基于逆概念頻率的詞語相似度計算
2015-10-13 01:24:10張東站
廈門大學學報(自然科學版) 2015年2期
孫 晶,張東站
(廈門大學信息科學與技術學院,福建廈門361005)
基于逆概念頻率的詞語相似度計算
孫 晶,張東站*
(廈門大學信息科學與技術學院,福建廈門361005)
詞語相似性度量在服務選擇、自然語言處理、文獻檢索等領域具有重要的作用,目前通用的詞語相似度計算方法是利用《知網》對詞的概念解釋得出詞語之間相似度.對《知網》結構進行分析,認為利用《知網》計算詞的相似度的方法中概念的4項基本結構的權重應該動態(tài)產生,并提出區(qū)分度作為衡量4項基本結構的動態(tài)權重.在分析現有研究基礎上,借鑒逆文檔頻率(IDF)權重計算思想,認為義原的區(qū)分度與義原在所有概念的相應位置中出現次數成反比,提出了一種基于義原出現頻次的義原權重計算方法:逆概念頻率(inverse concept frequency,ICF).通過分析概念的組織結構,計算第一基本義原結構、其他基本義原結構、關系義原結構、關系符號結構中各義原的ICF權重,將4個基本結構中的最大義原ICF權重作為基本結構的ICF權重.利用動態(tài)ICF值逼近基本結構的區(qū)分度,進而計算詞語相似度.通過對真實數據的實驗對比可以看出ICF算法能有效提高計算詞語相似度的準確率.相比較傳統(tǒng)算法平均前160個詞準確率從30.74%提高到72.28%,平均召回率從15.87%提高到49.64%.
知網;詞語相似度;逆概念頻率;義原權重
現階段以互聯網帶動的信息技術的不斷發(fā)展和普及,如何從海量的信息資源中挖掘出有價值的信息成為信息用戶的關注點.信息資源形態(tài)迥異,使得采用傳統(tǒng)的以字符串匹配為基礎的信息檢索系統(tǒng)逐漸被淘汰,取而代之的是以計算詞語之間的語義相似度為核心的概念模型匹配的信息檢索,因此提高詞語相似度的計算精度顯得尤為重要.
詞語是文章最基本的組成單位,詞語之間的關系也因為人們的思考邏輯而變得復雜.詞語相似度計算研究的是計算兩個詞語相似度的方法,是研究句子相似度的基礎.詞語相似性度量在服務選擇、自然語言理解、文獻檢索等領域具有重要的作用.可見詞語相似度研究有廣闊的應用前景和重大研究價值.
現今對詞語相似度計算主要分為兩類,一種是基于本體的計算方法,根據概念層次結構組織形式及概念之間的上下位與同位關系來計算詞語的相似度.另外一種是基于統(tǒng)計的方法,利用大規(guī)模語料庫,研究上下文環(huán)境中各個詞語之間出現的某種規(guī)律,總結出計算詞語相似度的方法.
基于統(tǒng)計的計算方法:基于這樣一個假設,語義相近的詞,其上下文也應該相似.從大規(guī)模語料庫中統(tǒng)計出被比較詞匯的相關上下文詞匯,組成集合、向量化并計算向量夾角余弦值,同時使用詞的上下文信息的概率分布作為參考值,進而計算詞語的語義相似度.
在中文方面,文獻[1]利用詞相關性知識計算詞語相似度.

基于本體的計算方法:基于這樣一個假設,兩個詞語具有一定的語義相似性,當且僅當其在概念結構層次網絡圖中存在一條通路.本體能夠準確描述概念含義和概念之間的內在關聯[2],并根據語義距離來計算詞語相似度,已經成為詞語相似度研究的基礎,當前基于本體的語義相似度計算方法已經取得了豐碩的成果,本文研究的也是基于本體的計算方法.在英文研究中文獻[3-4]對基于本體的多種計算方法進行了比較.目前中文詞語相似度計算都較多地采用了《知網》,《知網》采用的是一種多維的知識表示形式,內容與結構較同義詞詞林更加豐富,文獻[5]研究了利用義原特征結構的分類,計算不同義原的相似度來綜合求解詞的相似度.而文獻[6]改進了義原的計算方式,文獻[7]提出基于信息論的計算方法,文獻[8]提出知識庫描述語言對概念的描述具有線性關系,文獻[9]提出位置相關的權重分配策略等.在這些研究中,都未考慮到同類義原中不同義原含有的區(qū)分度不同,不同義原的計算時應動態(tài)分配權重.本文利用逆概念頻率動態(tài)地為不同義原定義權重,并根據動態(tài)的權重計算詞的相似度.實驗結果表明,該算法比固定義原權重的方法表現要優(yōu)異.
