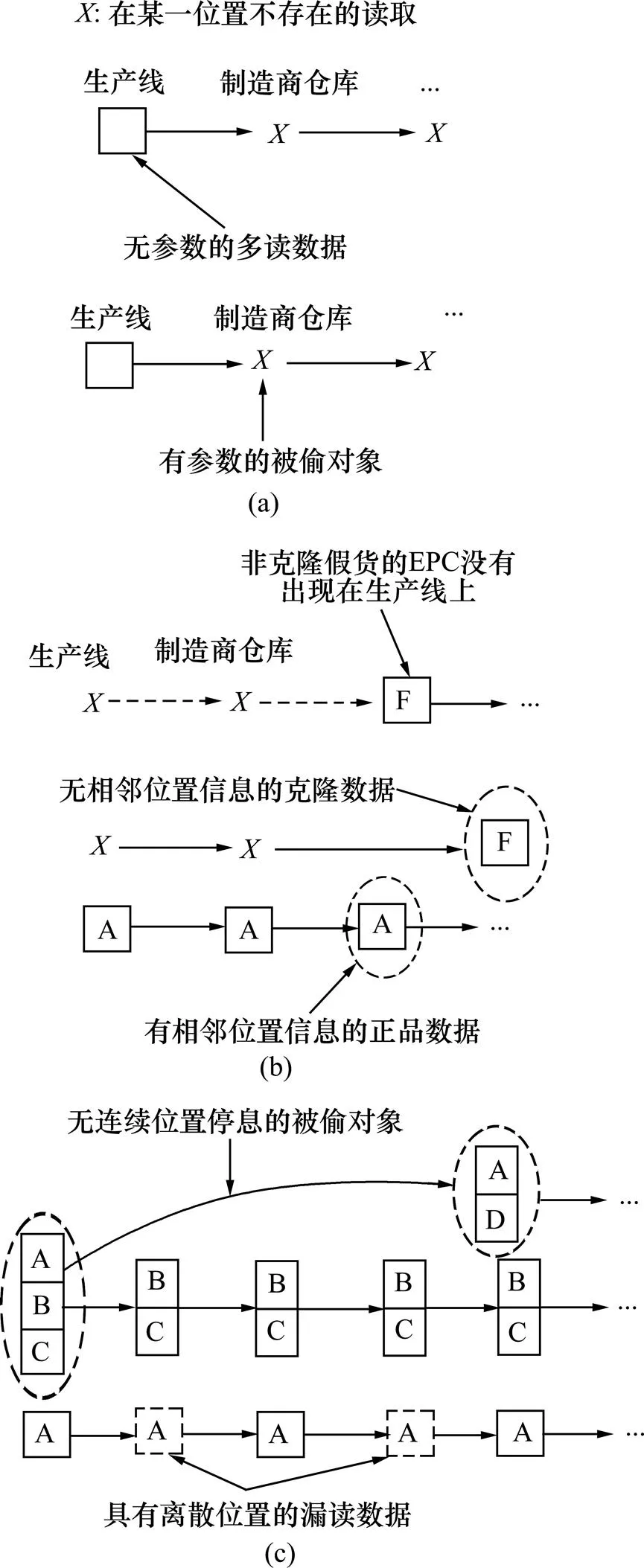
(a) 情況A;(b) 情況B;(c) 情況C
1.5 數據模型
本文采用如下的模型存儲非確定性數據(圖7)。在部署數據中,(,,)存儲閱讀器的EPC、名字和所有者;(,)存儲RFID對象的EPC和類型;(,,)存儲位置ID、名字、上一級位置ID;(,)存儲業務類型。在閱讀數據中,(,)通過和生成,存儲RFID對象的原始數據;為了區分非確定性數據,非克隆假貨、克隆假貨、被偷對象與正常對象的值分別為2, 1, 0和NULL。在概要數據中,(,in,out,,)存儲閱讀器在一定時間間隔內的業務活動;(,)存儲路徑序列;(,in,out)存儲在一定時間間隔內的位置;()存儲對象的路徑序列。
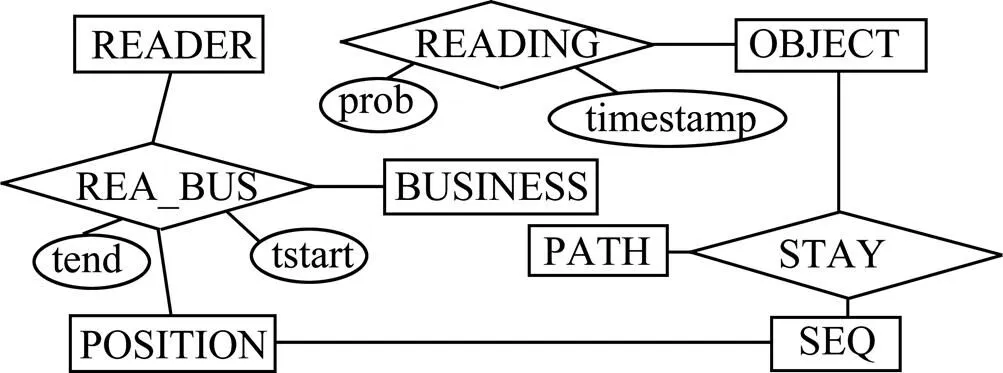
圖7 數據模型
1.6 算法
基于提出的框架和規則,本文提出了基于有向圖(定義1)的非確定性數據處理算法。
定義4 一個從上游到下游的供應鏈可表示為有向圖<,,>,其中表示為的物流節點,表示為一對物流節點<,>之間的對象移動,表示為對象移動的權重。根節點為對象的制造商,每個節點是其前驅節點的子節點,也是其后續節點的父節點。
圖8中的有向圖顯示邊<12>和<13>的權重分別為1和2,表示從1到2和從1到3的概率(即出現漏讀和非一致性數據的可能性),概率為前驅節點出發經過該有向邊的歷史移動對象與該前驅節點出發的總歷史移動對象的比例。
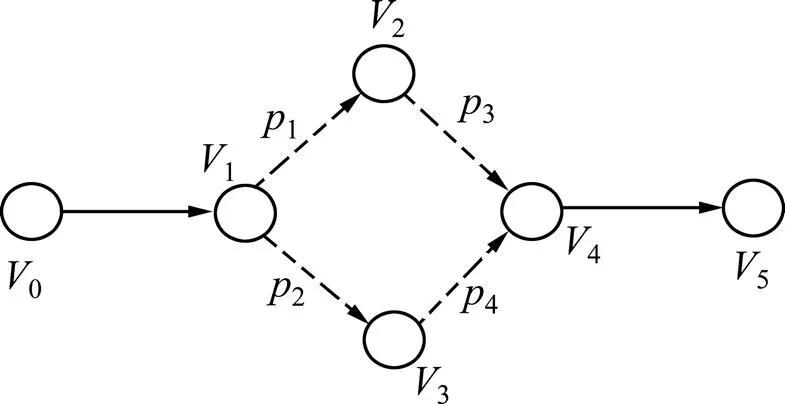
圖8 表示對象移動的有向圖
根據圖4(a)和4(f),算法1處理多讀、冗余、非完整性、漏讀和非一致性數據,調用算法2,建立有向圖和路徑序列。算法1再根據閱讀器出現的位置,對清洗多讀和冗余數據,并標記假貨和被偷對象的數據;根據有向圖中從父節點到子節點的路徑權重,在給定閾值條件下標記和處理漏讀和非一致性數據,插入漏讀數據到或者通過聚集更高層次的時間間隔和位置修改非一致性數據;最后,計算滑動窗口尺寸。
算法1首先調用算法2,由于中的元組數等于中的元組數,算法2在第1步開始的循環次數為,因此,算法2的時間復雜度為()。在第3步開始的外循環次數為,在第17和24步開始的內循環次數均為路徑長度(3~22)。由于內循環EPC不可能同時滿足第17和24步開始的2個條件,因此,第3步開始的循環的時間復雜度為(),最后得到算法的時間復雜度為((+1))。
