無監督排序學習算法的一致性比較
2016-01-20 01:46:37李純果李海峰
河北大學學報(自然科學版) 2015年2期
李純果,李海峰
(1.河北大學數學與信息科學學院,河北保定 071002;2.河北大學黨委組織部,河北保定 071002)
無監督排序學習算法的一致性比較
李純果1,李海峰2
(1.河北大學數學與信息科學學院,河北保定071002;2.河北大學黨委組織部,河北保定071002)
摘要:對于無監督的排序學習算法來說,排序結果的評價指標是非常具有挑戰性的問題.從一致性的角度,比較了4種比較典型的無監督排序學習方法,并在機器學習標準數據庫中進行實驗比較分析.結果顯示,RPC這種非線性的無監督排序融合方法產生的排序結果有最小的Kendall距離和Spearman簡捷距離,體現了RPC在無監督排序方法上的優越性.
關鍵詞:啟發式排序;學習式排序;排序一致性;RPC
DOI:10.3969/j.issn.1000-1565.2015.02.013
中圖分類號:TP181
文獻標志碼:志碼:A
文章編號:編號:1000-1565(2015)02-0182-06
Abstract:Unsupervised ranking has a big challenge that there is no standard metric to measure the ranking results. This paper tries to propose a comparison scheme for unsupervised ranking based on ranking consensus. Some metrics used in supervised ranking can be used here to measure unsupervised ranking consensus. However, these metrics are taken between ranking lists and attributes, rather than ranking lists and ranking labels. Experimental results on UCI datasets show that RPC, which is one kind of unsupervised ranking aggregation method, has the minimum Kendall Distance and Spearman Footrule Distance than the other representative unsupervised ranking methods.
收稿日期:2014-09-12
基金項目:河北省自然科學基金資助項目(F2013201060)
Comparison analysis on ranking consensus
LI Chunguo1, LI Haifeng2
(1. College of Mathematics and Information Science, Hebei University, Baoding 071002, China;
2. Department of Party Committee Organization, Hebei University, Baoding 071002, China)
Key words: heuristic ranking;learning to rank;ranking consensus;RPC
第一作者:李純果(1981-),女,河北邯鄲人,河北大學講師,主要從事模式識別理論基礎與應用、機器學習等研究.
E-mail:lichunguo@cmc.hbu.cn
排序問題是實際應用中的一個很基礎的問題,比如說信息檢索中的網頁搜索問題[1-2].一般地,排序問題分為啟發式排序和學習式排序.啟發式排序是根據給定排序對象在多個屬性上的觀測值,基于直觀或經驗構造一種融合多屬性觀測值的方法,得到每個排序對象的評分.學習式排序是把機器學習的方法應用到排序中,通過優化一定的規則,得到每個排序對象的排序位置.對于具有連接結構的排序對象來說,基于啟發式的排序方法不再適用,而對于當今大數據的局勢,更需要學習式的排序方法.
由于機器學習方法是根據一定的學習目標來進行排序,對象的排序順序根據學習目標不同而不同.對于監督學習來說,NDCG(normalized discount cumulative gain)和MAP(mean average precision)是應用的2種比較多的排序優化目標函數.在文本檢索中,NDCG是歸一化的累計折扣相關值[3],當NDCG達到最大時,會給出與檢索文本排序最相關的網頁順序;而MAP計算的是網頁評分對檢索文本的平均值[4]. 對于沒有真實的排序對象順序的時候,也就是無監督學習排序,NDCG和MAP都不能用做優化排序目標進行學習.無監督學習排序算法面臨很多挑戰,由于沒有真實排序順序作為參照,因而最重要的挑戰就是“如何保證所得到的排序順序的合理性”.例如,在大學排名中,根據多個選定指標的統計數據,Times,QS,ARWU,Webometrics的做法基本上都是線性加權和的方式,即給每個指標賦予一定權重值,然后計算把多指標觀測數據計算加權算術平均,得到平均分值.然而這種加權算術平均的方式往往會根據權重的不同改變排序對象的排序順序,權重值是根據不同的專家給定,就會存在權重比較不客觀問題.因此,對于無監督的排序方法,需要選擇合理適用的排序目標,或者說是如何選擇評價無監督排序結果的客觀指標.