1 詞語相似度計算方法
1.1 相關理論
《知網》[10](英文名稱How Net)是著名機器翻譯專家董振東先生創(chuàng)建的一個網狀的有機知識系統(tǒng),它描述概念與概念之間的關系以及概念的屬性與屬性之間的關系,含有關系層次豐富而多樣化的詞匯語義知識.
在《知網》結構中有兩個主要的概念是“概念”和“義原”,“概念”是用“義原”這種“知識表示語言”來描述的,“義原”是《知網》中不可分割的最小基本單位.一個詞用一個或多個概念描述,一個概念用一組義原描述,詞的相似度計算最終可以歸結到義原的相似度計算.本文采用《知網》系統(tǒng)分析詞的結構特征.
定義1 w為一個詞,W為詞的集合,即w∈W.
定義2 詞語相似度Sim(w1,w2).給定兩個詞語w1和w2,詞語相似度取值為一個0到1之間的實數,兩者相同為1,完全無關為0[5].
定義3 語義距離Dis(w1,w2).給定兩個詞語w1和w2,以概念間結構層次關系組織的語義詞典為基礎,兩個概念結構在給定的樹狀概念層次體系中存在的一條由上下位關系和同位關系構成的路徑,把這條路徑的長度稱作語義距離,取值為正整數.
詞語相似度和語義距離之間存在著反比關系[5],對于兩個詞語w1和w2,Dis(w1,w2)越大,則Sim(w1,w2)越小,反之亦成立.
定義4 c為《知網》中的一個概念,C為所有概念的集合,即c∈C.
定義5 B(ci)=w,ci∈C為概念ci用于表示詞w.
定義6 F(w)為w對應的概念集合.給定一個詞語w,在《知網》中被表示成一個或多個概念,稱為詞w的概念向量表示,表示為F(w)={c1,c2,…,ci,…,cn| ci∈C,B(ci)=w,1≤i≤n},有F(w)?C.
1.2 計算方法
1.2.1 詞語相似度計算
對于兩個詞語w1和w2,文獻[5]給出w1和w2的相似度定義為各個概念相似度的最大值,即

上述公式把詞語相似度計算轉換為概念相似度計算,而在《知網》中概念是由義原或極個別具體詞組成的,因此計算詞語的相似度最終可以轉換為計算義原的相似度.
1.2.2 義原相似度計算
在《知網》中義原是從所有漢語詞中提煉出可以用來描述其他詞匯的不可再分的基本意義單元,義原根據上下位關系構成了一個樹狀義原層次體系,故可通過計算在義原樹中的語義距離計算義原相似度,文獻[5]假設兩個義原在這個層次體系中的路徑距離為d,得到這兩個義原之間的相似度:

其中,p1和p2表示兩個義原,d是p1、p2在義原層次體系結構中的路徑長度,α是可調節(jié)參數.α的含義是當相似度為0.5時的詞語距離值.
1.2.3 概念相似度計算
定義7 y為《知網》中的一個義原,Y為所有義原的集合,即y∈Y.
在《知網》中,一個概念ci是用一組義原描述式組合,其中義原描述式由義原與對應的符號構成.
基本義原描述式:用“基本義原”,或者“(具體詞)”進行描述;
關系義原描述式:用“關系義原=基本義原”或者“關系義原=(具體詞)”或者“(關系義原=具體詞)”來描述;
符號義原描述式:用“關系符號基本義原”或者“關系符號(具體詞)”加以描述;
定義8 P(ci)={y1,y2,…,yi,…,yn|yi∈Y,1≤i≤n}為概念ci對應的基本義原集合.
定義9 P1(ci)為概念ci的第一基本義原描述式中的基本義原集合,第一基本義原描述式即在概念ci出現的第一個基本義原描述式.有0≤|P1(ci)|≤1,且P1(ci)?P(ci).
定義10 P2(ci)為概念ci的其他基本義原描述式中的基本義原集合,除第一基本義原描述式外的基本義原描述式稱為概念ci的其他基本義原描述式,有 P2(ci)?P(ci).
定義11 P3(ci)為概念ci的關系義原描述式中的基本義原集合,有P3(ci)?P(ci).
