大數據時代基于個性化服務的數字圖書館數據搜索引擎設計
2016-01-19 02:52:48蘭州商學院信息中心蘭州730020
圖書館理論與實踐 2015年4期
●陳 臣(蘭州商學院信息中心,蘭州 730020)
大數據時代基于個性化服務的數字圖書館數據搜索引擎設計
●陳臣(蘭州商學院信息中心,蘭州730020)
[關鍵詞]數據時代;數據搜索引擎;設計;圖書館 數據搜索過程缺乏或所設置的 不準確時,搜索引擎可通過機器自主學習過程,保證所搜索的數據全面、準確。第三,搜索引擎應具備較強的讀者閱讀服務保障功能,可為用戶提供即搜即得、即搜即用、不搜即得的服務。搜索引擎應具有較強的搜索數據預測和數據關系挖掘功能,可依據數據圖譜的關系挖掘出更深層次的知識關聯。用戶不通過數據搜索就可得到所需要的數據信息,搜索引擎可為用戶提供自動推送式服務。[7]
[摘要]大數據時代,數據搜索引擎在用戶個性化服務保障過程中的重要性不斷增長。本文設計了一種大數據環境下數字圖書館數據搜索引擎,該搜索引擎減少了大量的對歷史查詢的重復計算,節省了搜索時間,提高了查詢效率,并可使查詢成本最小,顯著提高了系統的整體搜索性能。
大數據時代具有數據規模化、數據類型多樣性、高價值、處理速度快和社會化5個特點。隨著數字圖書館讀者云閱讀需求和服務模式的變革,以及云計算技術、無線傳輸技術、傳感器網絡和閱讀終端技術的發展與普及,目前,基于大數據平臺為讀者提供安全、高效、經濟、便捷、可定制的個性化閱讀推送式服務,已成為圖書館用戶服務模式發展的一個重要趨勢。
大數據時代,圖書館的數據量呈現爆發式的增長,數據集的規模將達到TB或者PB的級別。此外,圖片、音頻、視頻等非結構化數據將占據數據總量的80%以上,大幅度增強了數據存儲、管理、搜索和查詢的難度。傳統以數字文本存儲、搜索和分析的數據庫關聯算法、語義分析方法,已不適合大數據時代用戶服務高效、準確、快速和經濟的需求。因此,如何依據大數據時代讀者閱讀內容和服務質量需求,提高圖書館搜索引擎信息發現和知識挖掘的效率、容錯性、可控性和可擴展,確保信息搜索過程智能、快速、低成本和負載均衡,是關系讀者大數據時代閱讀滿意度和圖書館市場競爭力的關鍵。[1]
1 大數據時代圖書館數據環境特點
(1)用戶私有化數據快速增長。大數據時代,以讀者個性化定制為核心的用戶推送式服務,已成為數字圖書館服務模式變革的主要方向。為了滿足讀者數字化閱讀需求和提高用戶滿意度,圖書館將與云服務商、電子商務運營商、第三方增值服務商、通信服務商等,以大數據平臺數據共享的方式進行服務數據和用戶數據資源共享。當運營商所采集的用戶數據量達到一定規模后,會通過屏蔽搜索引擎和加密等技術手段,對所存儲的個人隱私數據進行保密和屏蔽搜索。這大幅度增加了圖書館大數據共享平臺數據搜索體驗的難度和可靠性,降低了所搜索數據的價值和數據可用性,嚴重影響了數字讀者個性化閱讀服務的質量和用戶滿意度。[2]
(2)海量未WEB化的數據增加了數據搜索難度。大數據時代數據呈現海量級數增長的態勢。圖書館所采集和用戶服務保障數據,主要包括讀者閱讀行為數據、用戶個人信息數據、讀者社會關系數據、論壇與博客等社交流動產生的數據、APP(Accelerated Parallel Processing)應用產生的數據、個人云應用產生的數據、物聯網產生的數據等。這些數據海量存儲于圖書館與其他共享服務商的數據中心,卻并未進行有效的價值提取、類別劃分、組織編目、定位存儲、檢索維護和網頁WEB化,大幅度增加了數據搜索的復雜度、成本、時間和準確性。
(3)要求搜索引擎具備較強的大數據價值發現功能。根據摩爾定律可得出,每18個月圖書館數據中心的存儲性能可提高一倍,同時存儲設備硬件成本降低一半。因此,大數據時代圖書館數據中心的存儲能力和成本,將不再是困擾大數據環境讀者服務有效性的主要因素,而大數據的價值挖掘和應用有效性,則成為關系圖書館服務能力建設和用戶滿意度的關鍵。