對于無監督排序結果的評價指標,有些學者提出了用排序一致性的指標來評價,即當沒有真實的排序順序作為參照時,最終得到的排序結果希望與根據各個指標得到的排序結果盡可能的一致.早在最早的排序問題中,例如Borda計數法[5],就是排序結果保持大多數的一致性所提出的.
1一致性衡量方法
假設無監督的排序對象為A={a1,a2,…,an},排序對象在d個屬性V={v1,v2,…,vn}上的觀測結果記為X={x1,x2,…,xn}.對A中的元素進行排序,轉換為對X的n個向量進行排序,即需要根據觀測值,給出ai1≤ai2…≤ain,其中i1,i2,…,in是一組{1,2,…,n}的排列,記為τ.無監督排序的任務就是根據排序對象在d個屬性上的觀測結果,學習到一個最接近于真實存在的排列τ.
無論是監督排序學習方法還是無監督排序學習方法,首先都要確定一個評價排序的量化指標,例如NDCG,MAP,等等.在此指標的指導下,來評價一個排序學習算法的優劣.指標的選取,或者是發現現有指標存在的問題并對其改進,得到新的指標,或者是定義排序指標公理(不證自明的結論)并找到符合所有公理的指標. Kumar曾在2010年就提出了選擇排序指標的5條公理[6].
1)簡單性:容易理解;
2)廣泛的容納性:不僅支持基于分數的排序融合,還支持基于排序的排序融合;
3)普適性:可以退化到普通的度量指標;
4)滿足基本性質:具有尺度不變性,不因標簽改變而改變,三角不等式,等等;
5)與其他度量相關聯:指導排序的方式相似,可以選擇最適合的度量.
并且提出Kendall距離(Kendall tau distance)[7]和Spearman簡捷距離(Spearman’s footrule distance)[8]就符合這5條公理.
根據觀測結果X對對象進行排序,可以直接采用啟發式的排序融合方法,例如基于分值的排序融合,對各屬性賦予權重值,每個對象的得分為對象i在各屬性上的觀測值的加權平均;或者采用基于排序的融合方法,把根據各屬性值得到的排序表進行融合.但是這些融合方式都是啟發式的,在無監督排序學習中,由于沒有排序標簽可以參考,沒有辦法衡量哪一種排序結果的可信度更高一些,所以需要尋求一定的衡量方法.此時可以考慮用一致性的衡量:如果排序的結果與根據屬性值排序的結果都一致,則是一種理想的排序結果;如果兩者有很大差異,說明排序算法沒有遵循一致性的排序宗旨,導致排序結果不具有可信性.
1.1 NDCG
DCG(discounted cumulative gain)[3-4]是一種衡量排序效果的度量,常用來測量網絡搜索引擎算法的有效性.對于一個給定的搜索結果,DCG通過搜索結果對輸入關鍵詞的相關性的排序,并根據排序位置對相關性打折(Discounted),計算該搜索結果的累積增益,稱之為累積折扣增益.給定{1,2,…,n}的一個排列τ,其DCG定義為
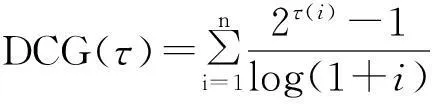
其中,τ(i)是第i個元素在τ中的排列位置.由于有的數據集大小的不同,所以可能導致搜索引擎的DCG有所不同.為了避免由于測試數據集而產生的不同的DCG,定義了NDCG:
其中,Zn是歸一化常數.NDCG使得搜索引擎的測試效果不隨測試集的大小而改變.
在信息檢索中,NDCG把相關分為多個級別,高度相關的文章比部分相關的文檔更有價值,其在評價中應該賦予更大的權值[9].文檔在序列中的位置越靠后,這個文檔的價值越小,從用戶的角度考慮,由于時間、精力等原因,用戶可能根本不會去看這些文檔.NDCG還可以用來衡量排序結果的一致性.例如,按照每個屬性值,可以對排序對象做一個排列順序,而對于每個排序對象的總評分值(score label)得到的排序結果,相對于每個屬性值的排序結果,可以得到一個一致性檢測.比較2個搜索引擎在同一個搜索集上的NDCG的大小,可以確定哪一個搜索引擎給排序對象的評分值更遵從一致性的原則.