定義12 P4(ci)為概念ci的符號義原描述式中的基本義原集合,有P4(ci)?P(ci).綜上有P(ci)= P1(ci)∪P2(ci)∪P3(ci)∪P4(ci)
文獻[5]提出了一種計算實詞概念相似度的方法,利用上述4個基本特征計算2個概念ci,cj的相似度:
1)第一基本義原描述式,這一部分的相似度記Sim1(y1,y2)(y1∈P1(ci),y2∈P1(cj)),計算方法見式(2);
2)其他基本義原描述式,這一部分的相似度記為Sim2(y1,y2),計算方法如下:
(i)列出P2(ci)和P2(cj)中的所有可能的配對情況,分別計算相似度,取相似度最大的一組,記錄下來并從P2(ci)和P2(cj)中刪除這組的2個元素.
(ii)重復執(zhí)行(i),直至P2(ci)和P2(cj)為空.
(iii)計算(ii)中得到的相似度的算術平均值.
3)關系義原描述式,這一部分的相似度記為Sim3(y1,y2),計算方法是將關系義原相同的描述式分為一組,并計算其相似度,最后取所有組的算術平均值.
4)關系符號描述式,這一部分的相似度記為Sim4(y1,y2),計算方法是將關系符號相同的分為一組,其值是對應的兩個集合,按2)中計算方法計算這2個集合的相似度,最后取各個特征的相似度的算術平均值.
又因為主要部分的相似度值對于次要部分的相似度值起到制約作用,所以如果主要部分相似度比較低,那么次要部分的相似度對于整體相似度所起到的作用也要降低.
于是兩個概念語義表達式的整體相似度記為:

其中,βi(1≤i≤4)是可調節(jié)參數,且有β1+β2+β3+β4 =1,β1≥β2≥β3≥β4.后者反映了Sim1到Sim4對于總體相似度所起到的作用依次遞減.
2 基于逆概念頻率(inverse concept frequency,ICF)的詞語相似度計算
定義13 基本義原區(qū)分度.I(ci,yj)(yj∈P(ci))為基本義原yj在概念ci中的區(qū)分度,即概念ci區(qū)分于其他所有概念的因素中,yj義原在P(ci)中所占的權重.
定義14 基本特征區(qū)分度.I(ci,Pj(ci))(1≤j≤4)為基本特征j(j為正整數,1對應第一基本義原描述式,2對應其他基本義原描述式,3對應關系義原描述式,4對應關系符號描述式)在概念ci中的區(qū)分度.有I(ci,Pj(ci))=max{I(ci,yk)(yk∈Pj(ci))}.
從區(qū)分度的定義可以得出,利用Pj(ci)(1≤j≤4)對應的4個基本特征計算2個概念相似度時, Simj(y1,y2)(1≤j≤4)所占的權重βj與I(ci,Pj(ci))越接近計算的結果越理想,即|βj-I(ci,Pj(ci))|的值應該越小越好.
對于不同的概念ci,I(ci,Pj(ci))(1≤j≤4)的值是不定的.而傳統(tǒng)的義原權重計算方法計算不同概念對的相似度時采用固定的義原權重,這必然導致|βj-I(ci,Pj(ci))|的結果是波動的.這種波動是會影響到詞的相似度計算.
2.1 ICF
本文借鑒TF-IDF權重計算方法[11],提出使用ICF計算義原在概念中的權重,ICF權重計算方法是一種統(tǒng)計方法,其主要思想是使用義原出現在概念的頻率來權衡該義原區(qū)分概念的能力,義原的重要性隨著它在概念庫中出現的頻率成正比下降.
定義15 ICF是一個義原區(qū)分度的普遍性的度量.對于某一義原pi的ICF,可以由《知網》概念的總數目除以該義原pi出現在Pj(ci)(ci∈C,1≤j≤4)上的概念總數目,再將得到的商取對數得到.

其中pi為《知網》中的某個義原,j為義原位置信息,C為《知網》概念集合.
定義16 ICF_C(ci,yj)(yj∈P(ci))為基本義原yj在概念ci中的ICF權重.對于一個概念ci而言,其基本義原的ICF權重就是該義原在《知網》中的ICF權重,故有
ICF_C(ci,yj)=ICF(yj,k)(對于k,有yj∈
Pk(ci)).
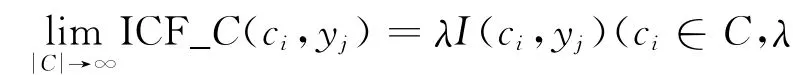
定義17 ICF_C(ci,Pj(ci))=max{ICF_C(ci, yk)(yk∈Pj(ci))}為各個基本特征概念ci中的ICF權重.
