改進的中心向量算法在農業信息分類中的研究
2016-02-23 06:29:02趙新苗馮向萍李永可
計算機技術與發展 2016年8期
趙新苗,馮向萍,李永可
(新疆農業大學 計算機與信息工程學院,新疆 烏魯木齊 830052)
改進的中心向量算法在農業信息分類中的研究
趙新苗,馮向萍,李永可
(新疆農業大學 計算機與信息工程學院,新疆 烏魯木齊 830052)
自21世紀以來,農業信息網站開始迅速增加。為了給廣大農民朋友和農業科研人員提供方便,需要對農業信息進行分類。將農業信息進行分類有利于農業信息的獲取和管理,農業分類的方法有很多種,其中中心法分類相對簡單且卓有成效。中心向量計算方法是中心法分類的核心,文中實驗目的在于找出效率較高的中心向量計算方法來提高分類的準確率。目前文本類的中心向量計算多數是由該類別文本特征向量的簡單算術平均得到的,這樣計算得出的中心向量往往會有模型偏差,以至于不能得到很好的分類效果。為解決這個問題,使用總和法、均值法和歸一化法計算中心向量,并進行對比實驗,結果表明歸一化法在查準率、查全率和F1測度都有較好的表現。
農業信息;分類;中心法;中心向量;文本特征向量
0 引 言
自21世紀以來,在信息技術迅猛發展的強勁推動下,農業信息化進程明顯加快。計算機科學在農業信息領域中發揮著重大作用,農業信息網站開始迅速增加,為廣大的農民朋友和農業科研人員提供了極大的方便,但是在眾多農業信息中要尋找到自己所需要的信息卻面臨著極大的挑戰。因此如何有效地對農業信息進行分類管理,方便信息的查找成為農業信息化亟待研究的重要領域。
目前使用的網頁分類算法主要有KNN算法、樸素貝葉斯算法、支持向量機算法和中心法。KNN(K-最鄰近算法)最初由Cover和Hart于1968年提出,金一寧等使用該方法對中文網頁進行分類,最終分類的準確率達到80%以上[1];江小平等采用分布式編程的樸素貝葉斯算法對中文網頁文本進行分類,其識別率達到86%[2];李瓊等使用改進的支持向量機算法對文本進行分類,在一定程度上提高了識別的準確率[3]。
中心法是一種相對簡單并且高效的文本分類算法,但是其需要滿足一個條件,即待分類向量與它所屬文本類別的中心向量相似度要大于其他的類別。因此中心法的準確率在很大程度上依賴于中心向量的計算方法,目前類別的中心向量是由該類別文本特征向量的簡單算術平均得到的,但是對于各個類別的文本往往是很分散的,空間上也有和其他類別重疊的區域,這樣計算出來的中心向量往往會有模型偏差,以至于不能得到很好的分類效果。
針對上述偏差,文中提出一種改進的中心向量計算方法,并進行了實驗對比。
