基于LPC和MFCC得分融合的說話人辨認
2016-02-23 06:22:10單燕燕
計算機技術與發展 2016年1期
單燕燕
(南京郵電大學 通信與信息工程學院,江蘇 南京 210003)
基于LPC和MFCC得分融合的說話人辨認
單燕燕
(南京郵電大學 通信與信息工程學院,江蘇 南京 210003)
實驗室環境下,說話人識別研究已經取得很大進展,但是在實際生活中,說話人識別系統的性能受到環境噪聲、健康狀況等因素的影響很大。日常生活中,感冒是不可避免的。而感冒往往會誘發鼻腔的炎癥,改變鼻腔的容積和形狀,引起說話人聲音的改變,導致說話人識別性能下降。文中研究測試者感冒時說話人識別系統的性能。為了有效利用不同特征參數得分的互補性,針對基于GMM模型的說話人辨認系統,提出了將特征LPC和MFCC分別應用于該系統,并將二者的得分歸一化后進行融合計算。實驗結果表明,對正常語音來說,與LPC特征系統相比,該方法能夠有效提升辨認性能;對感冒語音來說,當高斯成分為16時,較之LPC特征系統,該方法提升辨認性能12.5%左右,較之MFCC特征系統,該方法也能提升8.5%左右的辨認性能。
感冒語音;說話人辨認;得分融合;得分歸一化
語音信號不僅傳遞了所要表達的語義信息,還傳遞了說話人的健康狀況以及情緒等信息。例如,當說話人身體不舒服或生病時,他說出的語音往往比身體健康時的低沉,給人一種有氣無力的感覺,有時甚至是聲音沙啞的,所以說話人生病時產生的語音波形也隨著而改變,從而降低了說話人識別系統的性能。實際生活中,說話人識別系統的性能受到兩方面因素的影響:外部因素和內部因素[1]。外部因素主要指的是環境噪音、編碼方式不同以及通道變化。說話人識別的研究目前主要集中在環境噪音和通道失配等外部因素的影響。在這方面已取得了非常大的進展[2]。內部因素,也稱自身因素,主要是指說話人的聲道特征或者獨特的行為特征發生變化,按照時間長短可分為短時和長時兩大類。長時變化[3]通常指的是隨著說話人年齡的增大發聲器官產生的緩慢變化,包括疾病、物理損傷或者發育期變化等帶來發聲器官的長久性變化。與長時變化不同,短時變化[1]則是由于發聲方式的變化、說話人偽裝、情緒變化以及短時疾病(如感冒)等因素使得說話人的聲音發生暫時性的變化。長時變化通常可利用自適應的方式得到很好地解決,然而短時變化則因其具備復雜性和突變性等特點而成為當前說話人識別中的一個難題。短時疾病一般指感冒、咳嗽、扁桃體發炎等造成發聲器官變化的短暫的可康復的疾病。