2.2 概念相似度的計算
不同于文獻[5]中使用固定權值計算相似度,使用ICF計算特征結構權值進而計算整體相似度,需要消除主要部分相似度值對于次要部分相似度值的牽制作用,4類特征結構的相似度對于總體的相似度所起到的作用決定于ICF,并不存在遞減關系.于是,本文采用以下公式(4)計算兩個概念語義表達式的整體相似度:
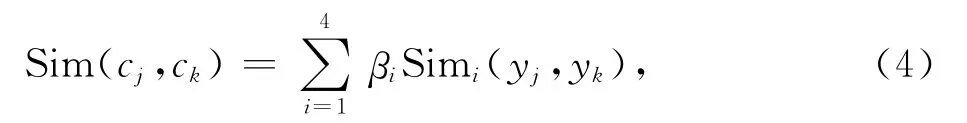
其中,βi(1≤i≤4)是據ICF計算得出的權重參數,且有β1+β2+β3+β4=1.
2.3 基于ICF的詞語相似度計算
對于概念c∈C,?ci∈C(i=1,2,…,|C|),使用式(4)計算概念c和ci的相似度Word_Simi(c,ci).假設c有n(0<n≤4)個特征結構p11,p12,…,p1n,ci有m(0<m≤4)個特征結構p21,p22,…,p2m.
算法:基于ICF的詞語相似度計算算法
輸入:詞語W
輸出:按與詞語W相似度從高到低排列的《知網》詞集
方法:
1)對于在義原樹中的每一個義原yi,分別計算基本義原yi出現在第一義原、其他基本義原、關系義原、關系符號位置上的次數.
2)對于在《知網》中的每一個概念ci(i≥1),再對于在概念ci中的每一個特征結構Pj,依據定義17計算Pj的ICF值并作歸一化處理,記作ICFPj.
3)對于在《知網》中的每一個概念ci,計算概念ci和概念c的相似度.

4)依據公式1)和第3)步的結果計算W和《知網》中所有詞語的相似度.
5)按相似度從高到低排序,最終得到有序結果集.
證明算法有效性時,本文提出一種假設,假設概念集合C中的元素ci對應的I(ci,Pj(ci))(1≤j≤4)是不相同的,且存在一個值α(0<α≤1)使得對于兩個不同的概念ci和cj,有I(ci,Pk(ci))-I(cj,Pk(cj))≥α(?1≤k≤4).這樣假設是符合人們對詞語的直覺的.
證明 在概念個數|C|較多的情況下基于ICF的詞語相似度計算比固定權重算法改進了概念的相似度計算.
對于概念的4個基本結構的權重βj(1≤j≤4),即|βj-I(ci,Pj(ci))|的值應該越小越好.現將βj固定為4個常數αj(1≤j≤4),基于上述假設,對于概念ci使得|αj-I(ci,Pj(ci))|≥α/2.
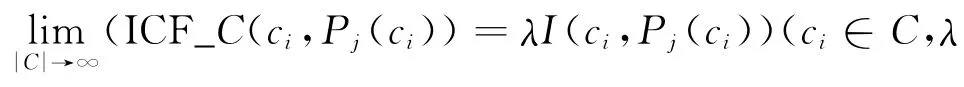

根據上式說明存在一個正整數N,當|C|≥N時有|βj-I(ci,Pj(ci))|<α/2,這就說明了在|C|足夠大的前提下,基于ICF的詞語相似度計算比固定權重算法改進了概念的相似度計算.
例1 給定詞語C=“軍事”,在《知網》中,C的概念解釋為affairs|事務,military|軍,令Ci=“軍管會”, Ci的概念解釋為institution|機構,military|軍.按2.3節(jié)的計算方法,經過歸一化處理后C的ICF=[0.229 6,0.7,0.01,0.05],C和Ci的基本義原、其他基本義原、關系義原、關系符號相似度數組為[0.231 6,1,1, 1],因此Sim(C,Ci)=0.823 6.使用文獻[5]的算法,并結合文獻[6]對義原相似度計算的改進,得出Sim (C,Ci)=0.231 6.因此,可以看出,本文在某些區(qū)域方面極大地提升了相似度計算的精度.
