反向對抗邏輯范式的創立與證實
——人工語法PDP對抗邏輯的改進*
2016-02-01 11:02:48張劍心李瑩麗劉電芝
心理學報 2016年9期
關鍵詞:實驗
張劍心 湯 旦 李瑩麗 劉電芝
(蘇州大學教育學院, 蘇州 215123)
1 引言
1.1 內隱學習對抗邏輯范式
對抗邏輯把意識定義為能被外顯策略控制的受控反應, 把無意識定義為不受外顯策略控制的自動反應, 兩種反應在特殊測量任務中對抗競爭(Jacoby, Woloshyn, & Kelley, 1989)。Jacoby (1991)根據對抗邏輯, 在再認任務中提出了加工分離程序即PDP, 包括包含任務(inclusion test)和排除任務(exclusion test):包含任務要求被試用先前學過的詞完成任務, 如果有意識回憶失敗也可用其它任何信息, 即被試可以利用有意識提取和無意識熟悉性兩種加工來完成任務; 排除任務要求被試用首先想到的但又不能是先前學過的詞來完成任務, 如果被試錯誤地選擇了學過的詞, 那么這些詞就是記憶的無意識成分——正是無意識熟悉性導致其不受意識控制。包含任務中受控反應(即有意識提取)和自動反應(即無意識熟悉性)的關系是Inclusion=C + (1 ?C)A, C表示controlled, A表示automatic; 排除任務中受控反應和自動反應的關系是Exclusion=(1 ?C)A 。那么受控反應可以用包含任務減去排除任務而得到C=Inclusion – Exclusion=〔C + (1 ? C)A〕?(1 ? C)A; 自動反應則由排除任務和受控反應的值獲得A=Exclusion / (1 ? C)。Jacoby通過這兩個任務成功分離了再認的意識成分和無意識成分, 此后PDP成為內隱記憶的主要分析范式之一。在PDP對抗邏輯中意識=外顯=受控反應, 而無意識=內隱=自動反應, 下文將采用這些等同性概念進行論述, 不再每次都加以說明。
而內隱學習經典范式之一的人工語法學習在2000年之前主要采用任務分離邏輯。Reingold和Merikle(1988)認為, 為了測量到純凈的意識和無意識, 需要設置兩種對照的測量任務即直接測量和間接測量。直接測量對意識更敏感, 而間接測量對無意識更敏感。人工語法范式采用主觀報告直接測量被試掌握語法規則的程度, 詢問被試是否發現任何構成字符串的規則; 采用對新字符串是否符合語法的判斷任務來間接測量對語法規則的掌握程度, 不要求說出語法規則本身, 只要求判斷新字符串是否合法。如果兩種測量成績差異顯著, 就證明意識成分和無意識成分具有相對獨立性。可見分離邏輯存在明顯缺陷:其邏輯必須建立在直接測量和間接測量結果的分離上, 但卻無法證明直接測量就是意識成分, 間接測量就是無意識成分, 更無法證明兩者差值是意識還是無意識(Jiménez, Méndez, & Cleeremans,1996)。
為了克服分離邏輯的缺陷, Higham, Vokey和Prithard (2000)首次成功地將PDP對抗邏輯引入人工語法學習(首次引入者是Dienes, Altmann, Kwan, &Goode, 1995, 但在檢測自動反應上并不成功, 見下一段), 認為不管是直接測量還是間接測量, 都是受控反應和自動反應共同作用的結果, 任務分離邏輯無法精確區分這兩種過程。由于內隱學習和內隱記憶的相似性, 內隱學習應該符合雙加工模型(Yonelinas, 2002), 并且已有大量研究證實內隱學習確實存在自動反應(Cohen & Poldrack, 2008; Soetens,Melis, & Notebaert, 2004), 因此PDP對抗邏輯可以應用到人工語法內隱學習。Higham等(2000)借鑒PDP對抗邏輯, 通過意識和無意識的“協同”與“對抗”關系來考察受控反應和自動反應。(1)其實驗設計是:采用被試間設計, 設置了意識成分和無意識成分的不同關系條件, 稱之為“相容條件”和“對抗條件”。實驗材料使用兩種不同的限定狀態語法A和B, 以及非法字符串U。(2)實驗程序是:學習階段要求被試記憶并排呈現的兩個字符串, 5秒后字符串消失, 被試立即把記憶過的字符串分別寫在標有“詞單A”和“詞單B”的欄內。然后再呈現兩個新字符串, 依次類推。測量階段指導語告訴被試有兩個不同的語法規則A和B用來生成兩個詞單中的字符串, 但不告訴語法規則的細節。要求相容條件組將任何認為符合語法A或語法B的新字符串評為合法G; 將不符合兩種語法的非法字符串U評為不合法NG; 要求對抗條件組僅將語法A評為合法,而將語法B和非法字符串U都評為不合法。(3)實驗結果發現:語法B的接受率在相容條件組(0.65)比在對抗條件組(0.51)大, 證明被試能明確地否定由語法B產生的新字符串來控制其任務, 這就是受控反應的證據。而對抗條件組以非法字符串U誤判為合法的概率作為基線水平, 對抗條件組語法B的接受率(0.51)比非法字符串U的接受率(0.39)更大,這就是自動反應的證據:盡管被試的受控加工試圖避免肯定語法B的新字符串, 但是較之非法字符串U, 被試還是更可能無意識地自動接受語法B的新字符串。
但是Dienes等(1995)在人工語法學習中首次采用了相容條件和對抗條件, 發現了受控反應的證據,卻沒有發現自動反應的證據。在該實驗中語法B(或A)在對抗條件組的接受率在數值上反而小于非法字符串U的接受率。Wan, Dienes和Fu (2008)使用了Dienes等(1995)的實驗程序探索主觀熟悉性能否受控, 在其兩個實驗中都得到了同樣結果:只發現受控反應, 沒有自動反應; 在實驗二中, 還發現被試可以通過主觀熟悉性來完美分辨語法A和B,主觀熟悉性對外顯任務要求非常敏感并且對內隱知識扮演著策略控制的角色——測量階段需要被拒絕的語法B在學習階段學習了兩次, 需要被肯定的目標語法A只學習了一次, 被試卻仍然可以按照外顯任務要求正確選擇語法A且熟悉性更高, 而正確拒絕語法B且熟悉性更低, 可見其熟悉性是主觀的, 并不服從客觀的重復次數。Norman, Price和Jones(2011)使用了同樣的范式, 但測量階段隨機要求被試判斷新字符串是否屬于A或者是否屬于B, 這種隨機設置增加了任務難度, 讓被試的判斷標準必須在兩套語法間切換, 但結果發現被試仍能正確分辨出兩套語法, 沒有出現自動反應。
