基于決策樹技術的CET-4成績數據挖掘研究
2015-12-01 07:06:32劉靜
赤峰學院學報·自然科學版 2015年24期
劉靜
(阜陽師范學院 教育科學學院,安徽 阜陽 236037)
基于決策樹技術的CET-4成績數據挖掘研究
劉靜
(阜陽師范學院 教育科學學院,安徽 阜陽 236037)
本文運用決策樹分類技術進行數據挖掘,從中發(fā)現CET-4考試四個部分對總成績的影響程度.其中由決策樹提取出分類規(guī)則,對于大學英語教學具有一定的指導意義.
數據挖掘;決策樹;ID3算法
1 引言
CET-4考試是國家教育部組織的標準化英語教學水平考試,教育管理機構把它當作檢查大學英語教學效果的一個有效尺度.每一年學校的數據庫系統(tǒng)中都存放著海量的CET-4成績信息,學校的數據庫能夠實現數據的快速錄入、查找、計算等操作,卻無法發(fā)現成績數據中隱藏的關系和規(guī)則.本文主要研究的就是如何從海量數據中發(fā)現隱藏的關系和規(guī)則,分析潛在影響學生成績的因素,從而為提高教學質量與教育管理提供依據.
2 數據挖掘決策樹技術
數據挖掘是指從大量的數據中通過算法發(fā)現隱藏于其中關系和規(guī)則的過程.數據挖掘有很多領域,分類就是非常重要的一個分支.決策樹是一種較為流行的分類技術,采用自頂向下的遞歸方式生成一個類似于流程圖的樹型結構.
3 ID3算法
1986年J·Ross Quinlan提出了著名的ID3算法.該算法就是信息增益屬性劃分,找出分裂后信息增益屬性最大的再次劃分.然后繼續(xù)同樣的過程,直到生成的決策樹能完美分類訓練樣例.
4 決策樹技術在CET-4成績分析中的應用
4.1數據獲取和數據預處理
4.1.1數據的獲取
從教務處下載了我校普通本科班2012屆學生某專業(yè)某次四級成績匯總表.
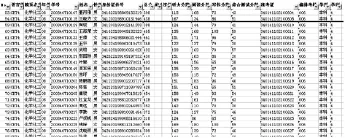
圖1 大學英語四級成績原始數據
4.1.2數據預處理
去除原有數據源EXCEL表格中的不相關字段,保留CET-4總成績、聽力成績、閱讀成績、寫作成績、綜合測試成績.使用忽略元組的方法將缺考學生的記錄刪除,共計175條.經過數據預處理后參加模型構建的樣本數共計3384條,而預處理前的樣本總數是3559條,樣本的有效率達90.8%.
將樣本數據進行離散化的處理.CET-4考試的試卷總分數為710分,將425分作為分割點,把CET-4成績字段y離散為“pass”、“nopass”兩個部分.
聽力部分滿分249分,閱讀部分滿分249分,寫作和翻譯部分滿分142分,綜合部分滿分70分.分別將聽力字段(st)、閱讀字段(sy)、寫作和翻譯字段(sx)、綜合字段(sz)的所有記錄按照 st<=125、125<=st<199、st>=199、sy<=125、125<=sy<199、sy>=199、sx<=71、71<=sx<100、st>=100、sz<35、35<=sz<45、sz>=45離散化為“C”、“B”、“A”三段.
4.2決策樹分類模型的構造
根據ID3算法構造決策樹,操作過程如下:
(1)計算決策樹分類屬性的期望信息量
經過數據預處理、離散化操作后,用于構造決策樹的記錄為3384條,其中,“pass”和“nopass”記錄分別為2015條、1359條.由公式定計算出分類屬性的期望信息量為:
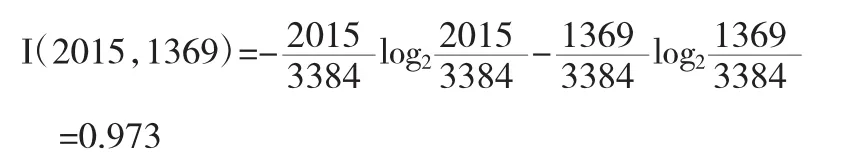
(2)依次算出st、sy、sx、sz 4個屬性字段的信息量
算出st屬性字段的信息量.st值為“C”的樣本數707個,記為 (25,682);st值為“B”的樣本數2580個,記為(1893,687);st值為“A”的樣本數97個,記為(97,0).