2.4 多義詞處理
中文詞匯中,存在著一詞多義的現象,在《知網》中體現為一個詞語對應多個概念.對于一詞多義的詞語其根據上下文來判斷具體的釋義,《知網》的構建已經提出了處理一詞多義的方法[10].
在《知網》的概念屬性集中存在E_C屬性,該屬性解釋為例子屬性.例子屬性用途在于為消除歧義提供可靠的幫助.這里試以“打”的兩個義項為例,一個義項是“buy|買”,另一個是“weave|辮編”.
W_C=打,
G_C=V,
E_C=~醬油,~張票,~飯,去~瓶酒,醋~來了,
DEF=buy|買,
W_C=打,
E_C=~毛衣,~毛褲,~雙毛襪子,~草鞋,~一條圍巾,~麻繩,~條辮子,
G_E=V,
DEF=weave|辮編.
設要判定的歧義語境是“我女兒給我打的那副手套哪去了”.我們通過對“手套”與“醬油”等的語義距離的計算以及跟“毛衣”等的語義距離的計算的比較,將會得到一個正確的歧義判定結果.
文獻[9]則取兩個詞對應的概念對中概念相似度的最大值作為兩個詞的相似度.與文獻[10]相比,則沒有考慮上下文對詞義的影響,本文認為文獻[10]中的消除歧義的方法充分利用上下文對詞義的影響,而一詞多義的產生也是由于上下文的不同而產生.故本文認為使用文獻[10]的方法來消除歧義更為合適.
由于《知網》還未完善概念中E_C屬性,且在現有的《知網》中概念的E_C屬性值還未公布.故本文無法對一詞多義的處理結果進行實驗分析.
3 實驗結果及分析
3.1 實驗結果
本文使用Visual Studio 2008在Window操作系統(tǒng)上實現了基于ICF的義原權重計算,采用式(1)計算詞語相似度,基于義原在義原層次樹中的深度和密度[5]計算義原相似度.
實驗選取了部分具有代表性的詞匯,采用6個分類詞“財經”、“教育”、“美食”、“政治”、“軍事”、“體育”作為實驗對象,對《知網》中的詞匯進行相似度計算,并按相似度從高到低排序.由于與分類詞相關的詞語總數數量相差甚遠,常用的準確率、召回率對不同的分類詞無法選取統(tǒng)一的標準,故我們使用圖表和準確率、召回率結合的形式描述實驗結果.圖1中,每個分類詞使用5~6個點作為階段性結果統(tǒng)計點,其中,點(x,y)表示在實驗結果的詞集中,排名前x詞集的準確率或召回率.
實驗將本文算法(方法1)、文獻[6]算法(方法2)和文獻[5]算法(方法3)3種算法比較,從圖1可以看出本文算法在部分中心詞匯取得了不錯的擴展效果.
3.2 實驗結果分析
本文基于ICF權重計算方法是基于這樣的一個假設:對區(qū)分概念最有意義的義原應該是那些在其他概念的相應義原位置中出現次數少的義原,它們區(qū)分概念的能力較大.這種假設是符合人們平時的認知的.應用ICF完成對義原權重的調整,取代了傳統(tǒng)實驗中義原固定權重,避免計算時權重與實際區(qū)分度產生波動.從實驗結果可以看出,利用ICF完成對義原權重的調整抑制了這種波動的產生.
但ICF只是對義原實際區(qū)分度的一種假設,本質上是一種試圖抑制噪聲的加權,并且單純地認為概念頻率小的義原就越重要,概念頻率大的義原就越無用,顯然這不是完全正確的.比如概念“美食”的義原是“食品”“好”“良”,“食品”在第一基本義原結構中出現次數是364,“好”在其他基本義原結構中出現次數是263,概念“美食”在計算義原權重時更趨向于“好”而非“食品”,這導致對“美食”進行詞的擴展時,很多和“好”相關的詞具有較高的相似度,導致局部實驗結果不夠理想.文獻[6]中的算法在“美食”概念上表現得較為不理想,是由于它忽略了第一義原和其他義原的區(qū)別,從《知網》的結構上來看,這樣在計算詞的相似度的時候會導致對褒貶義的詞較為敏感,從實驗結果可以看出,其排序較前的詞都是具有義原“好”、“良”等相近意思的詞.