1.2 SRCC
斯皮爾曼相關系數(Spearman rank correlation coefficients, 簡稱SRCC)是衡量2個變量的依賴性的非參數指標.2個變量x和y的SRCC定義為
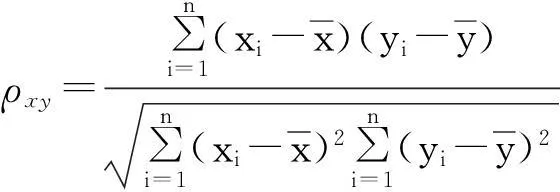
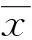

其中,di是第i個元素在x和y的排列中的位置差.SRCC利用單調方程評價2個統計變量的相關性,如果數據沒有重復值,并且當2個變量完全單調相關時,SRCC為+1或-1.根據這個特性,SRCC可以用來衡量排序結果是否與屬性的排序結果的一致性.如果排序對象根據屬性值得到的排序結果與根據屬性值排序的結果是完全一樣的,說明排序算法可以得到與屬性值一致的排序結果,SRCC的絕對值接近于1.排序算法的SRCC越接近于1,說明排序結果與屬性值排序結果越一致.
1.3 Kendall距離
Kendall距離(Kendall tau distance)是指2個排序表中2個對象的排序位置不同的對象對的個數[7].如果2個排序表完全一致,Kendall距離達到最小為零;而2個排序表中的對象的位置越混亂,Kendall距離越大.因此,Kendall距離可以用來衡量排序的一致性,作為無監督排序結果評價標準之一.給定2個{1,2,…,n}的排列τ和κ,τ和κ的Kendall距離定義為
K(τ,κ)=|{(i,j):i
其中,τ(i)和κ(i)分別是第i個排序對象在隊列τ和κ中的排列位置.
1.4 Spearman簡捷距離
Spearman簡捷距離(Spearman’s footrule distance)計算了第i個排序對象在2個排列中的位置的絕對距離之和,定義為[8]
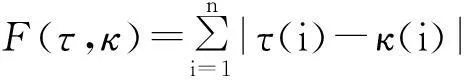
其中,τ(i)和κ(i)分別是第i個排序對象在隊列τ和κ中的排列位置.
2排序方法比較
針對綜合評價問題,基于一維流形的思想,Li等人[10]基于一維流形綜合評價方法,提出了排序主曲線(ranking principal curves,RPC)無監督排序模型.該模型通過非線性融合排序對象在排序觀測指標上的觀測值,給出每個排序對象一個綜合評分結果.一維流形綜合評價方法是主成分分析方法(principal component analysis, PCA)的非線性推廣(圖1),根據研究對象的各評價指標的多屬性觀測數據,用機器學習的方法確定穿過數據中心的一條曲線,即為面向排序的一維流形.根據研究對象的觀測數據在一維流形上的投影點可以確定一個索引值為研究對象的綜合評價分值,根據此分值可以確定研究對象的綜合排名.RPC的學習排序過程如圖2所示.