1 農業信息網站的現狀與研究
1.1 農業信息網站的現狀與分類標準
目前國內農業信息資源的建設在總體上存在缺乏專業特色、信息資源缺乏多樣性、信息共享和開放程度較低,以及信息的時效性較差等問題。并且在農業信息資源建設方面缺乏科學權威的農業信息搜索引擎,現代先進的信息科學技術還未得到廣泛的應用。現代信息科學技術在農業信息資源建設中的作用需要得到重新認識和足夠重視,同時還需要加強對關鍵技術的研究,如信息自動采集與發布技術、農業信息分類檢索技術、網絡數據庫技術等[4]。
雖然先后在農業領域頒布了1 064個國家標準,卻沒有全面的農業信息分類國家標準。根據農業信息分類的原則,將農業信息分為四級,其中包括一級分類8項,二級分類42項,三級分類192項,四級分類1 136項[5]。文中使用一級分類標準,具體為林業、種植業及制品、漁業、園林、畜牧業、農業生產資料、農業機械、植物病理共八類。
1.2 農業信息網頁分類流程
文中從各大農業網站上獲取與農業信息相關的網頁樣本進行人工標注,并且將標注樣本分為訓練集和測試集。先進行文本預處理去除文檔標簽及非中文字符;然后對網頁內容進行中文分詞,去除停用詞;再進行特征詞提取,并且構建特征向量;最后構建文本類的中心向量分類器,使用中心法對測試集網頁進行測試,進行性能評估。中文農業信息網頁分類流程如圖1所示。

圖1 農業信息網頁分類流程
2 主要技術簡介
文中使用到的技術主要是分詞方法、特征提取、特征加權、中心法。
(1)分詞。
對于中文網頁分類,分詞是很重要的基礎。使用高效率的分詞方法能夠在很大程度上提高網頁分類結果的準確性[6]。文獻[7-8]對多種分詞方法進行了比較,結果表明庖丁解牛分詞器從分詞效果、性能、準確率方面都表現良好。文中選擇庖丁解牛分詞器。
(2)特征提取。
在文本分類領域,目前比較常用的特征提取方法有:文檔頻率(Document Frequency,DF)、互信息(Mutual Information,MI)、期望交叉熵(Expected Cross Entropy,ECE)、信息增益(Information Gain,IG)和X2統計方法(CHI-square,CHI)等。
特征提取的質量將在很大程度上決定分類效果的效率與優劣,因而尋找有效的特征提取方法,不僅能降低文本特征向量的維數,而且可以抑制干擾詞語對分類的影響,從而提高分類精度[9]。文獻[10-11]對這幾種方法都進行了不同程度的介紹,并針對不同的中文語料集通過實驗進行分析比較。實驗結果表明,CHI分類效果較好,且在樣本數據分布不平衡或是樣本數據差異較大等情況下,同樣表現穩定。文中選擇CHI作為特征提取的方法。
