一種帶約束條件的購物籃分析方法
2016-02-23 06:33:38褚維偉張文斌陳小軍黃哲學
計算機技術與發展 2016年8期
關鍵詞:分析
褚維偉,張文斌,陳小軍,黃哲學
(深圳大學,廣東 深圳 518000)
一種帶約束條件的購物籃分析方法
褚維偉,張文斌,陳小軍,黃哲學
(深圳大學,廣東 深圳 518000)
購物籃分析是數據挖掘技術在零售業的典型應用之一,旨在從零售記錄中分析出顧客經常同時購買商品的組合,挖掘出購物籃中有價值的信息。如今購物籃分析在零售業已經有了廣泛的應用,包括商品的促銷、擺架、物流等。通過與零售客戶的詳細溝通與調研,發現傳統購物籃分析并不考慮商品之間的層次關系,并且將支持度作為評估購物籃的唯一指標,在實際應用中存在缺陷。針對傳統購物籃分析的不足,文中提出一種帶有約束條件的購物籃分析,定義了一種新的購物籃評估方法。通過對真實數據進行一系列實驗研究與分析,得到了更有實際意義的購物籃,并且在算法復雜度與運行時間方面比傳統購物籃分析算法有了很大提升。
數據挖掘;購物籃分析;約束條件;頻繁項集
1 概 述
在大數據時代,每時每刻都在產生著形形色色的數據。如何利用數據挖掘的知識與工具從這些海量的數據中挖掘出想要的信息,是最重要的研究內容之一。關聯規則是數據中所蘊含的一類重要規律,對關聯規則進行挖掘則是數據挖掘中的一項根本性任務,甚至可以說是數據庫和數據挖掘領域中所發明并被廣泛研究的最為重要的模型。關聯規則挖掘的目標是在數據中找到所有的并發關系,也可以把這種關系稱作關聯。自從1993年Agrawal等第一次提出這個概念后,它已經引起了眾多學者的注意,出現了許多算法、擴展以及應用[1]。
關聯規則挖掘最經典的一個應用就是購物籃分析。通過發現顧客每次放入購物籃中的商品之間的聯系,分析顧客的購買行為并輔助零售企業制定營銷策略[2]。通常說的購物籃分析指的是通過購物籃中顯示出來的交易信息來分析顧客的購買行為,顧客在購買商品的過程中通常會一次購買多件商品,從而使得這些商品之間具有很強的關聯性[3-4]。因此,可以認為顧客的購買行為是一種整體行為,是否購買一件商品會影響到其他商品的購買,從而影響到每個購物籃的利潤。所以,購物籃分析的目標就是找出重要而且有價值的購物籃[5]。目前關于購物籃分析的研究大多關注商品之間的關聯度算法,而在實際應用方面,特別是在零售業中的應用卻很少[6-7]。
在傳統的購物籃分析中,得出的結果通常是一些常規商品的組合。這些組合的購物籃支持度很高,但是它們已經是被大家所認知的,對企業的價值和意義不大。此外,傳統購物籃分析中一個很大的局限性在于它并不考慮商品的層次結構,通常只選擇一個層次的商品來進行購物籃分析[8-9]。這樣就導致得出的結果往往是同一小類產品的組合,例如不同品牌的飲料,這種購物籃滿足不了企業的需求,妨礙了其在零售業中的實際應用[10]。
針對傳統購物籃分析的局限性并結合企業實際應用中的需求,文中提出一種帶有約束條件的購物籃分析方法。約束每個購物籃的組成中不能包含有相同父類的商品,并通過支持度和銷售額的閾值來對候選購物籃進行評估、篩選。
2 傳統購物籃分析
消費者日趨成熟的心理、越來越多樣化的需求以及越來越激烈的市場競爭,使得充分分析并正確了解顧客已成為企業成功至關重要的因素[11]。雖然部分零售企業已經意識到這個問題并且做了很多這方面的工作,例如計算機輔助銷售、顧客資料登記分析、人口統計分析等,但是很多時候效果并不明顯。因此,購物籃分析的方法便應運而生,它提供了一種有效地研究顧客購買行為的方法[12]。購物籃分析作為關聯規則挖掘在零售領域中的一個經典應用,通常所使用的技術也是關聯規則挖掘的經典算法,文中以經典的Apriori算法為例對傳統購物籃分析方法進行介紹。