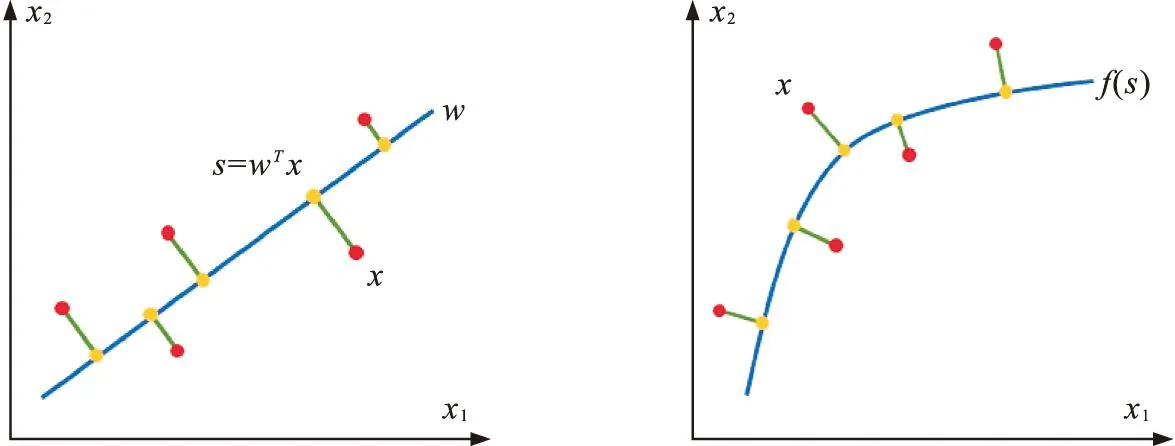
圖1 PCA與RPC排序方法Fig.1 Ranking methods of PCA and RPC
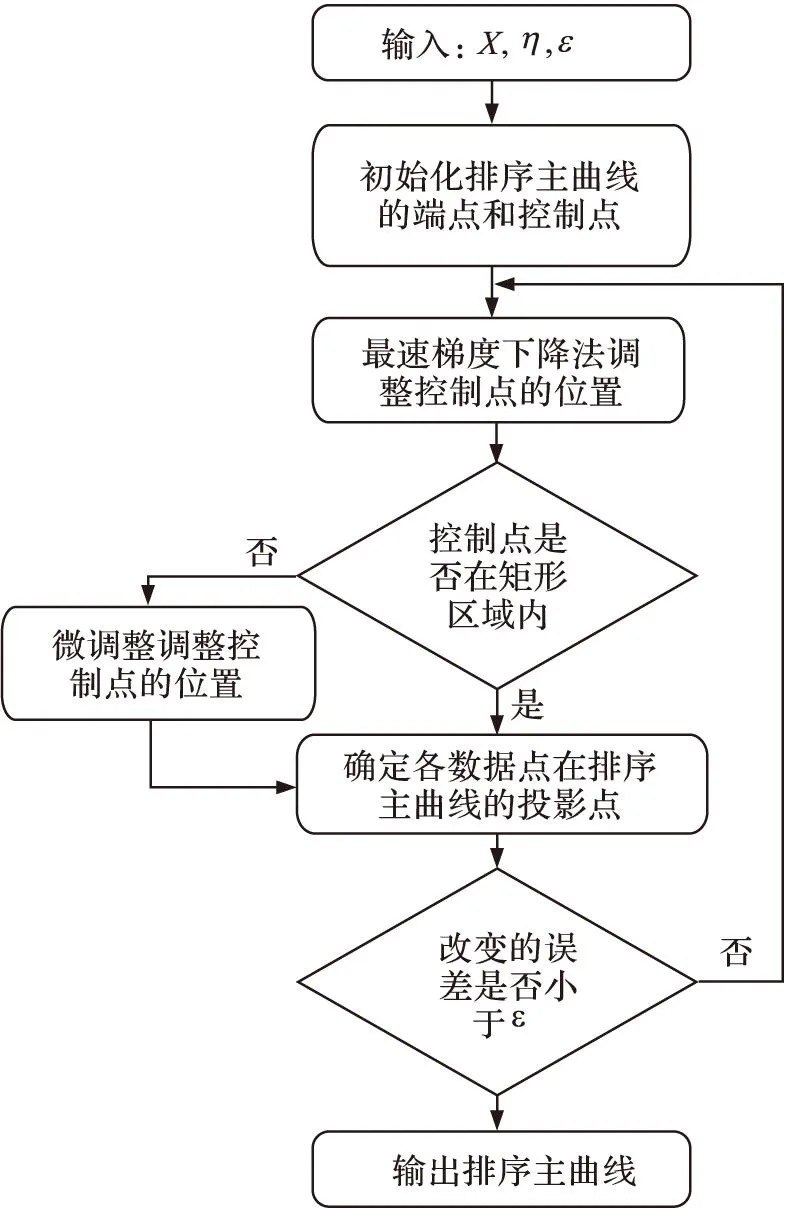
圖2 RPC學習流程 Fig.2 Learning scheme of RPC
雖然KPCA(kernel principal curve analysis)也是PCA的非線性推廣[11],但KPCA是把原數據點映射到高維數據空間,在高維空間中進行PCA操作,所以KPCA的實質仍是PCA,而主曲線才是真正的從學習動機上非線性推廣了PCA,即從線性x=λμ+μ0到非線性x=f(λ)+μ0的推廣,其中,μ0是數據的中心點,μ是PCA第一主成分方向,λ是在主成分上的值,f是非線性函數向量.本文把RPC得到的排序結果與KPCA和PCA的排序結果進行了一致性比較.