(3)特征加權。
特征集合中不同的特征詞對樣本文檔的重要程度和區分度不同,所以需要對特征集合中的所有特征詞進行賦權重處理。常用的加權算法有:布爾權重(BooLean,BL)、詞頻權重(TermFrequency,TF)、倒文檔權重(InverseDocumentFrequency,IDF)和TFIDF權重(TermFrequency,InverseDocumentFrequency)等等[12]。
TFIDF權重規避了TF權重與IDF權重的缺點,將兩種權重算法結合起來,尋求一種折中[13]。即將以下兩種思想綜合考慮:特征詞t在樣本集中的文檔頻率df(t)越高,詞語t越不重要;特征詞t在文檔di中出現頻率越高,詞語t越重要。因此文中選擇了TFIDF方法進行特征權重的計算。
(4)中心法。
中心法文本分類的思想是:對于每個已知的類別i都存在一個類別的中心向量Ci,這個中心向量為該類別的代表向量。當需要對一個未知類別文本分類時,把文本向量d和每個類別的中心向量Ci進行對比,通過最大相似度確定該文本類別。但是,中心法分類需要滿足一個條件,即待分類向量與它所屬于的向量相似度要大于其他的類別,但是數據分布是有偏差的,這些偏差會導致判斷失誤,如圖2所示。

圖2 中心法偏差圖
如圖2所示,C1和C2分別為兩個類別,但是如果屬于C1類別的待分類文本位于兩個類別中心右側的位置,那么模型會將其判斷為C2類別,因為這樣待分類文本距離C2距離較近,若是如此將會出現偏差。
為了解決這一問題,進行兩點改進:一是修改中心向量的計算方法,使中心向量更具有顯著性和通用性;二是在中心法分類中盡量選擇更加合適的相似度計算方法。
通過以上分析,文中將嘗試使用不同的中心向量計算方法:均值法、總和法和歸一化法。分別對這些方法得到的結果進行評估,以確保中心法有更好的表現。
3 實驗設計
3.1 樣本的選取及處理
(1)樣本的選取。
由于目前國內尚無關于農業網頁的開放語料庫,文中的農業信息網頁樣本主要來源于國內農業相關網站。下面將簡單介紹樣本的選取和處理。
首先,從各大農業網站上抓取林業、種植業及制品、漁業、園林、畜牧業、農業生產資料、農業機械、植物病理農業相關的網頁,選取18 000張網頁。然后,組織30名學生每組3人共10組,每組標記1 800張網頁,每組三人對相同的1 800張網頁分別進行標記,標定結果寫入到結果表中。對每1張網頁3人標記相同時,才判定該網頁類別,不同則重新標記,標記結果差異數據統計見表1。

表1 數據標記差異統計