大數據環境下,圖書館擁有的標準化、結構化數
據約占數據總量的15%,近85%的數據為半結構化數據和非結構化數據。部分關系用戶個性化服務有效性的重要數據,則分別存儲于政府、第三方增值服務商和運營商的大數據庫中,并隨著其所擁有數據的數量、價值的快速增長而具有較強的壟斷性。其次,服務數據具有內容龐大和鏈接復雜的特點,對搜索引擎的運行效率、并發處理能力、智能化和經濟性要求較高。[3]
(4)要求搜索引擎具備較強的可用性和可控性。大數據時代,圖書館通常以自建大數據平臺和簽署合作協議的方式,與相關政府數據庫、運營服務商大數據平臺、企業大數據平臺共享大數據資源。但是,不同的政府機構、運營服務商和企業大數據平臺之間,可能存在數據存儲與管理標準不統一、不同的大數據平臺之間的數據缺乏橫向與縱向交流、平臺數據管理與搜索存在信息盲點、圖書館缺乏大數據管理與整合工具等問題,會導致搜索引擎在數據搜索過程中降低數據的價值密度和共享性。因此,可能會影響數據采集、處理、分析和挖掘結果的可用性,最終將影響圖書館在制定讀者個性化服務策略、優化服務資源、提高服務收益率和降低服務風險活動的有效性。[4]
2 面向讀者個性化服務的大數據搜索引擎設計
大數據時代,圖書館數據環境具有規模龐大、平臺結構復雜、搜索效率和準確率要求高、搜索時間和成本控制難度大的特點。因此,要求搜索引擎具備快速響應和復雜查詢、分析的能力。同時,可支持不同的大數據平臺系統結構,具有較高的容錯性、可擴展性和較低搜索延遲,數據接口開放并向下兼容性。結合大數據時代數據環境特點和圖書館讀者個性化服務要求,本文設計的圖書館大數據搜索引擎如下圖所示。
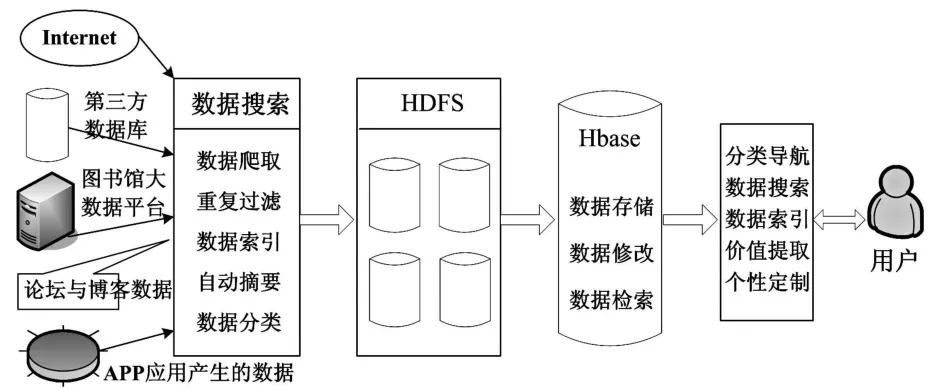
圖 圖書館大數據搜索引擎
sss
設計的搜索引擎主要由爬蟲與索引器、查詢器、HDFS(Hadoop Distributed File System)、Hbase、搜索管理平臺五部分組成。爬蟲是一種自動獲取網頁內容的程序,負責在后臺從互聯網、圖書館與第三方大數據平臺、論壇與博客服務器、APP應用服務器之中周期性地爬取數據,并為數據建立索引。查詢器主要利用這些索引,通過檢索用戶的查找關鍵詞來產生查找結果。HDFS自動提供了文件在集群中的存儲和冗余備份,是專為大文件的存儲而設計的。它將大的文件切分成多個小塊,然后將這些小塊分散存儲在多個數據結點中,具有存儲成本低廉、具備較強的容錯性和數據快速讀取的特點。Hbase是一種分布式、半結構化和基于列的分布式數據庫,適合非結構化數據的存儲。可對HDFS之中提取出來的文件進行存儲、修改與檢索。搜索管理平臺可根據用戶搜索定制需求,從Hbase中全面、準確、經濟、快速地提取出所需要的數據和信息。[5]
3 大數據時代圖書館搜索引擎設計應重點關注的問題
(1)應具備較強的數據過濾和去重功能。大數據時代,數字圖書館除自身擁有龐大的大數據用戶管理、服務平臺外,還可以簽署合作協議的方式,與第三方運營服務商、政府機構和企業共享大數據信息平臺。圖書館大數據平臺內部不同的存儲空間之間,以及圖書館大數據平臺與其他運營商大數據平臺之間,會不可避免地存在著大量重復數據。大量重復數據的存在,不但大幅度降低了圖書館大數據平臺的數據價值密度,而且嚴重影響了圖書館讀者大數據閱讀服務質量。因此,圖書館必須提高搜索引擎的數據過濾和去重功能,來增強所搜索數據的價值密度和可用性。