內隱序列學習是內隱學習的另一個經典范式,要求對陸續呈現的刺激位置進行按鍵反應, 刺激位置遵循某套序列規則, 但是不告知被試。對抗邏輯范式在內隱序列學習中的應用卻很成功:Destrebecqz和Cleeremans (2001)在內隱序列學習的學習階段使用兩套不同的序列, 測量階段使用了生成任務(包含任務和排除任務), 發現被試能夠控制使用所學的兩套序列。Mong, McCabe和Clegg (2012)使用類似的范式, 但測量階段是再認任務, 設置了相容條件和對抗條件, 結果發現了受控反應和自動反應的證據。相比人工語法學習, 內隱序列學習中采用對抗邏輯范式能輕易找到自動反應, 這可能是因為內隱序列學習是對序列的重復學習, 規則相對簡單導致習得程度較高, 而測量階段仍然是針對學過的舊序列片段, 則被試區分序列片段和隨機片段較容易,對隨機片段的接受率不會太高。而人工語法學習獲得的是需要做出判斷推理的內隱語法規則:學習階段通過對一部分合法字符串的學習, 被試只內隱習得了語法的部分規則, 測量階段時新字符串是否合法必須由舊字符串的規則推導出來, 則非法字符串U可能因推導過程不完備或不準確而被錯誤接受,造成對非法字符串U的高接受率而掩蓋了自動反應。
1.2 人工語法對抗邏輯范式的缺陷
正因對抗邏輯范式難以捕捉到人工語法的自動反應, 無法通過客觀測量分離出內隱成分, 所以在人工語法學習中很少應用。本研究分析兩個具有開創性和代表性的實驗即Higham等(2000)與Dienes等(1995)的矛盾, 試圖找到可能的原因。他們的實驗程序有5點不同, 可能導致了實驗結果不一致。
第一, 學習階段對兩套語法的記憶方式不同。
Dienes等(1995)的學習階段是先記憶語法A的詞單, 再記憶語法B的詞單, 對每套語法都是連貫學習, 各自內部的字符串能夠互相參照比對, 可能習得了深層語法結構, 即產生了規則學習(Pothos,2005)。這樣在學習階段就可能通過外顯/內隱辨別把兩套語法充分辨別開來, 在對抗條件組更易分辨新字符串符合哪套語法, 而按外顯要求完成任務,就很難產生自動反應。因此這種結果雖然被對抗邏輯認為是受控反應, 但事實上可能是與外顯任務要求協同的特殊內隱知識(Kiefer, 2012; Horga & Maia,2012)。反之, Higham等(2000)的實驗程序讓兩套語法同時記憶, 打亂了同一套語法字符串的連貫學習,則在學習階段可能不能夠把兩套語法充分辨別開來, 在對抗條件組內隱知識與外顯任務要求無法協同而產生了真實的對抗。而且Higham等(2000)同一時間出現的兩個字符串并不是匹配出現的, 長短不一致, 難以提供兩套字符串差異的結構線索, 被試可能無法充分習得各自的深層語法結構, 即只產生了熟悉性學習(Nosofsky, 1988; Nosofsky & Zaki, 1998),甚至把語法A和B當做是一套聯合語法A*B來學習和存儲(未來應該研究這種可能性)。這導致在對抗條件組測量階段被試根本區分不出新字符串是屬于語法A或B, 既無法也無需拒絕語法B, 因為語法B可能根本不存在, 只存在一個聯合語法A*B!或者至少被試無法準確辨別出屬于B的新字符串, 所以更易受形式相似性影響, 覺得只要與語法A相似,就傾向于判斷為G。
上述分析僅僅從兩套語法A和B的學習程度和形式相似性來分析兩個研究的差異, 并未涉及到非法字符串U的影響。
第二, 非法字符串U的設計有差異, 導致對非法U的拒絕難易不同。
Higham等(2000)對Dienes等(1995)的實驗結果推測是:其實驗保證了非法字符串U與兩個語法A和B的字符串非常相似, 而Higham等(2000)的實驗沒有做這樣的限制, 非法字符串和合法字符串有更大的差異, 可能使得拒絕非法字符串更容易, 導致至少部分自動反應來自于被試拒絕古怪字符串的能力。這就可能由于三套字符串之間的形式相似性的差異使得真實的自動反應無法被測量到:如果三組字符串形式相似度都高, 拒絕非法字符串變得困難, 基線水平上升就掩蓋了自動效應; 如果合法字符串A和B之間形式相似度高, 而非法字符串U與之相似度相對較低, 則非法字符串U就更易被拒絕, 而與語法A更相似的語法B自然就更易被接受, 并不是真實內隱知識導致的自動反應。因此Redington(2000)對Higham等(2000)的對抗邏輯范式進行了尖銳批評:假如被試只學習語法A, 但測量階段既有語法B又有語法A, 還有非法字符U。由于語法B在形式上和語法A很相似, 比起非法字符串U被試會更容易接受語法B, 這樣就檢測到了自動反應的證據。但邏輯矛盾是, 被試根本沒有學過語法B,談何自動反應呢?這個質疑非常有力。Higham和Vokey(2000)回應Redington說其自動反應并不虛假, 至少是相似性導致的熟悉性產生的真實自動反應, 類似內隱記憶中的基于熟悉性產生的自動反應。但本研究并不認同其解釋, 筆者認為:Higham等(2000)檢測到的自動反應僅僅是因為沒有在學習階段把A和B辨別開來而已, 被試從自動和受控層面都把語法B和A看做是同一套聯合語法A*B來學習和存儲。因此在對抗條件組, 將語法B自動判定為合法正是遵從外顯任務要求的受控反應!其認知過程并沒有產生任何對抗, 談何自動反應呢?
Tunney和Shanks (2003) 則認為對抗邏輯范式得到的數據不能顯示出受控反應和自動反應的二元加工, 而完全可以被一元的熟悉性加工所解釋。他們使用了簡單反饋網絡(Simple Recurrent Network—SRN)對Higham等(2000)實驗數據做了擬合, 結果顯示受控反應和自動反應的數據不能讓SRN區分出是雙加工系統還是單系統, 而可以由熟悉性的分辨系統產生。Vokey和Higham (2004) 回答說Tunney和Shanks (2003)的模型不能完全解釋Higham等(2000)所獲得的分離, 所以使用了自動聯結網絡模型(auto associative network model)發現受控反應和自動反應的數據只能由雙加工系統獲得。但是Vokey和Higham (2004)的模型只是一種可能性, 不能證明Tunney和Shanks (2003)的模型就是錯的——因為其模型同樣能與實驗數據完美吻合。也就是說Vokey和Higham (2004)只是證明了在自動聯結網絡模型中, 實驗數據只符合雙加工系統; 但不能否定Tunney和Shanks (2003)在簡單反饋網絡模型中證明實驗數據可以由單系統產生, 因為Vokey和Higham (2004)沒有證明(可能尚無法證明)實驗數據只能采用自動聯結網絡模型來模擬。
上述分析只是從排除非法字符串U的難易來論述兩個實驗的差異, 尚未涉及到形式相似性的差異對測量階段辨別語法A和B的影響, 即內隱辨別加工的差異。
第三, 測量階段的內隱辨別加工不同。