去除無法確定類別的剩余472條記錄。對分類結果進行數據統計,見表2。
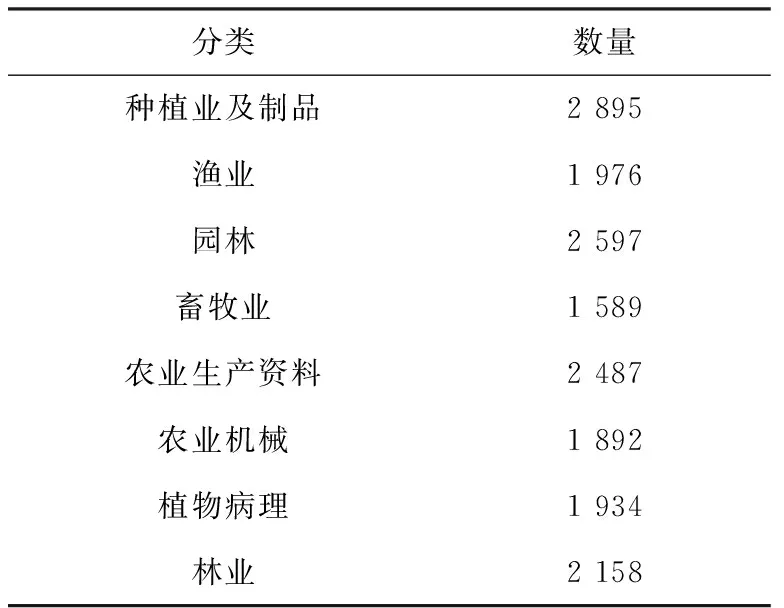
表2 分類結果統計
取其中每類70%作為訓練樣本集,其他每類30%作為測試樣本集。最終得到訓練樣本集共12 270個樣本,測試樣本集共5 258個樣本。
(2)樣本的處理。
首先,對樣本進行分詞,去除停用詞,提取特征詞。提取特征詞使用的方法是CHI,公式如下:
(1)
其中,N為訓練集中的文檔總數;A為屬于類別Ci且包含特征詞t的文檔頻數;B為不屬于類別Ci但包含特征詞t的文檔頻數;C為屬于類別Ci但不包含特征詞t的文檔頻數;D為不屬于類別Ci也不包含特征詞t的文檔頻數。
(2)
其中,w為使用TFIDF計算各項特征的權重。
(3)
其中,tfij為特征詞tj在文檔di中的詞頻權重;df(tj)為特征詞tj在樣本集中的文檔頻率。
然后,計算出每類樣本的中心向量,三種中心向量計算方法如下所示。
均值法計算公式為:
(4)
總和法計算公式為:
(5)
歸一化法計算公式為:
(6)

最后,使用歐氏距離計算待分類樣本與各類中心向量的相似度,待分類樣本與某類的相似度最高即屬于該類。
歐氏距離公式為:
(7)
3.2 實驗方案
中心法分類中需要兩步:第一步是訓練階段,即使用已給定的樣本標記集合生成具有分類能力的中心向量分類器;第二步是分類階段,即使用訓練階段生成的分類器對未知類別樣本進行分類,確定其所屬的類別。
(1)訓練階段。
①將從農業網站上獲取的農業網頁進行預處理,去除文檔標簽。
②使用庖丁解牛分詞器對中文文本進行中文分詞和去除停用詞等操作。
③使用X2統計提取出對分類貢獻較高的特征詞,將每篇文檔用一個特征詞集的向量表示。

(2)分類階段。


4 實驗結果
4.1 分類器性能評估
評估分類準確程度的依據是通過對網頁分類結果與人工分類結果進行比較,結果越相近,分類的準確程度就越高。國際上通用的評價指標有:查準率(Precision,P)、查全率(Recall,R)和F1測度[14]。
假設A、B、C、D含義如下:A表示樣本集中原本是正例,被模型判斷為正例的樣本數;B表示樣本集中原本是正例,卻被模型判斷為反例的樣本數;C表示樣本集中原本是反例,被模型判斷為反例的樣本數;D表示樣本集中原本是反例,卻被模型判斷為正例的樣本數。
查準率評價指標公式為:
(8)
查全率評價指標公式為:
(9)
F1測度是對查準率和查全率兩個指標進行加權和平均后形成的一個綜合指標。公式為:
(10)
4.2 結果與分析