2.1 基于Apriori算法的傳統購物籃分析
Apriori算法是一種經典的關聯規則頻繁項集挖掘算法,其主要分兩步進行:
(1)生成所有頻繁項目集:一個頻繁項目集是一個支持度高于最小支持度閾值的項集。
(2)從頻繁項目集中生成所有可信關聯規則:一個可信關聯規則是置信度大于最小可信度閾值的規則。
把一個項集中項目的個數稱為這個項集的基數,則k-項集表示一個基數是k的項集,k-頻繁項集表示一個基數為k的頻繁項目集[13-14]。
Apriori算法使用一種稱為逐層搜索的迭代方法,即用k-項集來產生(k+1)-項集。首先找出1-項集的候選集,記為C1,然后根據最小支持度對C1進行剪枝得到頻繁1-項集L1。再由L1連接產生2-項集的候選集C2,由C2產生頻繁2-項集L2,循環下去,直到得到的Lk為空為止[15]。
Apriori頻繁項集挖掘算法是根據支持度來進行剪枝的,其過程可以描述為:
設I=[i1,i2,…,im]是所有項目的集合,即所有商品類別的集合;D=[T1,T2,…,Tn]是所有事務的集合,即所有交易記錄的集合。事務T可以表示為:T=[TID,
(1)
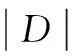
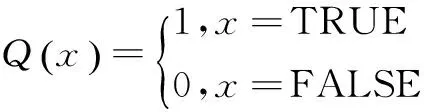
(2)
設P為支持度閾值,當且僅當PB≥P時,購物籃B才是有效的[16-19]。
2.2 傳統購物籃分析的局限性
商場中出售的商品都有自己的類別,根據交易記錄可以得到商品類別的層次結構。例如,圖1是從由某超市的交易記錄得出的商品層次結構樹。從圖中可以得到這些商品的層次信息,如白菜與胡蘿卜都屬于蔬菜類,雪碧與可樂都屬于飲料類。

圖1 商品層次結構樹
在購物籃的項目組成方面,由于傳統購物籃分析并不考慮商品的層次結構和所屬關系,通常得出的購物籃很多是同一小類產品的組合,例如得到的購物籃B=[蘋果,梨子,香蕉,葡萄,牛奶]。其中,[蘋果,梨子,香蕉,葡萄]?[水果],此種購物籃對企業的價值不大。同時,真正有價值的購物籃被大量重復、沒有價值的購物籃所掩蓋,這是影響購物籃分析在零售業應用的一個重要因素。
在購物籃選擇方面,根據調研發現,企業對支持度的需求與傳統購物籃分析的支持度計算方法有一定的區別。例如,購物籃B=[蔬菜,牛奶,豆腐,豬肉,水果]中含有5個品類,如果按5-項集計算支持度,可能不滿足頻繁集的條件,但這個購物籃對企業有用。如果放松支持度的條件,只要某筆交易含有這5個品類中的3個或者4個(用戶可以自己定義),就可以認為這筆交易記錄符合購物籃。另一方面,傳統的購物籃分析僅僅依據支持度來進行篩選,而支持度表征的是符合條件的交易數占總的交易數的比例,在實際應用中并不是衡量購物籃重要性的唯一屬性。企業不僅希望得出的購物籃在數量上有較高的支持度,同時希望在價值上能夠最大化。所以除了支持度之外,對購物籃進行評估還需增加購物籃的銷售額。
3 帶有約束條件的購物籃分析
基于上述傳統購物籃的局限性,文中提出一種帶有約束條件的購物籃分析方法。首先提出基于商品層次結構的購物籃生成算法,然后定義兩種購物籃評估方法,最后對整個算法進行總結和分析。
3.1 基于約束條件的購物籃生成算法
3.1.1 約束條件定義
在購物籃分析中,通常會選擇商品分類層次中的某一層。首先找出這一層商品對應的父類,形成如圖1所示的商品層次結構樹,并將其符號化表示。


給定一個具有商品層次分類信息的交易數據庫D,商品的層次樹可以用下面的方法獲得:

商品的層次結構挖掘算法get_Tree()(算法1)如下所述:
輸出:帶有商品層次信息的項目集I。
步驟:
Tree[0]=(0,-1); //初始化根節點
point_of_insert=1;
for每筆交易記錄T∈Ddo//按行讀入數據庫