P.Rose[4]指出感冒往往會伴隨著鼻腔(nasal cavities)中的炎癥和腫大,這會改變鼻腔的容積和形狀,從而改變鼻腔對聲源激勵信號的調制作用,引起說話人聲音的改變,從而導致說話人識別性能急劇下降。R.G.Tull等[5]也發現用正常語音訓練的說話人識別系統,在說話人感冒時的識別率明顯下降。但是對于說話人感冒時引起語音的具體變化以及如何減小感冒時語音的短時變化對說話人識別系統的影響缺乏進一步的研究。
日常生活中,人們總是難以避免地感冒,感冒使得說話人語音發生變化進而影響說話人識別系統的性能,所以,研究測試者感冒時的說話人識別系統具有很大的現實意義。
文中定義說話人未感冒時錄制的中性語音作為正常語音,而患有感冒時錄制的語音為感冒語音。用正常語音訓練說話人GMM模型,而待識別語音分別為正常語音和感冒語音,文中提出了將線性預測系數和梅爾倒譜系數分別應用于基于GMM模型的說話人辨認系統,歸一化處理匹配得分,然后進行融合計算,融合得分最高者即為最終的匹配結果。實驗結果表明,該方法能顯著提高系統的性能。
1 基于GMM模型的說話人辨認系統
說話人辨認分為兩個階段:訓練階段和辨認階段。在訓練階段,對說話人的語音信號進行一系列的處理,提取其特征參數之后,然后對這些特征參數進行聚類以表征這個特定說話人,即建立說話人模型。而辨認階段則提取出待辨認說話人的測試語音特征參數,并將其與已建立的說話人模型進行相似性比較,根據相應的評估準則判定說話人身份。
基于GMM[6-8]模型的說話人辨認系統框圖如圖1所示。
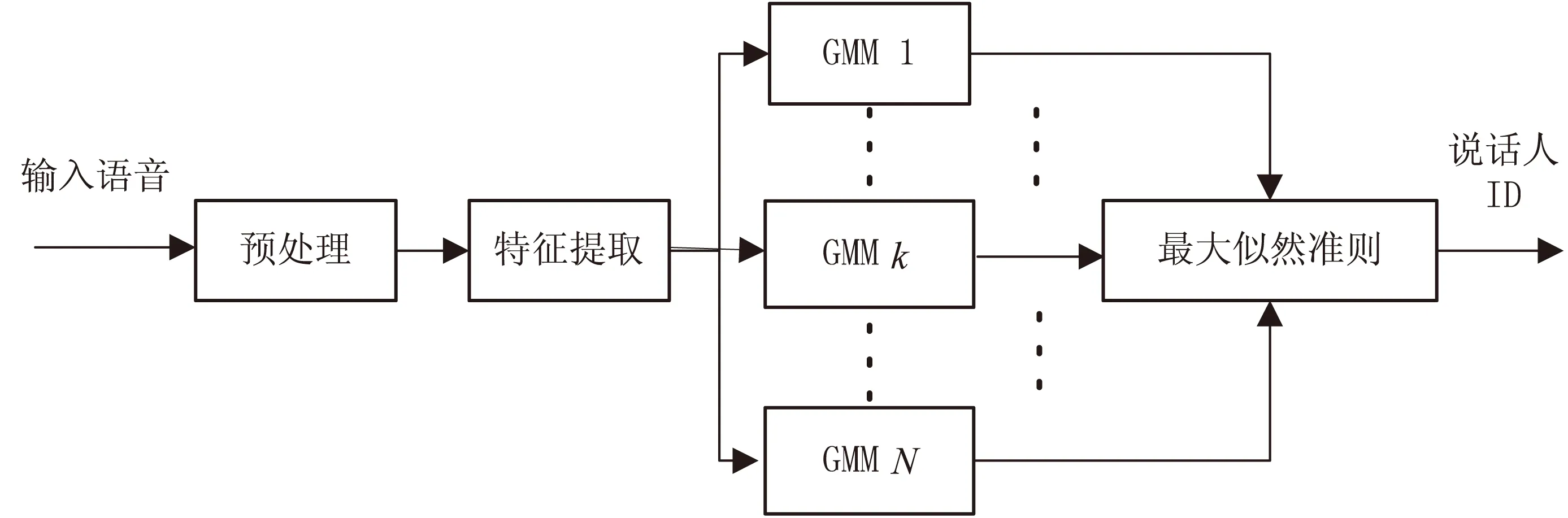
圖1 基于GMM模型的說話人辨認系統框圖
2 特征提取
2.1 線性預測系數(LPC)
語音信號的線性預測的基本思想是:在特定時間內,語音信號采樣點之間具有一定的相關性,因而可以用過去的樣點值的線性組合來表示現在或未來的樣點值。通過使語音的預測樣點值在最小均方誤差準則下逼近實際樣點值,可以求得唯一的一組預測系數。這組預測系數表征了語音信號的特性。語音信號下一時刻的樣點值可以利用該語音信號過去p個時刻的樣點值的線性組合來逼近,用過去p個時刻語音采樣值的線性組合以最小預測誤差預測語音信號下一時刻的采樣值,稱為對語音信號的p階線性預測[9]。設語音的采樣序列為{x(n)|n=0,1,…,N-1},則x(n)的p階線性預測值為:
(1)
