Bloom Filter在重復數據刪除技術中應用的研究
2016-02-23 06:29:04陳春玲
計算機技術與發展 2016年8期
陳春玲,陳 琳,熊 晶,余 瀚
(南京郵電大學 計算機學院 軟件學院,江蘇 南京 210003)
Bloom Filter在重復數據刪除技術中應用的研究
陳春玲,陳 琳,熊 晶,余 瀚
(南京郵電大學 計算機學院 軟件學院,江蘇 南京 210003)
為了緩解存儲系統中因為重復數據索引而引起的存儲設備訪問過于頻繁的問題,深入研究重復數據刪除技術,并針對目前重復數據刪除技術中Bloom Filter的運用以及存在的存儲設備訪問性能問題進行分析和研究,提出一種基于Bloom Filter的高效去重優化模式。針對單一Bloom Filter固有的假陽性的缺陷,增加輔助Bloom Filter,從而減小誤判率,達到減少存儲設備訪問次數的目的;針對因系統軟件錯誤引起的Bloom Filter假陰性錯誤,引入單校驗位的錯誤校驗機制可以實現避免假陰性值存儲的同時又能減小內存存儲開銷。仿真實驗結果表明:改進方法能夠兼顧Bloom Filter的誤判率與存儲設備訪問開銷問題。通過引入一種判斷機制配合輔助Bloom Filter和單校驗位機制,能夠達到誤判率降低、存儲設備訪問開銷減小的高性能優化效果。
Bloom Filter;假陽性;假陰性;單位校驗;訪問開銷
0 引 言
大數據時代的到來使得數據呈現爆炸性增長態勢,信息存儲的應用領域越來越廣泛,指數級增長的數據無疑給企業的業務運營乃至人們的日常生活都帶來了巨大的挑戰[1],數據占用的存儲空間變得越來越大。根據國際數據公司(International Data Corporation,IDC)的最新預測,在未來的10年內,全球的數據總量將增長為現在的50倍[2]。爆炸式增長的數據量對現有的存儲系統的容量、吞吐性能、能耗管理和可擴展性等都帶來了新的挑戰。研究發現,所存儲的數據中約有六成以上都是冗余的,并且隨著時間的推移,這種冗余所造成的存儲成本與管理能耗問題將變得越來越嚴重。為了節省存儲空間資源,重復數據刪除技術應運而生,并因其能夠在很大程度上緩解存儲利用率低的問題而應用廣泛,并成為近年來存儲領域的研究熱點。該技術可以識別并消除大量的冗余數據,從而大大降低存儲成本,提高數據索引的質量。