首先,搜索引擎應注重提取信息的代表性特征。應從語義、用法、結構和統計上,分析詞匯、短語、命名實體或流行用語的知識特征,明確各種類型重復數據的知識結構方式,通過數據清洗、整合過程有效降低數據冗余。其次,搜索引擎應根據用戶設定的搜索模式和數據權重,及時發現關系圖書館用戶服務和讀者閱讀體驗的特征數據。同時,應具備快速搜索、精確處理、準確排序和開放接口的能力,并支持對博客、短信等非結構化數據的分析。第三,搜索引擎應擁有海量處理規模、多字段過濾、智能篩選、高效過濾的功能,具有較高的數據搜索效率和較低的數據發現成本。[6]
(2)搜索引擎擁有智能、自動化的數據搜索能力。大數據時代,圖書館搜索引擎應具備智能管理、自動處理、自主學習和推薦服務的功能。首先,搜索引擎應具備對已搜索過程記憶、未搜索數據預測、最佳搜索模式判定和自主學習的功能。能夠自動發現、識別新的語言知識和適應網絡環境變化,按照用戶搜索定義分類整理、過濾出所需的數據內容。其次,當
(3)搜索引擎系統應功能強大和可靠。圖書館應根據大數據時代讀者閱讀需求、用戶服務模式和數據環境特點,加強搜索引擎的可用性、可控性和功能性建設,確保搜索引擎可靠、易用、經濟和便捷。首先,搜索引擎在設計過程中,應對服務器日志數據、讀者訪問記錄、Office文檔、XML格式的電子表格數據、博客與論壇數據、APP應用產生的數據、圖片、音頻、視頻等半結構化和非結構化數據,實現統一搜索界面、統一運營模式和完成數據渠道的整合搜索。其次,通過建立高效的索引來加快數據的讀取速度和完整性檢查。索引過程應盡量保證語句符合查詢優化器的規則,避免進行數據庫全表掃描以提高數據查詢的效率。同時,搜索算法應允許同步更新索引和搜索,保證優先返回最佳查詢結果。第三,圖書館應獨立或與第三方開發商合作,利用谷歌、百度、亞馬遜、微軟等大型信息服務商預留的API(應用程序編程接口),結合圖書館管理和讀者服務需求進行二次開發,實現對大型信息服務商大數據庫的數據共享和增值服務。圖書館管理員和讀者可利用大型信息服務商的大數據處理能力,實現諸如用戶所處地理位置查找、在線翻譯、數據統計分析、大數據處理和云計算等大數據增值服務。
(4)提高搜索引擎的讀者個性化服務水平。大數據時代,圖書館用戶具有客戶群數量龐大、數據搜索需求個體差異大、單一用戶定制需求小和對搜索引擎定制能力要求高的特點。同時,圖書館搜索引擎的系統功能,將由傳統IT環境下利用關鍵字進行網站、網頁和匹配數據的查找,轉變為面向用戶個性化需求的潛在數據挖掘和信息推薦搜索服務。
圖書館搜索引擎設計與實現中,首先,應注重用戶個性化搜索服務的時效性要求。搜索引擎在用戶服務過程中,應及時感知用戶大數據搜索的目的與內容,并在用戶下一次搜索前快速做出響應。其次,搜索引擎的設計應基于先進的信息統計、數據挖掘、機器學習和知識管理等技術,確保搜索引擎在運行過程中,不會將用戶輸入的關鍵字作為唯一的搜索依據,而應將重點放在發現用戶真實信息與數據需求的語義搜索上。第三,搜索引擎在設計過程中,應加強系統個性化搜索推薦算法的科學性與經濟性,根據用戶特點和需求為用戶創建個性化定制推薦模型。并設置大數據搜索信息推薦的位置、大小、內容、目數、URL范圍和展現形式等參數,保證所推薦數據具有較高的價值密度、可靠性和可用性。[8]
(5)搜索引擎應保護讀者的隱私安全。讀者隱私安全保護,不僅關系讀者大數據環境閱讀活動的安全性、有效性、滿意度和可持續性,同時也涉及圖書館服務的可用性、可靠性、市場競爭力和未來發展,是大數據時代搜索引擎設計應重點關注的問題。