Dienes等(1995)和Higham等(2000)對非法字符串的設計不同, 還可能導致兩者測量階段的內隱辨別加工都產生本質差異。Higham等(2000)的實驗由于非法字符串U與語法A和B差異較大導致任務較容易, 辨別系統可能只在形式層面激活, 只辨別出非法字符串U即可, 而對語法A和語法B不進行深入辨別。而Dienes等(1995)的實驗, 由于三者形式上都相似導致任務很困難, 則可能充分激活內隱辨別系統, 在測量階段對已學習過的語法A和B進行了進一步辨別加工(當然這種辨別加工只能針對記憶中的語法知識), 因此很好地內隱辨別出了語法B。經過了深入辨別的語法B可能仍是內隱知識, 但已能與外顯任務要求協同而被正確拒絕, 是一種不具有自動反應特征的特殊內隱知識。由此還可以推測內隱知識不等于自動加工(Fu, Dienes, & Fu,2010)。
第四, 上述三種因素交互, 導致兩個實驗的學習機制和知識提取機制都不同。
Dienes等(1995)實驗對人工語法的學習和提取的方式正好一致, 都需要掌握兩套語法深層規則并辨別開來, 造成無法檢測到自動反應。而Higham等(2000)實驗對人工語法的學習可能只是基于熟悉性, 或者是對一套聯合語法A*B的規則學習, 兩種可能都導致無法分辨語法A和B; 而提取又正好不需要深入辨別兩套語法, 這就造成了虛假的自動反應。
綜合以上4點, 兩種對抗邏輯范式都有很大缺陷, 研究者們不能解決這個難題, 所以人工語法對抗邏輯范式就一直停留在原地。Johansson (2008)試圖建立新的人工語法對抗邏輯范式來調和兩者矛盾:只使用一套語法回避了形式相似性。要求被試首先記憶一套語法字符串, 接著告知字符串遵循某種規則但沒有細節; 然后要求生成新的合法字符串(包含任務)或者不合法字符串(排除任務), 自動反應的證據被定義為在排除任務中生成了高于隨機水平的合法字符串。但是遺憾的是在尋找受控反應和自動反應方面都失敗了, 因為無論包含任務還是排除任務都處于隨機水平。張潤來和劉電芝(2014)同樣采用一套語法, 測量階段設置了包含任務和排除任務, 包含任務讓被試在4個新字符串(其中只有一個符合已學過的語法)中選出符合學過語法的字符串, 排除任務讓被試在4個新字符串中選出最先想到的卻又不符合學過語法的字符串, 結果發現排除任務中錯誤選擇了合法字符串的概率仍然大于隨機, 成功得到了自動反應。但筆者發現該范式同樣沒有平衡新字符串中合法字符串和非法字符串的形式相似性:其測量階段每個試次有5個新字符串, 其中有一個是新合法字符串, 另外4個非法字符串是將此新合法字符串改動1~4個字母,那么這4個非法字符串與該新合法字符串以及已學過的舊合法字符串相似度不同。包含任務是選出與學過的字符串最相似的新字符串, 被試能通過相似性輕易排除不相似的非法字符串, 成功選擇最相似的新合法字符串或者比較相似的非法字符串, 從而得到虛高的包含任務成績(其計分是完全正確記2分, 選了錯一個字母的非法字符串仍記1.5分, 以此類推)。排除任務是選出與學過的字符串最不相似的新字符串, 被試又能通過相似性輕易排除合法字符串, 成功選擇最不相似的非法字符串, 從而得到虛低的自動反應。兩種任務相減, 就得到虛高的受控反應!因此這種設計不但沒有排除形式相似性,反而是鼓勵了形式相似性發揮作用。另外其排除任務是快任務, 每個試次被試對快速呈現的5個新字符串不易看清, 這又引入了知覺意識的額外變量,得到的自動反應也不純凈。并且該范式只適用于一套語法, 仍沒有解決兩套語法的經典對抗邏輯范式的缺陷。為何非得研究兩套語法的經典對抗邏輯范式呢?(1)現實生活中存在多套規則, 一套語法的實驗生態效度較低; (2)兩套語法的設計能探測到被試排除別的規則, 專門針對某套規則進行學習的抗干擾內隱學習和辨別過程, 這是不同的領域; (3)對兩套語法采用對抗邏輯范式, 還能探測到內隱層面刻意否定某套規則的加工過程, 這能與社會認知中的消極刻板印象如種族、外群體、性別歧視等相聯系。因此研究兩套語法對抗邏輯范式非常必要且有理論和應用價值。
以上論述對Higham等(2000)的質疑還只局限在自動反應的虛假上, 筆者發現其受控反應摻雜了高概率判斷偏向效應, 極有可能也是虛假的。見以下分析。
第五, 測量階段的相容條件組設置不同, 導致兩者的高概率判斷偏向效應不同。
Dienes等(1995)的實驗對抗條件組程序和Higham等(2000)相同, 但是相容條件組卻不一樣。Dienes等(1995)只設置了兩個對抗條件組, 兩組學習階段完全一樣, 都分別連貫學習語法A和B; 但在測量階段組1只需要從60個新字符串中挑出符合規則A的20個新字符串, 而拒絕符合規則B的20個新字符串和20個非法字符串U, 組2則相反只挑出規則B。因此將兩組結合起來看, 對于規則A來說, 組1就是相容條件組, 組2卻是對抗條件組; 對于規則B則相反, 由此可以得到受控反應和自動反應的值。這種設計的好處在于語法A或B在兩組中面臨的判斷概率背景是一樣的, 都是1/3概率判斷為合法, 2/3的概率判斷為不合法, 那么檢驗到的受控反應就很純粹。
Higham等(2000)的實驗則有專門的相容條件組。這就導致同一個新字符串在相容條件組和對抗條件組面臨的判斷概率環境不同。對于語法B, 在相容條件組需要被判定為合法, 由于該組每個新字符串判斷為合法的背景概率是2/3, 被試受此影響,自然更容易把語法B判斷為合法; 在對抗條件組需要被判定為不合法, 該組每個新字符串判斷為不合法的背景概率又是2/3, 被試受此影響, 自然更容易把語法B判斷為不合法。兩組的高概率判斷偏向效應大小相等, 方向相反, 必然造成相容條件組對語法B的接受率虛假偏高, 而對抗條件組對語法B的拒絕率虛假偏高則接受率虛假偏低。受控反應的操作性定義就是檢驗兩組語法B的接受率差異, 那么這種差異必然包含了高概率判斷偏向效應。如何檢測呢?通過語法A或非法U在兩組的接受率差異就可以量化出來。但由于語法A和B形式上同質(相似度較高), 而非法U與語法B形式上不同質(相似度較低), 故應采用語法A在兩組的接受率差異來衡量語法B的高概率判斷偏向效應。Higham等(2000)的實驗數據如下:相容條件組, Bin=0.65,Ain=0.70, Uin=0.34; 對抗條件組, Bop=0.51, Aop=0.645, Uop=0.39, 其研究報告稱Bin和Bop差異顯著(相差0.14)證明檢測到了受控反應。筆者計算高概率判斷偏向效應指標為Pr=(Ain? Aop)/2=(0.70 ?0.645) / 2 ≈ 0.028。再析出Pr效應這種干擾變量, Bin– Pr=0.65 ? 0.028=0.622, Bop+ Pr=0.51 + 0.028=0.538, 兩者相差很小只有0.084, 受控反應接近消失了。可見由于沒有考慮高概率偏向效應, Higham等(2000)的實驗檢驗到的受控反應不純粹, 甚至是虛假的!即在對抗條件組, 被試根本無法按照外顯任務要求正確排除語法B, 這佐證了第一點分析中對于聯合語法A*B的推測。