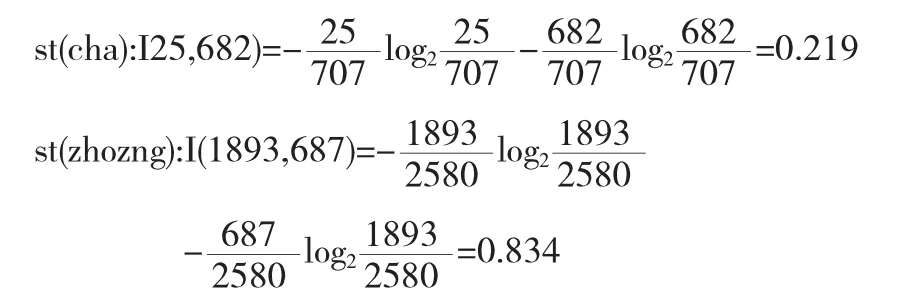
計算sy的信息量.sy值為“C”的樣本數468個,記為(7,461);sy值為“B”的樣本數2747個,記為(1839,908);sy值為“A”的樣本數169個,記為(169,0).
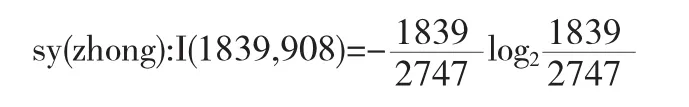
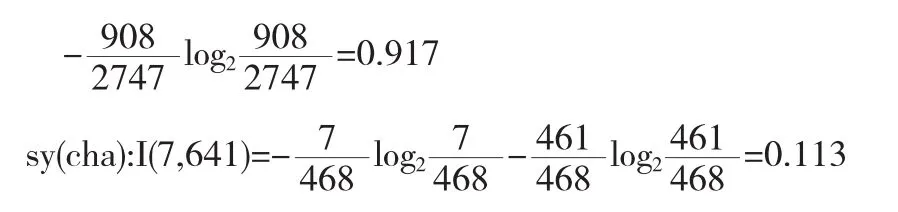
計算sz的信息量.sz值為“C”的樣本數442個,記為(53,389);sz值為“B”的樣本數2360個,記為(1414,946);sz值為“A”的樣本數582個,記為(548,34).
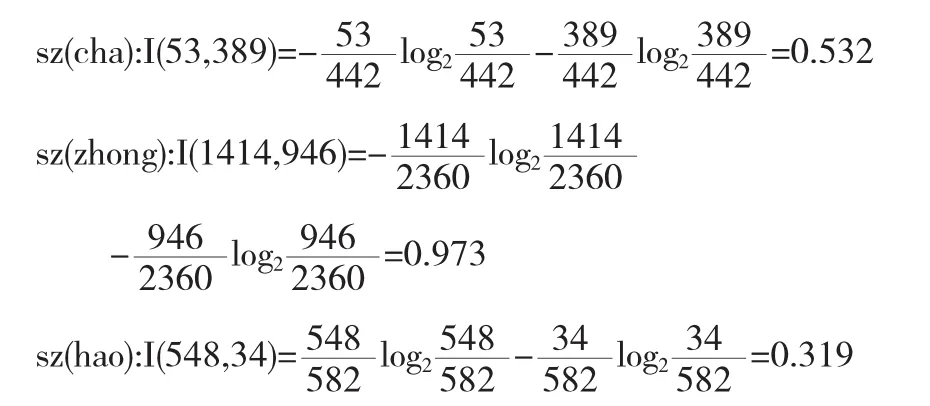
計算sx的信息量.sx值為“C”的樣本數645個,記為(59,586);sx值為“B”的樣本數2333個,記為(1560,773);sx值為“A”的樣本數406個,記為(396,10).