首先,圖書館應結合國家的法律、法規和行業安全規定,對圖書館管理數據、讀者個人信息、用戶行為數據和社會關系數據進行安全級別劃分。并與開發者簽署搜索引擎開發安全管理協議,通過數據屏蔽、高性能數據過濾接口等技術手段,限制搜索引擎對讀者隱私數據的采集。其次,針對搜索引擎讀取保密與隱私資料可能帶來的安全問題,圖書館管理員應利用robots協議,將放置圖書館系統管理密鑰、用戶服務系統帳號與密碼、讀者注冊信息數據、網站配置目錄、讀者社會關系等敏感文件的目錄,設置為拒絕搜索引擎讀取目錄,提高保密數據存儲的安全、可靠性。第三,應加強圖書館內部網絡與用戶訪問的安全管理,防止管理員與讀者因訪問非法網站而導致搜索引擎被病毒、木馬劫持,繞過網絡安全防御系統從內部向大數據庫發起攻擊,導致讀者隱私數據被泄露、截獲、竊取和篡改。
隨著大數據時代的來臨,大數據將為圖書館運營、管理和讀者服務提供有效的數據應用和決策支持,成為關系讀者個性化服務質量保障和圖書館可持續發展的重要因素。但是,大數據環境也存在著數據海量、種類繁多、數據價值密度低和數據知識發現難度大的問題。如何結合圖書館大數據環境特點和讀者服務需求,通過強化搜索引擎功能確保數據搜索過程可管、可控、經濟和可用,已成為提高圖書館大數據時代服務能力和市場競爭力的重要途徑。同時,也是關系讀者大數據時代閱讀體驗愉悅感和滿意度的關鍵因素。
因此,只有從圖書館大數據環境特點、讀者個性化服務能力建設、用戶閱讀需求和未來可持續發展出
發,在搜索引擎設計與實現過程中堅持安全、高效、智能和可擴展的理念,才能保證大數據搜索、挖掘和信息發現過程全面、高效、精確和經濟,才能為圖書館大數據管理和讀者個性化服務提供科學、全面、經濟、可靠的數據支持。
[參考文獻]
[1]王珊,等.架構大數據:挑戰、現狀與展望[J].計算機學報,2011,34(10):1741-1752.
[2]殷哲,曹炬.帶差商信息的云搜索優化算法及其收斂性分析[J].計算機科學,2012,39(1): 252-255,267.
[3]陳國華,等.基于學術社區的學術搜索引擎設計[J].計算機科學,2011,38(8):171-175.
[4]康波,劉勝強.基于大數據分析的互聯網業務用戶體驗管理[J].電信科學,2013(3):32-35.
[5]王大玲,等.基于用戶搜索意圖的Web網頁動態泛化[J].軟件學報,2010,21(5):1083-1097.
[6]余肖生,司新霞.基于聚類分析的元搜索引擎模型[J].重慶理工大學學報(自然科學版),2011, 25(6):69-72.
[7]李伏,朱青.混合MapReduce環境下大數據劃分的查詢優化[J].計算機科學與探索,2012,6 (10):877-887.
[8]尤川川,張桂剛.一種基于大數據的有效搜索方法[J].計算機科學,2013,40(6):183-186.
[收稿日期]2013-08-12 [責任編輯]菊秋芳
[作者簡介]陳臣(1974-),男,副教授,碩士,研究方向:云計算,大數據,數字圖書館建設。
[文章編號]1005-8214(2015)04-0091-03
[文獻標志碼]A
[中圖分類號]G250.76
猜你喜歡
小太陽畫報(2018年1期)2018-05-14 17:19:25
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
足球周刊(2016年14期)2016-11-02 10:56:23
足球周刊(2016年15期)2016-11-02 10:55:36
足球周刊(2016年10期)2016-10-08 10:54:55
中國衛生(2015年12期)2015-11-10 05:13:38
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
小天使·一年級語數英綜合(2014年8期)2014-06-26 14:42:04
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