算法1 main
Input:;閾值;用戶可接受的非確定性數據的比例;可調整的時間間隔;非確定性數據比例的調整參數和
Output: 清洗多讀和冗余數據;標記非完整性數據;修改漏讀和非一致性數據;滑動窗口尺寸w
Begin
1. Builddirectedgraph (EPC);
2. ra ← 0;t ← READING元組數;
3. For RADING中EPC do
4. If EPC 在節點上只出現一次
5. 刪除多讀數據;
6. Else if EPC在同一節點出現2次以上
7. 刪除所有時間戳較晚的冗余數據;
8. Else if EPC沒有出現在根節點
9. 區分EPC為非克隆假貨;
10. Else if EPC出現在根節點且有完整路徑,但路徑的相鄰節點不連續
11. 區分EPC為非克隆假貨;
12. Else if EPC出現在根節點但沒有出現在后續節點
13. 區分EPC為被偷對象;
14. Else if EPC 沒有出現在某一節點
15. ra ++;
16. 區分EPC為漏讀數據;
17. For i =1 to 路徑長度l do
18. {W ← 第i個漏讀節點路徑的權重;
19. If W ≥ TV
20. STAY ← EPC的漏讀節點;
21. Else 通過聚集上級AT和AP修改EPC在STAY的模糊路徑節點位;}
22. Else if EPC在同一時間出現在2個位置
23. 區分EPC為非一致性數據;
24. For i ← 1 to 路徑長度l do
25. {W ← 第i個非一致性節點路徑的權重;
26. If W ≥ TV
27. 修改EPC的非一致性節點到STAY;
28. Else通過聚集上級AT和AP修改EPC在STAY的非一致性路徑節點位;}
29. }
30. ra2 ← ra/t;
31. ra1 ← 1 – 已清洗的READING元組數/t - ra2 ;
32. sw ← adj*(m*(acra–ra1)–n*(acra–ra2)) ;
End
算法2 Builddirectedgraph