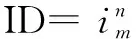


point_of_insert++;
endfor
I=trans(Tree);//將Tree轉化為I輸出
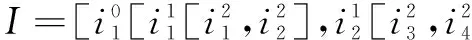
3.1.2 候選購物籃生成算法
在上一節定義了基于商品層次結構的約束條件。這個約束條件保證了同一個購物籃中不會出現相同父類的商品,從而增加了購物籃的多樣性,提升了購物籃的可用性。根據該條件,設計一種新的購物籃生成算法。對任意一對頻繁(k-1)-項集,只有它們的前(k-2)項相同,并且(k-1)項不屬于同一個父類時,才進行合并生成一個k項的購物籃。在這里,購物籃和頻繁集是同一個概念,k-項集購物籃挖掘算法gen_Candidate()(算法2)如下所述:
輸入:頻繁(k-1)-項集Lk-1,商品層次結構樹I;
輸出:候選k-項集Ck。
步驟:
for任意兩個A,B∈Lk-1do
令A={a1,a2,…,ak-1},B={b1,b2,…,bk-1}
ifaj=bj(j=1,2,…,k-2) &&
H(ak-1)≠H(bk-1)then
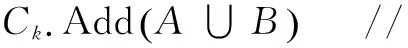
endfor//其中函數H(x)為根據商品層次結構I找出x的父類
3.2 基于支持度和銷售額的購物籃評估方法
在傳統的購物籃分析中,支持度是檢驗購物籃的唯一指標,導致最后得到的分析結果通常都是一些最常見的商品組合,例如蔬菜、豬肉、豆腐等。這些商品雖然銷售量很大,但是它們的銷售額卻不高,從而給企業帶來的利潤不高。因此文中在利用支持度對購物籃進行評估的基礎上,加入了銷售額的評估維度,從而保證得到的購物籃價值較高。設B為一個購物籃,則定義B的支持度為:
(3)
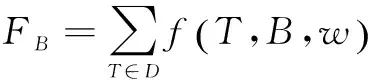
B的銷售額占比為:
(4)

由式(3)和式(4)得出k-項集候選購物籃Ck中每個購物籃B對應的支持度PB和銷售額RB,當且僅當PB和RB都大于對應的閾值時,購物籃B有效。購物籃評估算法basket_Assess()(算法3)如下所述:
輸入:候選集Ck,支持度閾值min_sup,銷售額閾值min_sale;
輸出:頻繁集Lk。
步驟:
for每個購物籃B∈Ckdo
ifPB≥min_sup &&RB≥min_salethen
Lk.Add(B) //將購物籃加入到Lk中
endfor
3.3 帶約束條件的購物籃挖掘算法
綜合上述商品層次樹挖掘算法,約束條件和候選購物籃生成算法以及購物籃評估算法,可以得出帶約束條件的購物籃挖掘算法。
(1)用算法1從交易數據庫得出商品的層次結構樹;
(2)用算法2生成滿足約束條件的候選購物籃;
(3)根據支持度和銷售額對候選購物籃進行篩選。
重復這個過程,直到候選購物籃個數為0或者購物籃數量滿足給定值為止。帶約束條件的購物籃挖掘算法(算法4)如下所述:
輸入:交易數據庫D,最小銷售額閾值min_sale,最小支持度閾值min_sup,期望得到的購物籃中商品個數aim_k,期望購物籃中項目匹配個數w;
輸出:aim_k項購物籃。
調用商品的層次結構挖掘算法得到商品層次結構I=get_Tree(D)
掃描D可得到C1
whileLk≠NULL &&k≤aim_kdo
Ck=gen_candidate(Lk-1,I)
k++;
end
文中提出的帶約束條件的購物籃挖掘算法,一方面考慮了商品之間的層次結構和所屬關系,在產生候選購物籃的過程中加入約束條件,增加了購物籃的多樣性與實用性;另一方面在評估候選購物籃的過程中加入銷售額的評估維度,并根據現實應用中零售企業的需求重新定義了支持度的計算方法,提高了購物籃對企業的價值和意義。