Dienes等(1995)的實驗只能確證人工語法學習中存在受控反應, 無法確證存在自動反應, 而Higham等(2000)的實驗得到的自動反應和受控反應都極有可能是虛假的。那么人工語法學習是否是內隱學習, 或者至少是否存在內隱成分, 就大大存疑了!并且無法為進一步研究各種學習機制的意識特征提供量化指標, 如片段學習、熟悉性學習和規則學習各自對內隱/外顯成分的貢獻量。因此本研究試圖彌補其缺陷。
1.3 本研究提出反向對抗邏輯范式
針對以上缺陷, 本研究新設計了反向對抗邏輯范式。完全采用Dienes等(1995)的實驗材料, 使用兩套語法A和B以及非法字符串U, 三者形式上都很相似。把語法A和“YES”標簽綁定, 讓語法A生成合法“詞單G”; 把語法B和“NO”標簽綁定, 讓語法B生成“詞單NG”, 它雖然也是合法, 但通過指導語讓被試在學習階段認為它是不合法“NG”。這樣被試內隱習得語法A并認為它合法; 內隱習得語法B但認為它不合法。然后測量階段設計相容條件組, 要求把符合“詞單G”的新字符串判斷為合法“G”; 把和“詞單NG”相像的新字符串判斷為不合法“NG”。而對抗條件組則要求把符合“詞單G”的新字符串判斷為合法“G”; 并把符合“詞單NG”的新字符串也判斷為合法“G”, 這就和學習階段把“詞單NG”標定為不合法“NG”的內隱學習產生了對抗。參照對抗邏輯的計算方式, 就能得到反向對抗邏輯范式的受控反應和自動反應(詳見2.5實驗結果)。
由于語法B在學習階段是被當做非法字符串NG學習的, 那么在對抗條件組中, 外顯任務要求把語法B判斷為合法, 而語法B在形式上和語法A相似, 如果被試的判斷只是出于形式相似性, 那么應該能夠很準確地把語法B判斷為合法; 如果結果顯示被試仍然將其判斷為不合法, 那只能是不受控的自動反應在起作用。而真正的非法字符串U, 在形式上與語法A和B都相似, 如果認為把語法B判斷為不合法是因為它和真正非法字符串U相似,那么對語法A也應該有同樣的效應, 即把語法B和A判斷為不合法的概率應該相等; 如果語法B判斷為不合法的概率顯著大于語法A, 就表明語法B存在自動反應。由此可見, 如果反向對抗邏輯得到自動反應, 就完全排除了形式相似性的影響。Redington (2000)對Higham等(2000)對抗邏輯實驗的尖銳批評, 對于本研究的反向對抗邏輯實驗, 完全失效。
本研究幾乎完全采用Dienes等(1995)的實驗材料和實驗程序, 所以對兩套語法的學習程度和辨別程度與其實驗一致。但有三個改變:一是把正向對抗邏輯變成了反向對抗邏輯。Dienes等(1995)的實驗對語法B先肯定學習后否定判斷, 產生了對抗,沒有發現自動反應, 可能是對于內隱的肯定知識,外顯具有很強的控制力, 外顯否定更容易。本研究對語法B先否定學習后肯定判斷, 也產生了對抗,但是內隱否定知識可能更深刻而更不易受控, 對其做外顯肯定判斷很難, 或許就能測量到自動反應。二是增加了對學過語法A和B的舊字符串進行再認辨別和訂正, 被試對兩套語法的學習和辨別程度應該比Dienes等(1995)的還要高, 那么如果本實驗發現了自動反應的證據, 就證明反向對抗邏輯可以不受辨別力的影響。三是測量階段采用Higham等(2000)的相容條件組和對抗條件組, 因為更容易設置反向對抗程序; 但是使用的新字符串采用的是Dienes等(1995)嚴格的實驗材料。
可見如果實驗結果理想, 能測量到受控反應和自動反應, 就證明反向對抗邏輯范式能夠不受形式相似性和辨別力影響, 有效地分離出受控反應和自動反應。這種范式既能適用于Dienes等(1995)的嚴格實驗材料, 又能解決Higham等(2000)范式的缺陷, 是對抗邏輯范式的改進版。
因此本研究假設:(1)外顯否定標簽NG (no grammer)可以和語法B綁定學習, 使被試內隱習得否定標簽NG+語法B。(2)反向對抗邏輯可以不受語法A和B以及非法字符串U三者之間的形式相似性和被試辨別力影響, 有效地檢測到受控反應和自動反應。下面將通過實驗創立反向對抗邏輯范式來驗證假設。
2 實驗方法
2.1 被試
45個蘇州大學本科生或研究生, 男生18人,女生27人, 平均年齡22.7,SD=1.6, 隨機分配20人為相容條件組, 25人為對抗條件組。
2.2 實驗材料
和Dienes等(1995)的實驗材料完全一樣。由圖1的兩套人工語法A和B生成字符串各52個, 語法A作為“詞單G”, 語法B作為“詞單NG”。其中各有32個用在學習階段, 各有20個用在測量階段。非法字符串U有20個, 只用在測量階段, 并保證非法字符串U與語法AB三者在形式上都很相似。
2.3 實驗設計和程序
采用單因素(測量階段:對抗條件和相容條件)被試間設計, 分為兩個組:對抗條件組和相容條件組。所有被試都收到固定順序排列的5張試卷, 并被告知測量記憶和辨別能力, 必須按照主試的現場指導語一步步作答。
首先, 被試只能看標有“詞單G”的試卷1, 需努力記憶32個字符串, 并在每個字符串后第一個格子內寫上 “G”, 然后在第二個格子內把這個字符串抄寫一遍。時間8分鐘。這一步目的是把語法A和標簽“G”綁定。由于沒有告知被試字符串符合語法, 只要求記憶, 所以被試進行的是內隱學習。
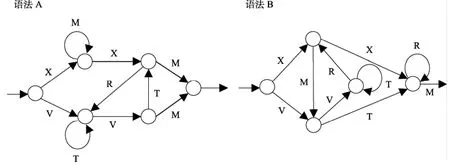
圖1 語法A和B (摘自Dienes et al., 1995)
記憶結束后, 要求只看標有“詞單NG”的試卷2, 同樣有32個字符串。指導語告訴被試, 在試卷1記憶的“詞單G”是通過某套語法生成的有規則的字符串, 標記的“G”表示它們符合語法“grammer”, 但是不告知任何語法A的細節; 試卷2的詞單“NG”則不符合試卷1的語法, 是不合法的“no grammer”。同樣要求被試努力記憶詞單“NG”的字符串, 并在每個字符串后第一個格子內寫上大寫的“NG”表示不合法, 然后在第二個格子內把這個字符串抄寫一遍。時間8分鐘。這一步的目的, 先解釋試卷1的標簽“G”表示合法, 以進一步把“合法G”標簽與語法A綁定; 然后對應的把試卷2的語法B與標簽“不合法NG”綁定起來, 這樣被試不會主動尋找試卷2的“不合法字符串”的語法規則, 保證對試卷2的詞單“NG”也是內隱學習, 從而標簽“不合法NG”就可能和語法B綁定進入內隱學習。