排序融合是另一種應用很廣泛的無監督排序方式[5].通常情況下,這種排序方式都是啟發式的融合,例如Borda計數法,Condorcet方法,Kemeny方法.這些方法通常應用在選舉中,使得選舉結果符合大多數人的排序結果,也是一種一致性的排序融合.本文采用了基于序列的排序融合方法(RankAgg),每個屬性都有相同的排序權重,根據每個屬性值對排序對象排序,然后取位置的中間值作為排序對象的最終得分,并依據得分進行排名.
3一致性比較
首先,比較了PCA,KPCA,RankAgg和RPC 4種方法的Kendall距離和Spearman簡捷距離,實驗結果如圖3所示.由于無監督排序方法沒有排序標簽,通過UCI數據庫中的回歸數據,把回歸分值作為每條記錄的綜合評價分值.將4種方法產生的排序結果與評價分值的結果做對比,來評價RPC方法在無監督排序上的效果.

圖3 4種無監督排序方法在Kendall距離和Spearman簡捷距離上的比較Fig.3 Comparisons on Kendall Distances and Spearman Footrule Distances of four unsupervised methods
從圖3可以看出,在選擇的1個人工數據集和4個UCI數據集上,KPCA幾乎在所有數據集上的排序結果與目標排序標簽的Kendall距離和Spearman距離最大,這也從側面說明了Kernel技術把觀測樣本從原數據空間映射到高維空間,映射不具有保序性.雖然KPCA可以實現非線性降維,但是不適用于排序的非線性降維,這是因為低維到高維的映射沒有保持數據間的序關系.對于其他的非線性降維,類似于LPP,Isomap,LEE等方法,都存在類似的問題.
PCA與基于MedianAgg的RankAgg方法具有類似的排序融合方式.從排序融合的角度看,PCA是學習融合權重的分值融合方法,而RankAgg是基于序列的融合方法.2類方法都是線性融合方法,對于隱含數據結構為非線性的數據不適用.由于數據本身的數據結構未知,所以不能貿然選擇線性或非線性的排序融合方法.如果排序的應用對象是網絡搜索和信息檢索,排序對象的規模較大,簡單的排序融合就比較有效率,因為要求搜索引擎需要在可容忍的時間內搜索結果.而本文討論的排序對象是靜態的,排序對象的個數和排序指標都是確定的,所以,不同于網絡搜索和信息檢索對排序速度的要求,這里討論的排序要求盡可能的尊重事實.