Input: EPC
Output: 有向圖;SEQ
Begin
For i ← 1 to STAY中的元組數do
{parent ← EPC的根節點;
node = EPC在parent的子節點;
If node is NULL then
{node ← new node;
node.loc ← EPC.loc;
node.tin ← EPC.tin;
node.tout ← EPC.tout;
parent的子節點 ← node;
}
加入node.path到PATH;
W ← parent到node邊的權重;
W ← PATH;
}
End
2 實驗評價
2.1 實驗環境
本文考慮了所有類型的非確定性數據,與以往工作的實驗數據不可能一致,因此,無法將本文方法與以往方法進行比較。
實驗評價環境中采用CPU為Core i2 2.00 GHz,內存為2 Gb RAM的機器,操作系統為Windows 7,數據庫為MYSQL5.6。由于缺乏通用的RFID測試數據,本文根據1個食品物流模型[17]生成數據,并建立相應的查詢進行測試。
對象被生成在進口市場和農產品供應商等根節點,再通過分組或個別運輸形式移動到下一個位置。采用有向圖并考慮分組因素去生成對象數據,分析分組因素對查詢性能的影響。有向圖的每個節點表示某一位置的一組對象,邊表示對象在位置之間的移動。一般地,靠近根節點的對象移動往往是更大的組,靠近葉子的對象移動往往是更小的組。分組的尺寸表示為,表示為一起移動的對象數量。本文根據有向圖中給定的隨機地生成數據,對應有向圖中的邊,表示對象移動。
由于非確定性數據大部分是漏讀數據,考慮如下影響因素:漏讀、冗余和多讀數據比例,用戶指定的位置和時間間隔層次(基于這2個層次的路徑序列將自動聚集),不同數據規模,實驗參數見表1。
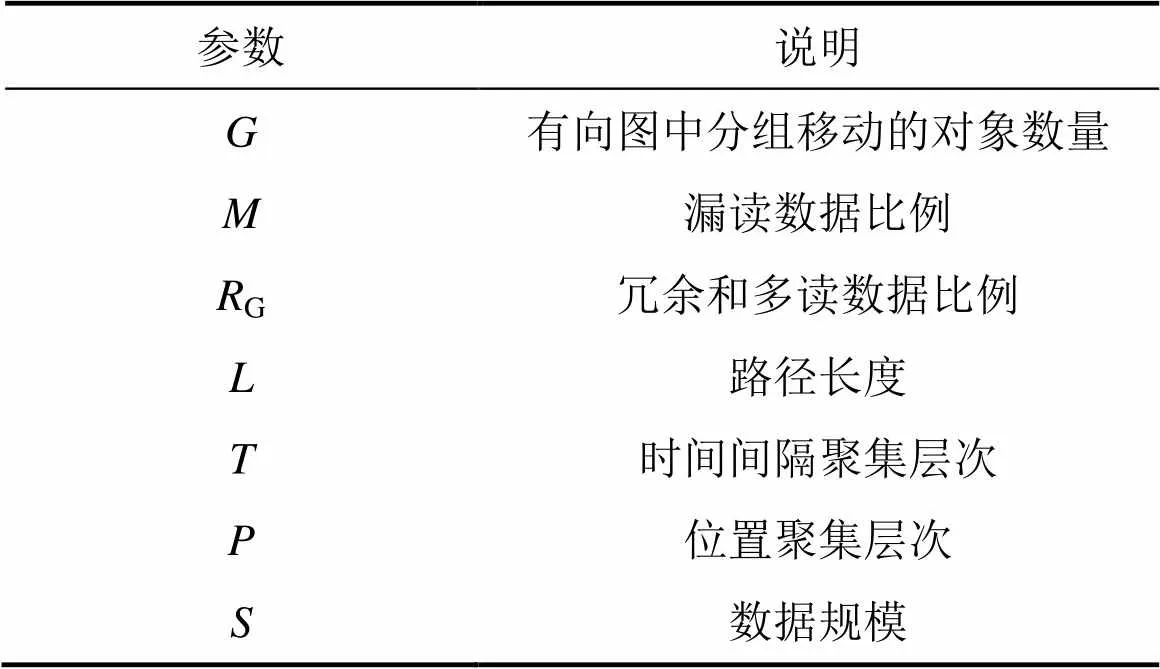
表1 實驗參數
2.2 數據處理
根據不同參數比較清洗后的存儲規模。設置漏讀數據比例=(0.500, 0.250, 0.100, 0.500, 0.025),冗余和多讀數據比例分別為G=(0, 0.333, 0.500, 0.666, 0.750),對象數量分別為1 000,2 500,5 000,7 500,10 000的數據規模為=(3 800, 31 700, 135 000, 427 500, 975 000)。本文在表中清洗冗余和多讀數據,計算漏讀數據且存入該表,也標注假貨和被偷對象等非完整性數據,并修改非一致性數據。