對試卷2記憶結束后是再認辨別任務。被試只能看試卷3, 64個字符串是由試卷1的32個合法字符串和試卷2的32個不合法字符串混合而成, 任務是把它們區分開來。指導語要求在認為合法的字符串后面格子內寫上大寫的“G”, 在不合法的字符串后面格子內寫上大寫的“NG”, 時間6分鐘。再認辨別任務結束后, 要求被試拿出試卷4“正確答案”,在試卷3上訂正作業, 在錯誤答案上畫一條斜線,在此格子內寫上正確答案, 并記憶該字符串屬于“G”還是“NG”, 時間4分鐘。這一步能測量到被試對試卷1和試卷2的字符串的記憶和辨別能力, 并進一步強化二者的合法和不合法的區別。
所有被試都進行上述任務。下面的任務, 則分為對抗條件組和相容條件組。
對抗條件組的被試, 拿到試卷5, 被指導語告知:試卷2“詞單NG”雖然不符合試卷1“詞單G”的語法, 但是符合另一套語法, 所以本質上也是合法的, 前面的任務只是強行貼上“NG”標簽。試卷5有60個字符串, 都是沒有記憶過的, 其中20個是由試卷1“詞單G”的語法生成的新字符串, 需判斷為合法“G”; 20個是試卷2“詞單NG”的語法生成的新字符串, 和詞單“NG”相像, 也需判斷為合法“G”;另外20個是混亂的字符串U, 則需判斷為不合法“NG”。時間7分鐘。
相容條件組的被試, 也拿到同樣的試卷5, 但是指導語不會告知試卷2“詞單NG”是合法的, 而是告知其中有20個是由試卷1“詞單G”的語法生成的新的合法字符串, 請判斷為合法“G”; 有20個是新的不合法字符串, 和試卷2“詞單NG”的不合法字符串相像, 請判斷為不合法“NG”; 另外20個是混亂的字符串U, 也是不合法字符串, 也判斷為不合法“NG”。時間7分鐘。
3 實驗結果
剔除了3個未按要求做的被試的數據。相容條件組和對抗條件組各項數據見表1。
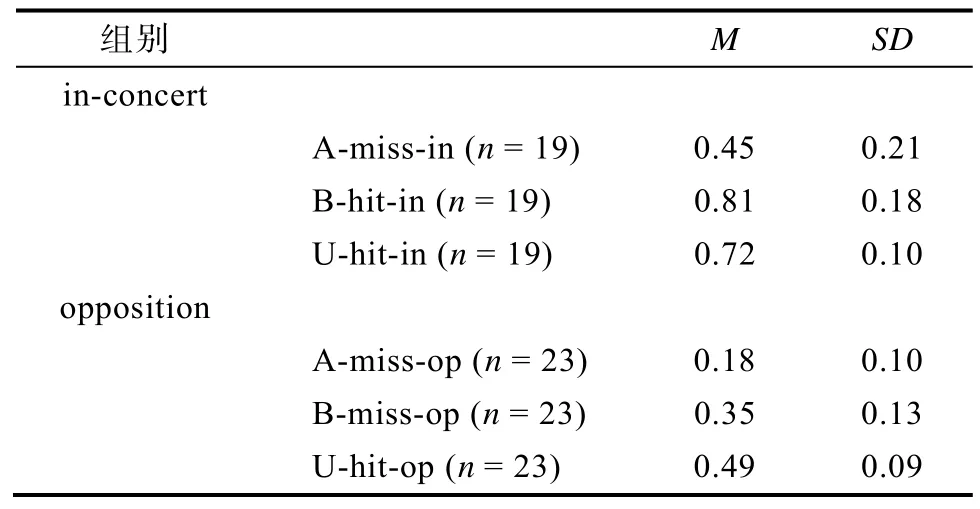
表1 相容條件組和對抗條件組對語法A和B及非法U的判斷結果
3.1 檢驗語法A的學習有效性, 以及標簽“NG”和語法B綁定學習的有效性
比較相容條件組A-miss-in、B-hit-in和U-hit-in,三者方差不齊性不能做ANOVA, 故進行兩兩配對樣本t檢驗, 三者之間都差異顯著, 見表2。B-hit-in顯著大于A-miss-in,t(18)=4.20,p< 0.01,d=1.841;U-hit-in顯著大于A-miss-in,t(18)=4.33,p< 0.01,d=1.642。這兩點證明對語法A的學習是有效的, 被試能很好地拒絕語法B和非法U, 而對語法A作出接受反應, 故把語法A誤判為NG的概率顯著小于把另兩者判斷為NG的概率。

表2 相容條件組對語法A和B及非法U判斷的差異(M ± SD, n=19)
B-hit-in顯著大于U-hit-in,t(18)=1.91,p<0.05,d=0.618, 表明被試已能很好地辨別出語法B, 前面的學習階段是有效的, 已掌握了其深層結構; 且已和否定標簽“NG”成功綁定, 被試學會了拒絕語法B, 所以在測量階段的相容條件組更有把握地拒絕了它, 甚至高于對真正非法字符串U的拒絕。真正非法字符串U之前沒有出現過, 且和語法A相似, 辨別它有更大的難度, 所以拒絕率反而不如語法B。這可在一定程度上證明Dienes等(1995)的實驗沒有發現自動反應, 正是因為被試能很好地辨別出語法B, 既能區分語法B和語法A, 又能區分語法B和非法U。由于本研究測量階段相容條件組, 要求判斷為NG的個數是恒定的40個, 故此結果還顯示語法B部分侵占了對非法U作出拒絕判斷的空間。這種侵占空間的現象正是否定標簽“NG”和語法B綁定后得到有效學習的證據。當然此處的學習可能包括了外顯和內隱知識, 要檢驗出是否存在內隱否定知識, 則還需要分析對抗條件組語法B的自動反應。
3.2 檢驗受控反應的證據
3.2.1 初步檢驗受控反應的證據
相容條件組要求對語法B做拒絕反應, B-hit-in是把語法B正確判斷為NG的擊中率; 對抗條件組要求對語法B做接受反應, B-miss-op是把語法B誤判為NG的誤判率。在相容條件組的B-hit-in和對抗條件組的B-miss-op的差異, 就是受控反應的證據。對二者進行獨立樣本t檢驗, 差異顯著,B-hit-in顯著大于B-miss-op,t(40)=9.57,p< 0.01,d=2.930。證明在對抗條件組, 被試確實可以外顯控制語法B的一部分學習量, 而進行接受判斷。
3.2.2 析出高概率判斷偏向效應
相容條件組有對語法A的誤判率A-miss-in,對抗條件組也有對語法A的誤判率A-miss-op。兩者進行比較, 做獨立樣本t檢驗, A-miss-in顯著大于A-miss-op,t(40)=4.99,p< 0.01,d=1.612。相容條件組對語法A的誤判率高于對抗條件組, 這可能是由合法/不合法的相對概率決定的:相容條件組字符串合法的概率是1/3, 不合法的概率是2/3, 由于不合法的概率更高所以對語法A會產生了更多的拒絕; 而對抗條件組字符串合法的概率是2/3, 不合法的概率是1/3, 由于合法的概率更高所以對語法A會有更多的接受。因此必須將高概率判斷偏向效應作為一個誤差因子。假設高概率不合法NG和高概率合法G二者導致的偏向效應大小一致, 方向相反, 設對于語法A高概率不合法的判斷偏向效應為PrA即概率Probability, 則高概率合法的判斷偏向效應為-PrA。
由于兩組在學習和再認辨別階段的實驗程序完全相同, 故設相容條件組和對抗條件組對語法A的學習量是一樣的, 則兩組對語法A學習的真實缺失量(即未習得量)也是一樣的, 設為LoseA。畢竟對語法A只進行一次的內隱學習基本不可能完全掌握其語法結構, 排除了隨機誤差, 必有真實的缺失。由于A-miss-in由對語法A的學習的真實缺失量LoseA、高概率不合法判斷偏向效應PrA和隨機誤差E1組成; A-miss-op由對語法A學習的真實缺失量LoseA、高概率合法判斷偏向效應-PrA和隨機誤差E2組成, 故有:

同理, 相容條件組有非法U的擊中率U-hit-in;對抗條件組也有非法U的擊中率U-hit-op。兩者進行比較, 做one-way ANOVA檢驗, U-hit-in顯著大于U-hit-op,F(1, 40)=67.15,p< 0.01, η2=0.627,這同樣是高概率判斷偏向效應。則有:
PrU=(U-hit-in-U-hit-op-E) / 2 ≈ (U-hit-in-U-hit-op) / 2=(0.72 ? 0.49) / 2 ≈ 0.12.