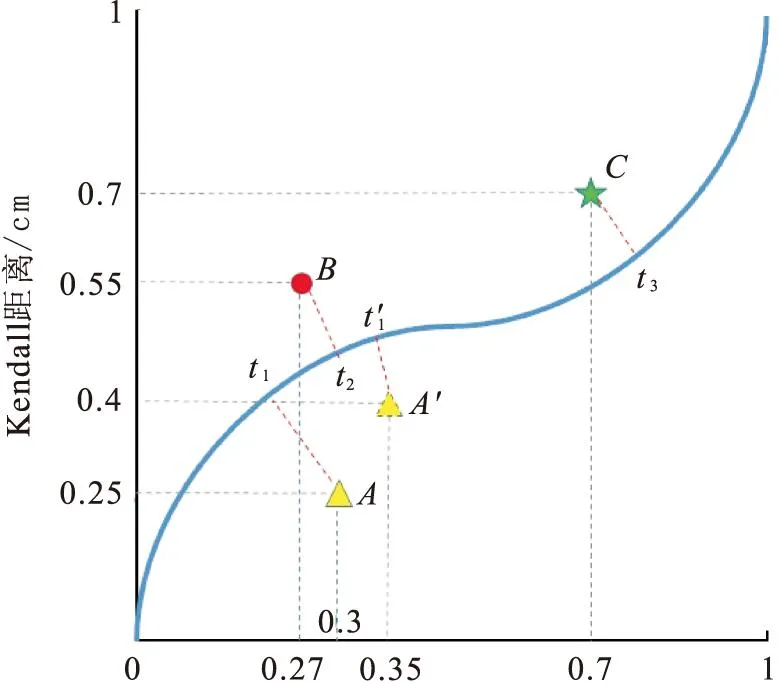
Spearman距離/cm圖4 RPC可以反映觀測值的微小區別Fig.4 RPC can detect the minor differences in numerical observations
4總結
對于排序學習,監督的學習方法通常用NDCG,MAP等指標來判別算法排序的結果與目標排序標簽的是否一致.而對于非監督的排序學習算法的評價,一直是一個很有爭議的問題.已經有相關學者提出,可以通過排序融合的方式融合屬性值或屬性值的排序序列,得到一個綜合的排序結果.排序算法在信息檢索、網絡搜索引擎方面已經有了飛速的發展.
主要針對無監督的排序方法,討論了4種排序方法對于排序一致性的比較.RPC的非線性排序融合方法不僅能處理線性數據結構問題,也能處理非線性結構問題,從而在Kendall距離和Spearman簡捷距離上體現了一定的優勢.但是,RPC的排序融合方法潛在的要求是綜合評價分值與各屬性值成單調關系(單調遞增或單調遞減),這也是大多數排序問題所滿足的條件,RPC正是充分利用了這個排序問題的先驗知識而設計的非線性排序融合方法.對于不滿足這個先驗知識的排序問題,RPC可以做相應的調整,仍然利用RPC的學習架構來進行排序融合,具體的操作是未來的工作之一.未來的工作還包括通過敏感性分析來進行無監督排序學習的屬性選擇(feature selection)問題.
參考文獻:
[1]DWORKC,KUMAR R, NAOR M, et al.Rank aggregation methods for the web[Z]. Proceedings of 10th International Conference on World Wide Web,Hong Kong, 2001.
[2]LI Hang. A short introduction to learning to rank [J].IEICE Transactions on Information Systems, 2011, E94-D(10):1-9.
[3]VOLKOVS M N, ZENEL R S. New learning methods for supervised and unsupervised preference aggregation [J]. Journal of Machine Learning Research, 2014, 15:1135-1176.
[4]PEDRONETTE D C G,TORRES R do S,CALUMBY R T. Using contextual spaces for image re-ranking and rank aggregation[J]. Multimedia Tools and Applications, 2014, 69(3): 689-716.
[5]LIN Shili. Rank aggregation methods [J]. Wiley Interdisciplinary Reviews: Computational Statistics, 2010, 2(5):555-570.
[6]KUMAR R, VASSILVITSKII S. Generalized distances between rankings [Z]. Proceedings of International Conference on World Wide Web,Raleigh,2010.
[7]KENDALL M. A new measure of rank correlation [J]. Biometrika, 1938, 30:81-89.
[8]CONTRERAS I. Emphasizing the rank positions in a distance-based aggregation procedure[J]. Decision Support Systems, 2011, 51(1): 240-245.
[9]BAEZA-YATES R, RIBEIRO-BETO B.Modern information retrieval [M].New York:ACM Press,1999.
[10]LI Chunguo,MEI Xing,HU Baogang.Unsupervised ranking on multi-attribute objects based on principal curves[J/OL].[2014-02-19].http://arxiv.org/pdf/1402.4542.pdf.
[11]BISHOP C. Pattern recognition and machine learning [M]. New York: Springer, 2006.
(責任編輯:孟素蘭)