由于漏讀數據比例與冗余和多讀數據比例是對立的,因此,采用5組數據比例來表示,組1為(=0.5,G=0),組2為(=0.25,G=0.333),組3為(=0.1,G=0.5),組4為(=0.05,G=0.666),組5為(=0.025,G=0.75)。漏讀數據比例從0.500 下降為0.025,冗余和多讀數據比例從0 提高為0.75。由圖9可知:沒有清洗過的數據在不同和G下呈線性增長。由于漏讀數據被推斷計算后插入,而冗余和多讀數據在被清洗,被清洗的數據規模在不同和G下是相同的。更高的G可能顯著地增加尺寸。但更小的G可能導致更多的漏讀,而影響漏讀推斷準確率。因此,根據滑動窗口調整G為更小值,且調整為合適的值。
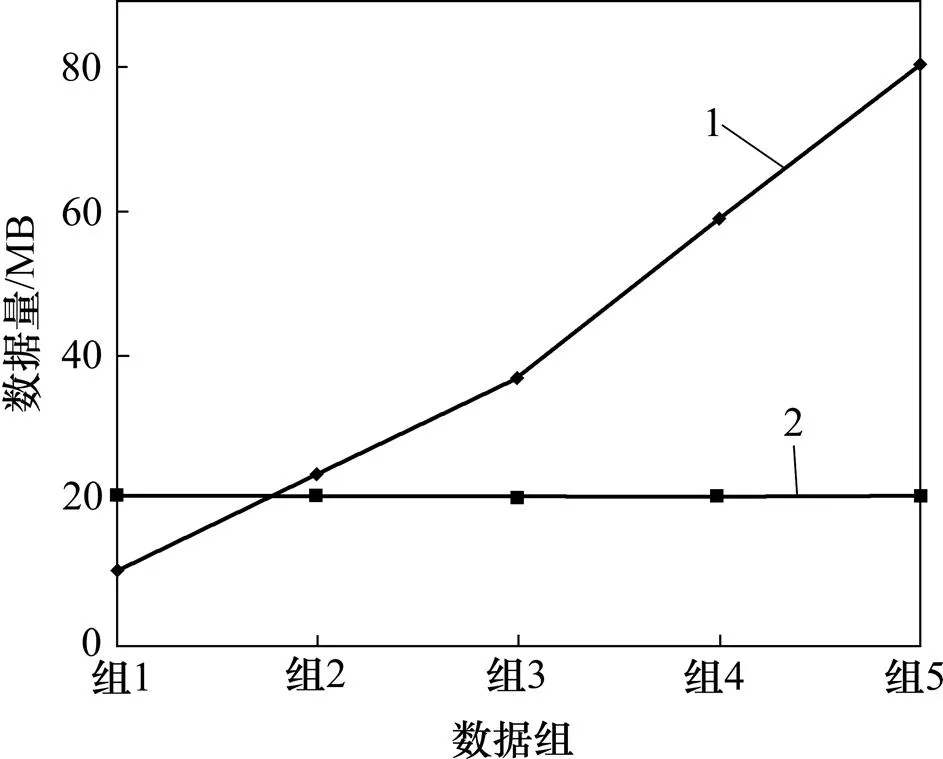
1—未清洗數據;2—清洗數據
圖10所示為不同的數據規模,參數為=0.1,G=0.5。根據對象數量(1 000,2 500,5 000,7 500,10 000)分別生成數據進入表,對應的路徑長度分別為(3?4),(3?7),(3?9),(3?17),(3?22) (每500個對象有相同的路徑長度)。由于G=0.5和長路徑可能導致更多的冗余數據,沒有清洗過的數據規模明顯地大于被清洗過的數據規模。生成的數據將進入表,和。由于表只存儲單一對象對應元組的一系列完整路徑序列(一一對應中的對象),表只存儲在2個可調整的時間間隔的位置,表只存儲基于有向圖的有限路徑,因此,用戶可以通過查詢更小尺寸的表,有效地獲取對象的完整路徑。
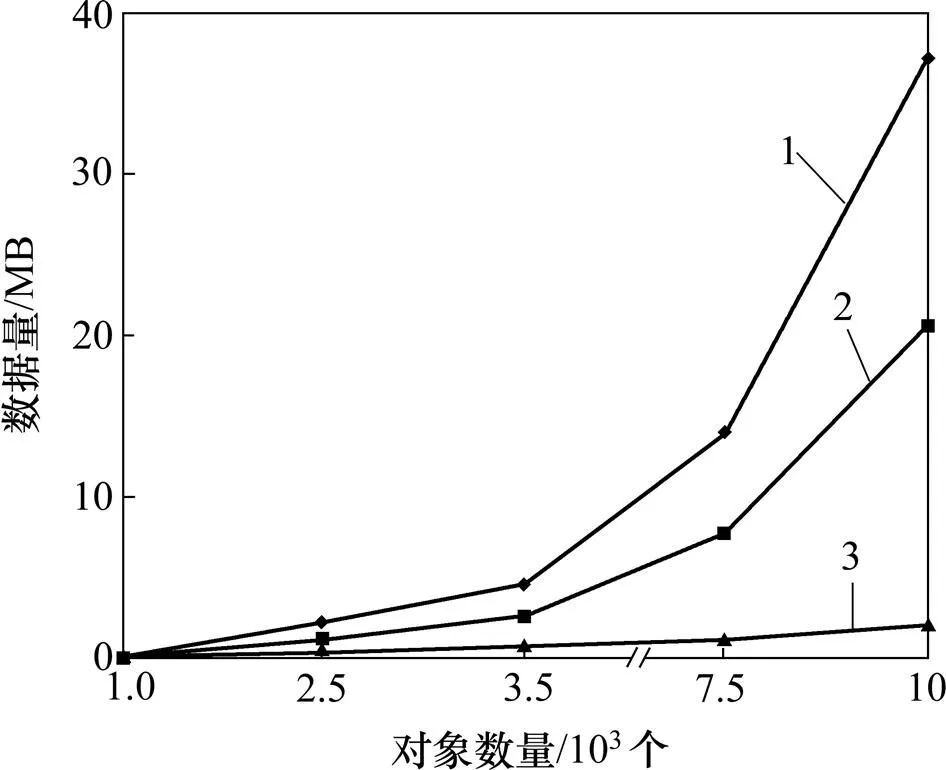
1—未清洗數據;2—清洗數據;3—路徑數據
文獻[17]給出的最小路徑為3,最大路徑為9。考慮循環和長路徑問題,延長了最大路徑長度到17或22。一般地,大多數路徑長度為3~9,特別是3~6。