式中,p為預測系數;ai(i=1,2,…,p)稱為線性預測系數。
每一幀語音求解的線性預測系數構成一個p維矢量。線性預測分析就是用這p維矢量來表示每幀語音。若用e(n)來表示預測誤差,則

(2)
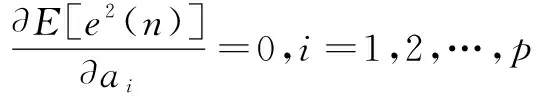
(3)
由上式可得p個方程,其矩陣表示為:
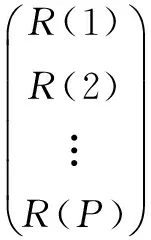
(4)
上述方程的解就是LPC系數。經典的求解方法有兩種:自相關法和協方差法[10]。其中Durbin遞推算法[11]是目前廣泛采用的一種自相關方法。
相比于它的預測功能,線性預測能夠提供一個非常好的聲道模型和模型參數估計方法,因而被應用于語音信號處理。
線性預測是一種分析語音信號頻譜的譜估計方法,之所以是目前最重要的語音特征參數之一,有以下幾個原因:
(1)它提供了很好的短時語音信號的聲道模型以及求解模型的方法。
(2)基音、共振峰等模型參數數據量小,容易計算,便于實時處理。
(3)LPC參數訓練得到的模型參數可以存儲起來,在語音識別等應用中減少識別時間。
(4)參數數據量小,傳輸速率低。
LPC模型階數p的選擇主要從兩方面考慮:共振峰個數和對口唇輻射影響的補償。通常p的取值范圍為8至12之間。12階的LPC模型可以以非常小的誤差逼近幾乎所有的語音信號產生的聲道模型。
2.2 梅爾倒譜系數(MFCC)
噪聲環境下及其他變異情況下,人耳仍能分辨出語音內容甚至說話人身份,這是因為耳蝸對輸入信號的調制作用。對于不同頻率的信號,耳蝸基礎膜的振動位置也是不同的。實際的聲音頻率與人耳所聽到的聲音高低不是線性關系,它經過了一個非線性的頻率變換。即不同的頻率信號,人的聽覺系統有不同的響應靈敏度。在1 000 Hz以下,實際聲音頻率與人耳感知到的聲音高低成線性關系,而1 000 Hz以上為對數關系。Mel頻率反映了實際頻率與感知頻率的轉換關系。其表達式為:
fmel=2 595log10(1+f/700)
(5)
式中,f的單位是Hz。
當兩個頻率成分的差值超出某個特定值時,這時人耳才能夠區分它們。這個特定值被稱為臨界帶寬。根據以上特性,人耳的聽覺特性可以用臨界頻帶濾波器來模擬。
一般,采用三角濾波器組[12]來逼近臨界頻帶濾波器組。
MFCC就是基于人耳聽覺系統的臨界效應提出來的一種倒譜參數。圖2即為MFCC參數提取框圖。

圖2MFCC特征參數提取框圖
具體流程為:
(1)將采樣后的語音信號進行歸一化、端點檢測、預加重和分幀加窗預處理后,得到語音信號的矩陣形式,其中每個行向量表示一幀語音。
(2)將預處理后的矩陣形式的語音信號進行離散傅里葉變換,并對語音頻譜取模的平方得到能量譜。
(3)通過三角濾波器組對語音信號進行濾波處理。計算出語音信號通過第m(1≤m≤M)個濾波器后的能量和,其中M為濾波器個數。
(4)對每個三角濾波器輸出的能量求對數,將得到M個系數。
(5)對這M個系數進行離散余弦變換,即得到MFCC參數。
文中使用的MFCC取其前1~12個,共12階。
3 基于得分融合的說話人辨認系統
語音信號不僅包含說話人特有的個性信息,還蘊含了語義信息,是二者的綜合體。迄今為止學者們仍未找出一個能夠將二者分離的語音特征參數。現有的語音特征參數都只是表示了語音信號的某些信息。為了比較充分地表征語音信號,提高說話人識別系統的識別率和魯棒性,特征參數的融合、不同說話人識別系統的融合以及得分融合已經成為了許多學者考慮的一個重要的研究方向。文中提出用LPC和MFCC分別訓練得到的GMM的說話人識別系統,并將這兩種特征的測試得分進行融合的說話人識別方法。其系統框圖見圖3。
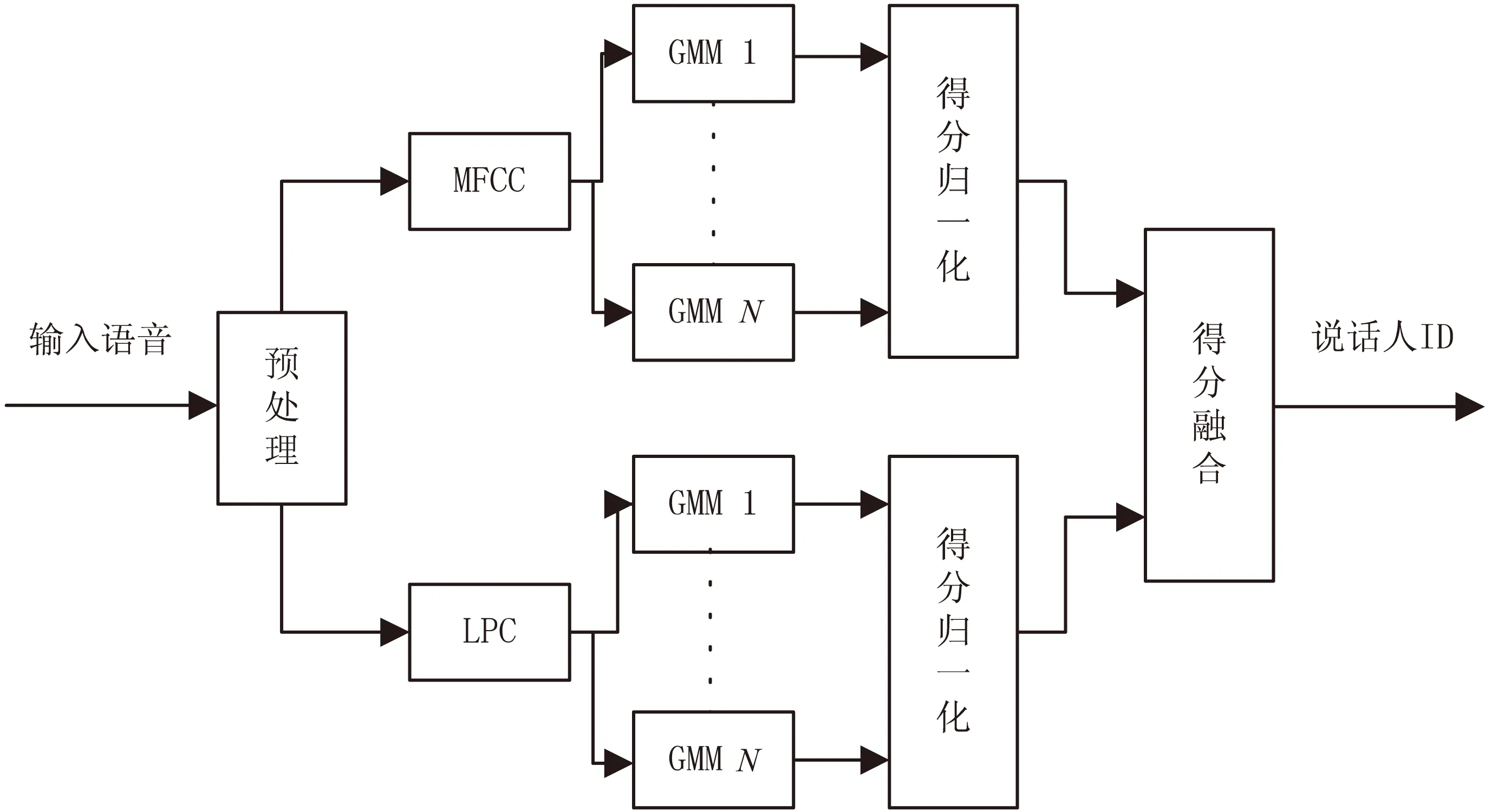
圖3 基于LPC和MFCC得分融合的GMM模型說話人辨認系統框圖
預處理主要包含預加重、分幀、加窗等操作,預加重技術[13]可以消除口鼻輻射,文中采用預加重濾波器的系數為0.91,其傳遞函數為:
H(z)=1-αz-1
(6)
建立的說話人模型,考慮了高斯混合成分分別為16、32、64三種情況。
3.1 得分歸一化
由于測試語音的特征不同,提取得到的數據之間有很大差異,通過系統的匹配計算部分獲得的得分變化幅度較大。如果將不同特征獲得的得分直接進行融合,很難獲得得分融合的分布規律,故而文中采用數據歸一化方法來處理得分。系統獲得的得分是一個向量x=(α1,α2,…,αN),歸一化處理如下:

(7)
其中,αi表示該測試語音與第i個說話人模型的匹配得分;N為模型庫中說話人總數。
3.2 得分融合

s=w1x1+w2x2
(8)
文中使用的加權系數為w1=0.7,w2=0.3。
4 實驗結果和分析
4.1 實驗設置