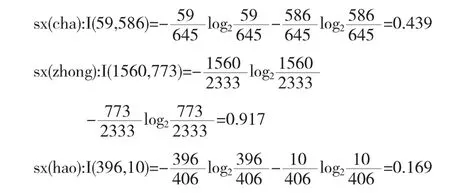
(3)分別計算st、sy、sx、sz的信息熵

(4)分別計算出st、sy、sx、sz的信息增益量
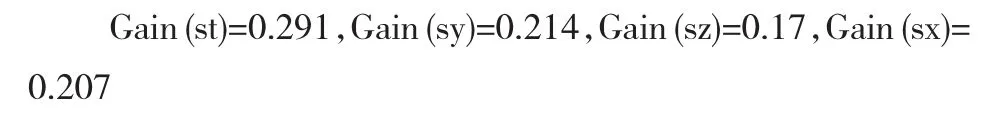
比較以上4個屬性字段的信息增益量,找出信息增益量最大的st字段,把該字段當作決策樹的根節(jié)點,計算st字段的3個屬性值構造出下面的分支.
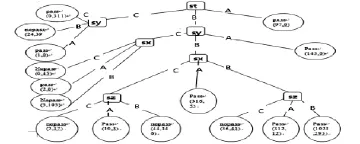
圖2 CET-4決策樹
(5)提取分類規(guī)則
研究顯示,在CET-4考試中,對CET-4分數影響最大的是聽力部分,然后是閱讀,接下來是寫作和綜合.下面從決策樹模型中,根據分類結果為“pass”或“nopass”,提取得到了學生能否能夠通過CET-4考試的分類規(guī)則.
提取出CET-4考試結果為“pass”的分類規(guī)則為:
IF“st”=“A”,THEN分類結果是“pass”;
IF“st”=“B”AND“sy”=“A”,THEN分類結果是“pass”;
IF“st”=“B”AND“sy”=“B”AND“sx”=“B”,THEN分類結果是“pass”;
IF“st”=“B”AND“sy”=“B”AND“sx”=“A”,THEN分類結果是“pass”;
IF“st”=“B”AND“sy”=“B”AND“sx”=“B”AND“sz”=“A”,THEN分類結果是“pass”;
提取出CET-4考試結果為“nopass”的規(guī)則為:
IF“st”=“C”,THEN分類結果是“nopass”;
IF“st”=“B”AND“sy”=“C”,THEN分類結果是“nopass”;
IF“st”=“B”AND“sy”=“B”AND“sx”=“B”AND“sz”=“C”,THEN分類結果是“nopass”;
IF“st”=“B”AND“sy”=“B”AND“sx”=“B”AND“sz”=“B”,THEN分類結果是“nopass”.
5 結論
由決策樹提取出來的分類規(guī)則,可以輔助指導大學生的英語學習.CET-4考試中,聽力部分對能否通過CET-4考試起到了關鍵性的作用;然后,是閱讀部分,對CET-4考試影響較大;最后,寫作部分和綜合部分對CET-4考試的影響較小.在英語學習中有些學生認為,CET-4考試中,閱讀和寫作是決定CET-4成績高低的關鍵,這種認識缺少科學依據,學生需要扭轉觀念,盡早調整自己的英語學習計劃,將聽力部分作為復習重點來強化練習.同學們在備考的過程中,可以參考決策樹模型以及分類規(guī)則的結果,找出自己英語學習中的短板,進一步強化自己的長項,制定適合自己的學習目標和學習計劃,進行針對性的復習,科學有效的提高CET-4成績.
〔1〕Jiawei Han,Micheline Kamber.數據挖掘:概念與技術[M].北京:機械工業(yè)出版社,2007.188-198.
〔2〕王永梅,胡學鋼.決策樹中ID3算法的研究[J].安徽大學學報(自然科學版),2011(3):35-37.
〔3〕劉紅巖,等.數據挖掘中的數據分類綜述[J].清華大學學報(自然科學版),2002,42(6):727-730.
〔4〕陳昌川.數據挖掘在大學英語考試中的應用研究[D].重慶:重慶大學,2009.
〔5〕韓亞峰.P2P流媒體數據調度策略研究[J].河南科技學院學報(自然科學版),2013,41(1):86~90.
〔6〕張科星.基于云計算的數字資源系統(tǒng)設計[J].河南科技學院學報(自然科學版),2013,41(1):91~94.
TP391
A
1673-260X(2015)12-0018-02
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
Coco薇(2017年11期)2018-01-03 20:59:57
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