本文設置5個系列的路徑長度:3~4(每5 000個對象有相同路徑長度);3~7(每2 000個對象有相同路徑長度);3~9(每1 500個對象有相同路徑長度,第9層為1 000個對象有相同路徑長度);3~17(從第3層到第9層每1 300個對象有相同路徑長度,從第10層到第17層每90個對象有相同路徑長度);3~22(從第3層到第9層每1 300個對象有相同路徑長度,從第10層到第22層每90個對象有相同路徑長度)。不同的數據規模(=10 000,=3 600,A=3,=0.1,G=0.5)如圖11所示。由圖11可知:沒有清洗的和清洗過的數據規模在路徑長度增加時顯著增加,而路徑數據規模隨路徑長度增加稍微增長。表明更長的路徑會顯著地影響數據規模,但對路徑數據規模影響不大。
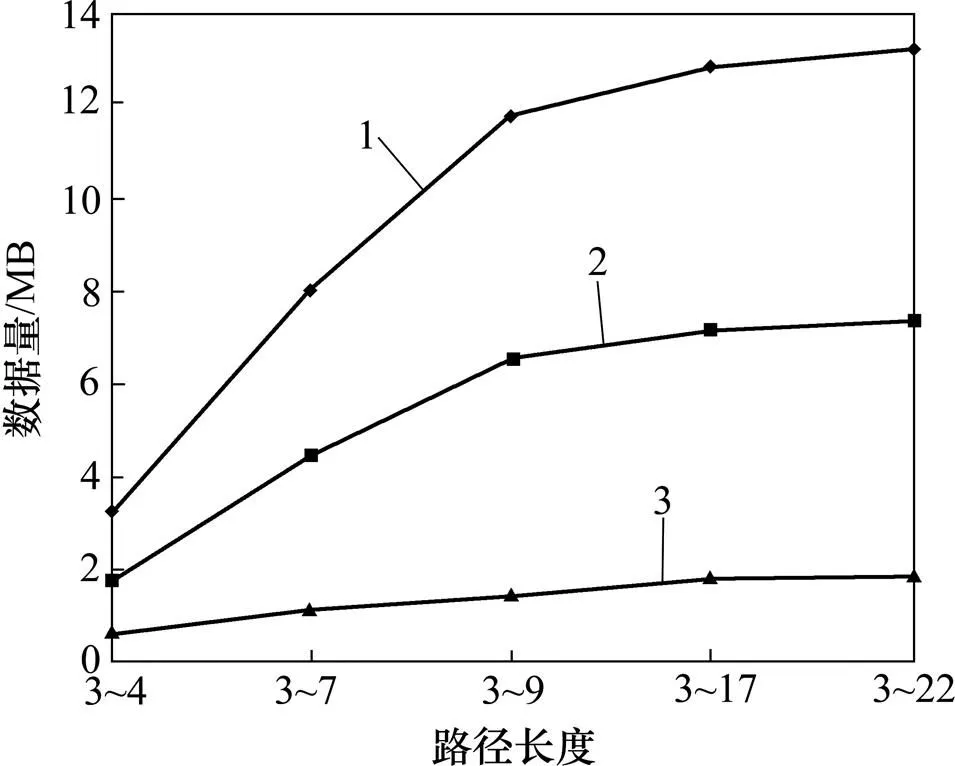
1—未清洗數據;2—清洗數據;3—路徑數據
考慮到對象在很短的時間內不可能從一個位置移動到另一個較遠的位置,因此,每一個位置將對應一個合適的時間間隔,如時間間隔=60對應于位置間隔A=2。不同的和的數據規模(=10 000,=3?22,=0.1,G=0.5)如圖12所示。由圖12可知:路徑數據規模隨和A的增加而減少(被清洗數據的規模不隨和A的改變而改變)。路徑數據規模的減少對降低路徑查詢的負載是非常有效的。

1—未清洗數據;2—清洗數據
2.3 查詢
由于沒有清洗過的數據不適合于進行查詢評價,本文采用算法清洗數據和聚集,并給定查詢進行比較。Q1為跟蹤查詢,Q2,Q3,Q6和Q7為追蹤查詢。其中Q4和Q5為聚集查詢,Q6為非完整性數據查詢,Q7為循環和長路徑查詢。
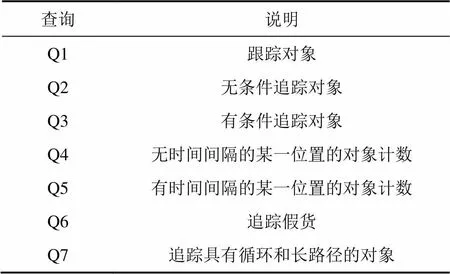
表2 測試查詢
在表中存儲對象EPC及其路徑序列,Q1和Q2不需要連接多個表去獲取路徑信息。盡管Q3需要連接2個表去獲取路徑信息,但存儲時間間隔和位置信息的表已經被顯著地壓縮。聚集查詢Q4和Q5需要連接2個表,但相當多的類似數據也通過聚集壓縮,也能顯著地改善查詢性能。由于查詢假貨涉及到表,和,Q6連接這3個表區分非克隆假貨和克隆假貨。循環和長路徑查詢也涉及表,和,Q7需要連接這3個表獲取細節的路徑信息。