4 實驗與結果分析
為了檢驗文中提出的帶約束條件的購物籃挖掘方法在實際應用中的效果,采用真實數據對效果和性能進行驗證。數據來源于大型連鎖超市的實際交易記錄數據,共有3 073 886條記錄,532 484個交易號(TID)。觀察數據可知,該超市的商品結構分為四層,從高到低依次是經營小類、商品中類、商品小類、單品。針對商品種類進行分析,使用上述數據集,對帶有約束條件的購物籃挖掘算法進行了性能測試。實驗使用的計算機配置:3.2GCPU和16G內存。
圖2對比了不同長度的購物籃中有相同父類的購物籃占比隨著支持度變化的趨勢。實驗采用Apriori算法來產生購物籃。
由圖中可以看出,隨著支持度增加,含有相同父類商品的購物籃占比明顯增加,尤其是當購物籃長度較長時,這一比例始終維持在95%以上。在實際應用中,企業往往想要的是含有多個項目的購物籃,購物籃中商品的多樣性盡可能最大化,而不是人們常識中已經熟悉的那些商品組合。傳統購物籃分析得到的購物籃中有相同父類的購物籃的比例會很高,對企業的價值與意義不大,妨礙了購物籃分析在實際場景中的應用。新的有約束條件的購物籃分析可以有效避免這種問題。

圖2 不同長度購物籃中含有相同父類
圖3比較了文中提出的帶有約束條件的購物籃分析算法和傳統購物籃分析算法所產生的購物籃的銷售額的分布情況。

圖3 兩種算法產生的購物籃銷售額分布對比
可以看出,文中提出的算法產生的購物籃銷售額明顯高于傳統購物籃分析算法的銷售額。因此,新算法可以提升購物籃對用戶的應用價值,找出了銷售額較高、利潤率較高的購物籃,而不再是傳統購物籃分析中經常出現的蔬菜、豆腐等低利潤的常規項。
Apriori算法的一個最大缺點就是產生大量的候選項集,對機器的內存大小要求很高,算法的運行時間較長。
圖4對比了隨著實驗數據量的增加,傳統的購物籃挖掘方法和文中提出的算法的運行時間變化情況。設支持度為0.1%,銷售額占總銷售額比例的閾值為1%,期望產生的購物籃中商品個數為5。
由圖可看出,帶有約束條件的購物籃分析算法運行時間明顯小于基于Apriori算法的傳統購物籃分析算法,大大減少了傳統購物籃分析算法的時間復雜度。此外,當數據量增大時,基于Apriori算法的運行時間增加較快,而帶有約束條件的購物籃分析算法的運行時間增加相對較緩。

圖4 實驗數據量增加時兩種購物籃
圖5為實驗得到的購物籃分析結果示例。

圖5 帶有約束條件的購物籃分析實驗結果示例
由圖可以看出,購物籃的組成符合人們的生活常識。例如,第一個購物籃為家居生活用品,第二個購物籃為零食小吃,并且在同一個購物籃中的商品都是屬于不同的父類,滿足約束條件,增加了購物籃的多樣性,方便企業進行交叉銷售,提升購物籃的應用價值。
根據算法描述以及實驗結果,可以總結出帶有約束條件的購物籃分析算法的兩個主要優點:
(1)約束條件和新的購物籃評估方法產生的購物籃應用價值更高。
(2)通過參數的設定,有效減少了傳統購物籃分析方法的時間和空間復雜度。
5 結束語
文中詳細描述了帶有約束條件的購物籃挖掘方法,并提出了新的購物籃評估方法,采用實際數據進行了性能測試,并與傳統的購物籃分析方法進行了對比。結果表明,帶有約束條件的購物籃挖掘算法能有效避免同一購物籃中商品相似度過高和銷售額較低的問題,產生企業需要的購物籃,新算法的時間和空間復雜度相對于傳統購物籃分析都有顯著下降。
下一步,計劃結合多層次的關聯規則來進行購物籃分析。對于很多的應用來說,由于數據分布的分散性,很難在數據最細節的層次上發現一些強關聯規則。當引入概念層次后,就可以在較高的層次上進行挖掘。 然較高層次上得出的規則可能是更普遍的信息,但是對于一個用戶來說是普通的信息,對于另一個用戶卻未必如此。 所以購物籃分析應該提供這樣一種在多個層次上進行分析的功能。