通過優化存儲方式可以減少數據對存儲設備的訪問次數。Bloom Filter是一種支持重復數據快速判斷的輕量級索引機制。在付出一定誤判率的前提下,其所需的存儲容量只和條目數相關,而與具體字符的個數無關[3]。并且它的存儲空間和通過k個hash函數進行插入/查詢的時間都是常數O(k),同時BloomFilter占用的空間很小,BloomFilter的比特位通常被存放在內存里,而且存儲BloomFilter所需的空間又遠小于其可以存儲的元素個數,因此訪問BloomFilter的查詢速率很高,所以被廣泛應用于眾多領域。當查詢一個數據塊是否為重復數據時,在訪問存儲設備之前先訪問BloomFilter。如果在BloomFilter內查找不到該塊的索引,說明數據塊不存在,是一個新的數據塊,可以直接存儲數據塊的相關信息和元數據本身,而不需要訪問存儲設備進一步查找,能夠大大減少對存儲設備的I/O訪問次數[4],從而減小訪問開銷。
1 相關技術
1.1 Bloom Filter
Bloom Filter,即布隆過濾器,由Burton Howard Bloom于1970年提出。它是一種空間效率極高的隨機數據結構,可以用于檢索一個元素是否在一個集合中,因此通常被應用于基于磁盤的備份系統中,旨在減少存儲系統中使用的存儲容量和磁盤訪問量。不管這個元素大小如何,Bloom Filter都只以一種類似“簽名”的方式使用幾個比特位來表示并存儲在數組中。它包括一個m位的數組B,并將每位初始化為0,數組存儲一個來自通用集的集合S中的元素信息。BloomFilter可以分為插入與索引:
插入:將集合S里的n個元素x1,x2,…,xn插入到BloomFilter過濾器,通過k個不同且相互獨立的hash函數hi(x),1≤i≤k,hi(x)取值范圍為數組B的下標[0,m-1],隨機映射到m位數組B中對應的k個比特位上,并將數組B上對應的B[h1(x)],…,B[hk(x)]置為1。圖1展示了將元素插入到k為3、數組大小為m的BloomFilter的過程[5]。
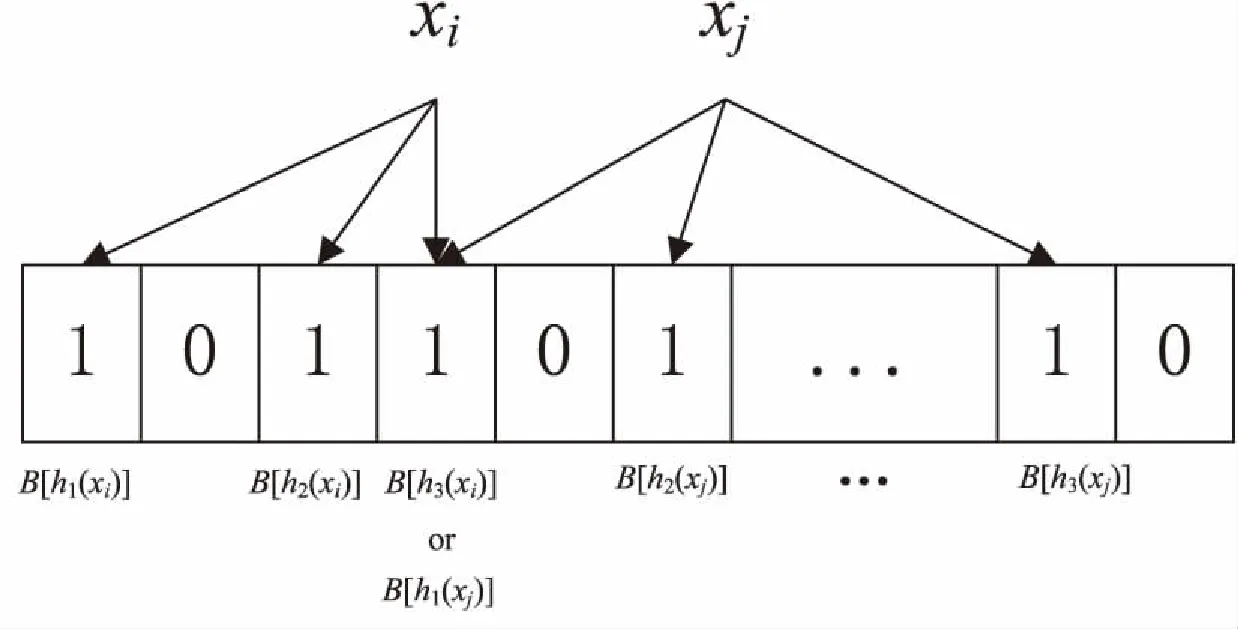
圖1 元素插入示意圖
其中數組下標為3的比特位上,元素xi和xj都映射到了該位置。
檢索:當檢索一個元素x是否屬于集合S時,通過k個hash函數映射到BloomFilter對應的數組里的k個比特位上,看該k個位置是否全為1。如果全為1,就以一定的誤判率認為該元素x屬于集合S;若發現k個位置上有一位為0,就可以肯定元素x一定不屬于集合S。索引的示例圖如圖2所示。

圖2 元素索引示意圖
一個BloomFilter不會存在假陰性的情況,即如果顯示一個元素不在數組里,那么在數組里就真沒有該元素;但是BloomFilter存在假陽性,即使待索引的元素不在集合里,經過k個hash函數映射進BloomFilter里也有可能產生陽性結果,即認為該元素已在集合內[6],而這個元素所映射到的比特位之所以為1是由于別的元素經過hash函數后映射到了該位,如圖1中就存在了這樣的問題。所以BloomFilter即使判斷出一個元素在數組里也不一定就真的在數組里,也就是說BloomFilter存在誤判率,可以表示為:
(1)
其中,n為集合中元素的個數。


(2)

(3)
內存極易受到軟件錯誤的攻擊,給Bloom Filter的計算帶來不必要的麻煩。但是,在Bloom Filter中假陽性是固有的,因此,軟件錯誤導致假陽性的概率不會顯著增加,因此給過濾器帶來的影響也幾乎可以忽略不計。但是由于軟件錯誤造成的假陰性值的問題將給Bloom Filter的判重性能帶來質的影響,尤其是當Bloom Filter運用在安全領域時,假陰性值將帶來致命的錯誤。因此必須針對一些可能造成Bloom Filter假陽性或者假陰性的系統軟件錯誤引入系統糾錯碼來識別并糾正錯誤[8]。ECC中比較具有代表性的是單一糾錯碼(Single Error Correction code,SEC)。它將Bloom Filter里m比特的數組映射為內存字進行存儲,并對每個字都設置校驗位進行校驗。
SEC能夠成功識別出被系統錯誤修改的字,并加以改正,但是用于糾錯在內存中引入了大量的校驗位,無疑會給內存帶來更多存儲空間的需求,造成了存儲開銷的增加。不僅如此,由于內存空間是有限的,即使是SEC,也因為引入了額外的內存存儲空間,使得BloomFilter的比特位數量不得不減少來讓出更多的比特校驗空間,這樣反過來也增加了誤判率,而且對讀寫所必須的編碼和譯碼的使用也會影響ECCs的訪問次數,一定程度上以增加能耗來換取對系統軟件錯誤的檢測效果[9]。
文獻[10]中提到可以運用多個BloomFilter指紋摘要陣列來存儲相鄰存儲節點里的信息,通過先列后行的方式檢索,使得每個節點不僅可以快速判斷出新數據塊,還能夠進行全局范圍的重復數據刪除,并且消除各節點之間的冗余數據,確保不會因為誤判率而錯誤刪除新數據。但是它必須在每個節點里都存儲這樣的指紋陣列,這樣會增加存儲開銷,在一定程度上降低了系統的性能。
文獻[11]針對在大數據環境下查詢存儲系統里的一個源文件花費時間長的問題,在存儲系統中應用一種加強版的布隆過濾器來加速在大型存儲系統中索引文件的過程,其產生的假陽性率與假陰性率也能控制在一個很小的范圍,證明了BloomFilter在存儲系統中的運用是高效可行的,但是對于因BloomFilter表沒有及時更新所帶來的假陰性值的處理與預防方式還沒有進行深入研究。
基于上述情況,文中引入輔助BloomFilter,通過兩次BloomFilter判斷,不僅可以減小內存開銷,同時能夠實現較低的誤判率,進而減少對存儲設備的訪問頻率;引入單校驗位以期達到SEC的校驗效果,又能夠減少對內存空間的需求,同時可以防止因為系統軟件錯誤導致的假陰性情況的發生。
2 針對Bloom Filter判重關鍵技術的研究與改進