不同分組的執行情況如圖13所示,參數為= 10 000,=3?22,=3 600,A=3。由圖13可知:方法在Q3~Q7的執行時間隨著分組的增加而減少。這是因為Q1和Q2只需要查詢表獲取路徑信息,因而Q1和Q2的執行時間沒有改變。Q3的執行時間隨的增加而減少,這是因為更大的分組可以顯著地壓縮以獲取路徑信息。盡管Q4和Q5需要連接2個表進行聚集,隨著的增加,在參數=3 600和A=3條件下的壓縮比也顯著地增加。類似地,Q6和Q7需要連接3個表(,和)去追蹤假貨和具有循環和長路徑的對象,壓縮比隨著的增加而增加。
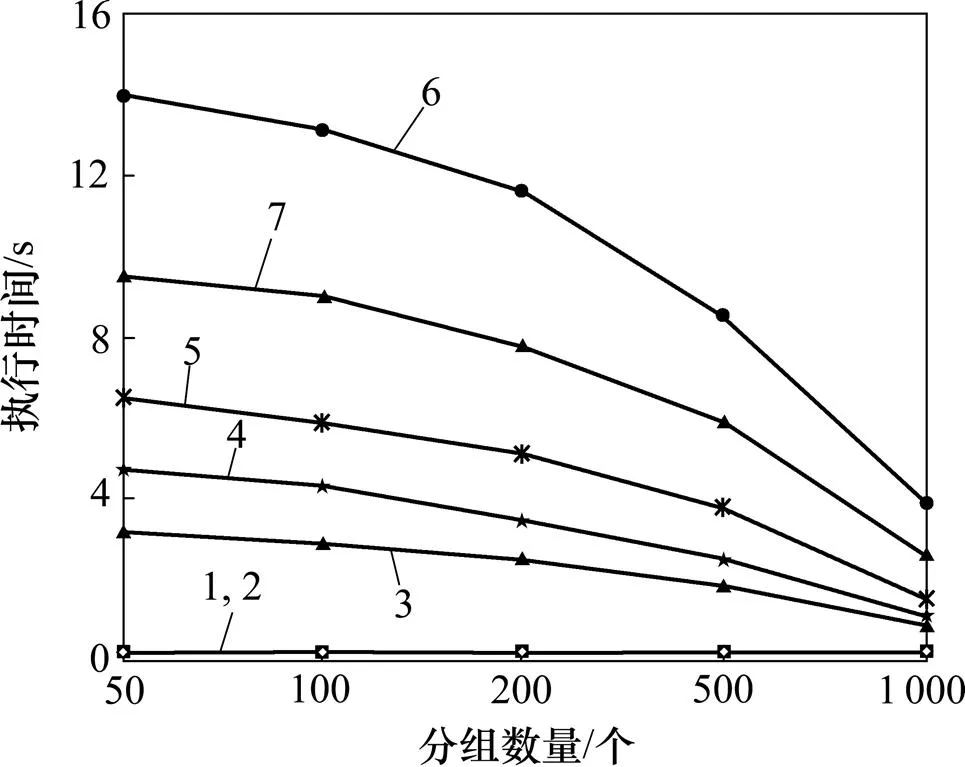
1—Q1;2—Q2;3—Q3;4—Q4;5—Q5;6—Q6;7—Q7
Q1~Q7在不同數據規模時的評價如圖14所示,測試參數=200,=3~22,=3 600,A=3。數據規模顯著地影響Q3~Q7的執行時間。由于Q3~Q7需要連接多個表,其執行時間隨的增加而顯著增加。而Q1和Q2只查詢表,數據規模的變化對其執行時間影響很小。
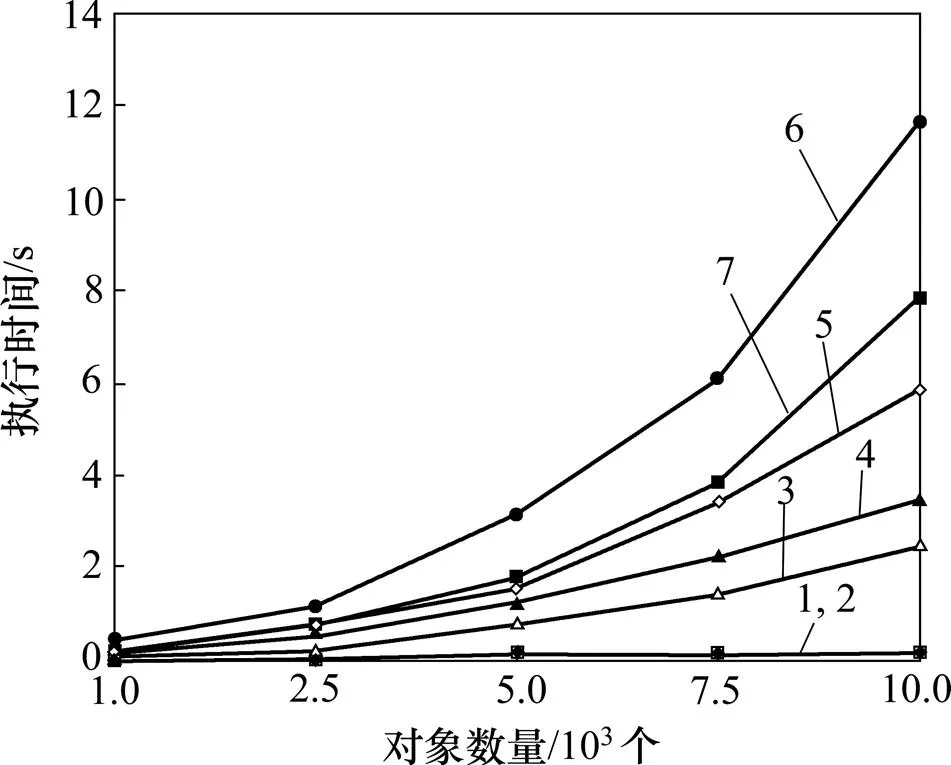
1—Q1;2—Q2;3—Q3;4—Q4;5—Q5;6—Q6;7—Q7
由于RFID閱讀器是在連續的時間段內而不是相同的時間戳讀取對象標簽,聚集時間間隔和位置,忽略了具體的時間戳和位置,可以顯著地改善存儲和查詢的有效性。圖15所示為在不同聚集層次下的查詢執行時間。本文設置4組不同的聚集層次:Ⅰ組(=0,A=1),Ⅱ組(=60,A=2),Ⅲ組(=3 600,A=3),Ⅳ組(=21 600,A=4),由這4組聚集層次評價查詢Q1~Q7。其中,Ⅰ組(=0,A=1)是沒有聚集的,因而對Q3~Q7是無效的。隨著聚集時間間隔和位置間隔的延長,Q3~Q7的執行時間顯著減少。
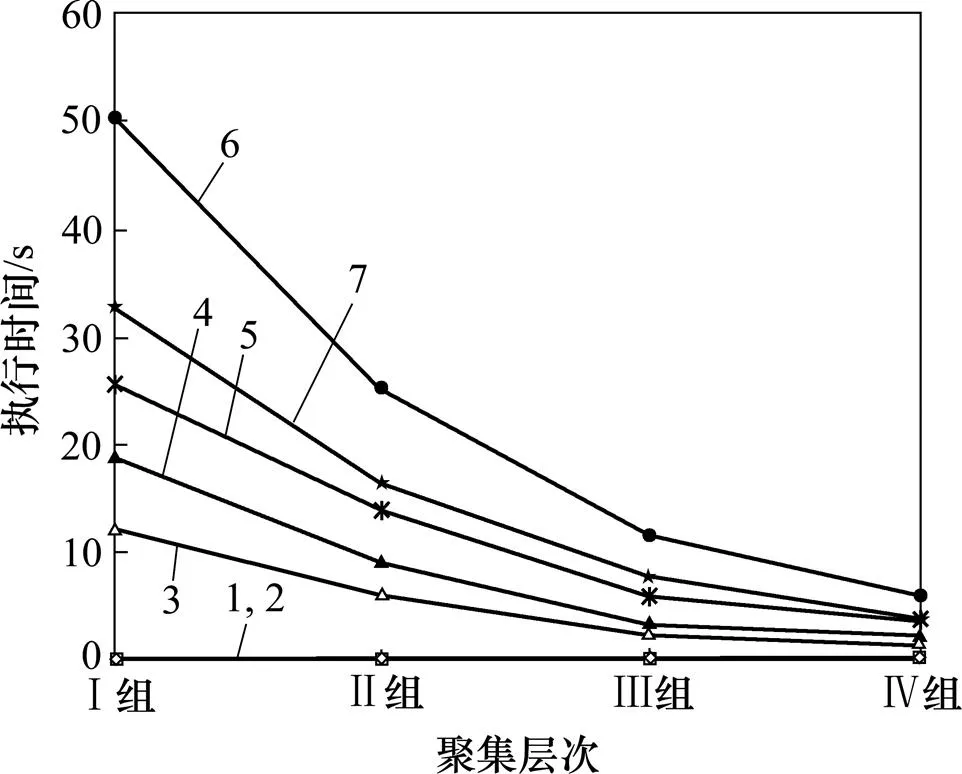
1—Q1;2—Q2;3—Q3;4—Q4;5—Q5;6—Q6;7—Q7
一般的路徑長度為3?9[17],因此,考慮大部分對象的路徑長度為3?9,設置了4組不同的路徑長度1=3~5,2=3~9,3=3~17,4=3~22來評價Q1~Q7。若路徑長度超過9,則實驗設置10%的對象的路徑長度為10~22 (每個長度的對象數量相對平均),設置90%的對象的路徑長度為3~9(每個長度的對象數量相對平均)。圖16所示為Q3~Q7在不同路徑長度的執行時間。由圖16可見:Q3~Q7的執行時間隨著路徑長度的增加而顯著增加。這是因為短路徑包含大量可以被壓縮的相同路徑信息,而長路徑包含大量難以壓縮的不同路徑信息。由于具有路徑長度10~22的對象較少,執行時間的增幅趨緩。