可見PrA和PrU在數值上非常接近, 又由于語法A和B與非法U三者都相似, 故可用PrA和PrU的平均數作為高概率判斷偏向效應的近似值:
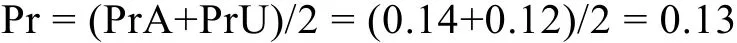
3.2.3 檢驗純粹受控反應的證據
在3.2.1中初步檢驗了受控反應的證據, 但沒有排除高概率判斷偏向效應, 得到的受控反應是不純粹的:相容條件組把語法B判斷為NG的概率B-hit-in顯著高于對抗條件組把語法B判斷為NG的概率B-miss-op, 可能僅僅是受到各自環境的高判斷概率的影響, 而非受控反應。而Higham等(2000)沒有分析和排除高概率判斷偏向效應, 導致其受控反應很可能是虛假的, 這是已有人工語法對抗邏輯范式的另一大缺陷。因此下面將排除高概率判斷偏向效應, 以檢驗出純粹受控反應。
由3.2.2的分析可知相容條件組B-hit-in包含了一個Pr, 對抗條件組B-miss-op包含了一個-Pr, 必須把兩者都剔除, 則在B-hit-in中減去一個Pr, 在B-miss-op中加上一個Pr。由統計法則可知每個數據加上/減去同一常數, 平均數增加/減少此常數而標準差不變。故B-hit-in ? Pr=(0.81 ? 0.13) ± 0.18=0.68 ± 0.18, B-miss-op + Pr=(0.35 + 0.13) ± 0.13=0.48 ± 0.13。對二者進行獨立樣本t檢驗差異顯著,B-hit-in ? Pr顯著大于B-miss-op + Pr,t(40)=4.46,p< 0.01,d=1.274, 兩者相減得到差值為0.20, 這證明在統計上完全排除了高概率判斷偏向效應后,結果顯示對抗條件組的被試確實可以外顯控制一部分學習量, 而對語法B給予接受判斷, 這就是純粹受控反映的證據(0.20)。
3.3 檢驗自動反應的證據
Higham等(2000)的對抗邏輯范式用對抗條件組中語法B的誤判率(誤判為G)與其基線水平——非法字符串U的誤判率(同樣誤判為G)做比較, 如果語法B的誤判率顯著大于基線水平就證明存在自動反應。相對應地, 本研究創立的反向對抗邏輯范式的對抗條件組中, 語法B的誤判率B-miss-op是誤判為NG的概率(而非誤判為G), 因此基線水平只能采用將語法A誤判為不合法NG的概率即A-miss-op, 而不能采用非法字符串U的誤判率U-miss-op, 因為它是將非法U誤判為合法G的概率, 與B-miss-op方向相反。另一個理由是被試對語法A和B進行了同等學習, 對非法U則沒有進行任何學習, 因此Higham等(2000)和Dienns等(1995)采用非法U的誤判率作為基線水平就有缺陷——沒有匹配學習程度和熟悉性。本研究采用A-miss-op作為基線水平則匹配了學習和熟悉性因素, 彌補了該缺陷。
本研究認為基線水平的本質是真實缺失量+隨機誤差。對抗條件組要求將語法A和B都判斷為合法G, 由于學習的真實缺失量+隨機誤差, 必然對語法A產生一定的誤判率(誤判為NG), 故以A-miss-op作為基線水平就是最標準的指標。那么如果語法B誤判為NG的概率B-miss-op顯著高于基線水平A-miss-op, 則可以排除真實缺失量和隨機誤差等因素, 而認定其差值是自動反應量。
古詩文的創造不是憑空產生的,它們都有一定的歷史寓意,或許是在一個特定的歷史環境或許是要紀念某人某物。因此,教師在講解古詩詞的時候,應該提前對古詩文的創作背景做詳細了解,了解當時的背景,發生了什么事情,作者寫這篇古詩文的寓意是什么。這些事情都應該一清二楚,尤其是在講解某一典故或者英雄事跡的時候,更應該要對此展開有針對性的教學。并在講解過程中引入傳統文化,加深學生對傳統文化的領悟能力。
比較對抗條件組A-miss-op、B-miss-op和U-hit-op, 三者方差齊性, 做ANOVA, 模型主效應顯著,F(2, 23)=3.03,p< 0.01, η2=0.209; 組間主效應顯著,F(2, 23)=35.39,p< 0.01, η2=0.755。對三者做成對比較, 見表3, B-miss-op (0.35)顯著高于A-miss-op (0.18),F(1, 23)=3.91,p< 0.01, η2=0.145, 兩者相減得到差值為0.17, 這就是自動反應的證據:盡管被試的控制加工過程試圖接受符合語法B的新字符串, 但是較之語法A, 被試還是更多地無意識拒絕語法B。這很好地驗證了實驗假設:反向對抗邏輯范式確實能夠排除形式相似性的影響, 比對抗邏輯范式更有效地檢測到真正的自動反應。
而U-hit-op顯著高于A-miss-op,F(1, 23)=3.95,p< 0.01, η2=0.147; U-hit-op顯著高于B-miss-op,F(1, 23)=10.04,p< 0.01, η2=0.304, 這證明比起拒絕語法A和B, 被試確實能夠更好地拒絕非法字符串U。但是非法字符U的擊中率U-hit-op (0.49)處于隨機水平, 原因是對抗條件組要求判斷為不合法NG的個數是恒定的20個, 故對語法B的自動拒絕反應部分侵占了對非法U作出拒絕判斷的空間。這是標簽“NG”與語法B綁定得到有效內隱學習的另一證據。
3.4 辨別力和自動反應的關系
在引言1.2中論述了Dienes等(1995)的實驗可能充分激發了被試辨別力而掩蓋了自動反應。本研究在其實驗程序基礎上加入了對語法AB的再認辨別和訂正任務, 被試對兩套語法的學習和辨別程度應該比Dienes等的實驗還要高, 但卻成功發現了自動反應, 這證明反向對抗邏輯可以不受辨別程度的影響而測得自動反應。下面將進一步從數據上證明這一點。
將再認辨別任務的正確率作為被試辨別力指標, 記為DiscAB即對AB的辨別力Discrimination。由于所有被試從試卷1到試卷4的實驗處理都是一樣的, 所以相容條件組與對抗條件組的辨別程度完全同質; 更由于對自動反應的檢驗只出現在對抗條件組,所以只需考察對抗條件組的辨別力DiscAB與自動反應的關系。設自動反應為AutoR即Automatic Response,則由分析3.3可知AutoR=B-miss-op﹣A-miss-op。

表3 對抗條件組對語法A和B及非法U判斷的差異(M ± SD, n=23)
對DiscAB (0.74 ± 0.19)和AutoR (0.16 ± 0.21)做皮爾遜相關, 相關不顯著,r=0.32,p> 0.05, 證明再認辨別階段的辨別力與自動反應沒有相關, 本研究新設計的反向對抗邏輯范式所產生和測得的自動反應不受對兩套語法的辨別程度影響, 抗辨別力干擾的能力很強, 可能比對抗邏輯范式更強。
4 討論
4.1 自動化的新途徑:內隱聯結自動化
反向對抗邏輯范式將外顯的否定標簽NG和語法B綁定進行內隱學習, 在對抗條件組檢測到了否定的自動反應, 證明內隱知識可以接受否定標簽而成為內隱否定知識。根據Cleeremans和Jiménez (2002)的表征質量意識理論, 內隱、外顯和自動化的本質是表征質量漸進遞增, 低級表征可通過不斷練習漸進轉化為高級表征。本研究證明外顯標簽只需和內隱語法規則的一部分聯結, 隨著對語法的內隱學習就可以擴展到新字符串, 獲得了自動化特征, 不再受外顯意識控制。此時的標簽是內隱表征還是自動化表征尚需進一步確定, 但能確定的是自動化聯結可以發生在外顯標簽和內隱知識之間, 而不只發生在外顯知識之間。經典自動化是外顯知識通過練習形成的, 而如果只練習一部分則只有該部分能夠自動化。本研究由內隱聯結產生的自動化形成速度更快, 且只需要和內隱規則的一部分聯結就能自動擴散到整個內隱規則, 這種內隱聯結自動化可能是新的特殊自動化。未來應進一步研究外顯規則與內隱標簽、外顯規則與內隱規則的聯結。
4.2 內隱否定知識比內隱肯定知識更加自動化
本研究相容條件組被試對語法B和非法U都要做拒絕的NG判斷, 對語法B的擊中率顯著高于對非法U的擊中率, 證明對學到的內隱否定知識能夠很好地做出拒絕判斷, 既符合外顯的拒絕要求,又符合內隱的自動拒絕反應。這和Dienes等(1995)的對抗條件組相似, 其對抗條件組要求對語法B(或A, 詳見1.2的第五點, 下同)和非法U都要做拒絕的NG判斷, 只是語法B的擊中率高于非法U的擊中率但不顯著, 而學習階段對語法B做的是肯定學習, 那么對抗條件組語法B的擊中率(即拒絕率)本應顯著低于非法U的擊中率。這個矛盾證明即使學到的語法B是內隱肯定知識, 但僅僅是外顯要求對它做拒絕判斷時, 否定傾向同樣非常強大; 而內隱肯定知識的自動反應不足以抵抗這種強大的否定傾向, 甚至會協同外顯要求做出拒絕反應。本研究相容條件組和Dienes等(1995)的對抗條件組得到了同樣結果:對內隱知識做否定操作很容易。