文中采用的語音數據庫有10名20~30歲說話人,其中7名男性,3名女性。采樣頻率fs為8 kHz,語音文本包含一段約1分半鐘的長語句、10個短句子。每個說話人分別在身體正常和感冒的情況下,朗讀以上的長語音和10句短句子。正常情況下朗讀的長語音用來訓練說話人模型,說話人身體正常和感冒情況下說的10個短句子作為測試語音。說話人身體正常時朗讀的長語句作為訓練集,共10句,短句子80句作為測試集1;說話人感冒時朗讀的80句短句子作為測試集2。
4.2 LPC和MFCC系統性能
表1、表2分別給出了特征參數為LPC的GMM模型說話人辨認系統和特征參數為MFCC的GMM模型說話人辨認系統的識別率,文中采用的是正確識別率作為系統的評價標準。分別是對測試集1和測試集2的識別結果。

表1 基于LPC參數的GMM說話人辨認

表2 基于MFCC參數的GMM說話人辨認
從表1、表2可知,對于同一特征構建的說話人識別系統,感冒語音的識別率比正常語音的識別率低,這說明說話人感冒時發出的語音的個性特征發生了變化,使得說話人識別系統的性能下降。
4.3 得分歸一化和融合后性能分析
將測試語音分別提取特征參數LPC和MFCC,并輸入相應的系統模型,經匹配計算求得兩個得分,將兩者線性加權。其中,LPC特征參數獲得的得分權重為0.3,MFCC特征參數的得分權重為0.7,其實驗結果見表3。

表3 基于LPC和MFCC得分融合的 GMM模型說話人辨認
由表3可得,對于正常語音,與LPC特征系統相比,得分融合系統性能提高的比較顯著;對于感冒語音,高斯成分為16、32、64,得分歸一化和決策融合系統性能明顯優于單一特征系統,其中在16個高斯成分時,與LPC特征系統相比,其性能提高12.5%左右,比MFCC特征系統性能提高8.5%左右。
5 結束語
文中提出將LPC和MFCC兩特征分別應用于GMM模型的說話人辨認系統,提取測試語音的LPC和MFCC特征參數,輸入相應的說話人識別模型庫中進行匹配計算,將這兩個特征的得分進行歸一化處理后進行線性加權融合,并得出最終的判決結果。實驗結果表明,對于正常語音集,文中提出的系統能夠較顯著地提高說話人辨認系統的性能;對于感冒語音集,說話人辨認系統的性能得到了顯著提高,在高斯混合成分M=16時,相對于LPC單特征系統提高了12.5個百分點,相對于MFCC特征系統也提高了8.75個百分點。
[1]FuruiS.Recentadvancesinspeakerrecognition[M]//Audio-andvideo-basedbiometricpersonauthentication.Berlin:Springer-Verlag,1997:237-252.