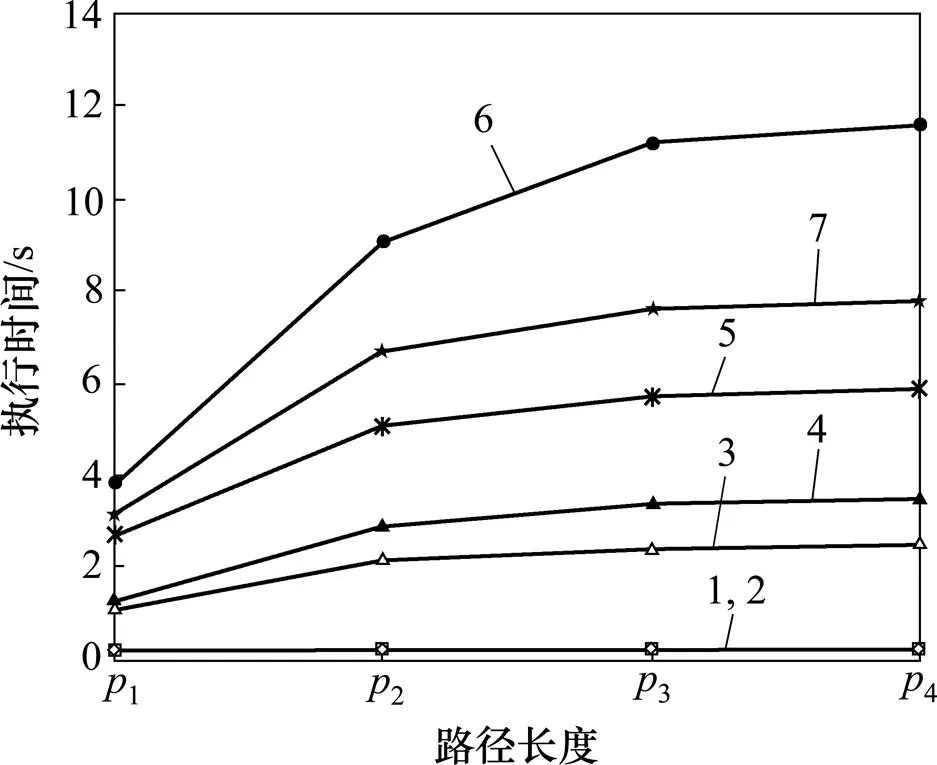
1—Q1;2—Q2;3—Q3;4—Q4;5—Q5;6—Q6;7—Q7
在以上實驗中,Q6和Q7的執行時間較長,但由于這2類查詢相對較少,因此,查詢性能也是可以接受的。
3 結論
1) 考慮了所有類型的非確定性數據,通過分析RFID對象的關鍵特征,根據漏讀與多讀、冗余和非一致性數據的比例來調整滑動窗口;提出了一種非確定性數據處理方法,采用不同策略處理漏讀、多讀、冗余、非一致性和非完整性(假貨與對象被偷)數據,并根據對象在供應鏈中出現位置及其連續性來識別多讀、漏讀和非完整數據。
2) 處理后的數據在不同參數條件下具有良好的清洗效果、存儲效率以及查詢性能,能有效地支持對象路徑查詢。
3) 下一步的工作將建立對象移動的主路徑和子路徑,進一步壓縮數據來提高存儲和查詢性能。
[1] Ilic A, Andersen T, Michahelles F. Increasing supply-chain visibility with rule-based RFID data analysis[J]. IEEE Internet Computing, 2009, 13(1): 31?38.
[2] WANG Fusheng, LIU Shaorong. Temporal management of RFID data[C]// Proceedings of the International Conference on Very Large Data Bases. New York: Association for Computing Machinery, 2005: 1128?1139.
[3] WANG Fusheng, LIU Shaorong, LIU Peiya. A temporal RFID data model for querying physical objects[J]. Pervasive and Mobile Computing, 2010, 6(3): 382?397.