文中提出的優化模式通過引入一個輔助Bloom Filter,來識別原Bloom Filter識別為陽性的結果,如果經過輔助Bloom Filter仍識別為陽性結果,就需要訪問存儲設備里的hash索引表,判斷其是否為重復數據[12]。而針對原Bloom Filter識別為陰性的結果不是直接將其判定為新數據塊進行存儲,而是使用單校驗位的校驗機制進行字的校驗。如果校驗結果為沒有被軟件錯誤修改過,那么就認為是新數據塊可以進行存儲;如果發現被軟件錯誤修改為陰性結果,就要改正并訪問存數設備的索引表查看是否為重復數據。具體實現過程如圖3所示。
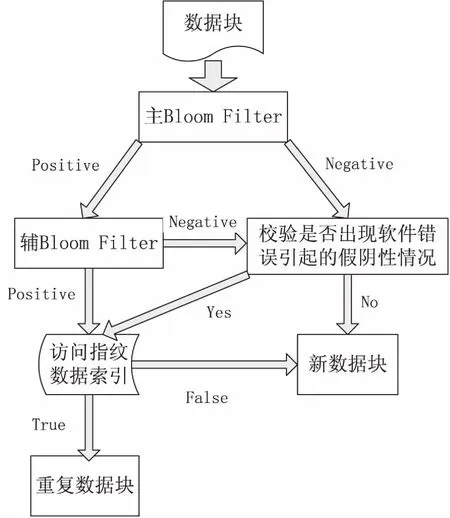
圖3 改進Bloom Filter的判重過程圖
針對情況一,在查詢一個輸入x是否為集合內的元素時,如果經過k個hash函數計算后B(hi(x))為1,x就被認為是集合S經過BloomFilter后的一個陽性結果。記集合A(S)為集合S里元素經過BloomFilter中k個hash函數后B(hi(x))為1的所有元素,即A(S)是S集合中BloomFilter為陽性的集合。如果有元素x∈S,那么經過k個hash函數后的B(hi(x))就為1且x∈A(S)。因此可以推出集合S屬于A(S)。但也存在一些元素不屬于集合S卻因為別的元素映射到了該位,使得該元素的B(hi(x))也為1,稱這樣的元素為x∈A(S)-S,即A(S)-S為假陽性。有關系如下:
A(S)=S∪(A(S)-S)
(4)
S∩(A(S)-S)=?
(5)
式(1)中的誤判率f是假設x?S的情況下成立的,故稱這種有條件的集合為S',此時f可以表示為:
(6)
其中,S'為集合S的補集,此時P(A(S))可以表示為:
(7)

P(A(S))=P(S)+P(S')f
(8)
由式(4)、(5)、(8)可以推出:
P(A(S)-S)=P(S')f
(9)
其中,式(4)、(5)可以推出P(A(S)-S)=P(A(S))-P(S)。
可以使用A(S)和(A(S))'兩部分來表示通用集,而A(S)又可以由S和A(S)-S表示;同理,通用集也可以由A(S')和(A(S'))'兩部分表示,而A(S')同樣可以由S'和A(S')-S'表示。因此可以推斷出通用集由A(S)-S,(A(S))',A(S')-S'和(A(S'))'四部分組成,而(A(S'))'屬于S,并且(A(S))'屬于S',因此可以推測出通用集由(A(S'))',A(S)∩A(S'),(A(S))'三部分組成,進而推出A(S)∩A(S')可以由A(S)-S和A(S')-S'表示:
A(S)∩A(S')=(A(S)-S)∪(A(S')-S')
(10)
(A(S)-S)∩(A(S')-S')=?