4 結 論

圖1 準確率和召回率Fig.1 Accuracy rate and recall rate
基于《知網》進行詞的擴展,充分利用概念描述結構,考慮義原代表所在概念的信息量,根據義原的ICF賦予義原權重.在詞的相似度計算實驗中,采用將概念的4個義原基本結構權重分別與4個義原基本結構相似度相乘,得到概念與概念的相似度,最后采用文獻[5]中公式(1)得到相似度從高到低排列的詞集.實驗結果證明,與分類詞相似的詞集整體上得到了不錯的效果.某些分類詞的擴展效果有待改善,原因在于,基于ICF計算義原權重算法對概念解釋的依賴性過大,隨著時代的進步和漢語的演化,《知網》中某些詞語的義原解釋和現實生活中人們所理解的含義有偏差.在今后的研究工作中,重點在于如何提高基于ICF計算義原權重算法的魯棒性,使算法適用于更多的詞匯,并把該項研究成果應用于文本分類等領域.
[1] 魯松.自然語言處理中詞相關性知識無導獲取和均衡分類器構建[D].北京:中國科學院研究生院計算技術研究所,2001.
[2] Rodríguez M A,Egenhofer M J.Determining semantic similarity among entity classes from different ontologies [J].Knowledge and Data Engineering,IEEE Transactions,2003,15(2):442-456.
[3] Budanitsky A,Hirst G.Semantic distance in Word Net:an experimental,application-oriented evaluation of five measures[C]∥Workshop on Word Net and Other Lexical Resources.Pennsylvania:The Pennsylvania State University,2001:1-6.
[4] Lee W N,Shah N,Sundlass K,et al.Comparison of ontology-based semantic-similarity measures[C]∥AMIA Annual Symposium Proceedings.Bethesda MD,USA:American Medical Informatics Association,2008:384-388.
[5] 劉群,李素建.基于知網的詞匯語義相似度計算[J].中文計算語言學,2002,7(2):59-76.
[6] 江敏,肖詩斌,王弘蔚,等.一種改進的基于《知網》的詞語語義相似度計算[J].中文信息學報,2008,22(5):84-89.
[7] 劉青磊,顧小豐.基于《知網》的詞語相似度算法研究[J].中文信息學報,2010,24(6):31-36.
[8] 王小林,王義.改進的基于知網的詞語相似度算法[J].計算機應用,2011,31(11):3075-3077.
[9] 朱征宇,孫俊華.改進的基于《知網》的詞匯語義相似度計算[J].計算機應用,2013,8:2276-2279,2288.
[10] 董振東,董強.知網[DB/OL].[1999-06-01].http:∥www.keenage.com/.
[11] 劉赫,劉大有,裴志利,等.一種基于特征重要度的文本分類特征加權方法[J].計算機研究與發(fā)展,2009,10: 1693-1703.
Word Similarity Computing Based on Inverse Concept Frequencies
SUN Jing,ZHANG Dong-zhan*
(School of Information Science and Engineering,Xiamen University,Xiamen 361005,China)
The word similarity computation plays an important role in service selection,natural language processing,and literature retrieval.Current researches of word similarity are generally based on How Net.By analyzing the structure of How Net,we present an idea that the weight of four basic structures of the concept should be dynamically generated during computing the similarity between two words and a method of calculating the weight of primitive based on the frequency.We compute the ICF of each basic primitive in the first basic primitive,other basic primitives,relation primitive and mark primitive through concept structure analyzing,and take the maximum ICF as the ICF of the basic structure.Then we compute the word similarity by using dynamic ICF obtained as the weight of four basic structures.Experimental results show that the accuracy of word similarity calculation is effectively improved.The average accuracy of former 160 words rises from 30.74%to 72.28%,and the recall rises from 15.87%to 49.64%.
How Net;word similarity;inverse concept frequency;primitive weight
10.6043/j.issn.0438-0479.2015.02.018
TP 391.1
A
0438-0479(2015)02-0257-06
2014-04-29 錄用日期:2014-08-25
國家自然科學基金(61303004);福建省自然科學基金(2013J05099)
*通信作者:zdz@xmu.edu.cn
孫晶,張東站.基于逆概念頻率的詞語相似度計算[J].廈門大學學報:自然科學版,2015,54(2):257-262.
:Sun Jing,Zhang Dongzhan.Word similarity computing based on inverse concept frequencies[J].Journal of Xiamen University:Natural Science,2015,54(2):257-262.(in Chinese)
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
開放教育研究(2020年2期)2020-03-31 01:54:14
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
湘江法律評論(2016年0期)2016-06-15 20:29:32
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
衡陽師范學院學報(2015年2期)2015-02-26 03:24:39
當代修辭學(2011年6期)2011-01-29 02:49:50