[4] Rizvi S, Jeffery S R, Krishnamurthy S, et al. Events on the edge[C]// Proceedings of the International Conference on Management of Data. New York: Association for Computing Machinery, 2005: 885?887.
[5] Jeffery S R, Garofalakis M, Franklin M J. Adaptive cleaning for RFID data streams[C]// Proceedings of the International Conference on Very Large Databases. New York: Association for Computing Machinery, 2006: 163?174.
[6] 谷峪, 于戈, 胡小龍, 等. 基于監控對象動態聚簇的高效RFID數據清洗模型[J]. 軟件學報, 2010, 21(4): 632?643. GU Yu, YU Ge, HU Xiaolong, et al. Efficient RFID data cleaning model based on dynamic clusters of monitored objects[J]. Journal of Software, 2010, 21(4): 632?643.
[7] 王永利, 錢江波, 孫淑榮, 等. AMUR: 一種RFID數據不確定性的自適應度量算法[J]. 電子學報, 2011, 39(3): 579?584. WANG Yongli, QIAN Jiangbo, SUN Shurong, et al. AMUR: An adaptive measuring algorithm of underlying uncertainty for RFID data [J]. Acta Electronica Sinica, 2011, 39(3): 579?584.
[8] Tran T T L, Peng L P, DIAO Yalei, et al. CLARO: Modeling and processing uncertain data streams[J]. The VLDB Journal, 2012, 21 (5):651-676.
[9] NIE Yanming, Cocci R, ZHAO Cao, et al. SPIRE: Efficient data inference and compression over RFID streams[J]. IEEE Transactions on Knowledge and Data Engineering, 2012, 24(1): 141?155.
[10] ZHOU Aoying, JIN Cheqing, WANG Guoren, et al. A survey on the management of uncertain data[J]. Chinese Journal of Computers, 2009, 32(1): 1?16.
[11] LIAN Xiang, CHEN Lei, SONG Shaoxu. Consistent query answers in inconsistent probabilistic databases[C]// Proceedings of the International Conference on Management of Data. New York: Association for Computing Machinery, 2010: 303?314.
[12] Arenas M, Bertossi L, Chomicki J. Consistent query answers in inconsistent databases[C]// Proceedings of the Symposium on Principles of Database Systems, 1999: 68?79.
[13] Chen L, Tseng M, Lian X. Development of foundation models for internet of things[J]. Frontiers of Computer Science in China, 2010, 4(3): 376?385.
[14] 謝東. 非確定性關系數據處理研究[R]. 長沙: 中南大學信息科學與工程學院, 2010: 30?55. XIE Dong. Research on uncertain relational data processing[R]. Changsha: Central South University. School of Information Science and Engineering, 2010: 30?55.
[15] XIE Dong, CHEN Xinbo, ZHU Yan. Tackling polytype queries in inconsistent databases: theory and algorithm[J]. Journal of Software, 2012, 7(8): 1861?1866.
[16] XIE Dong, Sheng Q Z, MA Jian-gang. A temporal-based model of uncertain RFID data[C]// Proceedings of the International Conference on Computer Science & Education. New York: Association for Computing Machinery, 2012: 847?850.
[17] Bowersox D J, Closs D J. Logistical management[M]. New York: McGraw-Hill, 1996: 55?80.
Methods for processing uncertain RFID data in traceability supply chains
XIE Dong1, 2, XIAO Jie3, GUO Guangjun4, JIANG Tong1
(1. Department of Computer Science and Technology, Hunan University of Humanities, Science and Technology, Loudi 417000, China; 2. School of Information Science and Engineering, Central South University, Changsha 410083, China; 3. Information Technology Department, Hunan First Normal College, Changsha 410205, China;4. Department of Electronics and Information Engineering, Loudi Vocational and Technical College, Loudi 417000, China)
Considering that massive uncertain radio frequency identification (RFID) data cannot be efficiently processed in application systems of traceability supply chains, key features of RFID applications were analyzed, and different smoothing windows were adjusted according to different rates of uncertain data. Different types of uncertain readings were obtained by employing different strategies, and the methods for efficiently and effectively processing various types of uncertain data were put forward. The methods distinguish between ghost, missing and incomplete data according to their appearing positions and their continuities in supply chains. The processing algorithms that are suitable to group and independent moving of objects were proposed based on the directed graph, which corresponds to moving paths of
objects in logistics nodes. The results show that the proposed methods provide good cleaning effects, storage efficiencies, and query performances, and also efficiently support path-oriented queries of objects under different parameters.
supply chain management; radio frequency identification (RFID); uncertain data
10.11817/j.issn.1672-7207.2015.05.017
TP311
A
1672?7207(2015)05?1688?11
2014?05?14;
2014?07?20
湖南省自然科學基金資助項目(12JJ3057);湖南省重點建設學科(計算機應用技術)資助項目(2011?2015);湖南省科技計劃項目(2013NK3090);湖南省教育廳科研基金資助項目(13A046) (Project(12JJ3057) supported by the Hunan Provincial Natural Science Foundation; Project(2011?2015) supported by the Construct Program of the Key Discipline “Computer Application Technology” in Hunan Province; Project(2013NK3090) supported by the Hunan Provincial Science and Technology Plan; Project(13A046) supported by the Research Foundation of Education Committee of Hunan Province)
謝東,博士,副教授,從事物聯網與數據管理研究;E-mail: dong.xie@hotmail.com
(編輯 趙俊)
猜你喜歡
遼寧教育(2022年19期)2022-11-18 07:20:42
公民與法治(2022年5期)2022-07-29 00:47:28
汽車實用技術(2022年9期)2022-05-20 05:51:26
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
裝備制造技術(2020年11期)2021-01-26 00:39:12
中國公共安全(2017年11期)2017-02-06 05:28:08
電測與儀表(2016年7期)2016-04-12 00:22:18
燕山大學學報(2015年4期)2015-12-25 02:19:49