而在檢測自動反應方面, Dienes等(1995)的實驗對語法B先肯定學習后否定判斷, 產生了對抗,沒有發現自動反應; 本研究反向對抗邏輯對語法B先否定學習后肯定判斷, 也產生了對抗, 卻發現了顯著的自動反應。由兩者結果的矛盾可推論:內隱知識不是完全自動的, 受到內隱標簽的制約。對于內隱肯定知識, 外顯具有很強的控制力; 但對于內隱否定知識, 外顯則難以控制而產生自動否定反應。這從純認知層面顯示人類內隱加工可能天生就具有否定傾向:內隱知識從肯定轉化為否定易, 從否定轉化為肯定難(Wilder, Simon, & Faith, 1996), 否定的力量何其強大!
4.3 反向對抗邏輯范式能有效地檢測到真實的自動反應和純粹的受控反應
在引言中提到, Dienes等(1995)的實驗在學習階段是把語法A和B分別連貫學習, 被試可能更能夠在同一套語法中比較不同的字符串, 從而習得深層的語法結構; 而在測量階段語法A和B以及非法U三者具有同等的相似性, 使得采用相似性和熟悉性的策略無法完成任務, 只能提取語法規則知識來完成。而本研究創立的反向對抗邏輯范式能夠在這種最嚴格和學習程度較高的人工語法學習范式中獲得純粹的受控反應和真實的自動反應, 比較有力地證明了人工語法學習確實包含了真實的內隱成分!
內隱序列學習范式中探索意識的研究很多, 主要原因就是遵從對抗邏輯范式產生的包含排除任務能夠客觀和定量地分離出內隱序列學習獲得的受控反應即受控意識和自動反應即內隱成分(Fu et al,2010)。而人工語法范式無法成功應用對抗邏輯, 難以客觀定量地分離其中的內隱和外顯成分, 所以其意識研究走向了主觀意識領域(Dienes & Scott,2005), 而在客觀意識領域發展緩慢。因此本研究的反向對抗邏輯范式的成功, 可以為人工語法范式提供一種良好的客觀定量的意識測量范式; 而作為一種普適性的工具, 可以進一步探索片段學習、組塊學習、熟悉性、規則學習等不同的人工語法學習機制, 以及對應的研究范式(Pothos, 2007)各自產生的受控反應和自動反應有何特征和差異?受控反應和自動反應的組合與互動模式能否作為這些學習機制的良好校標?在此基礎上可將該范式改造成被試內設計, 采用受控反應和自動反應的關系來確定每個人工語法字符串屬于哪種學習機制和哪種知識。這將可能促進人工語法學習和意識機制研究的發展。當然還可以擴展到其它內隱學習和內隱認知領域, 探索抗干擾內隱學習和內隱辨別, 以及否定性內隱規則的學習機制。
4.4 內隱知識不等同于自動反應
需要強調的是, 反向對抗邏輯范式和已有的對抗邏輯范式的自動反應存在一定程度的本質差異:反向對抗邏輯范式的自動反應, 既是測量得到的也是本范式產生出的內隱成分。如3.2指出本范式的自動反應是對帶有否定標簽的內隱知識的自動拒絕反應, 可能對內隱否定知識的反應本就更自動。另外本范式要求被試寫上標簽“G”和“NG”, 并有再認辨別任務, 可能加深了內隱學習, 這是新增的實驗程序, 與 Higham等(2000)和Dienes等(1995)都不同。因此可能是因為本研究在學習階段通過手寫將標簽和語法更好地綁定, 建立起了反應聯結。而Dienes等(1995)只是在學習結束后告訴被試記憶的語法B是合法的“G”, 在學習階段沒有給予反應聯結, 得到的內隱知識和標簽“G”的聯結可能比較松散, 在測量階段就難以對語法B產生相應標簽“G”的自動反應。故進一步研究可以改進其實驗程序——在學習階段對語法B手寫打上標簽“G”; 同理可以反過來在本研究范式中撤銷手寫步驟, 如果還是檢驗出自動反應就證明并非是手寫反應聯結的貢獻。
同理Higham等(2000)測量到的自動反應也是其實驗范式制造出來的, 其成分和本研究有本質差異, 它可能是形式相似性造成的虛假自動反應。而Dienes等(1995)雖然沒有發現自動反應, 但不能認為一定沒有自動反應和內隱成分, 因為按照經典人工語法口語報告的測量標準, 其實驗中對語法的學習存在很多內隱成分。由于實驗范式很嚴格, 可能這種自動反應被非法字符串U的高接受率掩蓋了;也可能是這種自動反應本身容易受到外顯的拒絕要求控制, 失去了自動特征(詳見3.2); 還可能是嚴格的實驗材料提高了被試辨別力, 導致這種自動反應被辨別力所控制而與外顯要求協同, 失去了自動特征(詳見3.3)。無論哪種情況, 這種可能存在的“自動反應”和本研究的自動反應的本質確實不一樣。對比可推論:內隱知識不等于自動反應, 既存在自動的內隱知識, 也存在受控的內隱知識(Kiefer,2012; Horga & Maia, 2012); 外顯知識也可能如此,既有受控的外顯知識, 也有明明意識到卻無法控制的自動外顯知識。
5 結論
為了解決人工語法對抗邏輯范式的缺陷, 本研究創立了反向對抗邏輯范式, 實驗證明:
(1)外顯否定標簽可以和語法綁定進行內隱學習, 成為自動化的否定標簽; 內隱否定知識比肯定知識更自動; 內隱知識從肯定轉化為否定易, 從否定轉化為肯定難。
(2)首次析出了高概率偏向效應, 得到純粹的受控反應。
(3)反向對抗邏輯范式能有效地檢測到真實的自動反應, 不受語法間形式相似性和被試辨別力的影響, 因此在對抗邏輯范式不能得到自動反應的嚴格匹配了形式相似性的實驗材料上卻非常有效, 解決了人工語法對抗邏輯范式的幾個重大缺陷。
Cleeremans, A., & Jiménez, L. (2002). Implicit learning and consciousness: A graded, dynamic perspective. In R. M.French & A. Cleeremans (Eds.),Implicit learning and consciousness: An empirical, philosophical and computational consensus in the making?(pp. 1–40). Hove, UK: Psychology Press.
Cohen J. R., & Poldrack R. A. (2008). Automaticity in motor sequence learning does not impair response inhibition.Psychonomic Bulletin & Review, 15, 108–115.
Destrebecqz, A., & Cleeremans, A. (2001). Can sequence learning be implicit? New evidence with the process dissociation procedure.Psychonomic Bulletin & Review, 8, 343–350.
Dienes, Z., Altmann, G. T. M., Kwan, L., & Goode, A. (1995)Unconscious knowledge of artificial grammars is applied strategically.Journal of Experimental Psychology: Learning,Memory, and Cognition, 21, 1322–1338.
Dienes, Z., & Scott, R. (2005). Measuring unconscious knowledge:Distinguishing structural knowledge and judgment knowledge.Psychological Research, 69, 338–351.
Fu, Q. F., Dienes, Z., & Fu, X. L. (2010). Can unconscious knowledge allow control in sequence learning?.Consciousness and Cognition, 19, 462–474.
Higham, P. A., & Vokey, J. R. (2000). The controlled application of a strategy can still produce automatic effects: Reply to Redington (2000).Journal of Experimental Psychology:General, 129, 476–480.