(11)
其中,A(S)∩A(S')表示兩個BloomFilter均產生陽性結果,也就意味著其中一個過濾器產生了假陽性值,這時就需要訪問hash表判別是否存在該重復數據塊在存儲系統中[13]。此時引入輔助的BloomFilter,令n'表示集合S'里元素的個數,可以推出對輔助BloomFilter的誤判率為:
(12)
故兩個BloomFilter都呈現假陽性的概率可以表示為:
P(A(S)∩A(S'))=P(A(S)-S)+P(A(S')-S')=P(S')f+P(S)f'
(13)

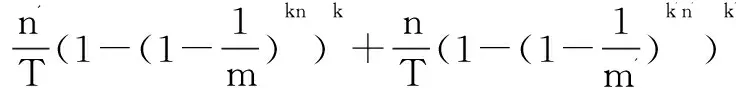
(14)
單個BloomFilter的情況下可以通過控制m的大小使誤判率降到很小,那么兩個BloomFilter同樣可以通過控制m的大小,使得誤判率達到一個更小的值。
針對情況二,如果原BloomFilter產生了陰性的值,那么不能直接判定該元素就是新數據塊,因為可能存在軟件錯誤引起的假陰性值的情況。文中通過將BloomFilter里m比特的數組映射為內存字存儲,假定每個字大小為L比特,那么數組一般可以表示成m/L個字,圖4展示了單比特位校驗機制。
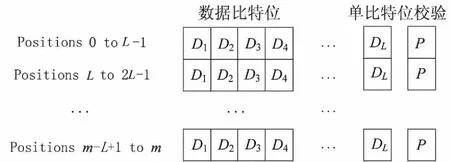
圖4 單比特位校驗機制
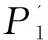
經過比特校驗位之后的數據塊,如果沒有發現被軟件錯誤修改,那么直接可以判斷出該數據塊為新數據塊,如果發現內存中字的校驗位被改變時,則使用文中提出的方法進行糾錯。一旦發現出現了假陰性值,定位出出錯比特位后再去訪問存儲設備內對應的索引表,如果找到該索引,則證明該數據塊是重復數據,可以刪除;如果沒有找到對應的索引,則證明該數據塊是新數據塊,可以直接存入存儲設備。
3 實 驗
改進的BloomFilter在時間復雜度上相比標準BloomFilter仍能保持常數級別的時間復雜法,不增加任何負擔。
3.1 實驗軟硬件配置及參數選取
仿真環境采用戴爾PowerEdge T410電腦,處理器為Intel Xeon E5506 16G,系統為64位Windows7,算法采用Java語言實現。
在性能測試中,針對標準Bloom Filter需要訪問存儲設備里的hash表的概率與文中改進方法對存儲設備訪問率進行比對。選取一個尺寸因子α來表示原BloomFilter和輔助BloomFilter的大小,m=αn,m'=αn'。根據式(3),分別選取α為2,22,23,24,相應的k取1,3,6,11來表示。針對引入的單校驗位錯誤校驗機制,對其所有字對應的位設為1所帶來的假陽性率進行實驗,看其是否增加了額外的假陽性率。