[1]GatziouraA,Sanchez-MarreM.Acase-basedrecommendationapproachformarketbasketdata[J].IEEEIntelligentSystems,2015,30(1):20-27.
[2]BuczakAL,GiffordCM.Fuzzyassociationruleminingforcommunitycrimepatterndiscovery[C]//ProcofISI-KDD2010.USA:ACM,2010.
[3]AguinisH,ForcumLE,JooH.Usingmarketbasketanalysisinmanagementresearch[J].JournalofManagement,2013,39(7):1799-1824.
[4]BasuchowdhuriP,ShekhawatMK.Analysisofproductpurchpatternsinaco-purchasenetwork[C]//Procoffourthinternationalconferenceofemergingapplicationsofinformationtechnology.[s.l.]:[s.n.],2014:355-360.
[5]GuptaN,YadavML.AnimplementationandanalysisofDSRusingmarketbasketanalysistoimprovethesalesofbusiness[C]//Procof5thinternationalconferenceofthenextgenerationinformationtechnologysummit.[s.l.]:[s.n.],2014:82-86.
[6]ZhouLe,LiJunjie,HuangZhexue.BalancedparallelFP-growthwithMapReduce[C]//ProcofIEEEyouthconferenceoninformationcomputingandtelecommunications.[s.l.]:IEEE,2010:243-246.
[7]KimHK,KimJK.Aproductnetworkanalysisforextendingthemarketbasketanalysis[J].ExpertSystemswithApplications,2012,39(8):7403-7410.
[8]BirtoloC,deChiaraD,LositoS,etal.SearchingoptimalproductbundlesbymeansofGA-basedengineandmarketbasketanalysis[C]//ProcofIFSAworldcongressandNAFIPSannualmeeting.Edmonton,AB:IEEE,2013:448-453.
[9]BhalodiyaD,PatelC.Anefficientwaytofindfrequentpatternwithdynamicprogrammingapproach[C]//ProcofNirmauniversityinternationalconferenceonengineering.[s.l.]:[s.n.],2014:1-5.
[10]CaviqueL.Next-itemdiscoveryinthemarketbasketanalysis[C]//Procofconferenceonartificialintelligence.[s.l.]:[s.n.],2005:198-199.