實驗首先通過人工標記的方式選取出了17 528篇網頁作為實驗數據來源。這些網頁來源于各大農業網站,其中包含:種植業及制品(2 895篇)、漁業(1 976篇)、園林(2 597篇)、畜牧業(1 589篇)、農業生產資料(2 487)、農業機械(1 892篇)、植物病理(1 934篇)、林業(2 158篇)。將這些網頁的70%作為訓練樣本,30%作為測試樣本,如表3所示。

表3 訓練集和測試集劃分表
分別對基于總和法、均值法、歸一化法三種不同的中心向量計算方法的中心法進行測試,測試指標包括:查準率(P)、查全率(R)、F1測度。測試結果如表4~6所示。
每一類文章經過預處理、特征提取、特征加權后會變成一個矩陣,每一行代表一篇文章,每個值代表特征詞的重要性。總和法是指將同一類的所有文章特征向量進行求和運算,最后得到的和向量即為該類的中心向量;均值法是在總和法的基礎上取得和向量的平均值,由實驗結果得出,均值法在查全率、查準率和F1測度上比總和法高出了5%左右;歸一化法是為了消除指標之間的量綱影響,由實驗結果得出,歸一化法在查全率、查準率和F1測度上比總和法高出了10%左右,比均值法高出了5%左右。

表4 總和法計算中心向量的中心法分類結果

表5 均值法計算中心向量的中心法分類結果
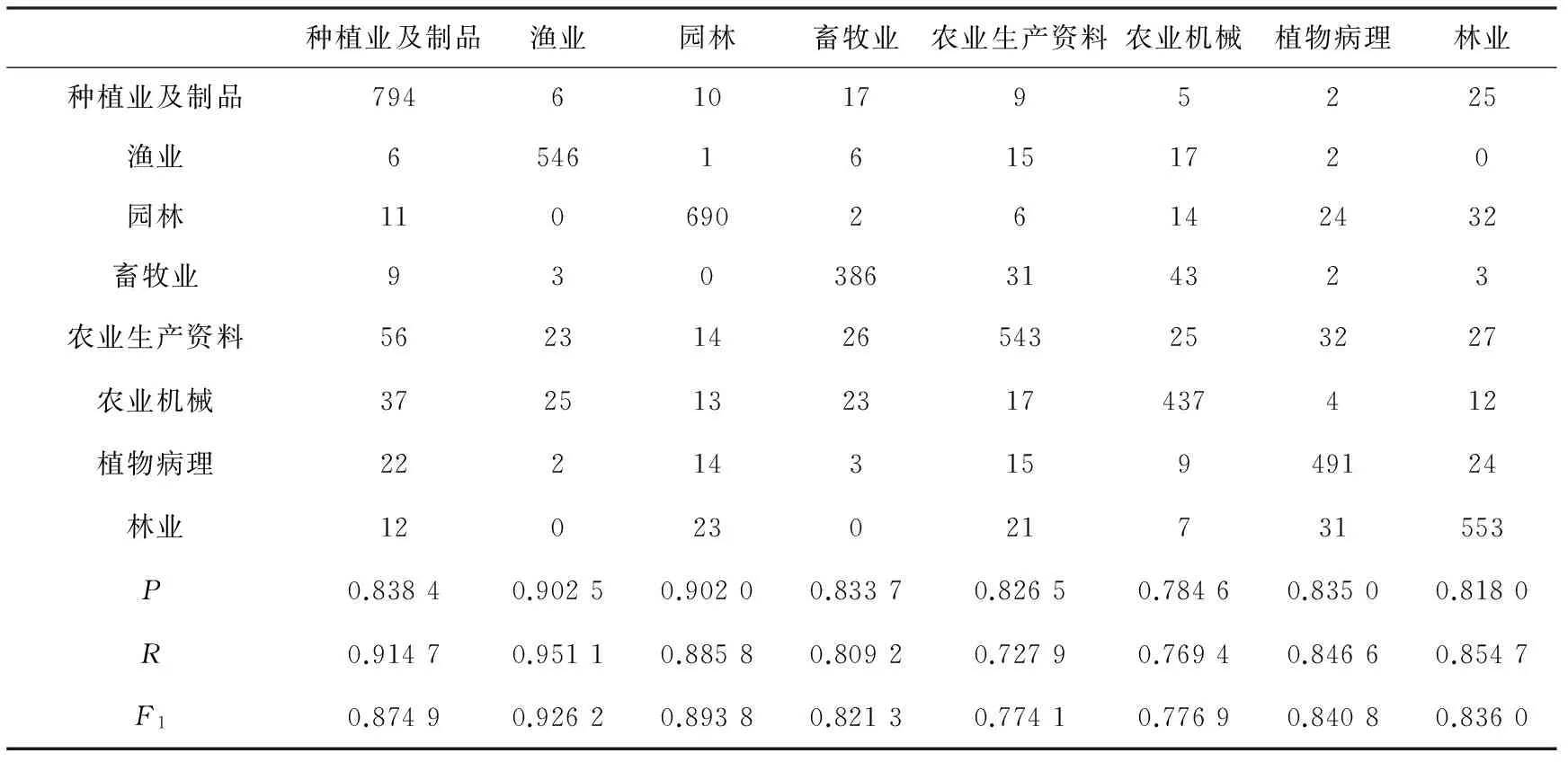
表6 歸一化法計算中心向量的中心法分類結果
通過測試結果可以發現,農業生產資料和農業機械分類結果在查全率、查準率和F1測度上表現的都比較差,原因可能是因為這兩類與其他類具有一定的關聯性,所以導致分類結果與其他相比較低。
實驗結果表明,改進后的使用歸一化方法計算中心向量的中心法的測試結果優于總和法和均值法,幾乎各項指標都達到了80%。由此可以推斷出改進中心向量的計算方法對中心法的改良起到了一定的作用,得到的分類結果更好,準確率更高。
5 結束語
文中采用中心法對農業信息網頁的分類進行了研究,實驗結果表明歸一化法計算中心向量對于農業信息網頁的分類判別有著較高的準確率。下一步將繼續調整中心向量的算法以及相似度算法,從而進一步提高模型在農業信息網頁分類中的準確率。與此同時探索其他文本分類方法,并設計對比實驗,以獲得更佳的農業信息網頁分類模型。
[1] 金一寧,王華兵,王德峰.基于KNN及相關鏈接的中文網頁分類研究[J].哈爾濱商業大學學報:自然科學版,2011,27(2):203-207.
[2] 江小平,李成華,向 文,等.云計算環境下樸素貝葉斯文本分類算法的實現[J].計算機應用,2011,31(9):2551-2554.