[2]KinnunenT,LiH.Anoverviewoftext-independentspeakerrecognition:fromfeaturestosupervectors[J].SpeechCommunication,2010,52(1):12-40.
[3]PawlewskiM,JonesJ.URUplus-ascalablecomponent-basedspeaker-verificationsystemforBT’s21stcenturynetwork[J].BTTechnologyJournal,2007,25(3):170-178.
[4]RoseP.Forensicspeakeridentification[M].London:Taylor&Francis,2002.
[5]TullRG,RutledgeJC,LarsonCR.Cepstralanalysisof“cold-speech”forspeakerrecognition:asecondlook[J].JournalofAcousticalSocietyofAmerica,1996,100(4):2760-2760.
[6]ReynoldsDA,RoseRC.Robusttext-independentspeakeridentificationusingGaussianmixturespeakermodels[J].IEEETransonSpeechandAudioProcessing,1995,3(1):72-83.
[7]ReynoldsDA,QuatieriTF,DunnRB.SpeakerverificationusingadaptedGaussianmixturemodels[J].DigitalSignalProcessing,2000,10(1):19-41.
[8]ReynoldsDA.SpeakeridentificationandverificationusingGaussianmixturespeakermodels[J].SpeechCommunication,1995,17(1-2):91-108.
[9]AkhoulM.Linearpredictionofspeakersfromtheirvoice[J].ProcofIEEE,1976,64:460-475.
[10] 張軍英.說話人識別的現代方法與技術[M].西安:西北大學出版社,1994:14-16.
[11] 張玲華,鄭寶玉.隨機信號處理[M].北京:清華大學出版社,2003.
[12]ZhuWeizhong,O’ShaughnessyD.IncorporatingfrequencymaskingfilteringinastandardMFCCfeatureextractionalgorithm[C]//Procof7thinternationalconferenceonsignalprocessing.[s.l.]:IEEE,2004:617-620.
[13] 王 青.基于神經網絡的漢語語音情感識別的研究[D].杭州:浙江大學,2008.
[14]YuP,SeideFTB.Ahybridword/phoneme-basedapproachforimprovedvocabulary-independentsearchinspontaneousspeech[C]//ProcofINTERSPEECH2004.JejuIsland,Korea:[s.n.],2004:293-296.
[15]ChenB.VoiceretrievalofMandarinbroadcastnewsspeech[J].InternationalJournalofPatternRecognitionandArtificialIntelligence,2006,20(1):91-109.
Speaker Identification Based on Score Combination of LPC and MFCC
SHAN Yan-yan
(College of Communication and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
At present,speaker recognition technology has made great progress in clean voice.But in daily life,there are various factors,such as environmental noise and healthy condition,impacting recognition rate of speaker recognition system.The cold tends to induce the nasal cavity’s inflammation,and changes the volume and shape of the nasal cavity and then changes the vocal characteristics of the speaker.In order to effectively use the complementarity of scores from different feature parameter,the performance’s change of speaker identification system was studied when the speaker gets the cold.So the method was proposed using linear prediction coefficient and MEL cepstrum coefficient to train the speaker model respectively,and then score normalization method is used to process scores from two feature systems.Finally,two outputs were weighted.The experimental results show that for normal speech,this method can improve the identification performance;for cold speech,the method improves the identification performance by 12.5% when the number of Gaussian components equals to sixteen compared with the system taking MFCC as feature,by 8.5% to the LPC system.
cold speech;speaker identification;score combination;score normalization
2015-01-07
2015-05-08
時間:2016-01-04
國家自然科學基金資助項目(61271335);國家重點基礎研究發展計劃(2011CB302303)
單燕燕(1988-),女,碩士研究生,研究方向為說話人識別、語音信號處理。
http://www.cnki.net/kcms/detail/61.1450.TP.20160104.1607.064.html
TN912.3
A
1673-629X(2016)01-0039-04
10.3969/j.issn.1673-629X.2016.01.008
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