[11]TrnkaA.Marketbasketanalysiswithdataminingmethods[C]//Procofinternationalconferenceonnetworkingandinformationtechnology.[s.l.]:IEEE,2010:446-450.
[12]ChenaYL,TangK,ShenaRJ,etal.Marketbasketanalysisinamultiplestoreenvironment[J].DecisionSupportSystems,2005,40(2):339-354.
[13]SarkanMO,AkcakocaA,KucukakdagC,etal.AlarmcorrelationusingApriorialgorithm[C]//Procofsignalprocessingandcommunicationapplications.[s.l.]:[s.n.],2015:1602-1605.
[14]ZakiMJ.Scalablealgorithmsforassociationmining[J].IEEETransactionsonKnowledgeandDataEngineering,2000,12(3):372-390.
[15]HanJ,PeiH,YinY.Miningfrequentpatternswithoutcandidategeneration[C]//Procofconferenceonthemanagementofdata.NewYork,NY,USA:ACMPress,2000.
[16]AgrawalR,Imieli′nskiT,SwamiA.Miningassociationrulesbetweensetsofitemsinlargedatabases[C]//Proceedingsofthe1993ACMSIGMODinternationalconferenceonmanagementofdata.[s.l.]:ACMPress,1993:207-216.
[17]ZhangChun-Sheng,LiYan.Extensionoflocalassociationrulesminingalgorithmbasedonapriorialgorithm[C]//Procof5thIEEEinternationalconferenceonsoftwareengineeringandservicescience.[s.l.]:IEEE,2014:340-343.
[18]ChangRui,LiuZhiyi.Animprovedapriorialgorithm[C]//Procofinternationalconferenceonelectronicsandoptoelectronics.[s.l.]:[s.n.],2011:476-478.
[19]SaxenaP,PantB.Inter-transactionalpatterndiscoveryapplyingcomparativeaprioriandmodifiedreverseaprioriapproach[C]//ProcofIEEE8thinternationalconferenceonintelligentsystemsandcontrol.[s.l.]:IEEE,2014:300-305.
A Market Basket Analysis Method with Constraints
CHU Wei-wei,ZHANG Wen-bin,CHEN Xiao-jun,HUANG Zhe-xue
(Shenzhen University,Shenzhen 518000,China)
Basket analysis is a typical application of data mining technology in retail industry.It aims to analyze customers’ purchase patterns of goods from sales transactions and digs out the valuable information in the basket.Nowadays,basket analysis has been widely used in retail business,including sales promotion,pendulum shelf and logistics for goods.Through communication with retail customers,it is found that traditional basket analysis,which doesn’t consider the hierarchical relation between goods and takes the support degree as the unique index of evaluating basket,has some defects in real applications.In view of the deficiencies,a new basket analysis method with constraints is proposed and a new basket evaluation method is defined.Through a series of experiment research and analysis of real data,the basket with more practical significance is obtained,and the complexity and run time of proposed algorithm is better than the traditional one.
data mining;basket analysis;constraints;frequent itemsets
2015-11-06
2016-03-10
時間:2016-06-22
國家自然科學基金資助項目(61305059);深圳大學青年教師科研啟動項目(201432)
褚維偉(1990-),男,碩士,研究方向為數據挖掘;黃哲學,特聘教授,研究方向為數據挖掘。
http://www.cnki.net/kcms/detail/61.1450.TP.20160622.0845.048.html
K921/927;TP393
A
1673-629X(2016)08-0069-06
10.3969/j.issn.1673-629X.2016.08.015
猜你喜歡
現代畜牧科技(2021年9期)2021-10-13 06:39:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
當代經濟研究(2016年5期)2016-12-01 03:12:05
現代農業(2016年5期)2016-02-28 18:42:46
出版與印刷(2016年3期)2016-02-02 01:20:11
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
華北水利水電大學學報(社會科學版)(2014年3期)2014-04-16 04:38:31
終身教育研究(2014年5期)2014-02-28 01:23:06