3.2 實驗結果及分析
在標準Bloom Filter里,即使在對一個Bloom Filter里m值設置很大且誤判率很低的情況下,產生每個陽性結果都會導致一次存儲設備的訪問。而文中提出的優化方法可以有效限制由于BloomFilter產生假陽性結果所引起的存儲設備訪問問題。
圖5為單一標準BloomFilter與文中提出的改進BloomFilter,隨著α因子大小的增加而產生的存儲設備訪問變化的比較。

圖5 存儲設備訪問率對照表
從圖中可以發現,文中提出的優化BloomFilter方法使得訪問存儲設備里hash表的訪問量大大降低,并且隨著α因子的增大而性能更優,當α為32時達到最佳情況,從而大大減小了存儲設備的訪問開銷。
圖6為引入單校驗位機制中為了避免假陰性值的產生,而將存儲字里的所有位都設為1可能帶來的假陽性率的變化情況。
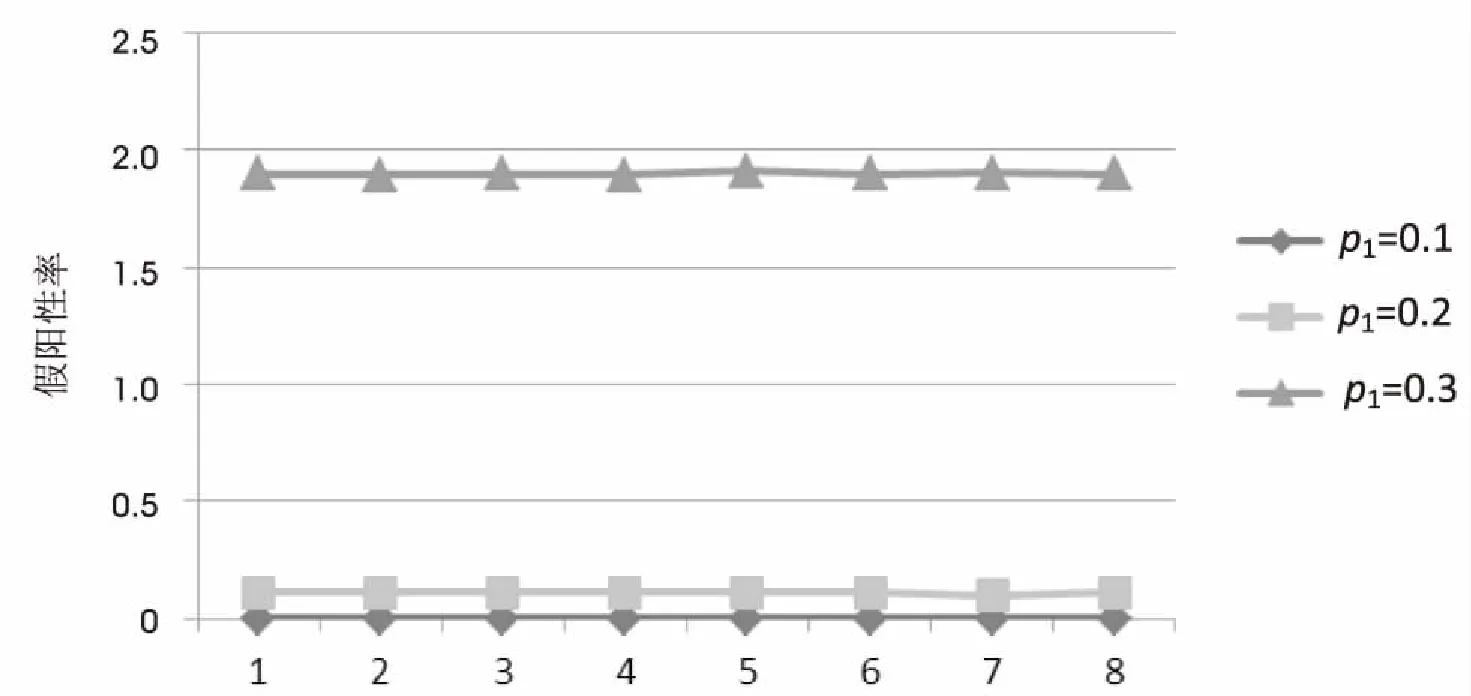
圖6 假陽性率變化表
從圖中可以看到,產生的假陽性概率的變化頻率很小,在同一標準下的波動幾乎可以忽略不計。
實驗結果表明,文中改進的BloomFilter算法,引入的輔助BloomFilter能夠有效降低假陽性率,減少對存儲設備的訪問量,大大減小了訪問存儲設備的開銷,優化了性能;引入的單校驗位錯誤校驗機制,沒有像SEC校驗那樣需要消耗大量的內存空間,僅使用一位校驗位,降低了對內存存儲空間的需求,同時將所有校驗字位設為1所帶來的額外假陽性率在大部分的應用場景中幾乎可以忽略不計,因此大大提高了存儲設備的空間利用率,在降低存儲訪問和存儲成本的同時,又能保證BloomFilter的高效性。
4 結束語
結合目前針對存儲設備訪問開銷的問題進行研究,引入輔助BloomFilter減少由假陽性值帶來的多次訪問存儲設備的問題,在減小訪問開銷的同時,運用數學方法證明了引入輔助BloomFilter的可行性。引入單校驗位校驗機制避免因假陰性值所帶來的不必要的存儲系統訪問和存儲空間的浪費,進而使得BloomFilter判重的性能得到優化,在容錯率允許的情況下識別出由系統軟件錯誤帶來的假陰性問題,同時又使得改進方法所帶來的假陽性率小到忽略不計。通過一種判斷機制,對BloomFilter產生值進行區分處理,改進的BloomFilter方法可以在保證準確率更高、性能更優的情況下,使判重效率更高,空間更加節約,訪問存儲設備開銷更小。未來可以在進一步探索如何實現高效重復數據刪除的同時兼顧重復數據刪除技術的可靠性、實時性以及索引等問題。
[1] 謝 平.存儲系統重復數據刪除技術研究綜述[J].計算機科學,2014,41(1):22-30.