[3] 李 瓊,陳 利.一種改進的支持向量機文本分類方法[J].計算機技術與發展,2015,25(5):78-82.
[4] 胡金有,張 健,游龍勇.我國農業信息網站現狀分析[J].農機化研究,2005(6):38-40.
[5] 王 健,甘國輝.多維農業信息分類體系[J].農業工程學報,2004,20(4):152-156.
[6]FengXia,TangXianchao.Animproveddictionary-basedchinesewordsegmentationapproachinLucene[C]//Proceedingsof2010internationalconferenceonservicesscience,managementandengineering.[s.l.]:[s.n.],2010.
[7] 孫殿哲,魏海平,陳 巖.Nutch中庖丁解牛中文分詞的實現與評測[J].計算機與現代化,2010(6):187-190.
[8]ZhangQun,ChengYu.ResearchonChinesewordsegmentationalgorithmbasedonspecialidentifiers[C]//Proceedingsofthe2011internationalconferenceoncomputing,informationandcontrol.[s.l.]:IntelligentInformationTechnologyApplicationAssociation,2011.
[9] 王霜霜,張太紅,馮向萍,等.農業網站導航頁面識別模型研究[J].新疆農業大學學報,2011,34(5):447-453.
[10] 蘇金樹,張博鋒,徐 昕.基于機器學習的文本分類技術研究進展[J].軟件學報,2006,17(9):1848-1859.
[11]WangBingkun,HuangYongfeng,YangWanxia,etal.Shorttextclassificationbasedonstrongfeaturethesaurus[J].JournalofZhejiangUniversity-ScienceC(Computers&Electronics),2012(9):649-659.
[12]ZhangYuntao,GongLing,WangYongcheng.AnimprovedTF-IDFapproachfortextclassification[J].JournalofZhejiangUniversityScienceA(ScienceinEngineering),2005,6A(1):49-55.
[13] 張保富,施化吉,馬素琴.基于TFIDF文本特征加權方法的改進研究[J].計算機應用與軟件,2011,28(2):17-20.
[14] 宋楓溪,高 林.文本分類器性能評估指標[J].計算機工程,2004,30(13):107-109.
Research on Improved Center Vector Algorithm in Agricultural Information Classification
ZHAO Xin-miao,FENG Xiang-ping,LI Yong-ke
(College of Computer and Information Engineering,Xinjiang Agricultural University,Urumqi 830052,China)
Since twenty-first century,the site of agricultural information has increased rapidly.In order to provide the convenience for farmers and agricultural researchers,it is need to classify agricultural information.The classification of agricultural information is favor of acquisition and management of the agricultural information.There are several ways to classify agricultural information,in which the centroid-based classification is simple and effective.In this paper,it uses centroid-based classification to find the more efficient one to improve the accuracy of agricultural information.At present,most of the methods for calculating the center vector of the text are the average value of the text feature vector.This method can’t get a good classification results due to the model deviation for center vector obtained.In order to solve this problem,the sum method,means method and normalization method is used to calculate the center vector and the result of three methods are compared.The results show that the normalization method has better performance in Precision,Recall andF1measure.
agricultural information;classification;centroid-based method;center vector;text feature vector
2015-11-19
2016-03-04
時間:2016-08-01
新疆維吾爾自治區高技術研究發展計劃項目(2015X0103)
趙新苗(1990-),女,碩士研究生,研究方向為數據庫技術;馮向萍,副教授,研究生導師,通訊作者,研究方向為數據庫技術及應用。
http://www.cnki.net/kcms/detail/61.1450.TP.20160801.0842.020.html
TP
A
1673-629X(2016)08-0146-06
10.3969/j.issn.1673-629X.2016.08.031
猜你喜歡
今日農業(2022年1期)2022-11-16 21:20:05
今日農業(2022年3期)2022-11-16 13:13:50
今日農業(2022年2期)2022-11-16 12:29:47
今日農業(2021年14期)2021-11-25 23:57:29
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