Higham, P. A., Vokey, J. R., & Pritchard, J. L. (2000). Beyond dissociation logic: Evidence for controlled and automatic influences in artificial grammar learning.Journal of Experimental Psychology: General, 129, 457–470.
Horga, G., & Maia, T. V. (2012). Conscious and unconscious processes in cognitive control: A theoretical perspective and a novel empirical approach.Frontiers in Human Neuroscience, 6, 199.
Jacoby, L. L., Woloshyn, V., & Kelley, C. (1989). Becoming famous without being recognized: Unconscious influences of memory produced by dividing attention.Journal of Experimental Psychology: General, 118, 115–125.
Jacoby, L. L. (1991). A process dissociation framework:Separating automatic from intentional uses of memory.Journal of Memory and Language, 30, 513–541.
Jiménez, L., Méndez, C., & Cleeremans, A. (1996). Comparing direct and indirect measures of sequence learning.Journal of Experimental Psychology: Learning, Memory, and Cognition,22, 948–969.
Johansson, T. (2008).Knowledge representation, heuristics,and awareness in artificial grammar learning. Printed in Lund, Sweden, by KFS in Lund AB.
Kiefer, M. (2012). Executive control over unconscious cognition: Attentional sensitization of unconscious information processing.Frontiers in Human Neuroscience, 6, 61.
Mong, H., McCabe, D. P., & Clegg, B. (2012). Evidence of automatic processing in sequence learning using processdissociation.Advances in Cognitive Psychology, 8(2), 98–108.
Norman, E., Price, M. C., & Jones, E. (2011). Measuring strategic control in artificial grammar learning.Consciousness and Cognition, 20, 1920–1929.
Nosofsky, R. M. (1988). Similarity, frequency, and category representations.Journal of Experimental Psychology: Learning,Memory, and Cognition, 14, 54–65.
Nosofsky, R. M., & Zaki, S. R. (1998). Dissociations between categorization and recognition in amnesic and normal individuals: An exemplar-based interpretation.Psychological Science, 9, 247–255.
Pothos, E. M. (2005). The rules versus similarity distinction.Behavioral and Brain Sciences, 28, 1–14.
Pothos, E. M. (2007). Theories of Artificial Grammar Learning.Psychological Bulletin, 133, 227–244.
Redington, M. (2000). Not evidence for separable controlled and automatic influences in artificial grammar learning:Comment on Higham, Vokey, and Pritchard (2000).Journal of Experimental Psychology: General, 129, 471–475.
Reingold, E. M., & Merikle, P. M. (1988). Using direct and indirect measures to study perception without awareness.Perception & Psychophysics, 44, 563–575.
Soetens, E., Melis, A., & Notebaert, W. (2004). Sequence learning and sequential effects.Psychological Research, 69,124–137.
Tunney, R. J., & Shanks, D. R. (2003). Does opposition logic provide evidence for conscious and unconscious processes in artificial grammar learning?.Consciousness and Cognition,12, 201–218.
Vokeya, J. R., & Higham, P. A. (2004). Opposition logic and neural network models in artificial grammar learning.Consciousness and Cognition, 13, 565–578.
Wan, L. L., Dienes, Z., & Fu, X. L. (2008). Intentional control based on familiarity in artificial grammar learningConsciousness and Cognition, 17, 1209–1218.
Wilder, D. A., Simon, A. F., & Faith, M. (1996). Enhancing the impact of counterstereotypic information: Dispositional attributions for deviance. Journal of Personality and Social Psychology, 71, 276–287.
Yonelinas, A. P. (2002). The nature of recollection and familiarity: A review of 30 years of research.Journal of Memory and Language,46, 441–517.
Zhang, R. L., & Liu, D. Z. (2014). The development of graded consciousness in artificial grammar learning.Acta Psychologica Sinica, 46, 1649–1660.
[張潤來, 劉電芝. (2014). 人工語法學習中意識加工的漸進發展.心理學報, 46, 1649–1660.]
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