[2] Labrinidis A,Jagadish H V.Challenges and opportunities with big data[J].Proceedings of the VLDB Endowment,2012,5(12):2032-2033.
[3] 黃慧群,何 敏,蘭巨龍.基于布魯姆過濾器的未決興趣表查找方法研究[J].信息工程大學學報,2015,16(1):84-89.
[4] 張星煜,張 建,辛明軍.相似性-局部性方法相關參數分析[J].計算機技術與發展,2014,24(11):47-50.
[5] Gong Q,Yang T,Tong H,et al.Reducing the number of Bloom filters[C]//Proc of international conference on progress in informatics and computing.[s.l.]:IEEE,2014.
[6] Guo D,Wu J,Chen H,et al.The dynamic Bloom filters[J].IEEE Transactions on Knowledge & Data Engineering,2010,22(1):120-133.
[7] Tang S,Jin A,Wang Y.A comment on “fast bloom filters and their generalization”[J].Molecular Medicine,2016,13(3-4):303-304.
[8] Saravanan K, Senthilkumar A, Chacko P.Modified whirlpool hash based bloom filter for networking and security applications[C]//Proc of 2nd international conference on devices,circuits and systems.[s.l.]:IEEE,2014.
[9] Xia W,Jiang H,Feng D,et al.Similarity and locality based indexing for high performance data deduplication[J].IEEE Transactions on Computers,2015,64(4):1162-1176.
[10] 王國華.高效重復數據刪除技術研究[D].廣州:華南理工大學,2014.
[11] Kim M,Oh K H,Youn H Y,et al.Enhanced dual Bloom filter based on SSD for efficient directory parsing in cloud storage system[C]//Proc of international conference on computing,networking and communications.[s.l.]:IEEE,2015:413-417.
[12] Rottenstreich O,Keslassy I.The Bloom paradox:when not to use a Bloom filter[J].IEEE/ACM Transactions on Networking,2015,23(3):703-716.
[13] Antikainen M,Aura T,S?rel? M.Denial-of-service attacks in bloom-filter-based forwarding[J].IEEE/ACM Transactions on Networking,2014,22(5):1463-1476.
Research on Application of Bloom Filter in Data Deduplication
CHEN Chun-ling,CHEN Lin,XIONG Jing,YU Han
(School of Computer Science & Technology,School of Software,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
In order to alleviate the problem of the frequent access to storage device which caused by the indexes using in data deduplication,data deduplication is deeply studied,making analysis and research on the application of Bloom Filter at the present situation of data deduplication and existing problems of the access of storage system performance and proposing a high-efficiency and optimal model based on Bloom Filter.Aiming at the situation that the probability of false positives is in the nature of Bloom Filters,an additional Bloom Filter is used to reduce false positive rate,achieving the purpose of reducing times of the access for storage system.In view of the situation that the system software errors may bring Bloom Filter false negative,single bit error checking mechanism is introduced to prevent it from happening,at the same time,it can reduce memory overhead.The simulation shows that the proposed method can balance the false positive rate and the access of storage system costs.By introducing a judgment mechanism with complement Bloom Filter and single bit error checking mechanism,it can achieve the effects of the reducing of false positive rate and the access of storage system costs.
Bloom Filter;false positive;false negative;single bit error checking;access costs
2015-11-26
2016-03-04
時間:2016-08-01
國家自然科學基金資助項目(11501302)
陳春玲(1961-),男,教授,研究方向為軟件技術及其在通信中的應用、網絡信息安全等;陳 琳(1990-),女,碩士研究生,研究方向為軟件技術及其在通信中的應用和大數據。
http://www.cnki.net/kcms/detail/61.1450.TP.20160801.0904.030.html
TP39
A
1673-629X(2016)08-0182-05
10.3969/j.issn.1673-629X.2016.08.039
